A case study of how some of Clojure's features helped us solve problems we were facing in onboarding the data of our enterprise customers to our platform, at numberz.
not need that shiny, new data processing framework (And not because your Data isn’t Big enough. I'm sure it is.) (But because sometimes you're not always working with ALL of that data, and you may have simpler tools at your disposal.)
Clojure in Production for the first time. • Demonstrate how plain ol’ Clojure and its features provide reasonably powerful alternatives to distributed computation frameworks.
(ERP inflexibility, licensing issues, etc.) • Need to rely on a hodgepodge of pre-existing canned reports (Excel, CSV) to get data we need • Reports are large-ish: ~50mb in size • Custom, complicated, compute-intensive transformations needed to get data into our format
spreadsheets (Excel, CSV) • Expressive data transformations • Support for processing reasonably large data-sets, preferably in-memory What we didn’t want • Maintenance overhead of a distributed computing platform • Incidental complexity *cough*type-systems*cough* • Proprietary ETL solutions with high licensing costs
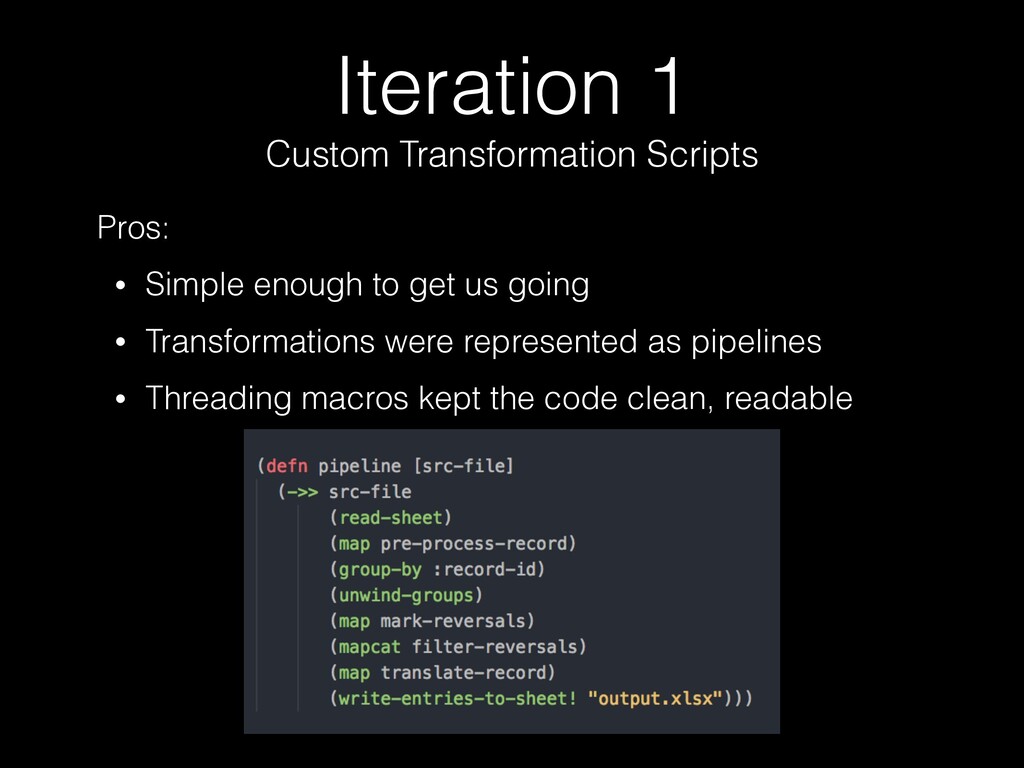
processing large Excel sheets • Lazy sequences, transducers helped with handling large payloads in-memory • Dynamic typing helped us avoid proliferation of unnecessary type definitions • Declarative data transformations
e2e involvement of devs in customer onboarding • Lack of standardisation was a potential risk when incorporating fixes/enhancements at a later time • Above was especially true for “multi-branch” pipelines • Clojure familiarity was low, hence only a handful of team-members were able to contribute
representing them as Directed Acyclic Graphs (DAGs). • Similar to workflow engines. Eg. Airflow, Oozie, etc. • Each node in the graph represented a simple transformation • Composing multiple nodes together, in the right sequence, allowed for complex, multi-branch flows
code to be written • Moved us towards an even more declarative expression of transformation • clojure.spec gave greater confidence when making changes to transformers Cons: • Less readable than using threading macros • Higher memory footprint than custom scripts, but still works on a single machine
persist to database • Move to declarative, config-driven expression of individual nodes in the DAG • Generate DAG documentation, diagrams from definitions
Clojure learning curve • Stacktraces pretty complicated for beginners, especially when working with lazy sequences and macros • Low convergence within the community on de facto libraries/frameworks for common tasks
a distributed computation platform, for the simplicity and predictability of a single-machine setup. • A lot of Clojure’s features fit very well with our problem space. • We’d imagine this would be the case for any ETL- like use case on data-sets that aren’t large enough to warrant Big-Data solutions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}