y Director Técnico en NOSYS • ¿Qué hacemos en NOSYS? ✔ Formación, consultoría y desarrollo de software con PostgreSQL (y Java) ✔ Partners de EnterpriseDB ✔ Formación avanzada en Java con Javaspecialists.eu: Java Master Course y Java Concurrency Course ✔ Partners de Amazon AWS. Formación y consultoría en AWS • Twitter: @ahachete • LinkedIn: http://es.linkedin.com/in/alvarohernandeztortosa/
pais, count(*) AS usuarios, sum( CASE WHEN activo THEN 1 ELSE 0 END ) usuarios_activos FROM usuarios GROUP BY pais; • En 9.4: SELECT pais, count(*) AS usuarios, count(*) FILTER (WHERE activo) usuarios_activos FROM usuarios GROUP BY pais;
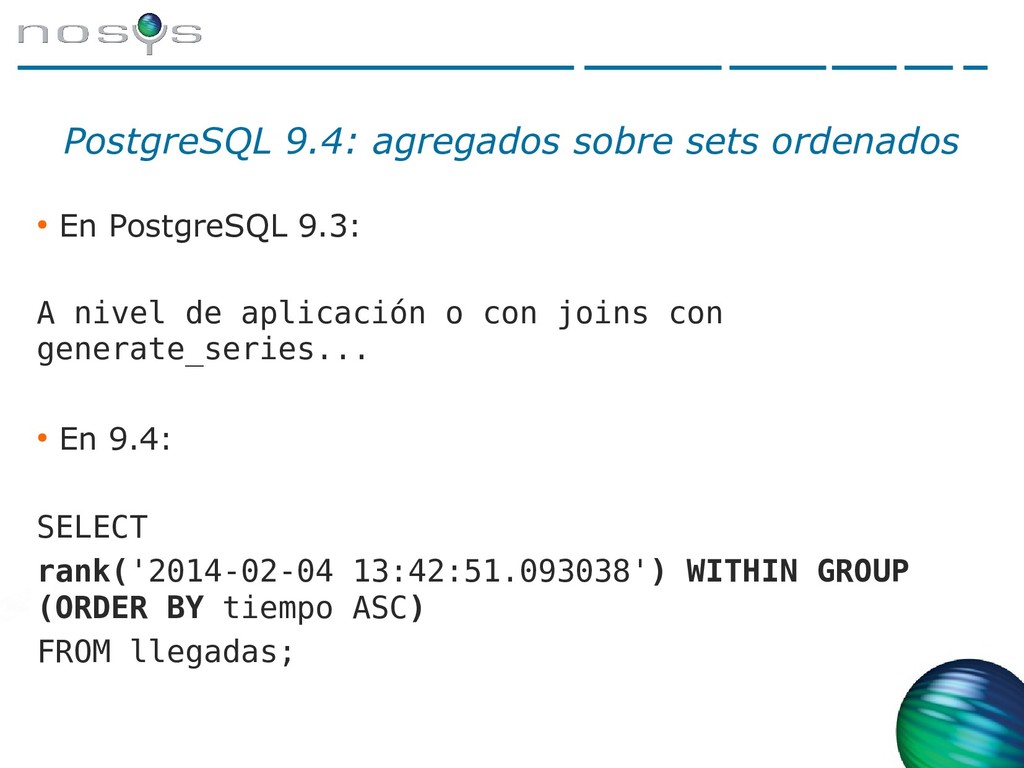
A nivel de aplicación o con joins con generate_series... • En 9.4: SELECT rank('2014-02-04 13:42:51.093038') WITHIN GROUP (ORDER BY tiempo ASC) FROM llegadas;
mode(), que devuelve el valor moda: SELECT clase, mode() WITHIN GROUP (ORDER BY nota_examen) FROM calificacion GROUP BY clase; • Hay otros adicionales, como percent_rank(), dense_rank(), percentile_cont(), percentile_disc() INSERT INTO i SELECT generate_series(1,10000); SELECT percent_rank(5000) WITHIN GROUP (ORDER BY i) FROM i; – Devuelve, no sorprendentemente: 0.4999
sobre conjuntos ordenados permiten valores hipotéticos; esto es, valores que “existirían”, pero no existen en la tabla. INSERT INTO i VALUES (1), (100); SELECT percentile_cont(.2) WITHIN GROUP (ORDER BY i) FROM i; percentile_cont ----------------- 20.8 SELECT rank(5) WITHIN GROUP (ORDER BY i) FROM i; rank ------ 2
siguiente charla :) • Vistas actualizables: ➔ Se amplía el conjunto de casos en el que se pueden actualizar los campos de la vista. ➔ Se añade soporte de “WITH CHECK OPTION” para que impida (o no) la introducción de valores que sean visibles en la vista. Valores LOCAL y CASCADE.
Con ORDINALITY (y WITH para que quede más bonito): WITH t (a, b, o) AS ( SELECT * FROM unnest( '{f1c1,f2c1,f3c1}'::text[], '{f1c2,f2c2,f3c2}'::text[] ) WITH ORDINALITY ) SELECT o, a, b FROM t; o | a | b ---+------+------ 1 | f1c1 | f1c2 2 | f2c1 | f2c2 3 | f3c1 | f3c2
de forma que nuevos servidores o servidores en hot standby tengan shared_buffers lleno y no sufran penalización en la primera lectura de disco. • Custom background workers: ahora pueden tener memoria dinámica e inicialización dinámica (no sólo en postmaster startup). • ALTER SYSTEM SET postgresqlconf_param = valor Edita postgresql.conf.auto, que tiene precedencia sobre postgresql.conf
en recuperación (recovery.conf) pase a modo online (aceptando queries) tan pronto como alcance estado consistente (sin necesidad de esperar a procesar todos los WAL pendientes). • Réplicas de lectura desfasadas: permite que la replicación se aplique de forma retrasada en la réplica, de manera que ante fallo humano se puedan recuperar datos de la réplica sin necesidad de tener que recuperar la base de datos mediante PITR. Parámetro min_recovery_apply_delay
equivalente a JSON, al permitir documentos embebidos. Gran extensión, con amplísimo soporte de operadores e índices sobre los valores del campo hstore. SELECT 'a=>1,b=>{c=>3,d=>{4,5,6}},1=>f'::hstore -> 'b'; • Más funciones JSON y jsonb: Se amplían las funciones para trabajar con JSON, y se añade el tipo nativo “jsonb”, que es una representación binaria más compacta para JSON (no preserva espacios en blanco ni permite claves duplicadas).
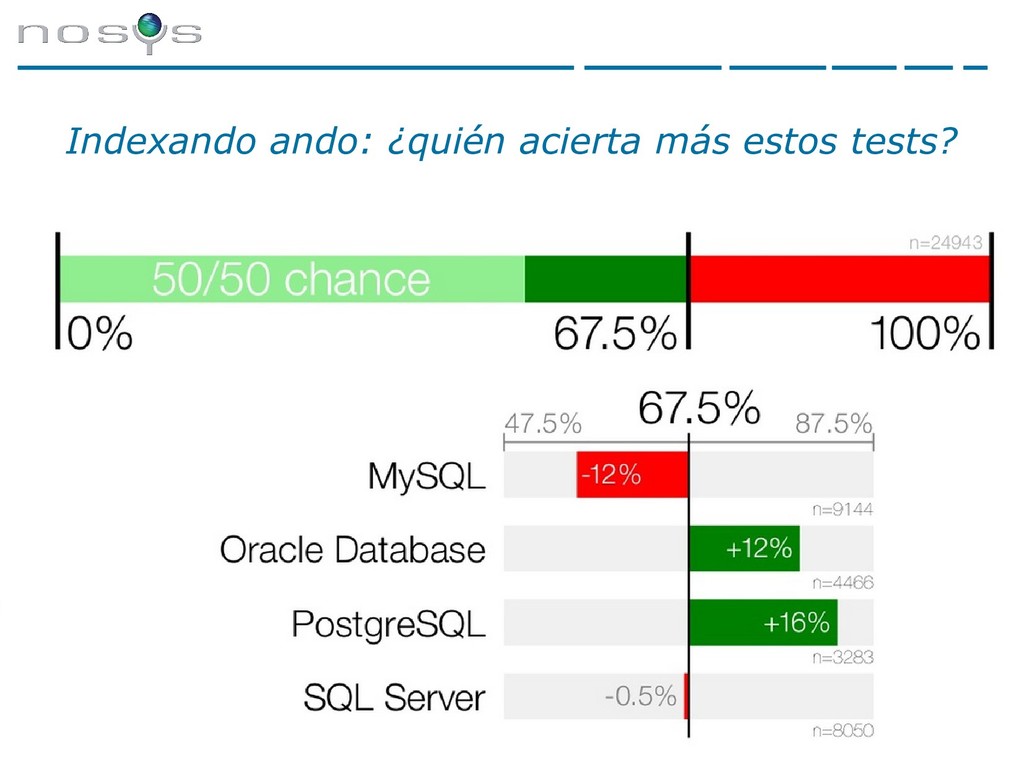
whitepaper de Percona, de las principales causas de indisponibilidad de una base de datos, destacan: ➔ 38% mal SQL ➔ 15% estructura de datos e índices • Según observaciones particulares, entorno al 50% de los problemas de rendimiento de SQL son por malos índices. • ¿Quién hace los índices? ¿Los DBAs o los programadores? Los índices no son tunning de bases de datos, son responsabilidad de los programadores. De hecho, su uso depende exactamente de las queries que se hagan.
casi óptima. La cláusula LIMIT 1 sobre un campo ordenado permite el uso del índice, incluso aunque el orden sea inverso. No hace falta ordenar todas las soluciones y recorrer el conjunto ordenado.
where tags @> array['double-agent','probation']; => -[ RECORD 1 ]-------------------------- name | Sterling Archer tags | {double-agent,probation,arrears} -[ RECORD 2 ]-------------------------- name | Barry Dylan tags | {double-agent,probation,arrears}
de tablas que preveen operaciones como rangos solapados (fundamental para bases de datos como reservas de recursos físicos, etc): ALTER TABLE reserva_salas ADD EXCLUDE USING gist (reservado WITH =, periodo WITH &&);
sobre un subconjunto de valores de una tabla. Permiten reducir el tamaño del índice, eliminando valores que no importan: CREATE INDEX tabla_indice ON tabla (cols) WHERE NOT borrado; • Índices sobre expresiones: se pueden crear índices no sólo sobre columnas existentes, sino también sobre expresiones arbitrarias sobre las columnas: CREATE INDEX tabla_indice ON tabla (lower(nombre));
![Lo mejor de FOSDEM y PostgreSQL Álvaro Hernández Tortosa <[email protected]>](https://files.speakerdeck.com/presentations/5712625aa8f04141b57dc4bd85018622/slide_0.jpg){kind=link}
![Acerca de mí • Álvaro Hernández Tortosa <[email protected]> • Fundador](https://files.speakerdeck.com/presentations/5712625aa8f04141b57dc4bd85018622/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}