Scala as language with it's ability to write highly concise and declarative code, is a perfect match to express neural network algorithms as well. We will leverage features like type inference, the REPL, operator overloading, extension
methods, first class functions as well as the new Scala 3 "optional
braces syntax" to implement Deep Learning Algorithms.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
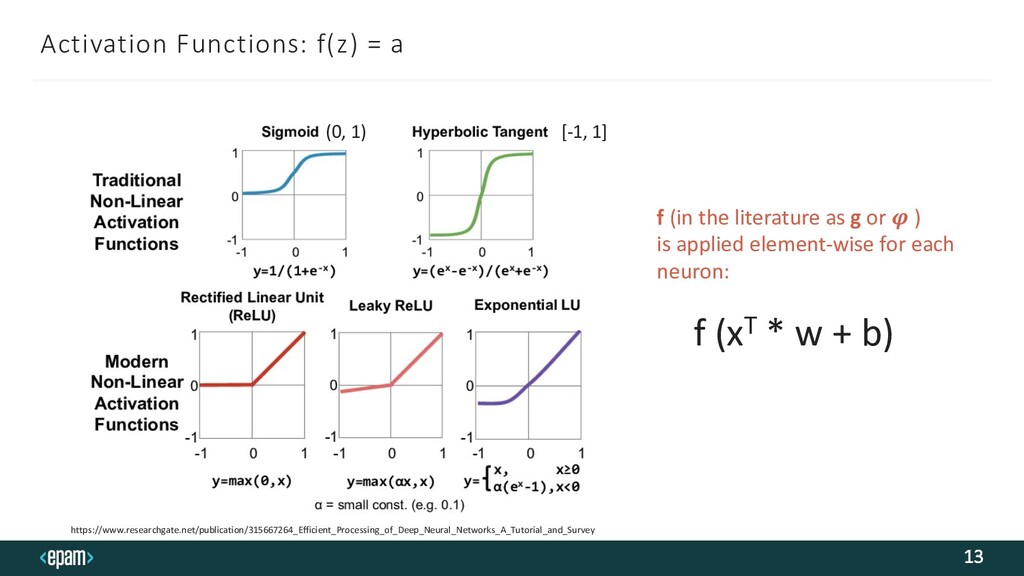{kind=link}
{kind=link}
{kind=link}
{kind=link}
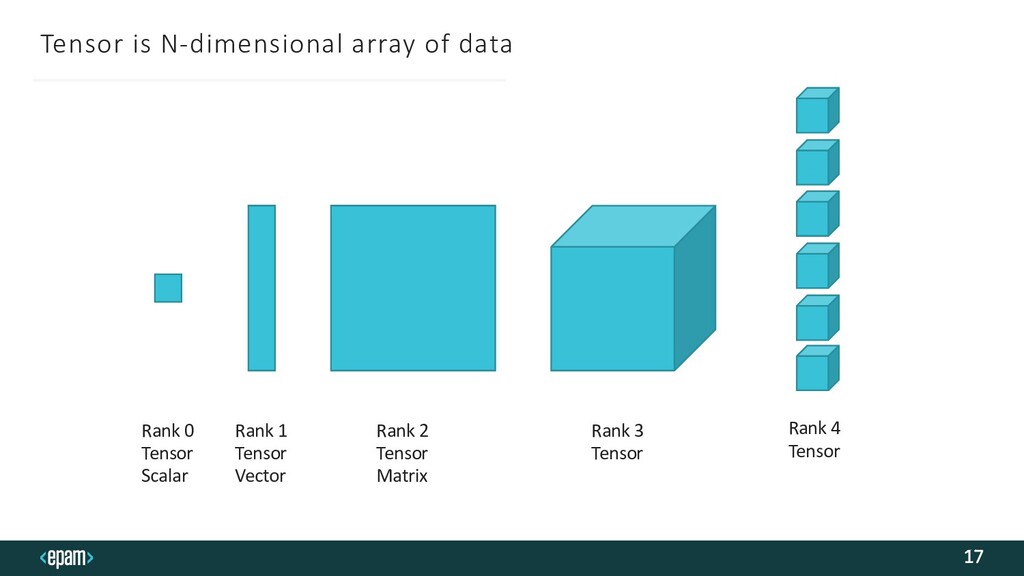{kind=link}
![Tensor in Scala 18 sealed trait Tensor[T]: def length: Int](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_17.jpg){kind=link}
 extends Tensor[T]: override def](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_18.jpg){kind=link}
 // dot product](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 val ((xTrain,](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![Model 29 sealed trait Model[T]: def train(x: Tensor[T], y: Tensor[T],](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_28.jpg){kind=link}
{kind=link}
![Layer Stack 31 def add(layer: LayerCfg[T]): Sequential[T, U] = copy(layerStack](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_30.jpg){kind=link}
![Training Algorithm 32 x: Tensor[T], y: Tensor[T] layers: List[Layer[T]] =>](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_31.jpg){kind=link}
![Train N epochs 33 def train(x: Tensor[T], y: Tensor[T], epochs:](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_32.jpg){kind=link}
![Train on batches: forward 34 private def trainEpoch( batches: Array[(Array[Array[T]],](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Optimizer 38 type Stub trait Optimizer[U]: def updateWeights[T: ClassTag: Fractional](](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_37.jpg){kind=link}
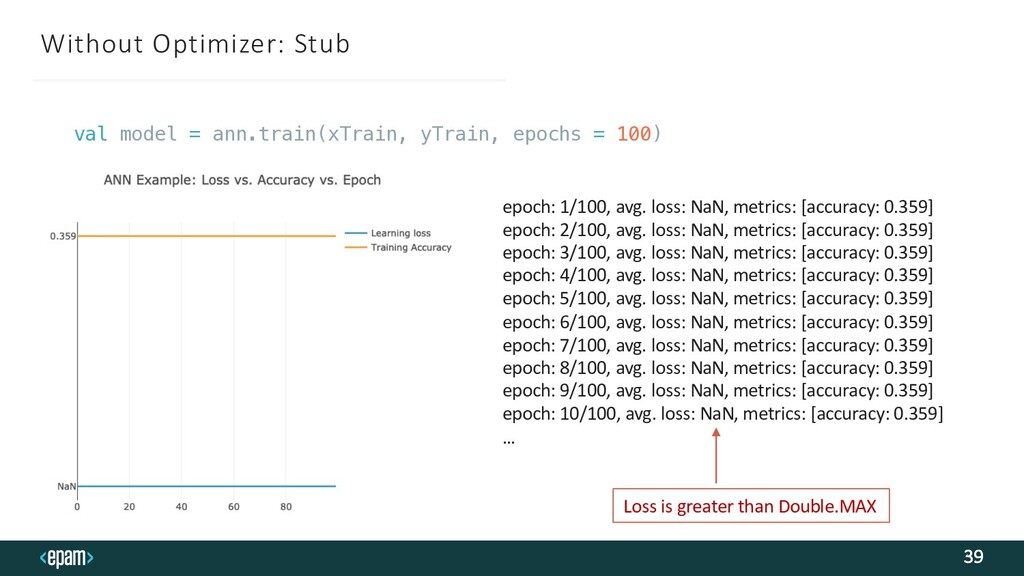{kind=link}
![With Optimizer (1) 40 type StandardGD weights: List[Layer[T]], activations: List[Activation[T]],](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_39.jpg){kind=link}
![With Optimizer (2): Backpropagation + Gradient Descent 41 layers.zip(activations) .foldRight(List.empty[Layer[T]],](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_40.jpg){kind=link}
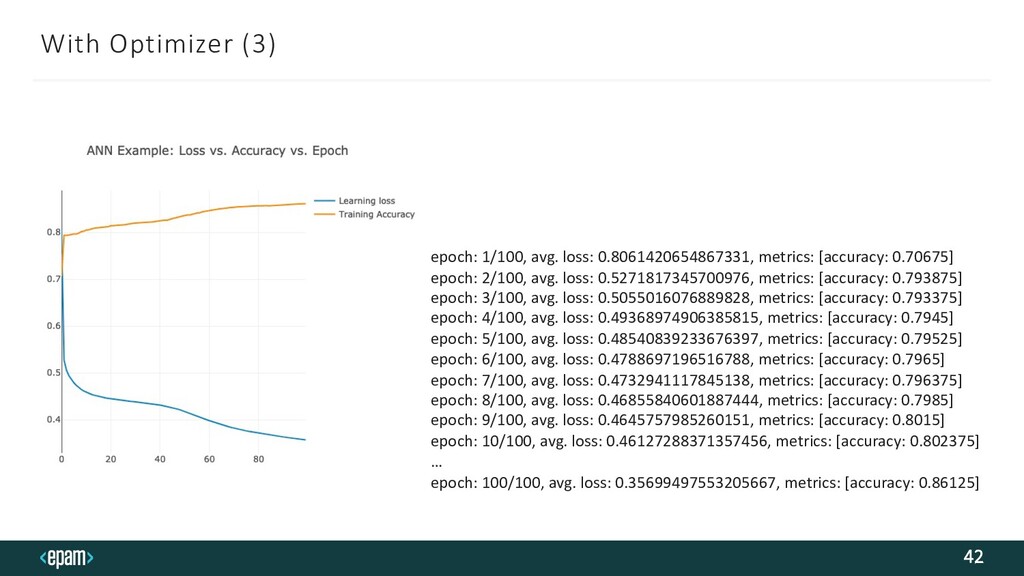{kind=link}
{kind=link}
{kind=link}
![Test 45 sealed trait Model[T]: def predict(x: Tensor[T]): Tensor[T] Feed](https://files.speakerdeck.com/presentations/0e9be2dd68344f239687e49150353b6d/slide_44.jpg){kind=link}
{kind=link}
{kind=link}