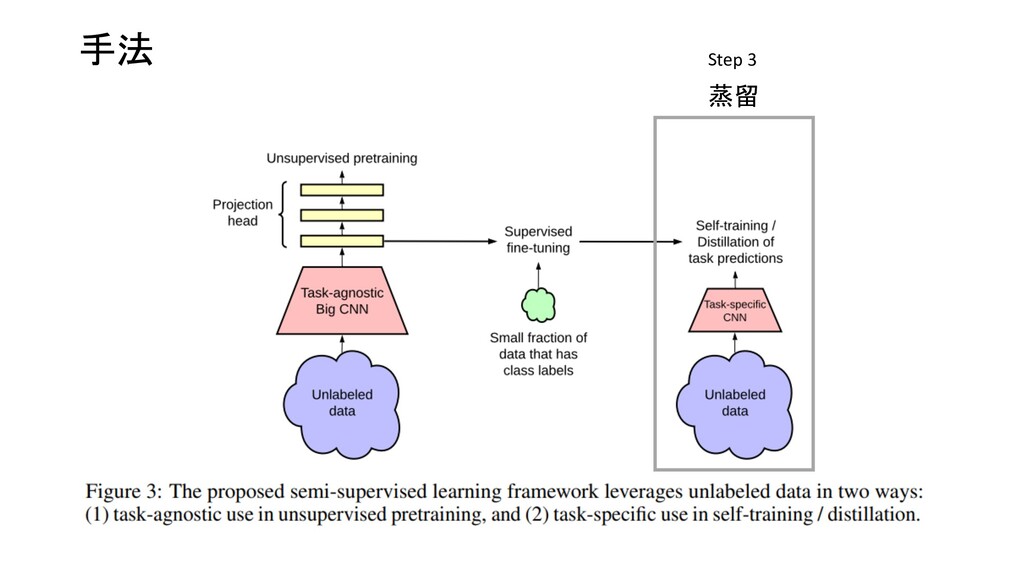
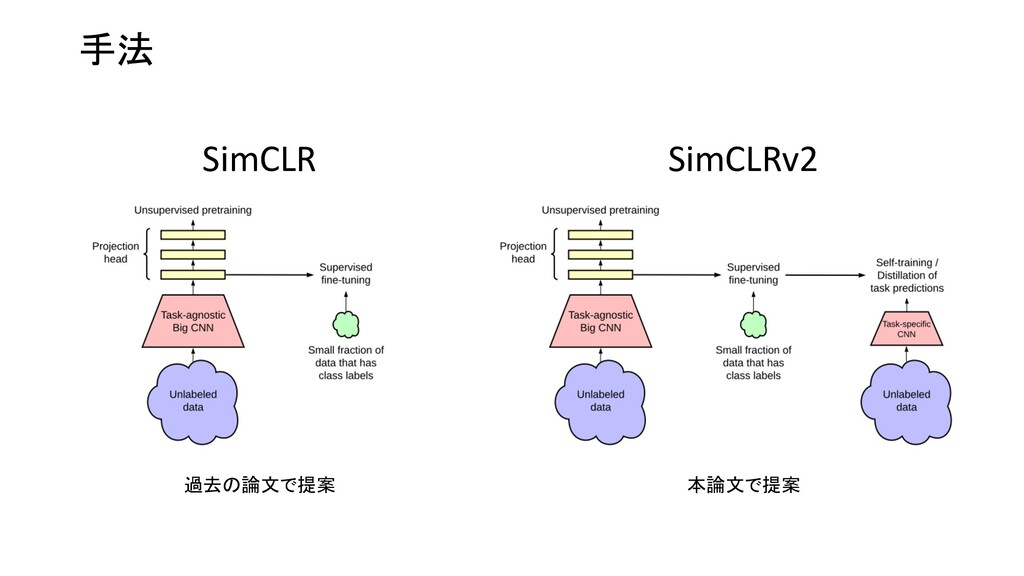
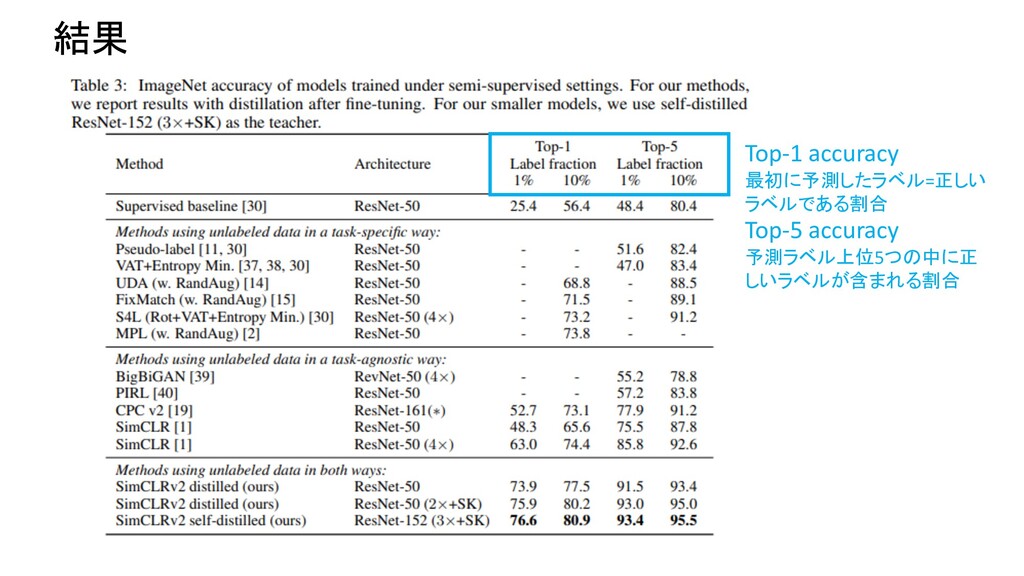
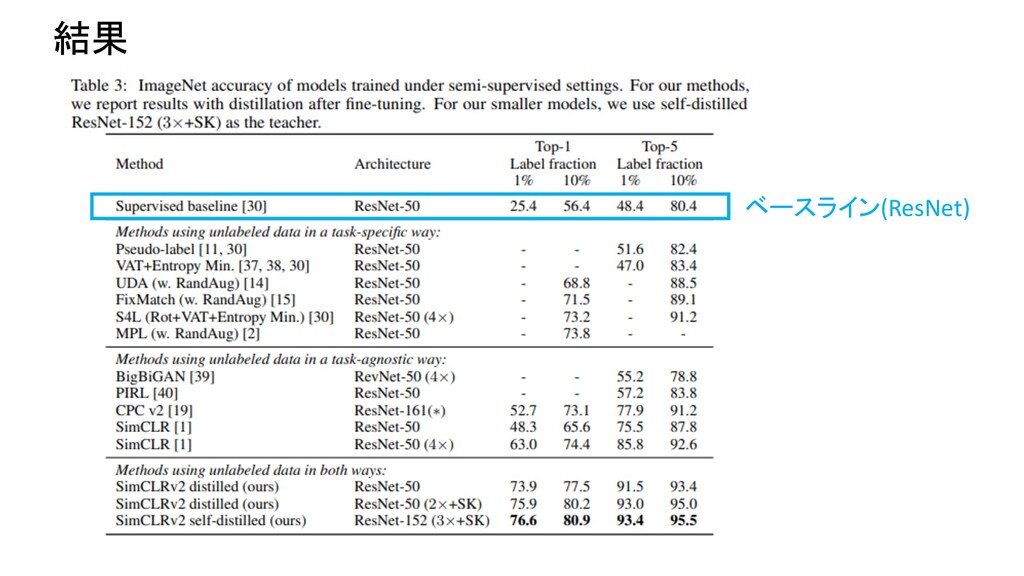
Network Predictions by Identifying Relevant Walks Top Recent 9 First I didn’t like the boring pictures, but finally it is one of the best movies I have ever seen. Image Sequential Graph Type ソーシャルネットワークなど Neural Network Convolutional Neural Network Recurrent Neural Network Graph Neural Network
Network Predictions by Identifying Relevant Walks Top Recent 9 First I didn’t like the boring pictures, but finally it is one of the best movies I have ever seen. Image Sequential 画像、文字列も一種のGraphとして扱える ノード:ピクセル エッジ:隣接関係 ノード:単語 エッジ:隣接関係、構文木
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
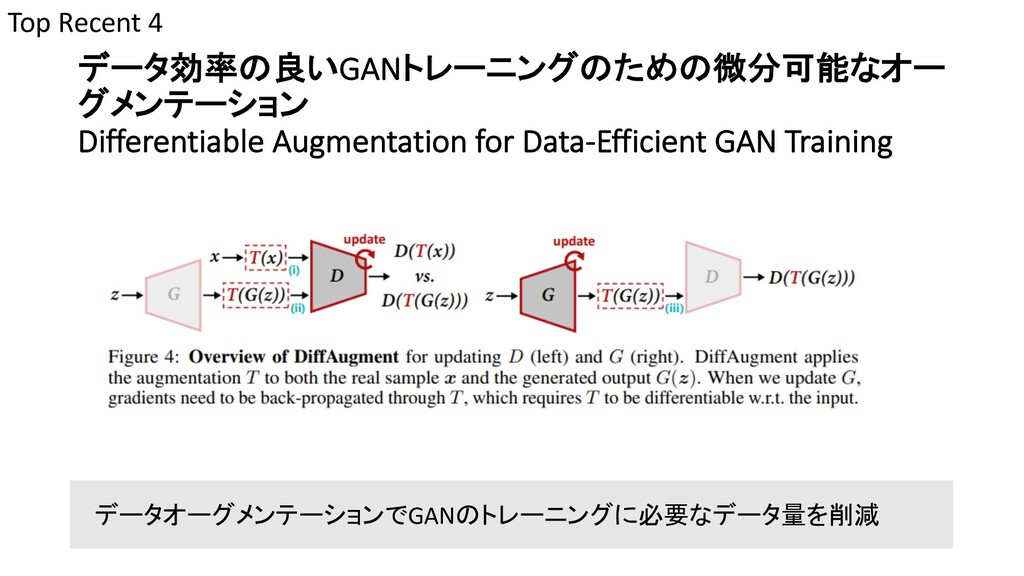{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
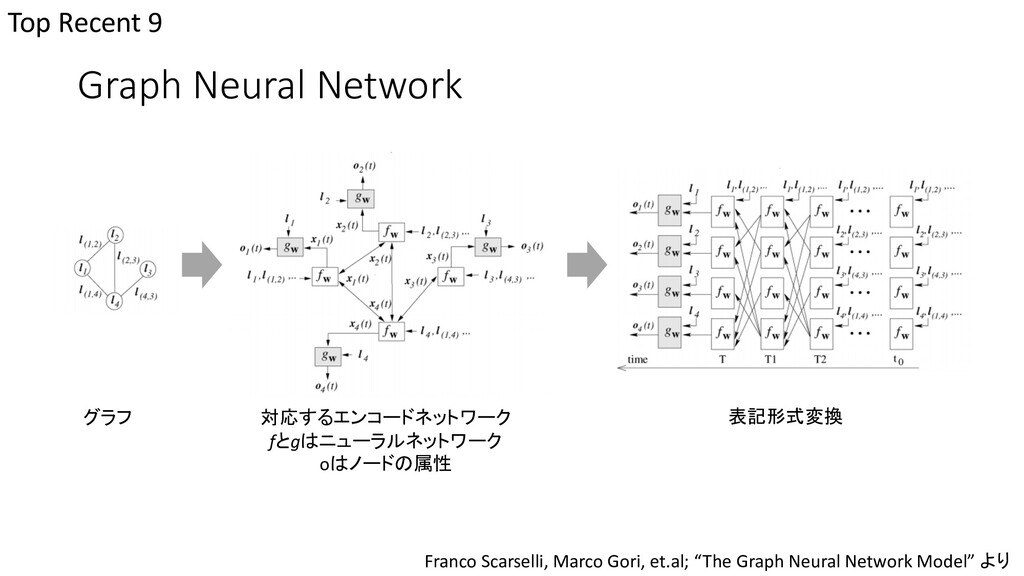{kind=link}
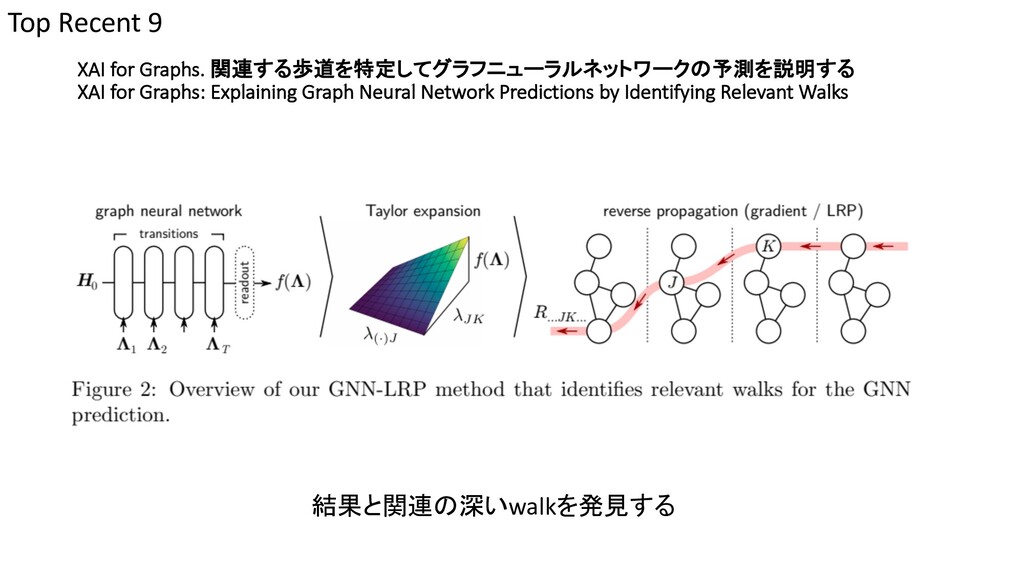{kind=link}
{kind=link}
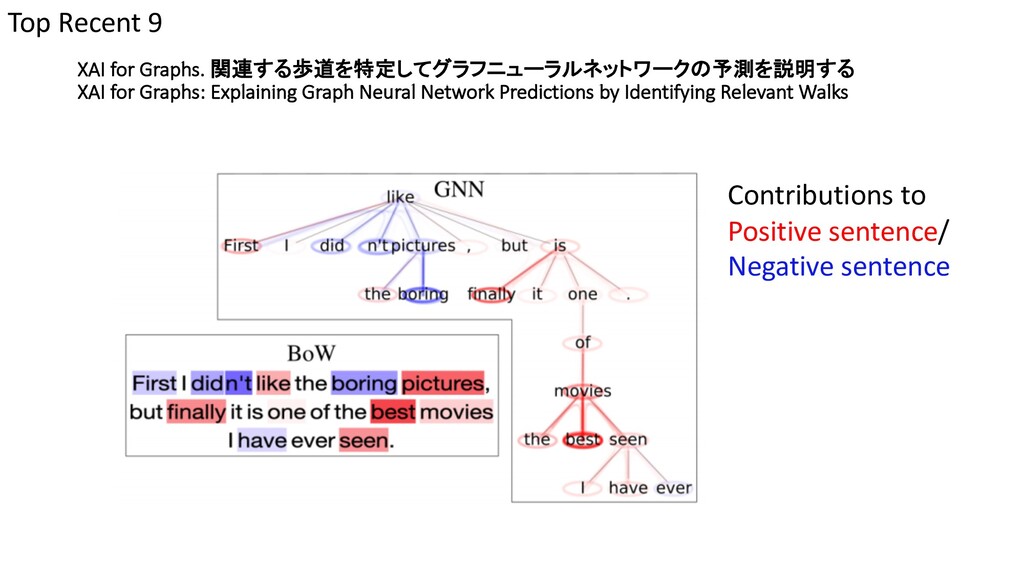{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}