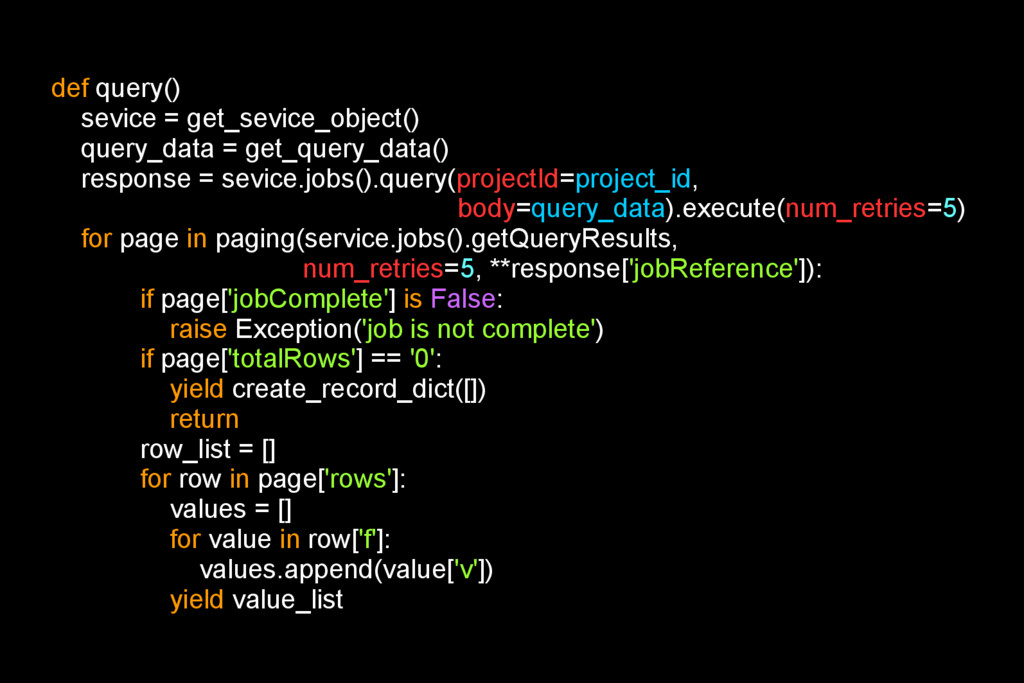
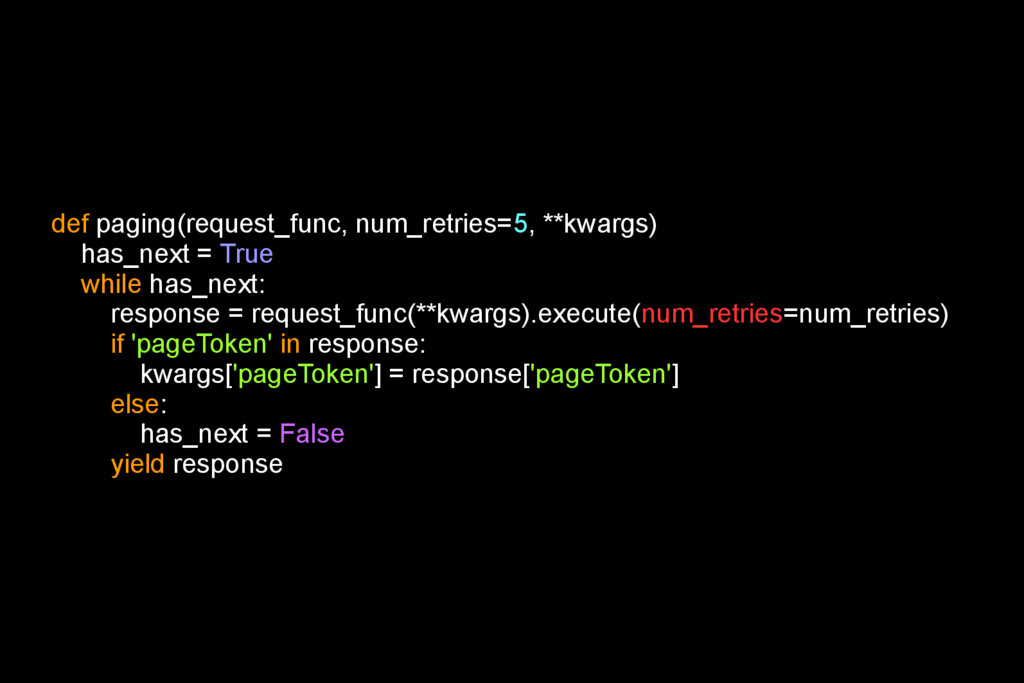
sevice.jobs().query(projectId=project_id, body=query_data).execute(num_retries=5) for page in paging(service.jobs().getQueryResults, num_retries=5, **response['jobReference']): if page['jobComplete'] is False: raise Exception('job is not complete') if page['totalRows'] == '0': yield create_record_dict([]) return row_list = [] for row in page['rows']: values = [] for value in row['f']: values.append(value['v']) yield value_list
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}