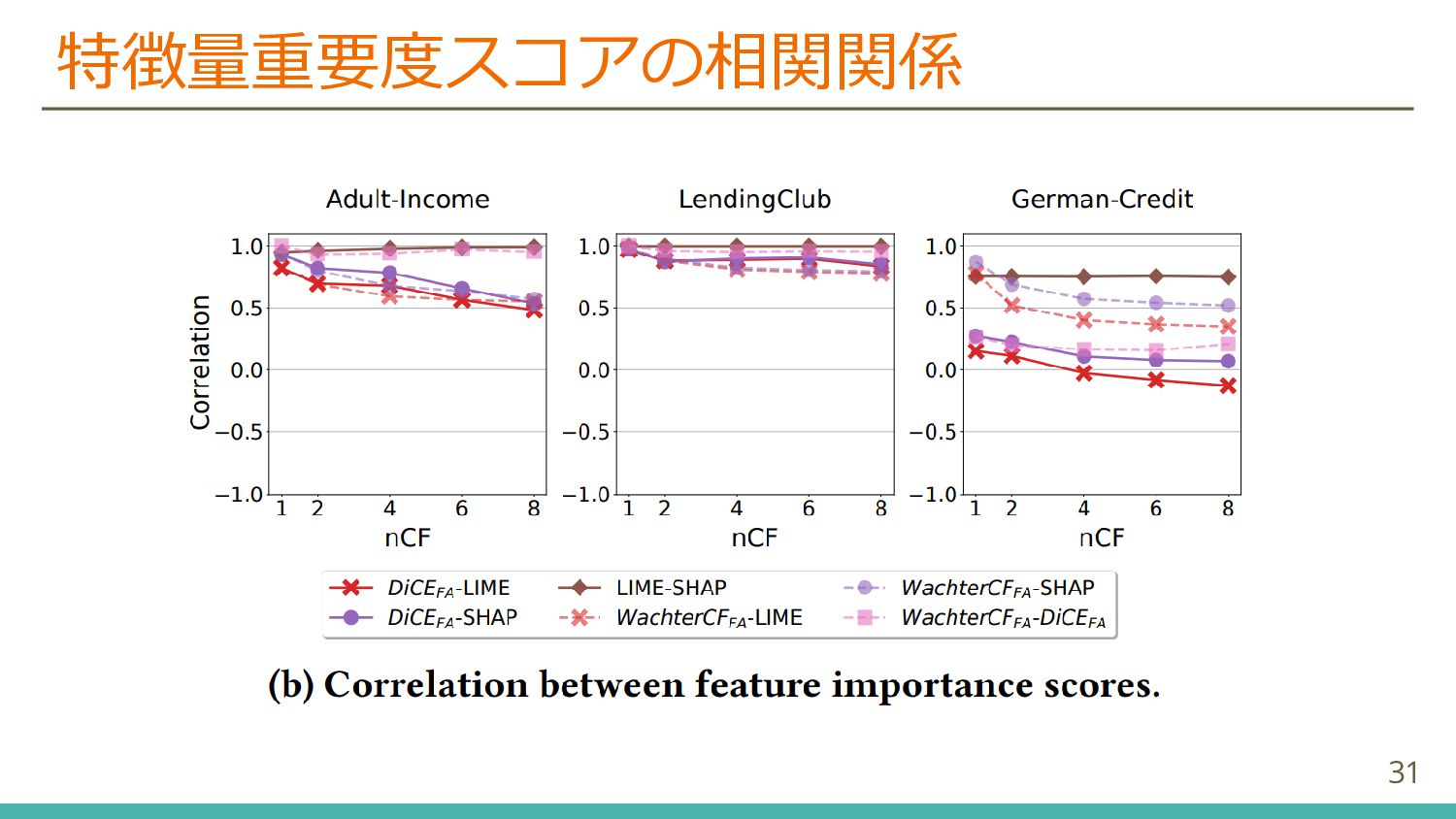
説明可能なAI (eXplainable AI, XAI) の研究において, 事後的な説明手法と反実仮想による説明手法で得られた別々の特徴量重要度スコアの一致度を比較した研究.
In a study of eXplainable AI (XAI), researcher compared the agreement of separate feature importance scores obtained by a posteriori and counterfactual explanatory methods.
{kind=link}
{kind=link}
{kind=link}
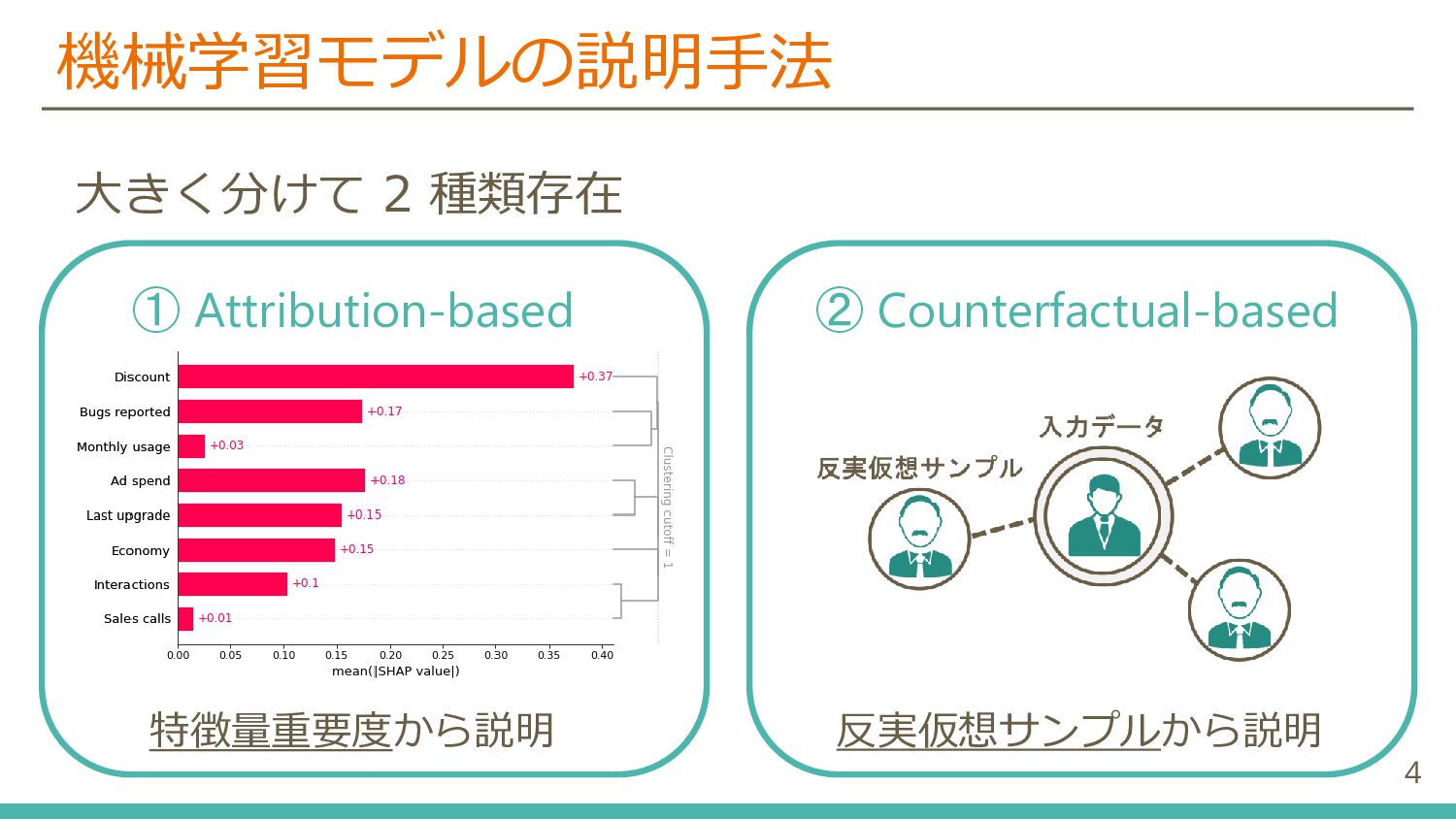{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Attribution-based methods ① LIME [Ribeiro et al. 2016] 複雑な機械学習モデルをより単純な 線形回帰モデルで近似した手法](https://files.speakerdeck.com/presentations/8e025cd533d44112acd1d22f458bfa94/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
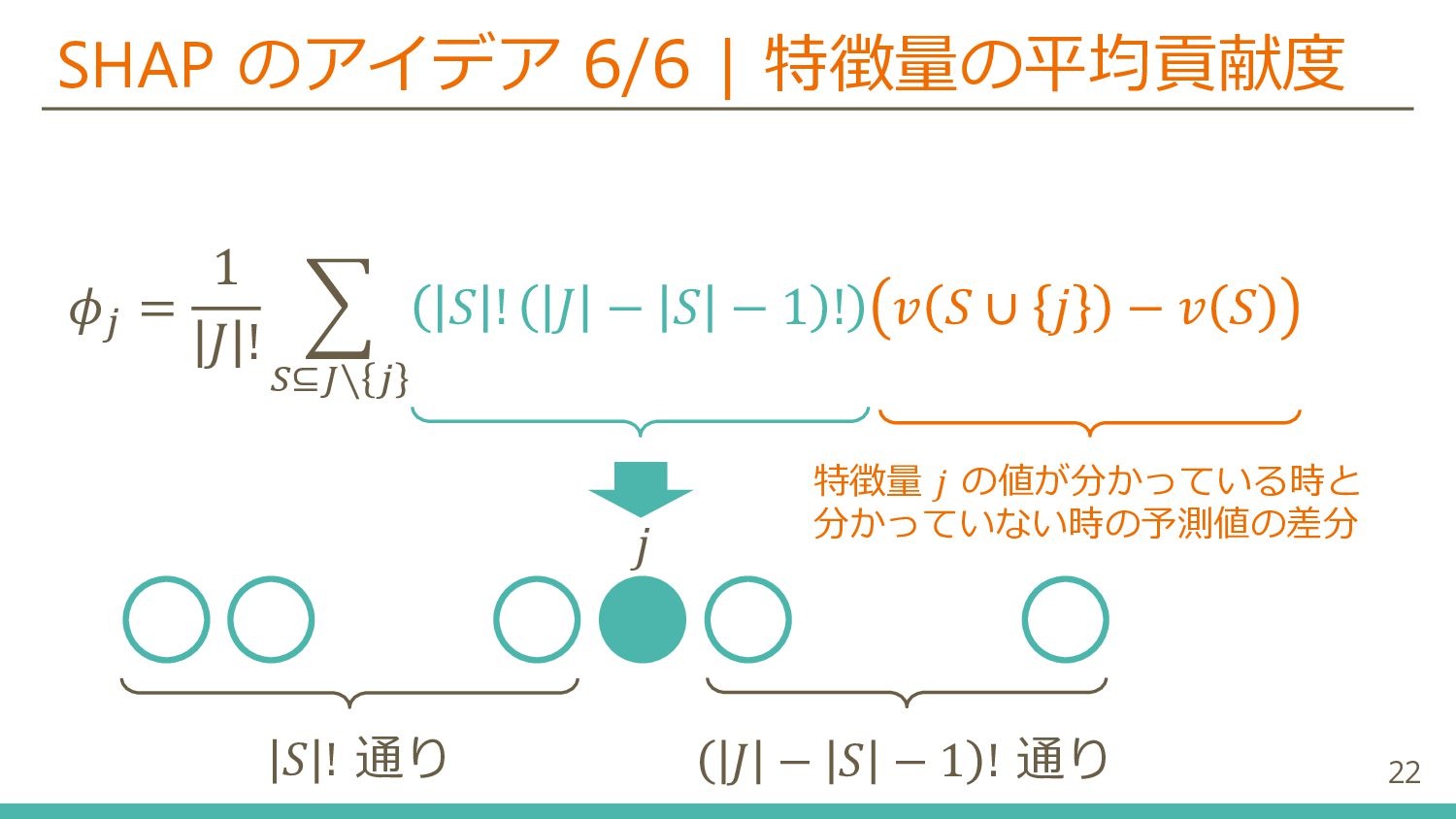{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
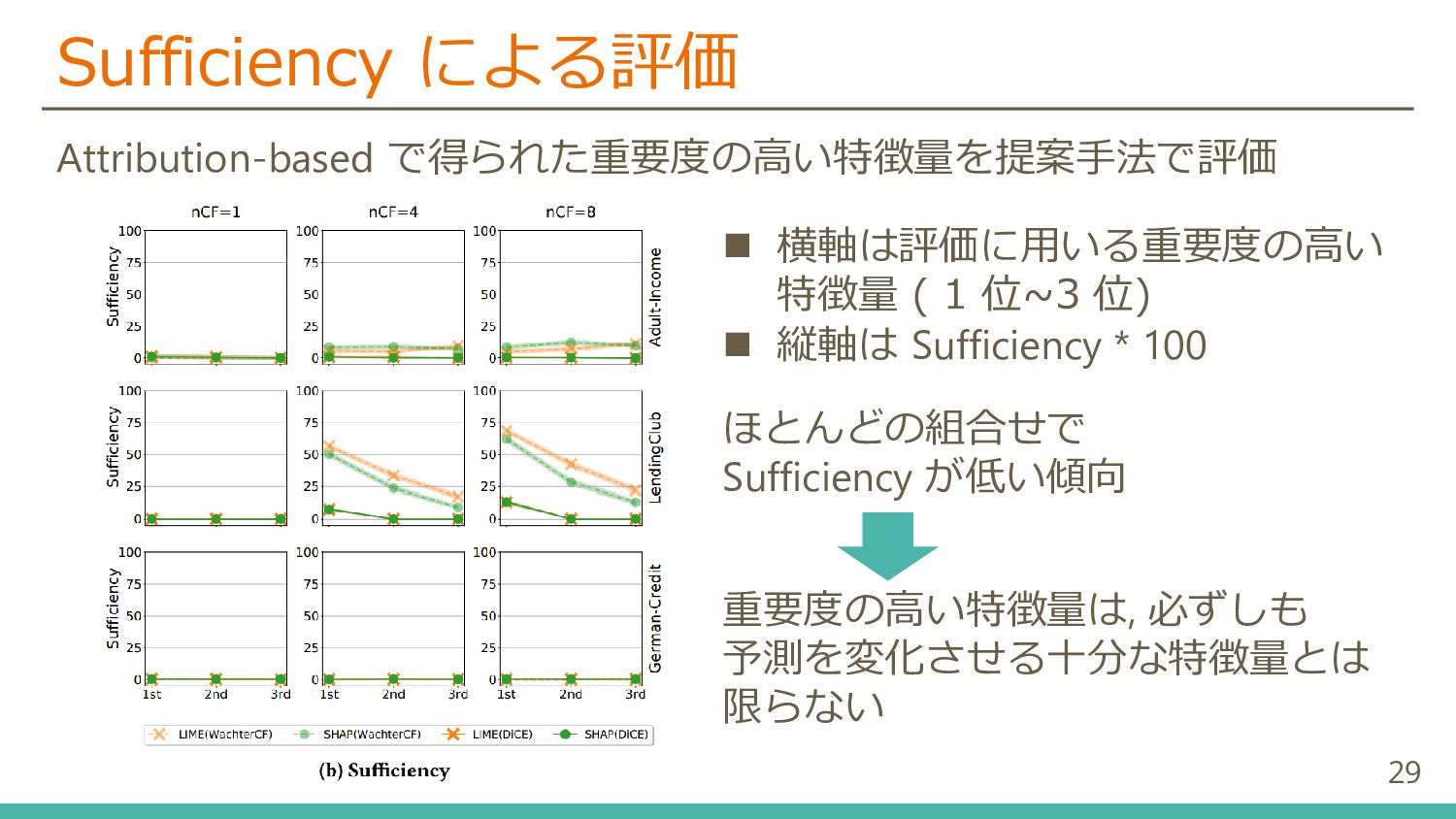{kind=link}
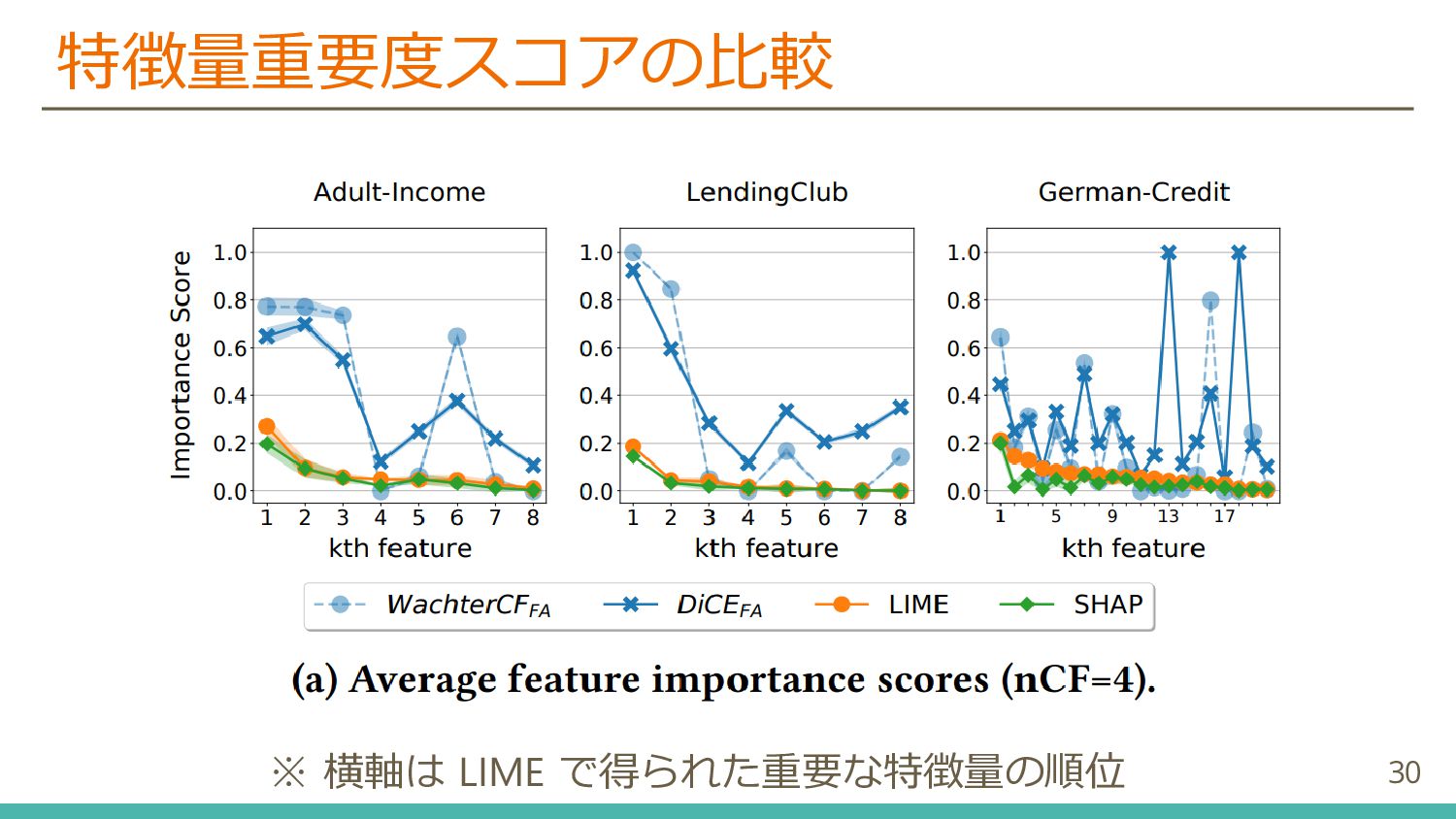{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}