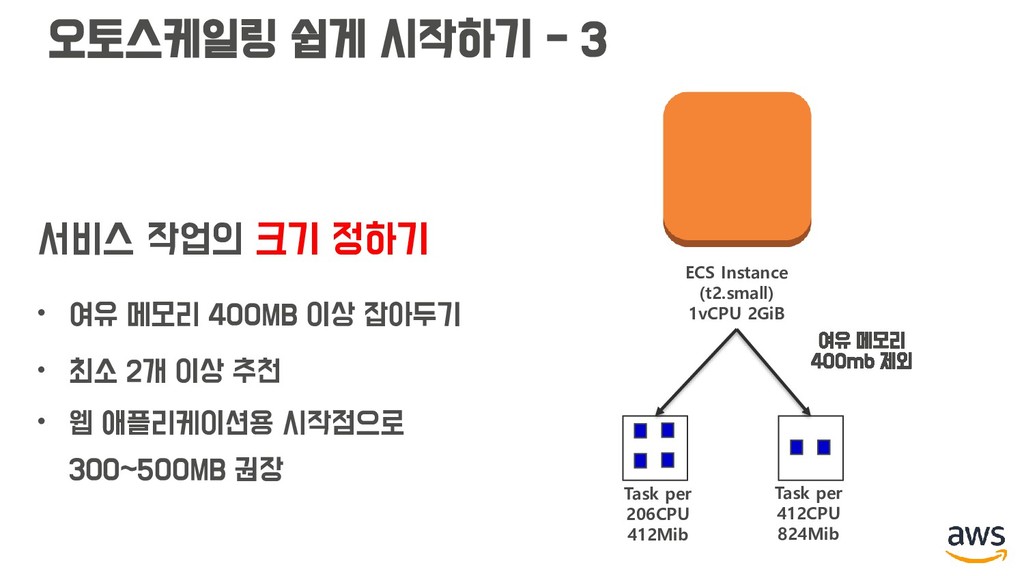
여유 메모리 400MB 이상 잡아두기 • 최소 2개 이상 추천 • 웹 애플리케이션용 시작점으로 300~500MB 권장 ECS Instance (t2.small) 1vCPU 2GiB Task per 206CPU 412Mib Task per 412CPU 824Mib 여유 메모리 400mb 제외
Utilization = 클러스터의 모든 작업이 사용중인 유닛 클러스터 인스턴스 전체의 유닛 합 ∗ 100 • Ex) t2.medium 클러스터 인스턴스 1개에 300 CPU 유닛을 사용하고 있는 작업 2개 • 300 ∗ 2 2048 ∗ 1 ∗ 100 = 29% • 클러스터 Mem Utilization = 클러스터의 모든 작업이 사용중인 메모리 클러스터 인스턴스 전체의 메모리의 합 ∗ 100 • Ex) t2.medium 클러스터 인스턴스 1개에 420MB 메모리를 사용하고 있는 작업 2개 • 420 ∗2 4096 ∗1 ∗ 100 = 20%
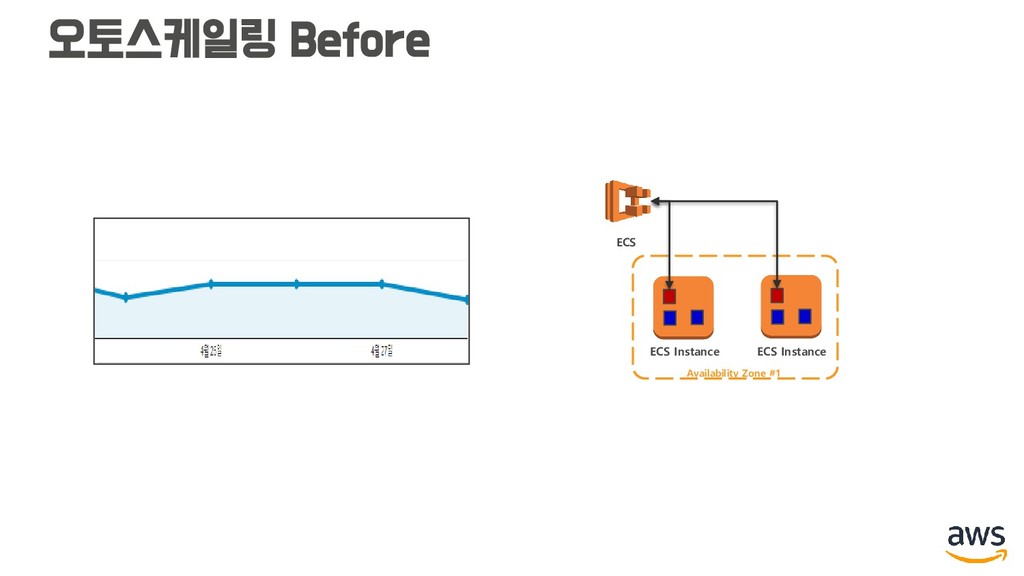
CPU 사용률 평균 60% 이상 1분 지속 => 스케일 아웃 지표: CPUUtilization 조건: >= 60 기간 1 / 1 작업: 인스턴스 1 추가 • 클러스터 인스턴스 메모리 사용률 평균 60% 이상 1분 지속 => 스케일 아웃 지표: MemoryUtilization 조건: >= 60 기간 1 / 1 작업: 인스턴스 1 추가
= 모든 작업이 사용중인 유닛 사용량 작업 1개당 유닛 제한 ∗ 전체 작업 수 ∗ 100 • Ex) 400 CPU 유닛 제한 작업 2개가 각 150 CPU 유닛 사용 • 150 ∗ 2 400 ∗ 2 ∗ 100 = 37.5% • 서비스 Mem Utilization = 모든 작업이 사용중인 메모리 사용량 작업 1개당 메모리 제한 ∗ 전체 작업 수 ∗ 100 • Ex) 420MB 제한 작업 2개가 각 250MB 메모리 사용 • 250 ∗ 2 420 ∗ 2 ∗ 100 = 59.5%
평균 60% 이상 1분 지속 => 스케일 아웃 지표: CPUUtilization 조건: >= 60 기간 1 / 1 작업: 작업 1 추가 • 서비스 메모리 사용률 평균 60% 이상 1분 지속 => 스케일 아웃 지표: MemoryUtilization 조건: >= 60 기간 1 / 1 작업: 작업 1 추가 • 서비스 CPU 사용률 평균 30 미만 10분 지속 => 스케일 인 지표: CPUUtilization 조건: < 30 기간 10 / 10 작업: 작업 1 삭제
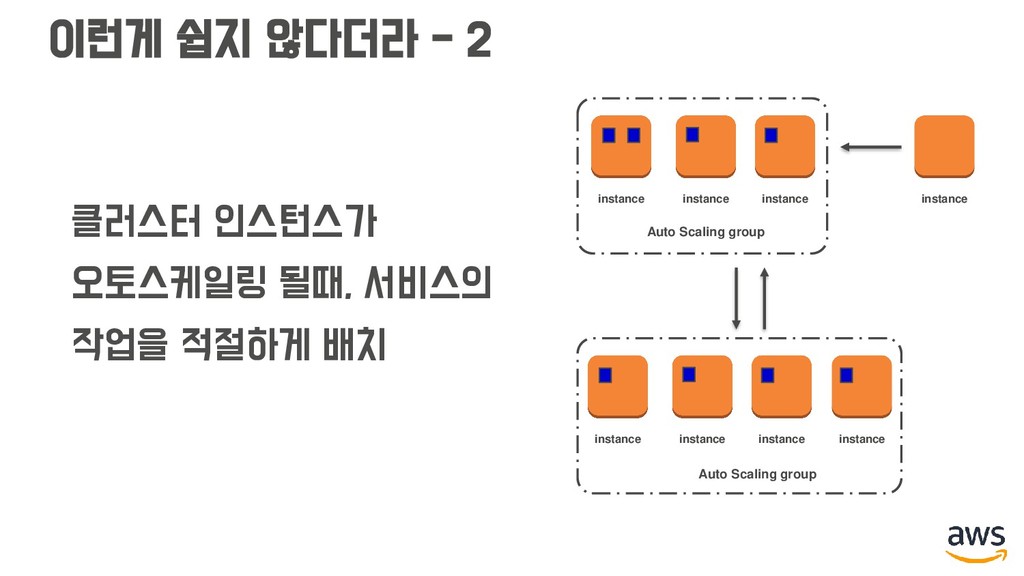
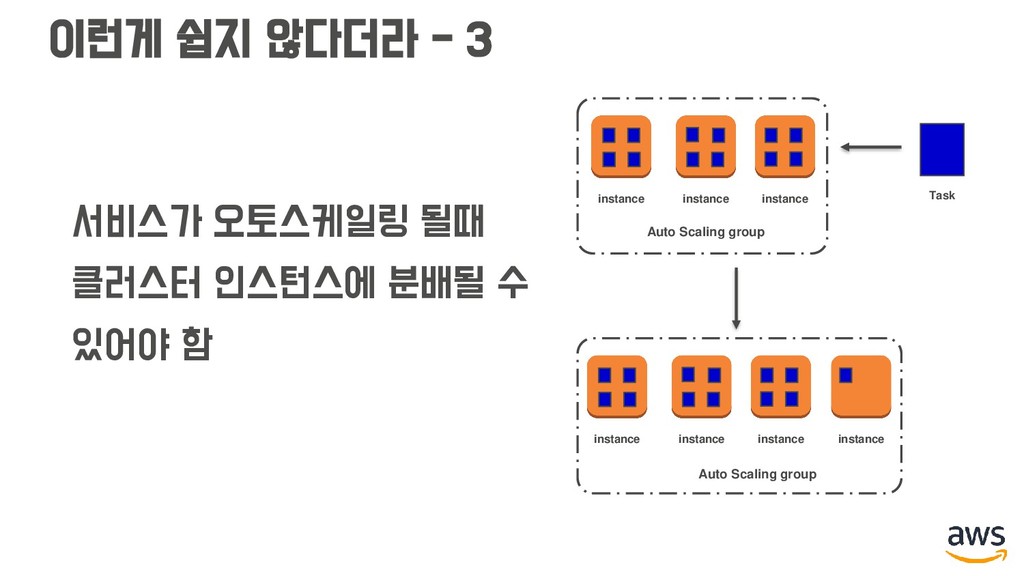
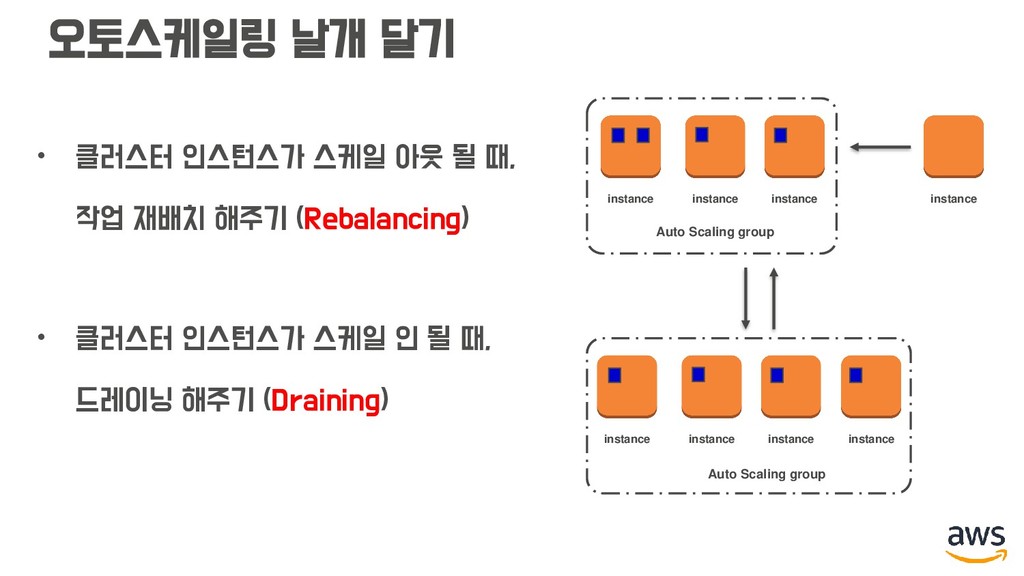
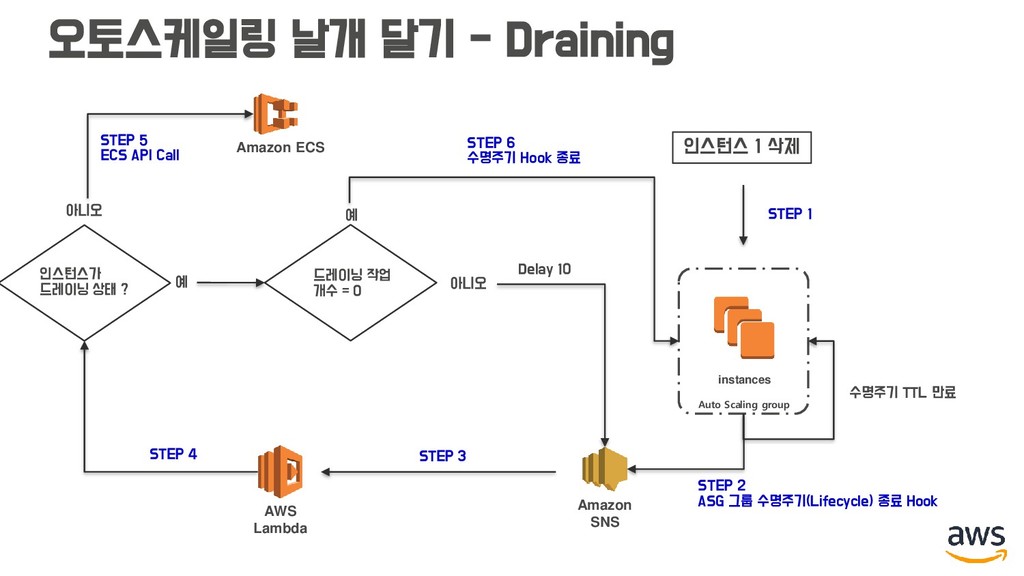
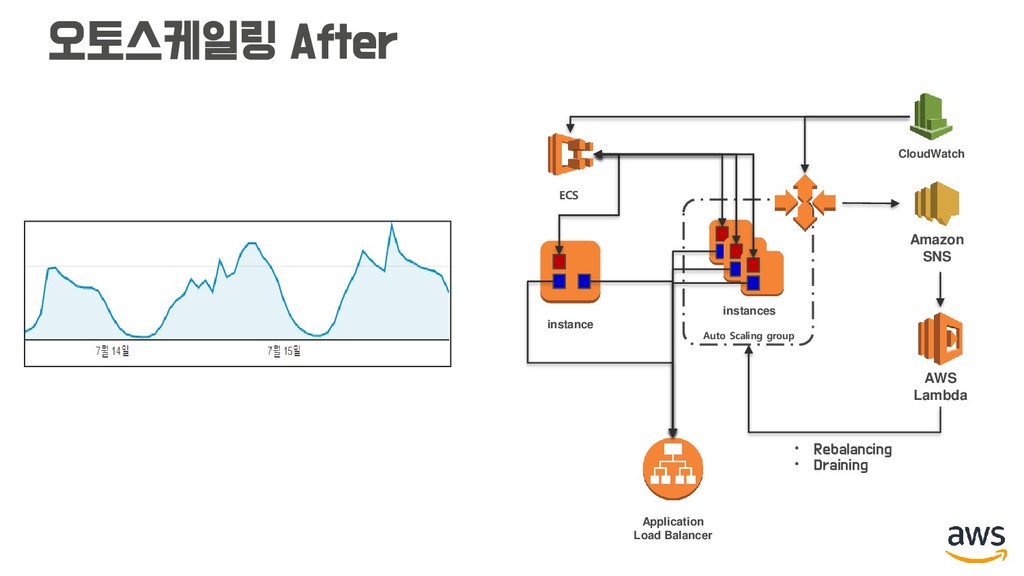
작업 재배치 해주기 (Rebalancing) • 클러스터 인스턴스가 스케일 인 될 때, 드레이닝 해주기 (Draining) instance instance instance instance Auto Scaling group instance instance instance instance Auto Scaling group
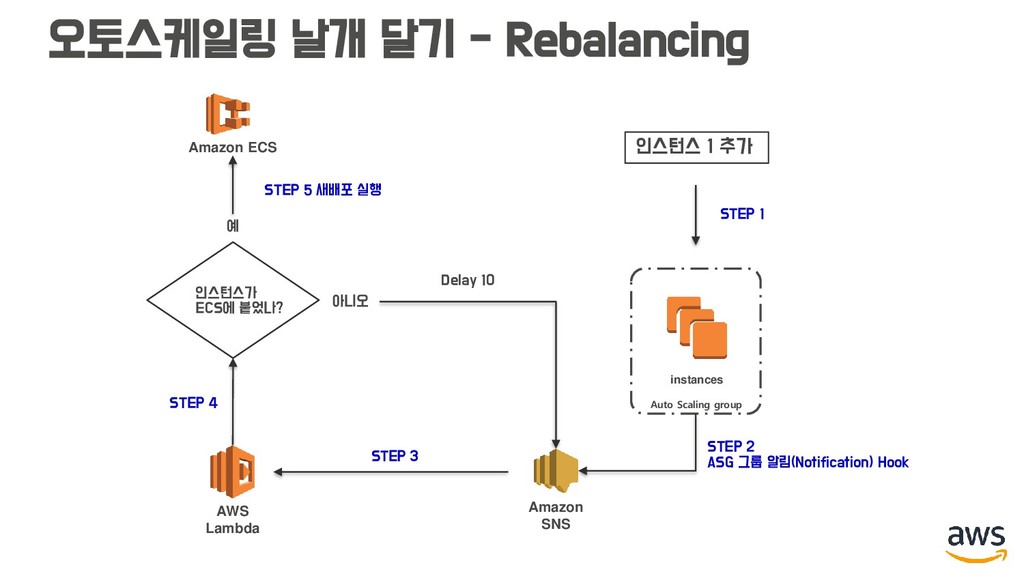
• 앞에 말씀드린 리발란싱은 깃허브 ECS-Agent 레포지토리 이슈에 아직도 열려 있는 상태입니다. (알림 받아놓으시면 더 좋은 방법을 얻을 수도...) • 지금도 여전히 서비스를 운영하며 더 나은 방법을 찾고 있습니다. (어쩌면 저는 그게 Fargate 서울 출시라고 생각하고요..)
![육승찬 [email protected] ECS 클러스터 & 서비스 오토스케일링](https://files.speakerdeck.com/presentations/541c3989a5624a018df90051fe307f8a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}