'__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__getstate__', '__hash__', '__init__', '__iter__', '__module__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_content', '_content_consumed', 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url']
{kind=link}
{kind=link}
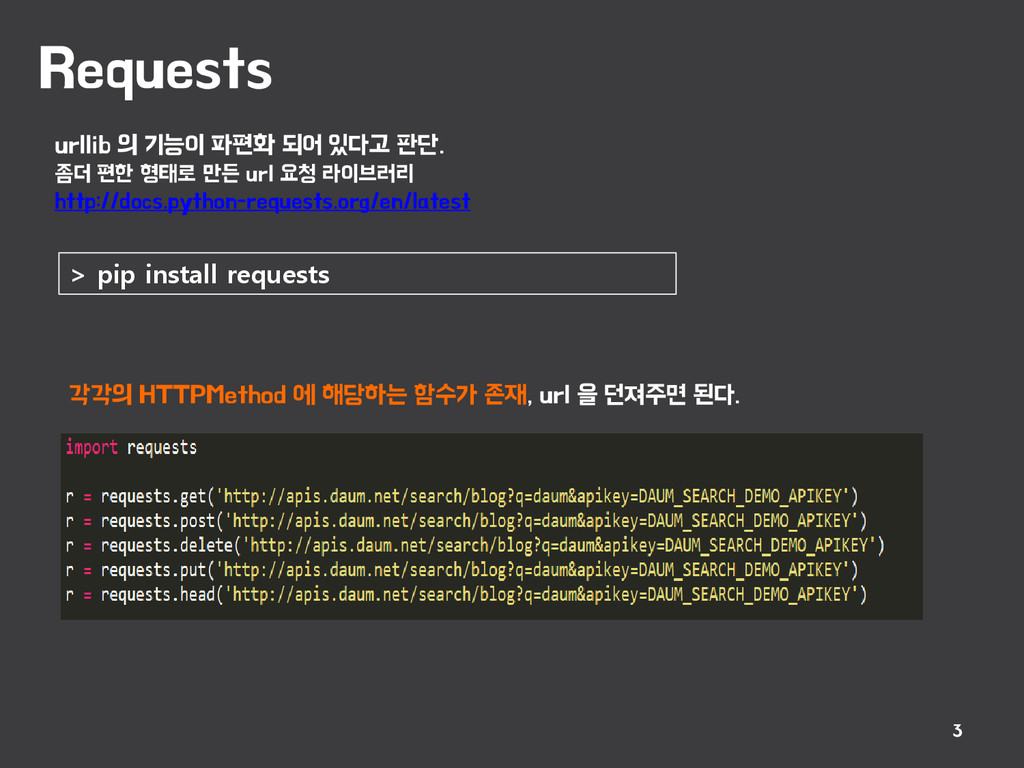{kind=link}
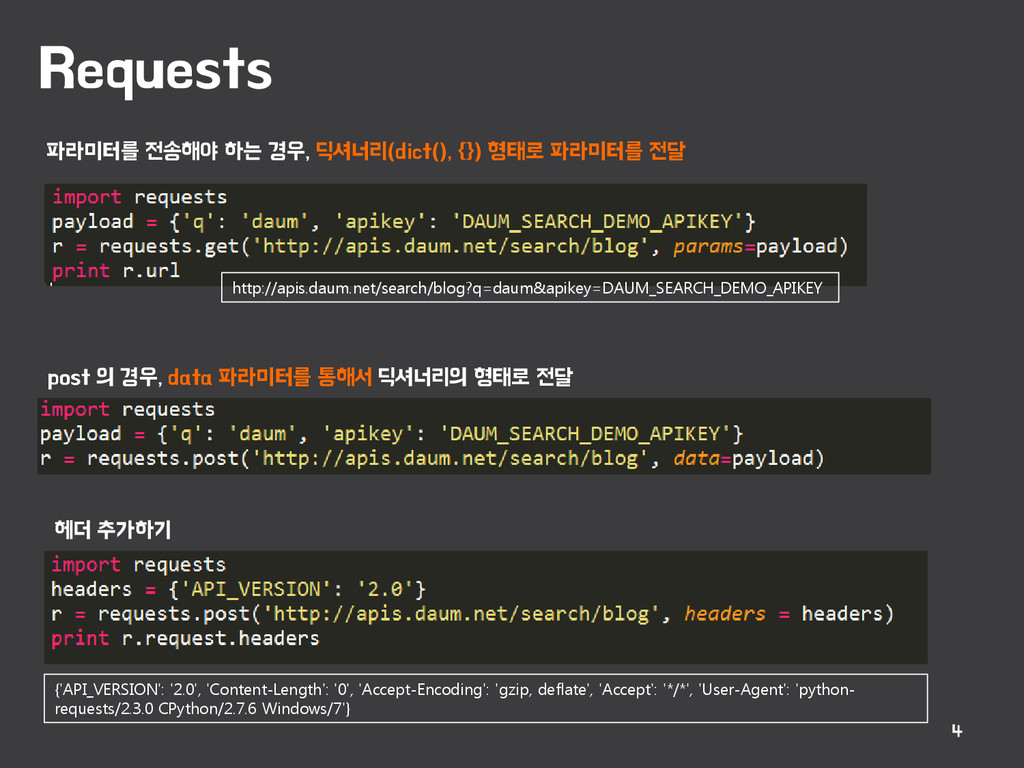{kind=link}
{kind=link}
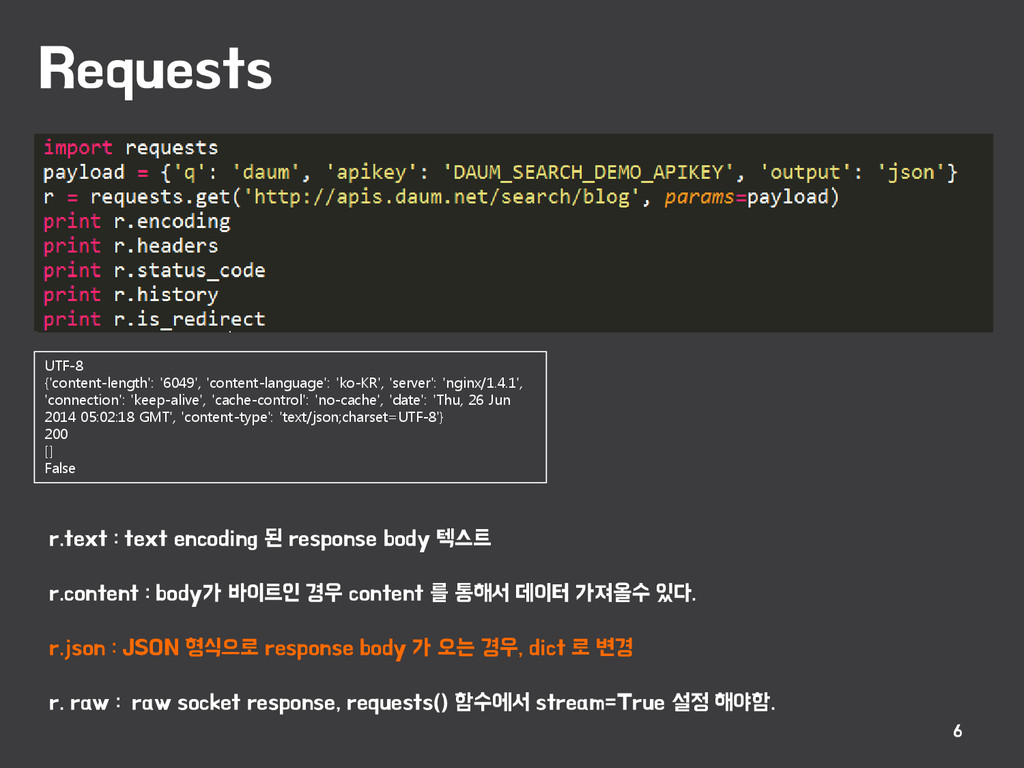{kind=link}
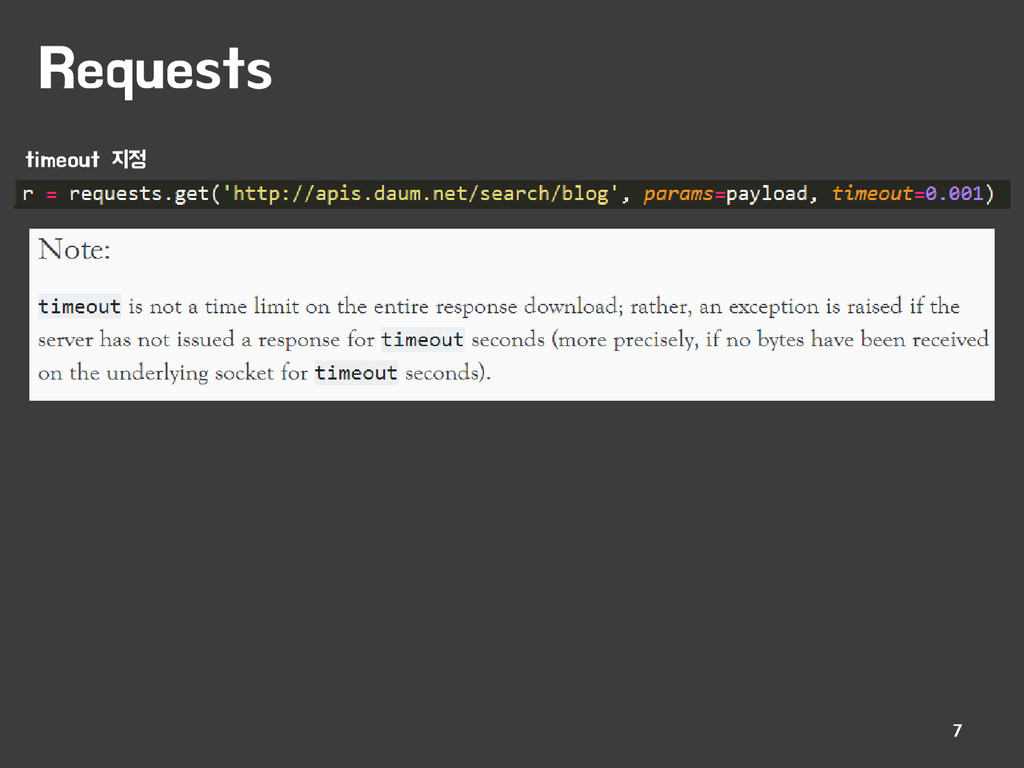{kind=link}
{kind=link}
{kind=link}
{kind=link}
![BS4(BeautifulSoup4) 11 <title>The Dormouse's story</title> title The Dormouse's story [u'title']](https://files.speakerdeck.com/presentations/457a1c55c973408daacfb77461fd249e/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
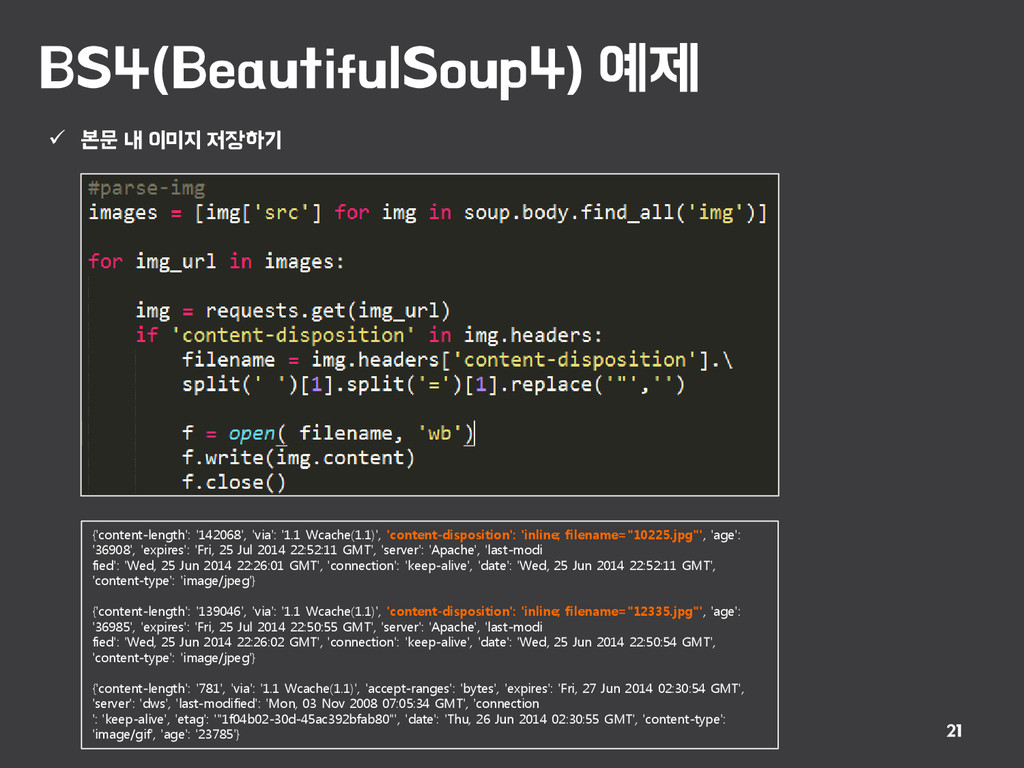{kind=link}
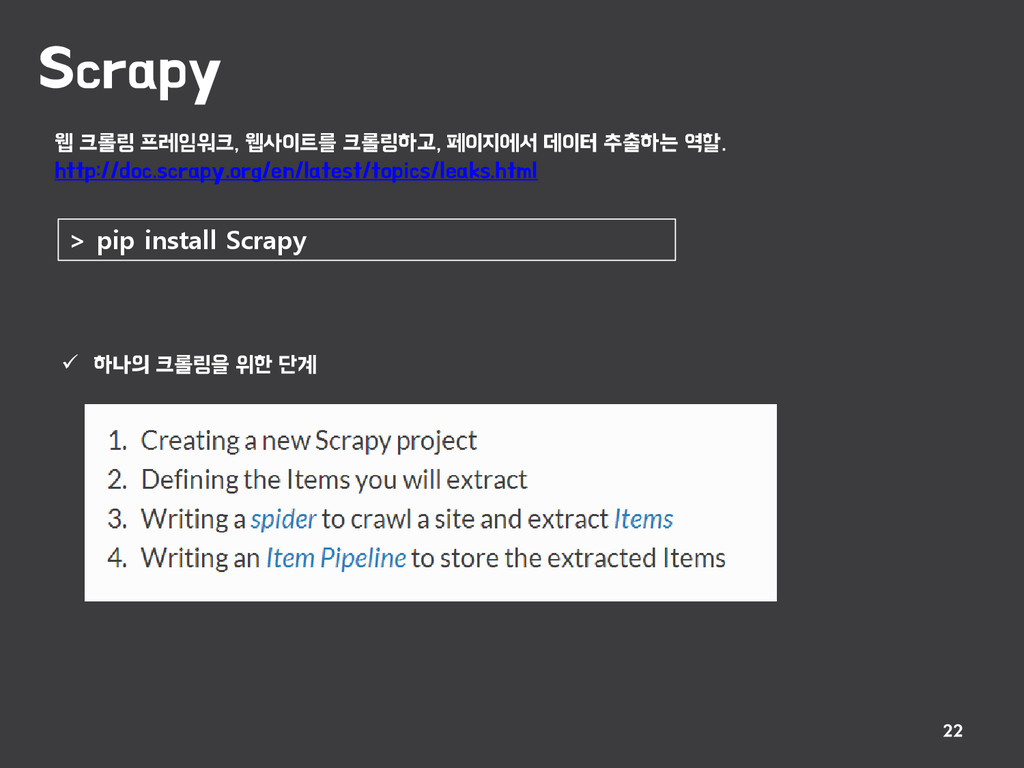{kind=link}
![Scrapy 23 프로젝트 생성하기 scrapy startproject [project_name]](https://files.speakerdeck.com/presentations/457a1c55c973408daacfb77461fd249e/slide_22.jpg){kind=link}
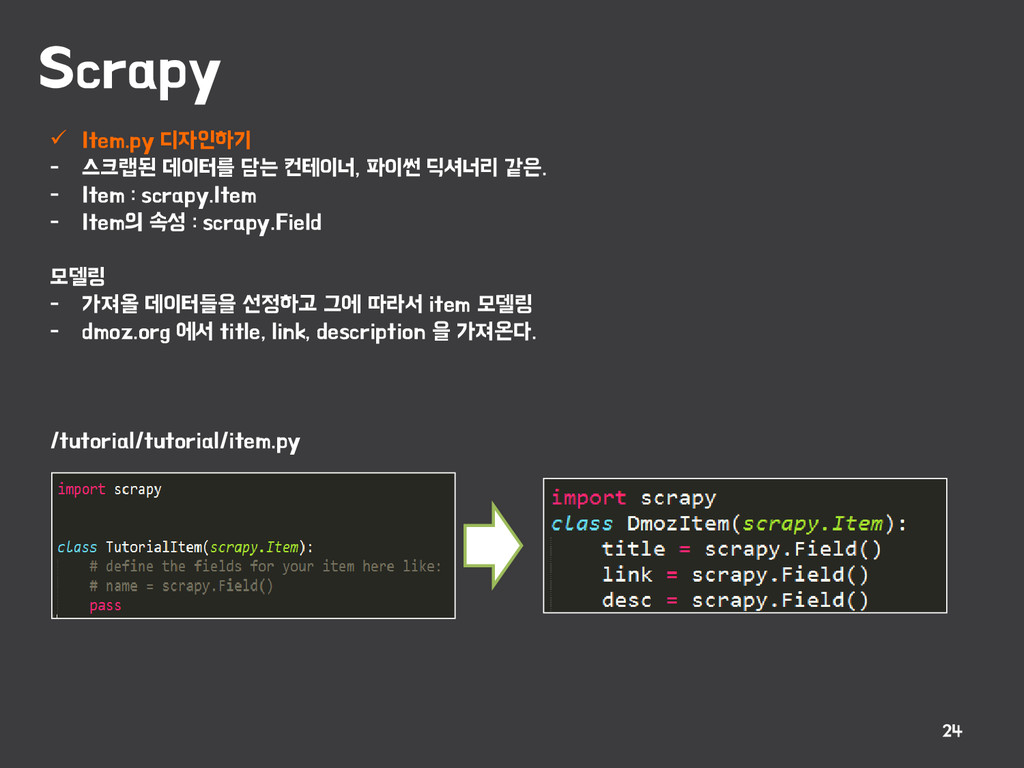{kind=link}
{kind=link}
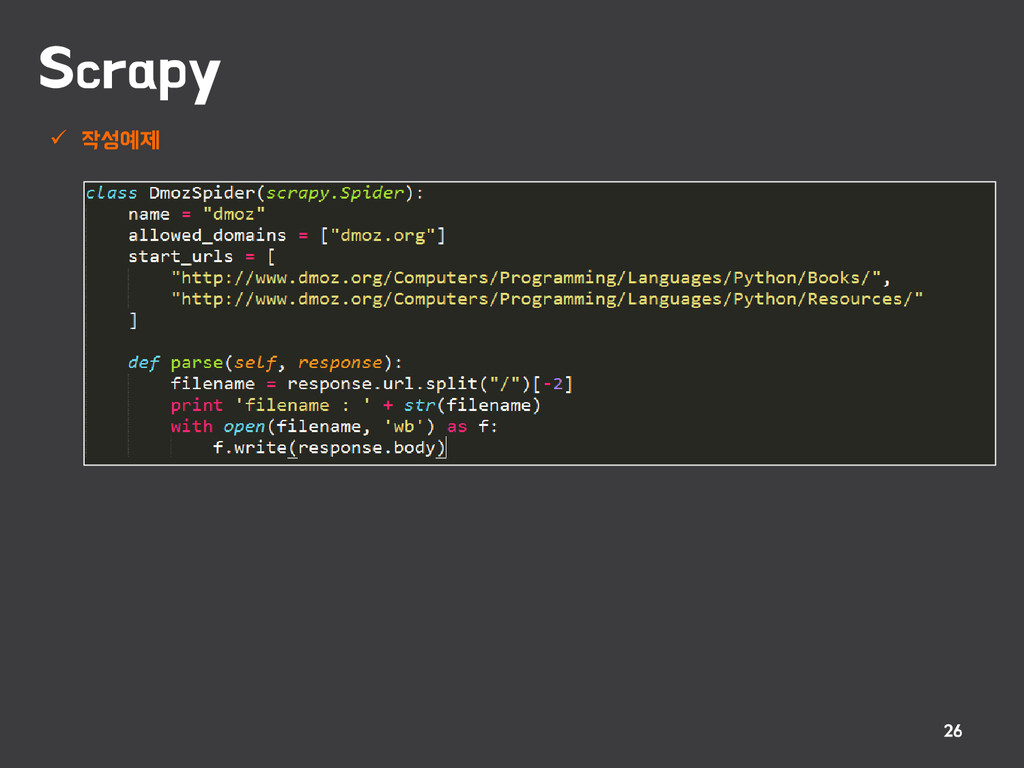{kind=link}
{kind=link}
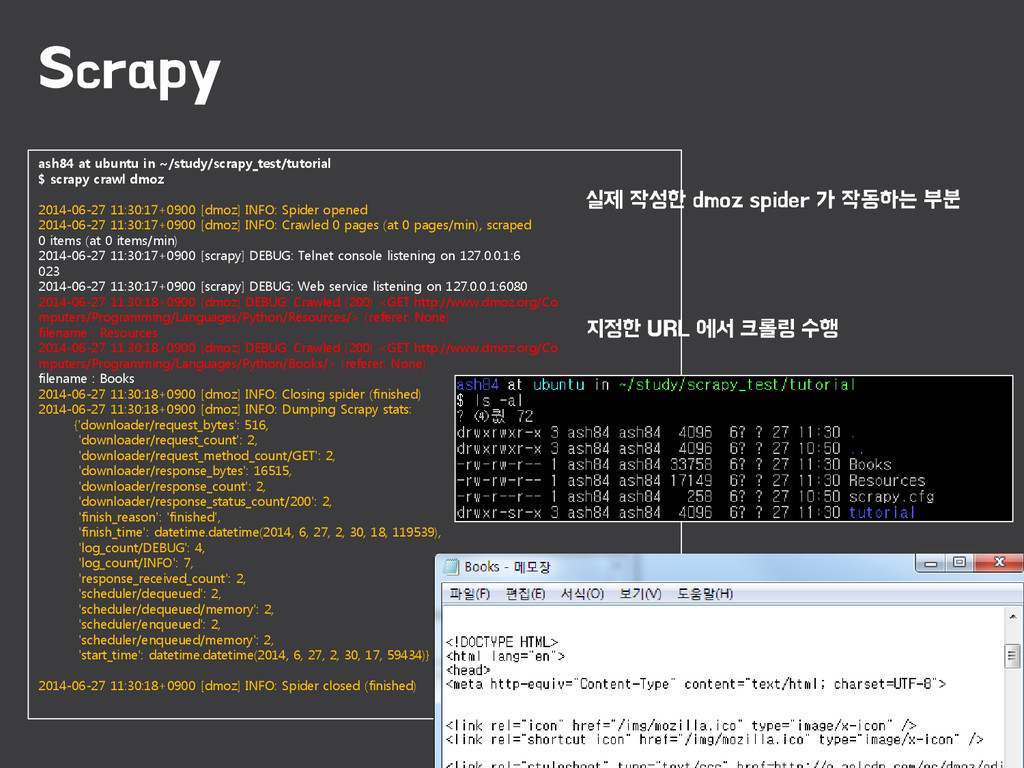{kind=link}
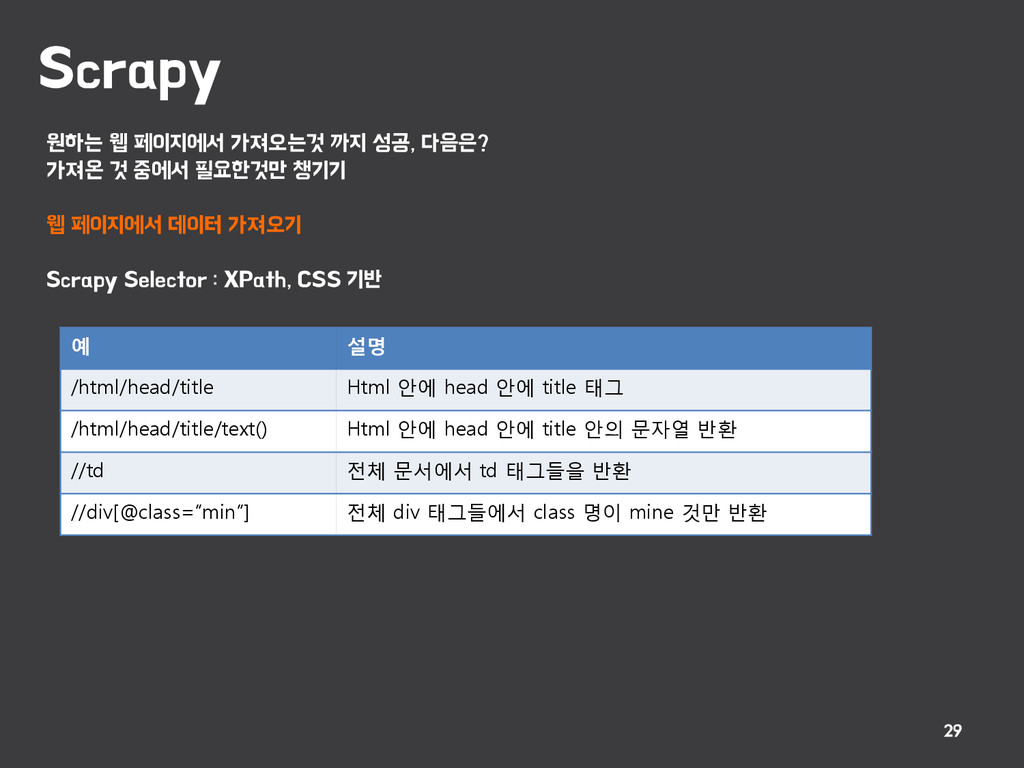{kind=link}
{kind=link}
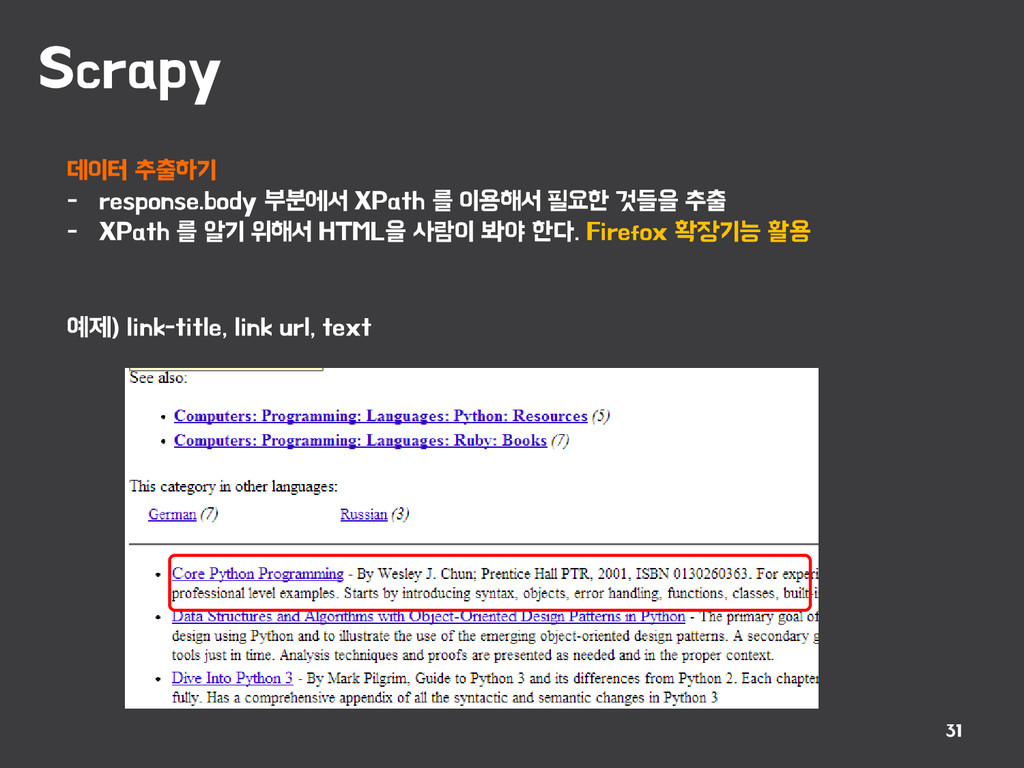{kind=link}
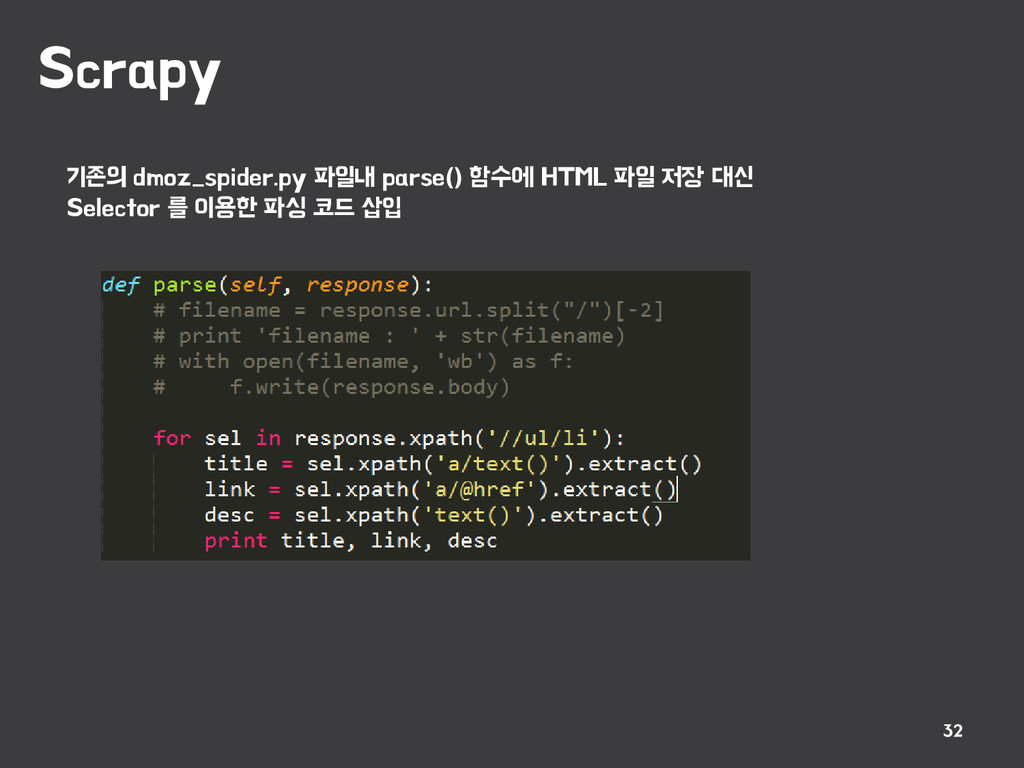{kind=link}
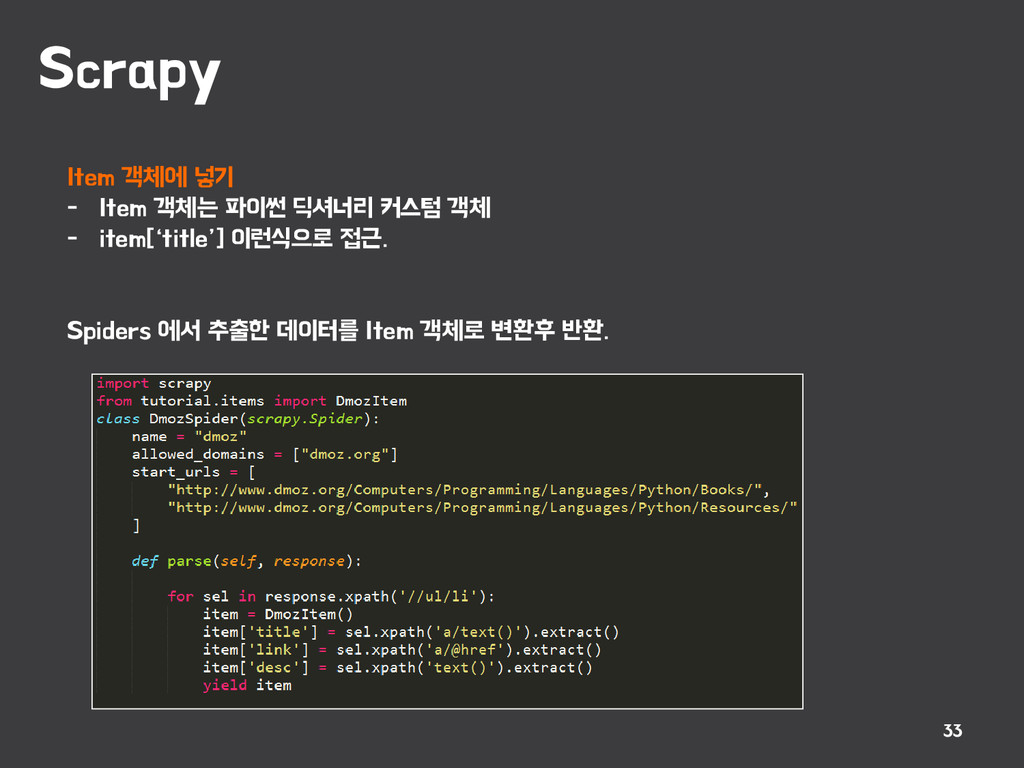{kind=link}
![Scrapy 34 scrapy crawl dmoz {"desc": [], "link": ["/Computers/"], "title":](https://files.speakerdeck.com/presentations/457a1c55c973408daacfb77461fd249e/slide_33.jpg){kind=link}
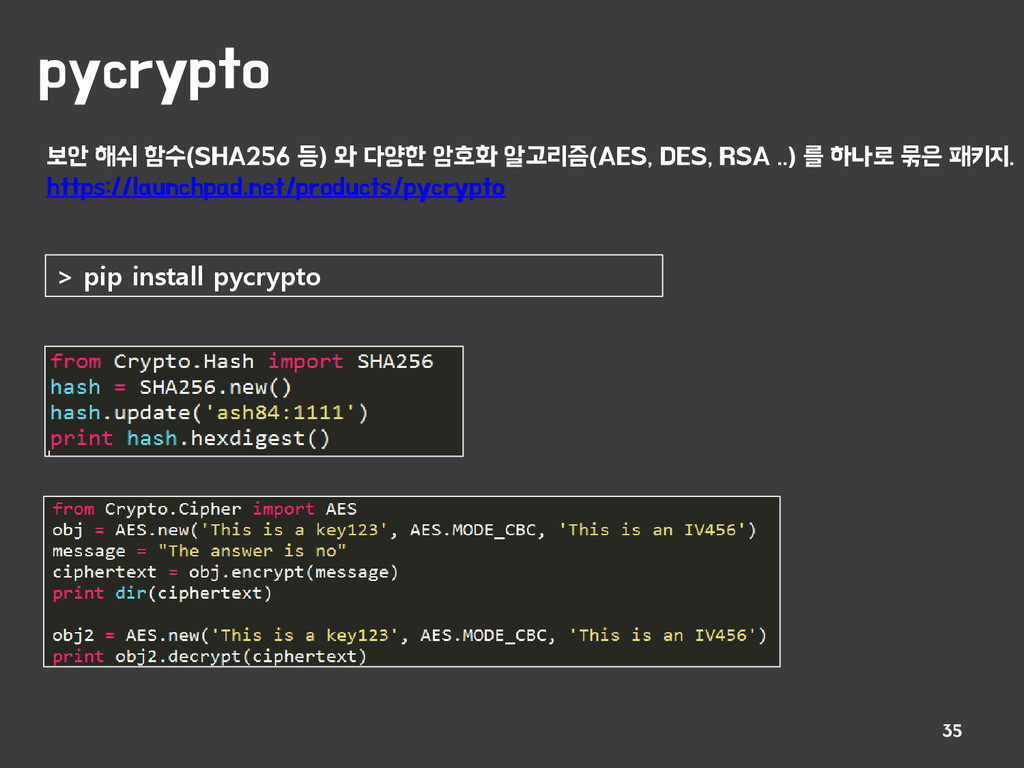{kind=link}
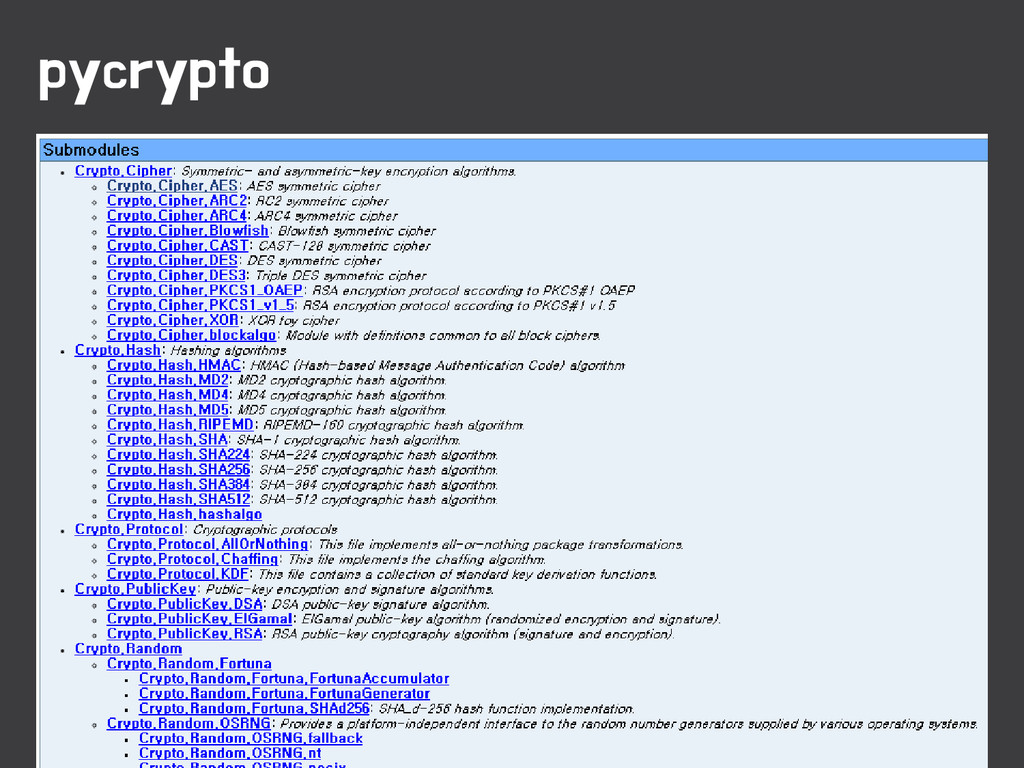{kind=link}
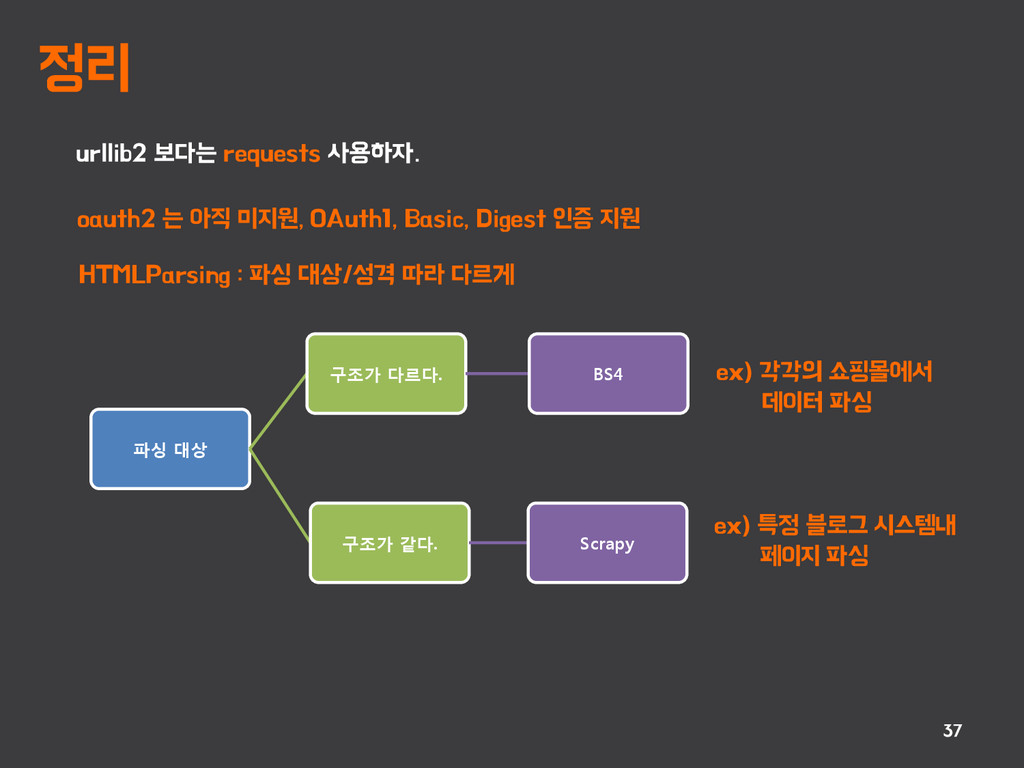{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}