쉬워졌을까? http://kr.vonvon.me/quiz/329, http://kr.vonvon.me/quiz/1633 (사실은 삽질 삽질 삽질 삽질 삽질을... 으어어) 일단 오픈소스 한컵 붓고.. 클라우드 살짝 얹고.. 딥러닝을 잘 부으면... 다 되는 건가? 신이 AI 분야를 만들 때
인프라가 점점 빠르게 좋아지고 있다 – Amazon Glue / GluOn – Azure ML Workbench / Studio – Google Cloud Datalab / DialogFlow – Naver nsml / C3 DL • 문제점 – AI 기반 기술의 발전 속도 >>> 연구·개발자들의 AI 활용능력 발전 속도 >>>> 인간사회의 AI 대응 속도 – 플랫폼이 아무리 좋아져도 data locality 문제와 규제는 근본적으로 피해가기 어렵다 – 플랫폼이 아무리 쉬워져도 여전히 비개발자에겐 어렵다
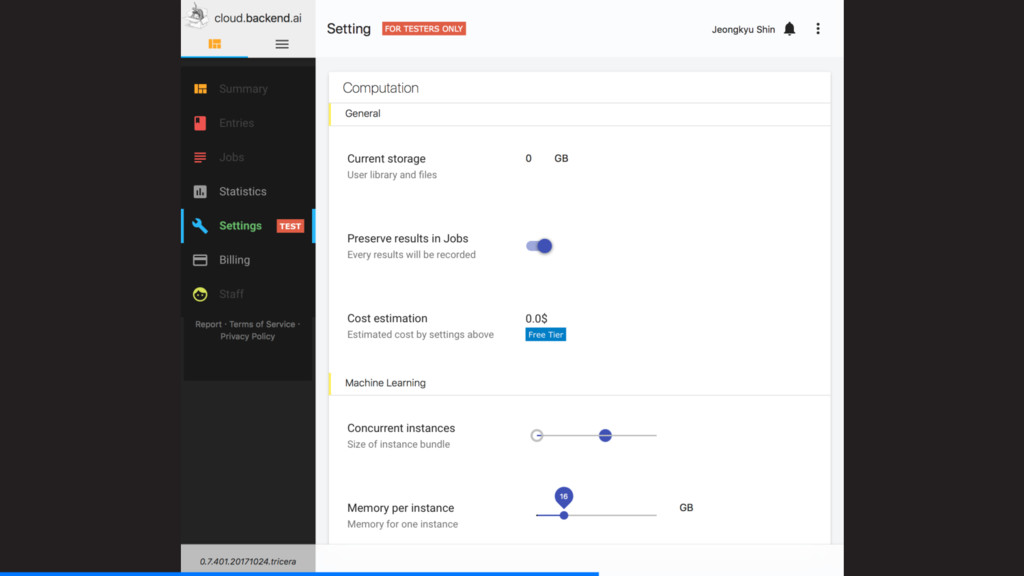
최소한의 환경설정만으로 빠르게 – GPU를 잘 활용할 수 있도록 – 원하는 만큼 연산자원을 바로바로 값싸게 – 사용한 만큼만 지불하도록 – 비용 제한에 맞춰 성능 조정을 자동으로 어디서나 – 내가 가진 서버를 지금 바로 활용하거나 – 이도저도 귀찮다면 클라우드에 맡겨서 함께 – 한번 만들면 누구나 똑같이 재현하고 재사용하도록 – 다른 사람들과 충돌 없이 자원을 공유할 수 있도록
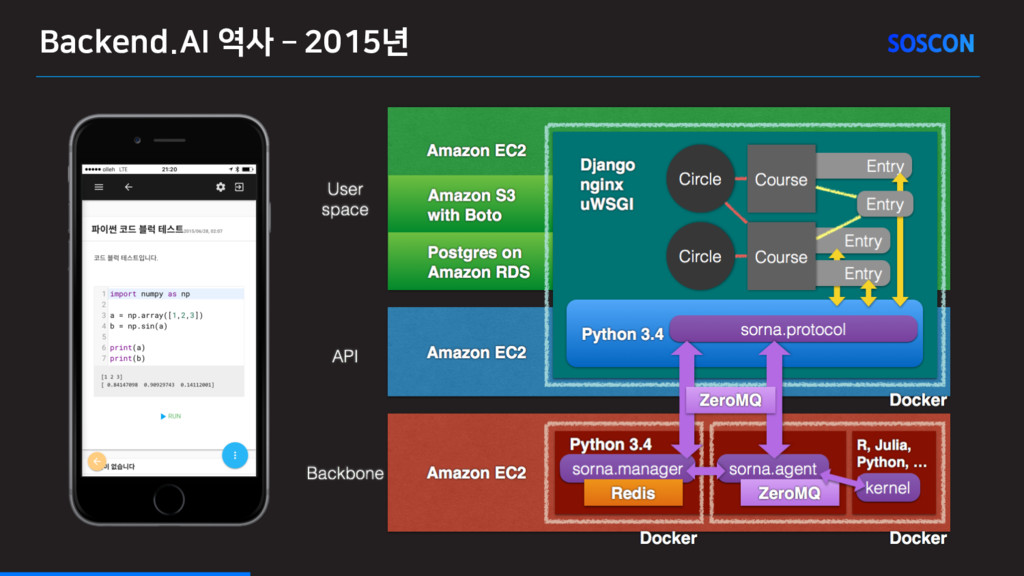
학도가 니르고져 홀빼이셔도 마참내 제 뜨들 시러펴디 못할 노미 하니라. 내 이랄 위하야 어엿비 너겨 새로 연구 코드 나누미와 과학 공학 노리터를 맹가노니 사람마다 희여 수비니겨 날로 쑤메 뼌한킈 하고져 할따라미니라. 2015년에 만들려고 보니까 이걸 받쳐줄 백엔드가 필요하다! 지금이야 좋은 오픈소스가 많지만 그때만 해도... ㅠㅠ
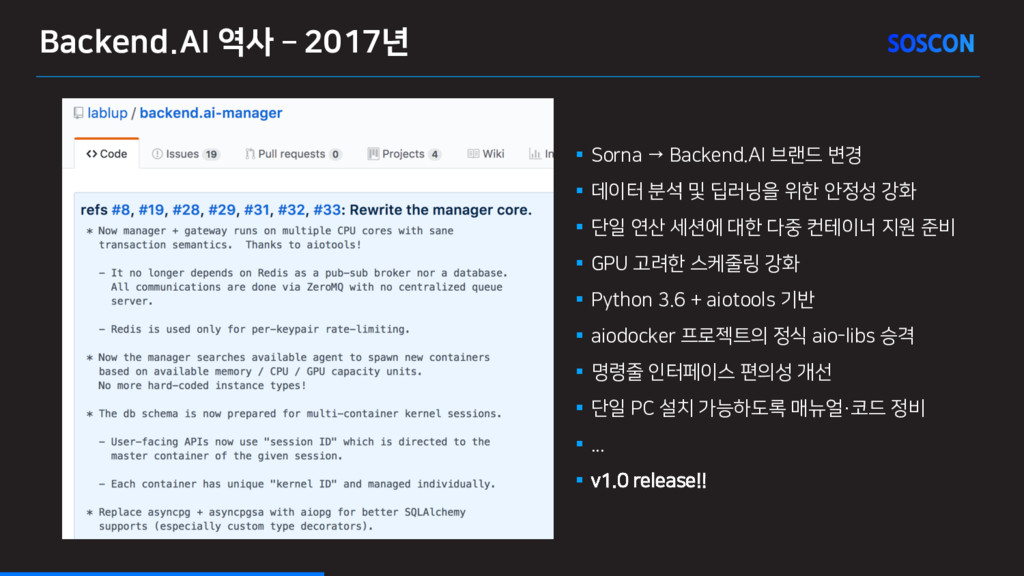
§ 데이터 분석 및 딥러닝을 위한 안정성 강화 § 단일 연산 세션에 대한 다중 컨테이너 지원 준비 § GPU 고려한 스케줄링 강화 § Python 3.6 + aiotools 기반 § aiodocker 프로젝트의 정식 aio-libs 승격 § 명령줄 인터페이스 편의성 개선 § 단일 PC 설치 가능하도록 매뉴얼·코드 정비 § ... § v1.0 release!!
Showcases 계산 기반의 과학·공학 연구, 딥러닝 모델 훈련 및 엄청나게 간편한 코딩 교육 환경을 구축하는 Scalable PaaS 자신만의 Lablup.AI 서버팜을 설치하고 수정하고 개발할 수 있는 오픈소스 버전 Lablup.AI 사용자들을 위한 문서, 포럼 및 쇼케이스들 Backend.AI codeonweb.com
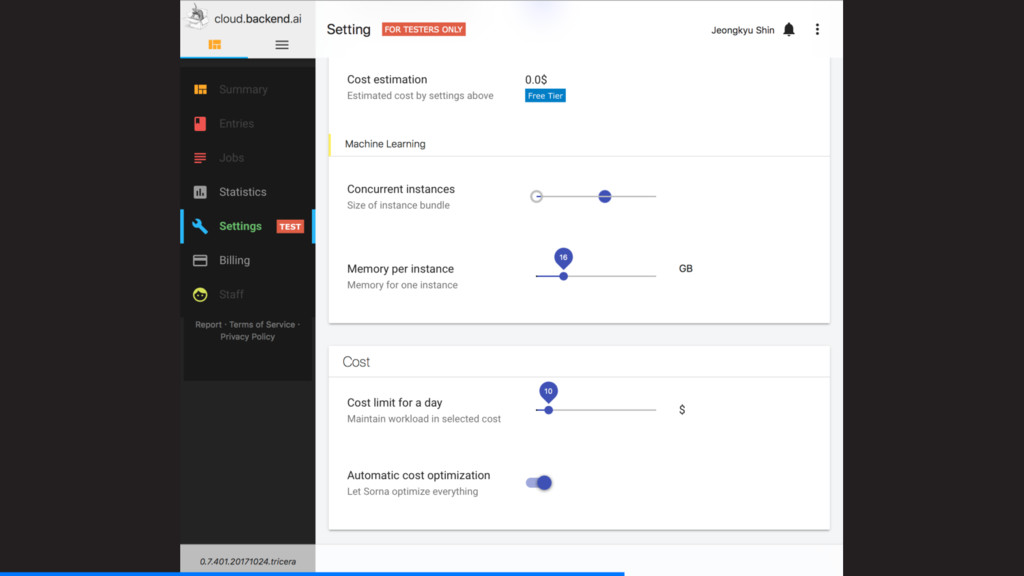
환경설정만으로 빠르게 – GPU를 잘 활용할 수 있도록 – 원하는 만큼 연산자원을 바로바로 값싸게 – 사용한 만큼만 지불하도록 – 비용 제한에 맞춰 성능 조정을 자동으로 어디서나 – 내가 가진 서버를 지금 바로 활용하거나 – 이도저도 귀찮다면 클라우드에 맡겨서 함께 – 한번 만들면 누구나 똑같이 재현하고 재사용하도록 – 다른 사람들과 충돌 없이 자원을 공유할 수 있도록 쉽게 – Jupyter, VS Code, Atom 플러그인 제공 – API key만 설정하면 끝! 빠르게 – 컨테이너와 GPU 기술을 결합 – 1초 이내에 연산 세션이 뜨도록 값싸게 – 밀리초/KiB 단위까지 정밀한 자원 사용 측정 – (향후 지원 예정!) 어디서나 – 오픈소스 버전 제공 (github.com/lablup/backend.ai) – 클라우드 버전 제공 (cloud.backend.ai) 함께 – 컨테이너를 활용한 언어별·버전별 가상 환경 제공 – 시스템콜 샌드박싱 + Docker의 자원제한 고도화
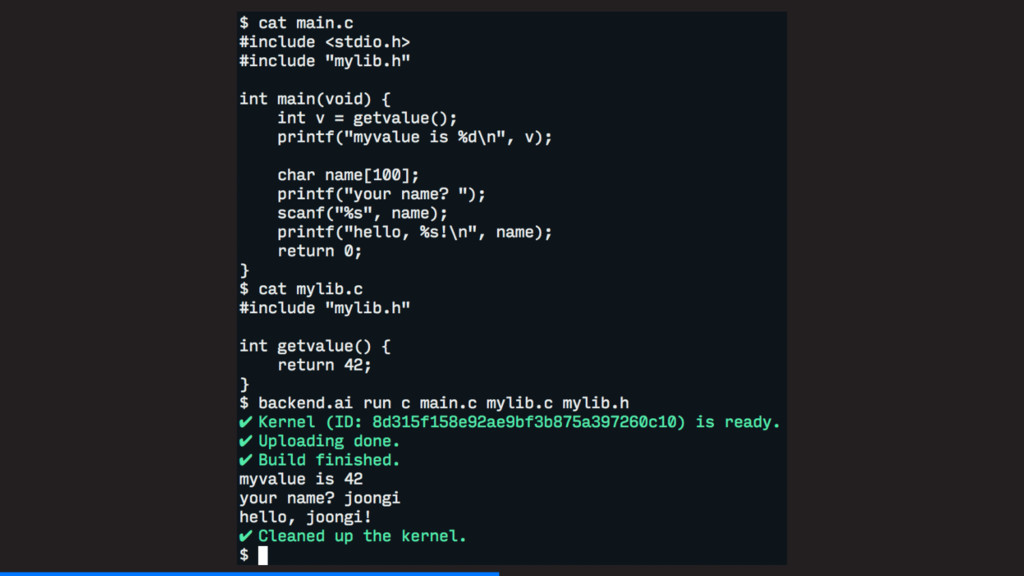
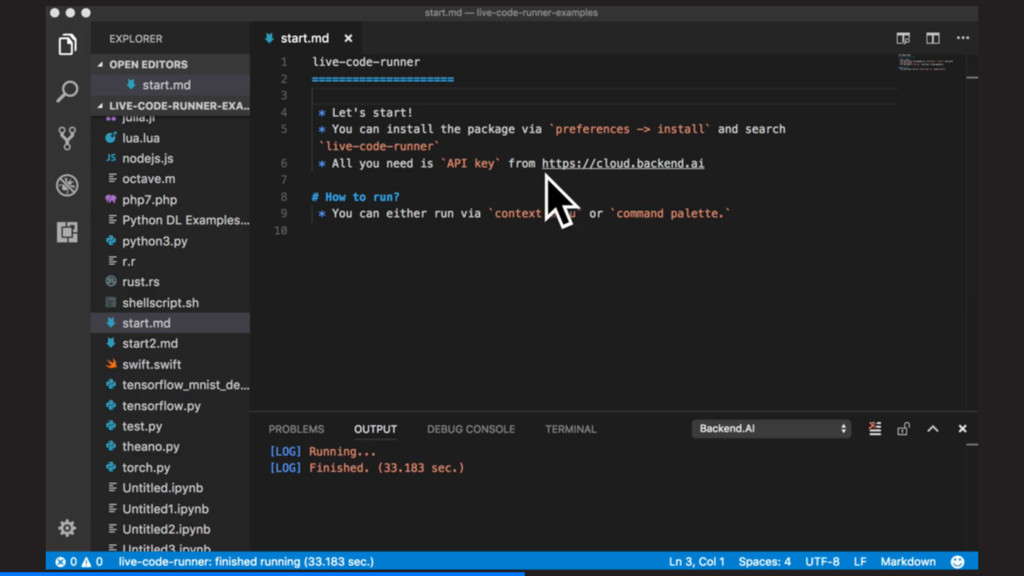
사용 가능 – 사용자의 요청 즉시 가상 프로그래밍 환경 생성 • 다양한 요구사항 충족 – 모든 주요 프로그래밍 언어와 런타임 지원 Python, R, Julia, Octave, PHP, Go, C/C++, Java, NodeJS, Lua, Haskell, Rust – 동일한 기계학습 라이브러리의 여러 버전 동시 지원 TensorFlow, Caffe, PyTorch, Keras • 친숙한 사용자 경험 + 개발자 친화적 프레임워크 – 기존 연구·개발자들에게 익숙한 환경과의 통합 지원 (코드편집기, 웹기반 연구노트) Jupyter, VS Code, Atom Editor, IntelliJ beta – $ backend.ai run 명령줄 및 클라우드 인터프리터·컴파일러 지원 – 개발자를 위한 HTTP 기반 공용 API 및 언어별 SDK 제공 Python, Javascript, PHP beta
Flow import tensorflow as tf import matplotlib v1 = tf.Variable(..., name="v1") v2 = tf.Variable(..., name="v2") ... plot(...) Java C++ Rust Internet Backend.AI Agent Backend.AI Agent 클라우드 또는 사용자 서버팜에서 실행 Spark API
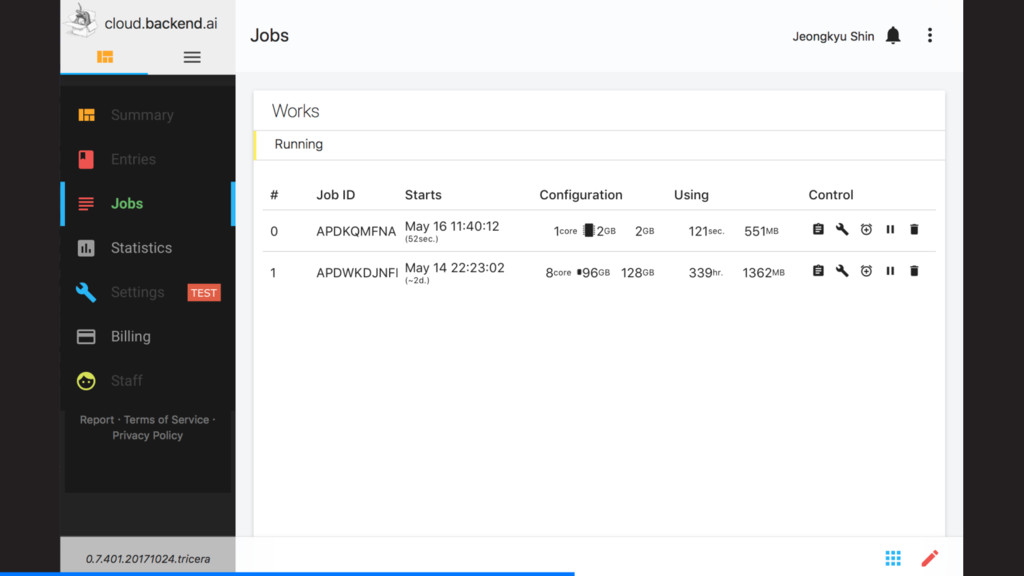
컨테이너 풀링 기법 (Python asyncio + Docker) – 컨테이너에서의 머신러닝 GPU 가속 지원 (nvidia-docker) • 다중 사용자 보안 – 다이나믹 샌드박싱 : 가상환경별로 특화된 시스템콜 제어 및 필터링 – 레거시 소프트웨어를 위한 컨테이너 리소스 제한 강제 기술 • 하이퍼 스케일링 Hyper-scaling – On-premise 단독 private cluster – Hybrid cloud (on-premise + public cloud) – Public cloud (AWS + MS Azure + Google Cloud 조합) – 계산종류·부하·설정에 따라 특화된 클라우드로 사용자 요청 routing
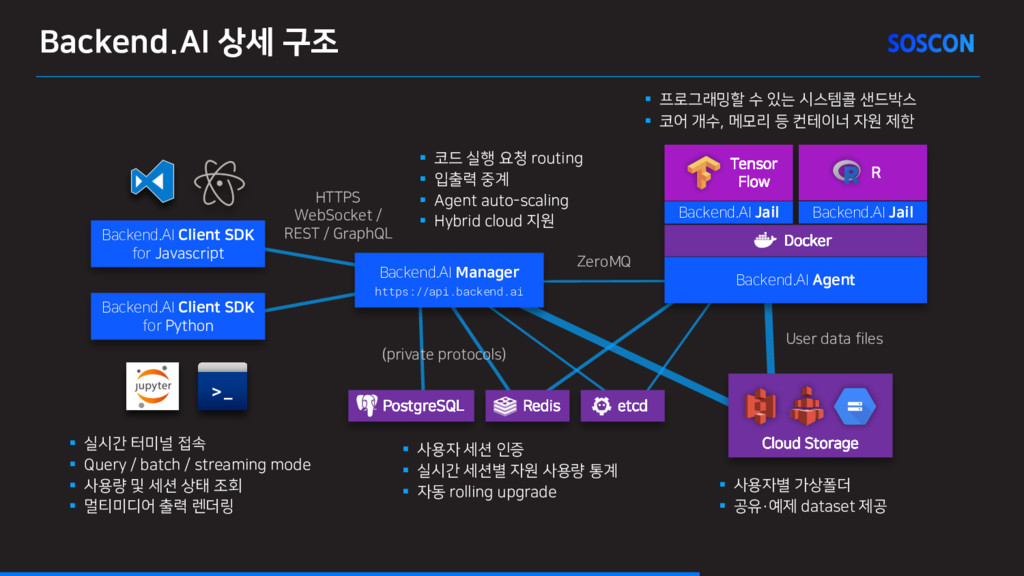
WebSocket / REST / GraphQL ZeroMQ etcd Redis PostgreSQL (private protocols) Backend.AI Client SDK for Javascript Tensor Flow Backend.AI Jail R Backend.AI Jail Docker User data files Cloud Storage Backend.AI Agent Backend.AI Manager https://api.backend.ai § 실시간 터미널 접속 § Query / batch / streaming mode § 사용량 및 세션 상태 조회 § 멀티미디어 출력 렌더링 § 사용자 세션 인증 § 실시간 세션별 자원 사용량 통계 § 자동 rolling upgrade § 프로그래밍할 수 있는 시스템콜 샌드박스 § 코어 개수, 메모리 등 컨테이너 자원 제한 § 사용자별 가상폴더 § 공유·예제 dataset 제공 § 코드 실행 요청 routing § 입출력 중계 § Agent auto-scaling § Hybrid cloud 지원
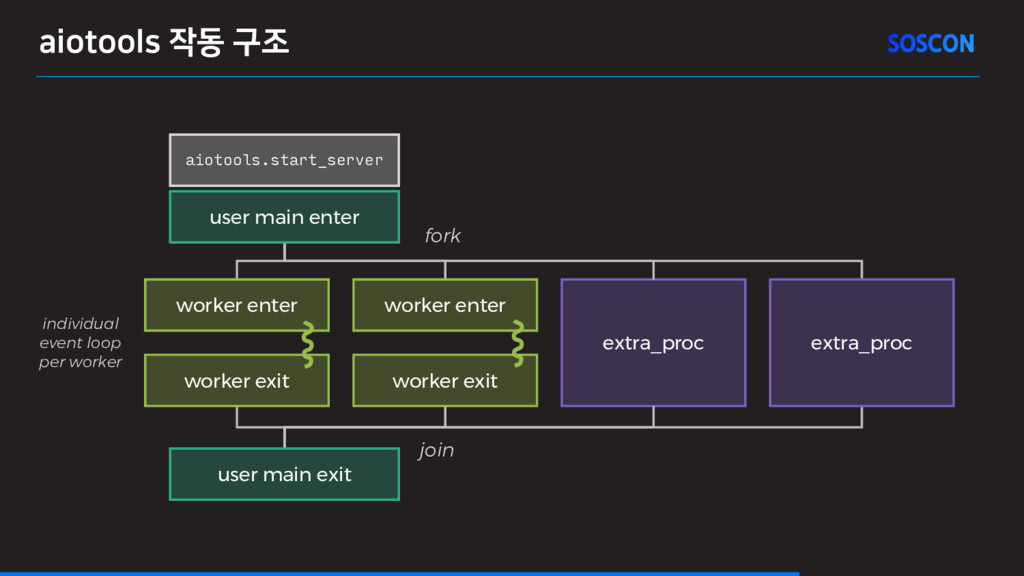
하기 – aiotools로 멀티쓰레드·멀티프로세스 구조로 이벤트 루프 사용하기 – etcd v3를 asyncio 기반으로 사용하기 • 프로그래밍 가능한 syscall 샌드박스 만들기 • Docker 컨테이너 CPU 개수 제한하기 • 유연하고 효율적인 GraphQL 서버 구현하기
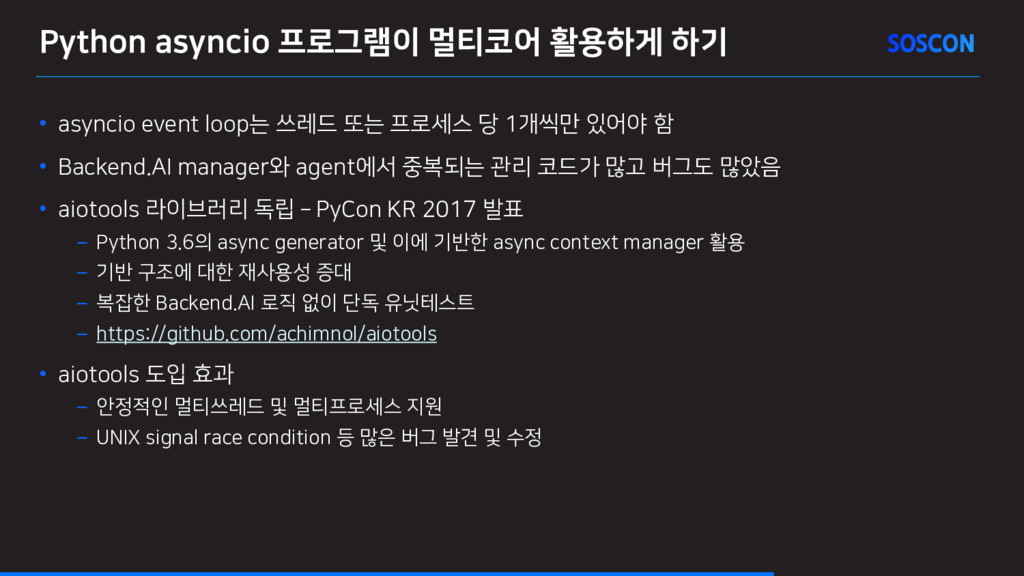
쓰레드 또는 프로세스 당 1개씩만 있어야 함 • Backend.AI manager와 agent에서 중복되는 관리 코드가 많고 버그도 많았음 • aiotools 라이브러리 독립 PyCon KR 2017 발표 – Python 3.6의 async generator 및 이에 기반한 async context manager 활용 – 기반 구조에 대한 재사용성 증대 – 복잡한 Backend.AI 로직 없이 단독 유닛테스트 – https://github.com/achimnol/aiotools • aiotools 도입 효과 – 안정적인 멀티쓰레드 및 멀티프로세스 지원 – UNIX signal race condition 등 많은 버그 발견 및 수정
기반한 strongly-consistent key-value storage – Go 언어 기반으로 ZooKeeper 등에 비해 쉬운 설치와 배포가 장점 – 클라우드 및 컨테이너 최적화 OS인 CoreOS 팀에서 개발 – v2와 v3는 완전히 다른 (호환되지 않는) API와 기능 제공 • Python 용 클라이언트 현황 – v2: python-etcd, python-aio-etcd – v3: python-etcd3 (2016년 9월 v0.1 릴리즈), aioetcd3 (2017년 8월 개발 시작) – 내부에서 gRPC 라이브러리를 사용하는데.... import를 먼저 하고 fork하면 hang-up [X] fork한 후 import 해야 함 [O]
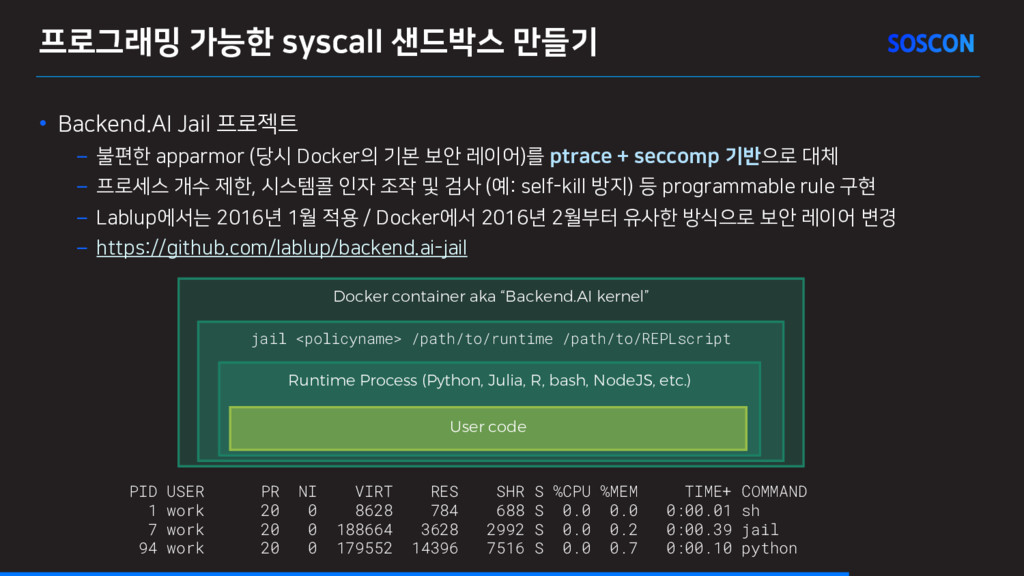
불편한 apparmor (당시 Docker의 기본 보안 레이어)를 ptrace + seccomp 기반으로 대체 – 프로세스 개수 제한, 시스템콜 인자 조작 및 검사 (예: self-kill 방지) 등 programmable rule 구현 – Lablup에서는 2016년 1월 적용 / Docker에서 2016년 2월부터 유사한 방식으로 보안 레이어 변경 – https://github.com/lablup/backend.ai-jail Docker container aka “Backend.AI kernel” jail <policyname> /path/to/runtime /path/to/REPLscript Runtime Process (Python, Julia, R, bash, NodeJS, etc.) User code PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 work 20 0 8628 784 688 S 0.0 0.0 0:00.01 sh 7 work 20 0 188664 3628 2992 S 0.0 0.2 0:00.39 jail 94 work 20 0 179552 14396 7516 S 0.0 0.7 0:00.10 python
연산용 라이브러리는 시스템 코어 개수를 알아내기 위해 다음 활용 ü 자체적으로 지정한 환경변수 (OMP_NUM_THREADS, OPENBLAS_NUM_THREADS, NPROC) ü sysconf(_SC_NPROCESSORS_ONLN) 리턴값 – 하지만, Docker container create API의 CPU set 인자는 affinity mask만 설정 ü /proc/cpuinfo, sysconf 등은 그대로... ü 결과는 thread 개수 폭발!! • 해결책 – Docker image label로 내부에 사용된 라이브러리에 따라 필요한 코어 개수 지정하는 환경변수 기록 – LD_PRELOAD 환경변수로 libc의 sysconf 함수를 affinity mask를 읽는 버전으로 바꿔치기
API 프로토콜 개발용 명세 – 미리 정의한 schema에 맞춰 query를 날리면 query의 구조 그대로 JSON 응답 생성 – URL 자체가 API 구조와 엮이는 REST와 달리 단일 endpoint 사용 – 각 field와 object를 실제로 어디에서 어떻게 가져올 것인가(resolving)는 온전히 개발자 몫! • 문제점 – RDBMS와 붙였을 때 너무너무 많은 SQL query 발생 – 라이선스 이슈 (BSD+Patents) 약 한달 전 해결! (MIT+OWFa) http://graphql.org API 버전 호환성 유지가 용이함
DataLoader 사용! ü 여러 resolve() 메소드에서 각각 다른 object ID로 loader.load()를 호출하면, lazy evaluation을 통해 "SELECT … WHERE id IN (…)" query 1번으로 줄일 수 있다 – Python asyncio 용으로도 잘 나와있음 (https://github.com/syrusakbary/aiodataloader) • 또다른 문제점 – Batching을 하기 때문에 같은 WHERE 조건을 가진 경우에만 적용 가능 – 필터링 조건을 자유롭게 추가할 수 있어야 유연한 API를 만들 수 있음 • 또다른 해결책 – DataLoader를 조건식별로 생성 및 캐시해주는 DataLoaderManager 제작 – functools.lru_cache()처럼 조건 argument를 이용한 DataLoader object cache 사용
분 모십니다! (오픈소스 기여 or 래블업 지원!) ü 삽도 같이 뜨면 낫겠죠? – 2017년 10월 v1.0 릴리즈 ü (드디어 기다리고 기다리던) 설치 및 개발 매뉴얼 제공! • 향후 로드맵 – 스케줄러 기능 강화 ü Hybrid cloud 및 on-premise 연동 – 오토스케일링 기능 강화 ü 장시간 연산 세션을 위한 scale-in protection ü cpu/memory/gpu slot 여유 용량에 따라 cold/hot instance group 운영
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU 질문이나 채용 문의는 [email protected] 으로!](https://files.speakerdeck.com/presentations/e569cdfdb11640b580a6e22e4dbb7df7/slide_41.jpg){kind=link}