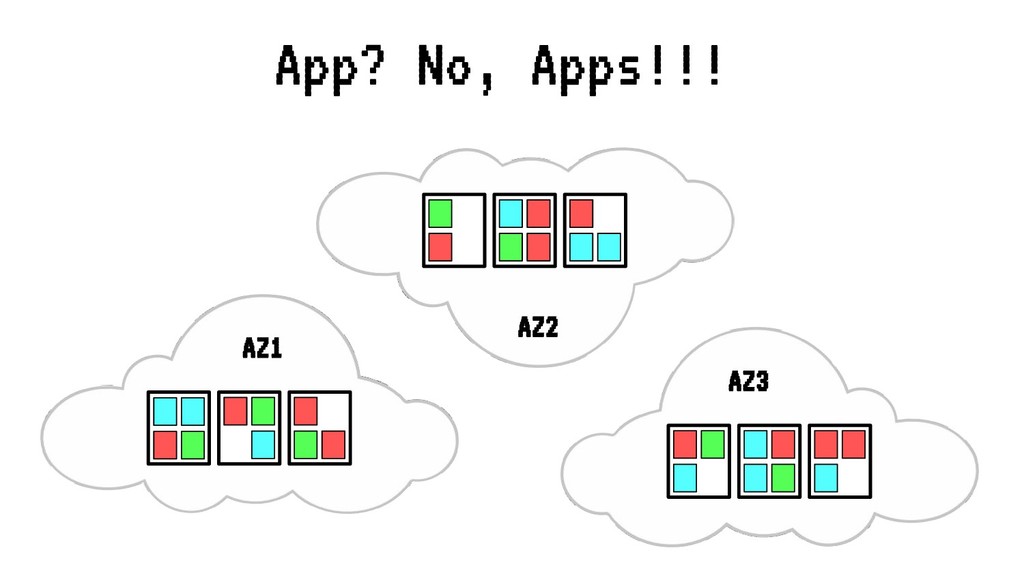
En BBVA construimos sistemas altamente distribuidos en alta disponibilidad donde diferentes arquitecturas orientadas a servicios y microservicios realizan varias despliegues al día, escalando según sea necesario.
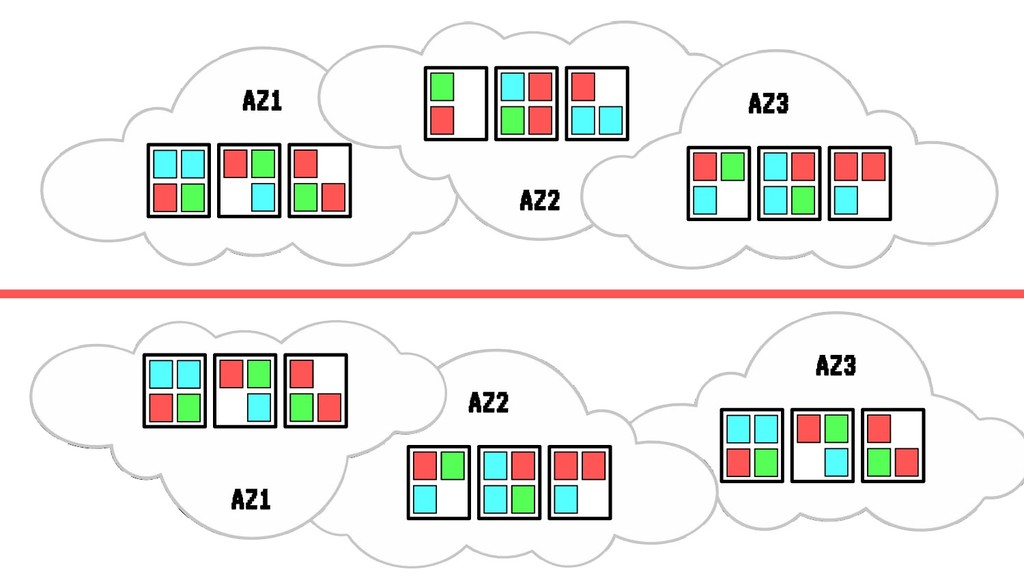
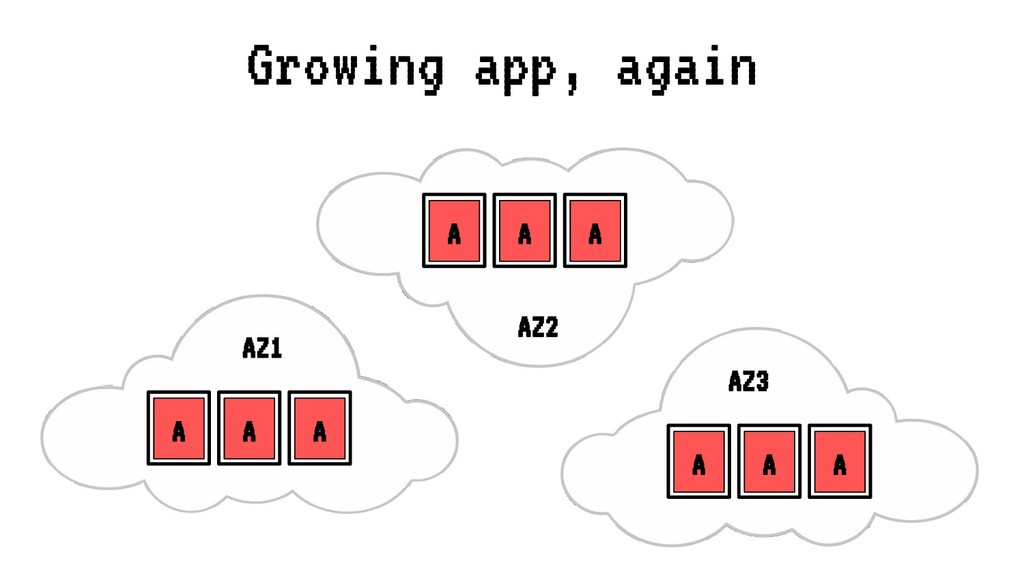
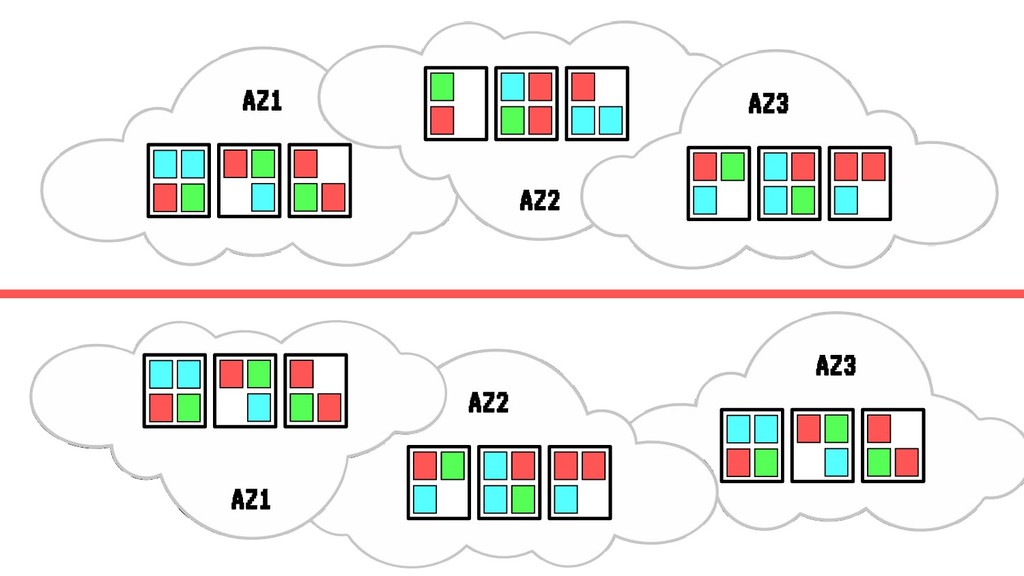
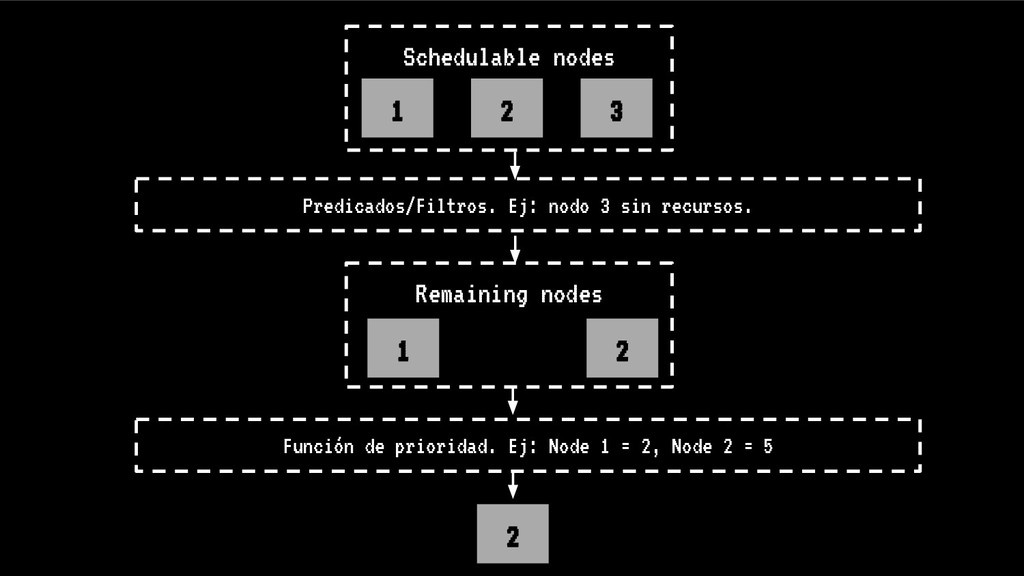
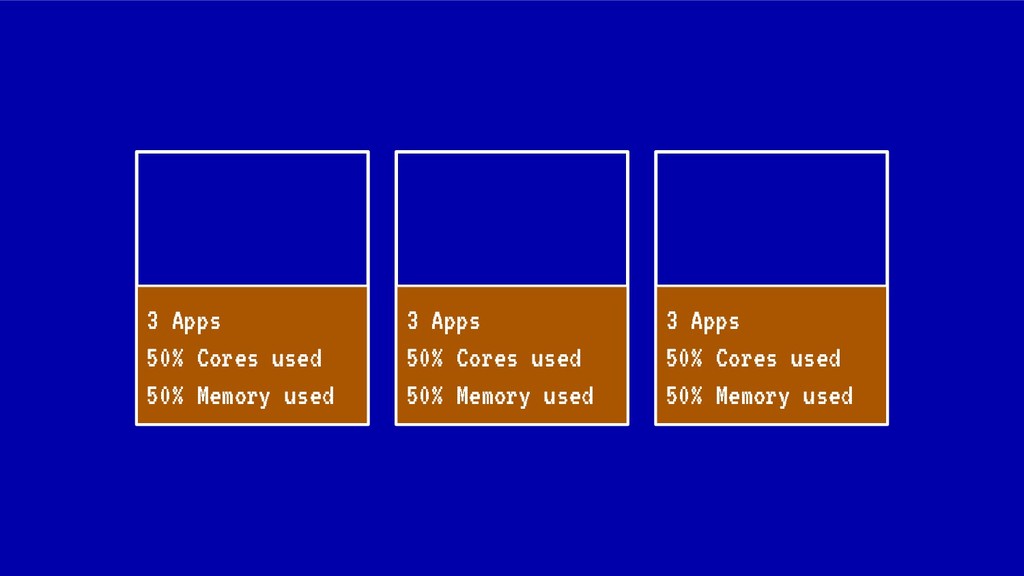
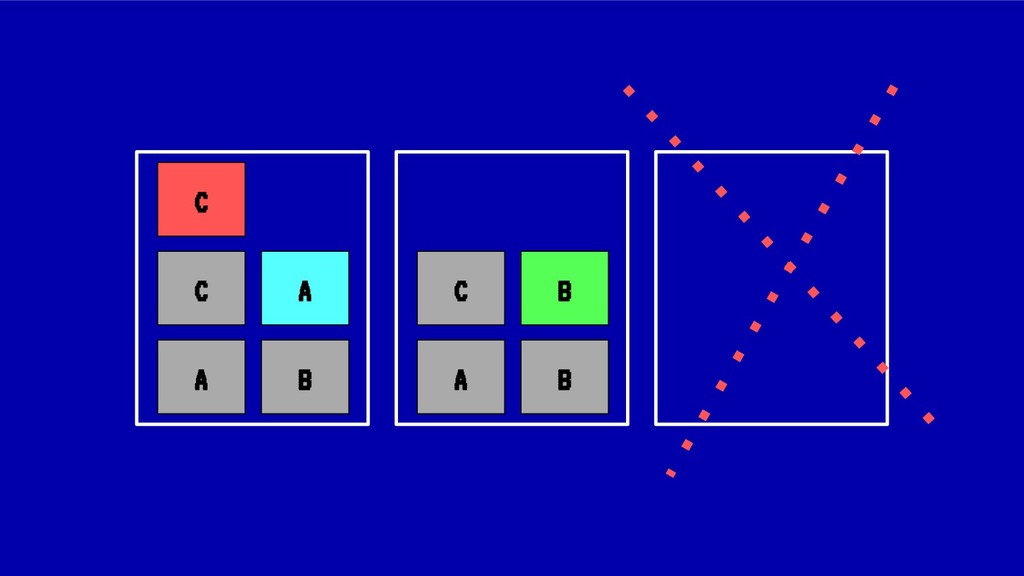
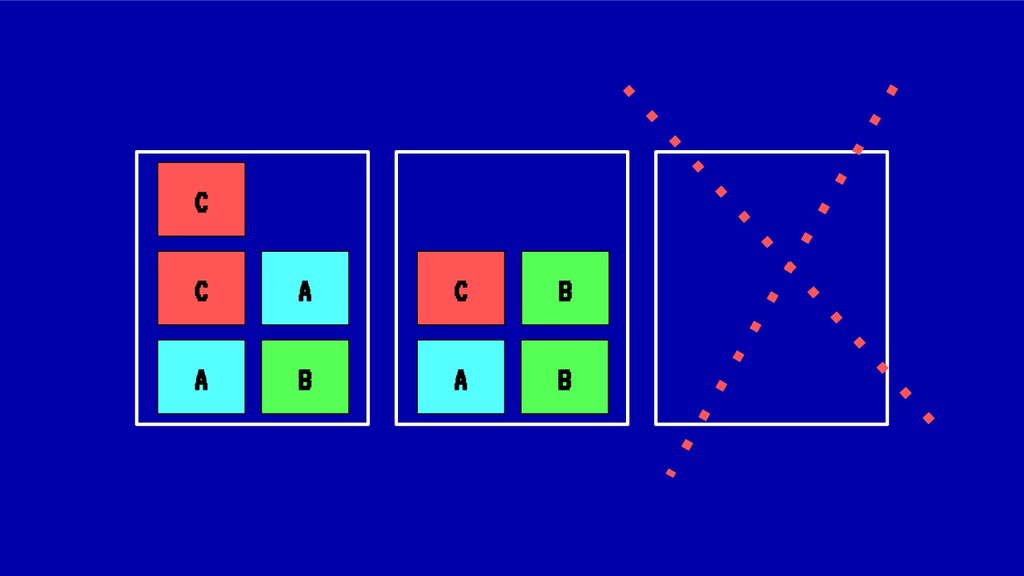
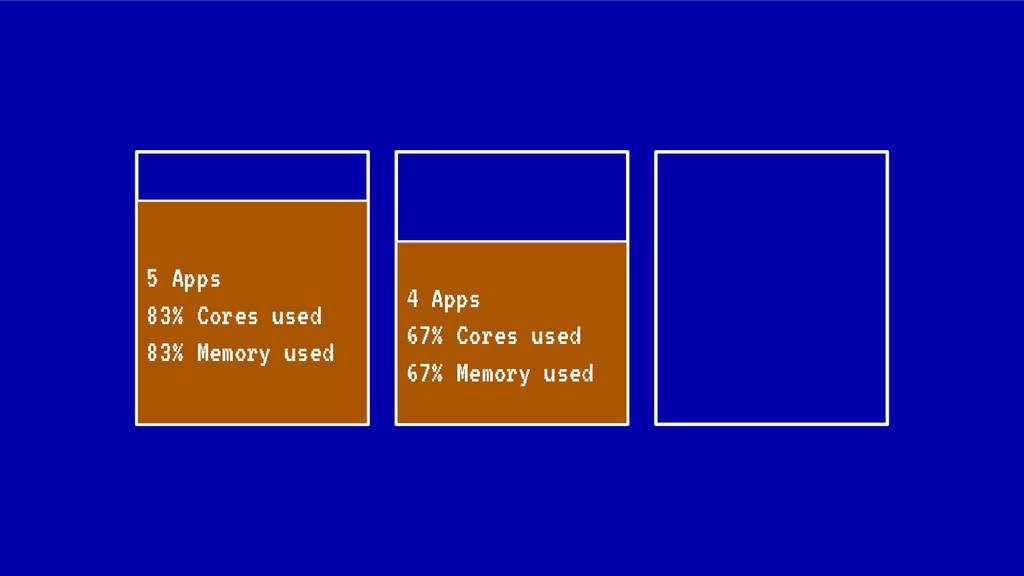
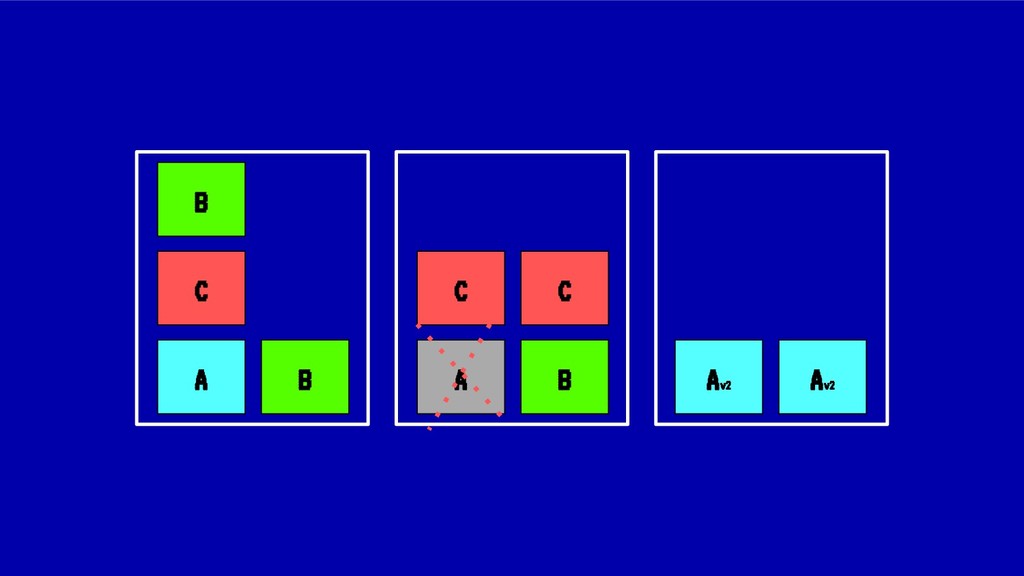
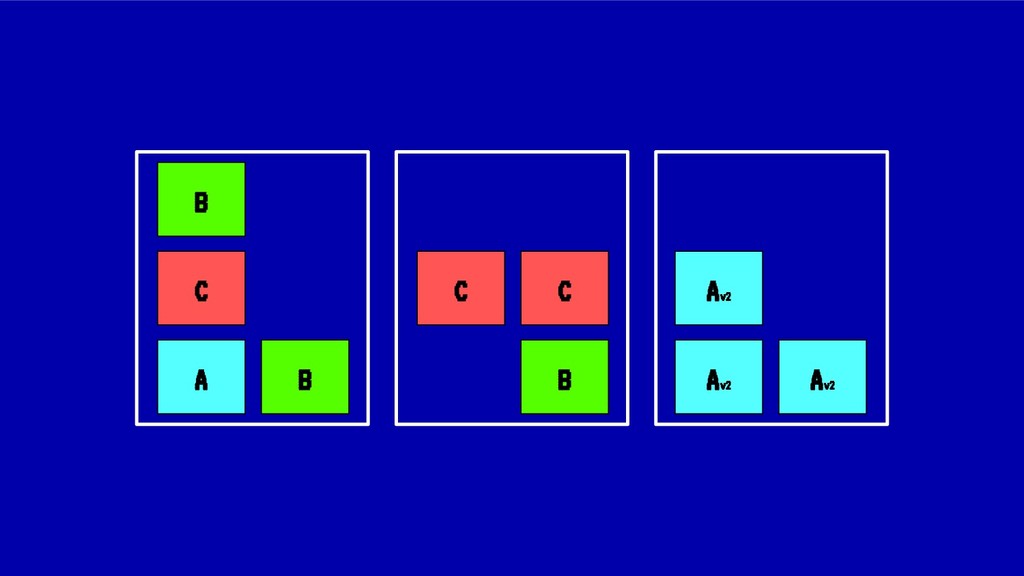
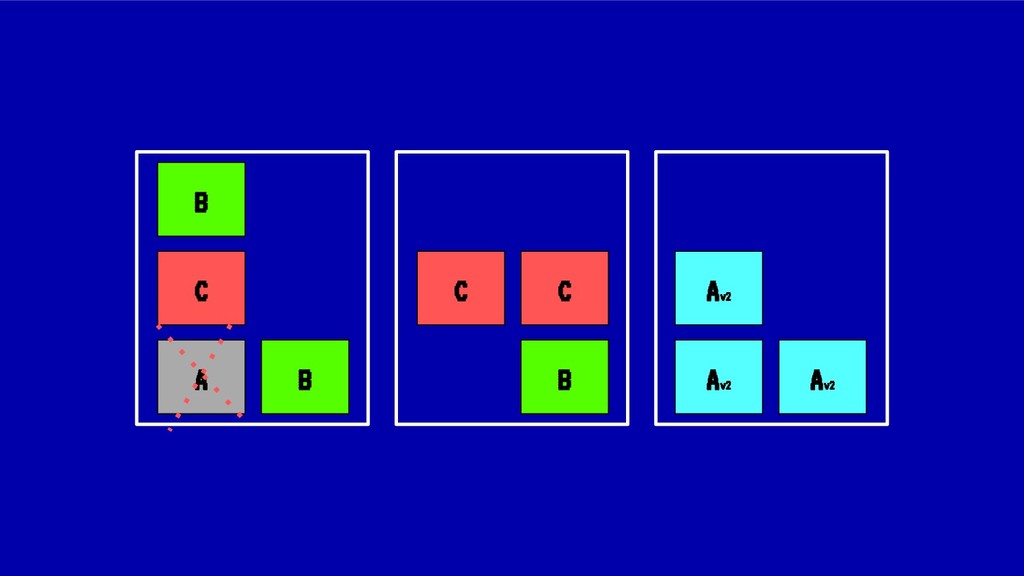
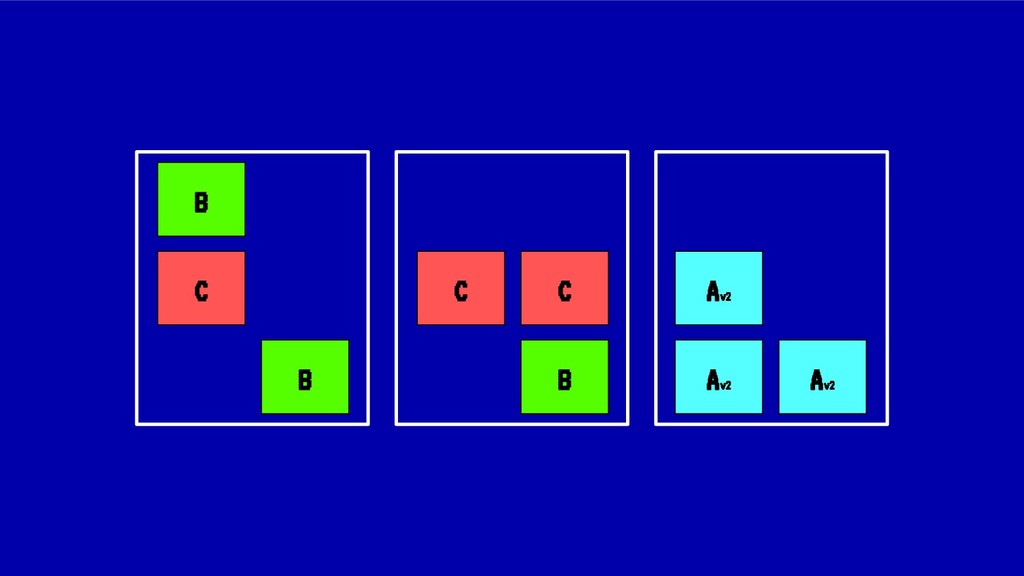
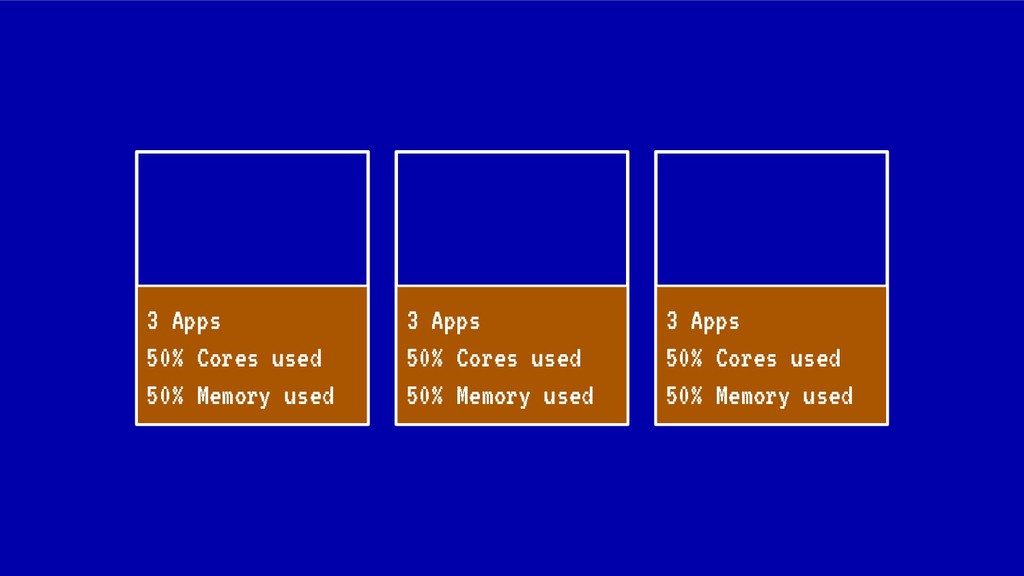
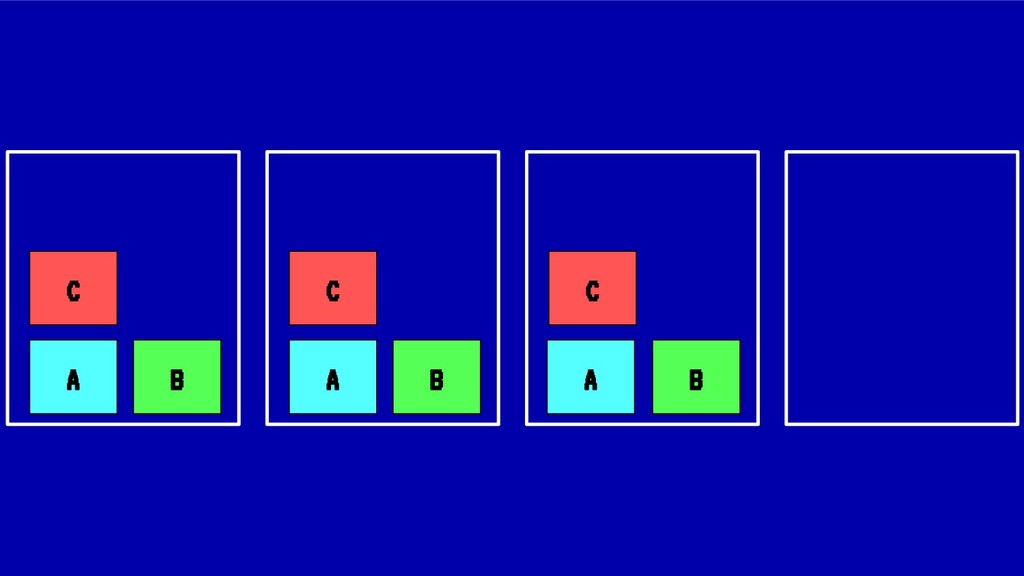
Sin embargo, cada vez que se realiza un despliegue, escalado o borrado de una aplicación, nuestro cluster tiende a fragmentar recursos o desbalancearse, haciendo un pobre uso de CPU o memoria ante situaciones de stress. En situaciones extremas esto puede llegar a poner en peligro la alta disponibilidad de nuestros sistemas.
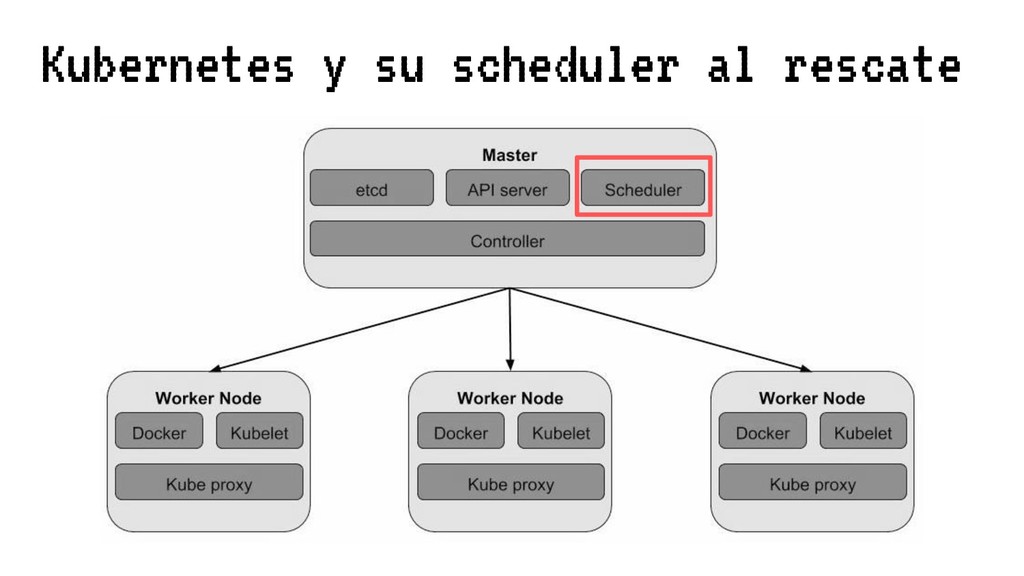
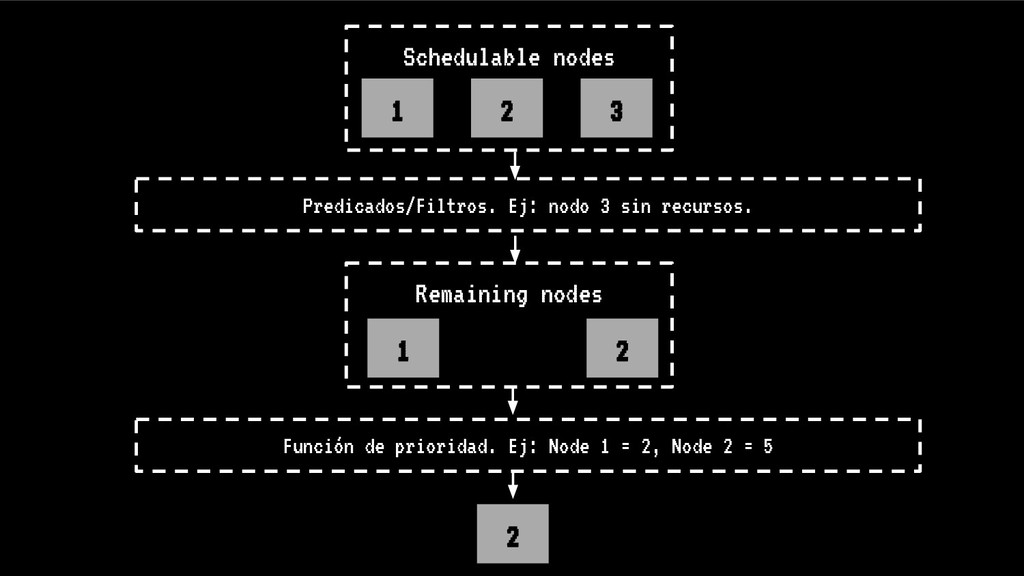
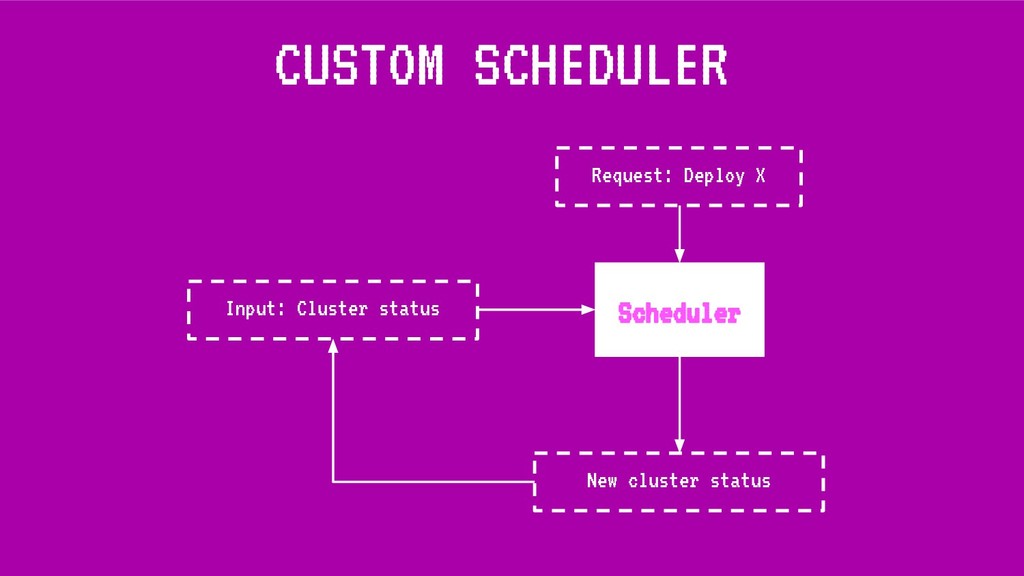
En esta charla trataremos la fragmentación en clusters de kubernetes para entenderla, medirla y mantenerla dentro de niveles óptimos. Veremos cómo hacemos en el equipo de PaaS de BBVA para desplegar sistemas altamente distribuidos y donde conviven aplicaciones altamente heterogéneas y con diferentes necesidades de recursos y quotas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
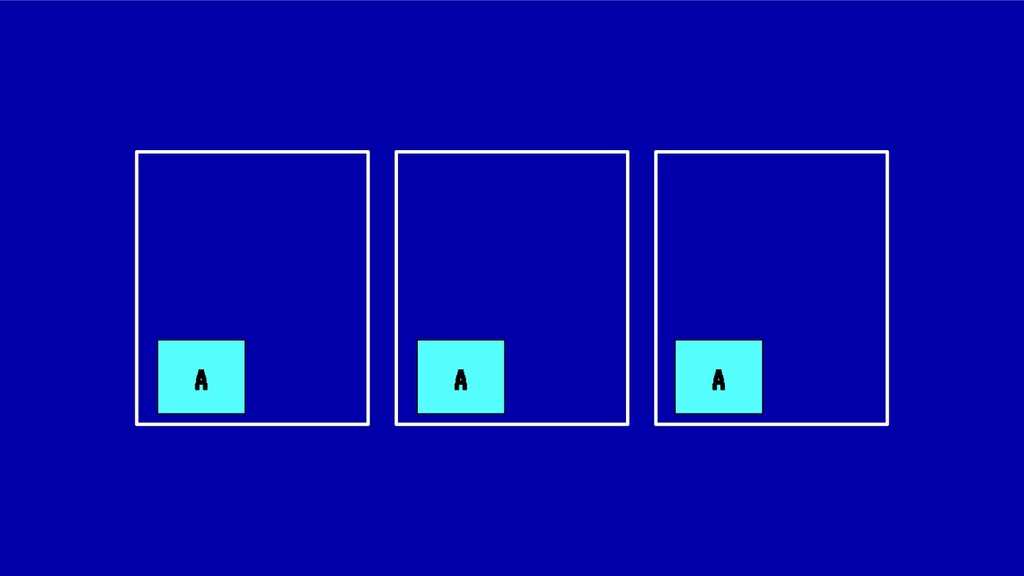
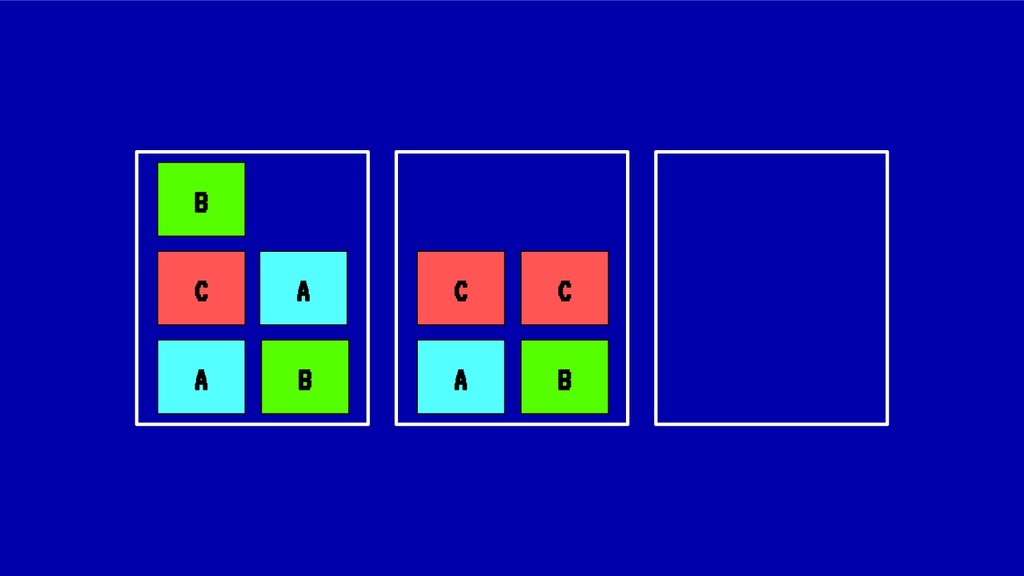
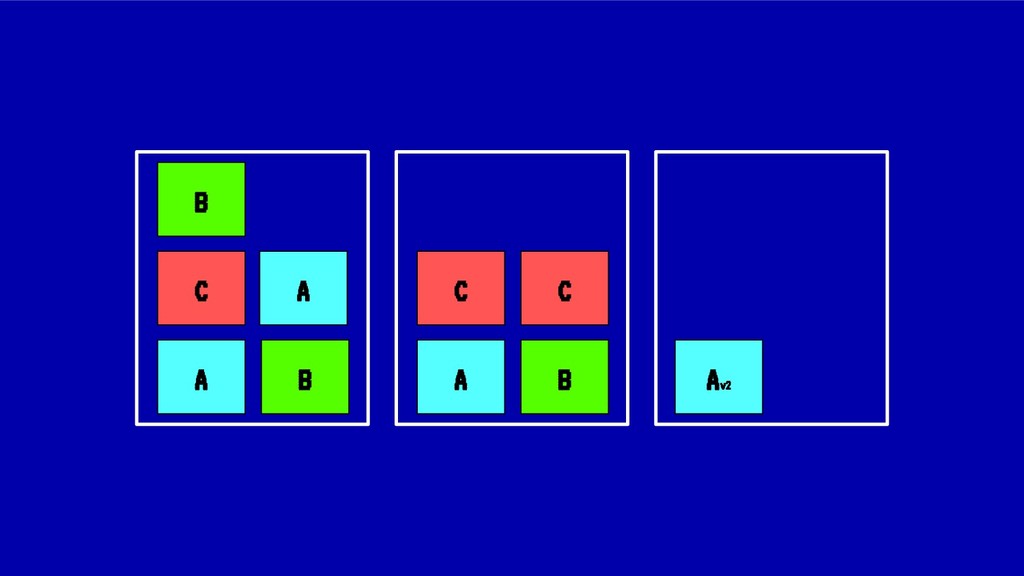
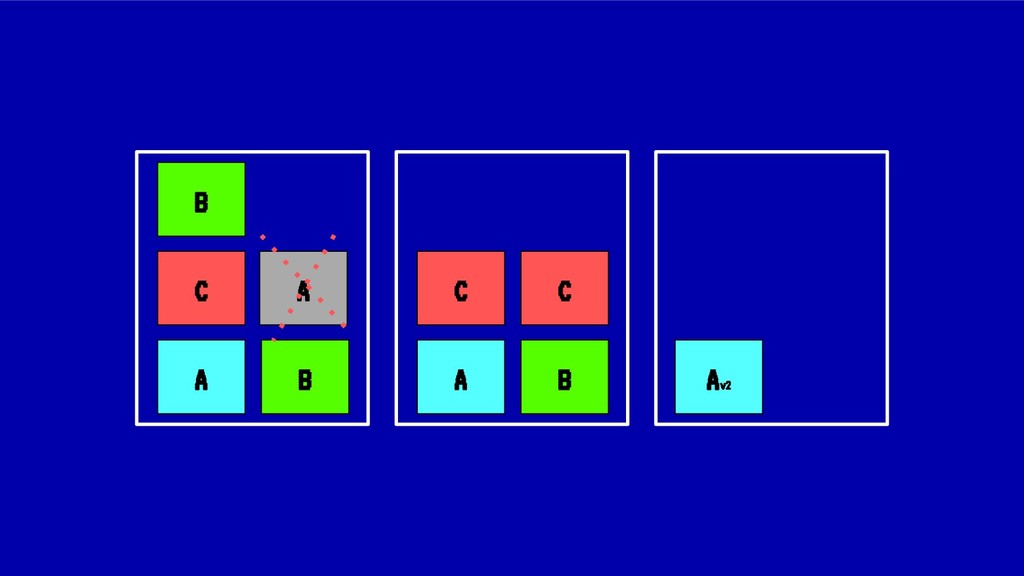
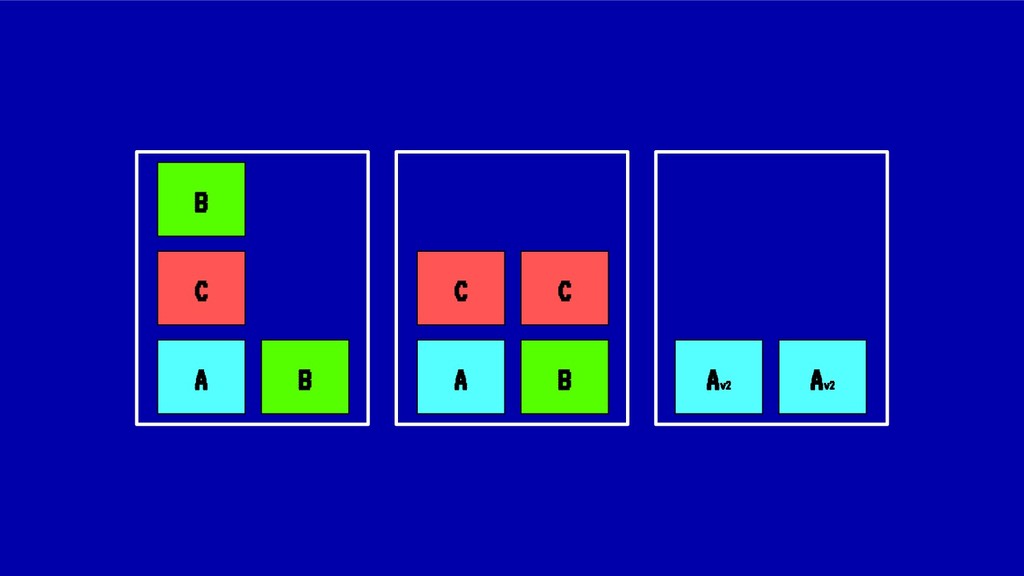
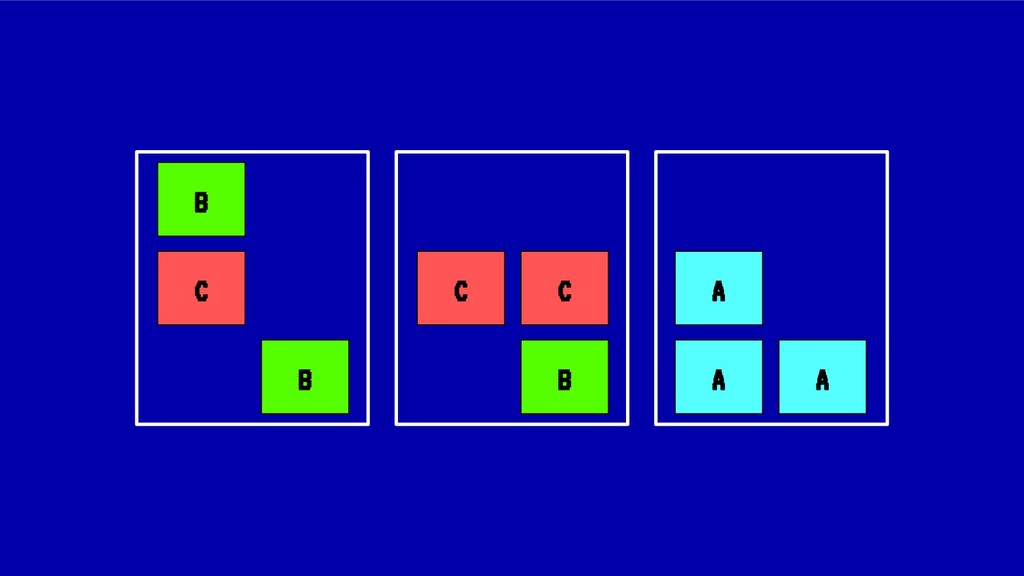
![MIDIENDO LA FRAGMENTACIÓN Para el caso anterior: IdealStatus(X) = [1,1,1,1,1,1,1,1,1]](https://files.speakerdeck.com/presentations/8846bedf2967411bb344e6fc9647ff40/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
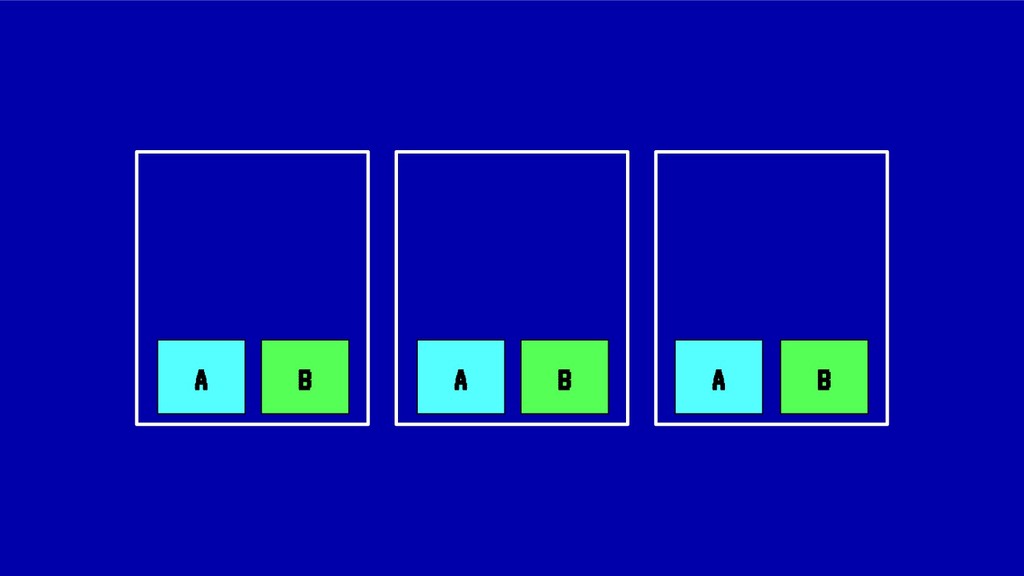
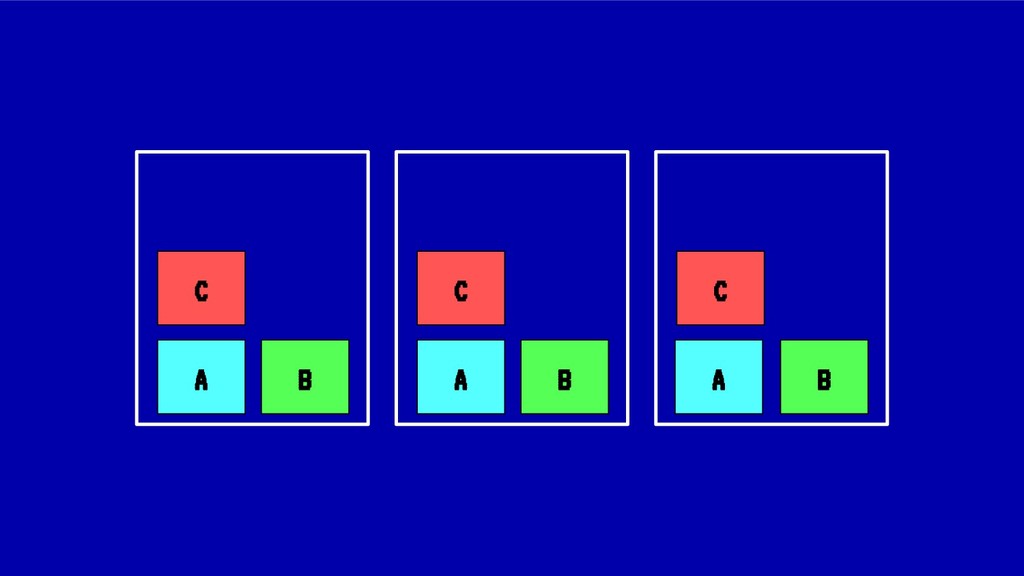
![MIDIENDO LA FRAGMENTACIÓN Para nuestro ejemplo original: IdealStatus(A) = [1,1,1]](https://files.speakerdeck.com/presentations/8846bedf2967411bb344e6fc9647ff40/slide_50.jpg){kind=link}
![MIDIENDO LA FRAGMENTACIÓN Para nuestro ejemplo original: IdealStatus(B) = [1,1,1]](https://files.speakerdeck.com/presentations/8846bedf2967411bb344e6fc9647ff40/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}