A brief look at Nomad (https://www.nomadproject.io/), created by Hashicorp for the scalable deployment and scheduling of applications, which is part of their toolset which makes the DevOps lives much easier.
Also a look at the basics of a 'Nomad Simulator' project, which allows to simulate a cluster in-memory, presenting it to Nomad as if they were real machines, then run Nomad jobs on them, and retrieve statistics regarding the scheduling process, which together with a separate visualizer tailored specificly for the output of this simulator were part of a software engineering internship project at Hooklift, Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
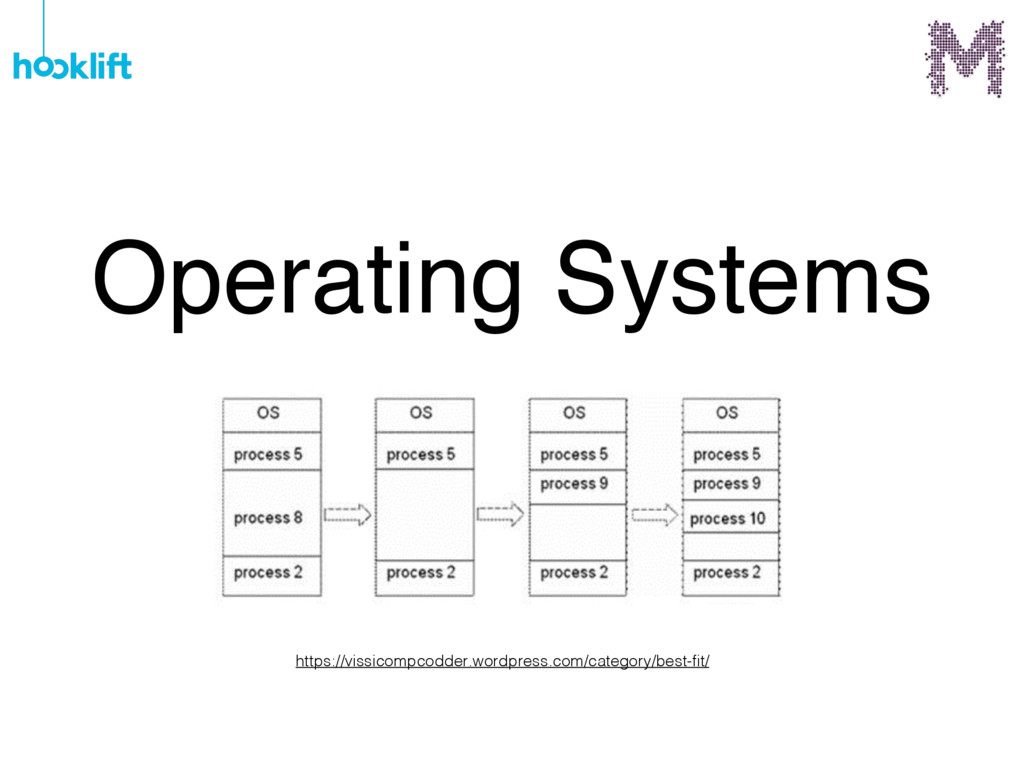{kind=link}
{kind=link}
{kind=link}
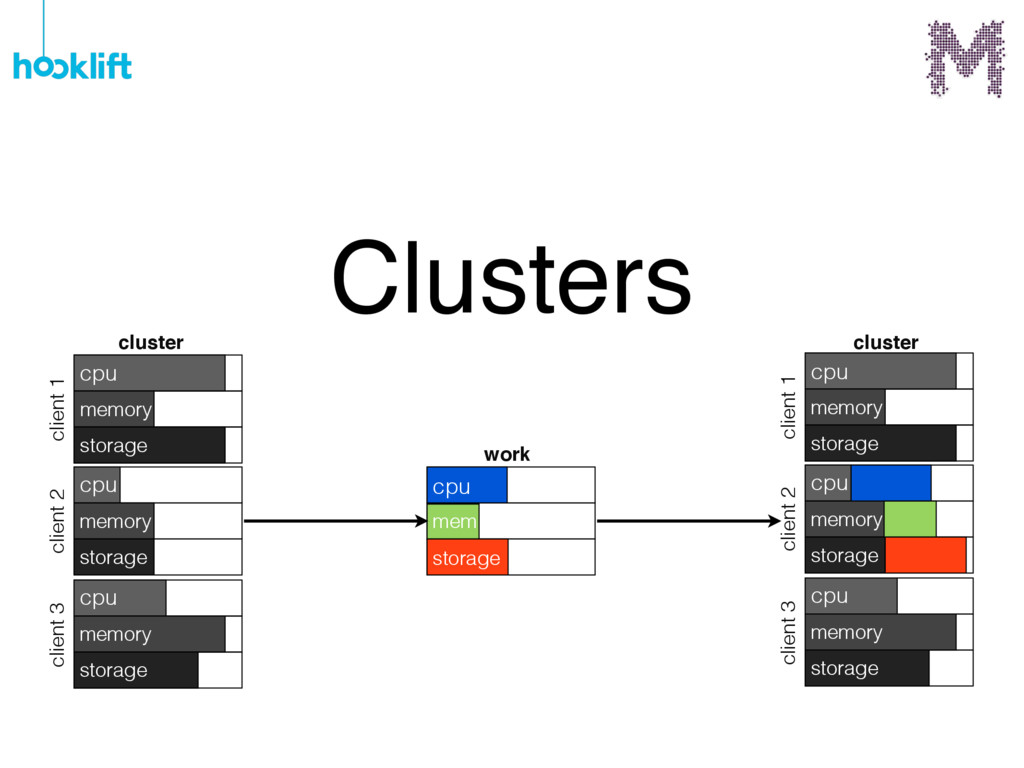{kind=link}
{kind=link}
{kind=link}
{kind=link}
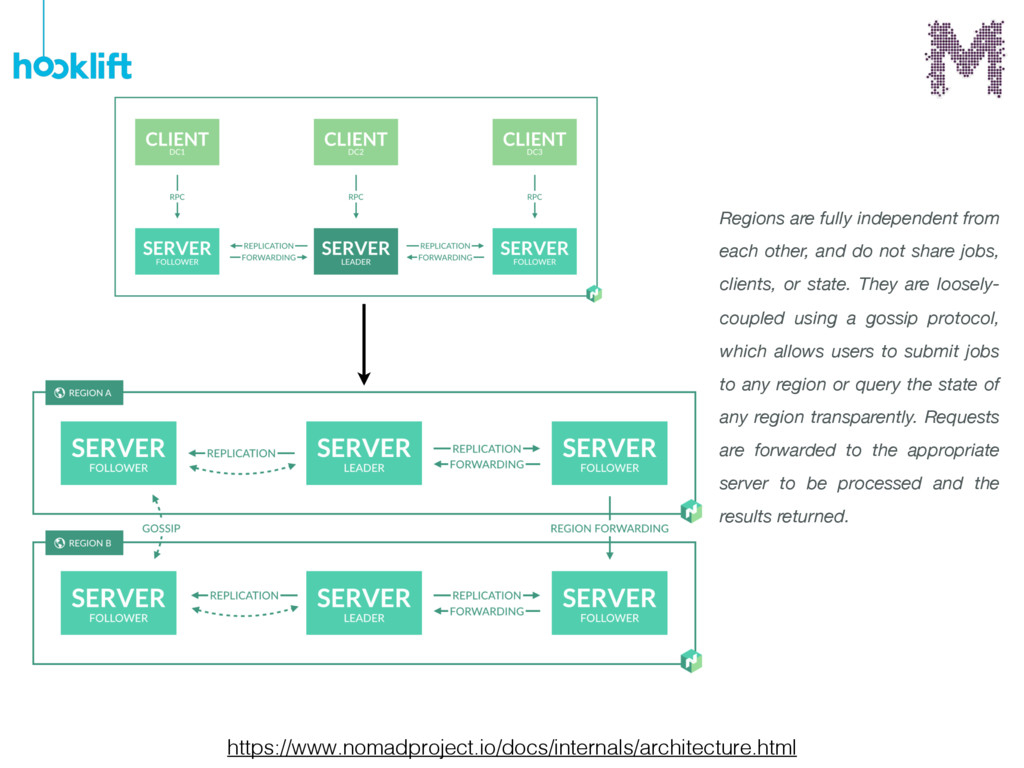{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}