Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Understanding deeplearning, Chapter 9: Regulari...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yusumi
June 07, 2023
Science
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Understanding deeplearning, Chapter 9: Regularization
Prince, S. J. D. (2023). Understanding Deep Learning. MIT Press.
http://udlbook.com
yusumi
June 07, 2023
More Decks by yusumi
See All by yusumi
Understanding deeplearning, Chapter 13: Graph neural networks
yusumi
0
150
論文紹介: Semi-Supervised Learning with Normalizing Flows
yusumi
0
90
Understanding deeplearning, Chapter 16: Normalizing flows
yusumi
1
200
論文紹介 : Beyond trivial counterfactual explanations with diverse valuable explanations
yusumi
0
120
論文紹介 : Regularizing Variational Autoencoder with Diversity and Uncertainty Awareness
yusumi
0
190
Recommender Systems
yusumi
1
94
論文紹介 : Multi objective optimization of item selection in computerized adaptive testing
yusumi
0
92
Neural Networks for Sequences
yusumi
0
150
【論文紹介】Towards Unifying Feature Attribution and Counterfactual Explanations
yusumi
0
140
Other Decks in Science
See All in Science
Bear-safety-running
akirun_run
0
170
データベース12: 正規化(2/2) - データ従属性に基づく正規化
trycycle
PRO
0
1.3k
CVPR2026_VGGTとその仲間たち
mickey_0226
0
980
Conversation is the New Dashboard: 属人性を排除する第4世代BIツールの勢力図
shomaekawa
1
610
Inside the Mind of an LLM
baggiponte
0
200
検索と推論タスクに関する論文の紹介
ynakano
1
250
生成AIと司法書士の未来.pdf
tagtag
PRO
0
130
(メタ)科学コミュニケーターからみたAI for Scienceの同床異夢
rmaruy
0
260
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
270
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.2k
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
210
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
tagtag
PRO
0
210
Featured
See All Featured
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Statistics for Hackers
jakevdp
799
230k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
Visualization
eitanlees
152
17k
Designing for humans not robots
tammielis
254
26k
エンジニアに許された特別な時間の終わり
watany
107
250k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
So, you think you're a good person
axbom
PRO
2
2.1k
The browser strikes back
jonoalderson
0
1.4k
Building Applications with DynamoDB
mza
96
7.1k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Transcript
Chapter 9: Regularization Understanding deep learning, Prince [2023] yusumi
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 「正則」とは何か 大学数学でよく触れられる概念だが, 専門科目によってその意味が異なり混乱することがある Chaper 9: Regularization – yusumi 2/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 「正則」とは何か はじめに「正則」という概念自体の意味を確認しよう Chaper 9: Regularization – yusumi 3/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
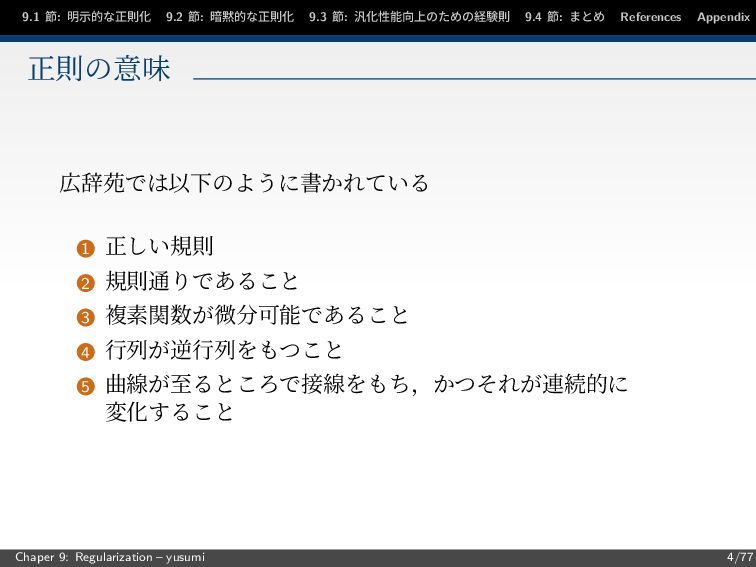
節: まとめ References Appendix 正則の意味 広辞苑では以下のように書かれている 1 正しい規則 2 規則通りであること 3 複素関数が微分可能であること 4 行列が逆行列をもつこと 5 曲線が至るところで接線をもち,かつそれが連続的に 変化すること Chaper 9: Regularization – yusumi 4/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
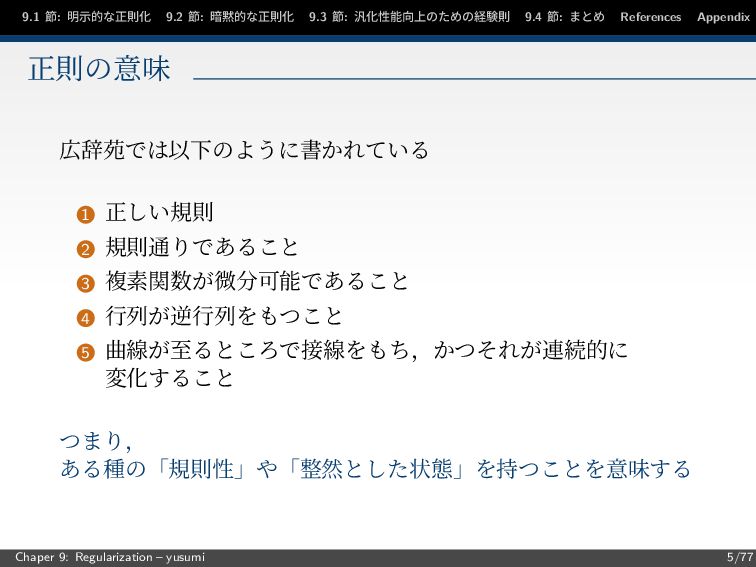
節: まとめ References Appendix 正則の意味 広辞苑では以下のように書かれている 1 正しい規則 2 規則通りであること 3 複素関数が微分可能であること 4 行列が逆行列をもつこと 5 曲線が至るところで接線をもち,かつそれが連続的に 変化すること つまり, ある種の「規則性」や「整然とした状態」を持つことを意味する Chaper 9: Regularization – yusumi 5/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 正則化の役割: 機械学習への適用 機械学習の文脈では, 「モデルの複雑さを制限し規則性を持たせる」という役割を担う Chaper 9: Regularization – yusumi 6/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 正則化の役割: 機械学習への適用 機械学習の文脈では, 「モデルの複雑さを制限し規則性を持たせる」という役割を果たす つまり,モデルが過学習することを避け, 全体が滑らかに (規則的に) 動作するように調整する Chaper 9: Regularization – yusumi 7/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 機械学習における正則化の2つの定義 広義の正則化 訓練データとテストデータの予測結果の乖離を減らすこと Chaper 9: Regularization – yusumi 8/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 機械学習における正則化の2つの定義 広義の正則化 訓練データとテストデータの予測結果の乖離を減らすこと 狭義の正則化 モデルの損失関数に特別な損失項 (正則化項) を追加すること Chaper 9: Regularization – yusumi 9/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 目次 1 9.1 節: 明示的な正則化 2 9.2 節: 暗黙的な正則化 3 9.3 節: 汎化性能向上のための経験則 4 9.4 節: まとめ 5 Appendix Chaper 9: Regularization – yusumi 10/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.1 節: 明示的な正則化 Chaper 9: Regularization – yusumi 11/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
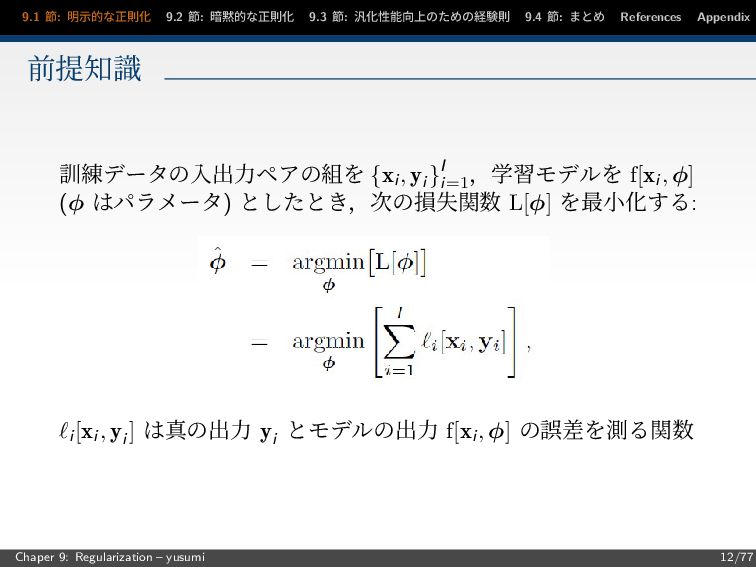
節: まとめ References Appendix 前提知識 訓練データの入出力ペアの組を {xi, yi }I i=1 ,学習モデルを f[xi, φ] (φ はパラメータ) としたとき,次の損失関数 L[φ] を最小化する: i[xi, yi ] は真の出力 yi とモデルの出力 f[xi, φ] の誤差を測る関数 Chaper 9: Regularization – yusumi 12/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
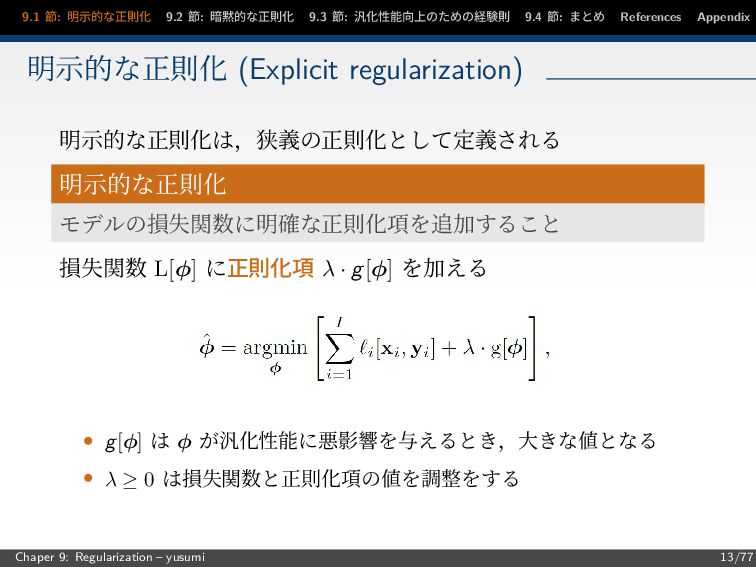
節: まとめ References Appendix 明示的な正則化 (Explicit regularization) 明示的な正則化は,狭義の正則化として定義される 明示的な正則化 モデルの損失関数に明確な正則化項を追加すること 損失関数 L[φ] に正則化項 λ · g[φ] を加える • g[φ] は φ が汎化性能に悪影響を与えるとき,大きな値となる • λ ≥ 0 は損失関数と正則化項の値を調整をする Chaper 9: Regularization – yusumi 13/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 正則化項の追加による大域最小点の移動 • a) ガボールモデルの損失関数における局所・大域最小点 • b) プロットの中心付近に制約を強めた正則化項 • c) 正則化項を加えた後の局所・大域最小点の移動 局所最小点の数が減り,大域最小点が中心に移動している Chaper 9: Regularization – yusumi 14/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
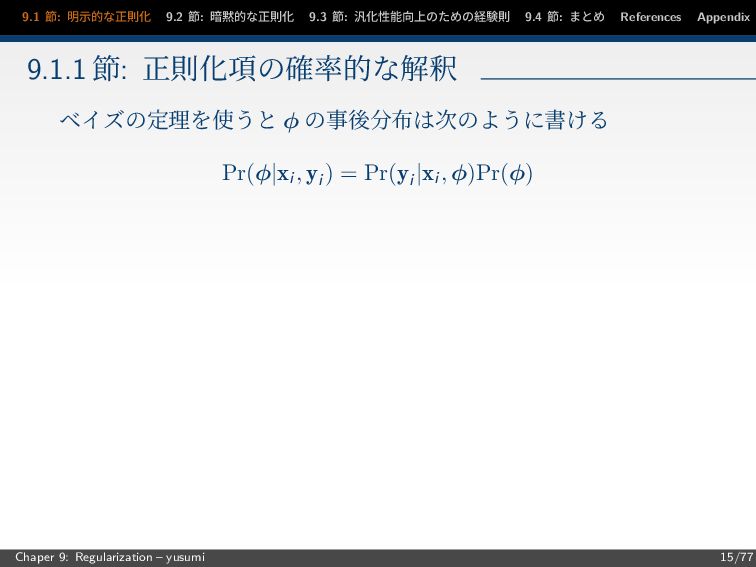
節: まとめ References Appendix 9.1.1 節: 正則化項の確率的な解釈 ベイズの定理を使うと φ の事後分布は次のように書ける Pr(φ|xi, yi ) = Pr(yi |xi, φ)Pr(φ) Chaper 9: Regularization – yusumi 15/77
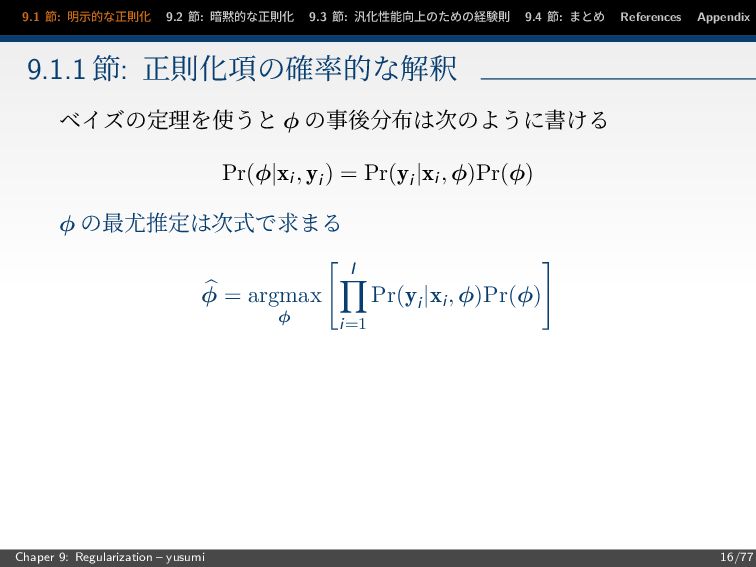
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.1.1 節: 正則化項の確率的な解釈 ベイズの定理を使うと φ の事後分布は次のように書ける Pr(φ|xi, yi ) = Pr(yi |xi, φ)Pr(φ) φ の最尤推定は次式で求まる φ = argmax φ I i=1 Pr(yi |xi, φ)Pr(φ) Chaper 9: Regularization – yusumi 16/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.1.1 節: 正則化項の確率的な解釈 ベイズの定理を使うと φ の事後分布は次のように書ける Pr(φ|xi, yi ) = Pr(yi |xi, φ)Pr(φ) φ の最尤推定は次式で求まる φ = argmax φ I i=1 Pr(yi |xi, φ)Pr(φ) このままでは計算が困難なため,負の対数尤度をとって推定する φ = argmin φ − I i=1 log Pr(yi |xi, φ) − log [Pr(φ)] 正則化項は事前分布の負の対数 λ · g[φ] = − log [Pr(φ)] に相当 Chaper 9: Regularization – yusumi 17/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
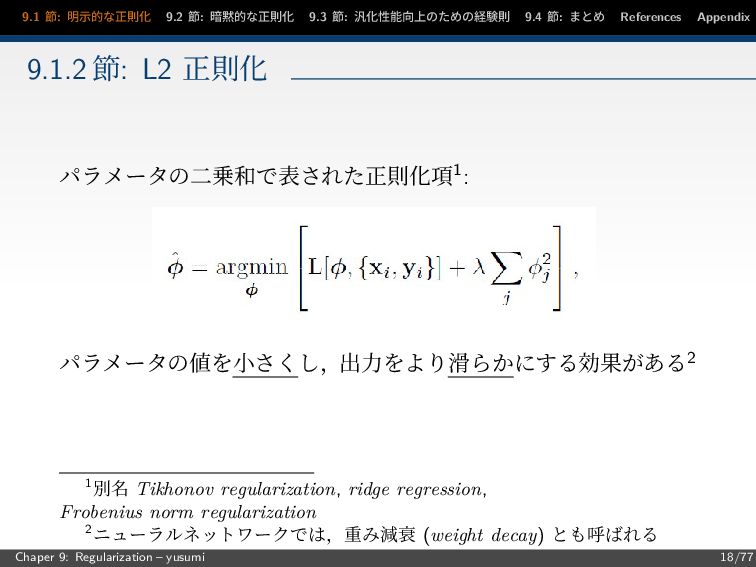
節: まとめ References Appendix 9.1.2 節: L2 正則化 パラメータの二乗和で表された正則化項1: パラメータの値を小さくし,出力をより滑らかにする効果がある2 1別名 Tikhonov regularization, ridge regression, Frobenius norm regularization 2ニューラルネットワークでは,重み減衰 (weight decay) とも呼ばれる Chaper 9: Regularization – yusumi 18/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
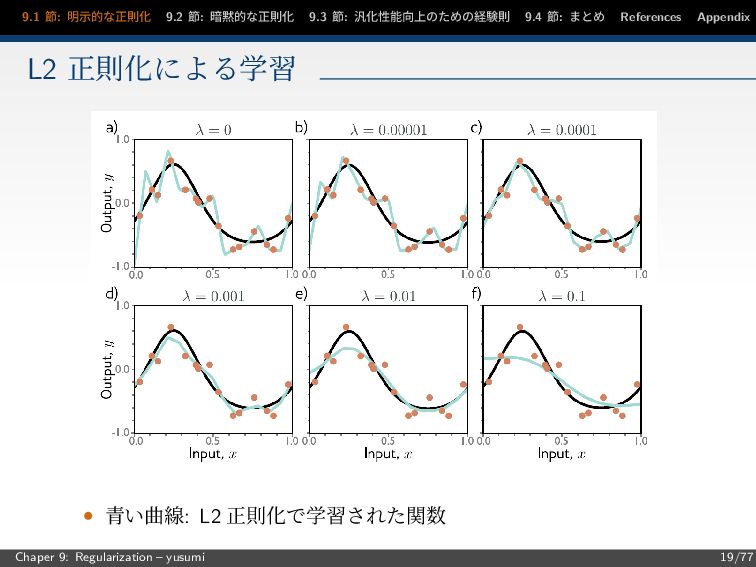
節: まとめ References Appendix L2 正則化による学習 • 青い曲線: L2 正則化で学習された関数 Chaper 9: Regularization – yusumi 19/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix L2 正則化による効果 テストデータに対する予測精度が高まる可能性がある L2 正則化項の追加による 2 つの効果 1 過学習の抑制: データの過適合を減らし滑らかな関数表現を優先する効果 2 未観測領域の補完: データが観測されていない領域を滑らかに補間する効果 Chaper 9: Regularization – yusumi 20/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.2 節: 暗黙的な正則化 Chaper 9: Regularization – yusumi 21/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 暗黙的な正則化 (Implicit regularization) 暗黙的な正則化 正則化項をモデルに追加せずとも,学習アルゴリズムや 最適化手法そのものがある種の正則化効果を生むこと 暗黙的な正則化の代表例は以下の通り: • 勾配降下法 • 確率的勾配降下法 Chaper 9: Regularization – yusumi 22/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 前準備: 勾配降下法の連続版 勾配降下法の連続版では,φ の勾配は微分方程式で与えられる: ここで t は時間を表す Chaper 9: Regularization – yusumi 23/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 前準備: 勾配降下法の離散版 勾配降下法の連続版では,φ の勾配は微分方程式で与えられる: ここで t は時間を表す しかし現実の計算機では連続量を扱うことができないため, 離散的なステップ α の更新式で近似する: ∂φ ∂t ≈ lim α→0 φ[t + α] − φ[t] α (1) Chaper 9: Regularization – yusumi 24/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
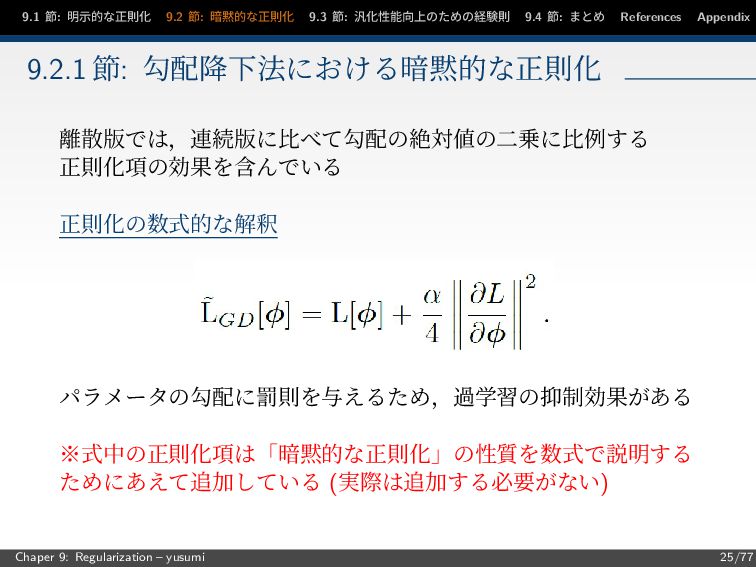
節: まとめ References Appendix 9.2.1 節: 勾配降下法における暗黙的な正則化 離散版では,連続版に比べて勾配の絶対値の二乗に比例する 正則化項の効果を含んでいる 正則化の数式的な解釈 パラメータの勾配に罰則を与えるため,過学習の抑制効果がある ※式中の正則化項は「暗黙的な正則化」の性質を数式で説明する ためにあえて追加している (実際は追加する必要がない) Chaper 9: Regularization – yusumi 25/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
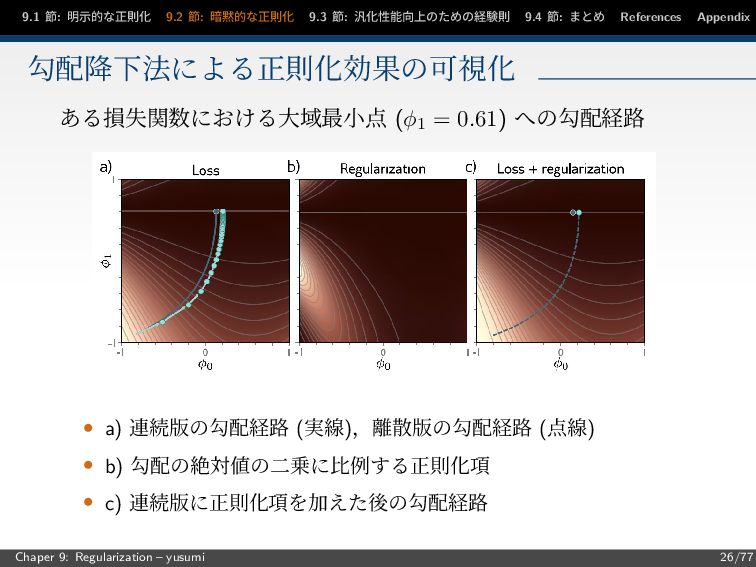
節: まとめ References Appendix 勾配降下法による正則化効果の可視化 ある損失関数における大域最小点 (φ1 = 0.61) への勾配経路 • a) 連続版の勾配経路 (実線),離散版の勾配経路 (点線) • b) 勾配の絶対値の二乗に比例する正則化項 • c) 連続版に正則化項を加えた後の勾配経路 Chaper 9: Regularization – yusumi 26/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.2.2 節: 確率的勾配降下法における暗黙的な正則化 B をバッチサイズ,Bb をミニバッチ内のデータ集合とすると, 各ミニバッチ勾配が全体勾配と一致するような正則化がはたらく 正則化の数式的な解釈 L は全データの誤差平均,Lb はミニバッチ内の誤差平均を表す Chaper 9: Regularization – yusumi 27/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.2.2 節: 確率的勾配降下法における暗黙的な正則化 B をバッチサイズ,Bb をミニバッチ内のデータ集合とすると, 各ミニバッチ勾配が全体勾配と一致するような正則化がはたらく 正則化の数式的な解釈 過学習・ミニバッチ勾配の偏りを同時に抑制する効果がある Chaper 9: Regularization – yusumi 28/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 確率的勾配降下法における損失関数の可視化 • a) ガボールモデルの 損失関数と大域最小点 • b) 確率的勾配降下法における 暗黙的な正則化項 (第 2 項) • c) 確率的勾配降下法における 暗黙的な正則化項 (第 3 項) • d) 確率的勾配降下法における 損失関数の変化 等高線に変化があるが, 大域最小点は特に移動していない つまり,大域最小点を変えずに 最適化プロセスを変更できる Chaper 9: Regularization – yusumi 29/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
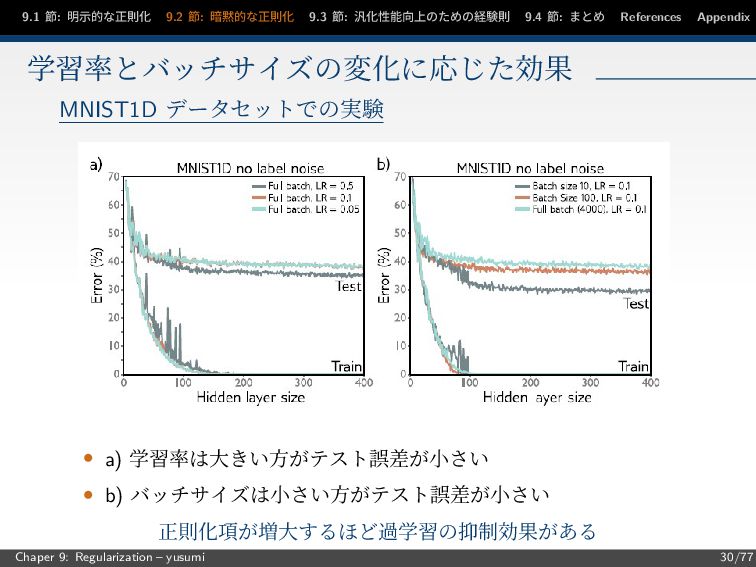
節: まとめ References Appendix 学習率とバッチサイズの変化に応じた効果 MNIST1D データセットでの実験 • a) 学習率は大きい方がテスト誤差が小さい • b) バッチサイズは小さい方がテスト誤差が小さい 正則化項が増大するほど過学習の抑制効果がある Chaper 9: Regularization – yusumi 30/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3 節: 汎化性能向上のための経験則 Chaper 9: Regularization – yusumi 31/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 32/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 33/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
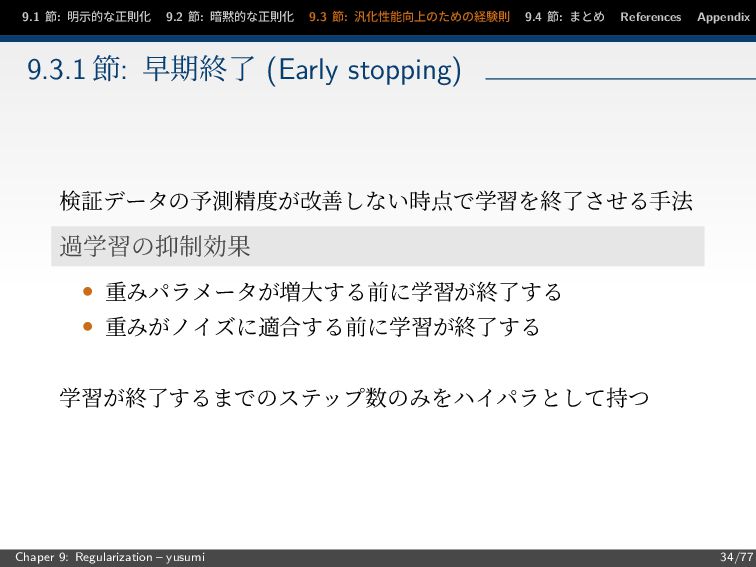
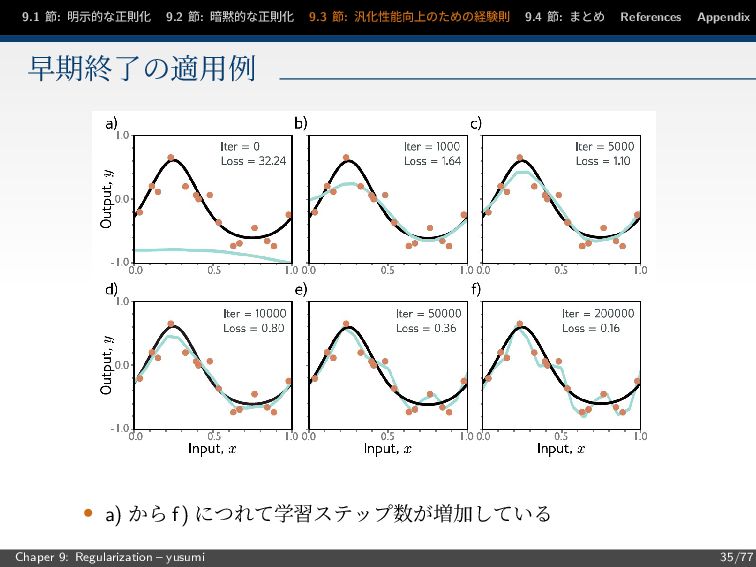
節: まとめ References Appendix 9.3.1 節: 早期終了 (Early stopping) 検証データの予測精度が改善しない時点で学習を終了させる手法 過学習の抑制効果 • 重みパラメータが増大する前に学習が終了する • 重みがノイズに適合する前に学習が終了する 学習が終了するまでのステップ数のみをハイパラとして持つ Chaper 9: Regularization – yusumi 34/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 早期終了の適用例 • a) から f) につれて学習ステップ数が増加している Chaper 9: Regularization – yusumi 35/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 36/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
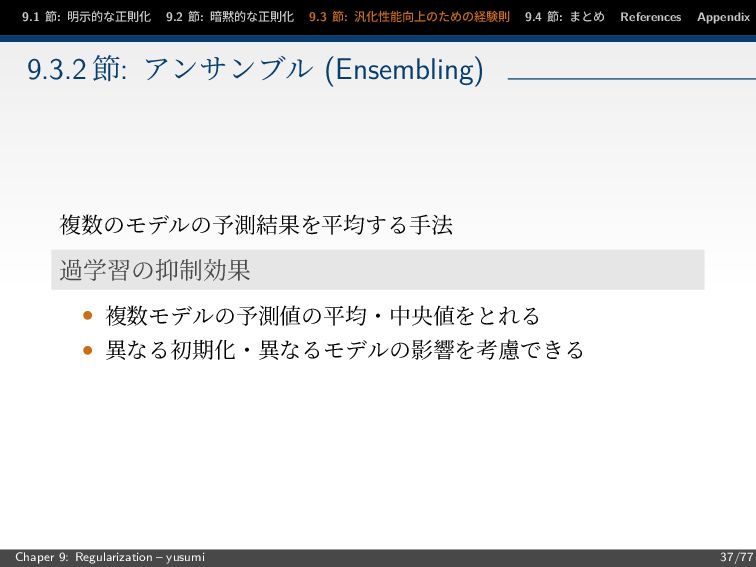
節: まとめ References Appendix 9.3.2 節: アンサンブル (Ensembling) 複数のモデルの予測結果を平均する手法 過学習の抑制効果 • 複数モデルの予測値の平均・中央値をとれる • 異なる初期化・異なるモデルの影響を考慮できる Chaper 9: Regularization – yusumi 37/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
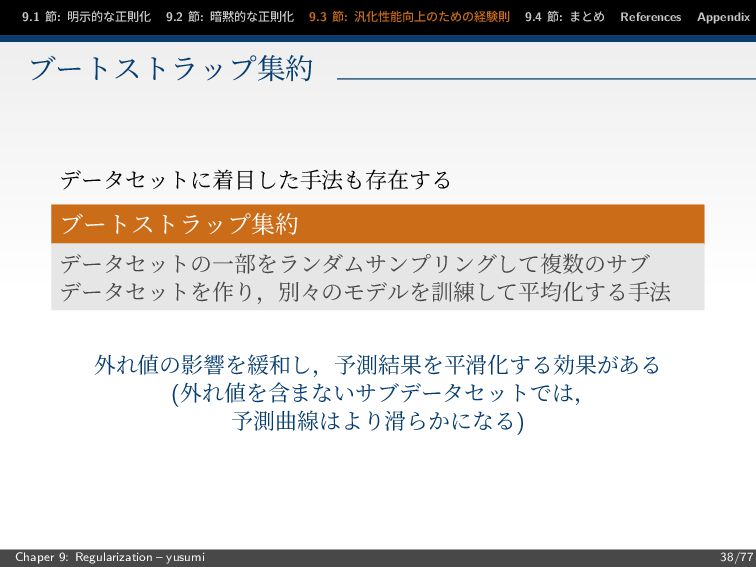
節: まとめ References Appendix ブートストラップ集約 データセットに着目した手法も存在する ブートストラップ集約 データセットの一部をランダムサンプリングして複数のサブ データセットを作り,別々のモデルを訓練して平均化する手法 外れ値の影響を緩和し,予測結果を平滑化する効果がある (外れ値を含まないサブデータセットでは, 予測曲線はより滑らかになる) Chaper 9: Regularization – yusumi 38/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
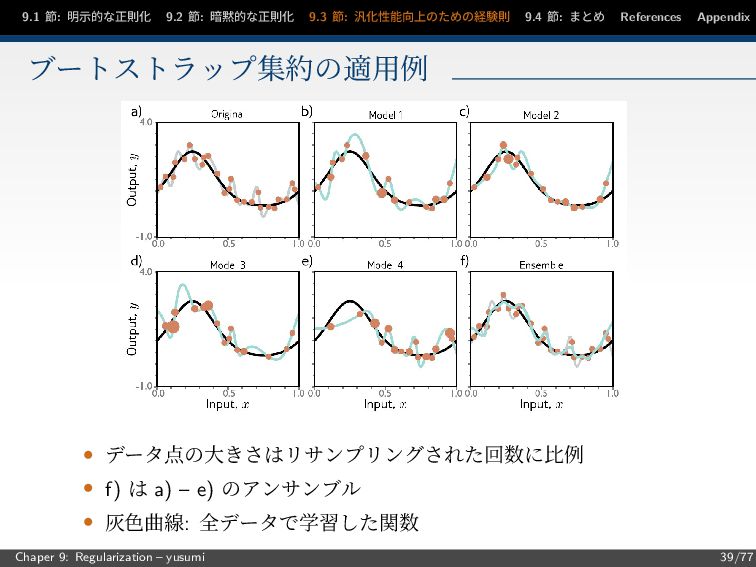
節: まとめ References Appendix ブートストラップ集約の適用例 • データ点の大きさはリサンプリングされた回数に比例 • f) は a) – e) のアンサンブル • 灰色曲線: 全データで学習した関数 Chaper 9: Regularization – yusumi 39/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 40/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3.3 節: ドロップアウト (Dropout) 確率的勾配降下法の各反復において, 隠れユニットをランダムに欠落させる手法 過学習の抑制効果 • 隠れユニットの状態に過度に依存しないようにする • 重みの大きさを小さくする効果がある Chaper 9: Regularization – yusumi 41/77
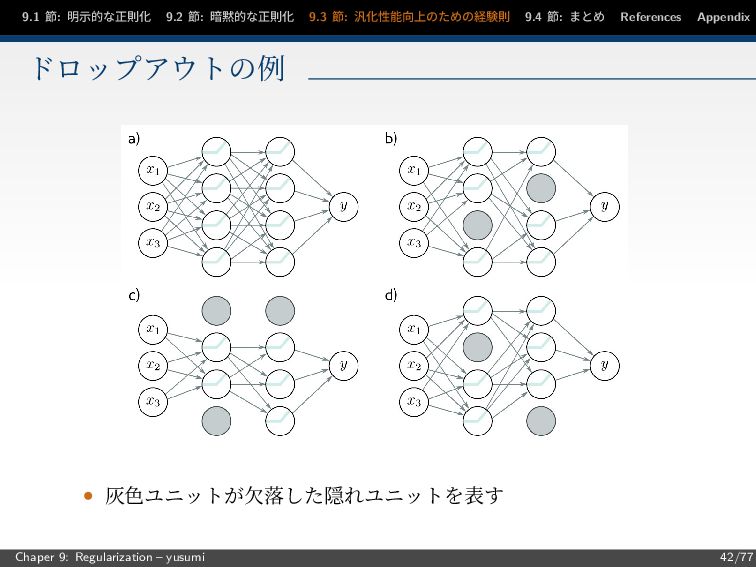
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix ドロップアウトの例 • 灰色ユニットが欠落した隠れユニットを表す Chaper 9: Regularization – yusumi 42/77
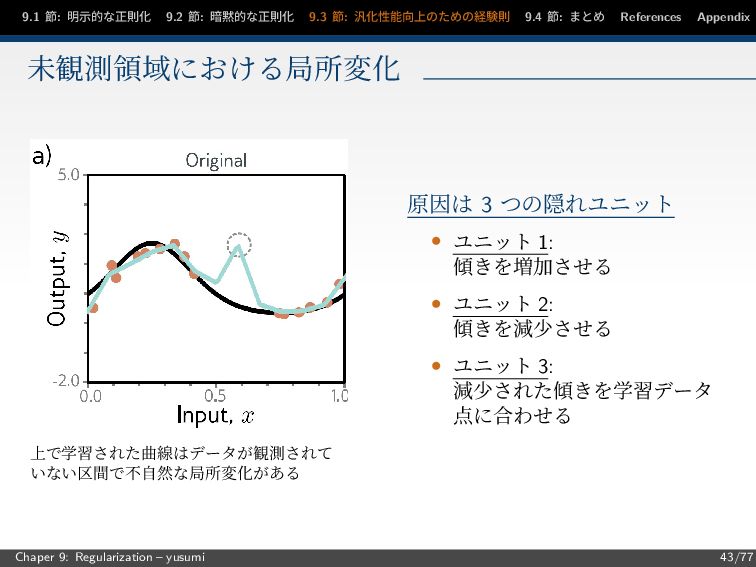
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 未観測領域における局所変化 上で学習された曲線はデータが観測されて いない区間で不自然な局所変化がある 原因は 3 つの隠れユニット • ユニット 1: 傾きを増加させる • ユニット 2: 傾きを減少させる • ユニット 3: 減少された傾きを学習データ 点に合わせる Chaper 9: Regularization – yusumi 43/77
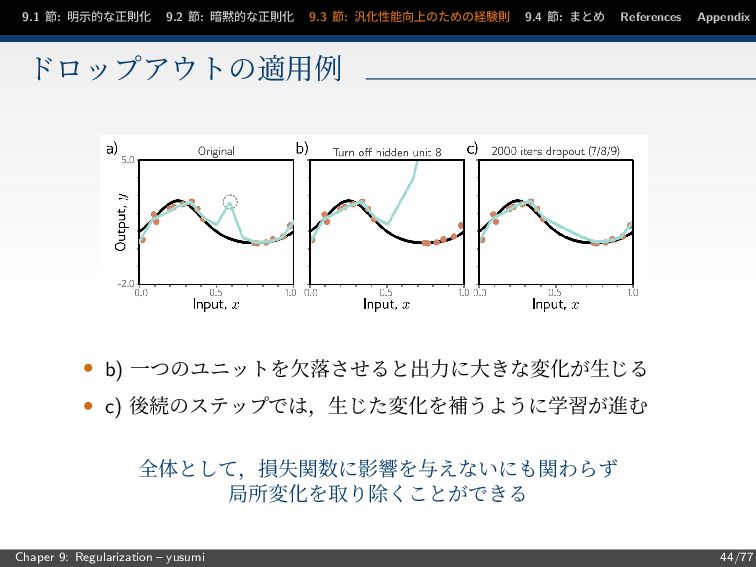
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix ドロップアウトの適用例 • b) 一つのユニットを欠落させると出力に大きな変化が生じる • c) 後続のステップでは,生じた変化を補うように学習が進む 全体として,損失関数に影響を与えないにも関わらず 局所変化を取り除くことができる Chaper 9: Regularization – yusumi 44/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 45/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3.4 節: ノイズ追加 (Applying noise) ノイズを加えてモデルを頑健にする手法 3 つの手法がある: 1 データにノイズを加える 2 重みパラメータにノイズを加える 3 ラベルにノイズを加える Chaper 9: Regularization – yusumi 46/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix データにノイズを加える手法 過学習の抑制効果 • 入出力の導関数の絶対値を正則化項として追加するのと等価 より具体的に: データにノイズを加えることにより,モデルはデータが僅かに 摂動しても頑丈な予測を行うようになる つまり,モデルが入力の微小な変化に過敏に 反応することを防ぐ効果がある Chaper 9: Regularization – yusumi 47/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
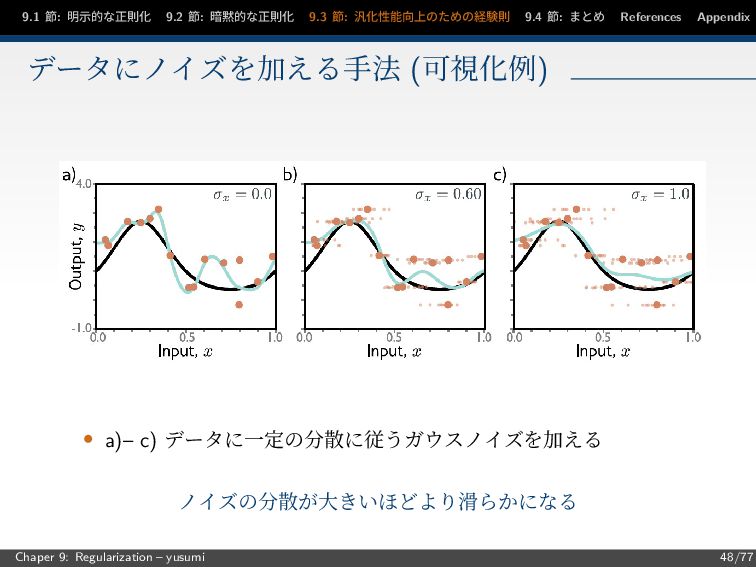
節: まとめ References Appendix データにノイズを加える手法 (可視化例) • a)– c) データに一定の分散に従うガウスノイズを加える ノイズの分散が大きいほどより滑らかになる Chaper 9: Regularization – yusumi 48/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 重みパラメータにノイズを加える手法 過学習の抑制効果 • 重みの微小摂動でも頑丈な予測をするように学習が進む • 局所最小値が広く平らな領域に収束する Chaper 9: Regularization – yusumi 49/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix ラベルにノイズを加える手法 ラベル平滑化 (Label smoothing) として広く知られた手法 過学習の抑制効果 • 多クラス分類における過剰な確信度を抑制する Chaper 9: Regularization – yusumi 50/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
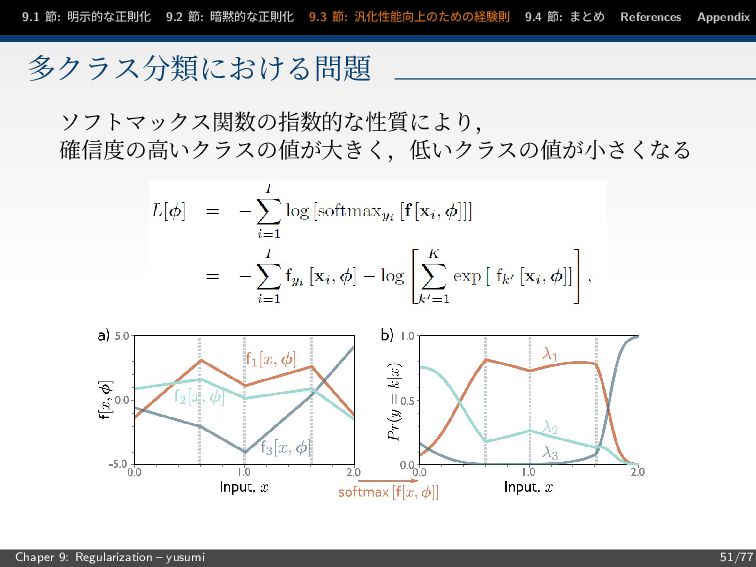
節: まとめ References Appendix 多クラス分類における問題 ソフトマックス関数の指数的な性質により, 確信度の高いクラスの値が大きく,低いクラスの値が小さくなる Chaper 9: Regularization – yusumi 51/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
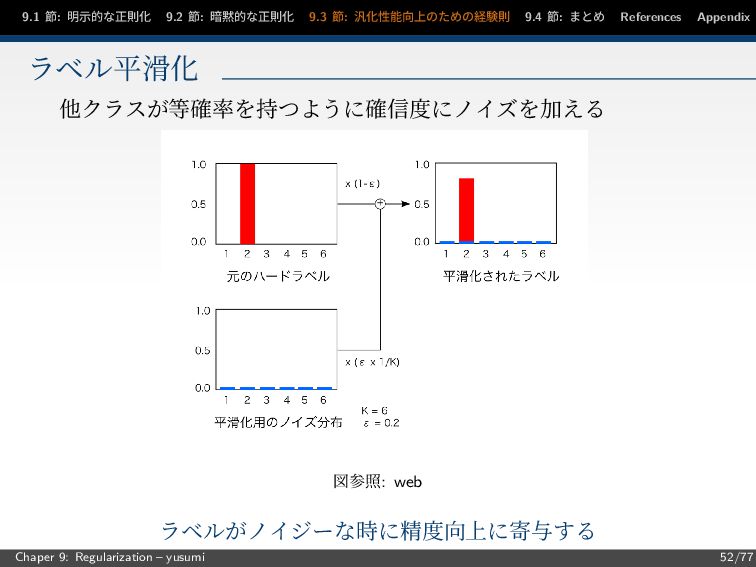
節: まとめ References Appendix ラベル平滑化 他クラスが等確率を持つように確信度にノイズを加える 図参照: web ラベルがノイジーな時に精度向上に寄与する Chaper 9: Regularization – yusumi 52/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 53/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3.5 節: ベイズ推論 (Bayesian inference) パラメータを確率変数として扱い予測する手法 過学習の抑制効果 • パラメータの不確実性を考慮できる • 複数のパラメータを平均化して予測できる Chaper 9: Regularization – yusumi 54/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
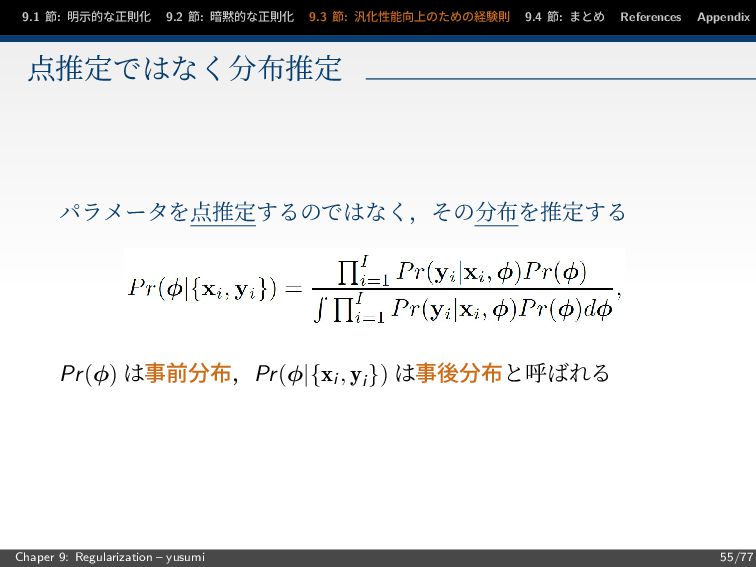
節: まとめ References Appendix 点推定ではなく分布推定 パラメータを点推定するのではなく,その分布を推定する Pr(φ) は事前分布,Pr(φ|{xi, yi }) は事後分布と呼ばれる Chaper 9: Regularization – yusumi 55/77
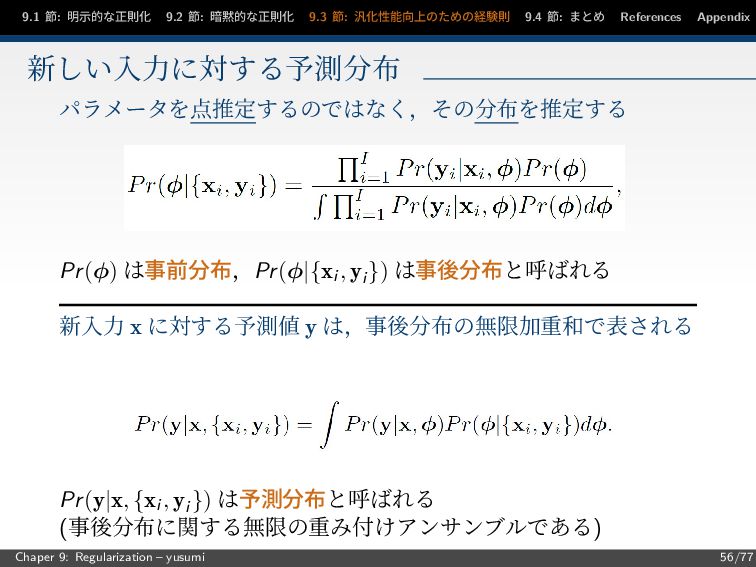
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 新しい入力に対する予測分布 パラメータを点推定するのではなく,その分布を推定する Pr(φ) は事前分布,Pr(φ|{xi, yi }) は事後分布と呼ばれる 新入力 x に対する予測値 y は,事後分布の無限加重和で表される Pr(y|x, {xi, yi }) は予測分布と呼ばれる (事後分布に関する無限の重み付けアンサンブルである) Chaper 9: Regularization – yusumi 56/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
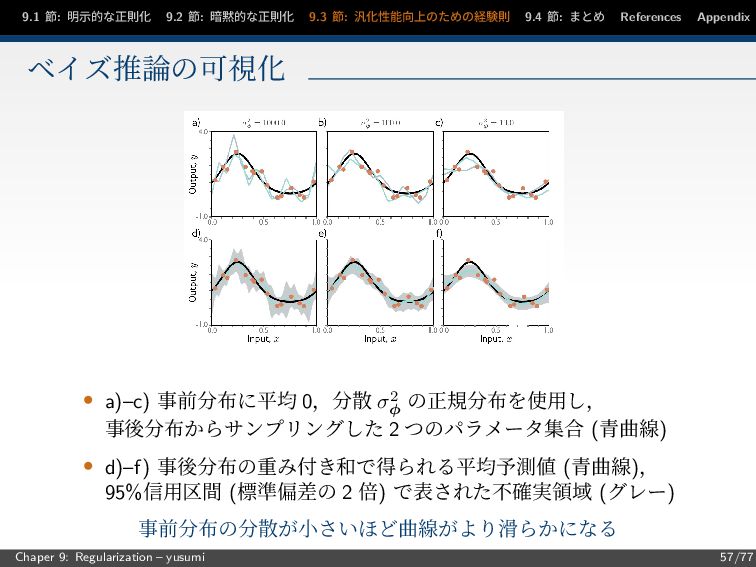
節: まとめ References Appendix ベイズ推論の可視化 • a)–c) 事前分布に平均 0,分散 σ2 φ の正規分布を使用し, 事後分布からサンプリングした 2 つのパラメータ集合 (青曲線) • d)–f) 事後分布の重み付き和で得られる平均予測値 (青曲線), 95%信用区間 (標準偏差の 2 倍) で表された不確実領域 (グレー) 事前分布の分散が小さいほど曲線がより滑らかになる Chaper 9: Regularization – yusumi 57/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 58/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3.6 節: 転移学習とマルチタスク学習 転移学習 一つのタスクに対して豊富なデータを用いて事前学習した モデルを,別の関連するタスクに転用する手法 マルチタスク学習 複数のタスクを同時に解決するように学習させる手法 Chaper 9: Regularization – yusumi 59/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
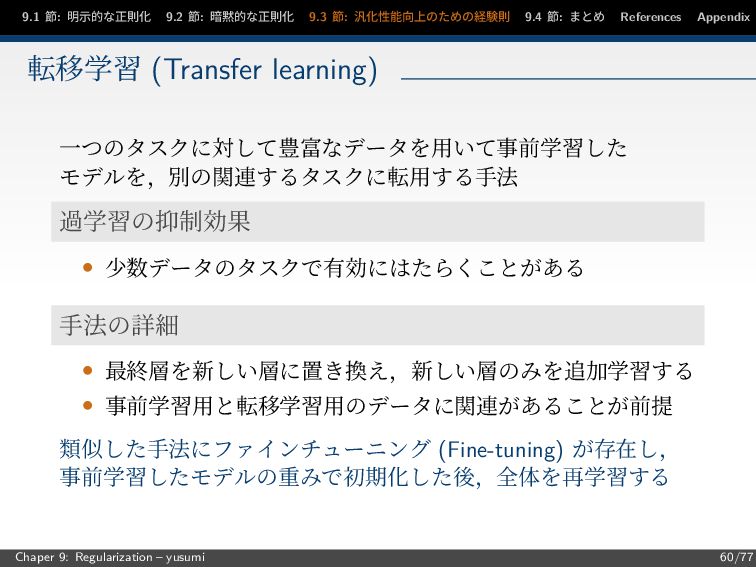
節: まとめ References Appendix 転移学習 (Transfer learning) 一つのタスクに対して豊富なデータを用いて事前学習した モデルを,別の関連するタスクに転用する手法 過学習の抑制効果 • 少数データのタスクで有効にはたらくことがある 手法の詳細 • 最終層を新しい層に置き換え,新しい層のみを追加学習する • 事前学習用と転移学習用のデータに関連があることが前提 類似した手法にファインチューニング (Fine-tuning) が存在し, 事前学習したモデルの重みで初期化した後,全体を再学習する Chaper 9: Regularization – yusumi 60/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 転移学習の適用例 例) 転移学習を用いて画像の深度推定を行うモデル 画像のセグメンテーションデータは豊富にあるが, 深度データは少ないことを前提とする 1 セグメンテーションの事前学習を行う (上側) 2 深度データで転移学習する (下側) Chaper 9: Regularization – yusumi 61/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
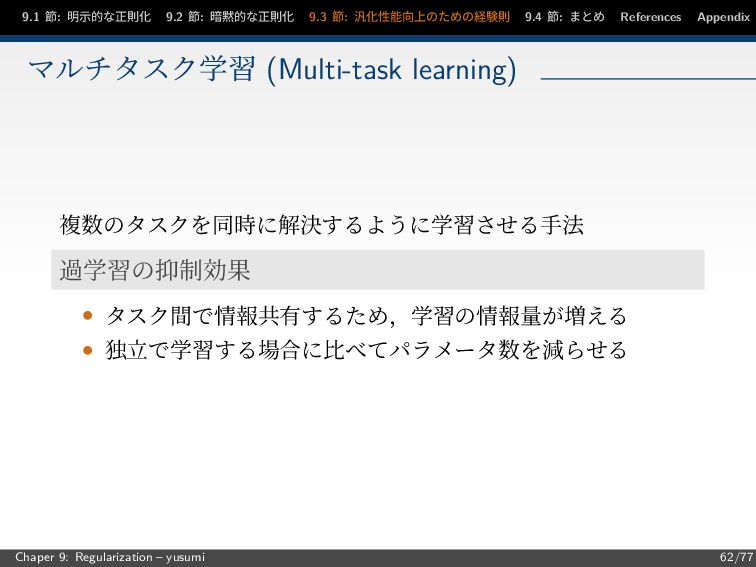
節: まとめ References Appendix マルチタスク学習 (Multi-task learning) 複数のタスクを同時に解決するように学習させる手法 過学習の抑制効果 • タスク間で情報共有するため,学習の情報量が増える • 独立で学習する場合に比べてパラメータ数を減らせる Chaper 9: Regularization – yusumi 62/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
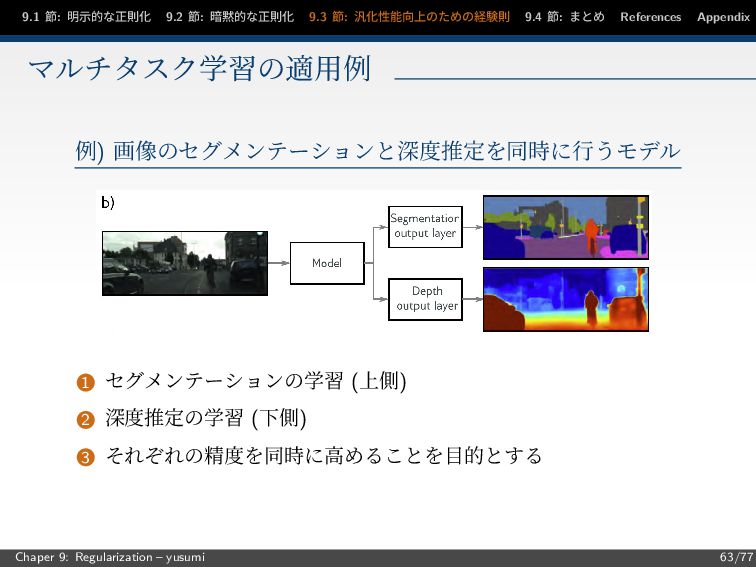
節: まとめ References Appendix マルチタスク学習の適用例 例) 画像のセグメンテーションと深度推定を同時に行うモデル 1 セグメンテーションの学習 (上側) 2 深度推定の学習 (下側) 3 それぞれの精度を同時に高めることを目的とする Chaper 9: Regularization – yusumi 63/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 64/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3.7 節: 自己教師あり学習 (Self-supervised learning) 大量の自由なラベル付きデータを生成し転移学習に利用する手法 過学習の抑制効果 • 大量のデータ利用を前提とするためノイズの反応を抑制する 生成的手法と対照的手法の二種類が存在する Chaper 9: Regularization – yusumi 65/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
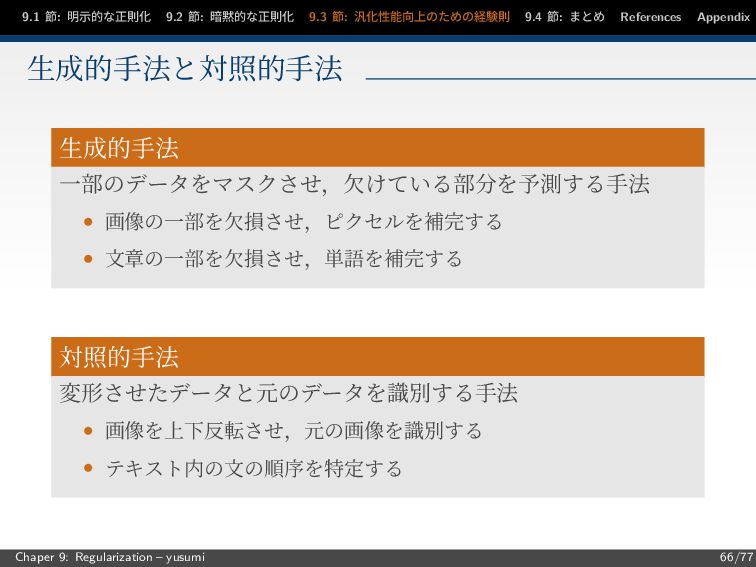
節: まとめ References Appendix 生成的手法と対照的手法 生成的手法 一部のデータをマスクさせ,欠けている部分を予測する手法 • 画像の一部を欠損させ,ピクセルを補完する • 文章の一部を欠損させ,単語を補完する 対照的手法 変形させたデータと元のデータを識別する手法 • 画像を上下反転させ,元の画像を識別する • テキスト内の文の順序を特定する Chaper 9: Regularization – yusumi 66/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
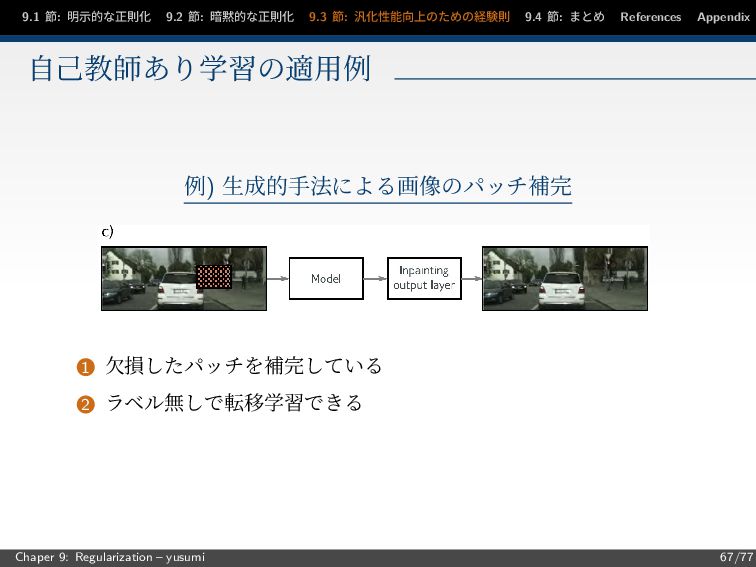
節: まとめ References Appendix 自己教師あり学習の適用例 例) 生成的手法による画像のパッチ補完 1 欠損したパッチを補完している 2 ラベル無しで転移学習できる Chaper 9: Regularization – yusumi 67/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 汎化性能向上のための経験則 過学習を防ぐその他の経験的手法について紹介する 1 9.3.1 節: 早期終了 2 9.3.2 節: アンサンブル 3 9.3.3 節: ドロップアウト 4 9.3.4 節: ノイズ追加 5 9.3.5 節: ベイズ推論 6 9.3.6 節: 転移学習とマルチタスク学習 7 9.3.7 節: 自己教師あり学習 8 9.3.8 節: データ拡張 Chaper 9: Regularization – yusumi 68/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.3.8 節: データ拡張 (Augmentation) 各入力データをラベルが同じ状態で変形する手法 過学習の抑制効果 • データの変化に頑丈になる • データ量が増大する Chaper 9: Regularization – yusumi 69/77
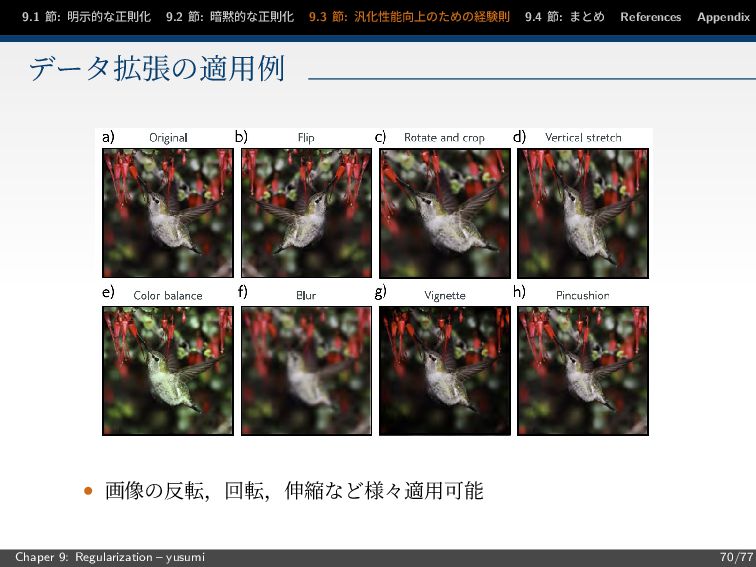
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix データ拡張の適用例 • 画像の反転,回転,伸縮など様々適用可能 Chaper 9: Regularization – yusumi 70/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 9.4 節: まとめ Chaper 9: Regularization – yusumi 71/77
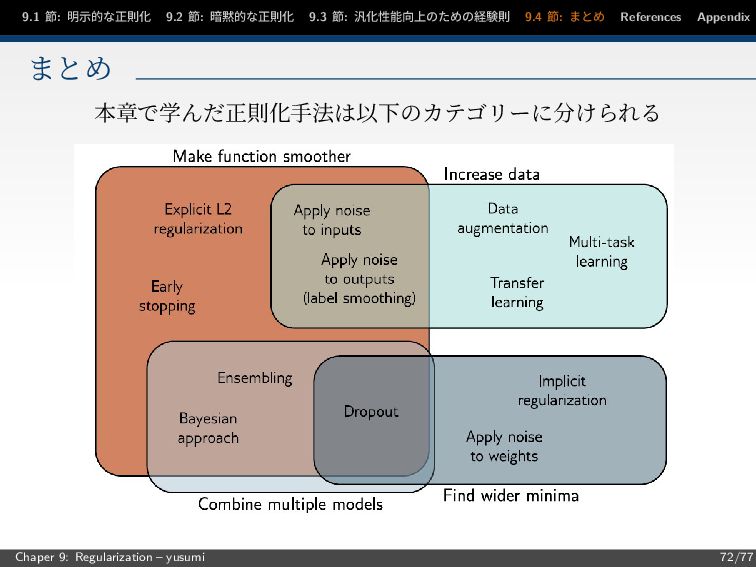
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix まとめ 本章で学んだ正則化手法は以下のカテゴリーに分けられる Chaper 9: Regularization – yusumi 72/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 参考文献 I [1] Simon J.D. Prince. Understanding Deep Learning. MIT Press, 2023. URL https://udlbook.github.io/udlbook/. [2] ラベル平滑化 (label smoothing) による正則化. URL https://cvml-expertguide.net/terms/dl/ regularization/label-smoothing/. Chaper 9: Regularization – yusumi 73/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix Appendix Chaper 9: Regularization – yusumi 74/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 勾配降下法における暗黙的正則化 (数式証明) 離散版の勾配降下法は以下で表現できる: 学習率を α → 0 に近づければ,連続版と等価になる: 離散版で近似するなら,テーラー展開を用いる: Chaper 9: Regularization – yusumi 75/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 勾配降下法における暗黙的正則化 (数式証明) 初期パラメータ φ0 の周りの二次のテーラー展開を考える: Chaper 9: Regularization – yusumi 76/77
9.1 節: 明示的な正則化 9.2 節: 暗黙的な正則化 9.3 節: 汎化性能向上のための経験則 9.4
節: まとめ References Appendix 勾配降下法における暗黙的正則化 (数式証明) 最初の離散版の式と合わせるには,第 3 項を 0 にすればよい: 以上から,連続版を離散版の一次の項で近似すると次式になる: これをパラメータで積分すると暗黙的正則化項が現れる: Chaper 9: Regularization – yusumi 77/77
![Chapter 9: Regularization Understanding deep learning, Prince [2023] yusumi](https://files.speakerdeck.com/presentations/a5b111458958472fa291346d9fcebba1/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}