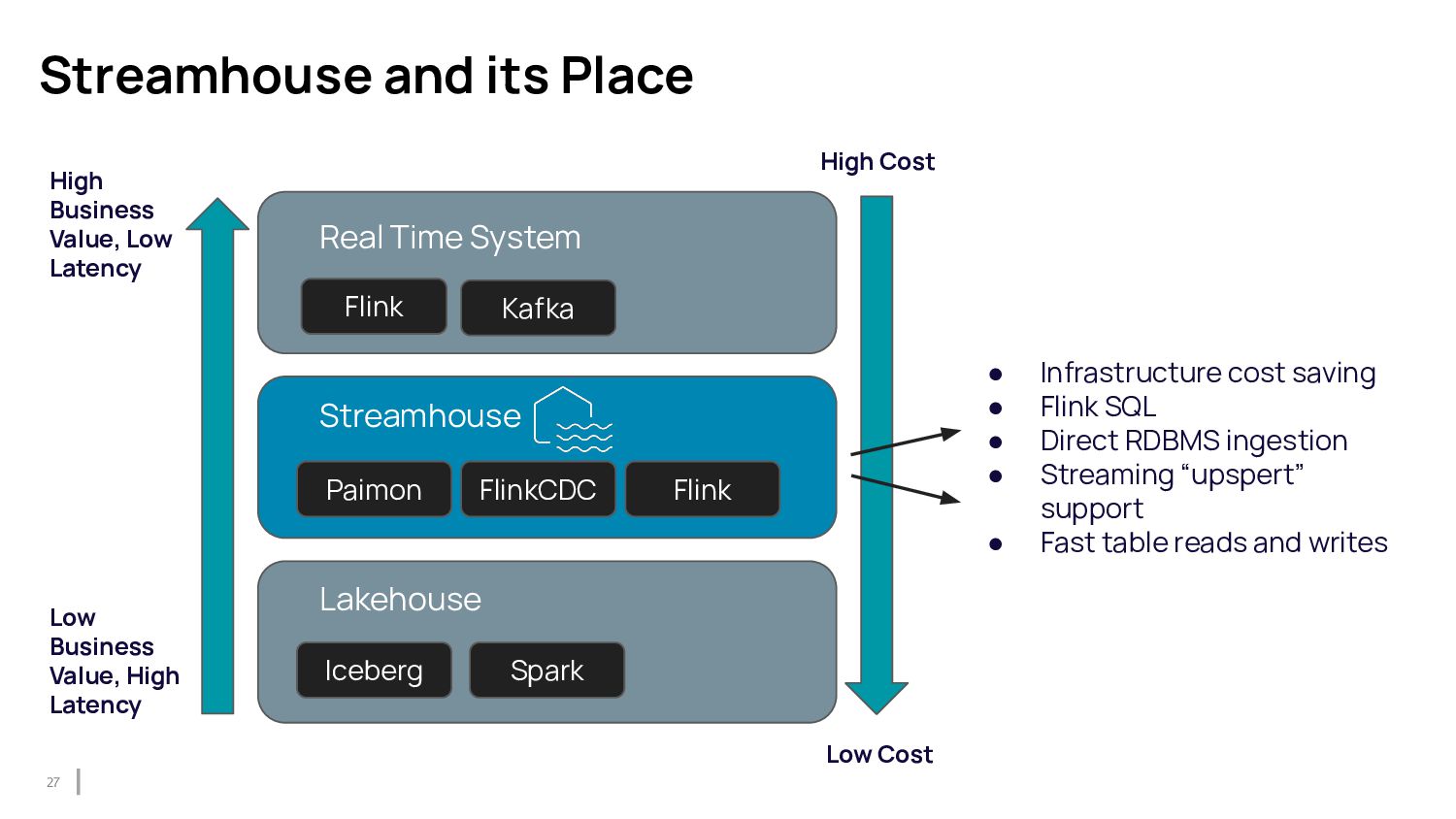
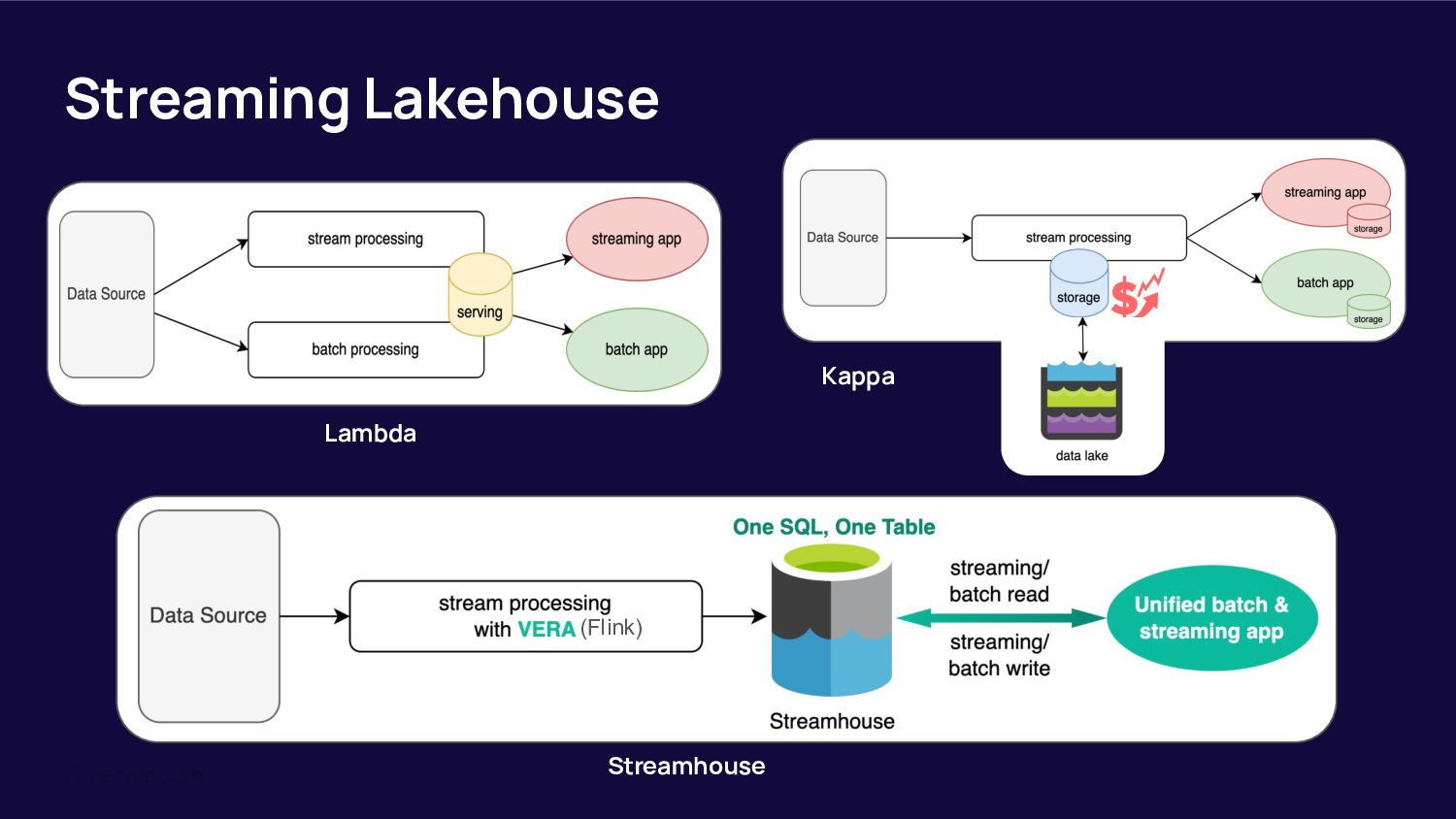
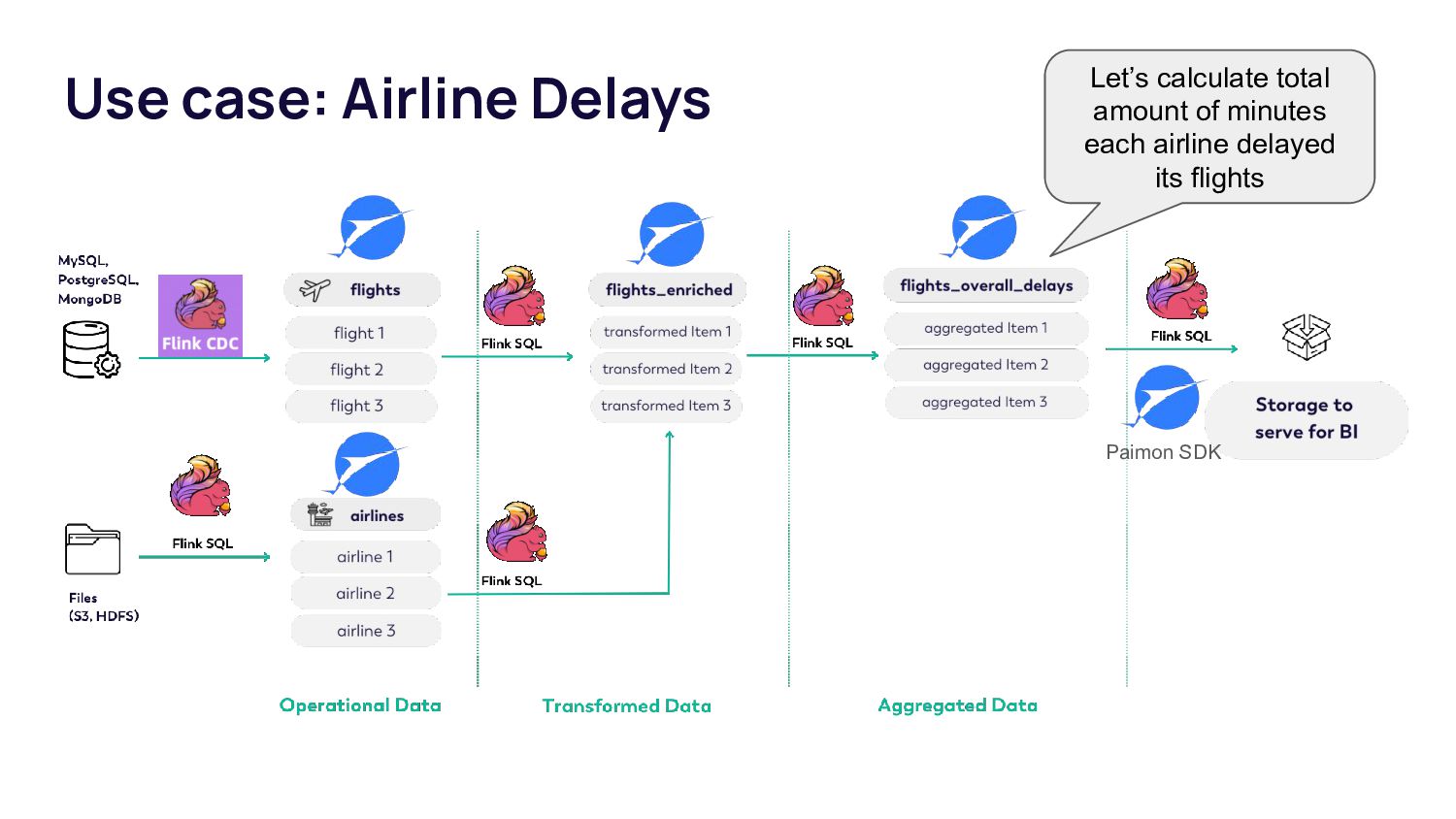
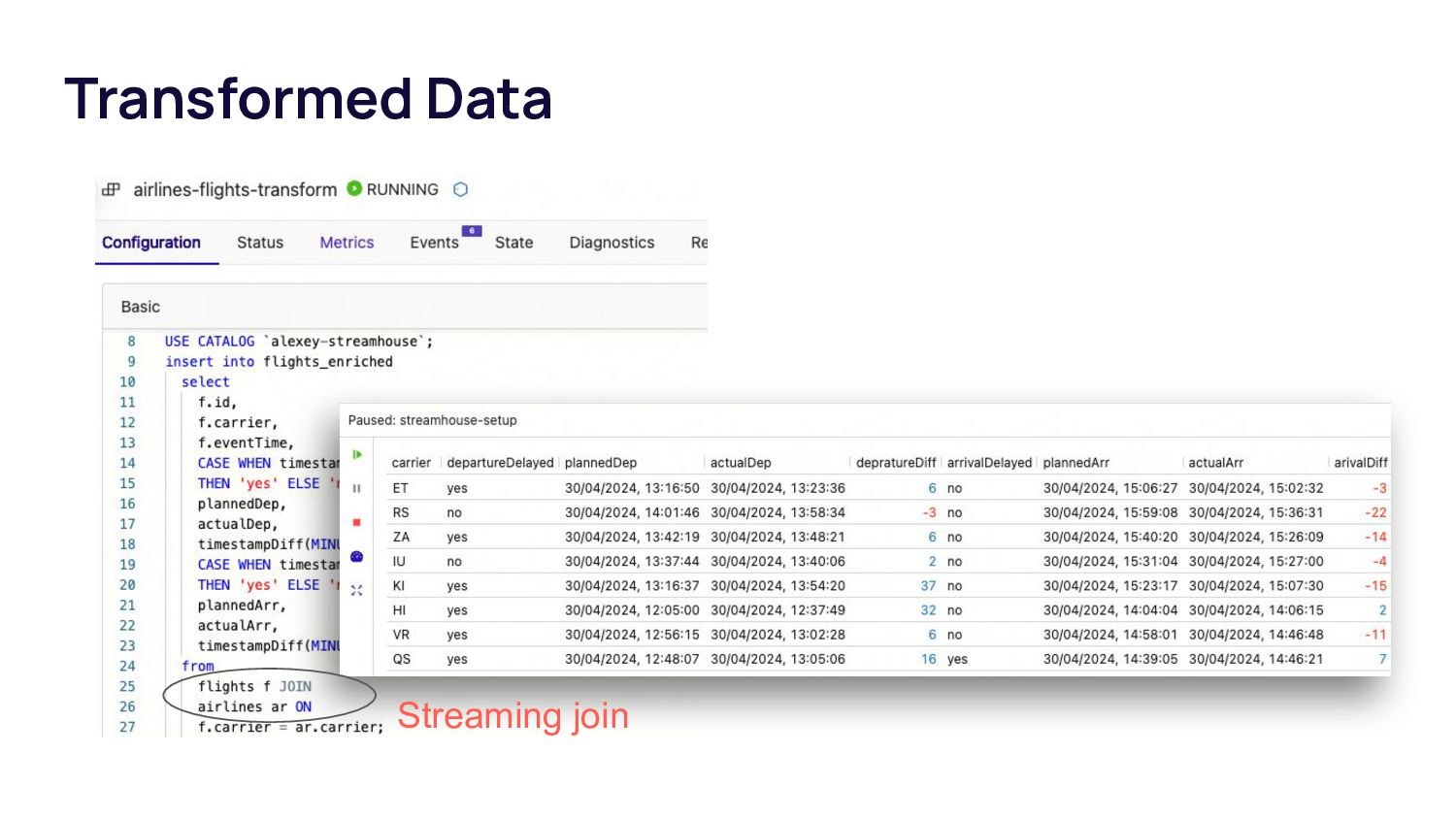
This talk introduces data teams to tools like Apache Paimon in combination with Flink. Paimon has been built with a strong focus on streaming workflows, serving as a table format in a lakehouse. It takes the stream processing approach in lakehouse architecture to the next level compared to other table formats that are more oriented towards batch data. After this talk, data teams will know how to use Paimon and Flink to build a cost-efficient and fast data layer for different data processing scenarios.
{kind=link}
{kind=link}
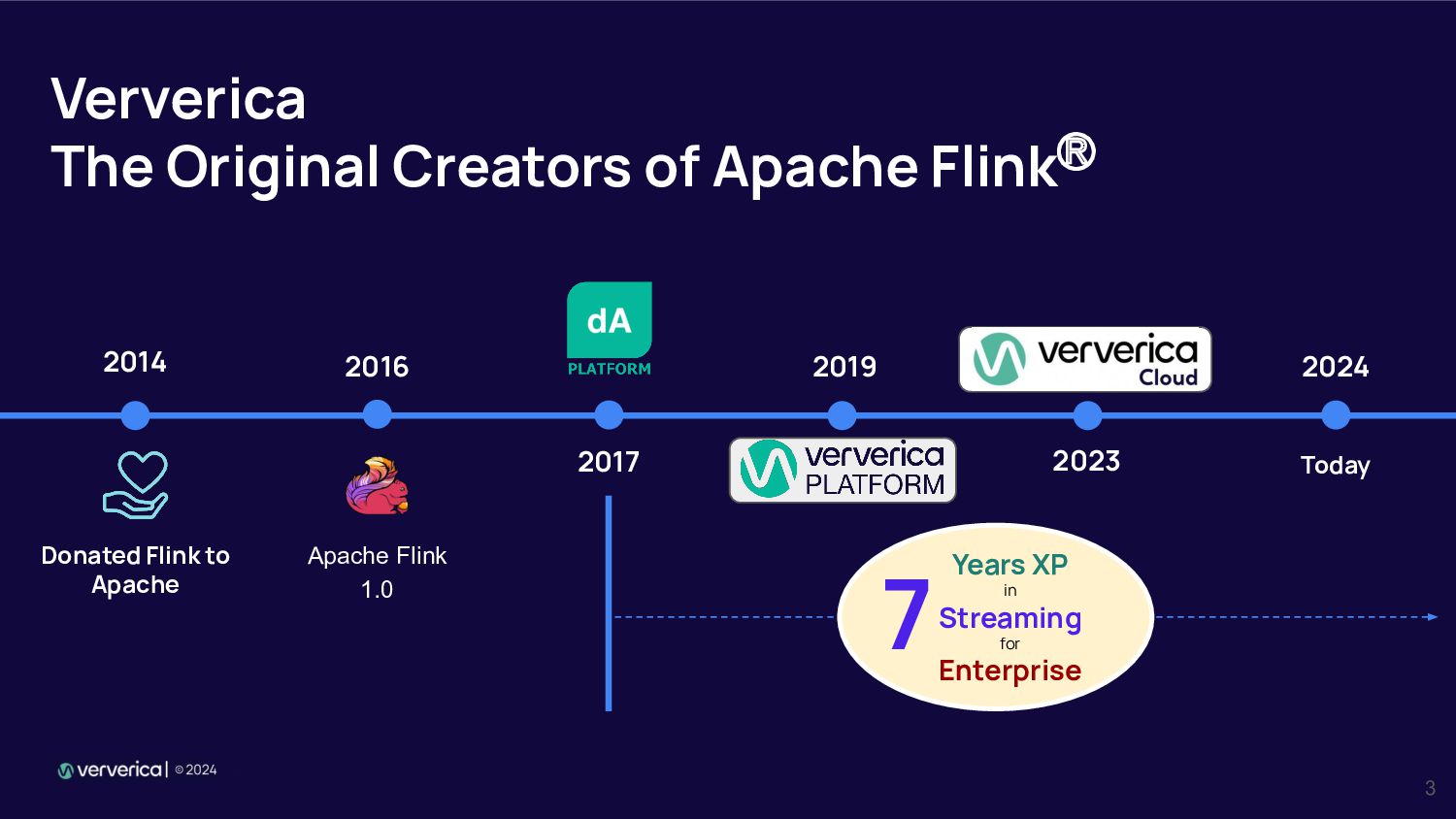{kind=link}
{kind=link}
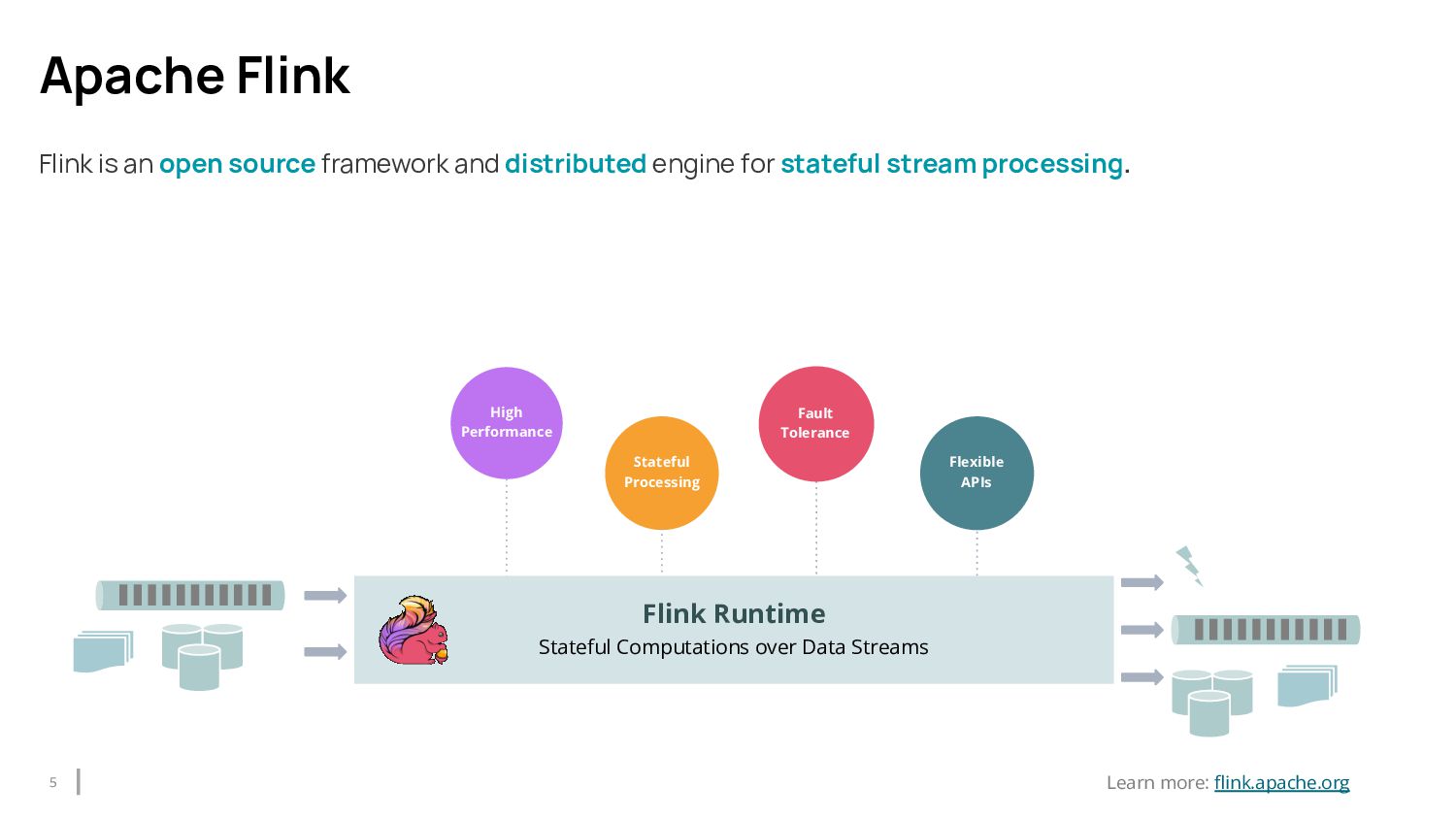{kind=link}
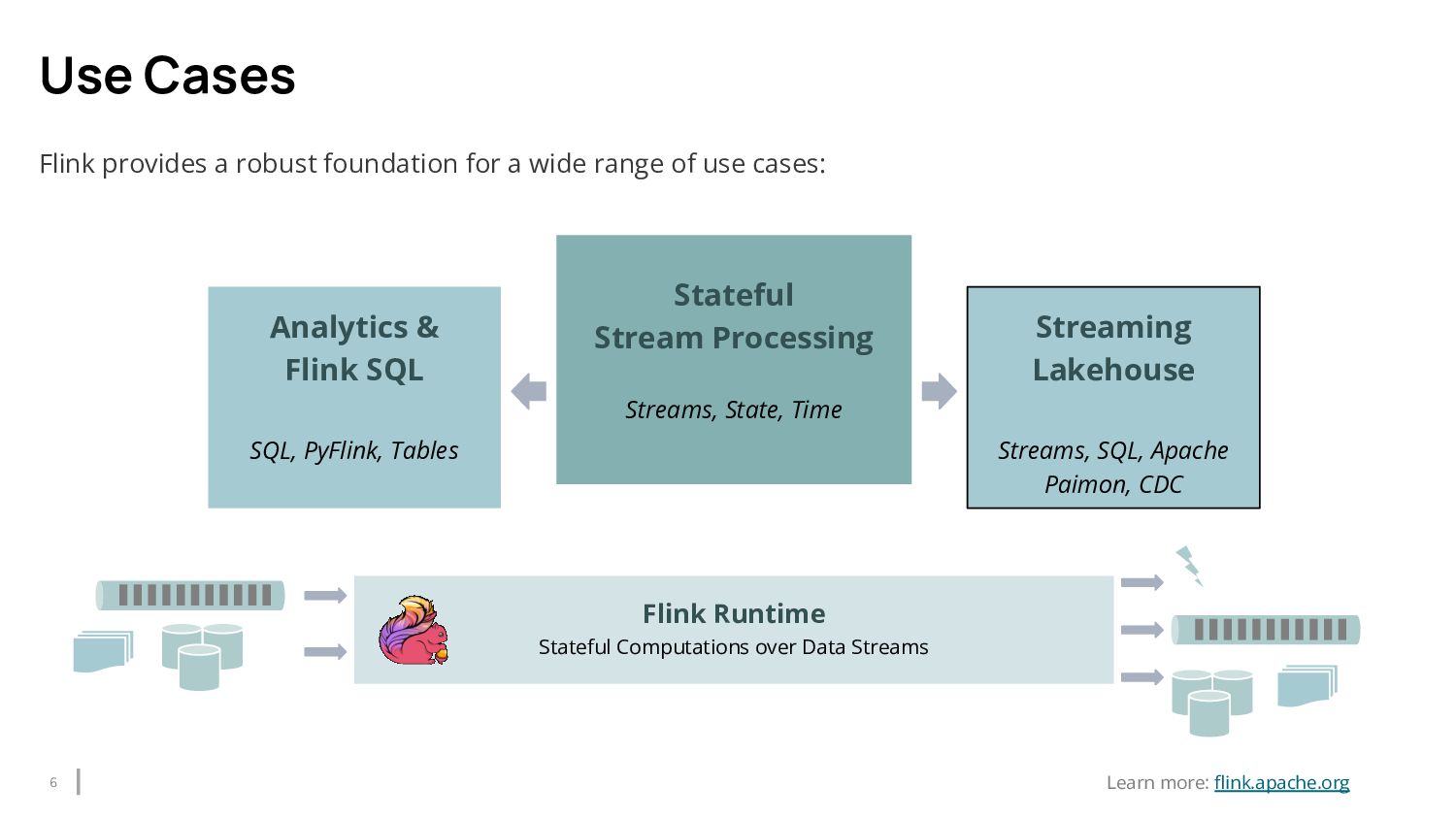{kind=link}
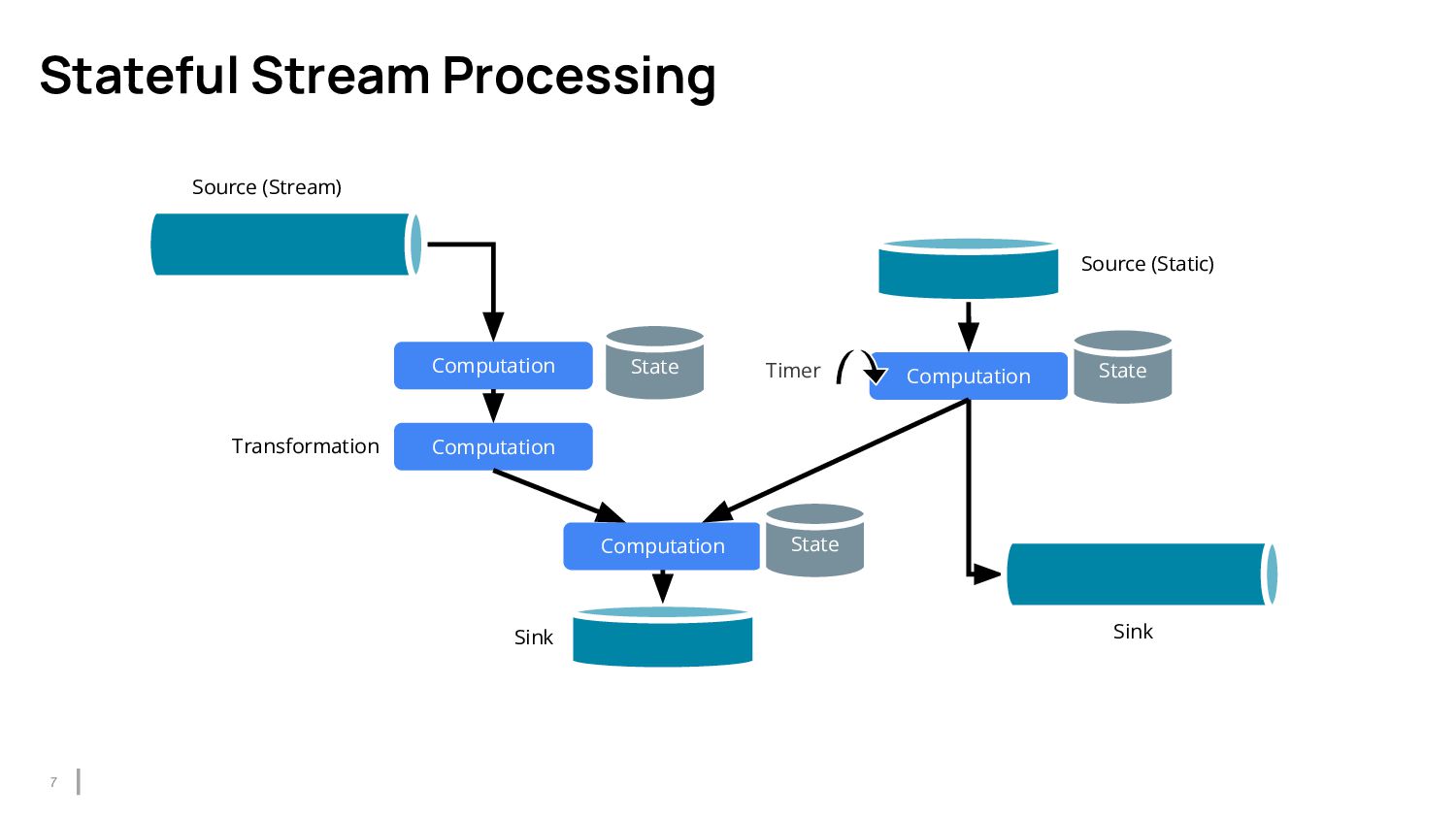{kind=link}
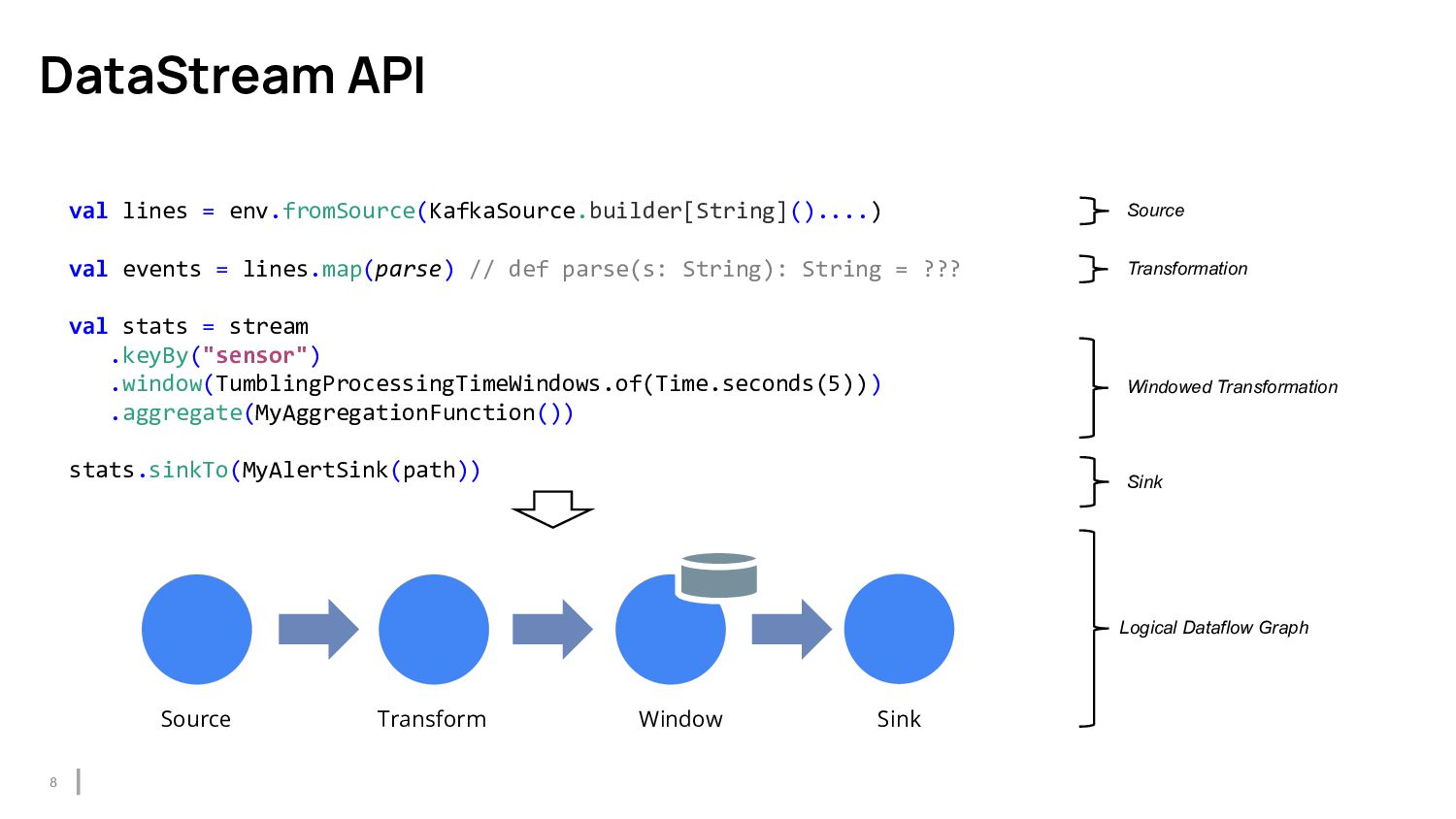{kind=link}
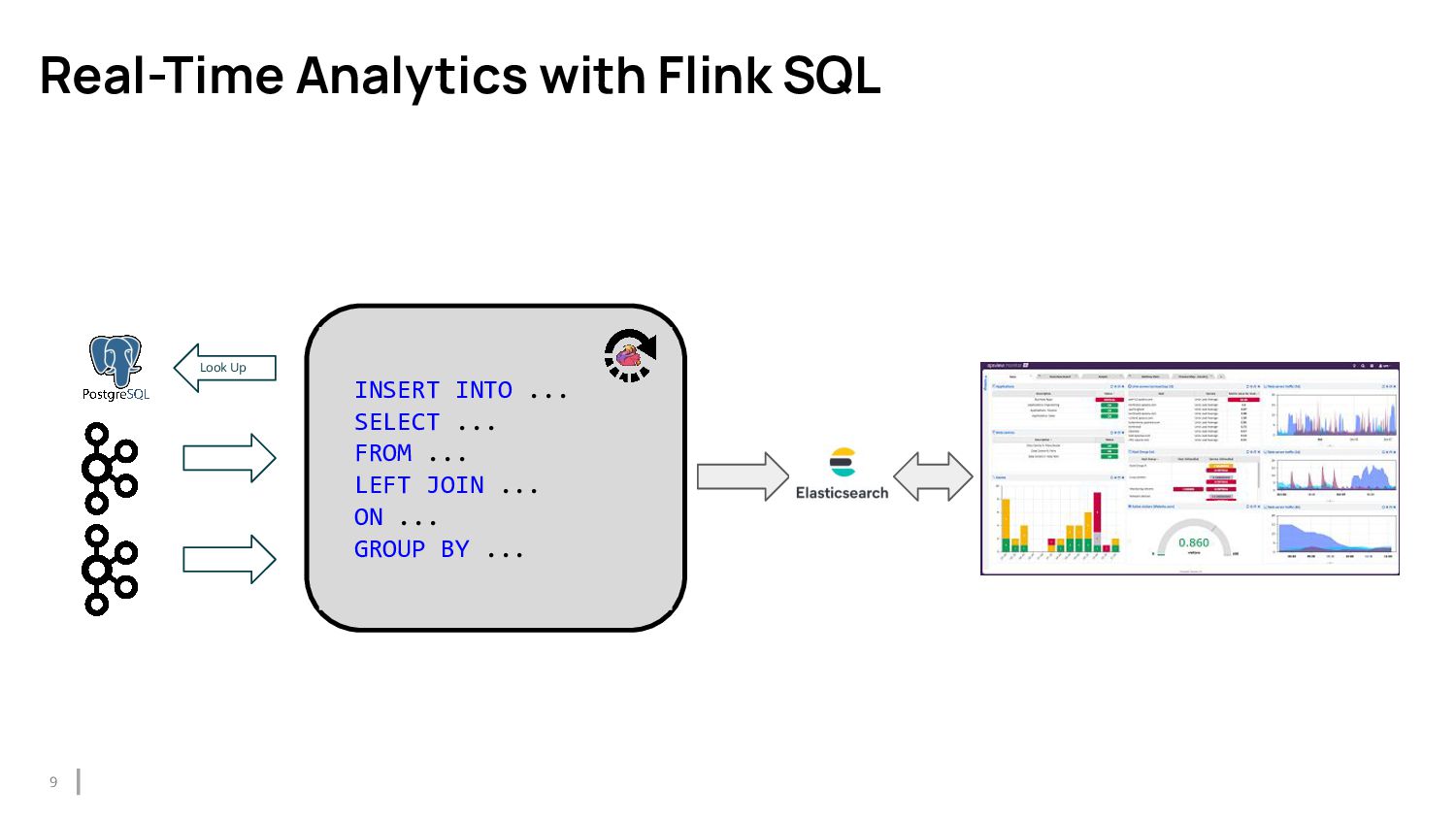{kind=link}
{kind=link}
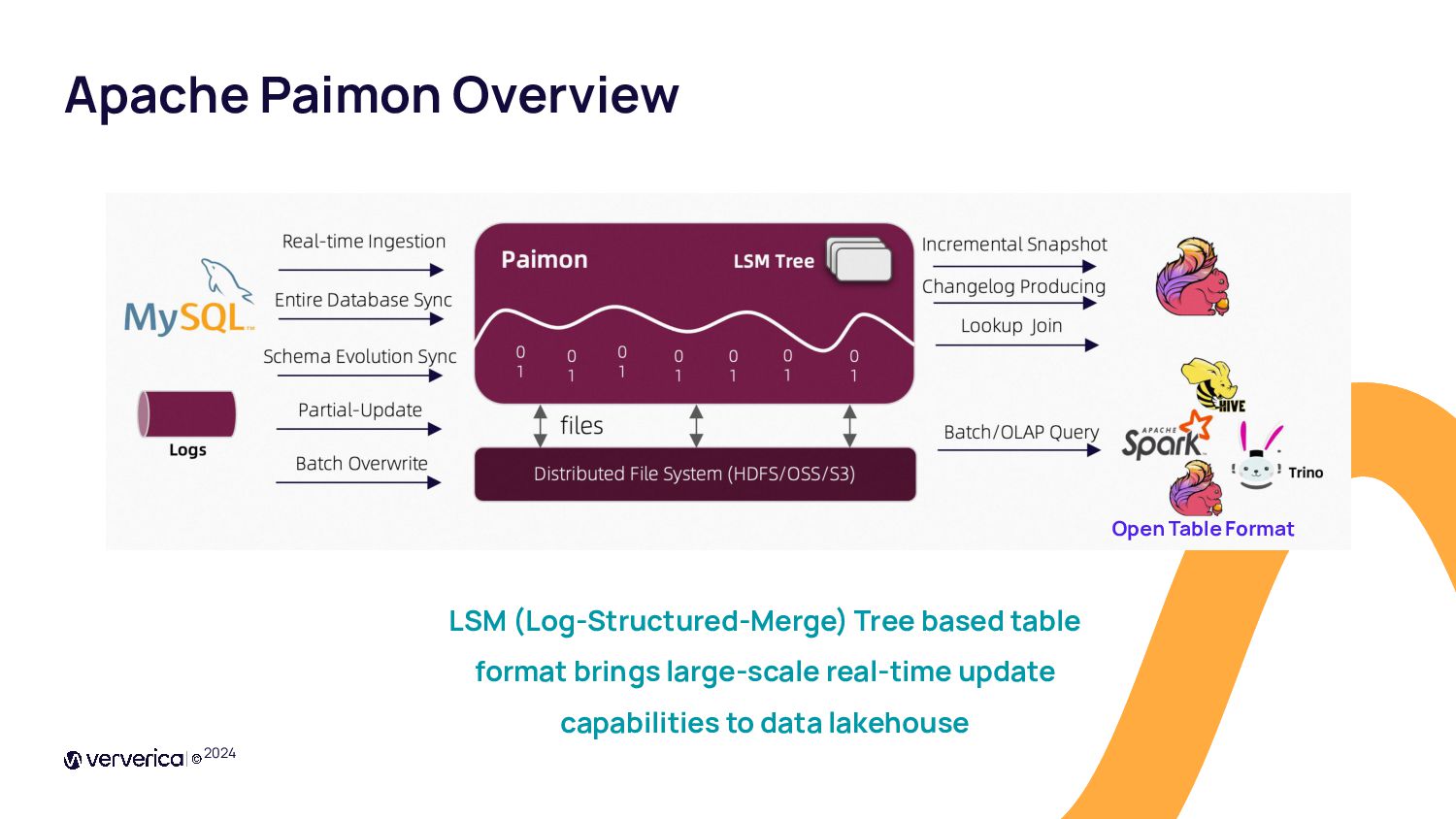{kind=link}
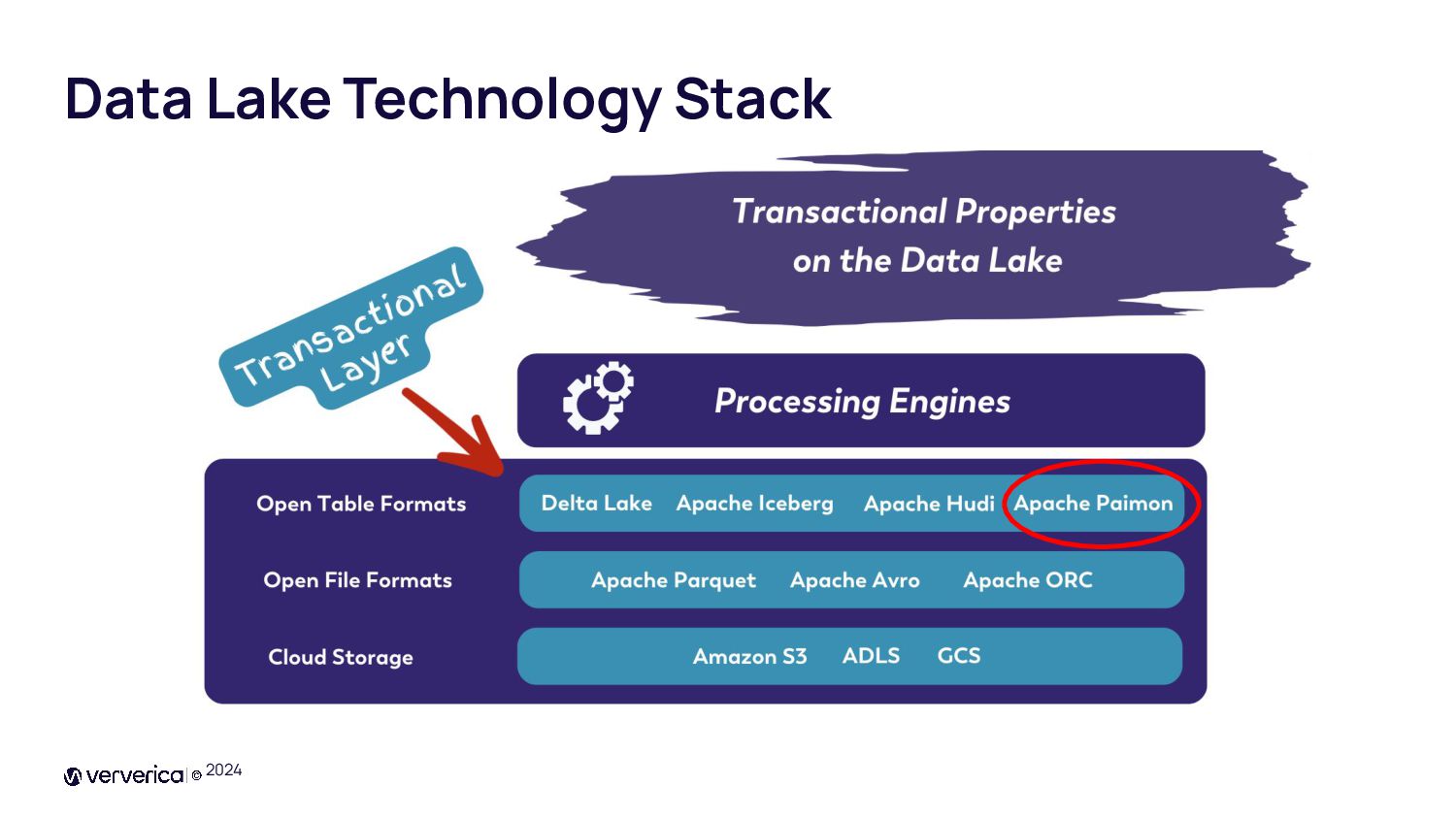{kind=link}
{kind=link}
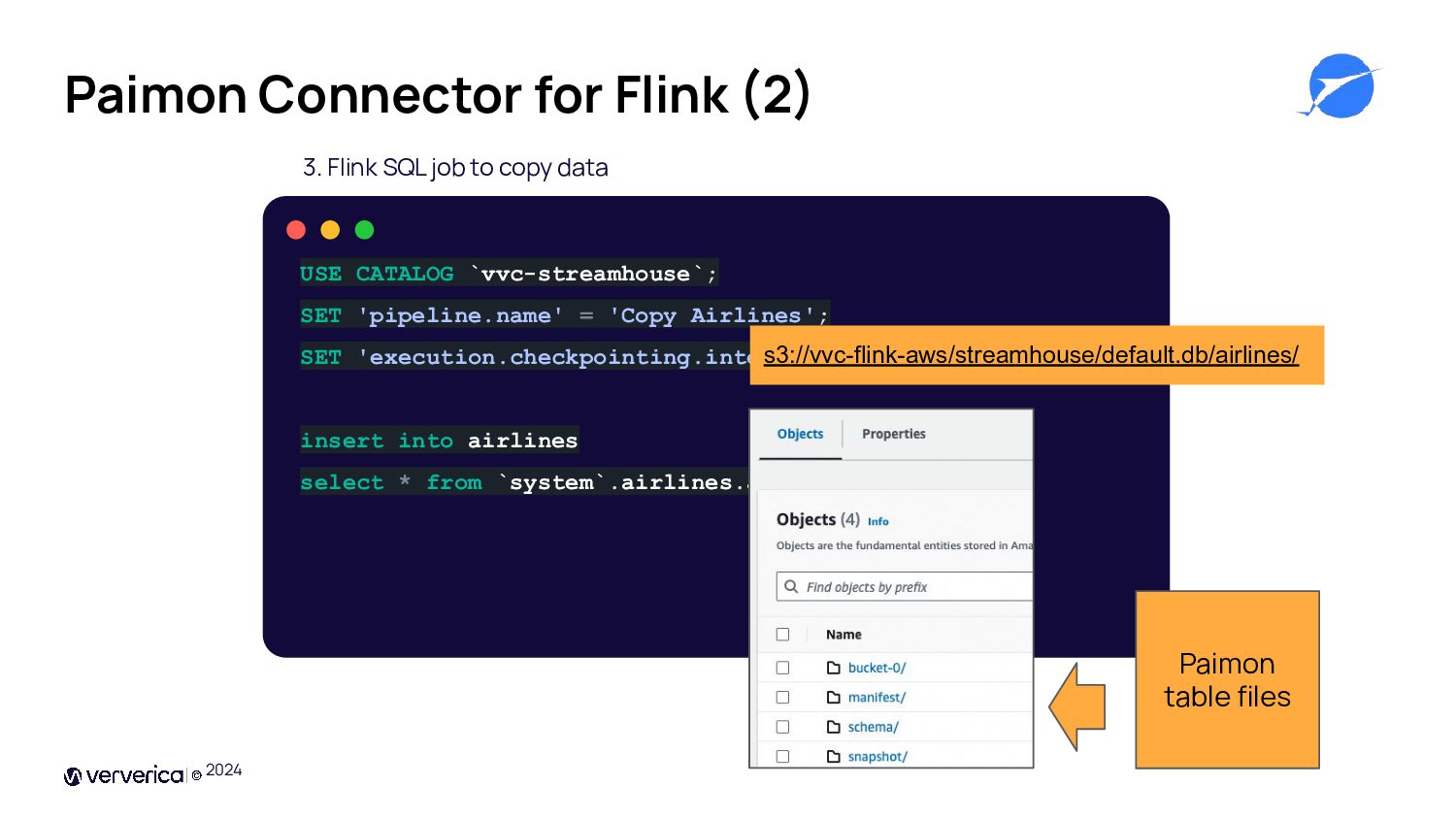{kind=link}
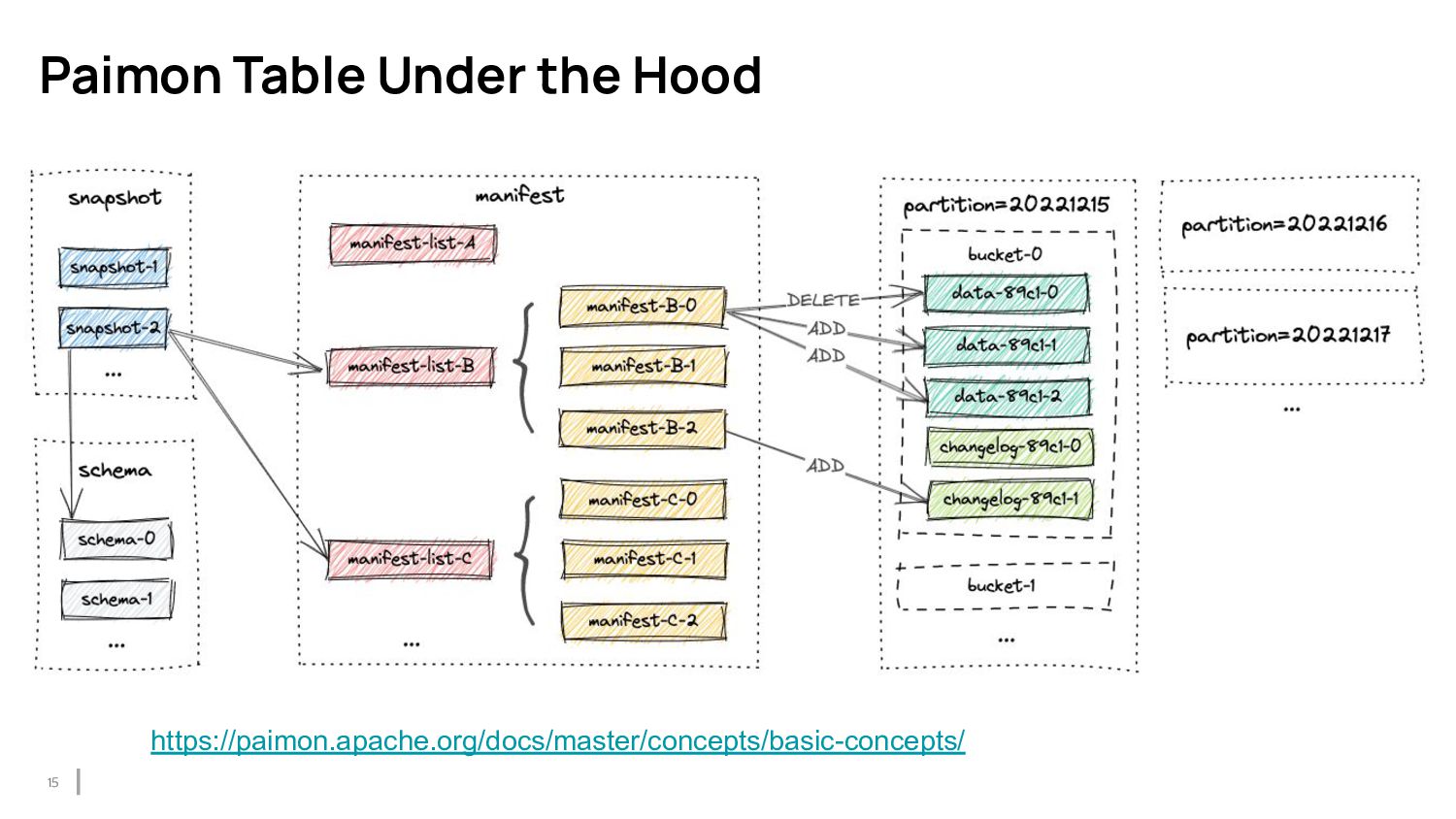{kind=link}
{kind=link}
{kind=link}
{kind=link}
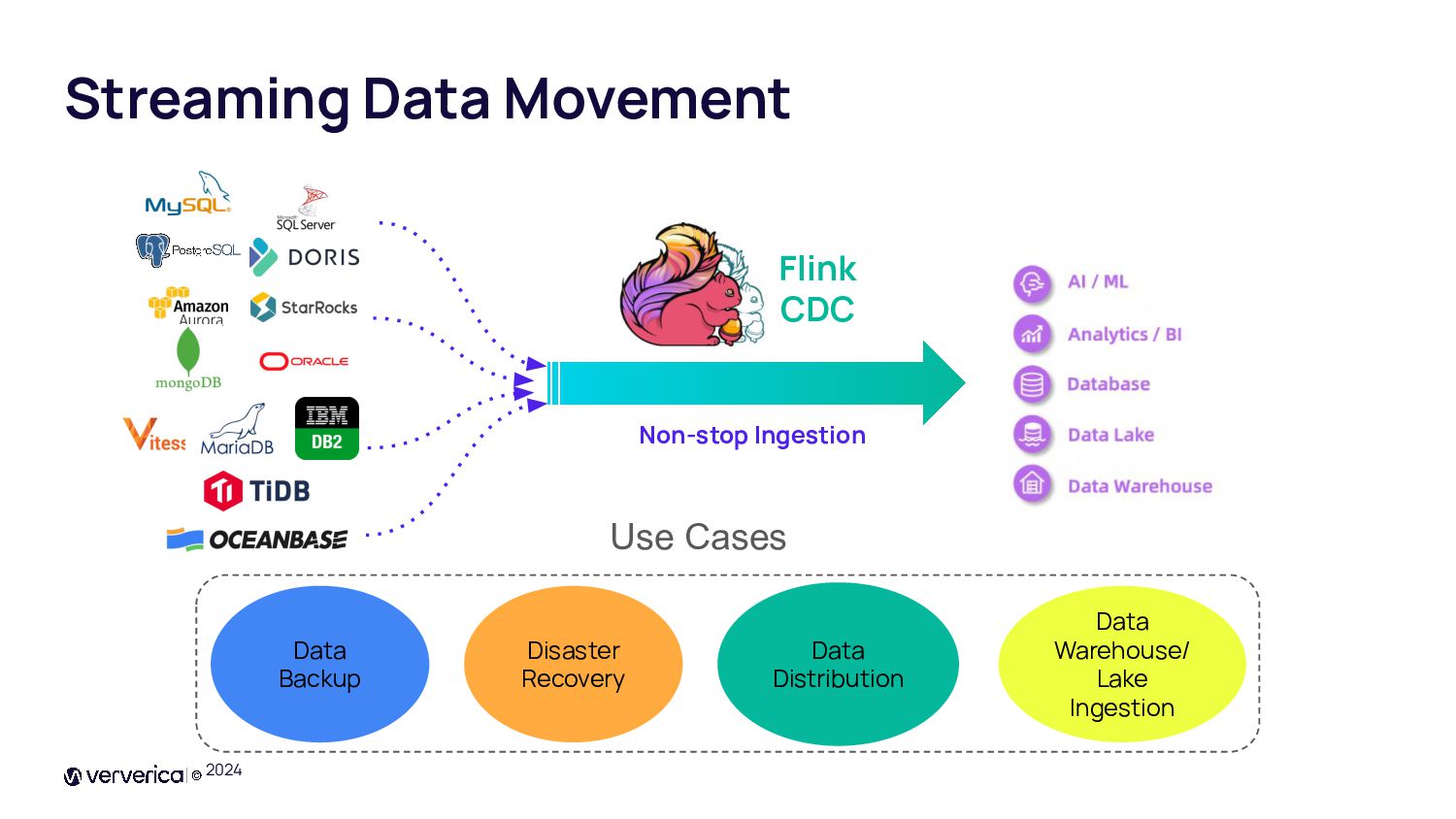{kind=link}
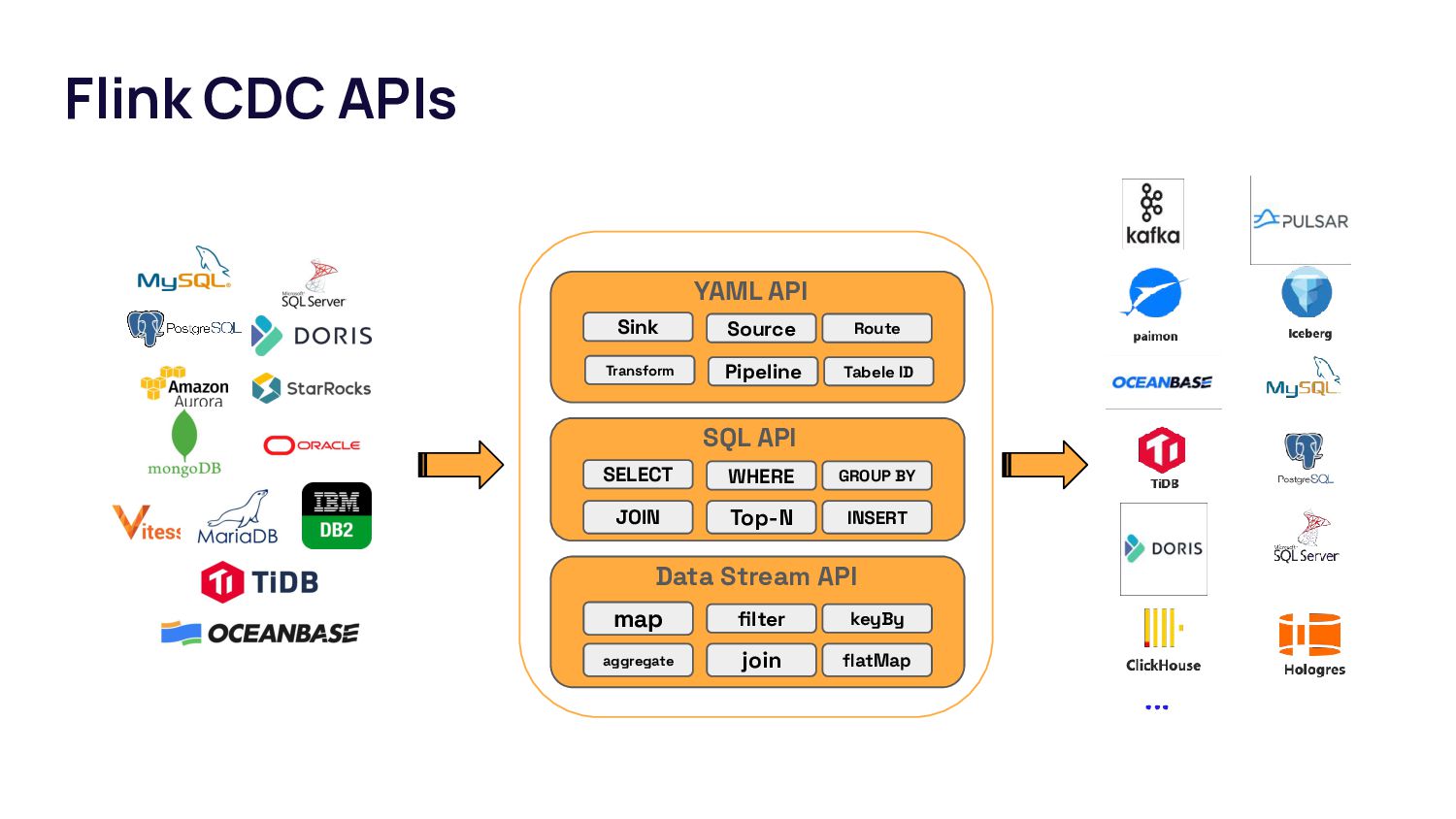{kind=link}
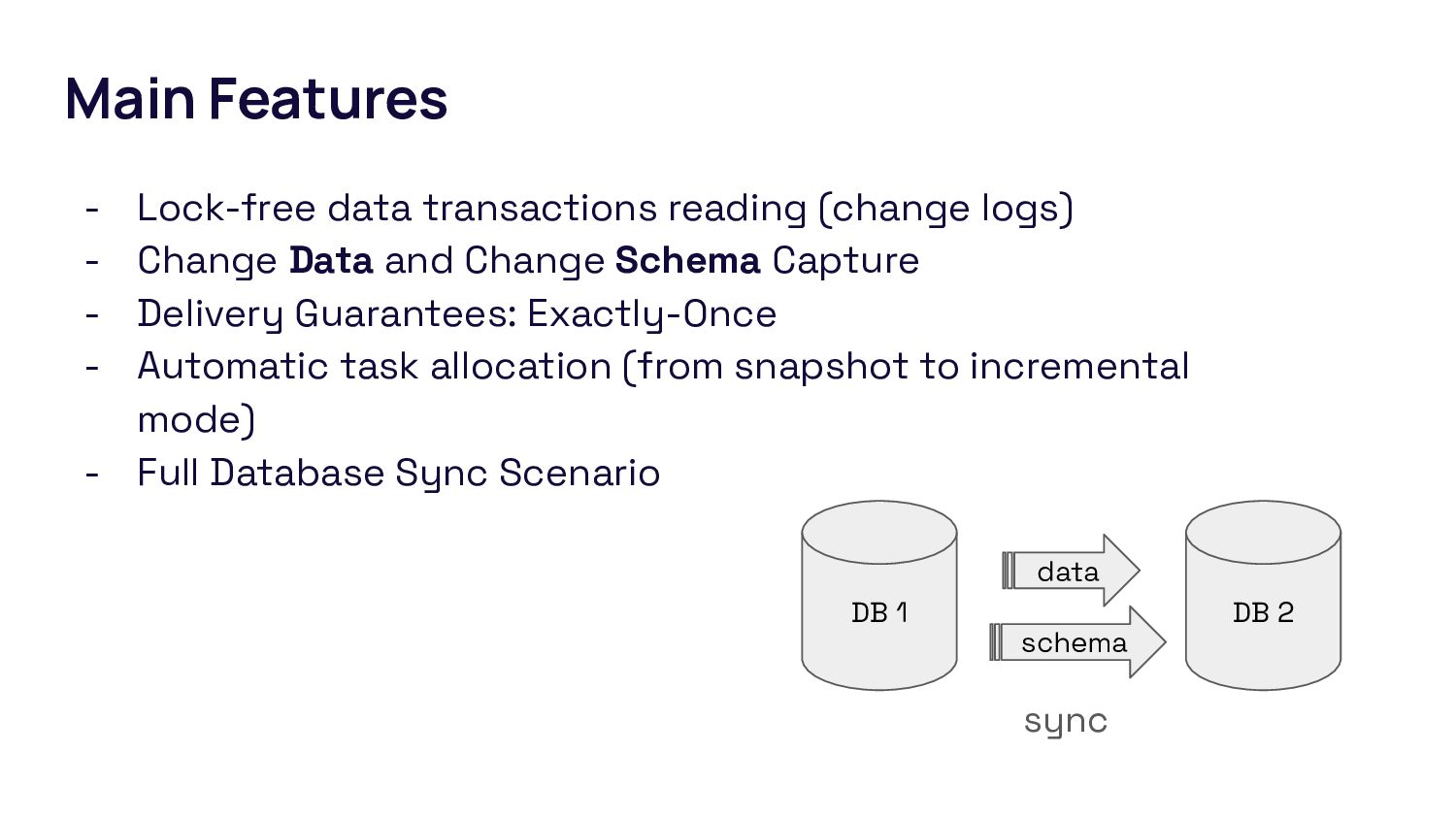{kind=link}
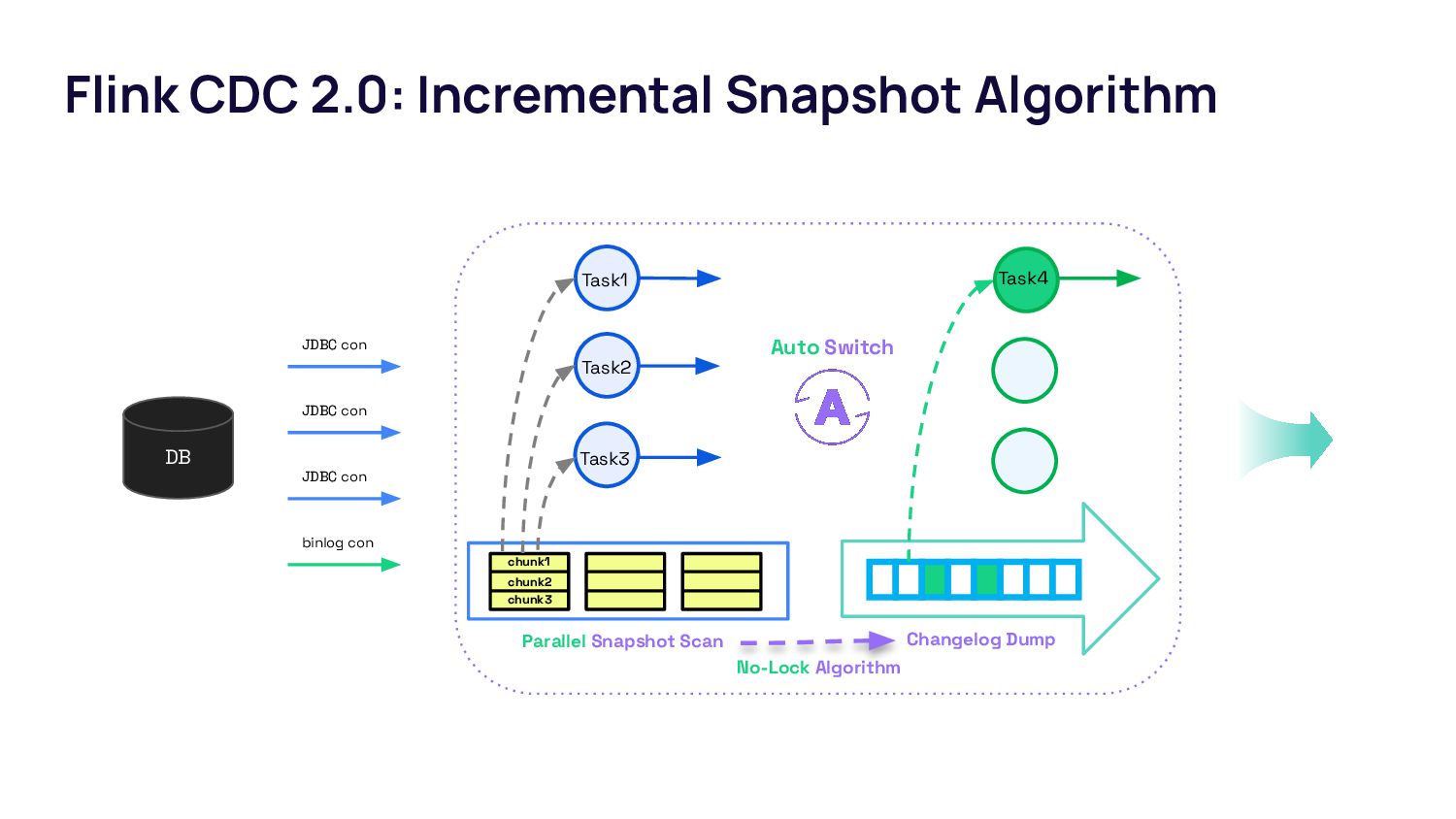{kind=link}
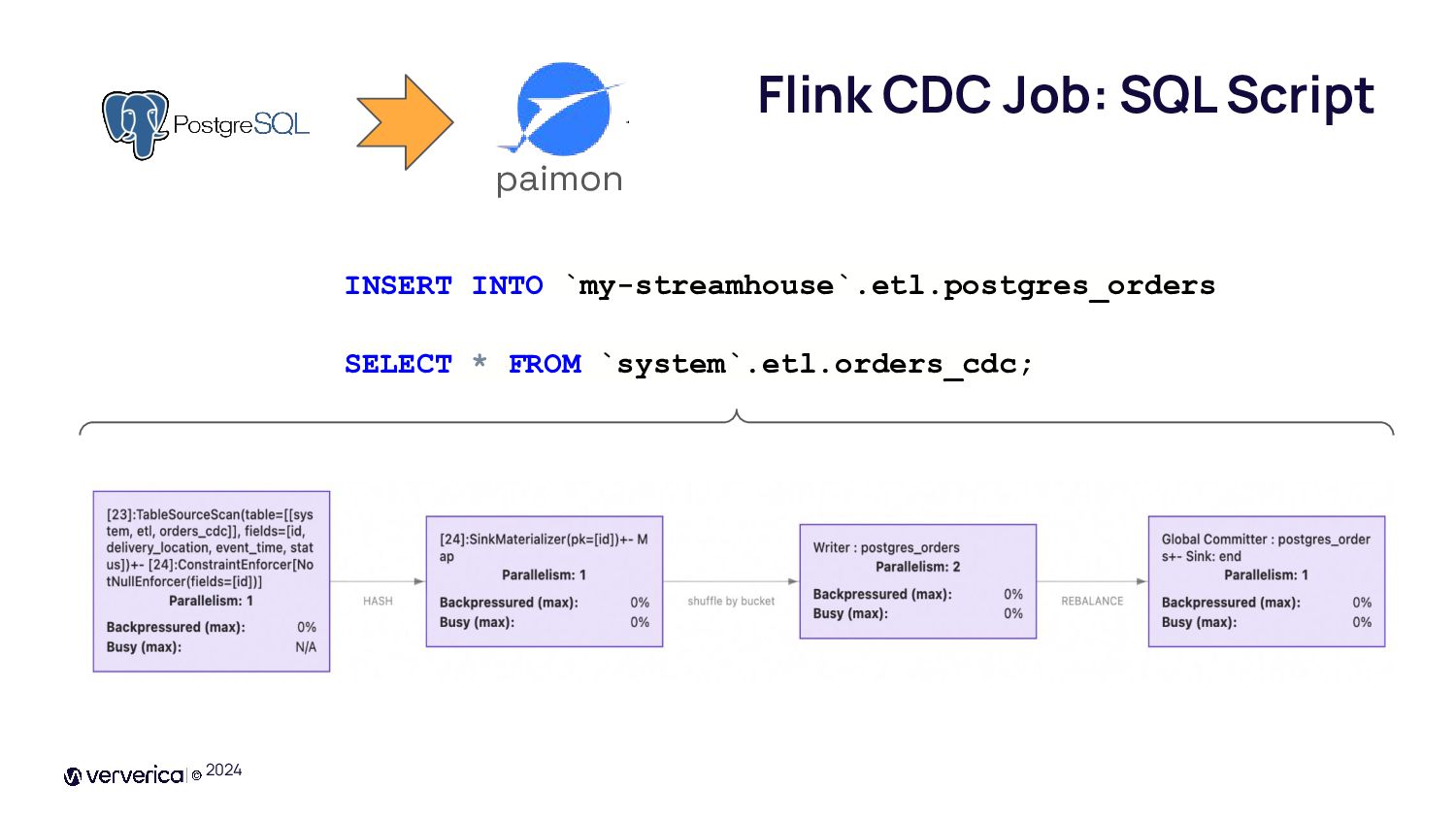{kind=link}
{kind=link}
{kind=link}
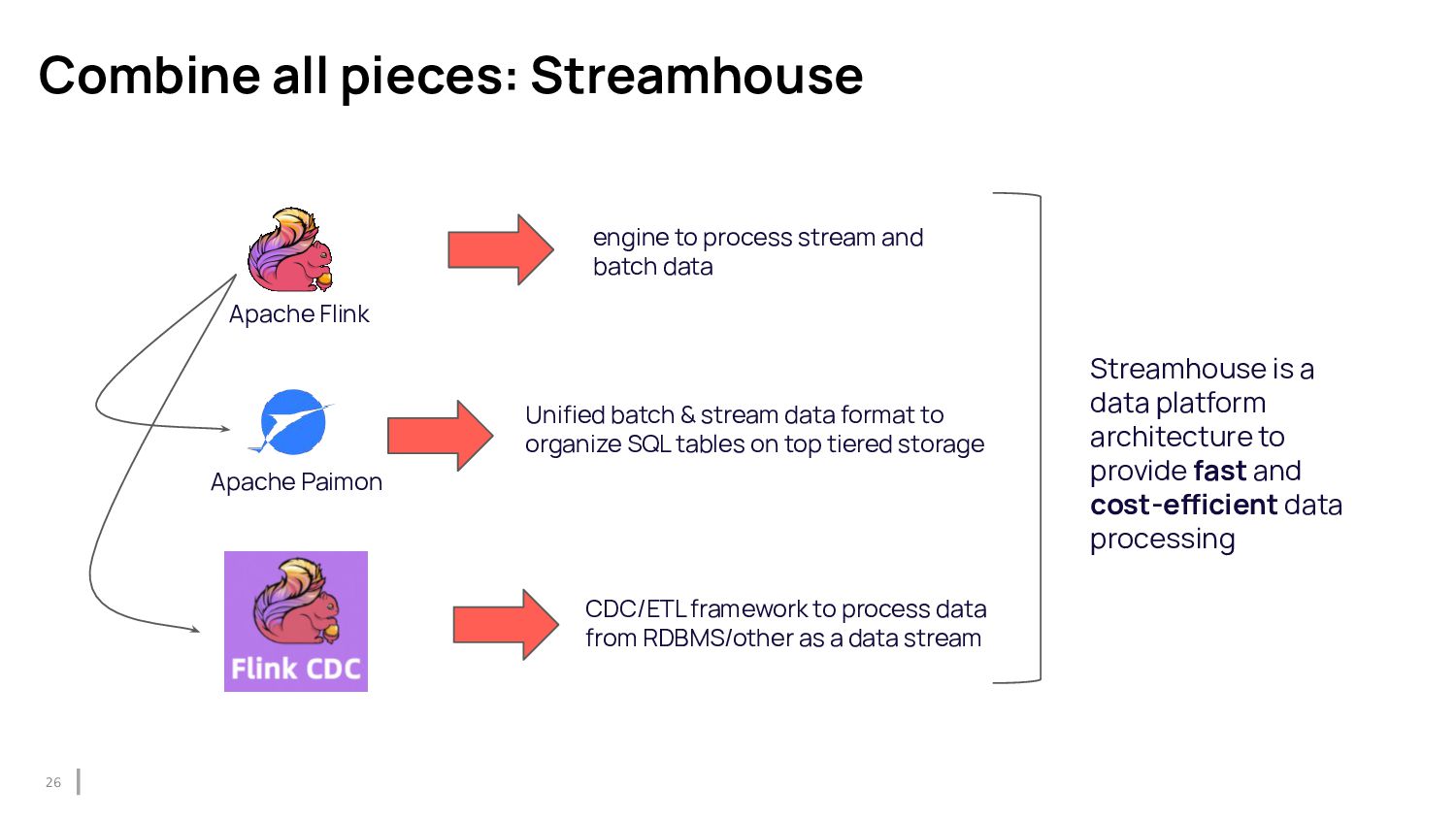{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}