al.小説会話文への話者情報付与, 2022, 国⽴国語研究所「日常会話コーパス」プロジェクト報告書 5 [ⅰ] Du et al.小説からの自由対話コーパスの自動構築, 2019, 言語処理学会第25会年次大会 [ⅱ] Miyazaki et al.発話テキストへのキャラクタ性付与のための音変化表現の分類, 2019, 自然言語処理 [ⅲ] Ishikawa et al.口調ベクトルを用いた小説発話の話者推定, 2022, 自然言語処理研究発表会 [ⅳ] Zenimoto et al. Speaker Identification of Quotes in Japanese Novels based on Gender Classification Model by BERT, 2022, PACLIC
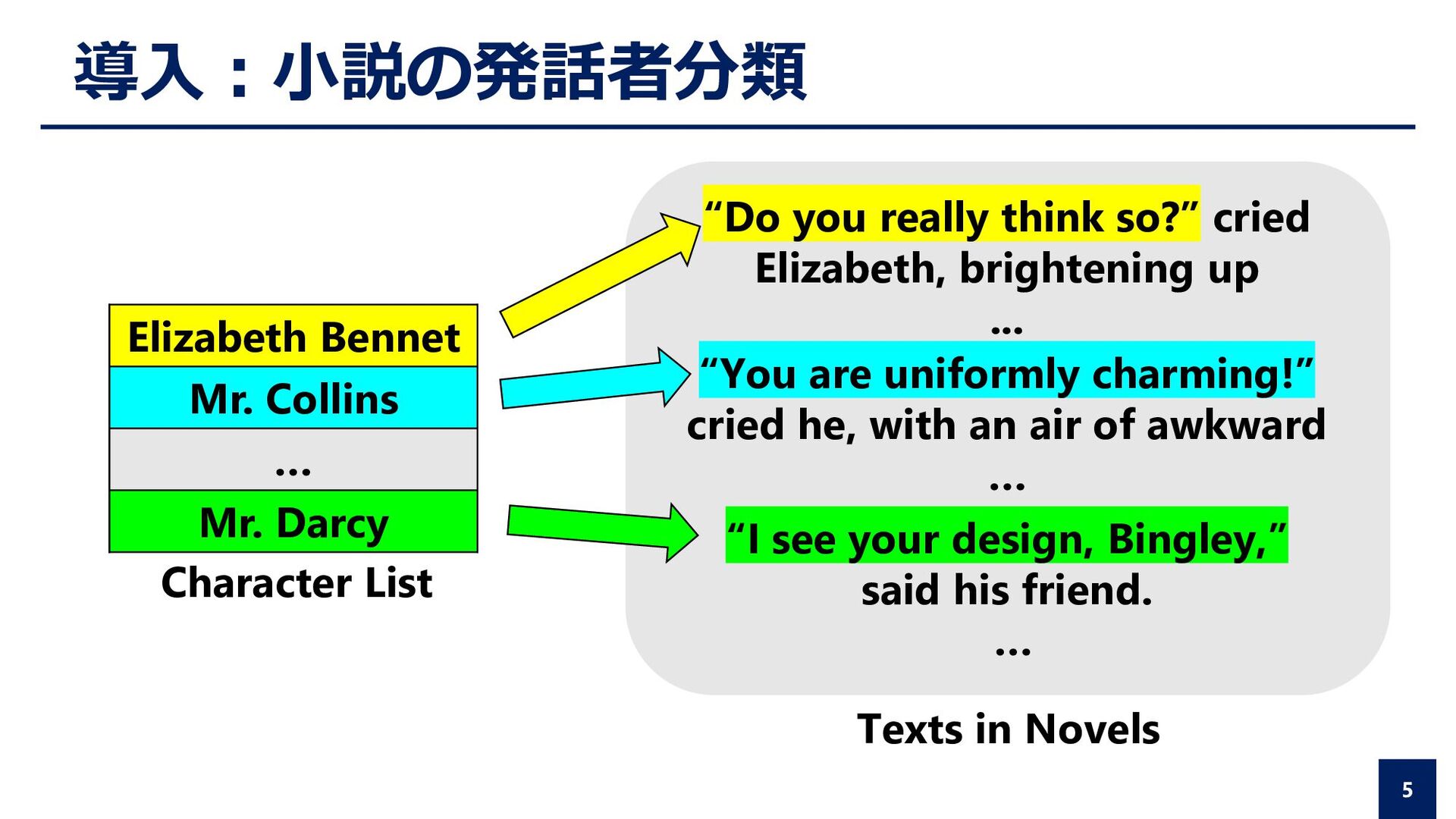
you really think so?” cried Elizabeth, brightening up ... “You are uniformly charming!” cried he, with an air of awkward … “I see your design, Bingley,” said his friend. … Texts in Novels Character List
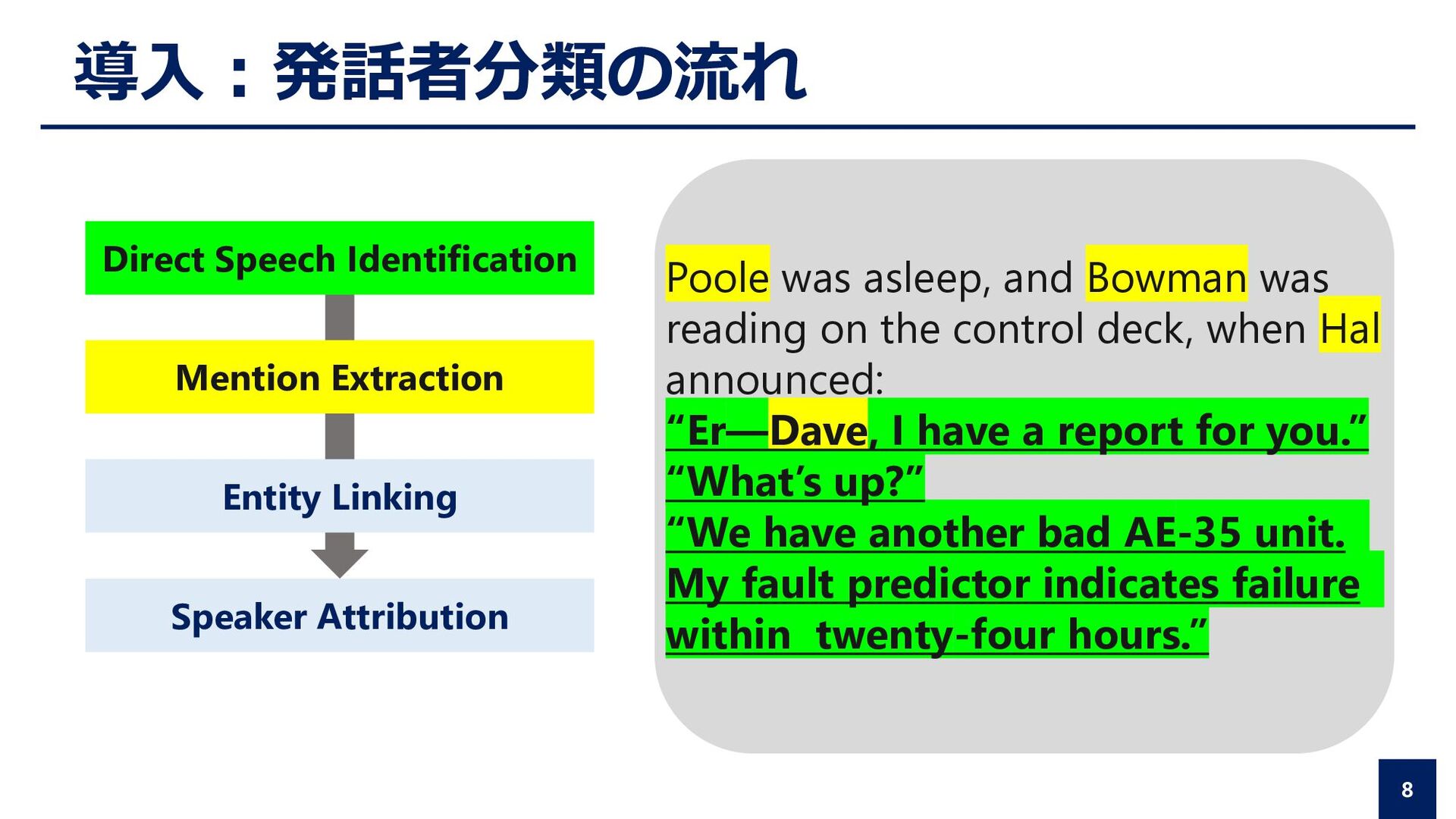
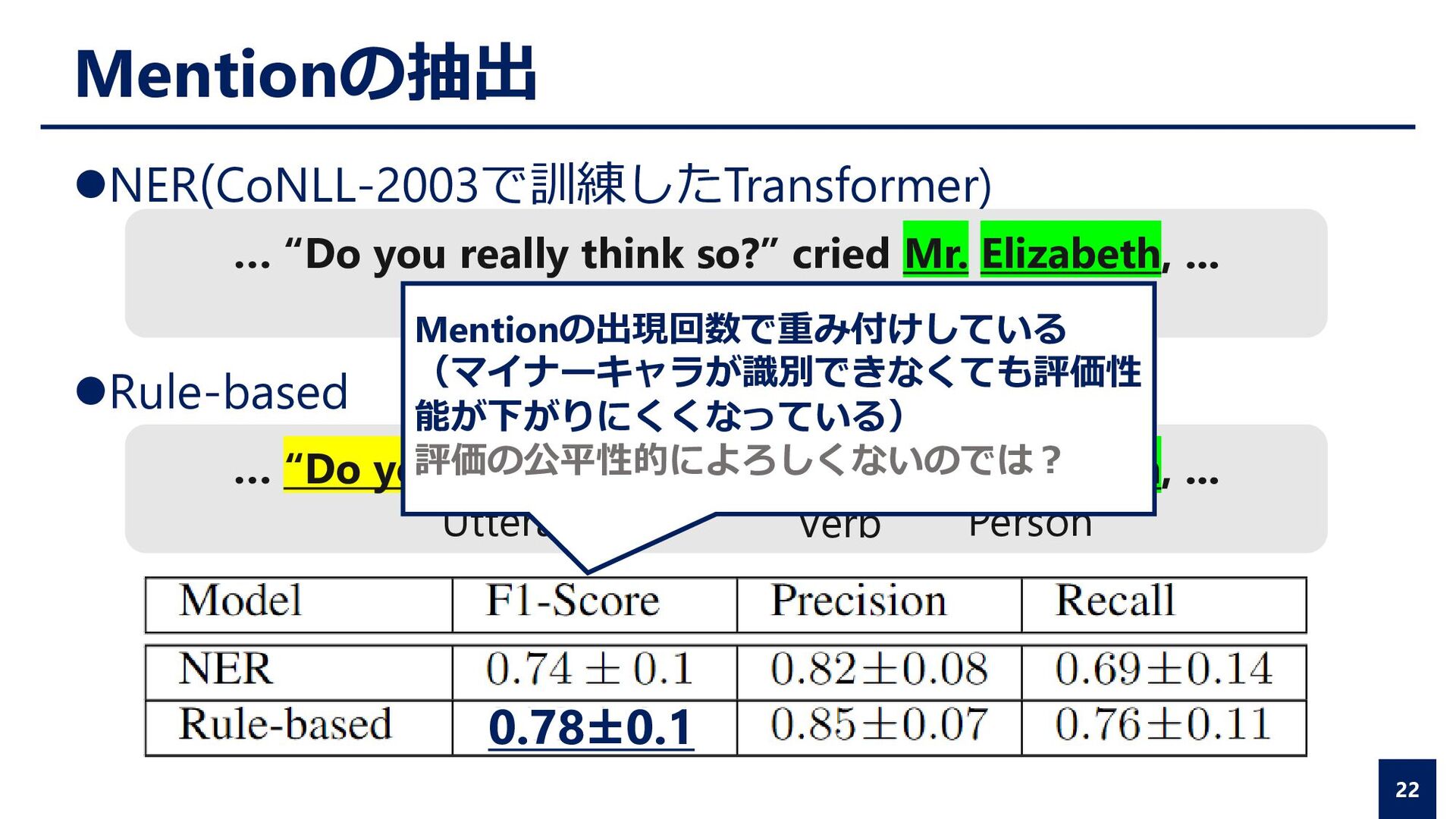
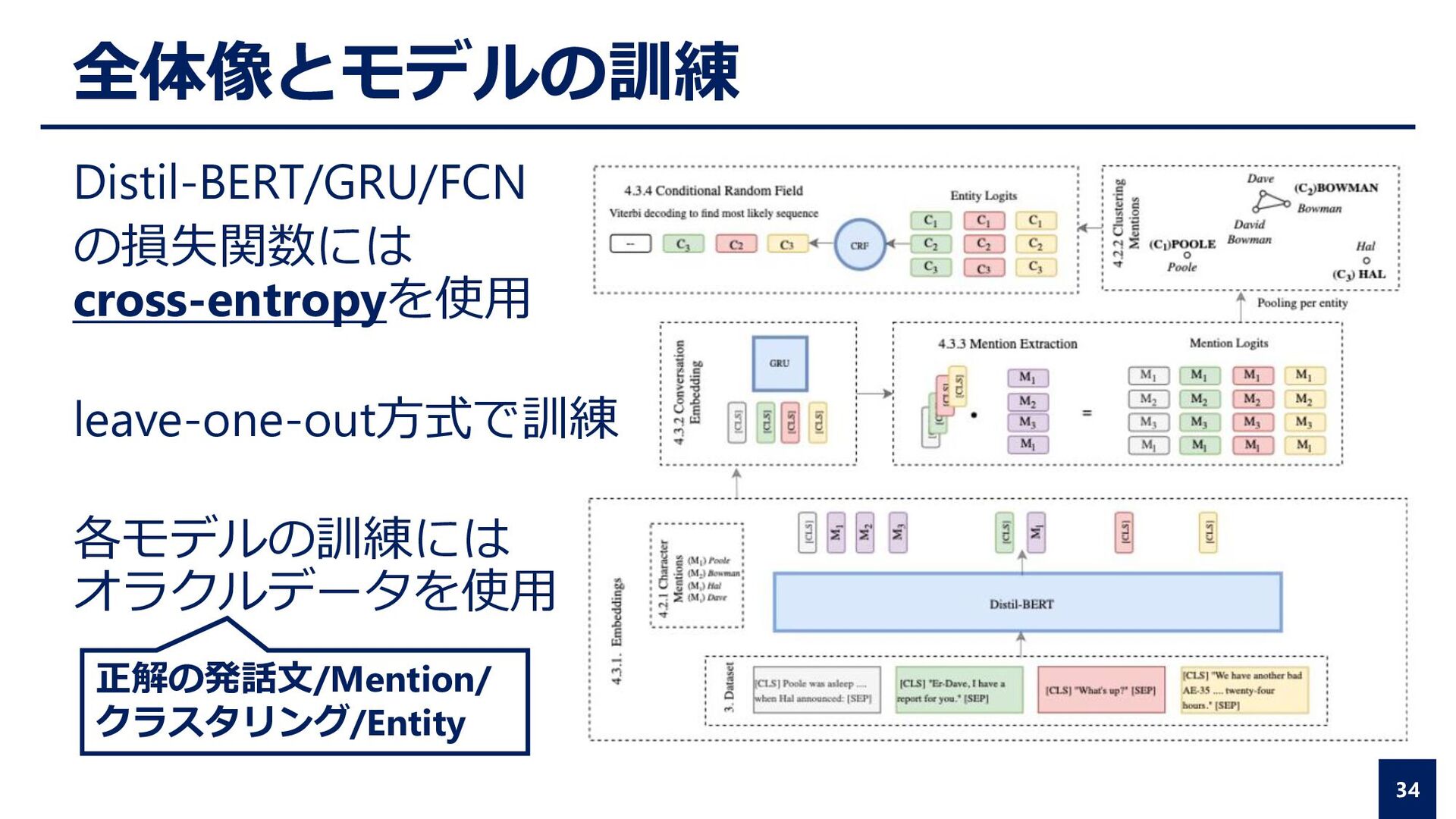
Attribution Poole was asleep, and Bowman was reading on the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.”
was reading on the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” Mention Extraction Entity Linking Speaker Attribution
the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” Direct Speech Identification Mention Extraction Entity Linking Speaker Attribution
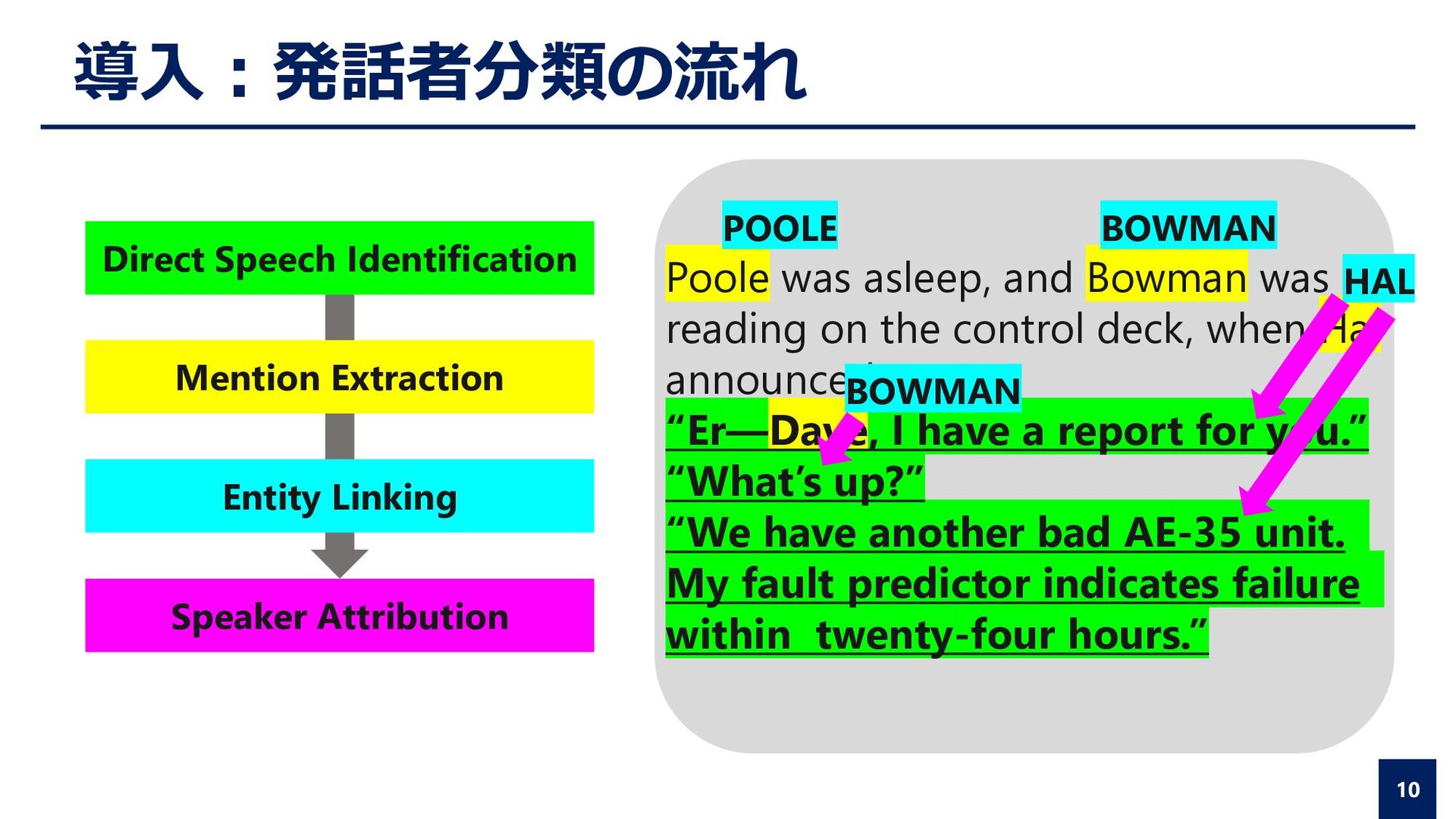
the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” BOWMAN POOLE BOWMAN HAL Direct Speech Identification Entity Linking Speaker Attribution Mention Extraction
the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” BOWMAN POOLE BOWMAN HAL Direct Speech Identification Speaker Attribution Entity Linking Mention Extraction
think so?” cried Elizabeth, ... Utterance by Elizabeth Verb Speaker “My dear Mr. Bennet,…” “Is that his … ” Vocative “Aye, so it …” … “Then, my …” … “Is that a …” by speaker A by speaker B by speaker A by Mr. Bennet ⚫Vocative Detection ⚫Conversational Pattern [1] Muzny et al. A Two-stage Sieve Approach for Quote Attribution, 2017, EACL [2] He et al. Identification of Speakers in Novels, 2013, ACL
et al. Understanding Quotation. Mouton Series in Pragmatics [MSP] , 2012 [6] Lee et al. Keeping Their Words: Direct and Indirect Chinese Quote Attribution from Newspapers, 2020, In Companion of the WWW ⚫日本語:カギ括弧を利用するだけでは不十分[3] ➢「」『』⇛直接発話or強調表現 ➢()⇛心の声or補足説明 ➢ 鉤括弧なしの発話文 [3] Yamazaki et al.小説会話文への話者情報付与, 2022, 国⽴国語研究所「日常会話コーパス」プロジェクト報告書 5 ⚫中国語:新聞の発話文検出での精度は50~60%程度[6]
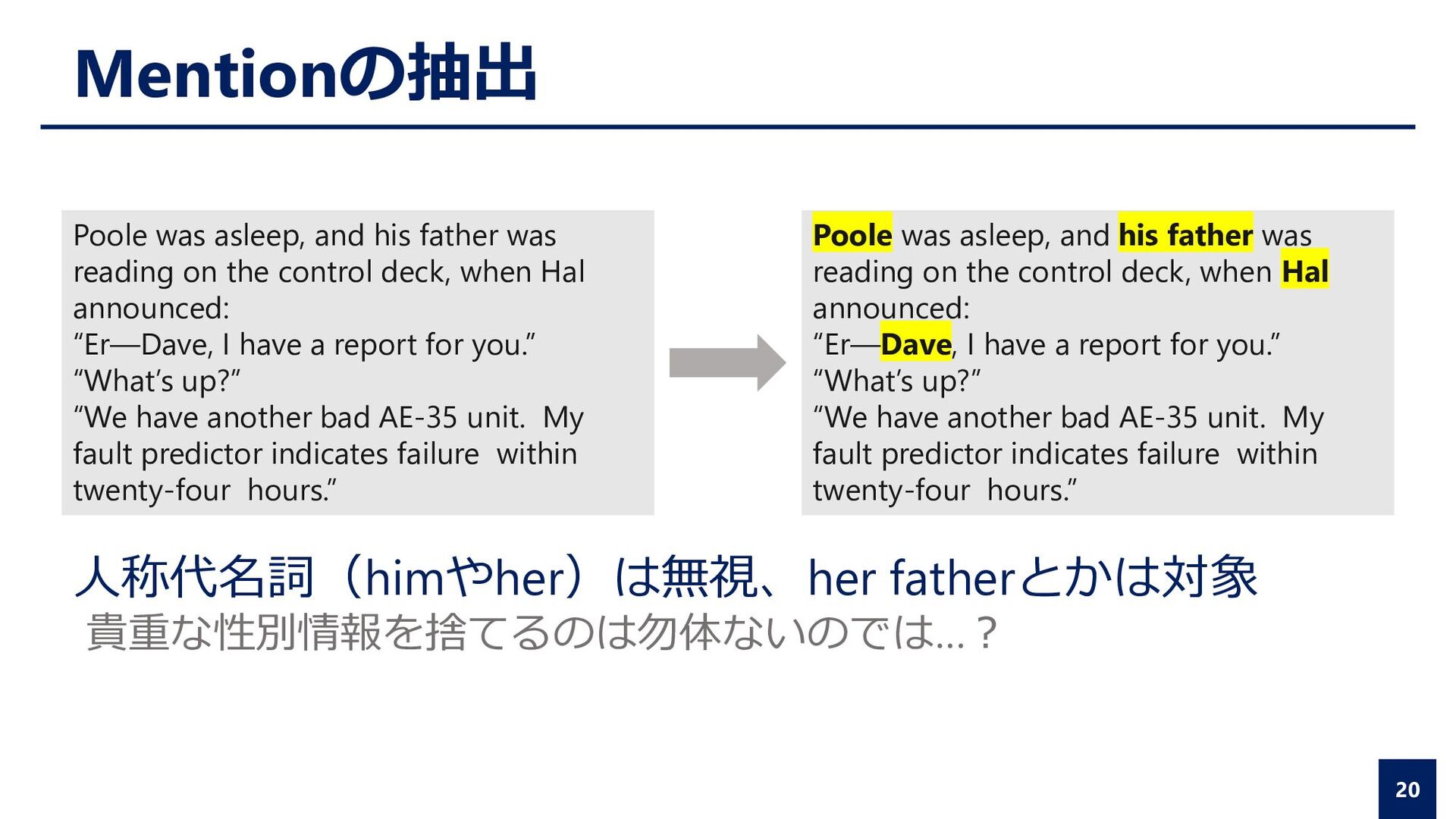
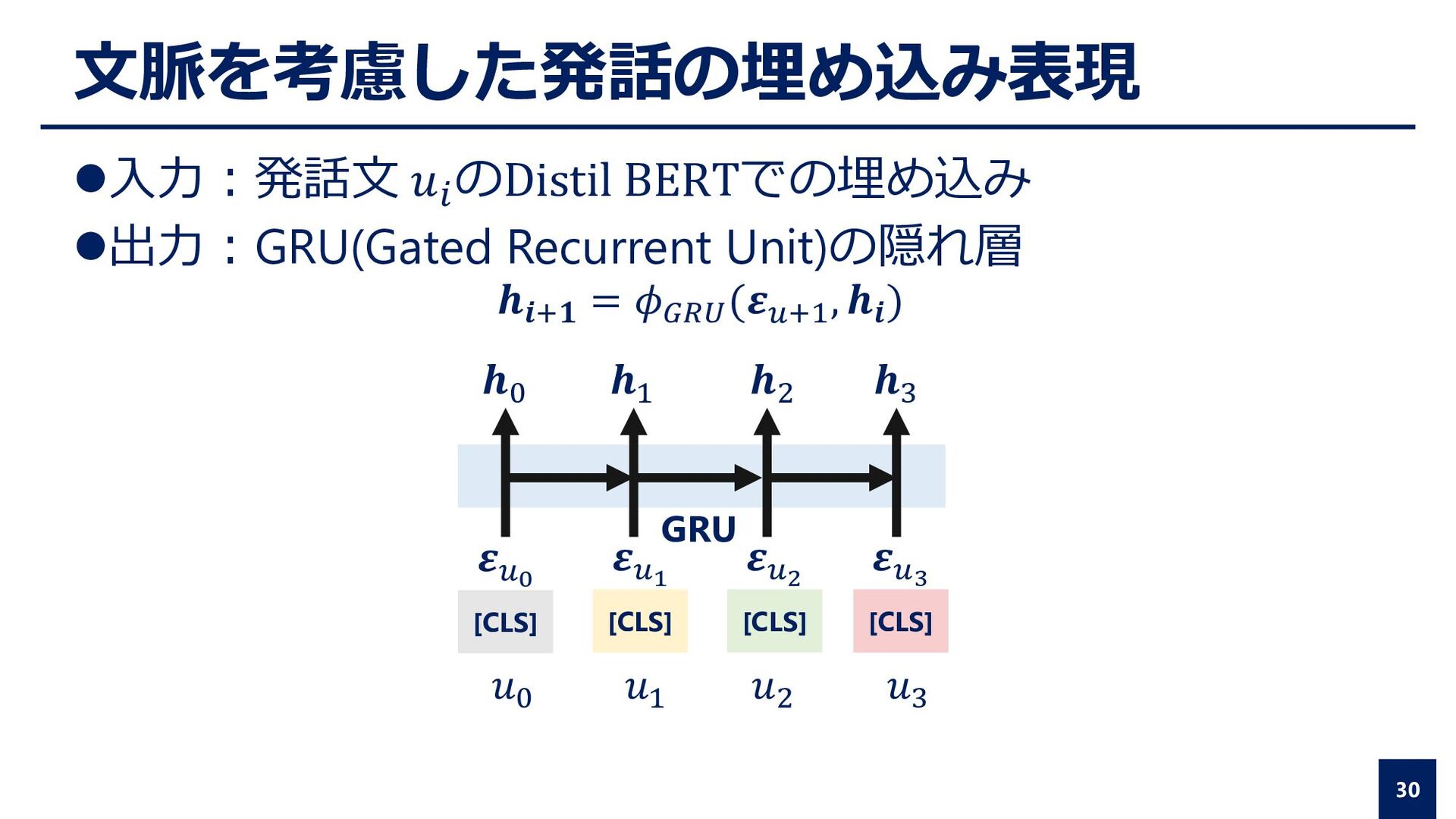
on the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” Poole was asleep, and his father was reading on the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” 人称代名詞(himやher)は無視、her fatherとかは対象 貴重な性別情報を捨てるのは勿体ないのでは…?
asleep, and his father was reading on the control deck, when Hal announced: “Er—Dave, I have a report for you.” “What’s up?” “We have another bad AE-35 unit. My fault predictor indicates failure within twenty-four hours.” Poole his father Hal Dave Poole his father Hal Dave BOWMAN HAL POOLE [7] Amigó et al. A comparison of extrinsic clustering evaluation metrics based on formal constraints, 2009, Information Retrieval
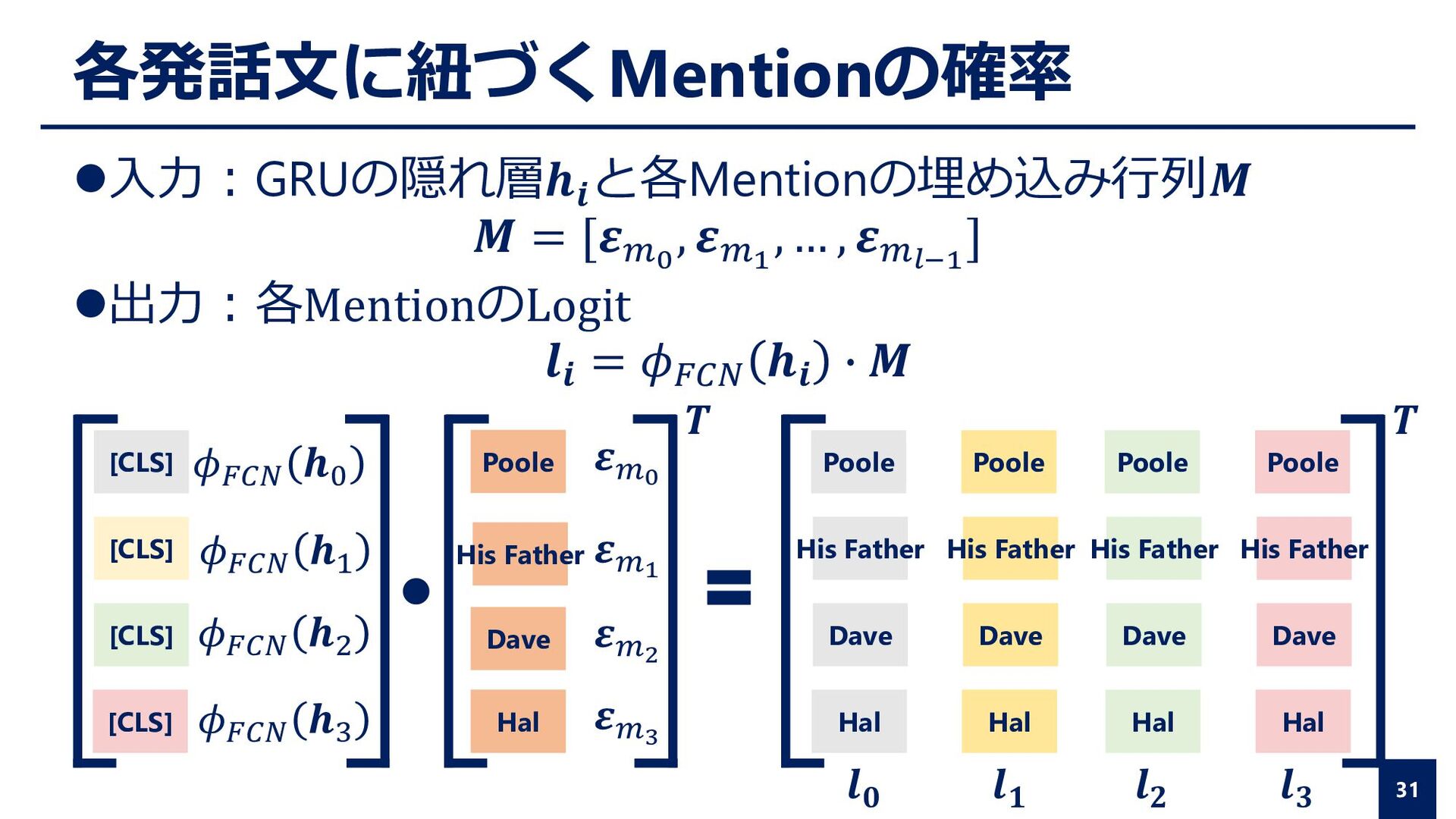
, 𝜺𝑚𝑙−1 ] ⚫出力:各MentionのLogit 𝒍𝒊 = 𝜙𝐹𝐶𝑁 𝒉𝒊 ∙ 𝑴 [CLS] [CLS] [CLS] [CLS] 𝜙𝐹𝐶𝑁 𝒉0 𝜙𝐹𝐶𝑁 𝒉1 𝜙𝐹𝐶𝑁 𝒉2 𝜙𝐹𝐶𝑁 𝒉3 𝜺𝑚0 Poole 𝜺𝑚1 His Father 𝜺𝑚2 Dave 𝜺𝑚3 Hal Poole His Father Dave Hal Poole His Father Dave Hal Poole His Father Dave Hal Poole His Father Dave Hal 𝑻 𝑻 𝒍𝟎 𝒍𝟏 𝒍𝟐 𝒍𝟑 31
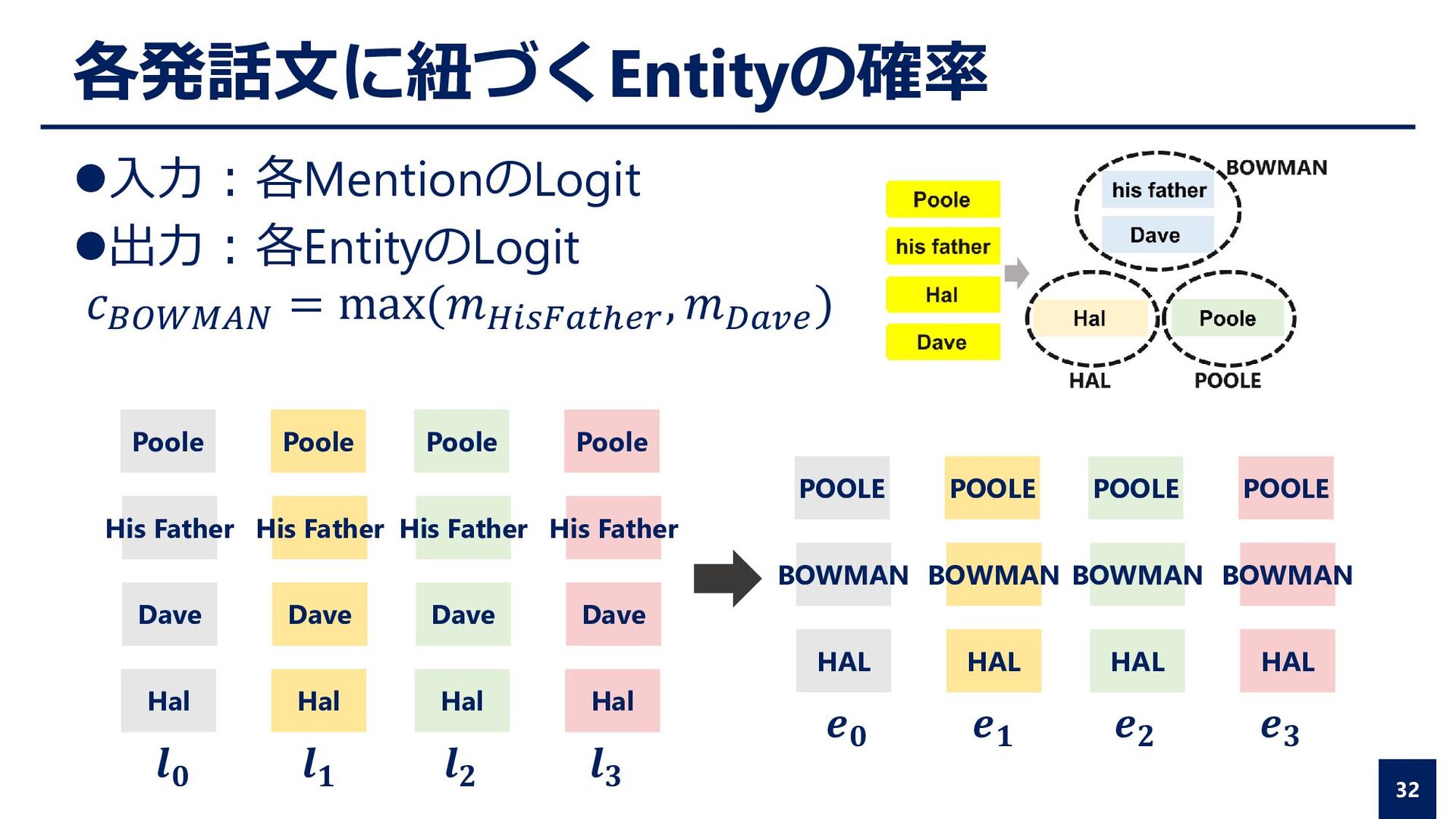
Dave Hal Poole His Father Dave Hal Poole His Father Dave Hal 𝒍𝟎 𝒍𝟏 𝒍𝟐 𝒍𝟑 POOLE BOWMAN HAL POOLE BOWMAN HAL POOLE BOWMAN HAL POOLE BOWMAN HAL 𝒆𝟎 𝒆𝟏 𝒆𝟐 𝒆𝟑 ⚫入力:各MentionのLogit ⚫出力:各EntityのLogit 𝑐𝐵𝑂𝑊𝑀𝐴𝑁 = max(𝑚𝐻𝑖𝑠𝐹𝑎𝑡ℎ𝑒𝑟 , 𝑚𝐷𝑎𝑣𝑒 )
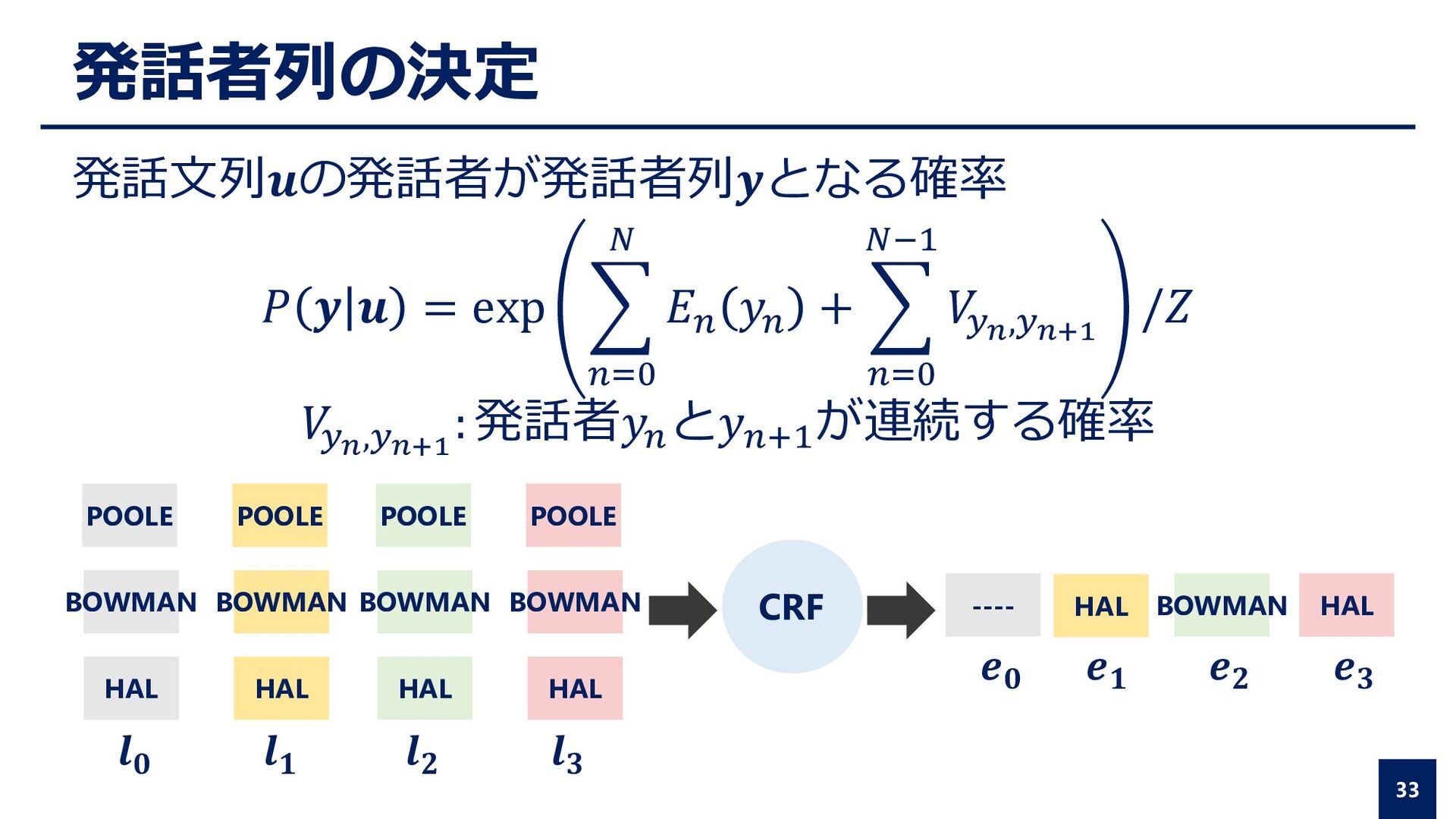
𝑦𝑛 + 𝑛=0 𝑁−1 𝑉 𝑦𝑛,𝑦𝑛+1 /𝑍 𝑉 𝑦𝑛,𝑦𝑛+1 : 発話者𝑦𝑛 と𝑦𝑛+1 が連続する確率 33 POOLE BOWMAN HAL POOLE BOWMAN HAL HAL POOLE BOWMAN HAL POOLE BOWMAN HAL 𝒍𝟎 𝒍𝟏 𝒍𝟐 𝒍𝟑 CRF HAL BOWMAN ---- 𝒆𝟎 𝒆𝟏 𝒆𝟐 𝒆𝟑 発話文列𝒖の発話者が発話者列𝒚となる確率
{kind=link}
![本発表の姿勢 ⚫小説発話者分類研究の布教をしたい ⚫日本語での研究が少ない[ⅰ][ⅱ][ⅲ][ⅳ] ⚫素晴らしい日本語データセットが爆誕[3]したので 日本語小説発話者分類研究がもっと増えてほしい ⚫発話者分類の包括的な話をします 2 [3] Yamazaki et](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_1.jpg){kind=link}
![どんな論文? 問題設定:異なる年代/文体に対応可能なEnd-to-End発話者分類 やったこと: ⚫ 発話者分類に深層学習を初めて導入 - Before:ルールベースがSoTA[1] ⚫ 1パラグラフ全体の埋め込みを分類に使用 -](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存手法-1発話毎に処理[1][2] 11 ⚫Rule Based Speaker Matching … “Do you really](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
![その他のデータセット ⚫日本語:BCCWJ 2,932小説665,828発話文(Entity付与)[3] ⚫英語[4]: ⇛ ⚫中国語[4]:⇛ データセット ⚫1900~2010年の18小説 ➢うち3つは既存の公開データセット[1] ➢それ以外の小説情報は未公開](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
![発話文の検出 ダブルクォーテーション””で括られた発話のみを対象 ➢ 95%の発話文は””で括られている[5] ➢ 単なる強調表現も多いのでは? ⇛F1:0.98±0.01の精度で適切に検出できた 17 [5] Steinbach](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_16.jpg){kind=link}
{kind=link}
![発話者候補の検出 i. Mention(発話文周囲の人称名詞)の抽出 ➢NER(CoNLL-2003で訓練したTransformer) ➢Rule-based[1] ii. Mentionのクラスタリング⇛Entity(一意の名前)の特定 ➢共参照解析(Out-of-domain Transformer) ➢Rule-based](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![クラスタリング結果は𝐵3 precision, recall, F1-scoreで評価[7] Mentionのクラスタリング⇛Entityの特定 入力:全パラグラフ&Mention 出力:各パラグラフに登場するEntity 23 Poole was](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![発話文とMentionの埋め込み表現 28 Poole [CLS] was … his father [SEP] [CLS]](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_27.jpg){kind=link}
![発話文とMentionの埋め込み表現 29 Poole [CLS] was … his father [SEP] [CLS]](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![End-to-End評価(オラクルなし) Baseline : Rule-based[1] 37 ⚫既存のSoTAと比較して平均50%以上の性能改善 ⚫異なる文体・年代の小説に対しても同様の性能 ➢小説の情報がないので確認のしようがない [1] Muzny](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
![本研究の概要(再) 問題設定:異なる年代/文体に対応可能なEnd-to-End発話者分類 やったこと: ⚫ 発話者分類に深層学習を初めて導入 - Before:ルールベースがSoTA[1] ⚫ 1パラグラフ全体の埋め込みを分類に使用 -](https://files.speakerdeck.com/presentations/84334ac07acb45df8be0b17cca2dfacc/slide_39.jpg){kind=link}