Felice, Zheng Yuan, Øistein E. Andersen, Helen Yannakoudakis, and Ekaterina Kochmar Proceedings of the 18th Conference on Computational Natural Language Learning: Shared Task, pages 15–24, 2014 自然言語処理研究室 小川 耀一朗 0
can also ・Srun: カンマ区切り The issue is highly [debatable, a → debatable. A] genetic risk could come from either side of the family.[1] ・Wa: 頭字語 After [WOWII → World War II], the population of China decreased rapidly.[1] 10 /12
Hadiwinoto, Raymond Hendy Susanto, and Christopher Bryant. 2014. The CoNLL- 2014 Shared Task on Grammatical Error Correction. In Proceedings of the Eighteenth Conference on Computational Natu- ral Language Learning: Shared Task (CoNLL-2014 Shared Task), Baltimore, Maryland, USA, June. Association for Computational Linguistics. To appear. [2]Diane Nicholls. 2003. The Cambridge Learner Corpus: Error coding and analysis for lexicography and ELT. In Dawn Archer, Paul Rayson, Andrew Wilson, and Tony McEnery, editors, Proceedings of the Corpus Linguistics 2003 conference, pages 572– 581, Lancaster, UK. University Centre for Computer Corpus Research on Language, Lancaster University. 13
{kind=link}
{kind=link}
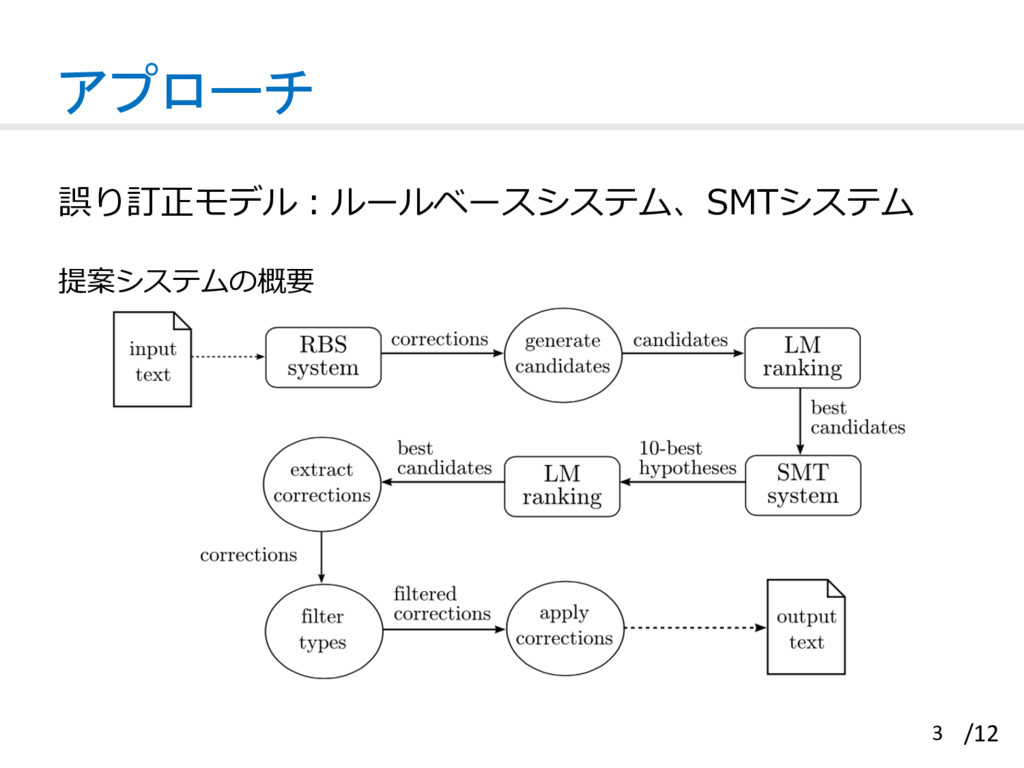
![背景 現在の⽂法誤り訂正⼿法は多くのエラータイプにおいて⾼ 性能を達成していない[1] CoNLL-2014 shared task: Grammatical Error Correction[1] •](https://files.speakerdeck.com/presentations/e87679a501cd40dfbacdf5c91e992a26/slide_2.jpg){kind=link}
{kind=link}
![ルールベース誤り訂正システム Cambridge Learner Corpus2(CLC) から⾃動的に得られ たルールを使って訂正 CLC: 1600万語の学習者英語コーパス、86の異なる⺟国語の英 語学習者によって書かれた全ての誤りを保持している[2] 4](https://files.speakerdeck.com/presentations/e87679a501cd40dfbacdf5c91e992a26/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
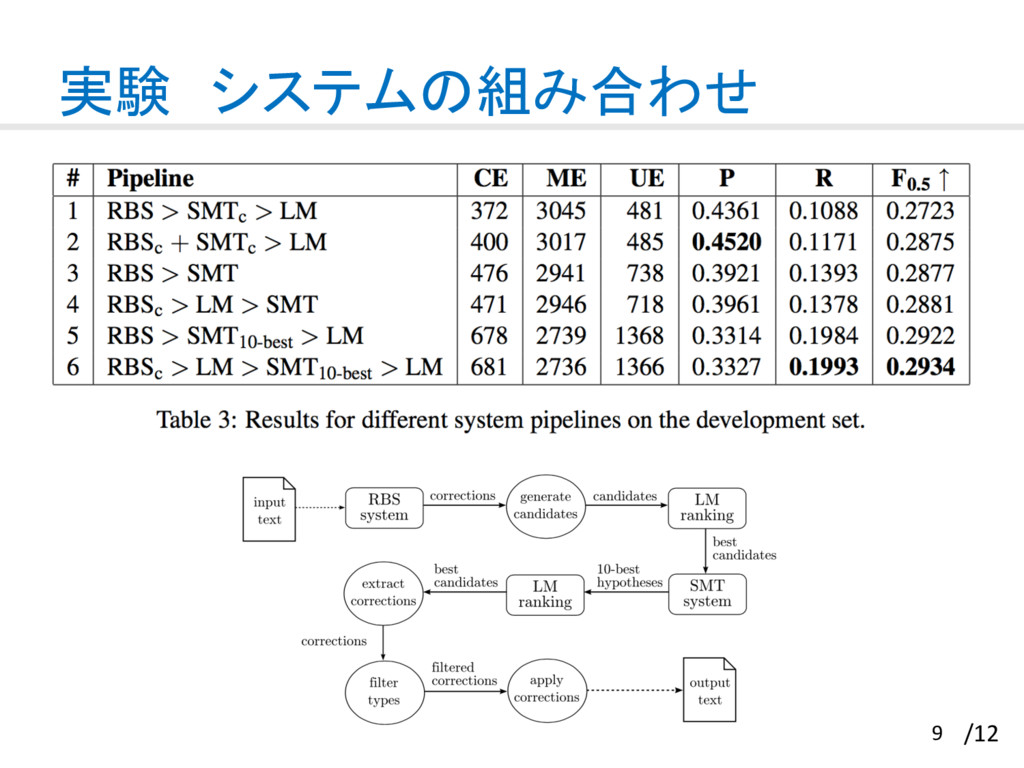{kind=link}
{kind=link}
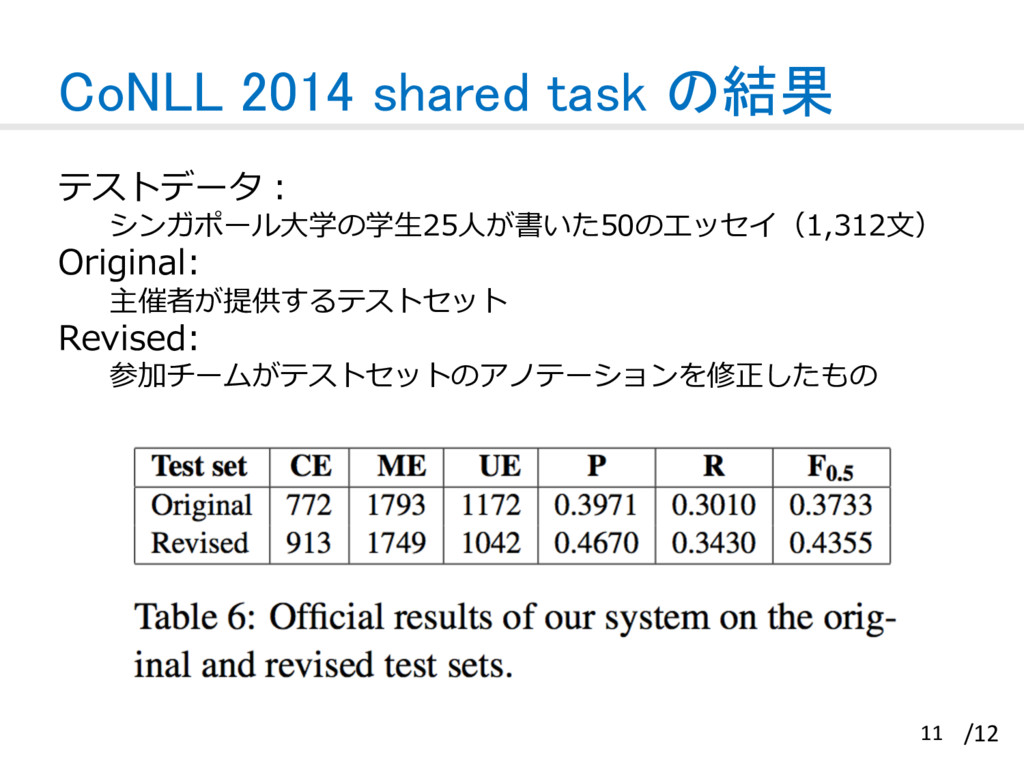{kind=link}
{kind=link}
![参考文献 [1]Hwee Tou Ng, Siew Mei Wu, Ted Briscoe, Christian](https://files.speakerdeck.com/presentations/e87679a501cd40dfbacdf5c91e992a26/slide_13.jpg){kind=link}
![参加チームのスコア[1] 14](https://files.speakerdeck.com/presentations/e87679a501cd40dfbacdf5c91e992a26/slide_14.jpg){kind=link}