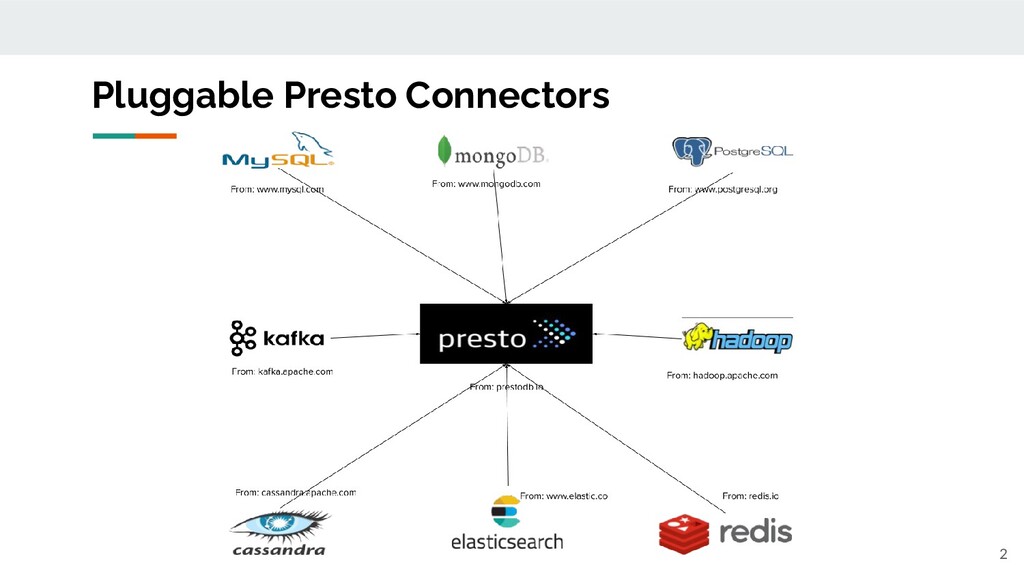
Tech Talk Series – Level 102 for Presto: Getting Started with PrestoDB
In this tech talk, we’ll build on what we learned in Level 101 and show you how easy it is to get started with PrestoDB. We’ll also dive deeper into key features and connectors.
the Tech Talk Series for Presto Getting started with PrestoDB? What’s the difference? Da Cheng Software Engineer, Twitter Dipti Borkar Co-Founder & CPO, Ahana
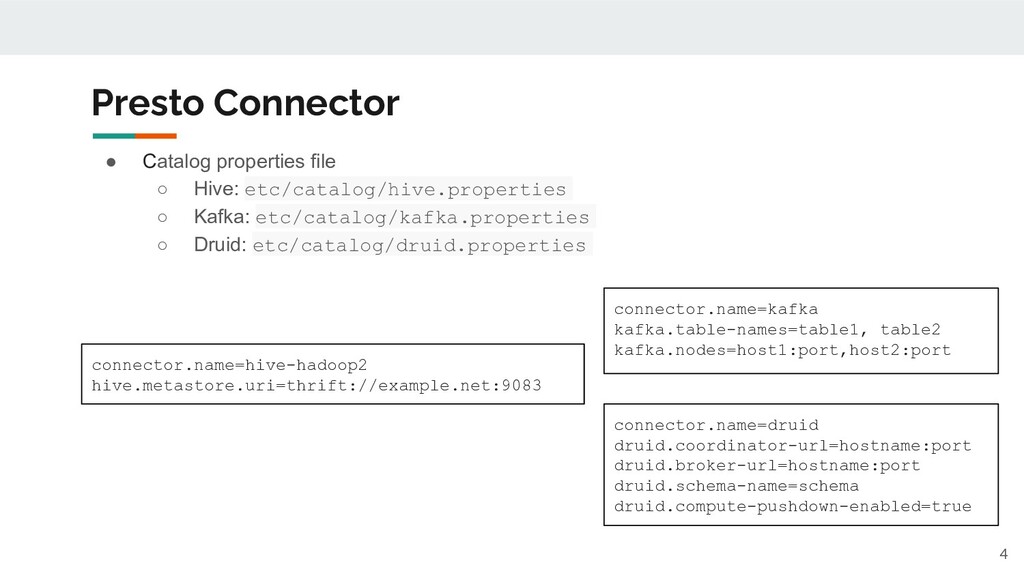
Access HDFS datasets, e.g., Hive ◦ Extend to real-time event streams, e.g., Kafka ◦ Push-down/offload computation to data engines, e.g., Druid • Data model from users’ perspective ◦ Catalog: Contains schemas from a datasource specified by the connector ◦ Schema: Namespace to organize tables. ◦ Table: Set of unordered rows organized into columns with types. SHOW TABLES FROM hive.default; select * from hive.default.employees limit 1;
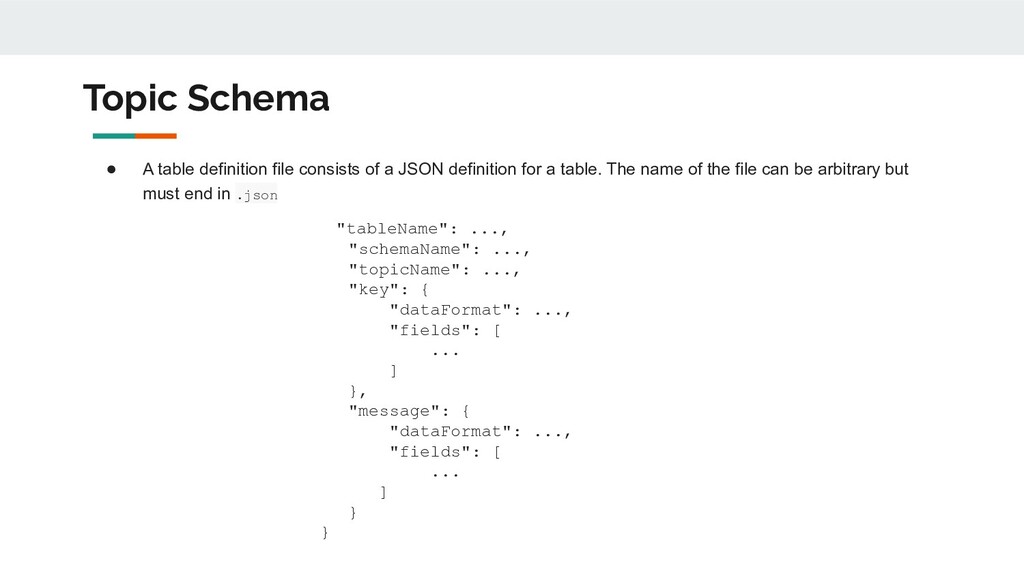
JSON definition for a table. The name of the file can be arbitrary but must end in .json "tableName": ..., "schemaName": ..., "topicName": ..., "key": { "dataFormat": ..., "fields": [ ... ] }, "message": { "dataFormat": ..., "fields": [ ... ] } }
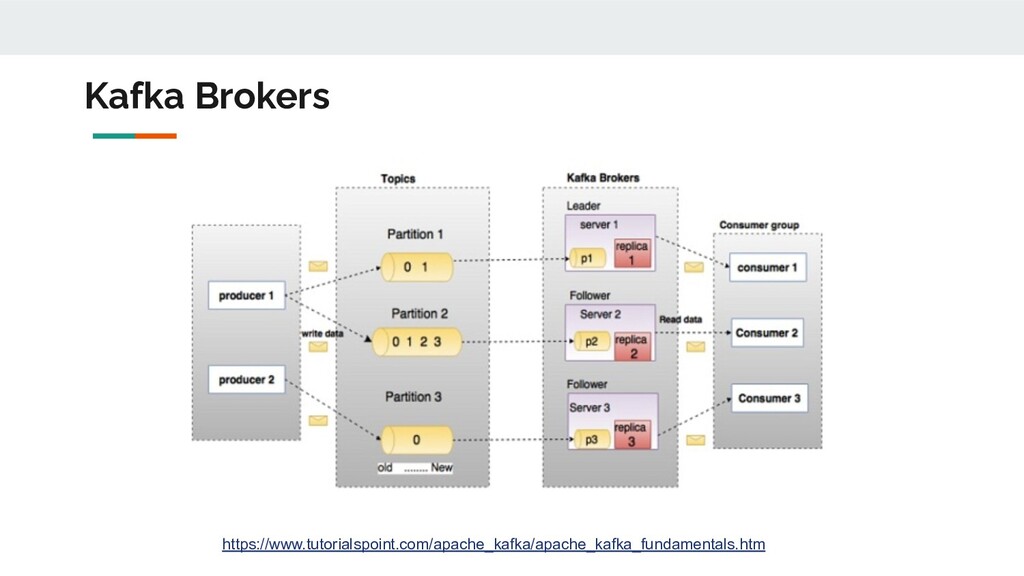
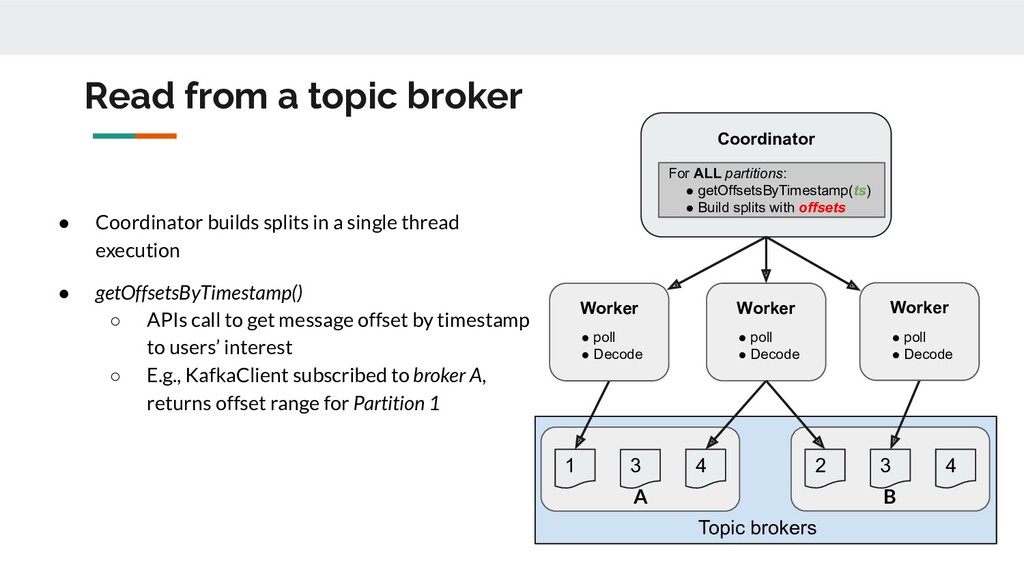
ALL partitions: • getOffsetsByTimestamp(ts) • Build splits with offsets Worker • poll • Decode Worker • poll • Decode Worker • poll • Decode Read from a topic broker • Coordinator builds splits in a single thread execution • getOffsetsByTimestamp() ◦ APIs call to get message offset by timestamp to users’ interest ◦ E.g., KafkaClient subscribed to broker A, returns offset range for Partition 1 A B
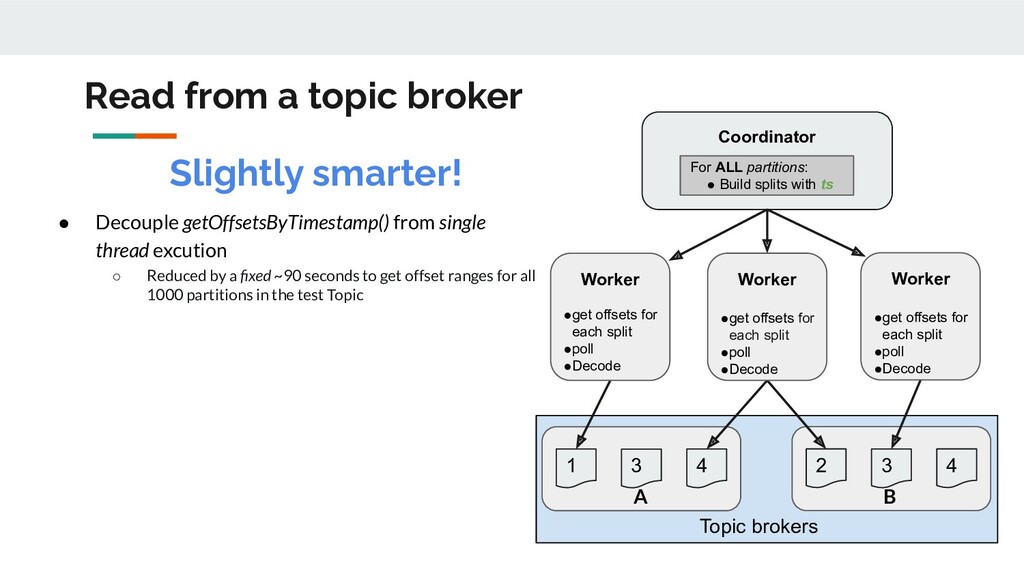
ts 4 3 1 4 3 2 Worker •get offsets for each split •poll •Decode Worker •get offsets for each split •poll •Decode Worker •get offsets for each split •poll •Decode • Decouple getOffsetsByTimestamp() from single thread excution ◦ Reduced by a fixed ~90 seconds to get offset ranges for all 1000 partitions in the test Topic Slightly smarter! Read from a topic broker A B
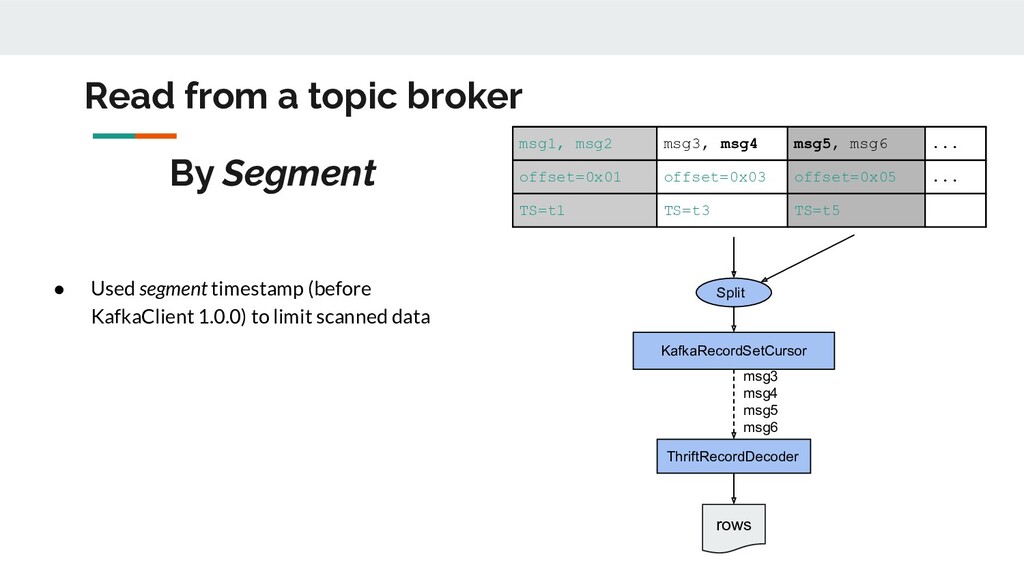
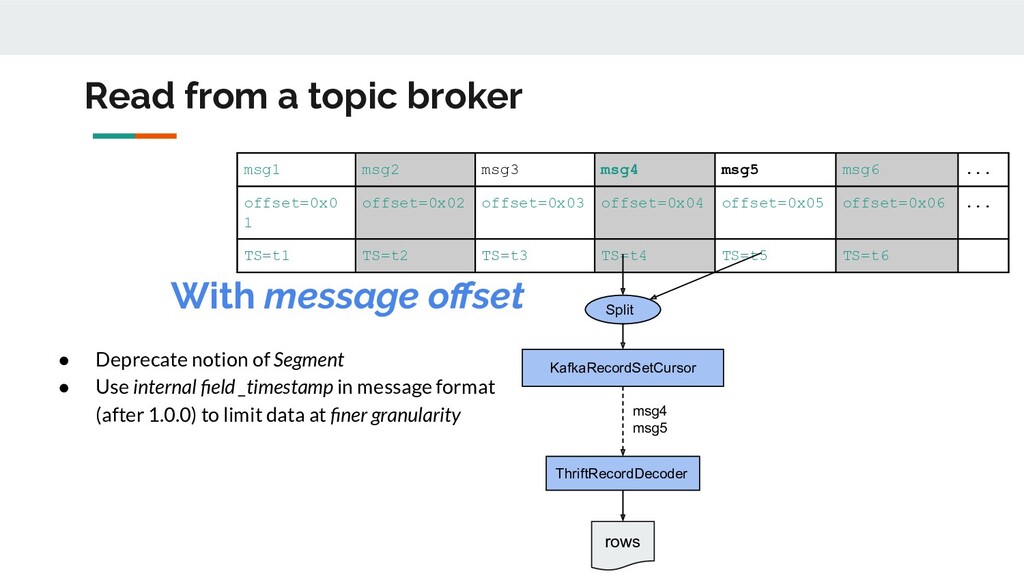
... TS=t1 TS=t3 TS=t5 • Used segment timestamp (before KafkaClient 1.0.0) to limit scanned data Split ThriftRecordDecoder msg3 msg4 msg5 msg6 KafkaRecordSetCursor rows By Segment Read from a topic broker
WHERE timestamp_ms between cast(to_unixtime(CAST('2019-11-13 21:00:00' AS timestamp))*1000 AS bigint) AND cast(to_unixtime(CAST('2019-11-13 21:01:00' AS timestamp))*1000 AS bigint) AND _timestamp between cast(to_unixtime(CAST('2019-11-13 21:00:00' AS timestamp))*1000 AS bigint) AND cast(to_unixtime(CAST('2019-11-13 21:01:00' AS timestamp))*1000 AS bigint) GROUP BY ip_address ORDER BY cnt DESC LIMIT 10; Performance • Query Event time Processing time
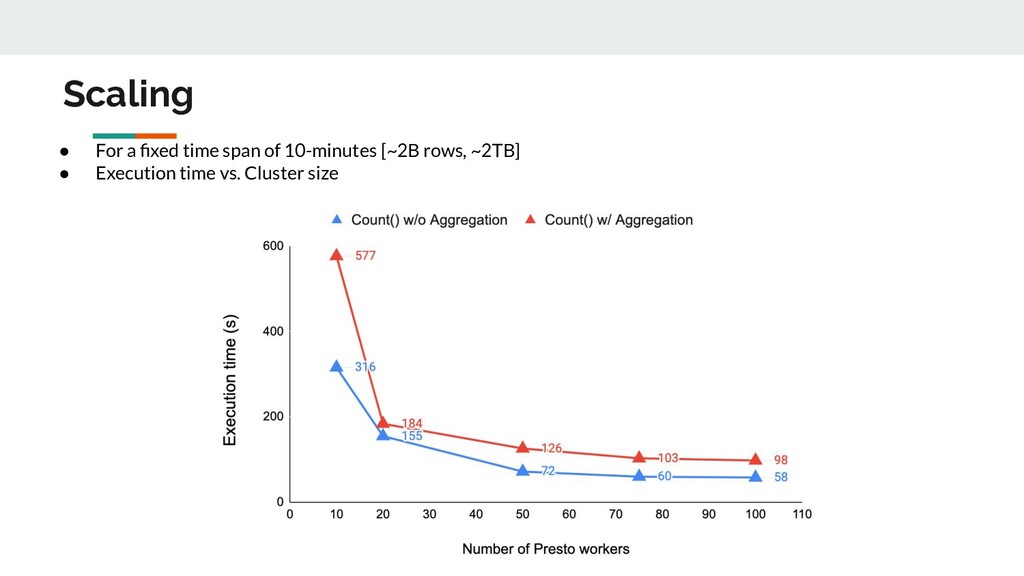
1.1.1 0:21 1:17 7:15 • Execution time ◦ Use a cluster of 50 Presto workers ◦ Messages from one partition is packaged in a single split, # splits is fixed ◦ Execution time increases linearly with time span (which decides message range) of users’ interests • Data scanned Time span 2 min 10 min 1 hour Kafka-clients 1.1.1 470GB 2.21TB 13.1TB
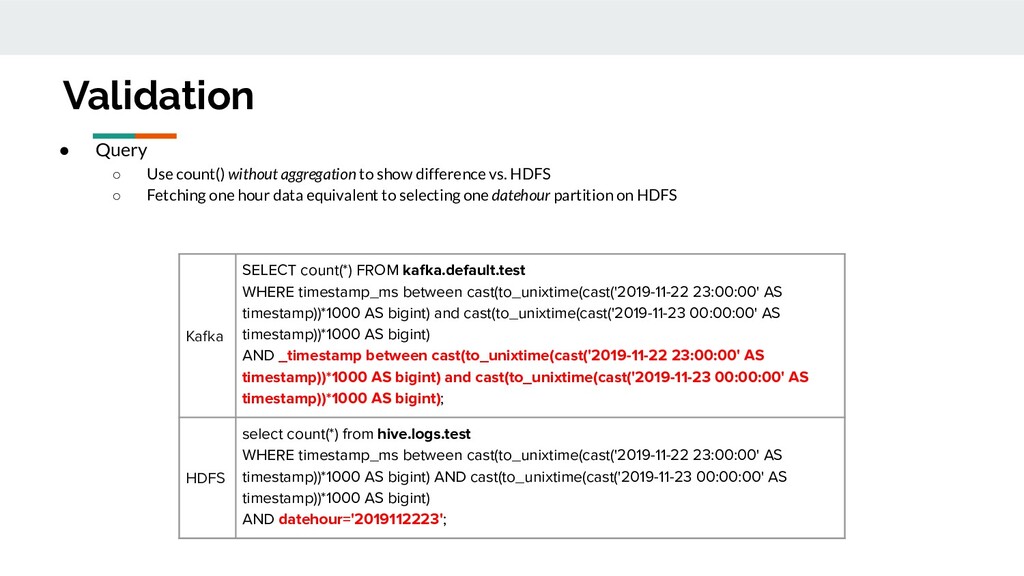
23:00:00' AS timestamp))*1000 AS bigint) and cast(to_unixtime(cast('2019-11-23 00:00:00' AS timestamp))*1000 AS bigint) AND _timestamp between cast(to_unixtime(cast('2019-11-22 23:00:00' AS timestamp))*1000 AS bigint) and cast(to_unixtime(cast('2019-11-23 00:00:00' AS timestamp))*1000 AS bigint); HDFS select count(*) from hive.logs.test WHERE timestamp_ms between cast(to_unixtime(cast('2019-11-22 23:00:00' AS timestamp))*1000 AS bigint) AND cast(to_unixtime(cast('2019-11-23 00:00:00' AS timestamp))*1000 AS bigint) AND datehour='2019112223'; • Query ◦ Use count() without aggregation to show difference vs. HDFS ◦ Fetching one hour data equivalent to selecting one datehour partition on HDFS
ConnectorSplitManager ◦ Divide data into splits • ConnectorSplit ◦ Split data range ◦ Predicate/Aggregation/Limit pushdown • ConnectorRecordCursor ◦ Transform underlying storage data into Presto internal page/block 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}