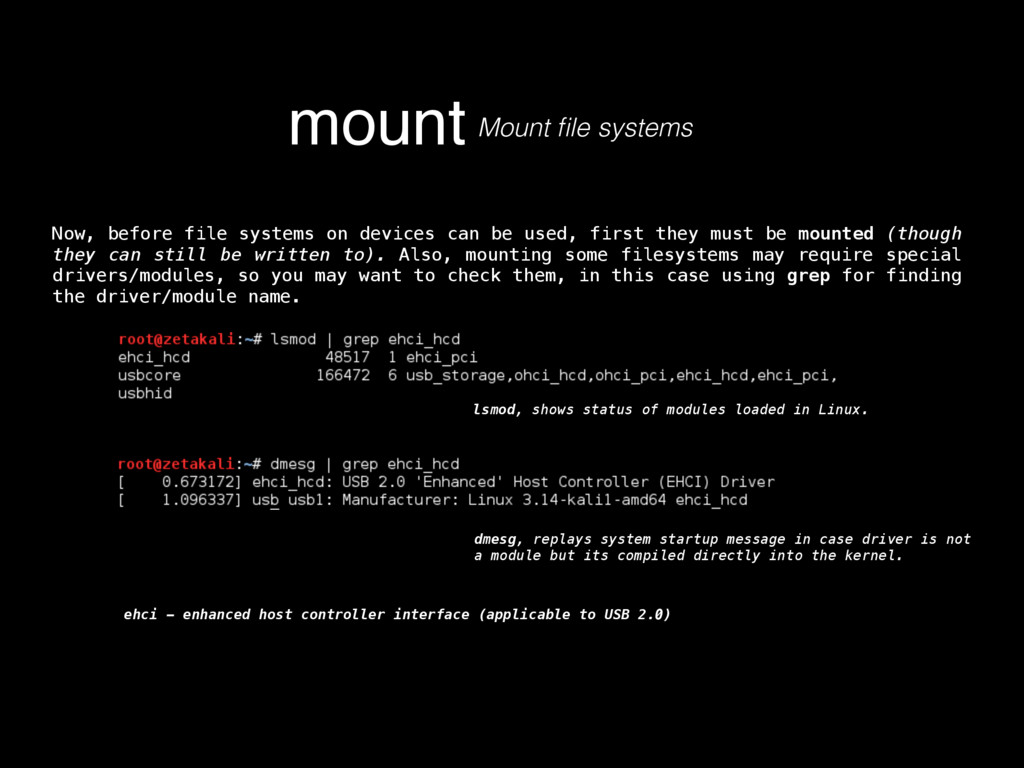
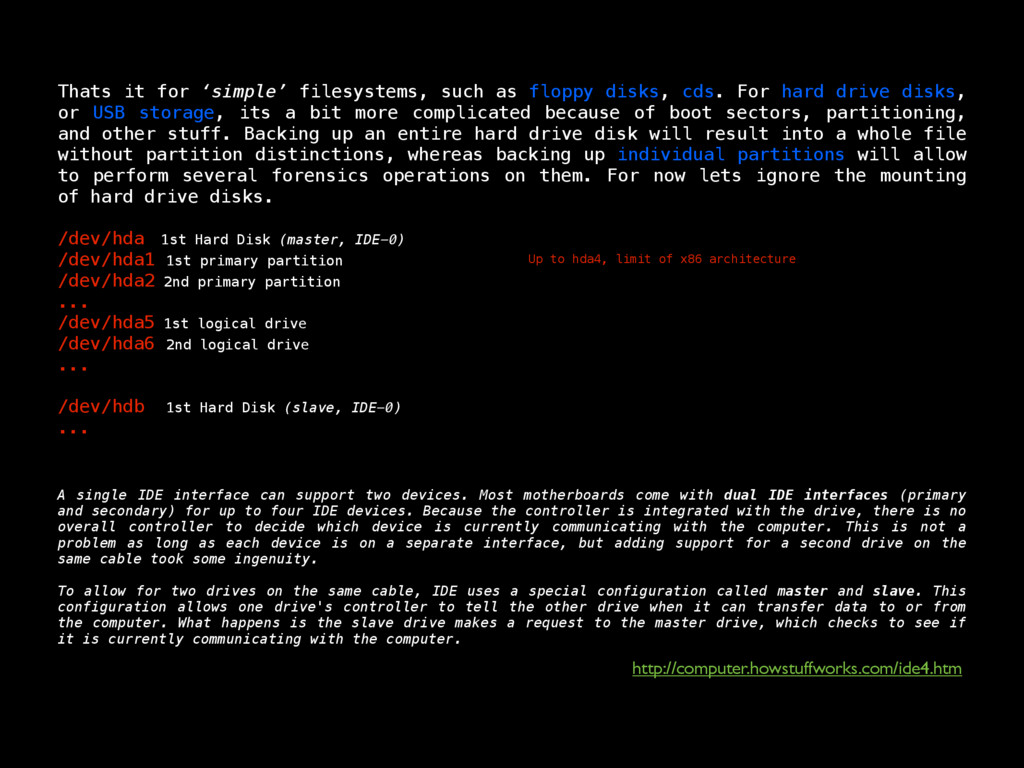
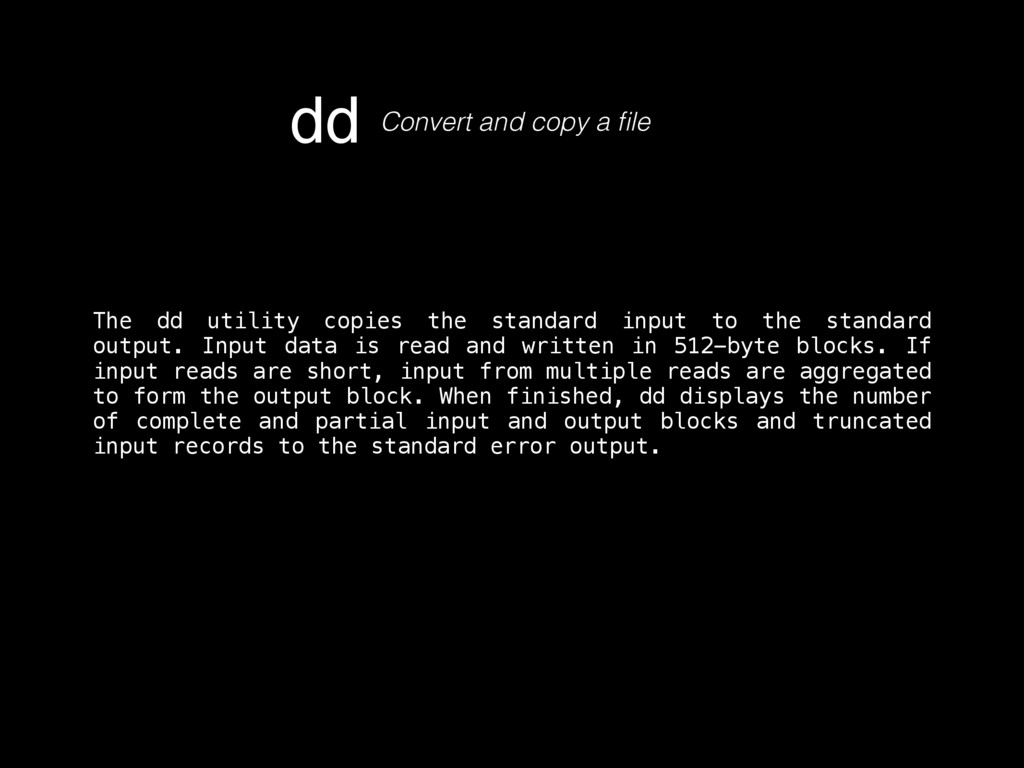
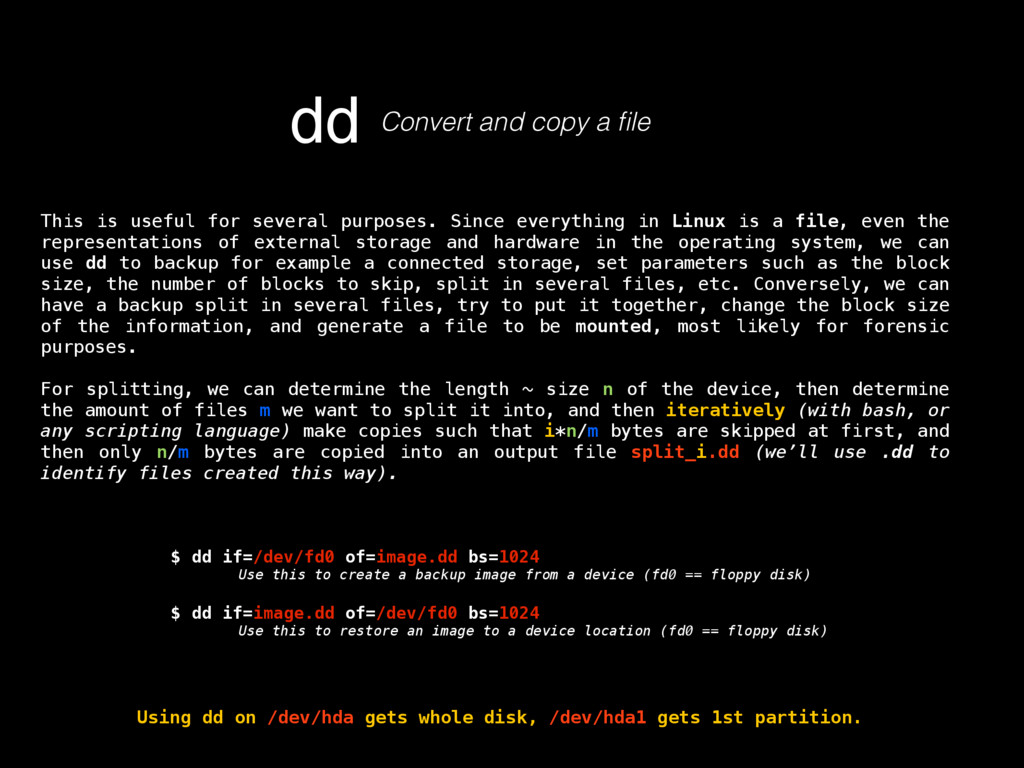
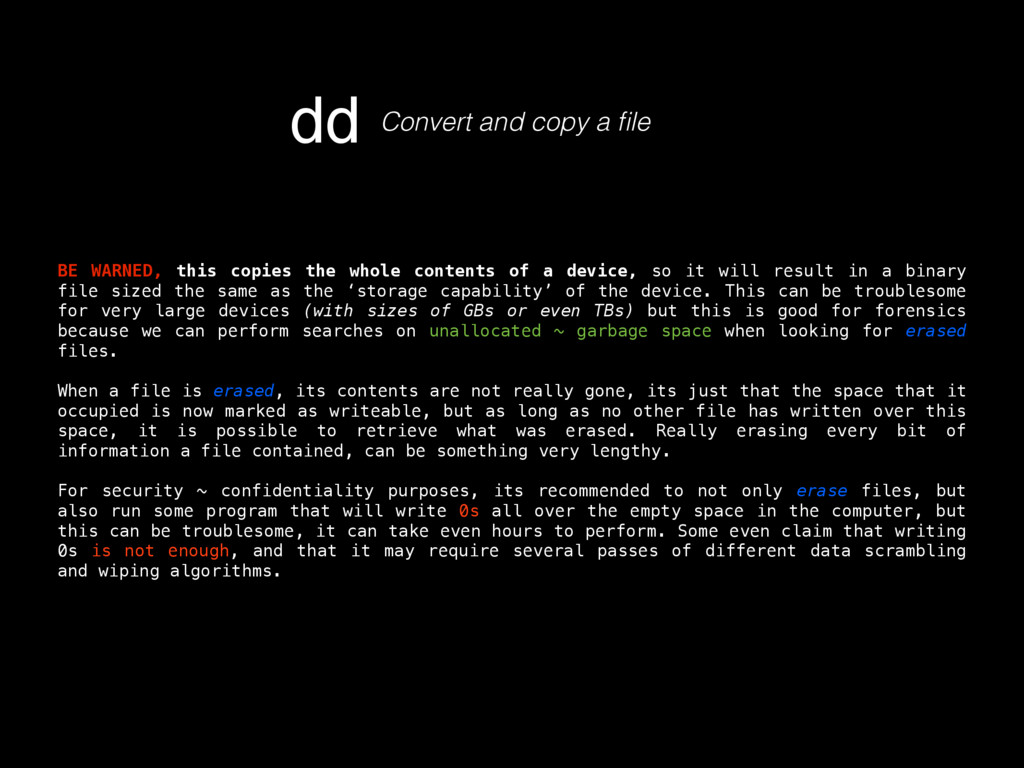
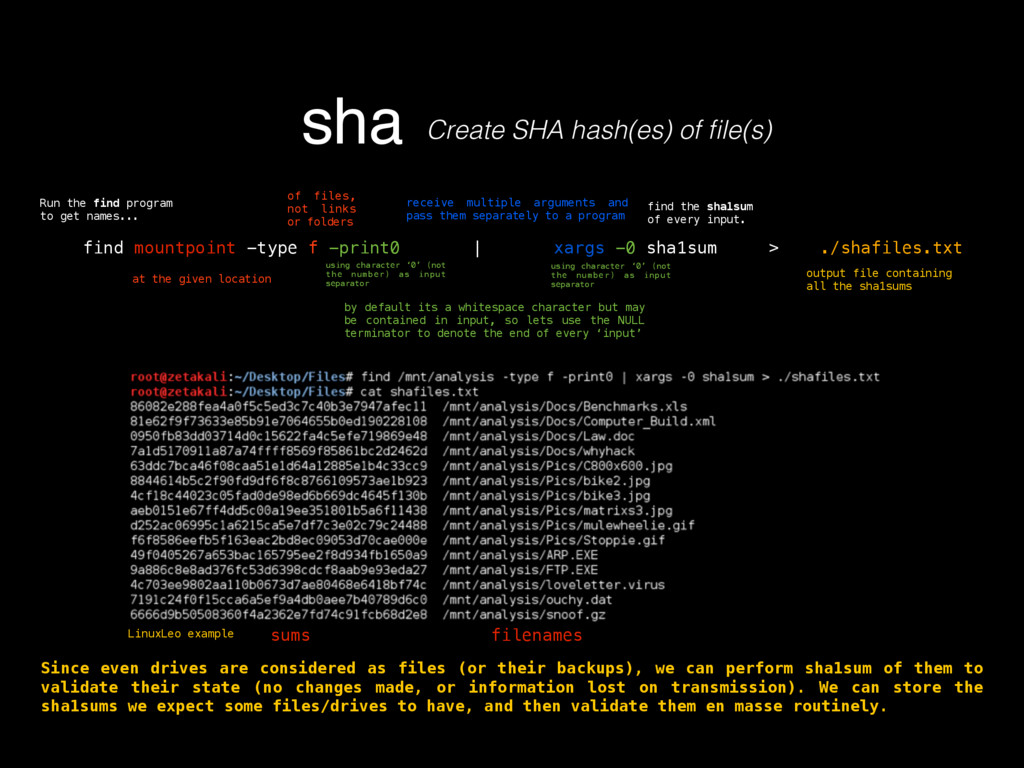
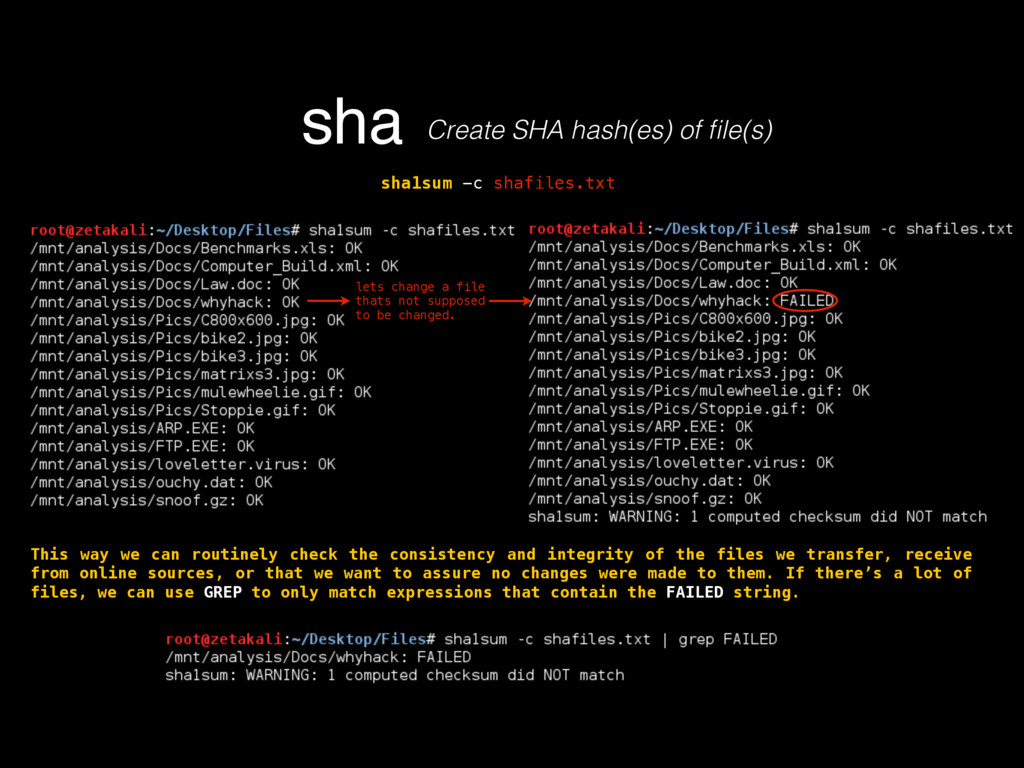
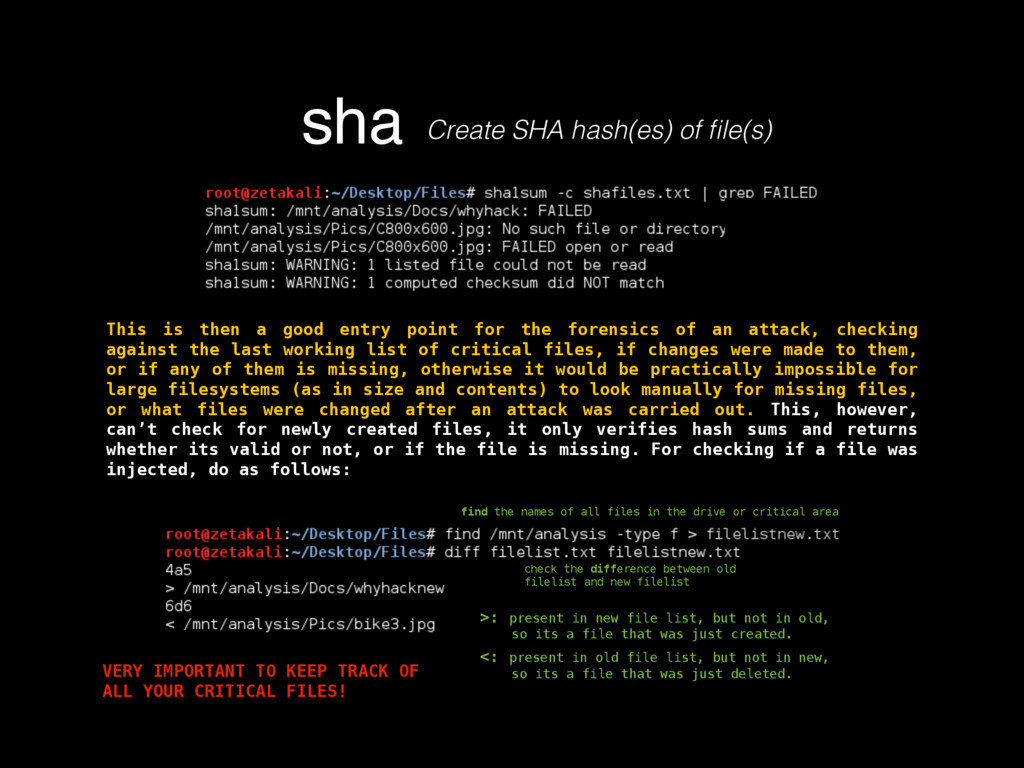
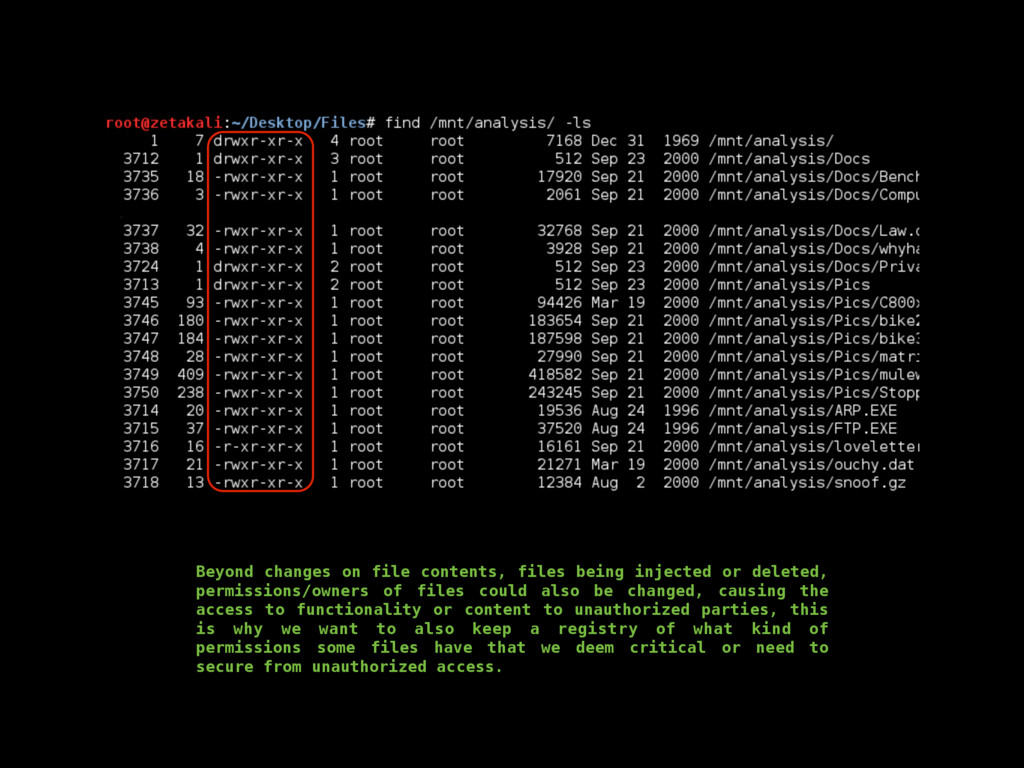
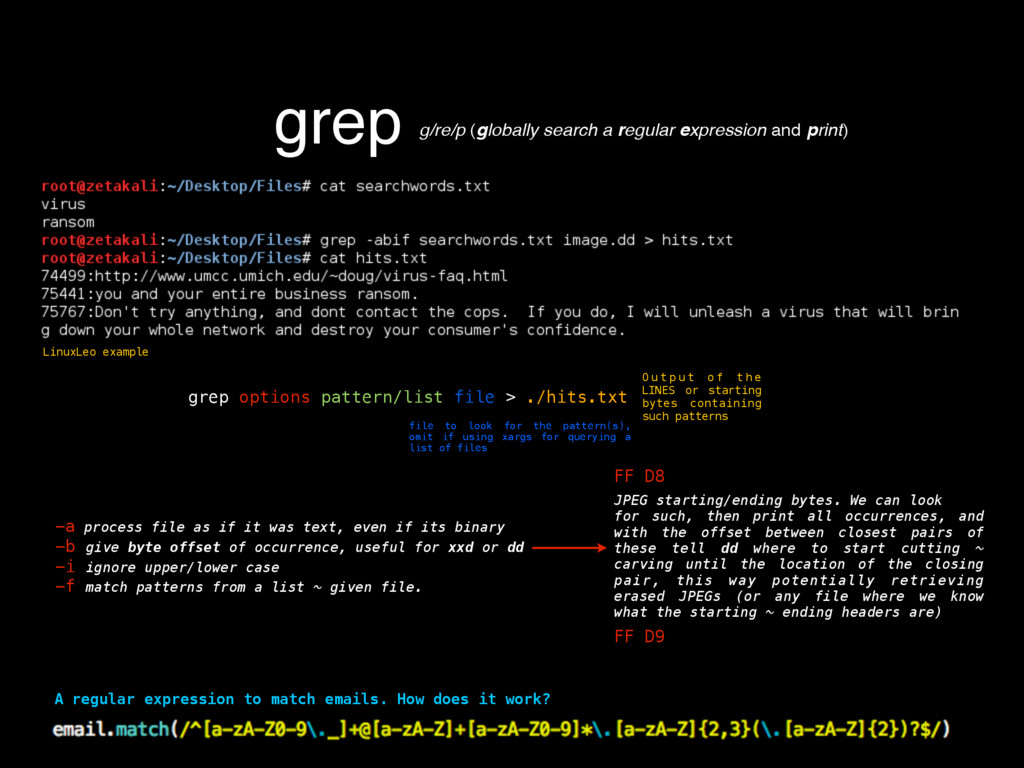
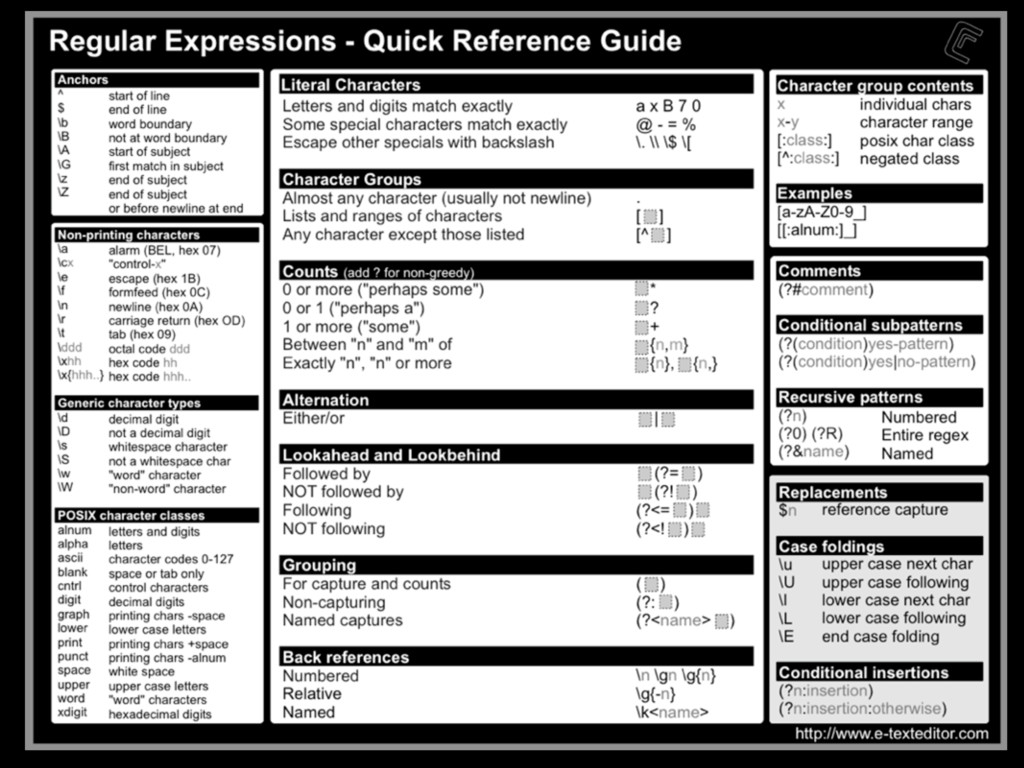
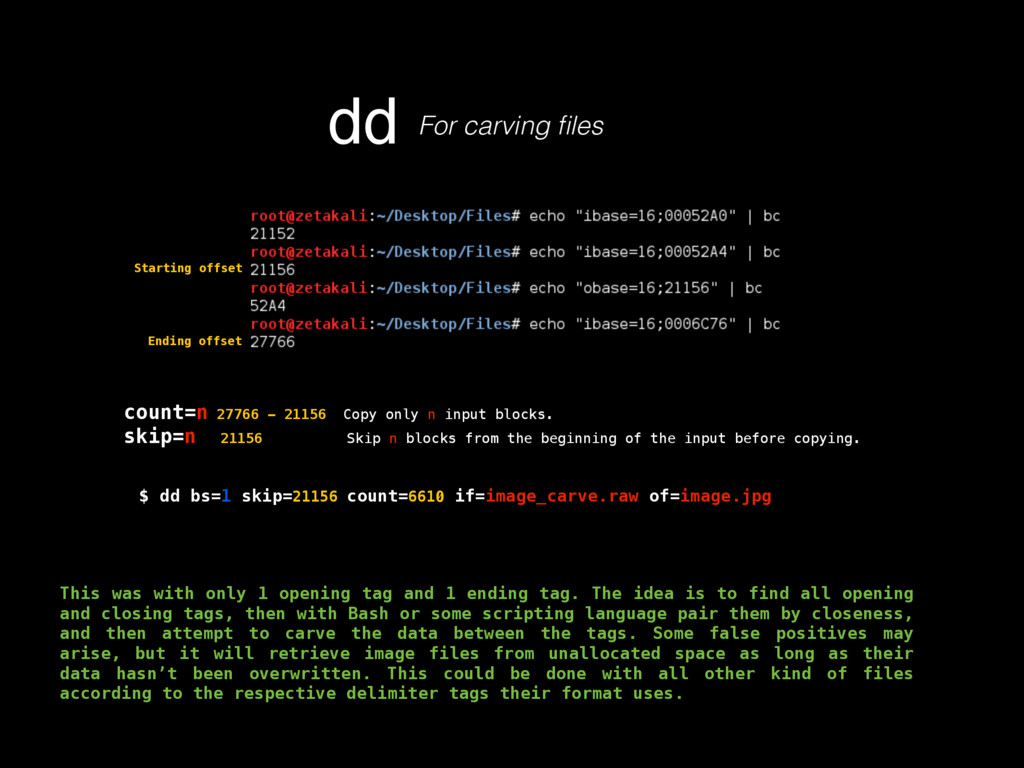
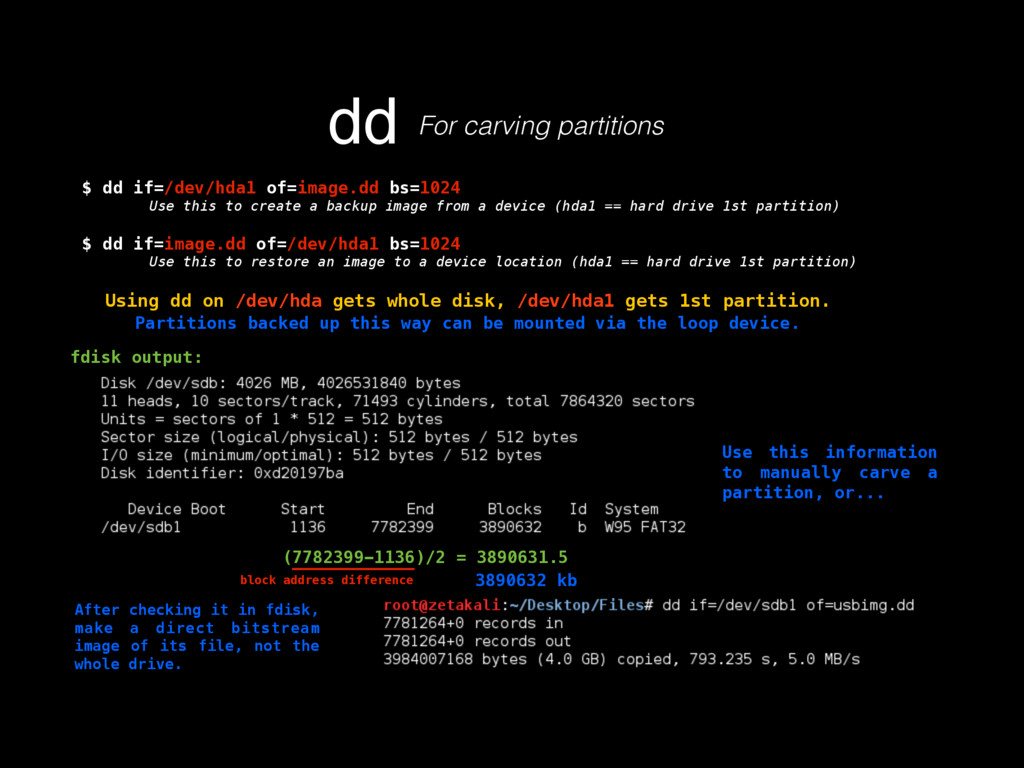
as in its contents, deletion, injection, permission changes, how to carve a binary file (backed up storages) looking for files, or for content by using regular expressions, which mostly helps knowing what happened to our turf, but now there’s a very important question, where did that come from? If any system has a decent security, it keeps track of all sorts of activity in logs. Entering to a mail server, downloading files, POST/GET requests made to a HTTP server, filesystem browsing, attempts to open a password protected file or accessing unprivileged functionality, everything must be logged, since all that serves as valuable evidence for determining what in earth took place after some people realized something happened, or better, looking for suspicious behavior to determine that something big has not yet happened but nonetheless someone is trying to break through security to make it so. Because of all this activity logging, log files can be very HUGE, to the order of gigabytes of pure plain text just for requests of a moderately sized website. Thankfully, these are usually stored by months, and after a month has passed, the logs are compressed using tar, which for plaintexts can compress a lot, like 1.6GB into 200mb. These are good to store because one never knows how further into the past we’ll need to look into when searching for the origins of an attack or the start of some suspicious behavior. logsKinda the sysadmin best friend Manually scourging log files can be a very tasking, if not impossible labor, thats where some simple tools from Linux like GREP, AWK and UNIQ come really handy.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![logsKinda the sysadmin best friend 41.142.223.88 - - [30/Nov/2014:16:39:00 -0600]](https://files.speakerdeck.com/presentations/cbd20040f8b74149b69f724ab0f9eff2/slide_22.jpg){kind=link}
![logsKinda the sysadmin best friend 41.142.223.88 - - [30/Nov/2014:16:39:00 -0600]](https://files.speakerdeck.com/presentations/cbd20040f8b74149b69f724ab0f9eff2/slide_23.jpg){kind=link}
{kind=link}
{kind=link}