otherwise noted, this presentation is licensed under the Creative Commons Attribution 4.0 International License. Third party marks and brands are the property of their respective holders.
are based on the corresponding slides of Mario Wolczko about Memory Management: ▪ Memory management part 1 ▪ Memory management part 2 ▪ Memory management debugging hints
Binding of name to memory address at compile/link time ▪ All sizes are fixed, i.e., known at compile time ▪ No stack allocation ▪ Used in early FORTRAN, BASIC, and various languages for embedded/real-time systems
Pros – No runtime overheads for allocation/de-allocation – Memory requirements known at compile time – No failures due to lack of memory ▪ Cons – Need to allocate and keep the maximum possible memory footprint for the whole program execution – No recursion due to lack of stack allocation
stack) ▪ Languages (at least most of them) are based on procedures ▪ LIFO/Depth-First invocation order (in most cases) – See Scheme and Smalltalk for counter-examples ▪ Memory used by procedures can be managed as a stack – Allocate on invocation – Release on return ▪ Hardware support (SP register, call/ret instr.) since the 1960s
stack) ▪ Pros – Low runtime overheads – Bump stack pointer for allocation – Bulk de-allocation on return – No memory leaks ▪ Cons – Names passed as parameters, the deeper a procedure is invoked the more parameters it gets – Cannot return memory to previous procedures – Data-lifetime equals the procedure’s lifetime – Can’t handle complex data structures like graphs
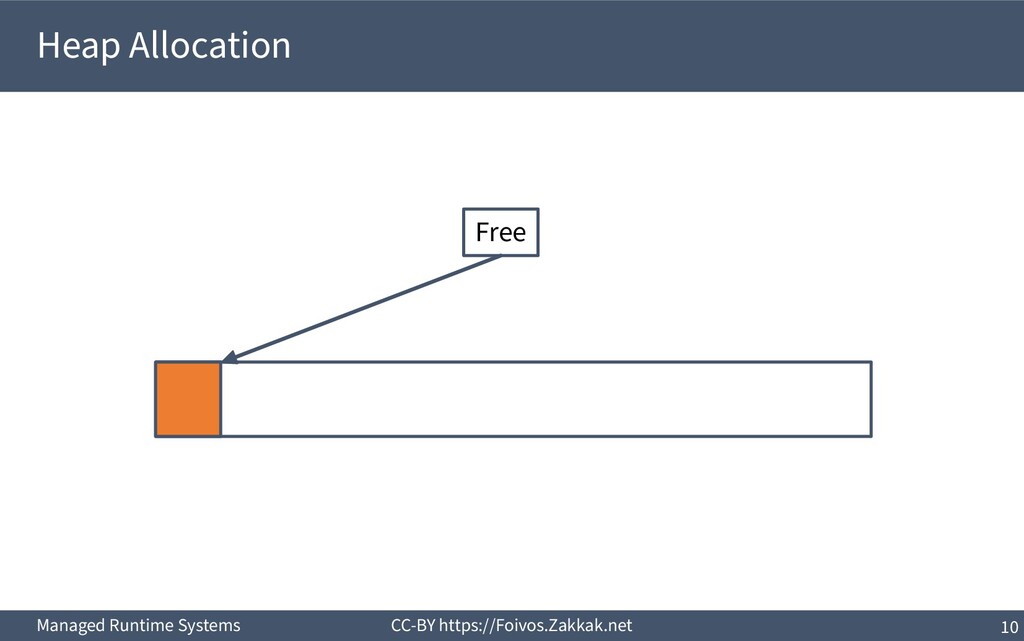
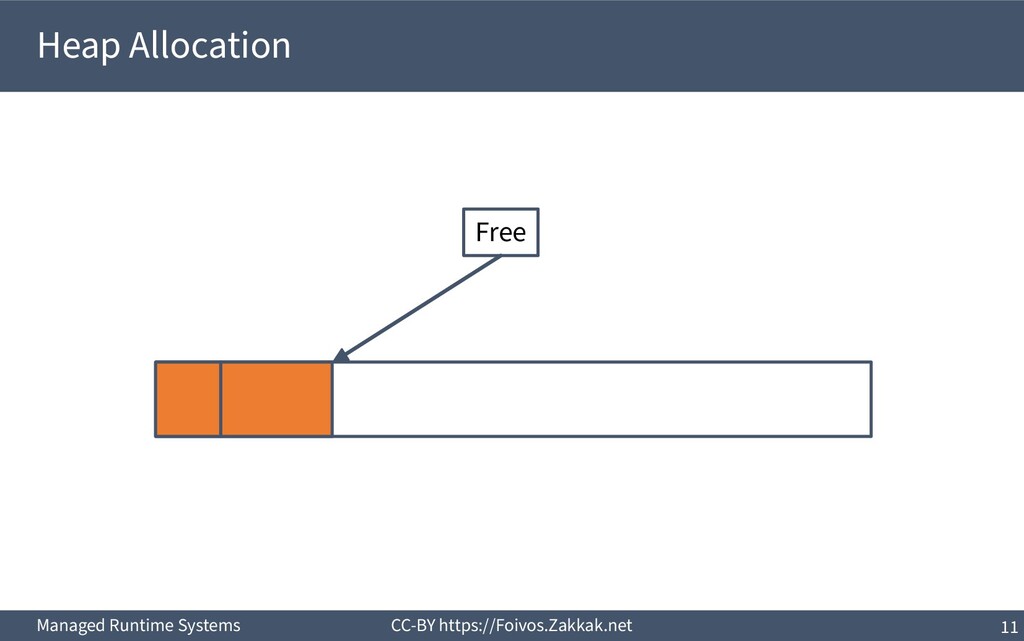
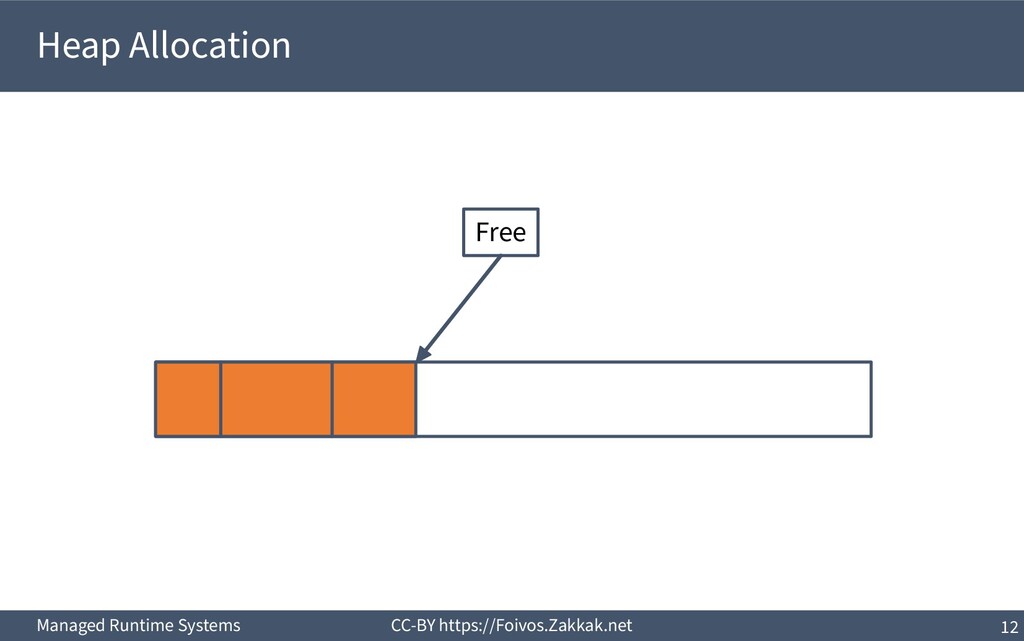
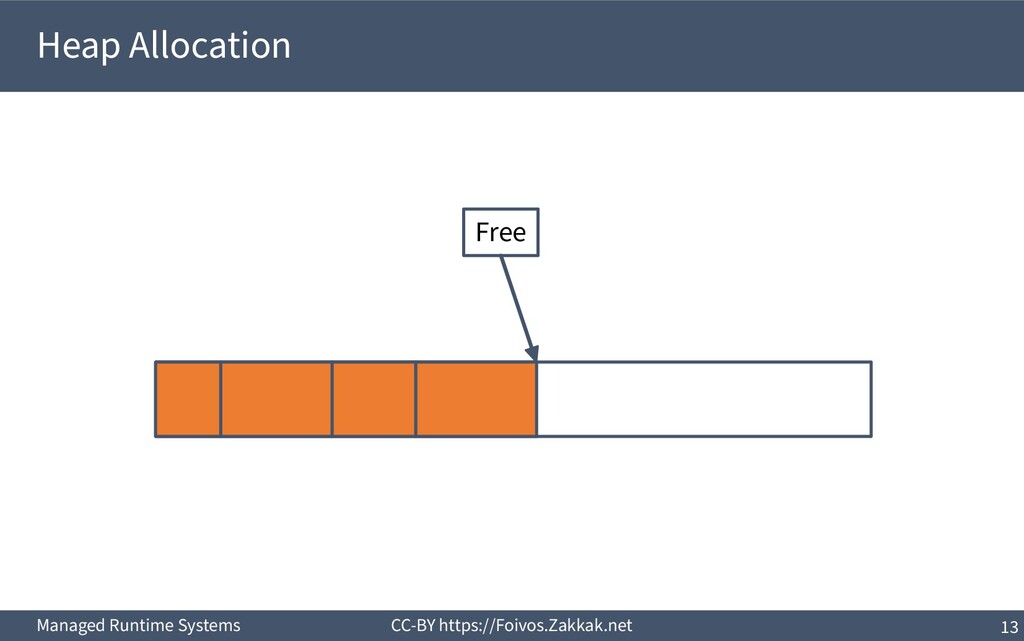
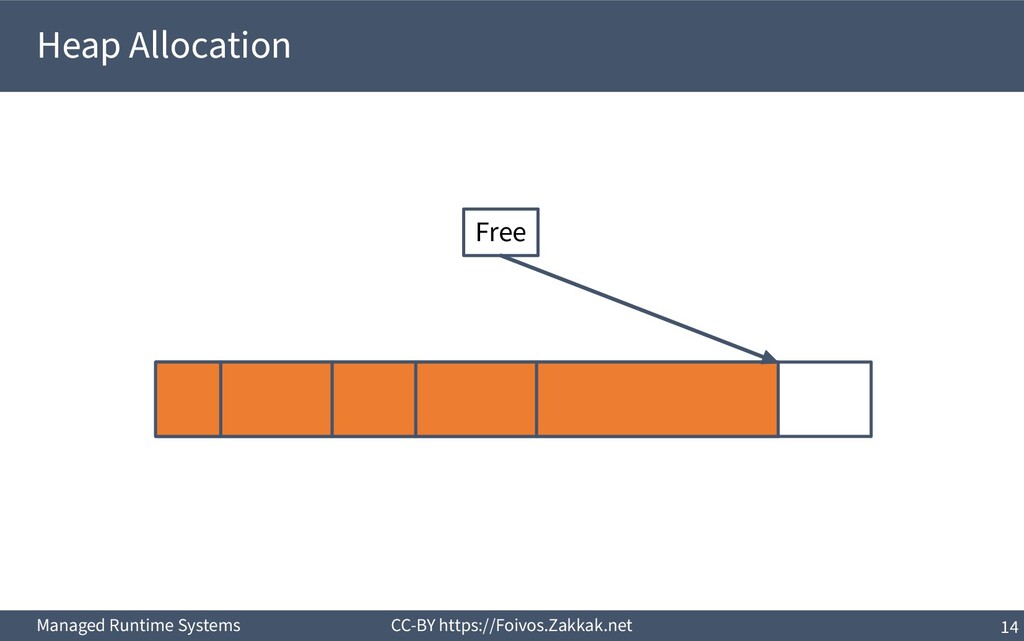
heap) ▪ Pros – Arbitrary allocation sizes – Allocation and de-allocation from different procedures – Handling of complex data structures ▪ Cons – Noticeable runtime overheads – Need to perform a de-allocation for each allocation ▪ See region-based allocation for an enhancement – Memory leaks are possible
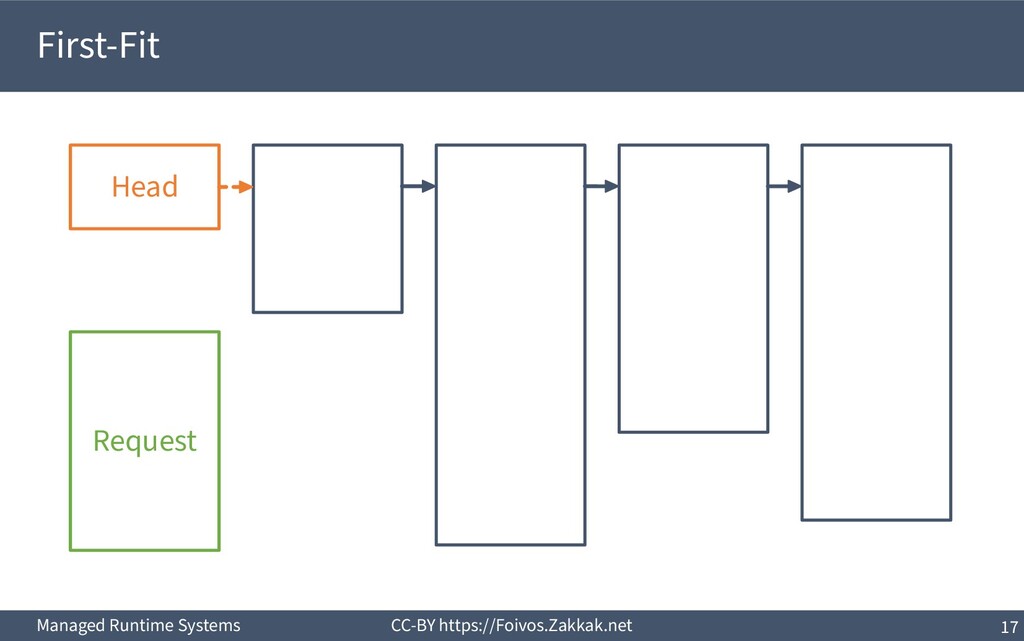
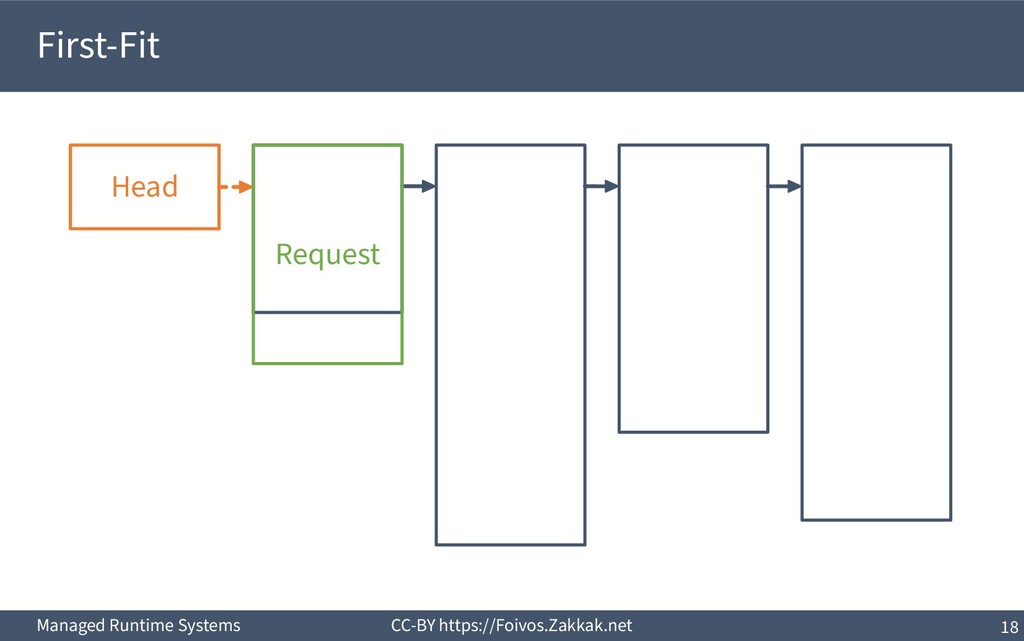
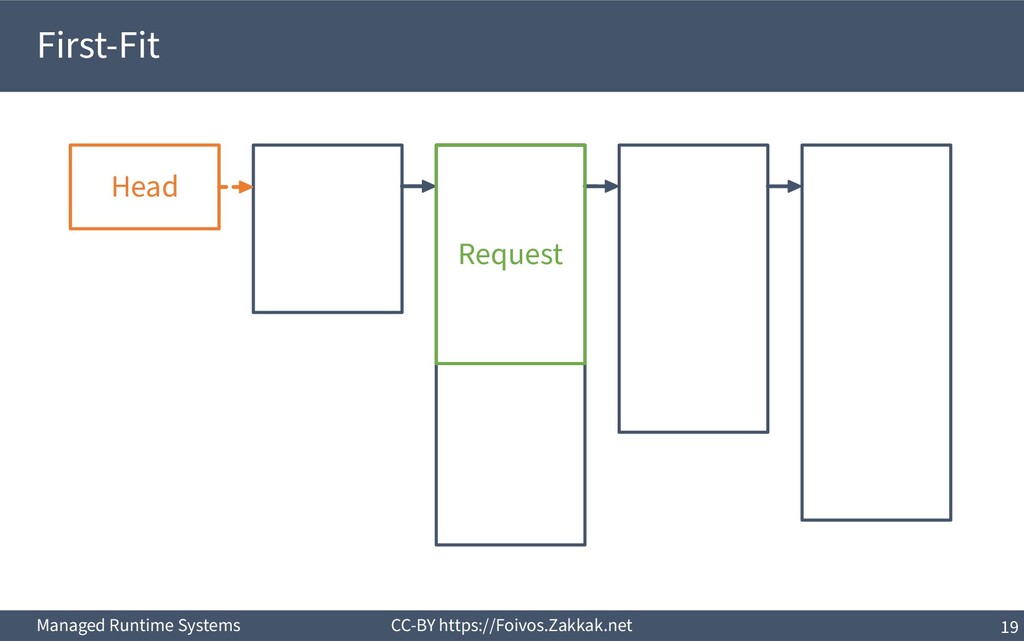
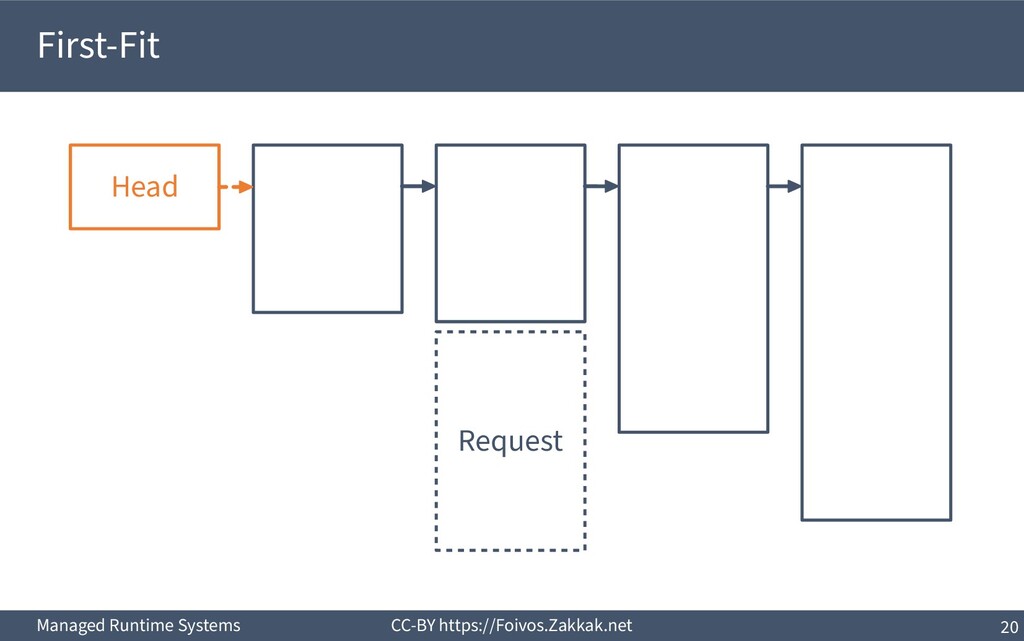
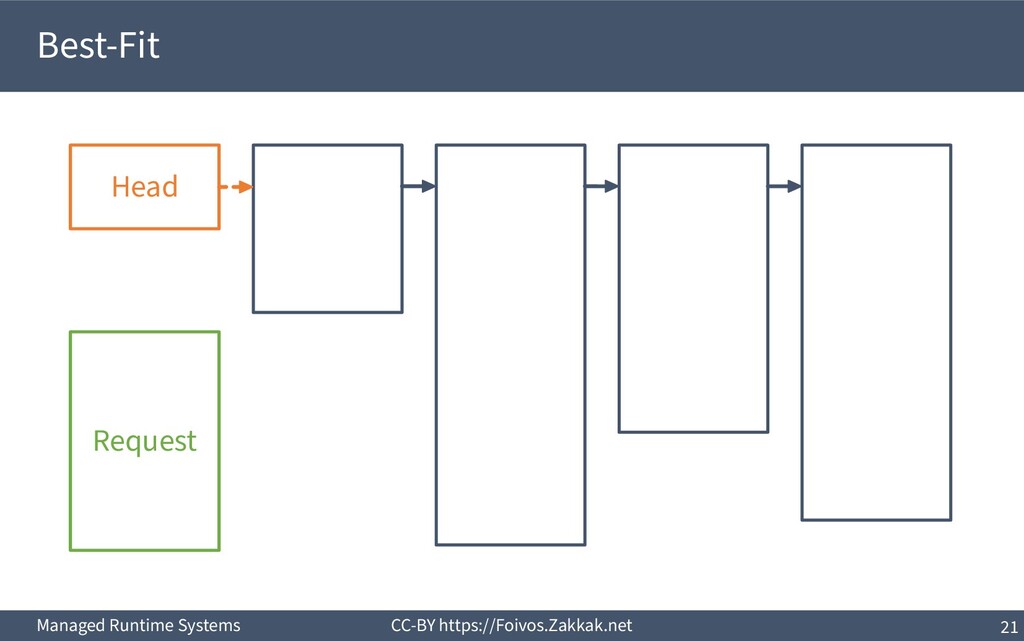
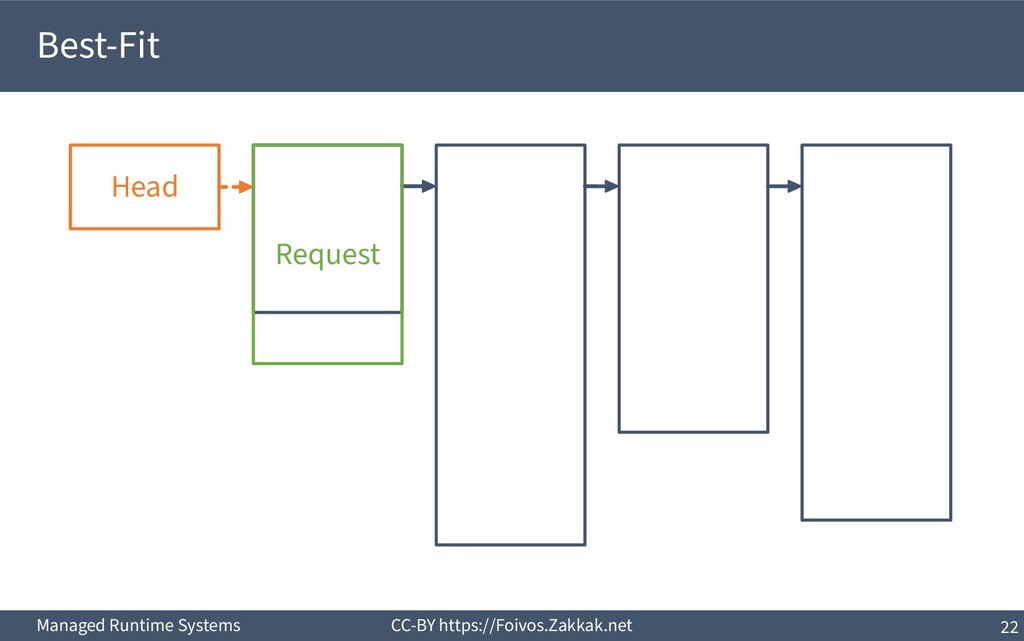
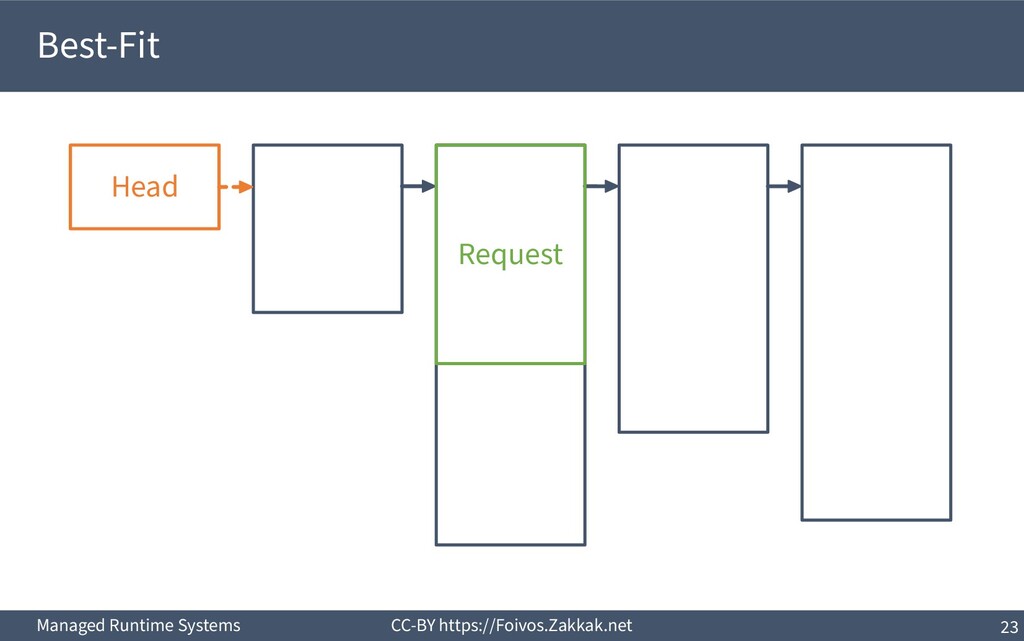
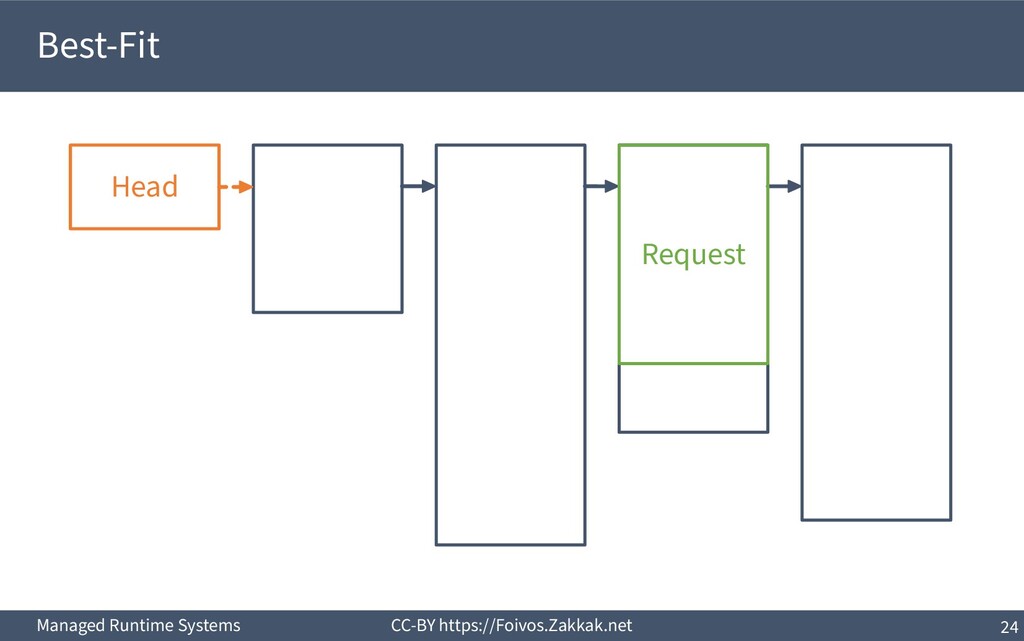
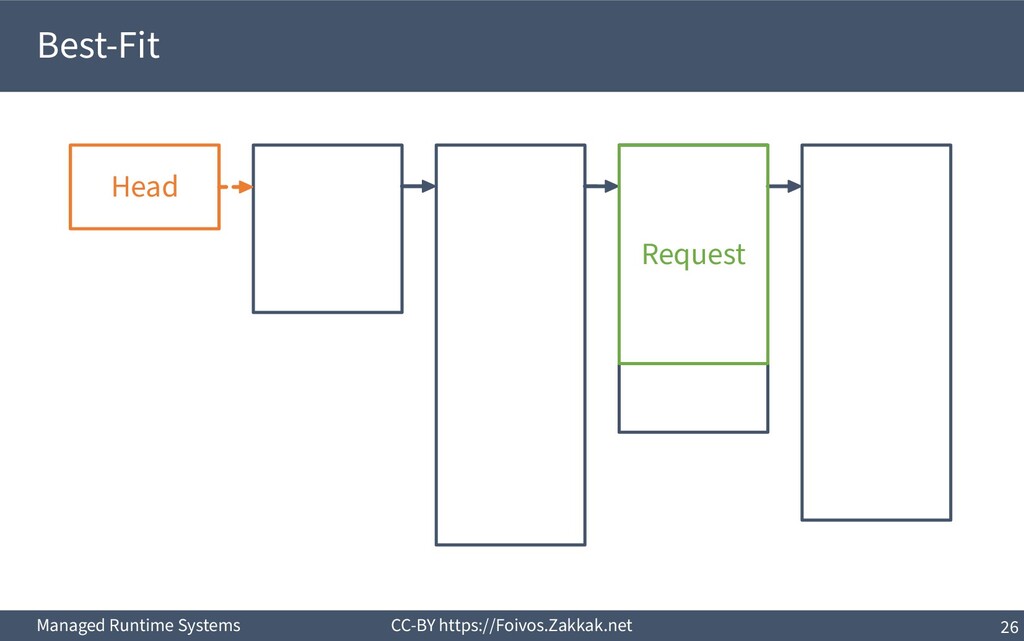
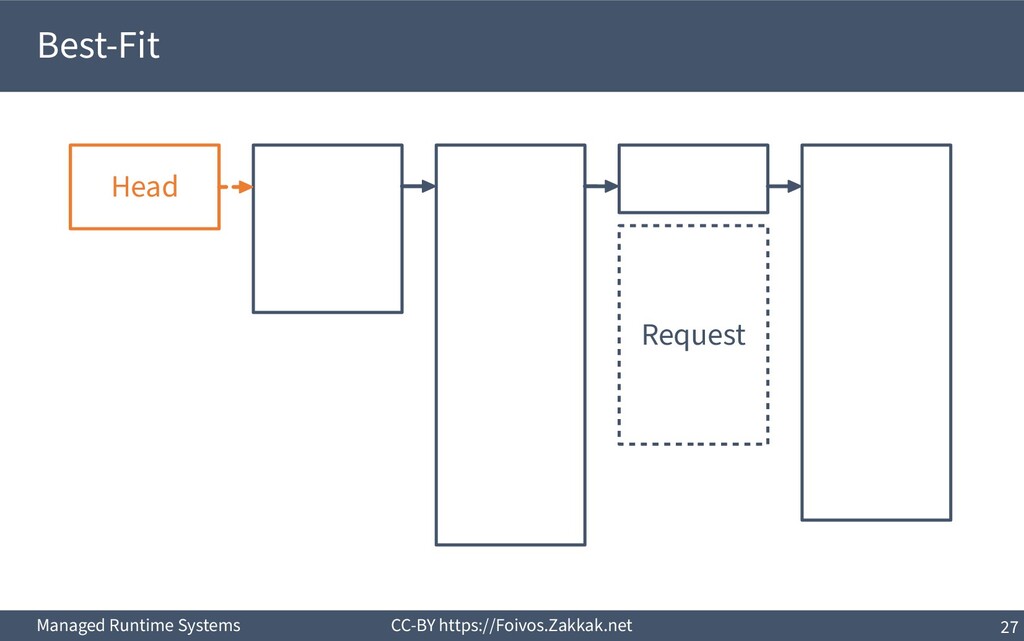
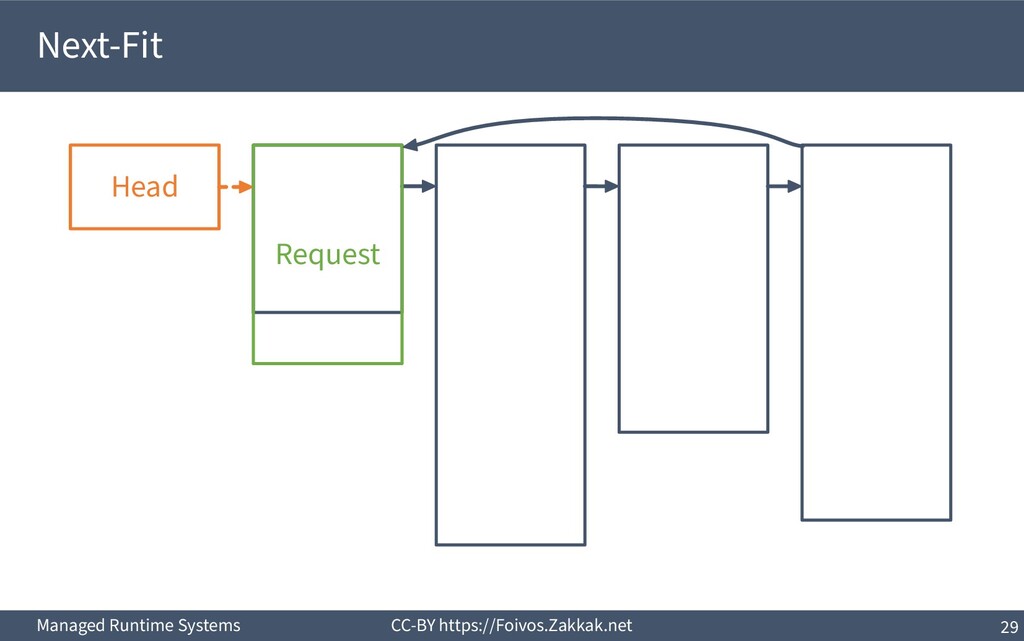
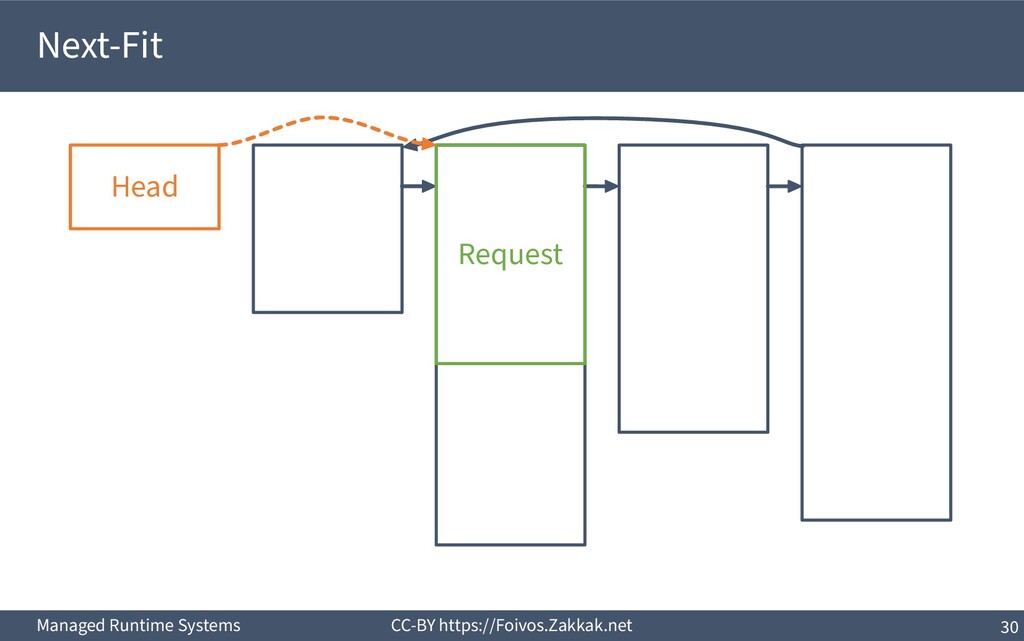
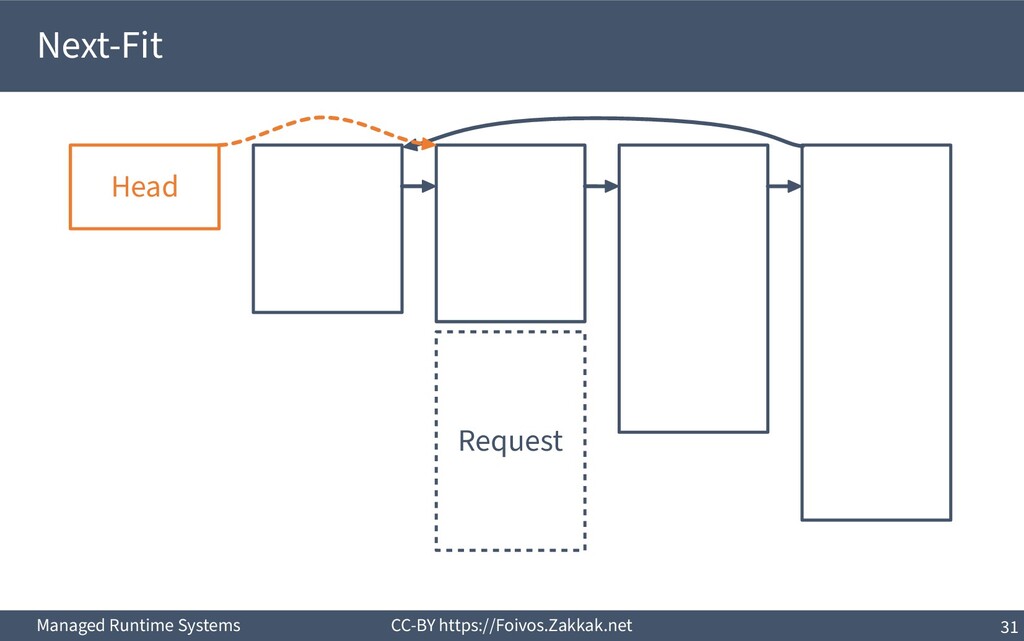
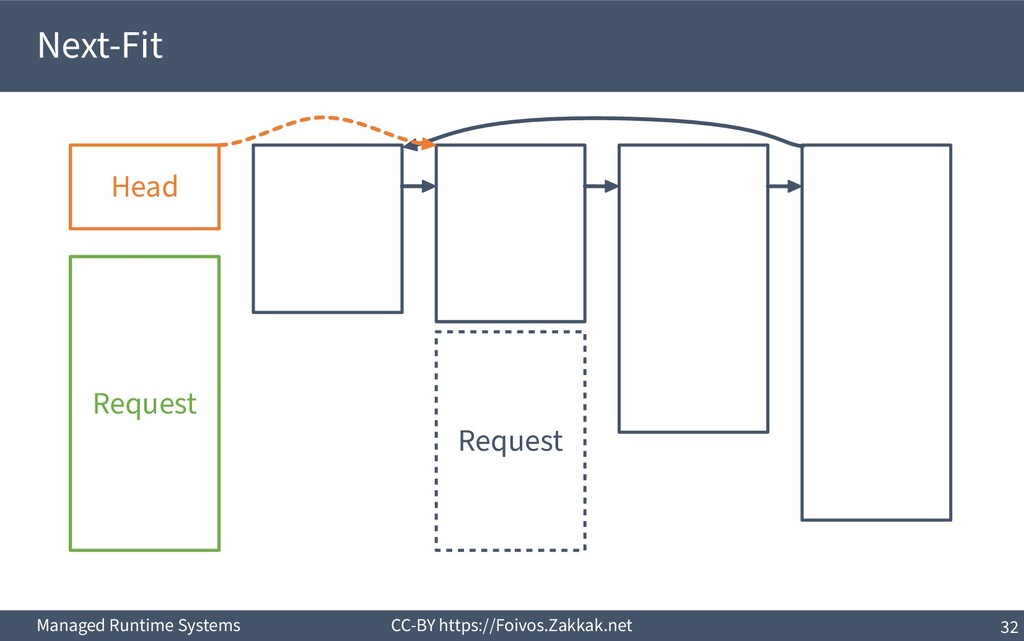
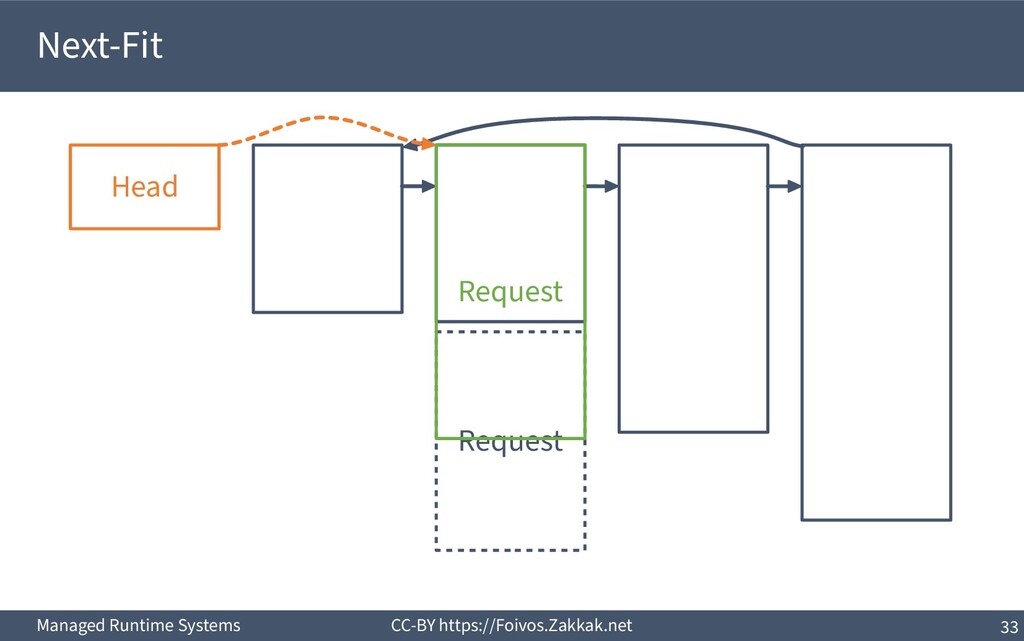
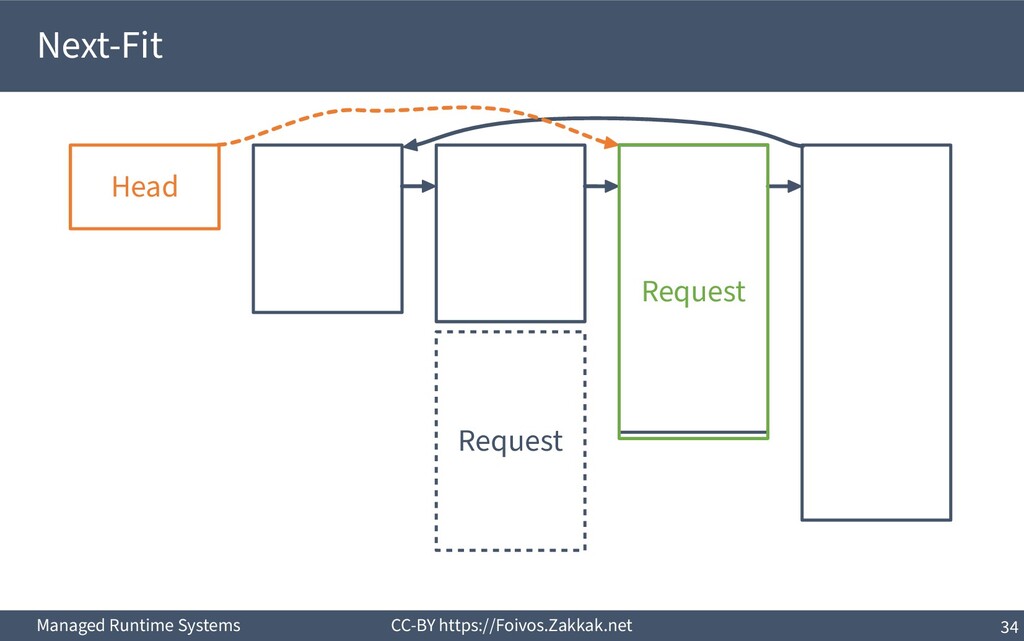
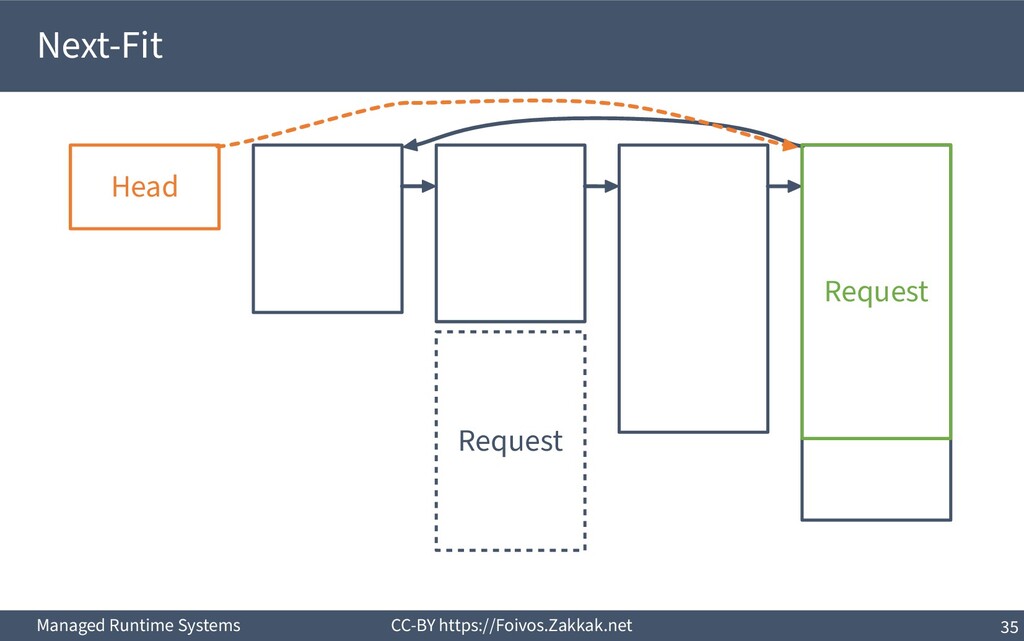
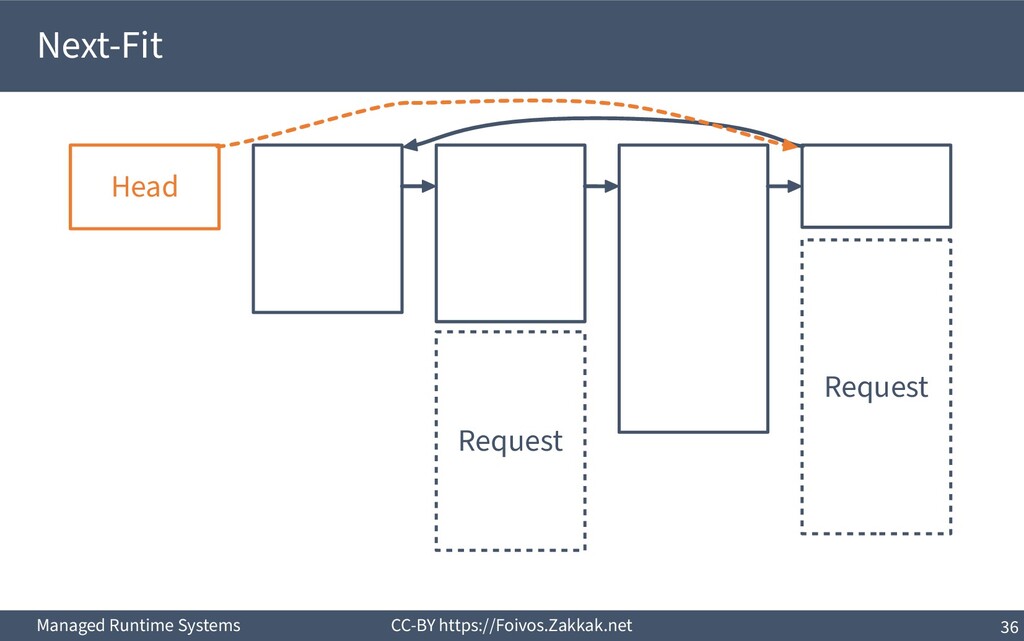
▪ First-Fit: – Search free-list from the beginning, peek first block that fits – Add the remaining of the block (if any) as a new block to the list – May result in a number of small blocks at beginning of free-list ▪ Best-Fit: – Search free-list from the beginning, peek the block that best fits – Add the remaining of the block (if any) as a new block to the list – Reduces fragmentation – Slow since we need to traverse the whole free-list ▪ Next-Fit: – Search from where we stopped last time, peek the block that best fits – Add the remaining of the block (if any) as a new block to the list – Might increase fragmentation – Often faster than First-fit
the phenomenon of not being able to use parts of memory because of inefficient management ▪ A heavily fragmented system may have plenty of free memory, but chopped in small blocks that don’t fit a new request
Fragmentation is the result of allocating larger chunks than actually needed (often due to alignment restrictions) ▪ External Fragmentation is the result of constantly splitting free blocks, resulting in multiple small non-contiguous free blocks that cannot be used
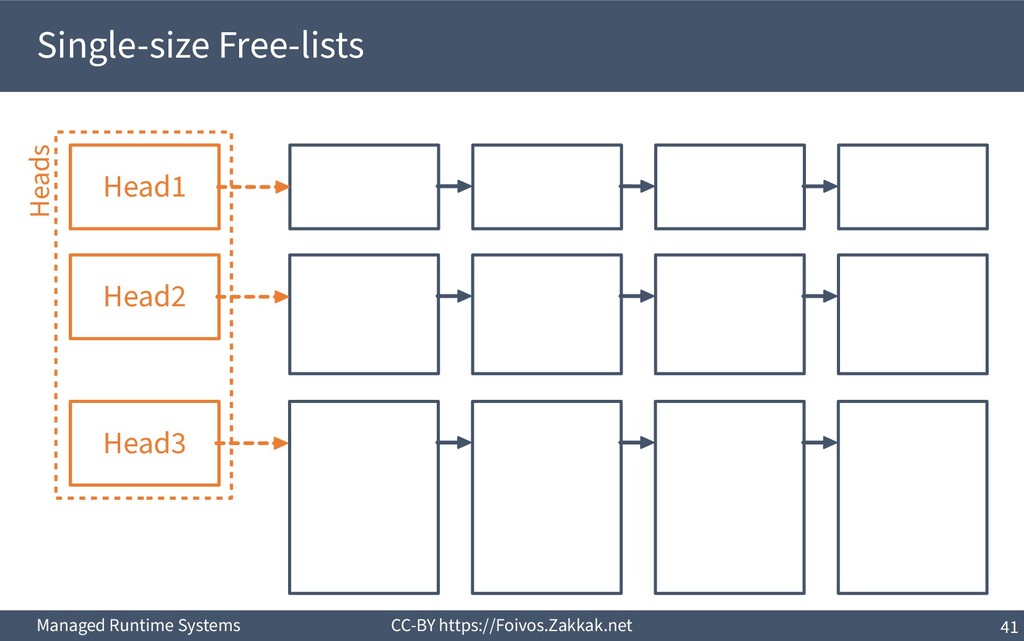
set of free-lists, one for each size (for a set of common sizes) 2) A generic free-list for the rest 3) Always peek the first block from the list of the desired size 4) If empty take a block from the generic one and split it
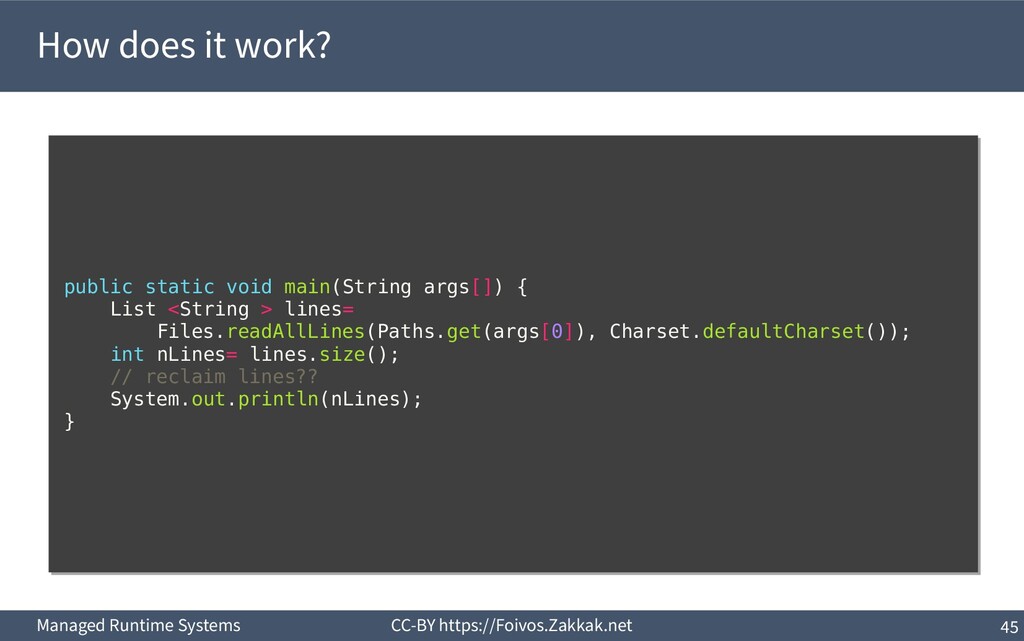
programming, no need to argue about object lifetimes 2) Eliminate errors due to dangling pointers 3) Take care of the previous issues 4) Still possible to leak memory!
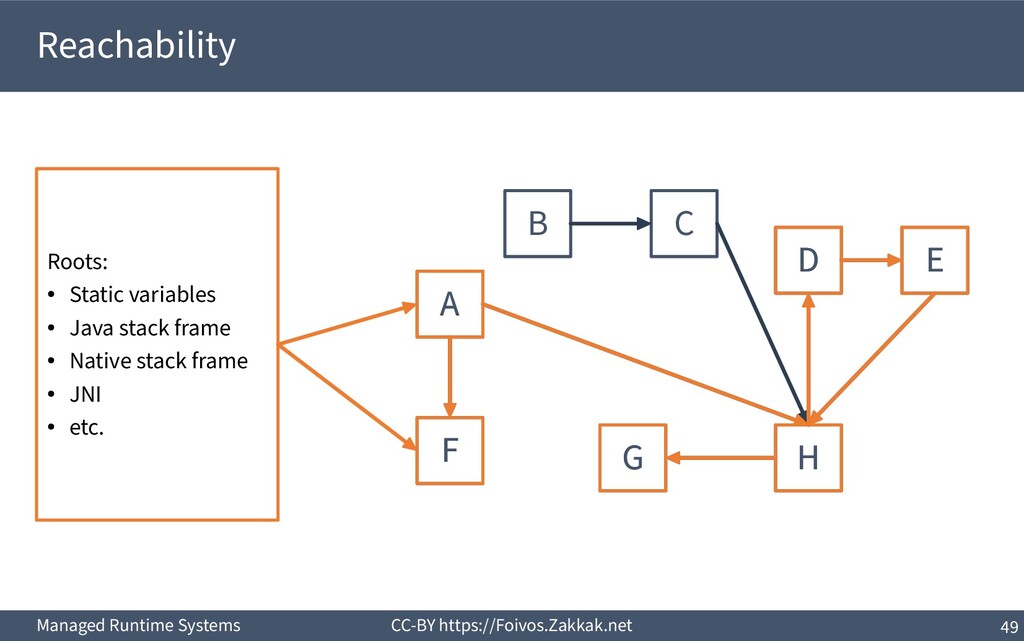
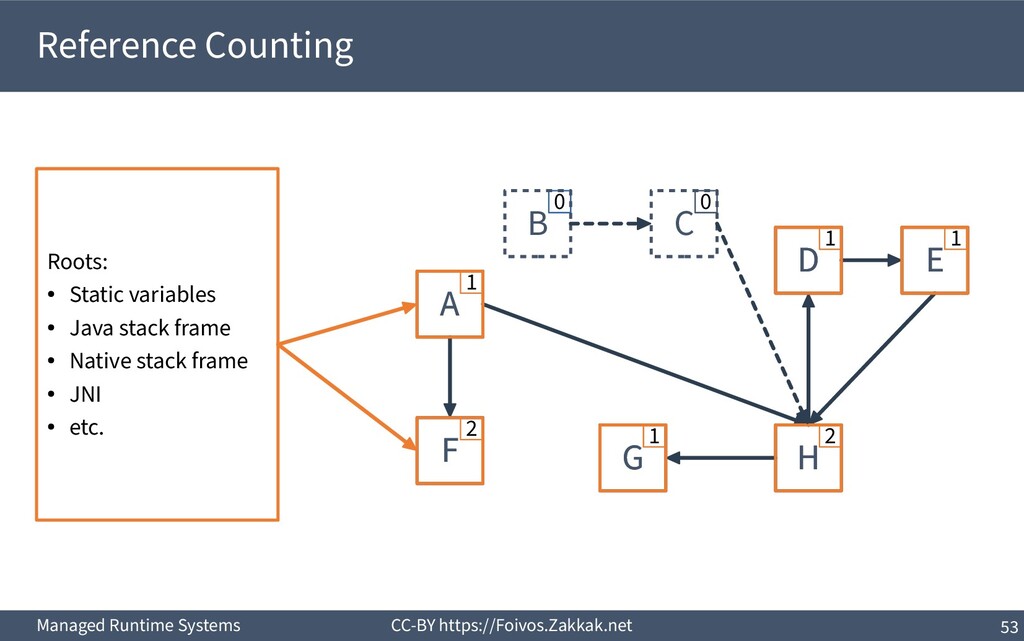
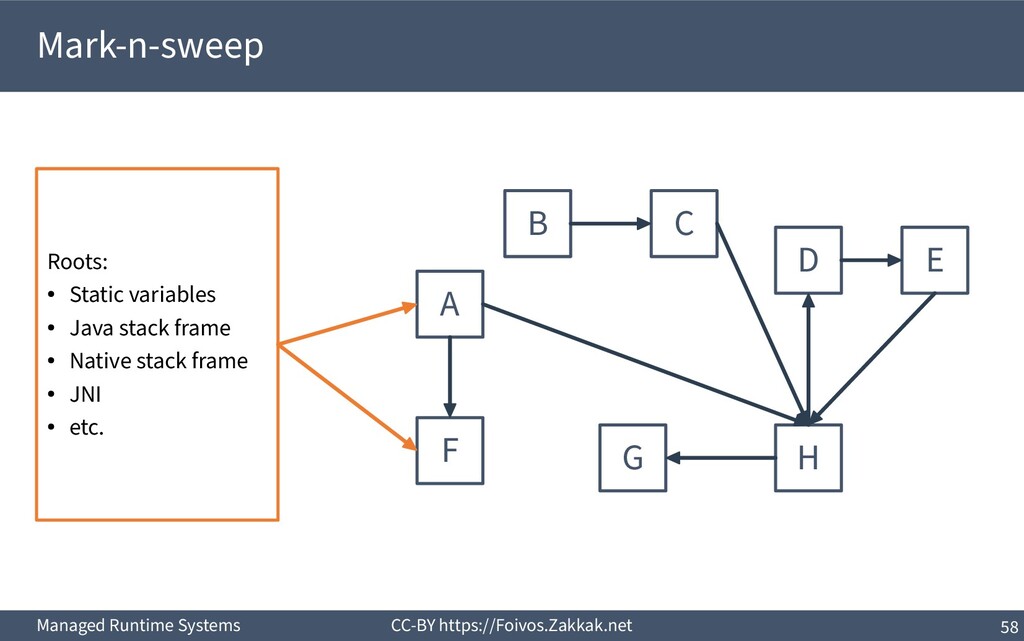
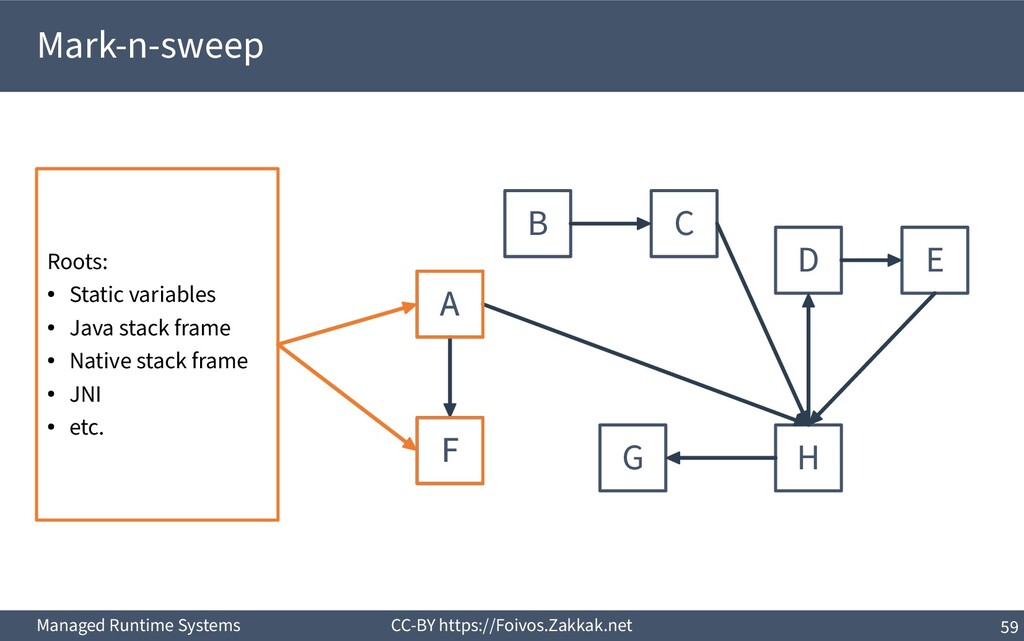
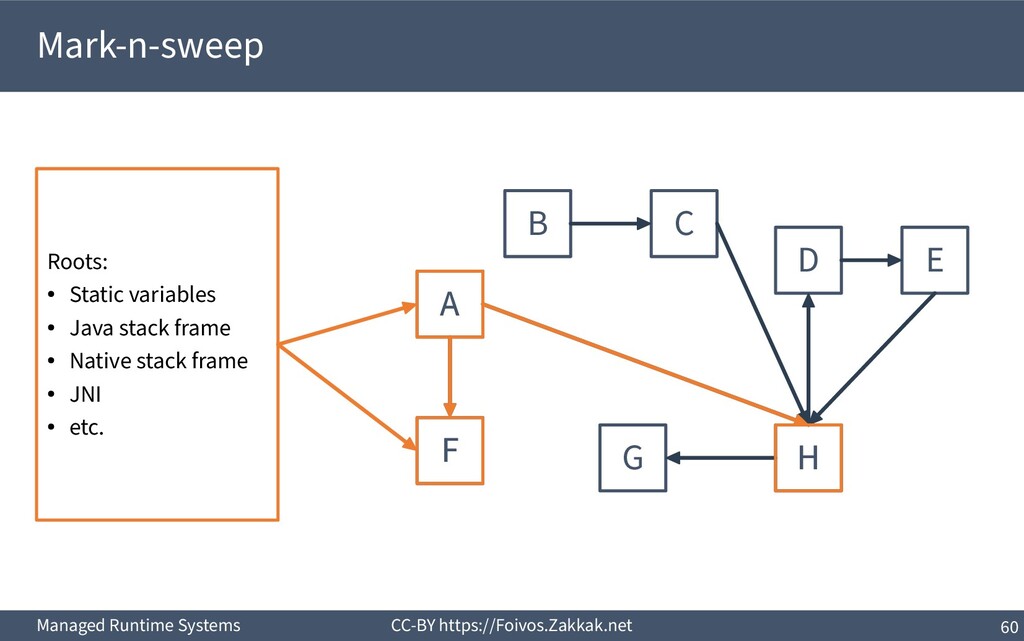
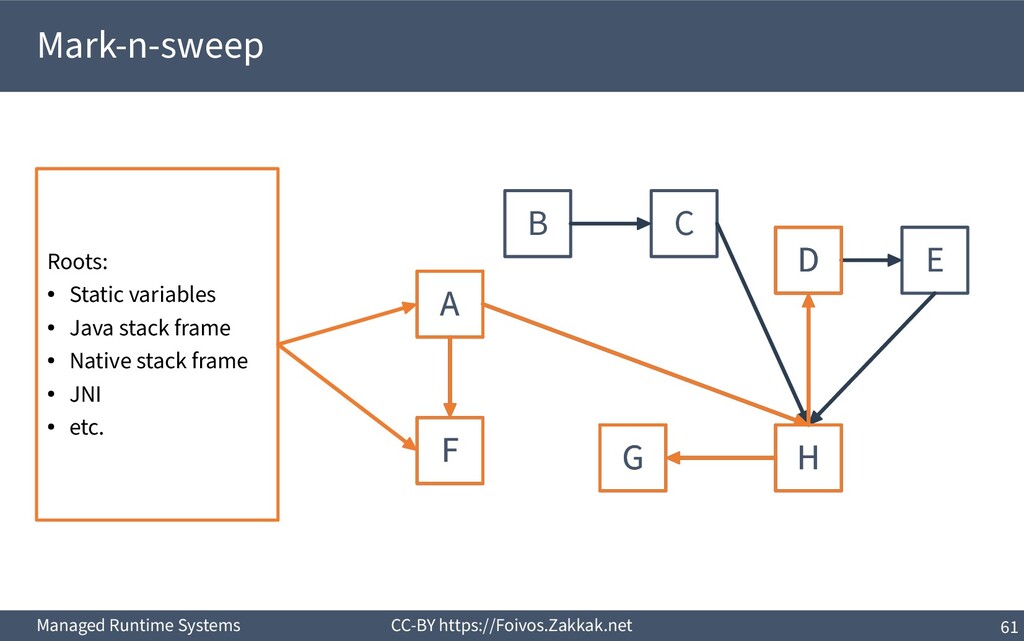
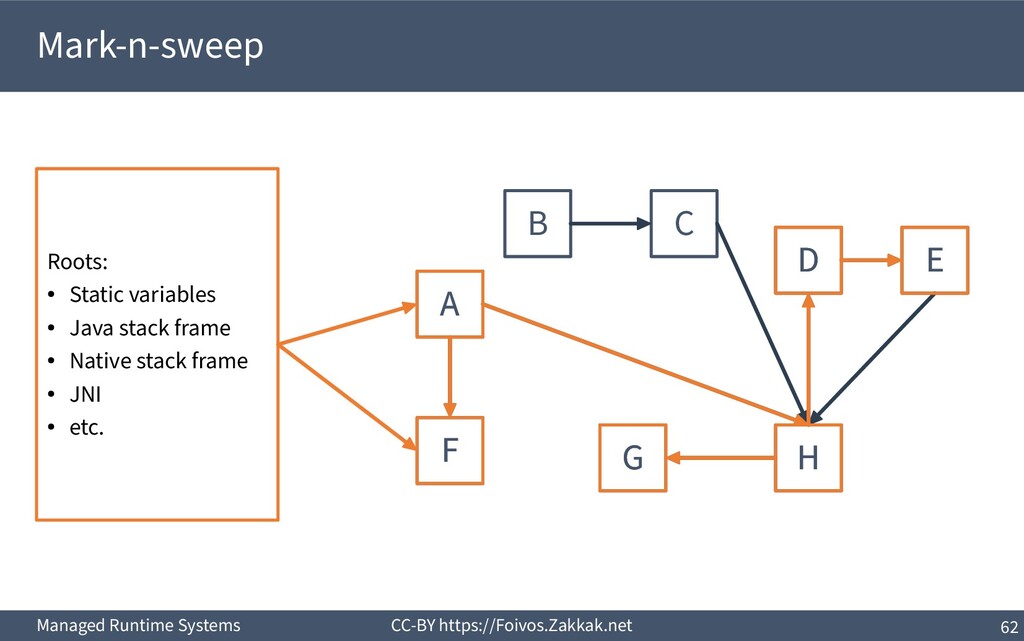
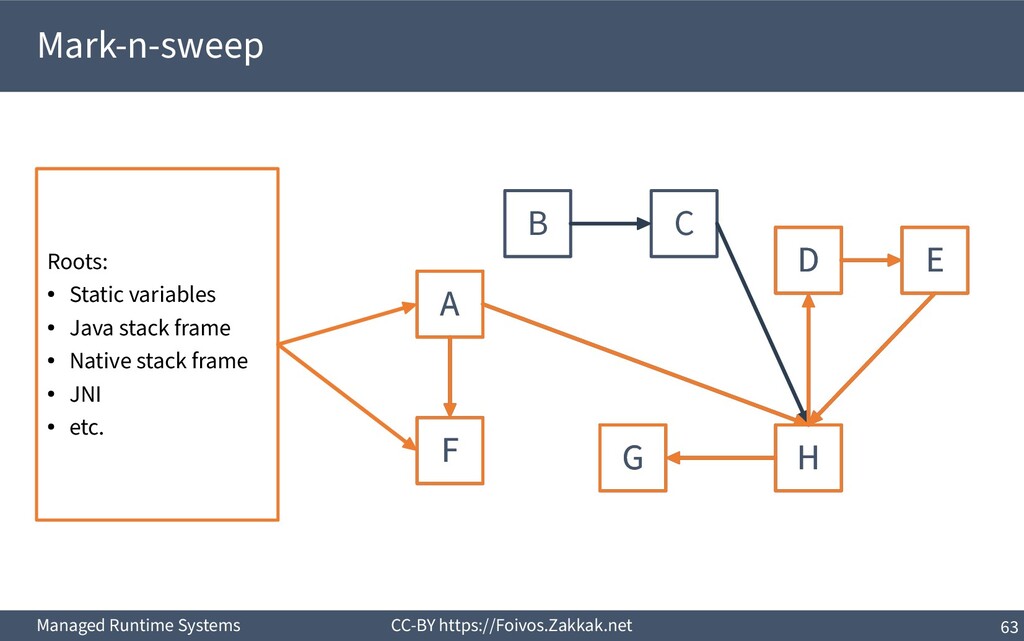
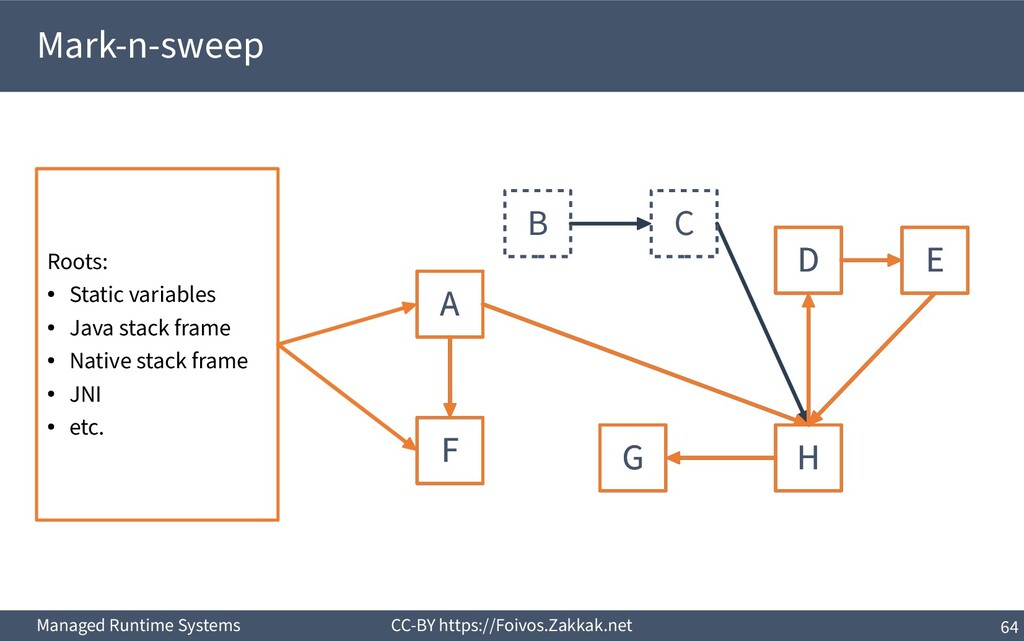
World ▪ An object is dead when it is no longer reachable – Reachable is an object that can be reached by following pointers starting from the system’s roots – The system’s roots are all the variables in scope (of all threads) – Requires traversal of stacks and globals
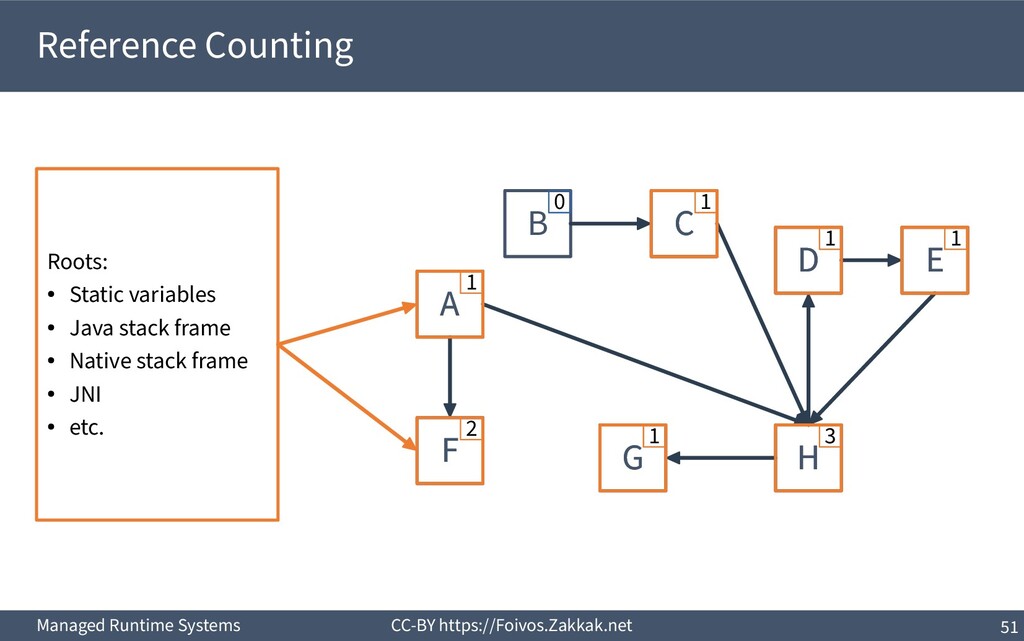
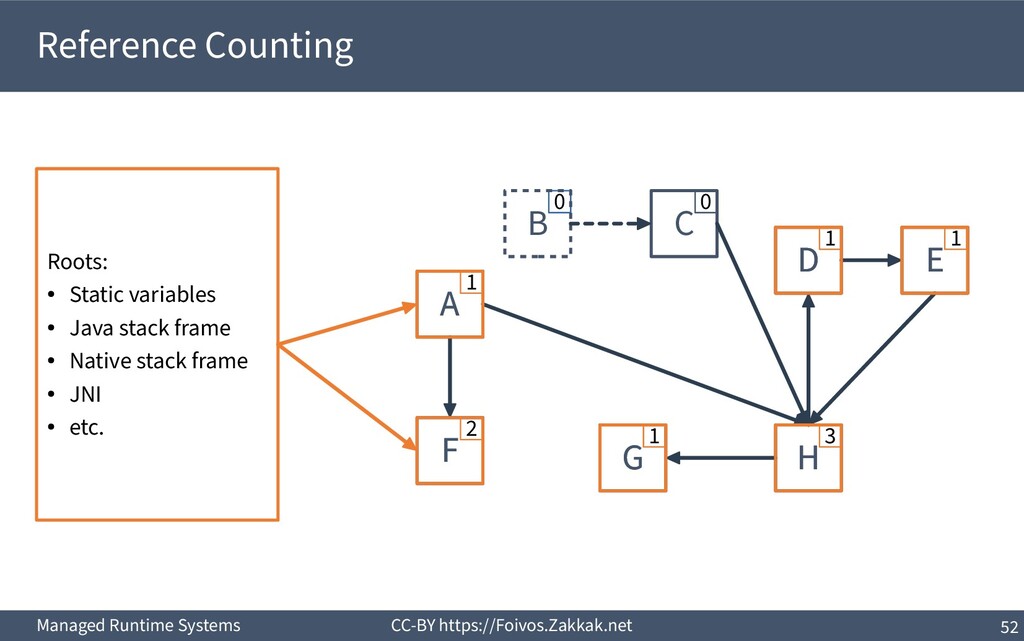
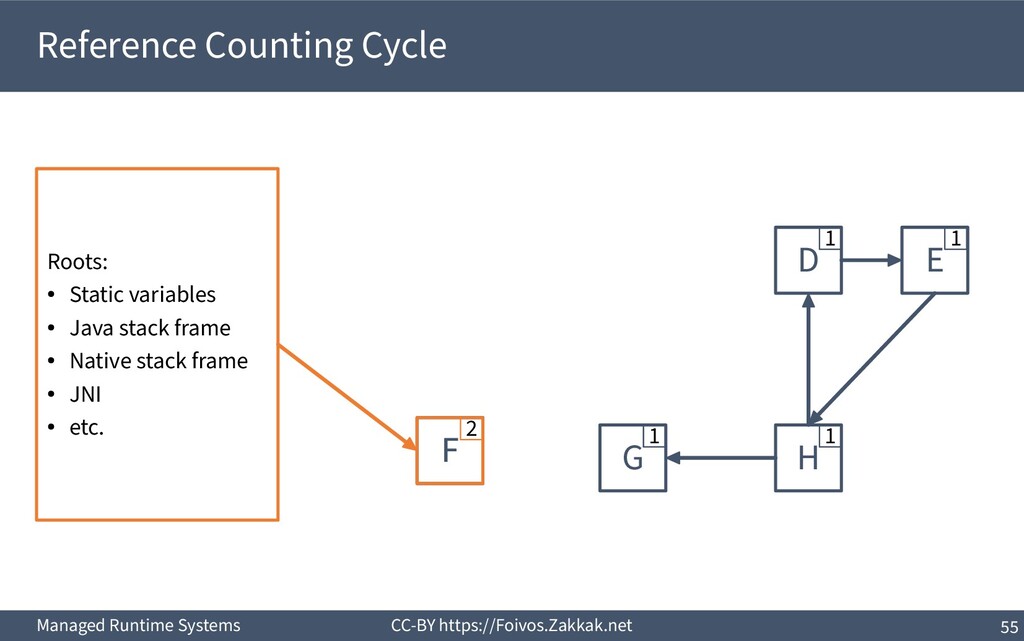
a reference counter per object ▪ Increment it when a reference to that object is assigned to a variable ▪ Decrement it when a reference to that object is overwritten ▪ If the counter is zero, the object can be reclaimed
Reference counting has to be performed on all variables (stack, global, and heap) 2) References in an activation record have to be decremented before de-allocating the frame upon return 3) Decrementing the reference counter often incurs a cache miss 4) Decrementing the reference counter always incurs a write 5) Concurrent threads might contend on the reference counter 6) Cannot reclaim cycles
Worst case each object creates an activation (i.e., marking a single linked-list) ▪ Work queue: Each object creates a new node in the queue – Dominant approach in parallel garbage collectors
Add reclaimed chunks to a free-list ▪ Requires parsing the whole heap to find the non-marked objects – Possible (using the object headers), but inefficient ▪ Coalescing adjacent free blocks
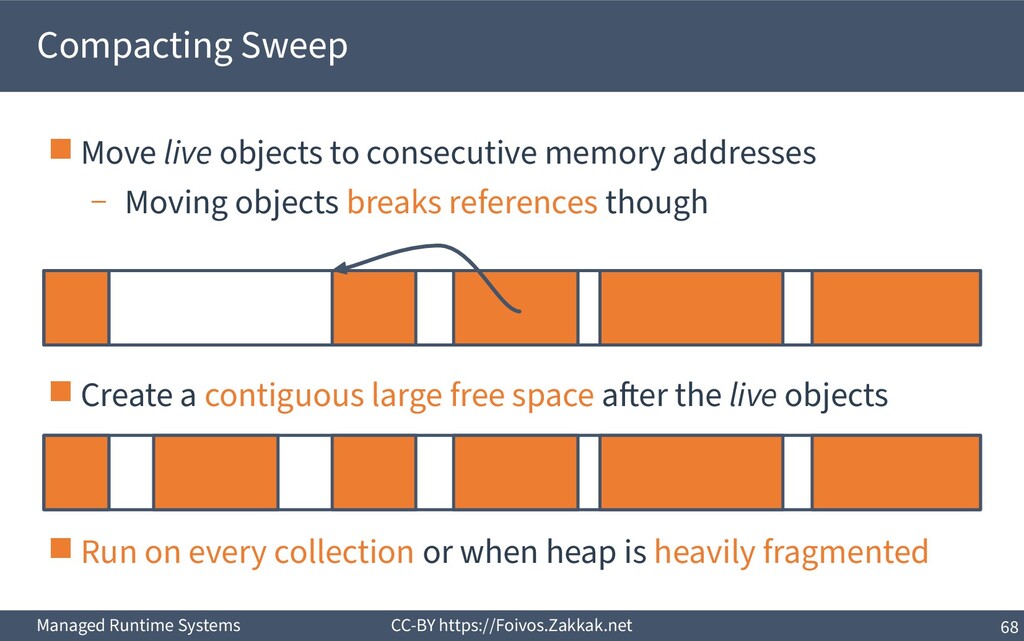
live objects to consecutive memory addresses – Moving objects breaks references though ▪ Create a contiguous large free space after the live objects ▪ Run on every collection or when heap is heavily fragmented
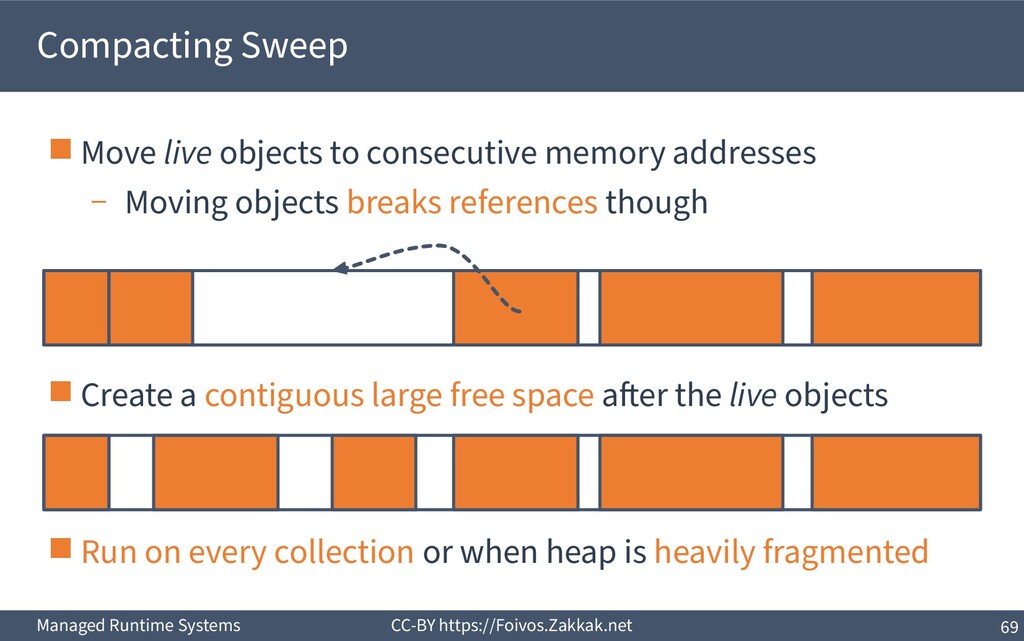
live objects to consecutive memory addresses – Moving objects breaks references though ▪ Create a contiguous large free space after the live objects ▪ Run on every collection or when heap is heavily fragmented
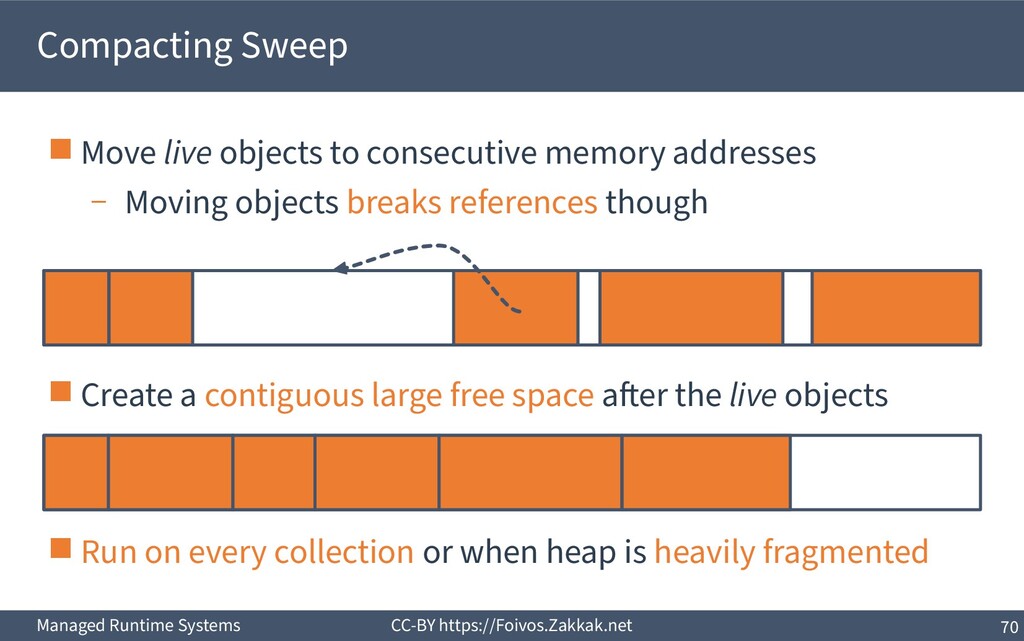
live objects to consecutive memory addresses – Moving objects breaks references though ▪ Create a contiguous large free space after the live objects ▪ Run on every collection or when heap is heavily fragmented
Pointers Add an extra field in each object’s header – the forwarding pointer 1) Compute forwarding pointers 2) Update all pointers using the forwarding pointers 3) Move the objects
Table ▪ Instead of using a forwarding pointer replace actual header with pointer to a temporary table entry ▪ Each temporary table entry holds a header and a forwarding location
1) Replace the object header with a pointer to a list 2) This starts from the object and goes through all the fields that reference it 3) The last field in the list contains the initial content of the object header 4) When the object is moved the list is traversed to update the corresponding fields
of Trace and Compaction Split heap memory in from and to semi-spaces Copy live objects on trace to to semi-space Leave forwarding pointers in from semi-space At the end, from becomes to and vice versa
– Bump allocation – Traverse only live objects – Can be used by parallel GCs – Increase locality? ▪ Cons – Requires twice the memory (at least during collection) – Copies the whole heap in each collection
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}