Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
強化学習による迷路抜け知識の学習
Search
youichiro
February 01, 2017
Technology
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
強化学習による迷路抜け知識の学習
長岡技術科学大学
自然言語処理研究室
B3ゼミ勉強会(第2回)
youichiro
February 01, 2017
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
100
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
770
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
170
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
3
4k
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.5k
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
2
160
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
780
kintone の AI コワーカーを、 Anthropic にエージェントを"ホストさせて"作った話 #devkinmeetup
sugimomoto
0
110
貴方はどのエンジニアリングを磨くのか
hatyibei
0
130
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2.5k
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
250
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.3k
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
130
Featured
See All Featured
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Unsuck your backbone
ammeep
672
58k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Design in an AI World
tapps
1
260
The SEO Collaboration Effect
kristinabergwall1
1
500
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Transcript
強化学習による迷路抜け知識の学習 平成29年2⽉2⽇ ⻑岡技術科学⼤学 ⾃然⾔語処理研究室 ⼩川耀⼀朗 1
⽬次 1. 強化学習とは 2. Q学習 3. 迷路抜け知識の学習 4. 強化学習プログラムの実装 5.
評価 参考⽂献 機械学習と深層学習 ⼩⾼知宏 オーム社 2
強化学習とは ⼀連の⾏動の最後に評価が与えられるような場合に⽤いる学習⽅法 例)将棋 教師あり学習の場合 • コンピュータが⼀⼿ごとにその⼿の評価を先⽣から教わる⽅法 • 効率的な学習は可能だが、⼤量の教師データを⽤意する必要があり⼤変 • ⼀⼿だけ取り出してその⼿が正しいかどうかは、多くの場合判断するこ
とができない 強化学習の場合 • ⼀連の着⼿が終了した後に評価を得てその評価に基づいて学習を進める • ゲームの勝敗によって評価(勝ち、負け、引き分け) → ใु • 最終の評価から、⼀⼿⼀⼿の⾏動に関する知識を学習する 3
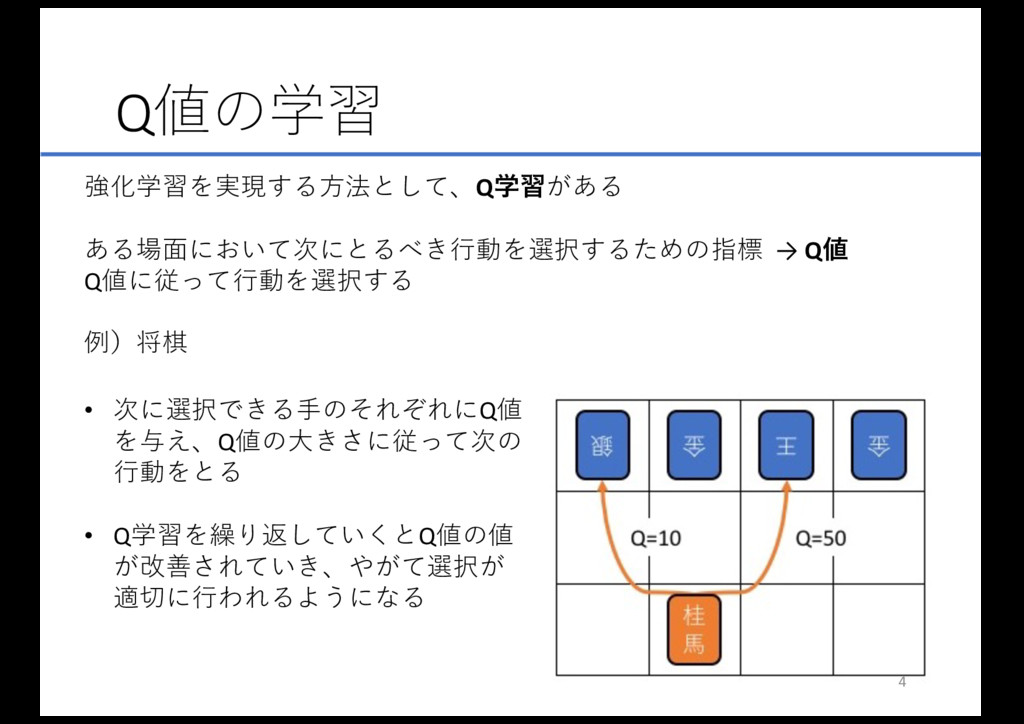
Q値の学習 強化学習を実現する⽅法として、Qֶशがある ある場⾯において次にとるべき⾏動を選択するための指標 → Q Q値に従って⾏動を選択する 例)将棋 • 次に選択できる⼿のそれぞれにQ値 を与え、Q値の⼤きさに従って次の
⾏動をとる • Q学習を繰り返していくとQ値の値 が改善されていき、やがて選択が 適切に⾏われるようになる 4
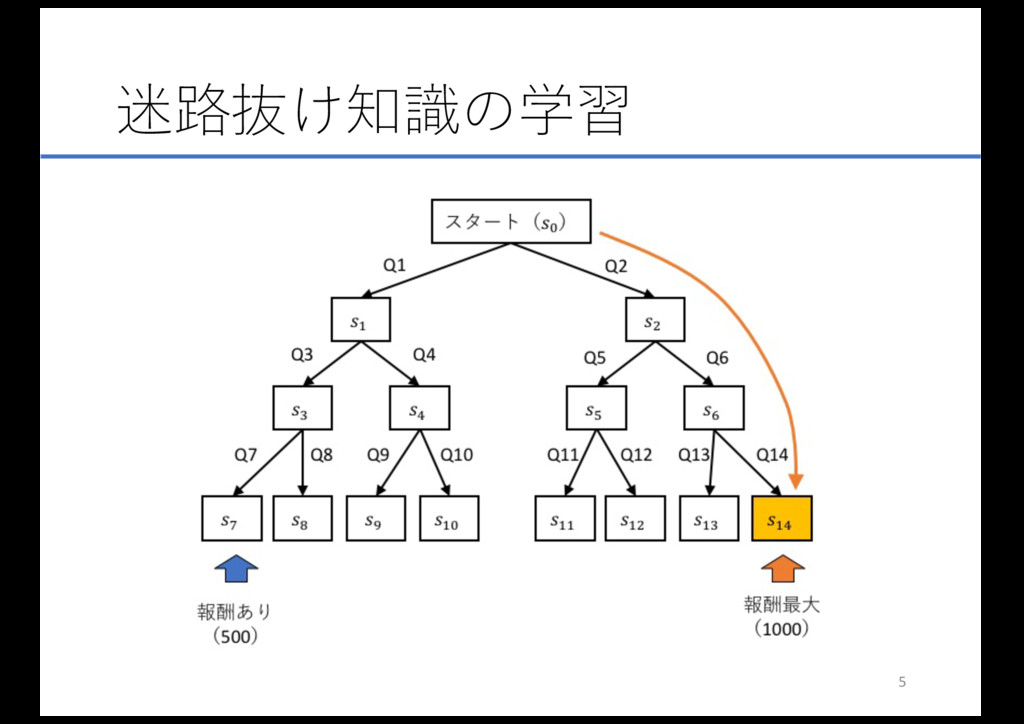
迷路抜け知識の学習 5
迷路抜け知識の学習 ઃఆ • スタート地点から開始 • 分岐を繰り返して最下段までたどり着くと、その場所 に応じた報酬が得られる • なるべく多くの報酬がもらえるような⾏動知識を学習 する
• 今回はs14が最⼤の報酬、s7が最⼤の半分の報酬を与え るとする 6
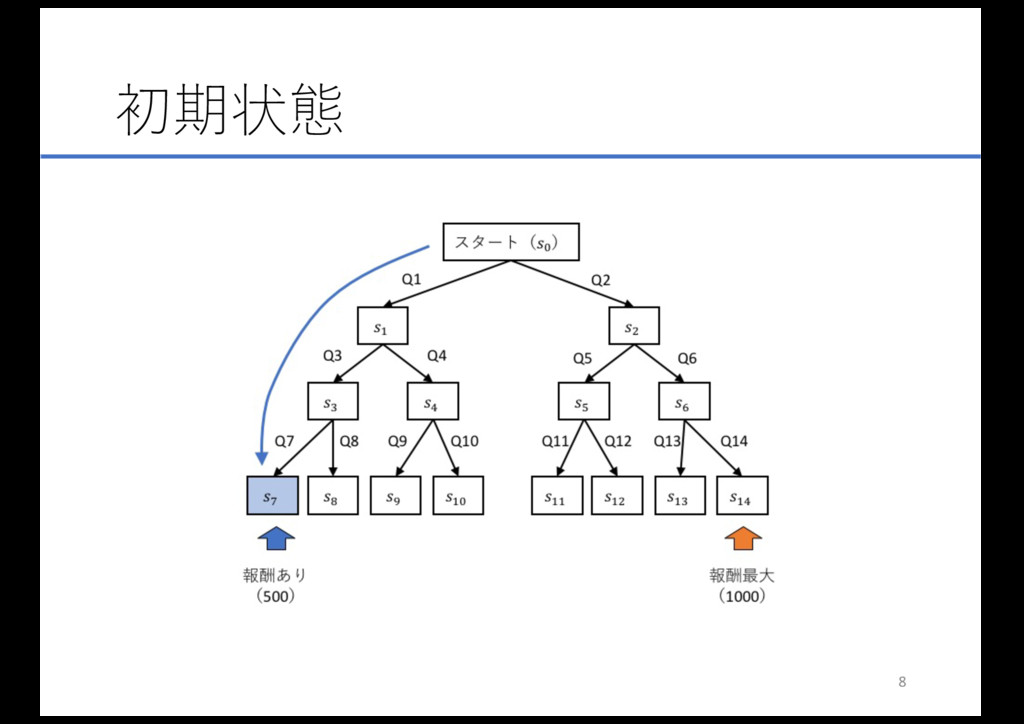
初期状態 • 初期状態学習の初期の⾏動はランダムに選択される • 初期状態でたまたま⽬標とする⾏動パターンに近いものが 現れることがある → この時に得た報酬によって、その⾏動パターンのQ値が増 加 →
次回からその⾏動パターンが選択されやすくなる これでは… 報酬に直結する⾏動のQ値が改善されるだけで、初期の⾏ 動に対するQ値はランダムに決定された値のまま更新されな い 7
初期状態 8
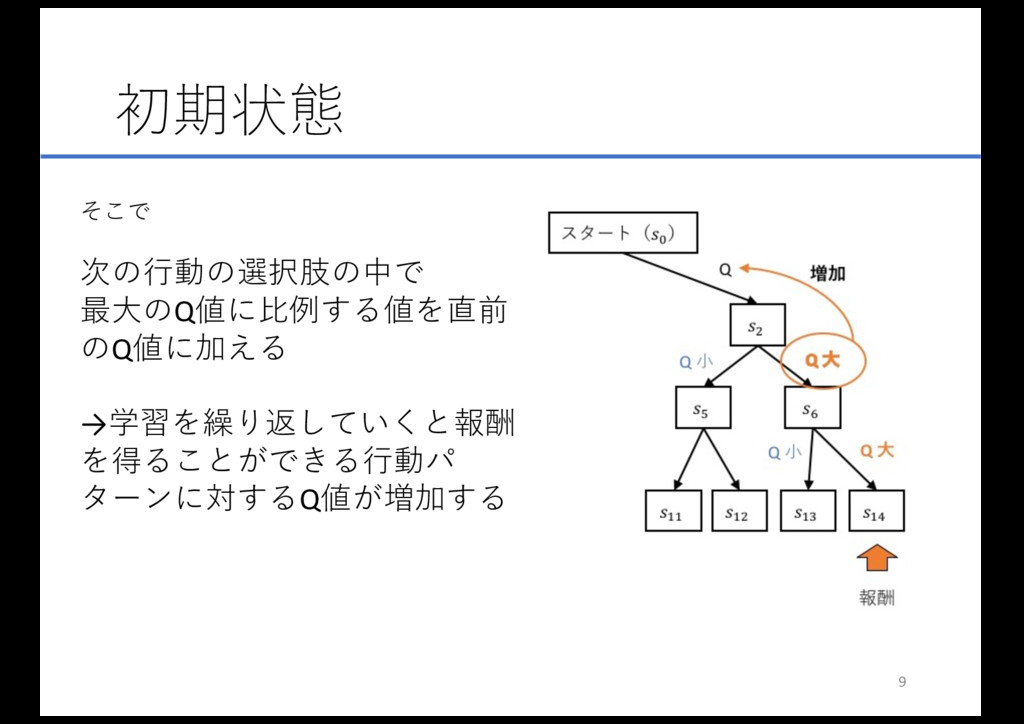
そこで 次の⾏動の選択肢の中で 最⼤のQ値に⽐例する値を直前 のQ値に加える →学習を繰り返していくと報酬 を得ることができる⾏動パ ターンに対するQ値が増加する 初期状態 9
Q値の計算 "#,%# = "#,%# + + 012 , 012 −
0 , 0 0 : 時刻tにおける状態 0 : 0 において選択した⾏動を表す r : 報酬(得られなければ0) α : 学習係数(0.1程度) γ : 割引率(0.9程度) 012 , 012 : 次の時刻における⾏動の選択肢中のQ値の最⼤値 10
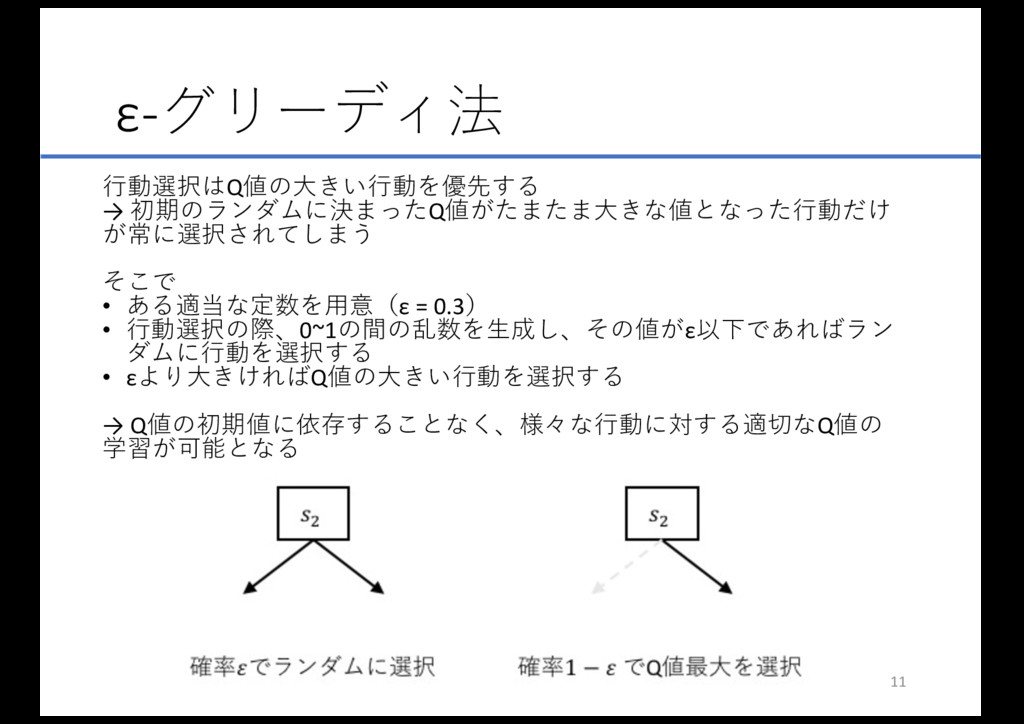
ε-グリーディ法 ⾏動選択はQ値の⼤きい⾏動を優先する → 初期のランダムに決まったQ値がたまたま⼤きな値となった⾏動だけ が常に選択されてしまう そこで • ある適当な定数を⽤意(ε = 0.3)
• ⾏動選択の際、0~1の間の乱数を⽣成し、その値がε以下であればラン ダムに⾏動を選択する • εより⼤きければQ値の⼤きい⾏動を選択する → Q値の初期値に依存することなく、様々な⾏動に対する適切なQ値の 学習が可能となる 11
Q学習の⼿順 1. 全てのQ値をランダムに決定 2. 学習が⼗分進むまで以下を繰り返す a. 動作の初期状態に戻る b. 選択可能な⾏動から、Q値に基づいて次の⾏動を決定する c.
Q値を更新 d. 報酬を得たら、報酬に⽐例した値をQ値に加える e. 次の状態で選択できる⾏動に対するQ値のうち、最⼤値に ⽐例した値をQ値に加える f. ⽬標状態に⾄ったら2に戻る g. 2に戻る 12
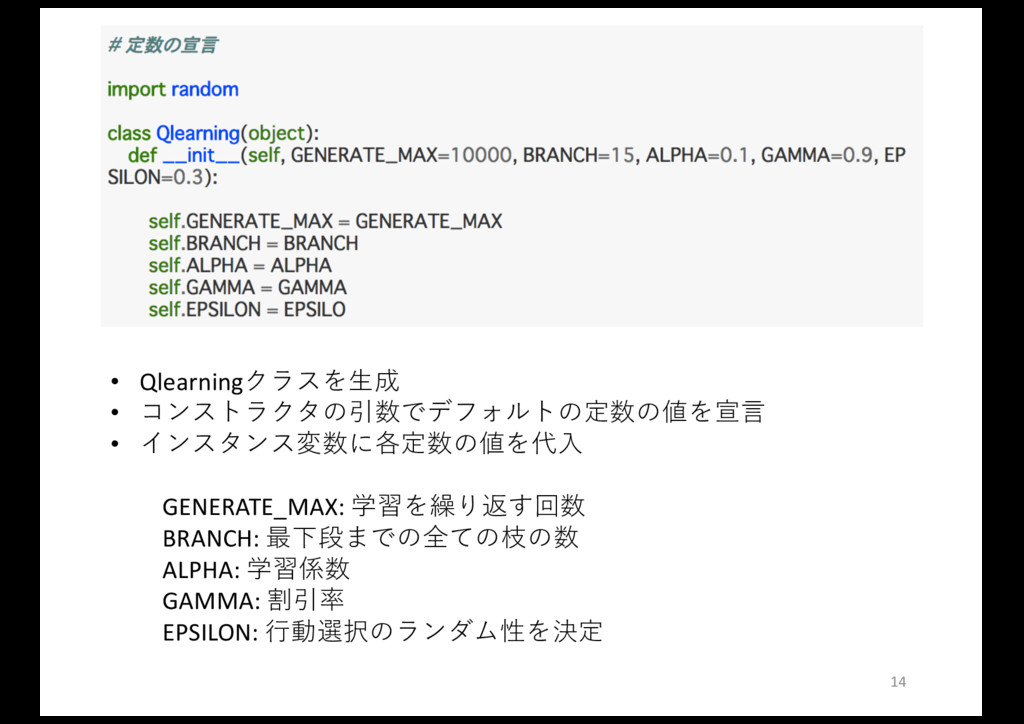
ڧԽֶशʹΑΔ໎࿏ൈ͚ࣝͷֶशϓϩάϥϜ ߏ Q学習を⾏うクラスを作成 • コンストラクタ: 定数を宣⾔ • learnメソッド: 学習のメイン処理を⾏う •
updateメソッド: Q値を更新する • selectメソッド: 次の⾏動を決定する 13
• Qlearningクラスを⽣成 • コンストラクタの引数でデフォルトの定数の値を宣⾔ • インスタンス変数に各定数の値を代⼊ GENERATE_MAX: 学習を繰り返す回数 BRANCH: 最下段までの全ての枝の数
ALPHA: 学習係数 GAMMA: 割引率 EPSILON: ⾏動選択のランダム性を決定 14
• 全枝のQ値を0~100のランダムな値に設定 • 以下を学習の繰り返し回数まで繰り返す • 以下を最下段まで繰り返す • 次の⾏動の選択 • Q値の更新
• 更新したQ値を出⼒ q: それぞれの枝のQ値(リスト) s: 次の⾏動を⽰す(int) 15
• 今が最下段にいる場合 • 今がs14かs7にいるなら => 報酬を与える • s14以外にいるなら => 報酬なし
• 最下段にいない場合 • 次の⾏動の中でQ値が⼤きい⽅をqmaxに代⼊ • gmaxに⽐例した値を加算 • 更新したQ値を返す 16
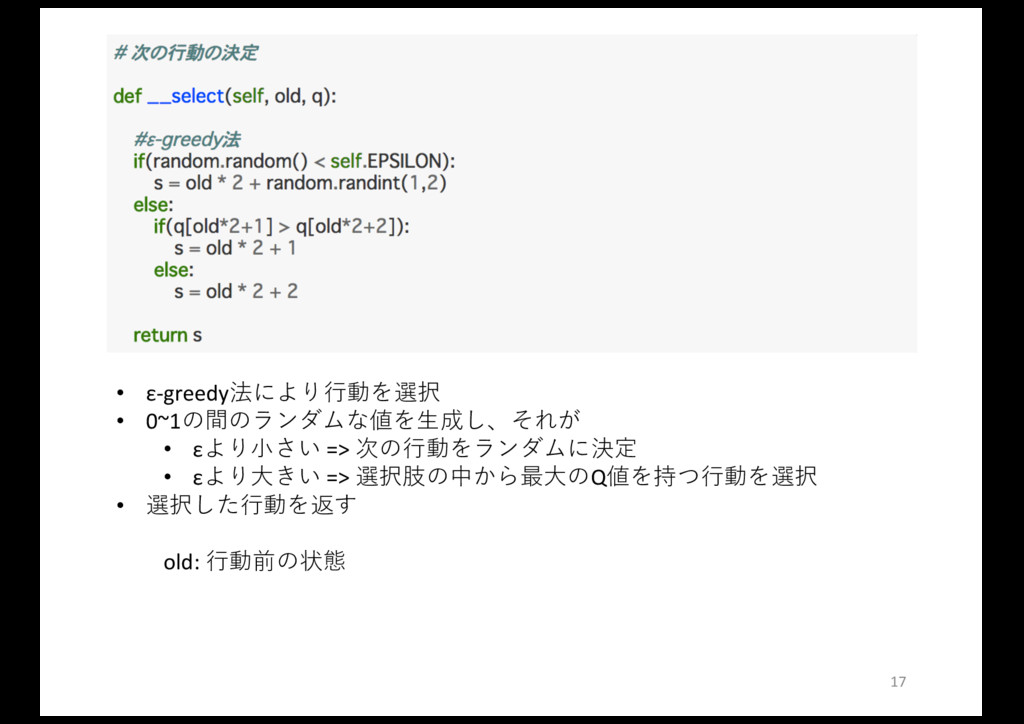
• ε-greedy法により⾏動を選択 • 0~1の間のランダムな値を⽣成し、それが • εより⼩さい => 次の⾏動をランダムに決定 • εより⼤きい
=> 選択肢の中から最⼤のQ値を持つ⾏動を選択 • 選択した⾏動を返す old: ⾏動前の状態 17
最後に実⾏ 18
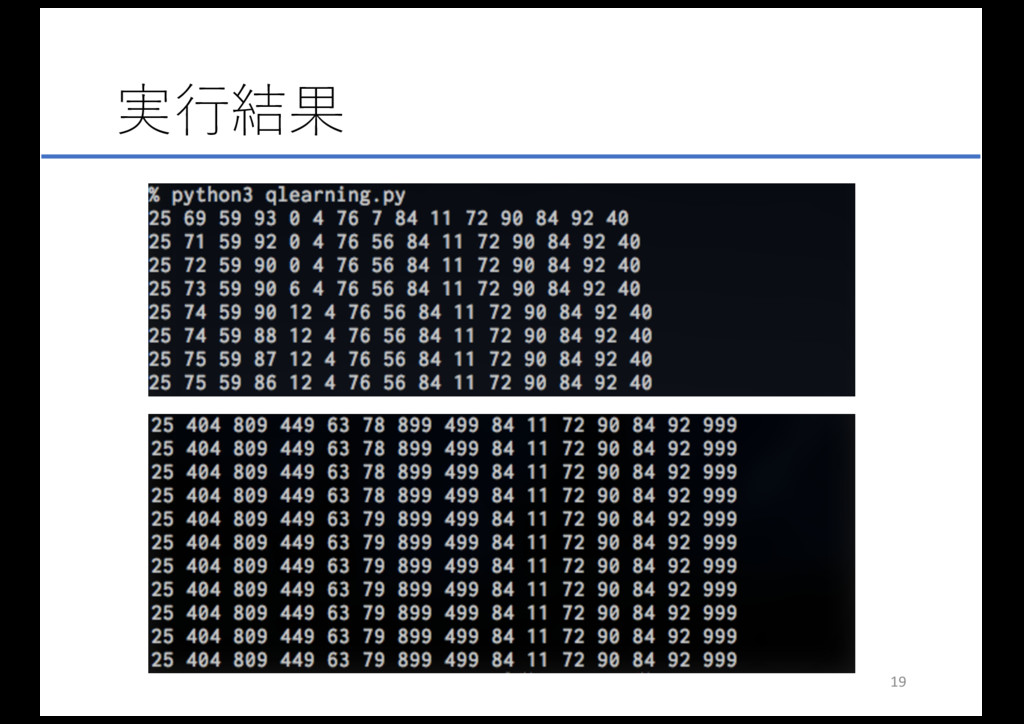
実⾏結果 19
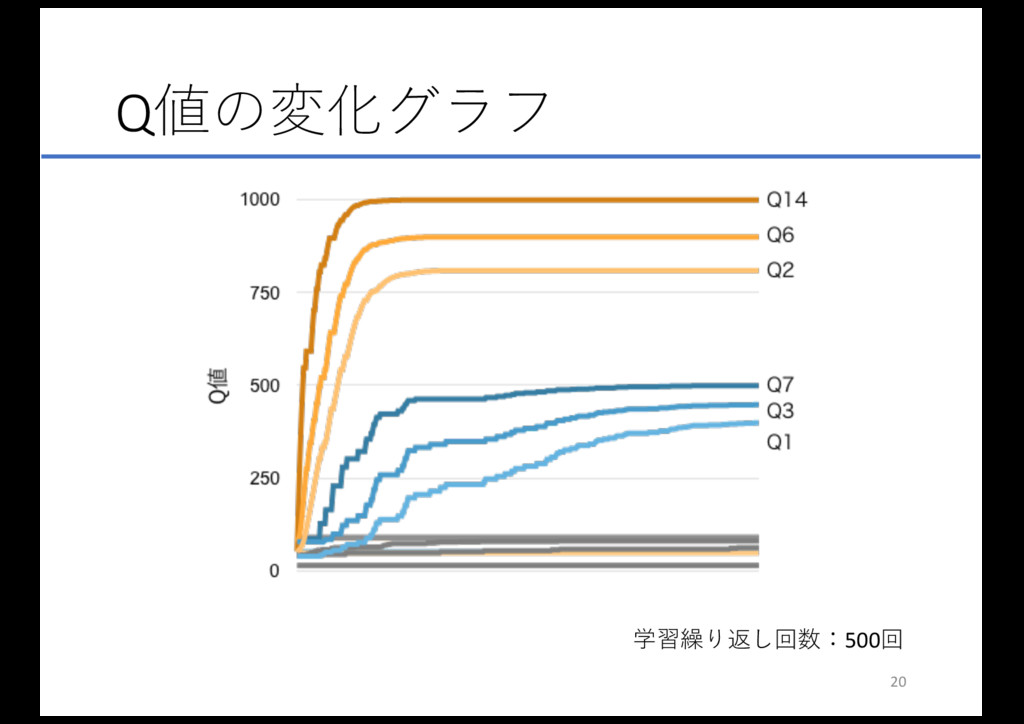
Q値の変化グラフ 学習繰り返し回数:500回 20
迷路抜け知識の学習 24 に⾄るまでの枝であるQ14、Q6、Q2では、得られる 報酬が1000のため、1000に近いQ値まで増加している 5 に到るまでの枝であるQ7、Q3、Q1では、得られる報 酬が24 の半分なのでQ値もおよそ半分のところまで増加 している 従って
… 構想した迷路において多くの報酬がもらえるような⾏ 動知識を学習することができた 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}