Processing data at scale usually results in struggling with performance, strict SLA, limited hardware etc. I've struggled with cutting Spark SQL query run-time and found the culprit! This culprit, and SOLUTION! I would like to share with you. Today in the world of Big Data and Spark we are processing high volume transactions. Catalyst is the Spark SQL query optimizer and in this talk, you will learn how to fully utilize Catalyst optimization power in order to make our queries as fast as possible, by pushing down actions and trying to avoid UDFs as much as possible and maximizing performance.
{kind=link}
![About me – Adi Polak @adipolak [email protected] https://medium.com/@adipolak](https://files.speakerdeck.com/presentations/2563edbcf89d449da4be492b18a322c2/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
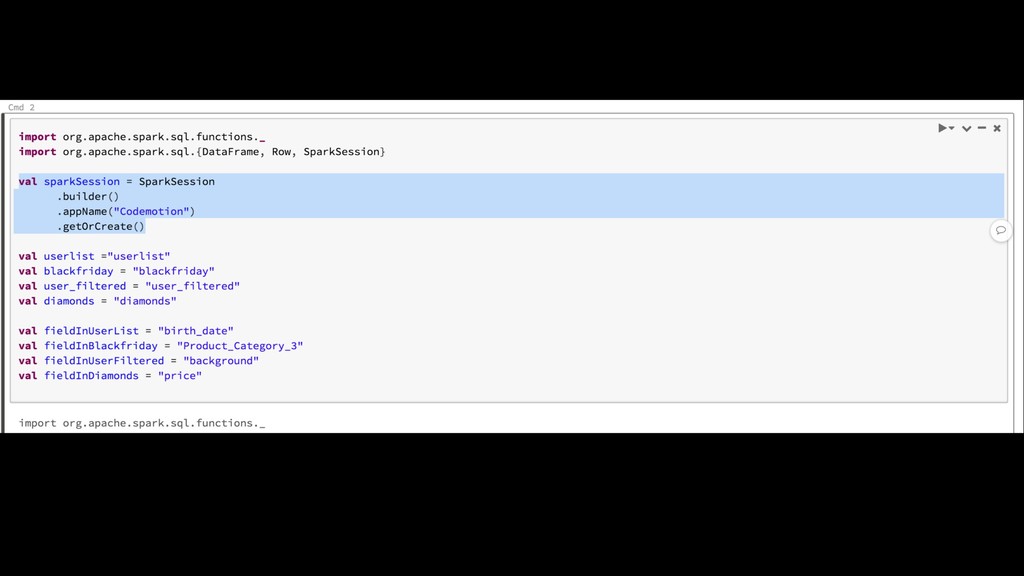{kind=link}
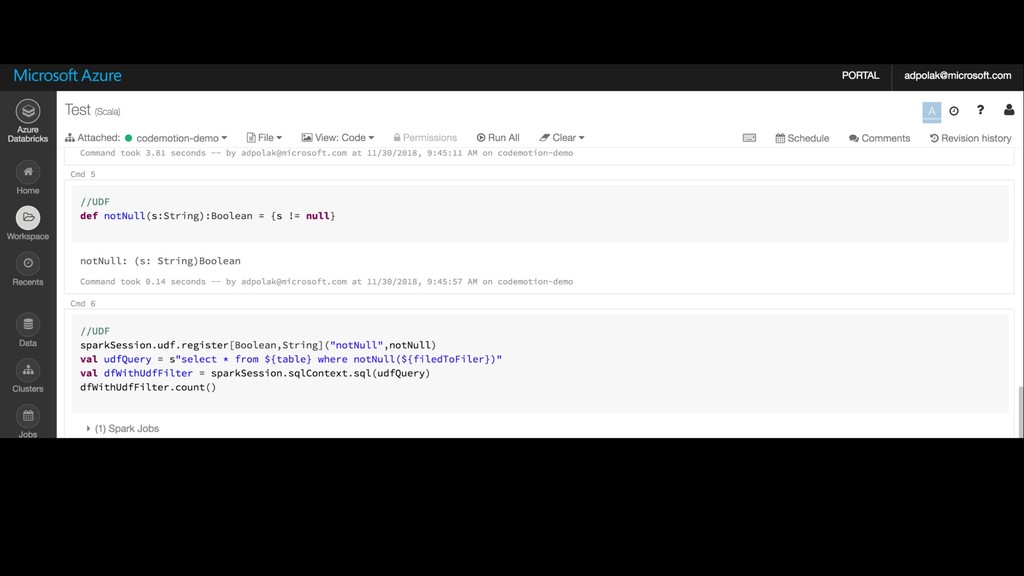{kind=link}
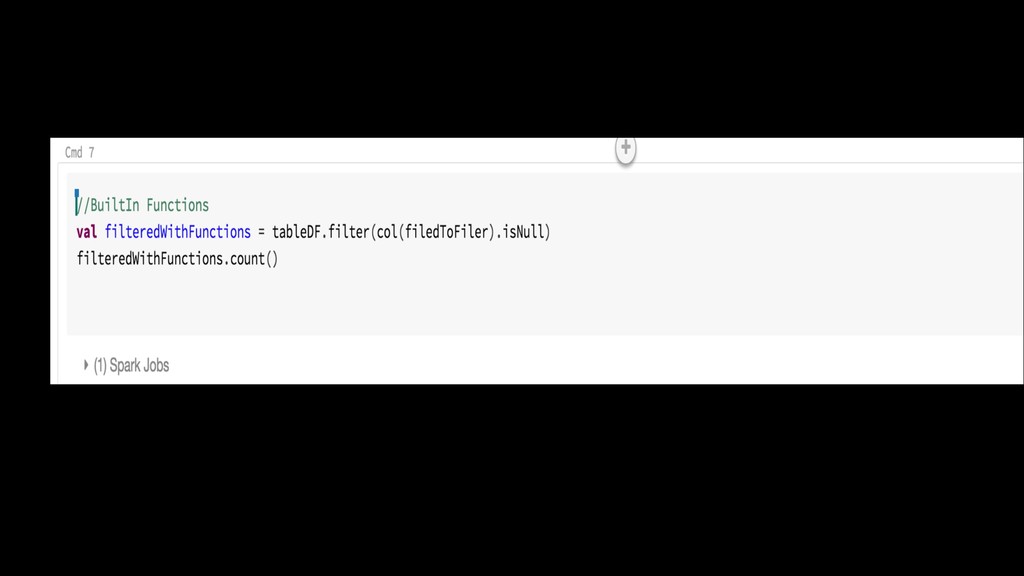{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
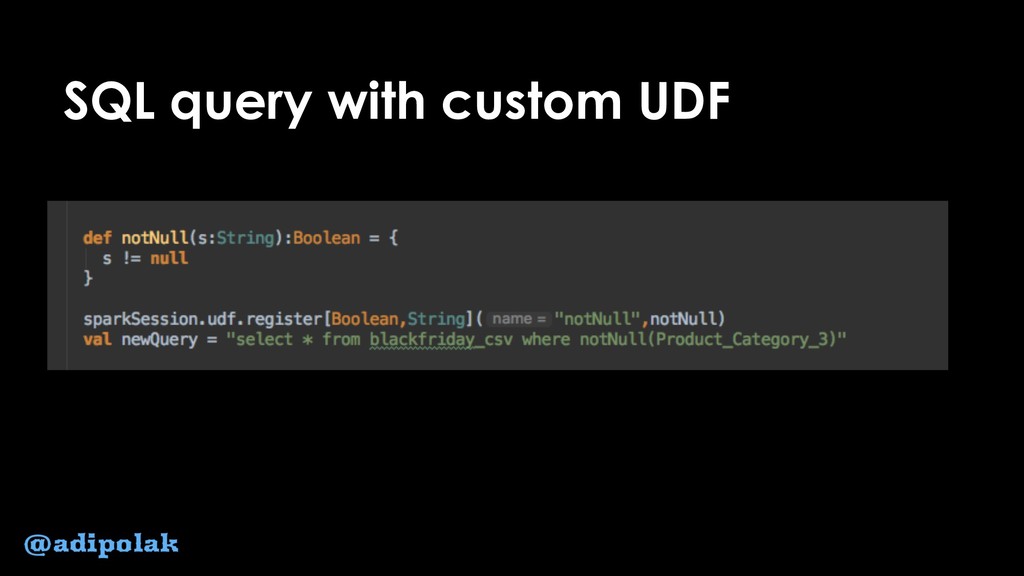{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
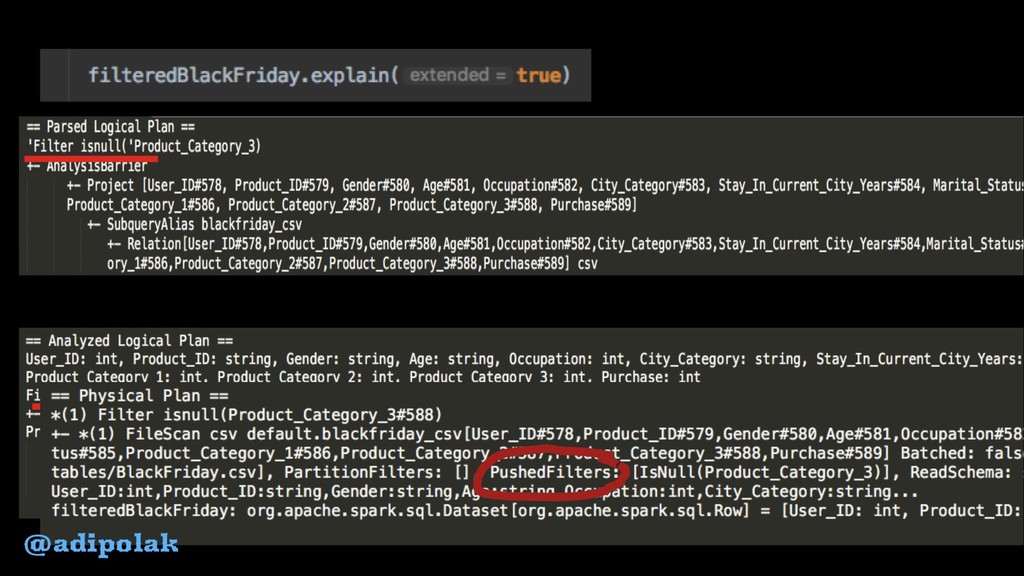{kind=link}
{kind=link}
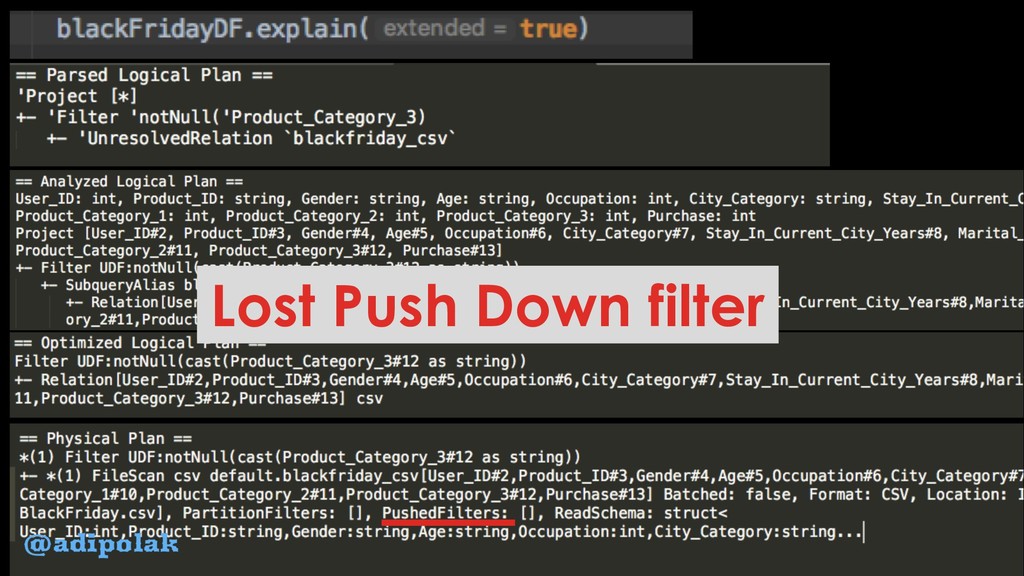{kind=link}
{kind=link}
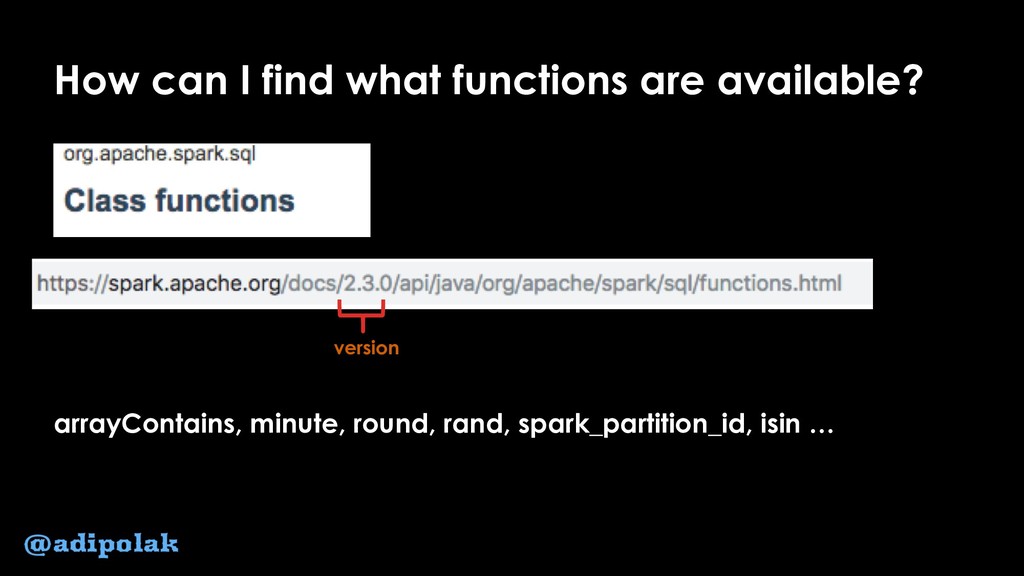{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GRATZIE @adipolak @adipolak [email protected]](https://files.speakerdeck.com/presentations/2563edbcf89d449da4be492b18a322c2/slide_35.jpg){kind=link}