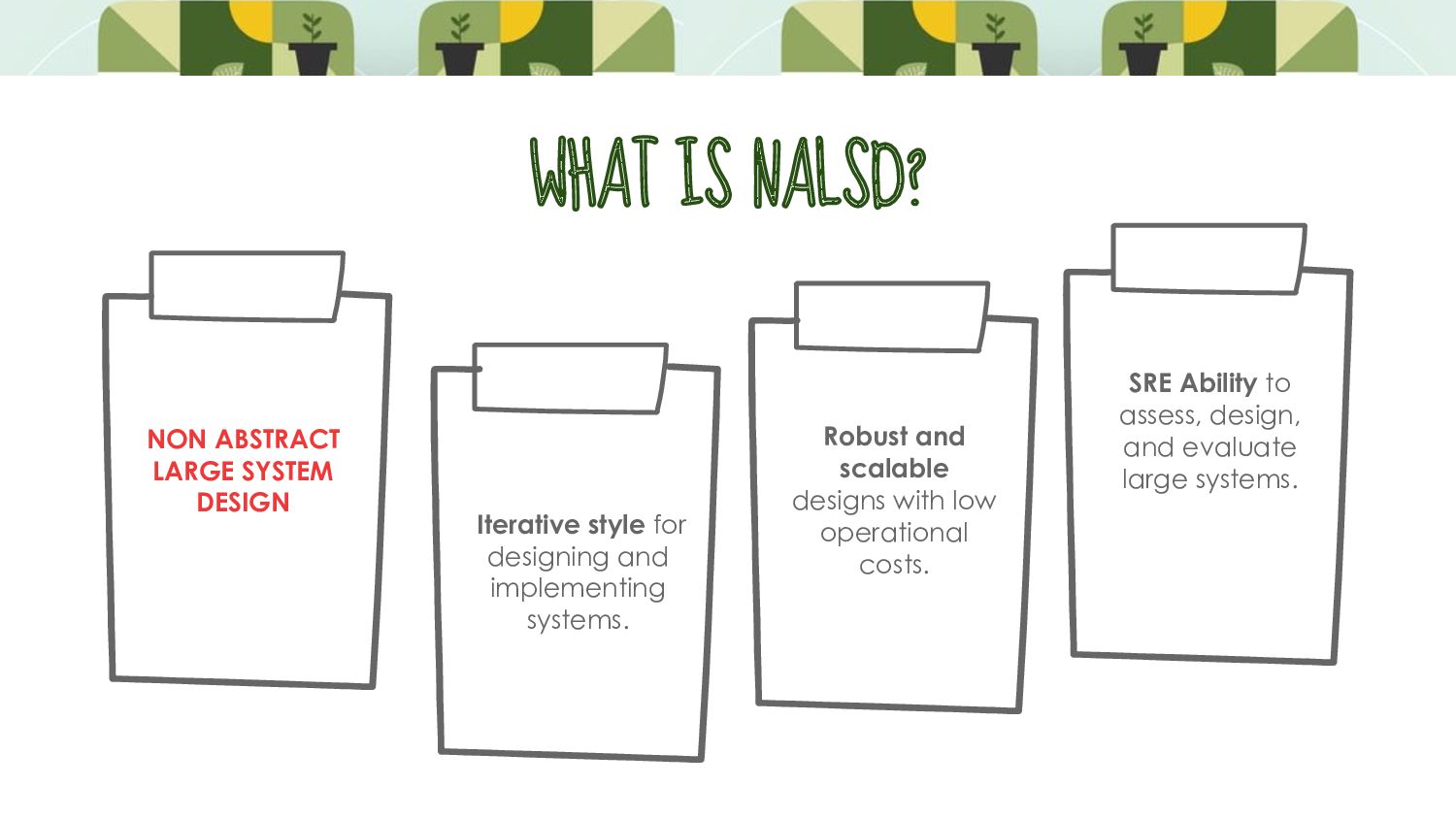
to start resource planning with a basic whiteboard diagram of a system, think through the various scaling and failure domains, and focus their design into a concrete proposal for resources.
distributed systems need to develop and continuously exercise the muscle of design into concrete estimates of resources at multiple steps in the process. WHY NALSD?
consider how to design large systems for reliability, resilience, and efficiency. NALSD is not only used when building a new system, but also when systems need to be changed. Focus on building experience and judgment, not simply more algorithms.
Machine Now we’ll need multiple machines, what’s the best design to join them? Distributed System Basic Design Phase * Is it possible? * Can we do better? Basic Design Phase * Is it feasible? * Is resilient? * Is it resilient? Design Process NALSD DESIGN PROCESS * Read & Understand * Required SLOs * Ask that you consider Initial Requirements
Main Memory Reference Time Round trip within same datacenter Power of ten? ns / us / ms Speed Read sequentially from SSD From: https://cloud.google.com/blog/products/manage ment-tools/sre-principles-and-flashcards-to-design- nalsd Time Read 1 MB sequentially from memory
on Google Web Search. • The click-through rate (CTR) metric tells advertisers how well their ads are performing. CTR = # clicks on the announcement # times that the announcement is shown AdWords Challenge Design a system capable of measuring and reporting an accurate CTR for every AdWords ad.
Machine Now we’ll need multiple machines, what’s the best design to join them? Distributed System Basic Design Phase * Is it possible? * Can we do better? Basic Design Phase * Is it feasible? * Is resilient? * Is it resilient? Design Process NALSD DESIGN PROCESS * Read & Understand * Required SLOs * Ask that you consider Initial Requirements
worry about enough RAM, CPU, network bandwidth, and so on, what would we design to satisfy the requirements? Can we do better? If the design solves the problem in O(N) time, can we solve it more quickly—say, O(ln(N))? CTR: the number of clicks divided by the number of impressions.
basic design Is it feasible? Is it possible to scale this design, given constraints on HW? What distributed design would satisfy the requirements? Is it resilient? Can the design fail gracefully? What happens when this component fails? How does the system work when fails? Can we do better? CTR: the number of clicks divided by the number of impressions.
Machine Now we’ll need multiple machines, what’s the best design to join them? Distributed System Basic Design Phase * Is it possible? * Can we do better? Basic Design Phase * Is it feasible? * Is resilient? * Is it resilient? Design Process NALSD DESIGN PROCESS * Read & Understand * Required SLOs * Ask that you consider Initial Requirements
is keyed by ad_id and is associated with a list of search terms selected by the advertiser. * How often this search term triggered this ad to be shown? * How many times the ad was clicked by someone who saw the ad? * With this information, we can calculate the CTR CTR: the number of clicks divided by the number of impressions.
That the dashboard displays quickly! ◦ That the data is recent. Therefore, we will consider our requirements in terms of SLOs: • 99.9% of dashboard queries complete in < 1 second. • 99.9% of the time, the CTR data displayed is less than 5 minutes old. INITIAL REQUIREMENTS
Machine Now we’ll need multiple machines, what’s the best design to join them? Distributed System Basic Design Phase * Is it possible? * Can we do better? Basic Design Phase * Is it feasible? * Is resilient? * Is it resilient? Design Process NALSD DESIGN PROCESS * Read & Understand * Required SLOs * Ask that you consider Initial Requirements
query occurred A QUERY_ID unique identifier An AD_ID The AD IDs of THE AdWords advertisements shown for the search A SEARCH_TERM the query content ONE MACHINE
as 2 KB. Click log volume should be considerably smaller than query log volume: because the average CTR is 2% (10,000 clicks / 500,000 queries) Remember that we chose big numbers to illustrate that these principles scale to arbitrarily large implementations. ONE MACHINE
Machine Now we’ll need multiple machines, what’s the best design to join them? Distributed System Basic Design Phase * Is it possible? * Can we do better? Basic Design Phase * Is it feasible? * Is resilient? * Is it resilient? Design Process NALSD DESIGN PROCESS * Read & Understand * Required SLOs * Ask that you consider Initial Requirements
with MapReduce. * We can grab the accumulated query logs and click logs. MapReduce works as a batch processor: its inputs are a large data set, and it can use many machines to process that data via workers and produce a result. Unfortunately, this type of batch process can’t meet our SLO of joined log availability within 5 minutes of logs being received. EVALUATION
Machine Now we’ll need multiple machines, what’s the best design to join them? Distributed System Basic Design Phase * Is it possible? * Can we do better? Basic Design Phase * Is it feasible? * Is resilient? * Is it resilient? Design Process NALSD DESIGN PROCESS * Read & Understand * Required SLOs * Ask that you consider Initial Requirements
and pull in the specific queries referenced. We’ll call this component the LogJoiner LogJoiner takes a continuous stream of data from the click logs, joins it with the data in QueryStore, and then stores that information, organized by ad_id. Once the queries that were clicked on are stored and indexed by ad_id, we have half the data required to generate the CTR dashboard. We will call this the ClickMap, because it maps from ad_id to the clicks. LogJoiner
process the logs: * (104 clicks/sec) × (2 × 103 bytes) = 2 × 107 = 20 MB/sec = 160 Mbps -- * 3 × (5 × 105 queries/sec) × (8.64 × 104 seconds/day) × (8 bytes + 8 bytes) = 2 × 1012 = 2 TB/day for QueryMap The next step in scaling the design is to shard the inputs and outputs. To divide the incoming query logs and click logs into multiple streams.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}