Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械翻訳システムの誤り分析のための誤り箇所選択手法
Search
youichiro
March 27, 2017
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械翻訳システムの誤り分析のための誤り箇所選択手法
文献紹介(17.3.28)
長岡技術科学大学
自然言語処理研究室
youichiro
March 27, 2017
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
100
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
2
160
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
340
Type-safe IaC for Dart
coborinai
0
110
誤解だらけの開発生産性 / Myths and Misconceptions about Developer Productivity
i35_267
2
710
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
9
3.8k
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
140
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
230
AICoEでAIネイティブ組織への進化
yukiogawa
0
180
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.8k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
220
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
270
Featured
See All Featured
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Become a Pro
speakerdeck
PRO
31
6k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Agile that works and the tools we love
rasmusluckow
331
22k
From π to Pie charts
rasagy
0
230
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Utilizing Notion as your number one productivity tool
mfonobong
4
410
What's in a price? How to price your products and services
michaelherold
247
13k
Discover your Explorer Soul
emna__ayadi
2
1.2k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Product Roadmaps are Hard
iamctodd
55
12k
Transcript
機械翻訳システムの誤り分析の ための誤り箇所選択手法 赤部 晃一, Graham Neubig, Sakriani Sakti, 戸田 智基,
中村 哲 自然言語処理, Vol. 23, No. 1, pp. 87-117, 2016 文献紹介 平成29年3月28日 長岡技術科学大学 自然言語処理研究室 小川耀一朗
概要 目的: 機械翻訳システムの比較・改善のための誤り分析の効率化 従来手法: 単純にシステムの翻訳結果と正解訳の差異に着目して分析 提案手法: 機械翻訳の誤り箇所選択法、選択箇所のフィルタリング法 結果: 従来手法より高い精度で適切な誤り箇所を捉えることに成功 優先的に選択された少量の誤り箇所からシステムの誤り傾
向を捉えることに成功 2/21
研究背景 u最近の機械翻訳システムはシステムの内部が複雑化して おり、翻訳システムの傾向を事前に把握することが難しい u翻訳結果に注目→システムの問題点、システム同士を比 較 u翻訳結果の誤り分析は労力がいる→効率化 3/21
提案手法 先行研究: • 参照文と翻訳結果の差分で誤り分析 • 同様の意味でありながら表層的な文字列が異なる場合に、 不一致箇所を誤り箇所と判断してしまう 提案手法: • 誤りと判断されたものの内、より誤りの可能性の高い箇所
を優先的に捉える手法 翻訳結果を生成 →誤り分析を優先的に行うべき箇所を選択 →選択箇所を人手により分析 4/21
誤りの可能性をスコア付け 誤りの可能性が高い箇所から順に提示 →人手による誤り分析の効率が上がる 手法: nランダム選択 n誤り頻度に基づく選択 n自己相互情報量に基づく選択 n平滑化された条件付き確率に基づく選択 n識別言語モデルの重みに基づく選択 5/21
ベースライン nランダム選択 • 順位づけを行わない誤り分析 n誤り傾向に基づく選択 • 翻訳結果に多く含まれ、正解訳に含まれない回数が多 いn-gramを重点的に分析する • 頻繁に発生する誤りが必ずしも分かりやすく有用な誤り
とは限らない • 目的言語に頻繁に出現するn-gramが分析対象の上位 を占めてしまう 6/21
提案手法1 n自己相互情報量に基づく選択 • 誤り頻度の高いn-gramと翻訳結果との関係性をスコア づけ • 翻訳結果と関係が強いn-gramは、正解訳との関係は 逆に弱くなる 7/21
提案手法2 n平滑化された条件付き確率に基づく選択 • 誤り頻度の高いn-gramがシステムの出力に含まれな がら参照文に含まれない確率をスコアとする 8/21
提案手法3 n識別言語モデルの重みに基づく選択 • 言語モデル →自然な出力言語文の特徴を捉えるように学習される • 識別言語モデル →起こりやすい出力誤りを修正するように学習される 9/21
スコア計算に用いる正解訳の選択 参照訳: 正解訳として事前に人手で翻訳されたもの → 使用する語彙が翻訳結果と異なる場合が多い オラクル訳: 機械翻訳システムが出力した翻訳候補の中で、自動評 価尺度により最も高いスコアが与えられた文 参照訳に近い表現を維持しながらシステムの翻訳に近づく 10/21
誤り候補n-gramのフィルタリング n厳密一致フィルタリング 誤り箇所のn-gramが、正解訳の一部に厳密一致するか どうかを確認し、一致する場合は選択を行わない n換言によるフィルタリング 表層的に異なるが意味が等しい文字列の場合、厳密一 致フィルタリングでは誤選択になる 換言データベースから正解訳の全単語に対して換言を 検出し、換言が誤り候補にあったら候補から除外する 11/21
選択された誤り箇所の調査 u各手法によって順位付けされた誤りn-gramを人手で分析 u各誤り箇所選択手法によって選択された箇所が、機械翻 訳の誤り箇所を捉えているかをアノテーション →誤り箇所の適合率を測定 u誤り箇所を捉えている場合は、誤りの種類をアノテーショ ン { 文脈依存置換誤り, 文脈非依存置換誤り,
挿入誤り, 削除誤り, 並べ替え誤り, 活用誤り } 12/21
実験設定 コーパス: 京都フリー翻訳タスク(KFTT)(Neubig 2011)日英翻訳 単一の機械翻訳システム: Travatarツールキット(Neubig 2013)に基づくforest-to- string(F2S) システム比較: Mosesツールキットに基づくフレーズベース翻訳システム
(PBMT) 階層的フレーズベースシステム(HIERO) 13/21
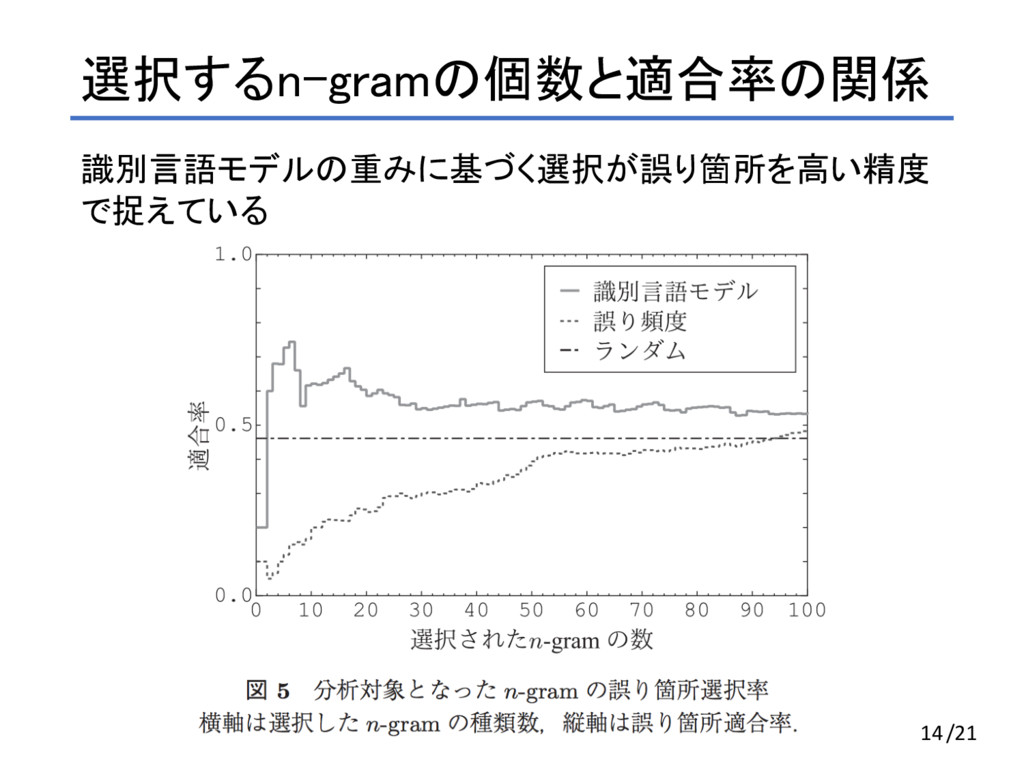
選択するn-gramの個数と適合率の関係 識別言語モデルの重みに基づく選択が誤り箇所を高い精度 で捉えている 14/21
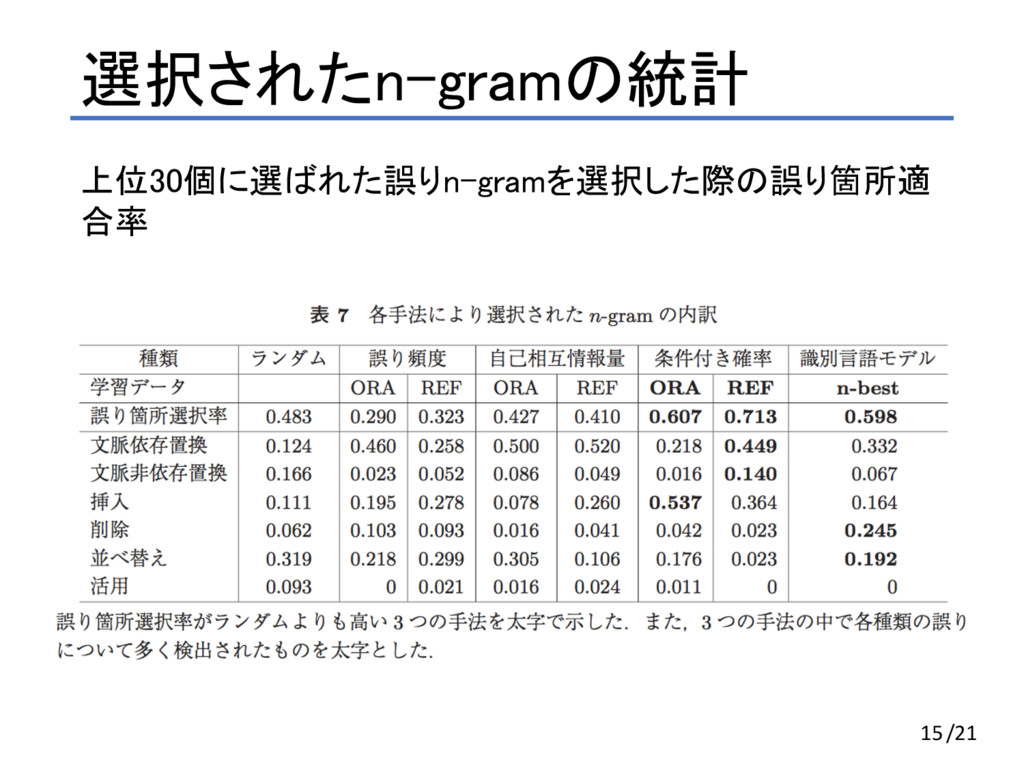
選択されたn-gramの統計 上位30個に選ばれた誤りn-gramを選択した際の誤り箇所適 合率 15/21
システム間比較 分析対象とするシステムによって含まれる誤りの分布が異な る→上位30個の誤りn-gramで分析 16/21
選択箇所に対するフィルタリングの効果 誤り箇所に対し、各フィルタリング法を適用した際の効果に ついて、誤り箇所アノテーションコーパスを用いた自動評価 により検証する 自動評価: 機械翻訳結果を後編集した際の編集パターンを利用した 手法(赤部, Neubig, Sakti, 戸田,
中村 2014b) 評価: 翻訳結果を後編集したコーパスを作成 (KFTTセット, 日英翻訳503文, 英日翻訳200文) 翻訳結果の誤り部分にラベルを付与し、これを誤り箇所 に正解ラベルとする 正解ラベルをどの程度予測できるかを評価 17/21
選択箇所に対するフィルタリングの効果 正解訳の換言を用いたフィルタリングで誤り箇所の選択の精 度が向上 18/21
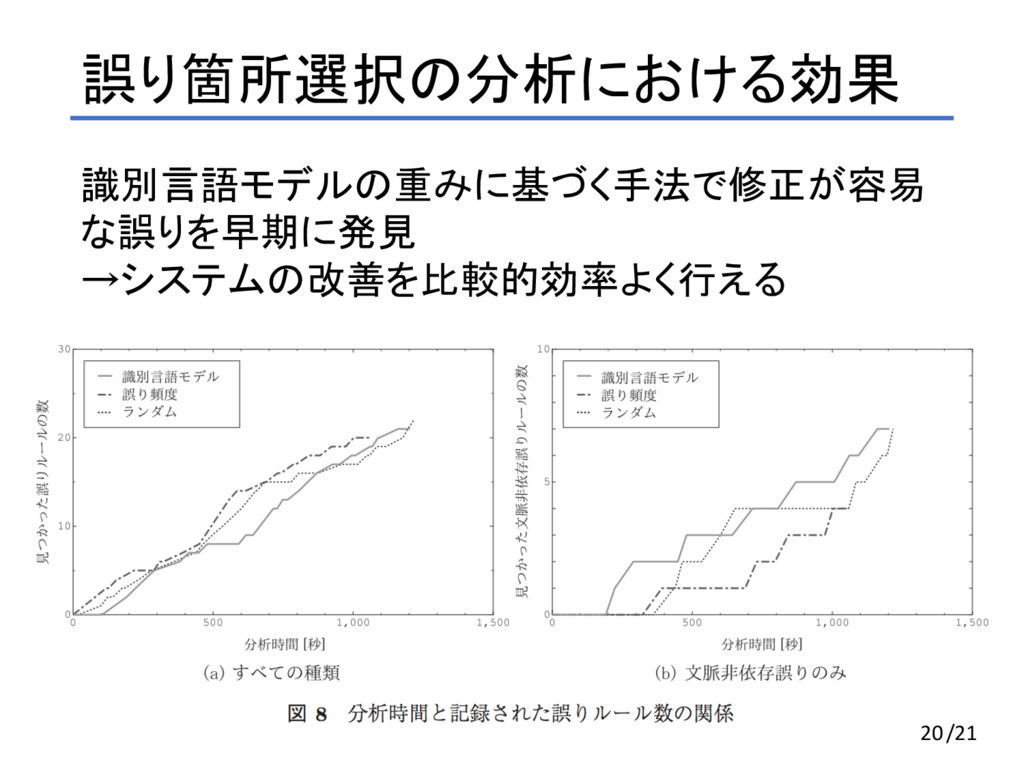
誤り箇所選択の分析における効果 実際の誤り分析を想定し、各誤り箇所選択手法を用いて一 定時間分析を行った 参照訳の換言によるフィルタリングを利用 手順: 1. 各手法によってn-gramにスコアを与える 2. 優先的に分析すべき順に抽出する 3.
翻訳結果の中で各n-gramが含まれている文を列挙 4. フィルタリング処理後、n-gramに一致する箇所を選択 5. 分析者は選択した箇所について誤り分析を行う 6. 「文脈依存誤り」か「文脈非依存誤り」かを記録 19/21
誤り箇所選択の分析における効果 識別言語モデルの重みに基づく手法で修正が容易 な誤りを早期に発見 →システムの改善を比較的効率よく行える 20/21
まとめ u機械翻訳システムの比較・改善のための誤り分析の効率 化のため、機械翻訳の誤り箇所選択法、及び選択箇所の フィルタリング法を提案 u従来法より高い精度で適切な誤り箇所を捉えることに成功 u優先的に選択された少量の誤り箇所を分析するだけで各 システムの誤り傾向を捉えることができ、システム間比較 の効率化に貢献 u容易に修正可能な文脈非依存誤りについて、提案手法に より比較的早い段階から捉えることが可能
21/21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}