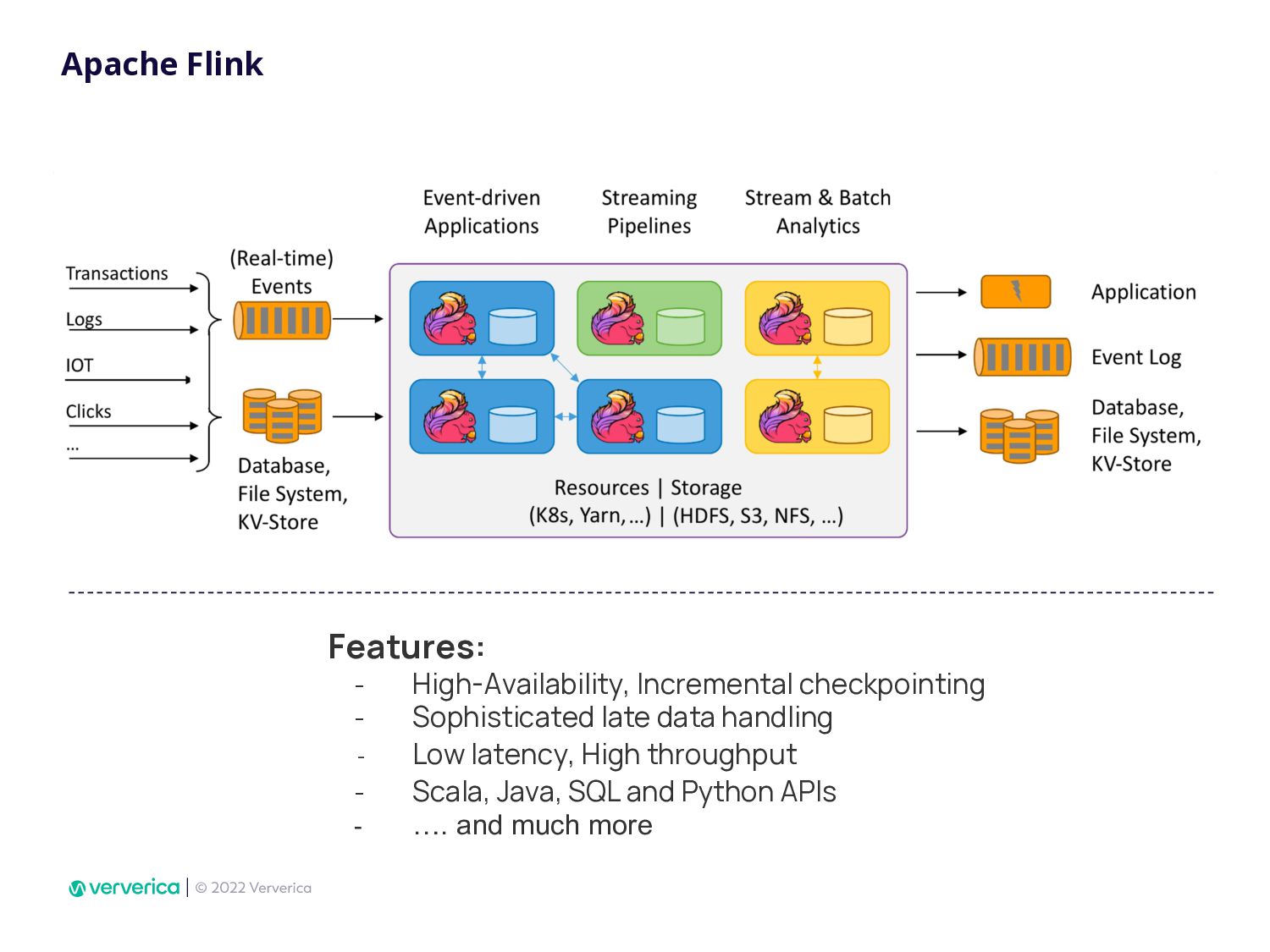
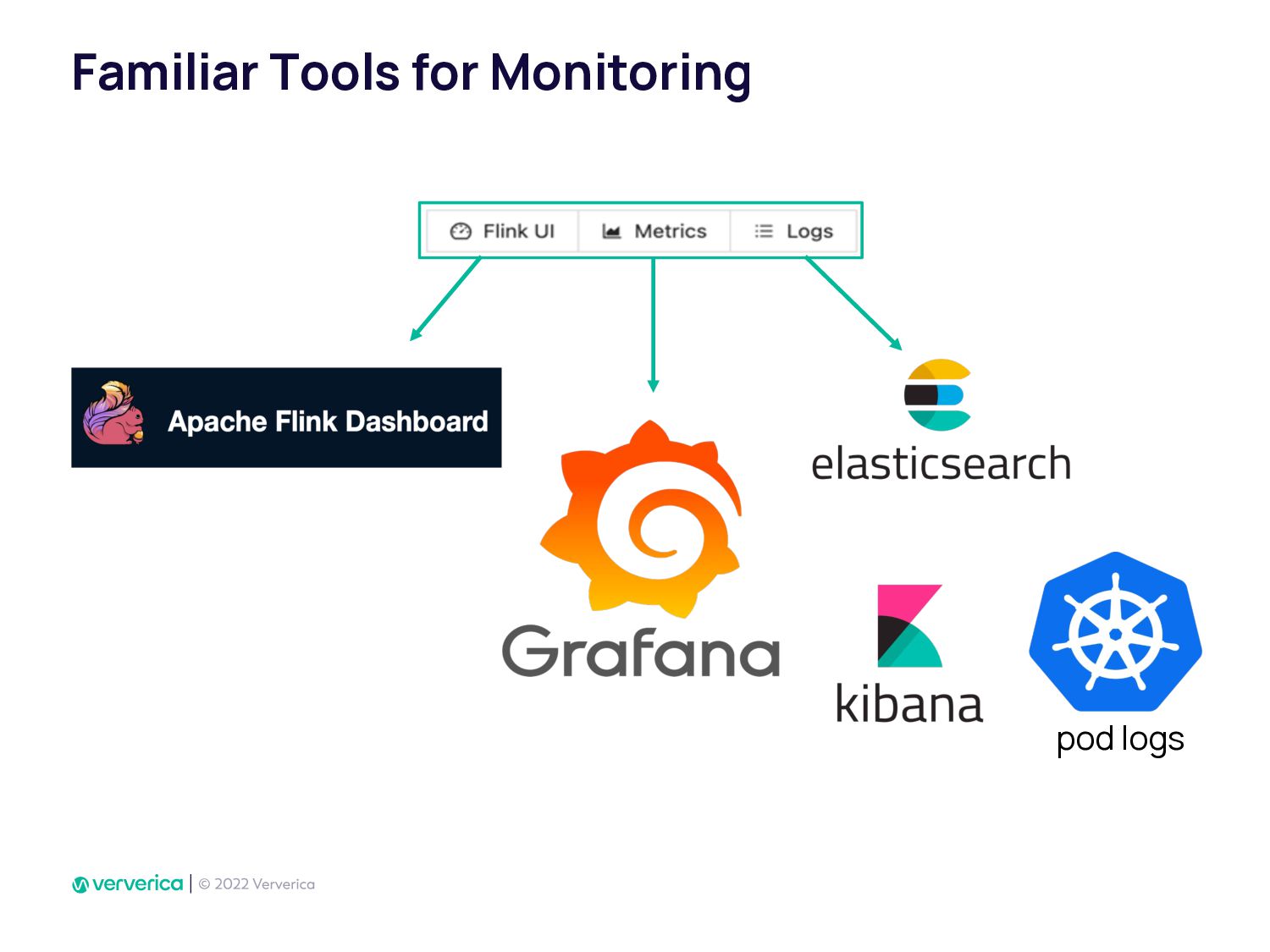
As a developer, in order to deploy locally tested Apache Flink Job to production it may take a while. Especially when you need to work with DevOps team to provide robust environment with Flink cluster, which can scale horizontally. A Flink cluster must provide all the tooling to monitor and debug job issues easilly. When deployment of the next streaming app managed by others than developers, it slows down the entire business who wants to leverage streaming data and quickly enable new business use cases.
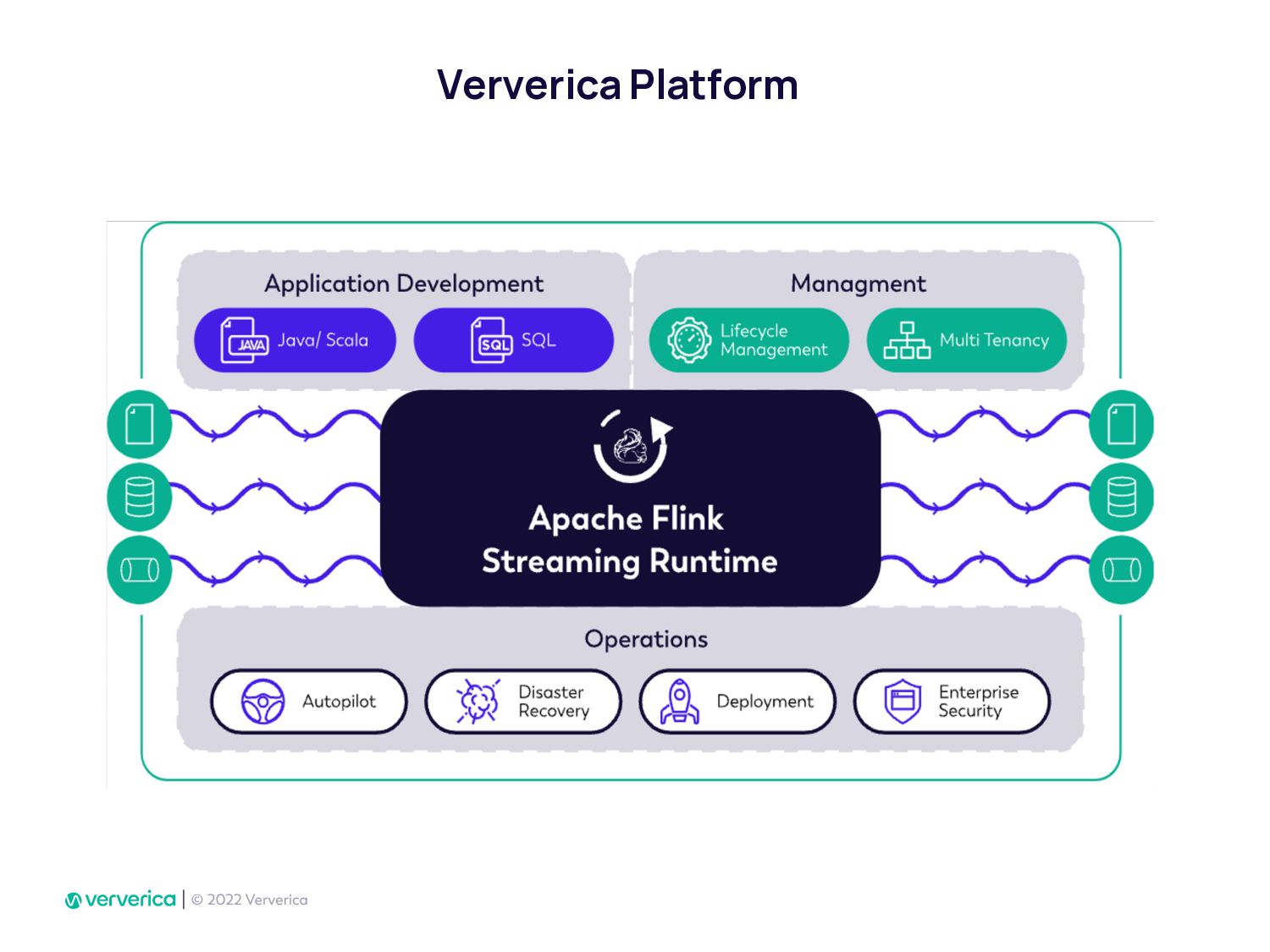
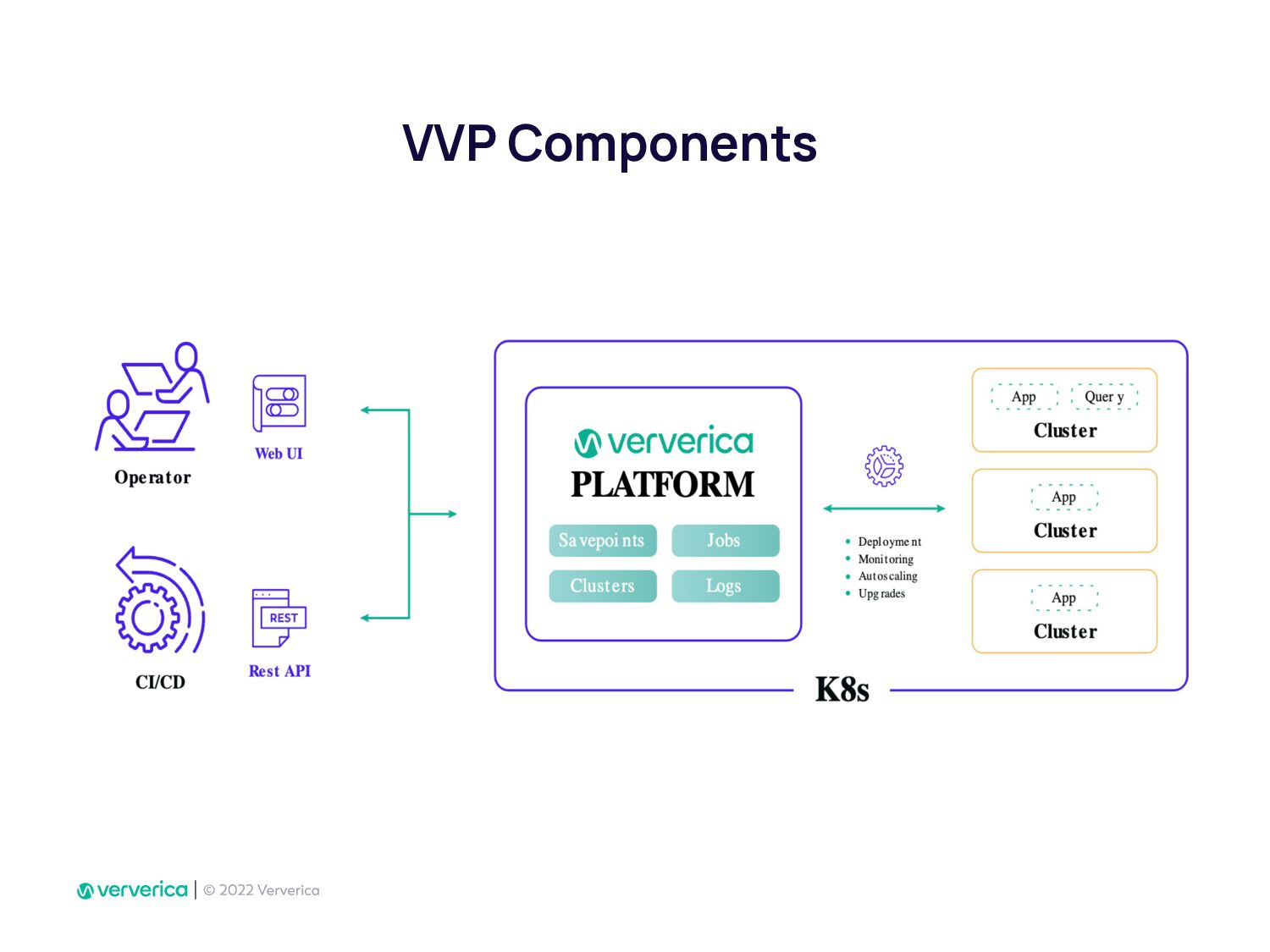
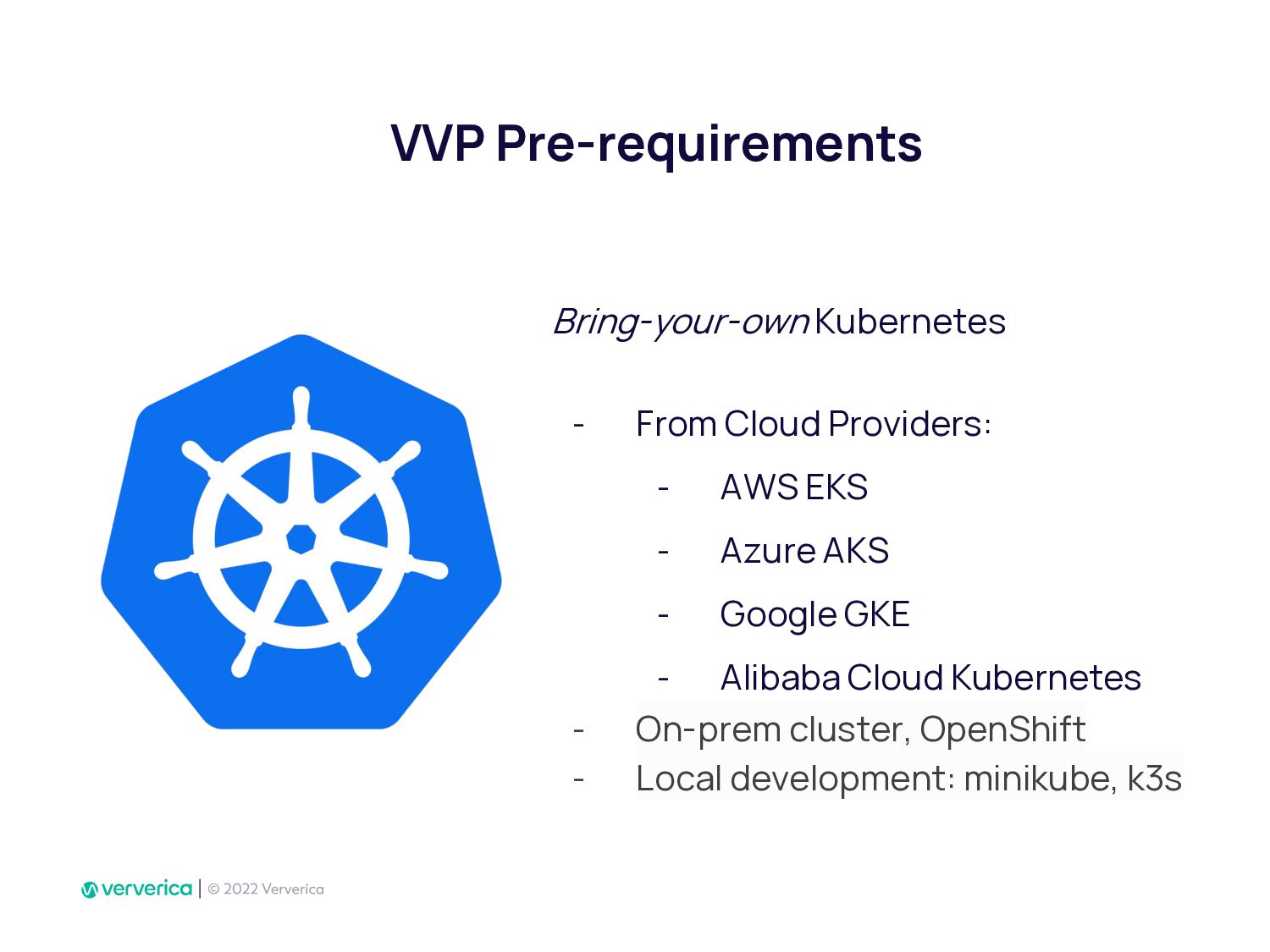
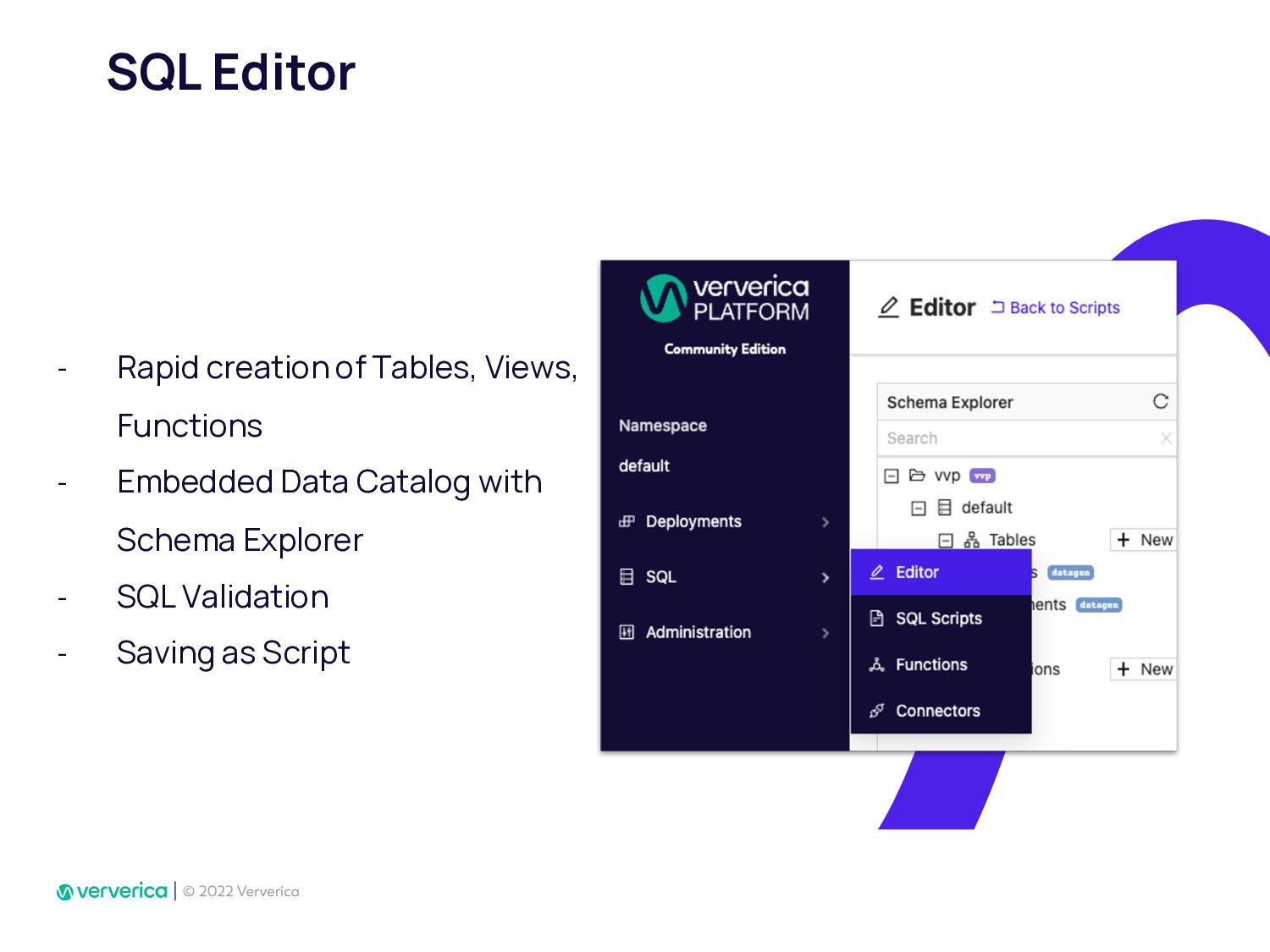
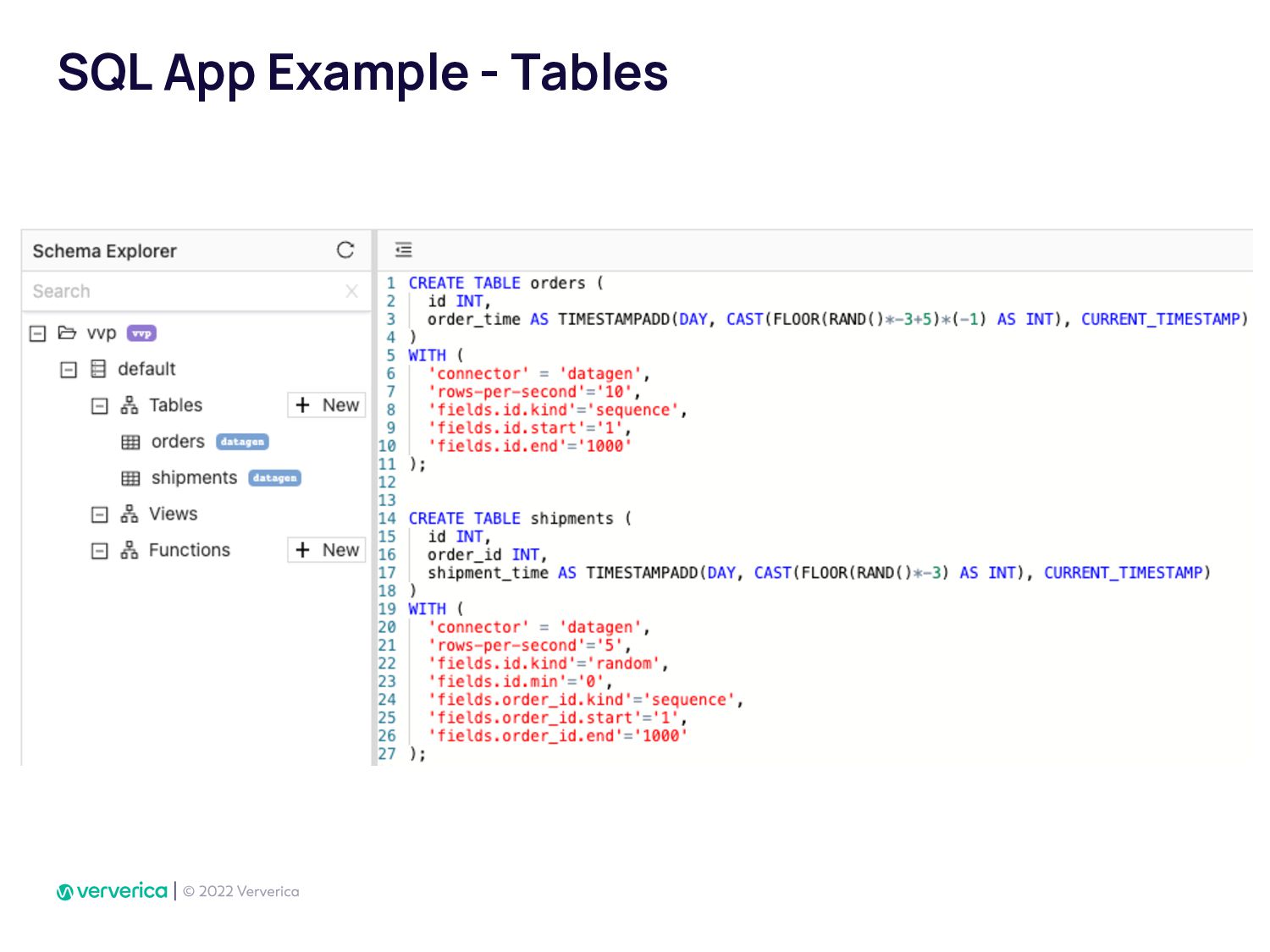
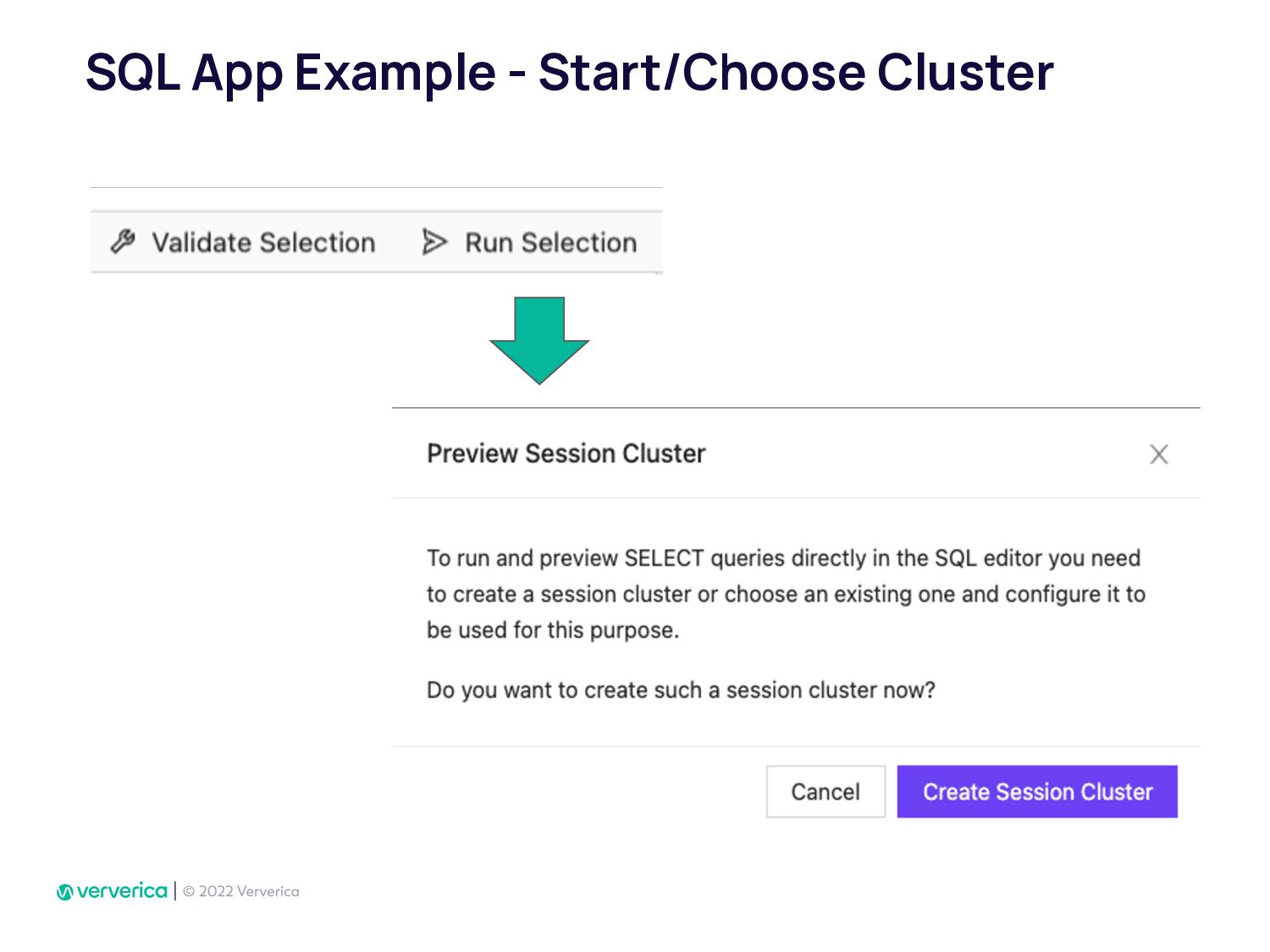
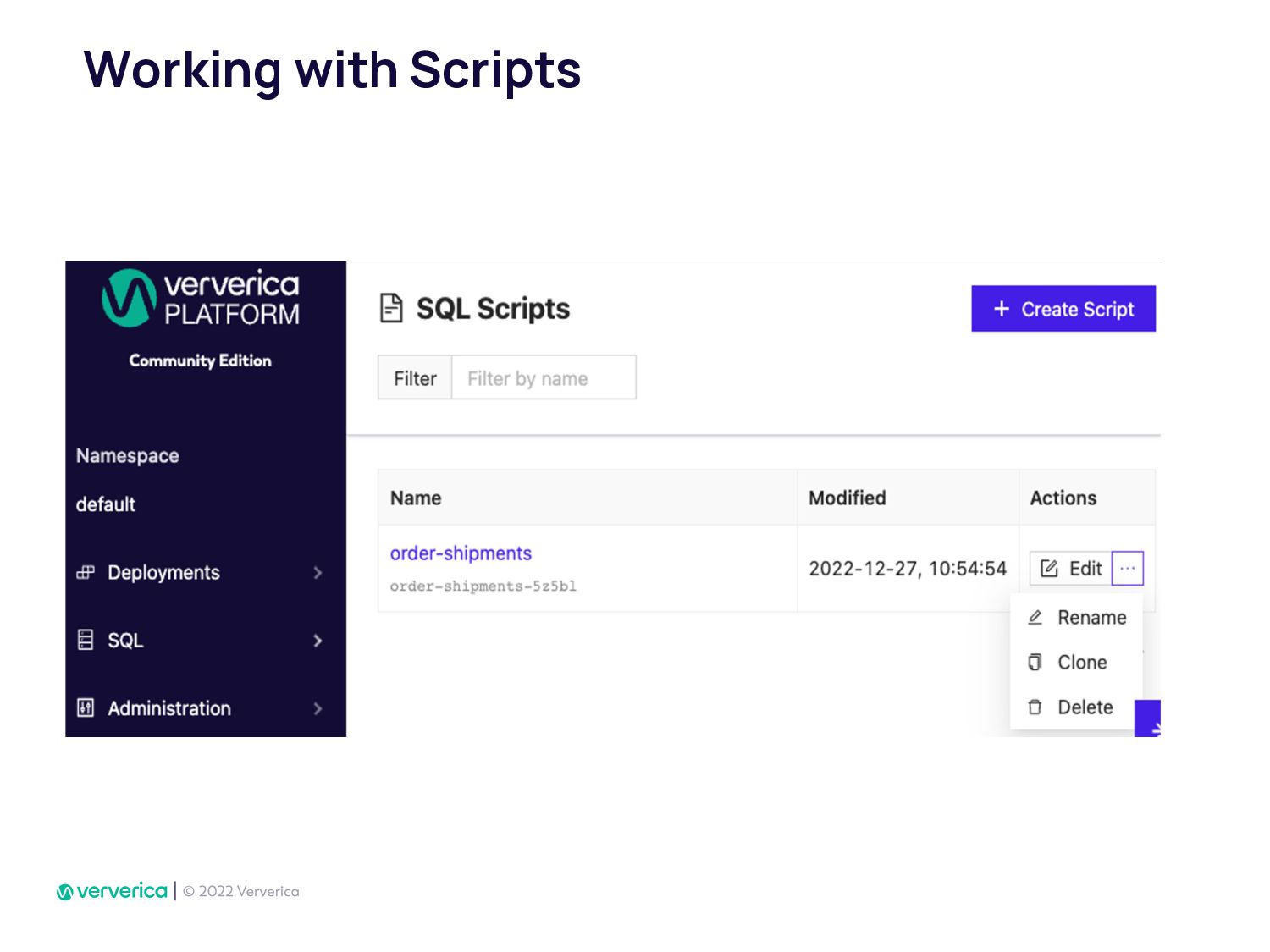
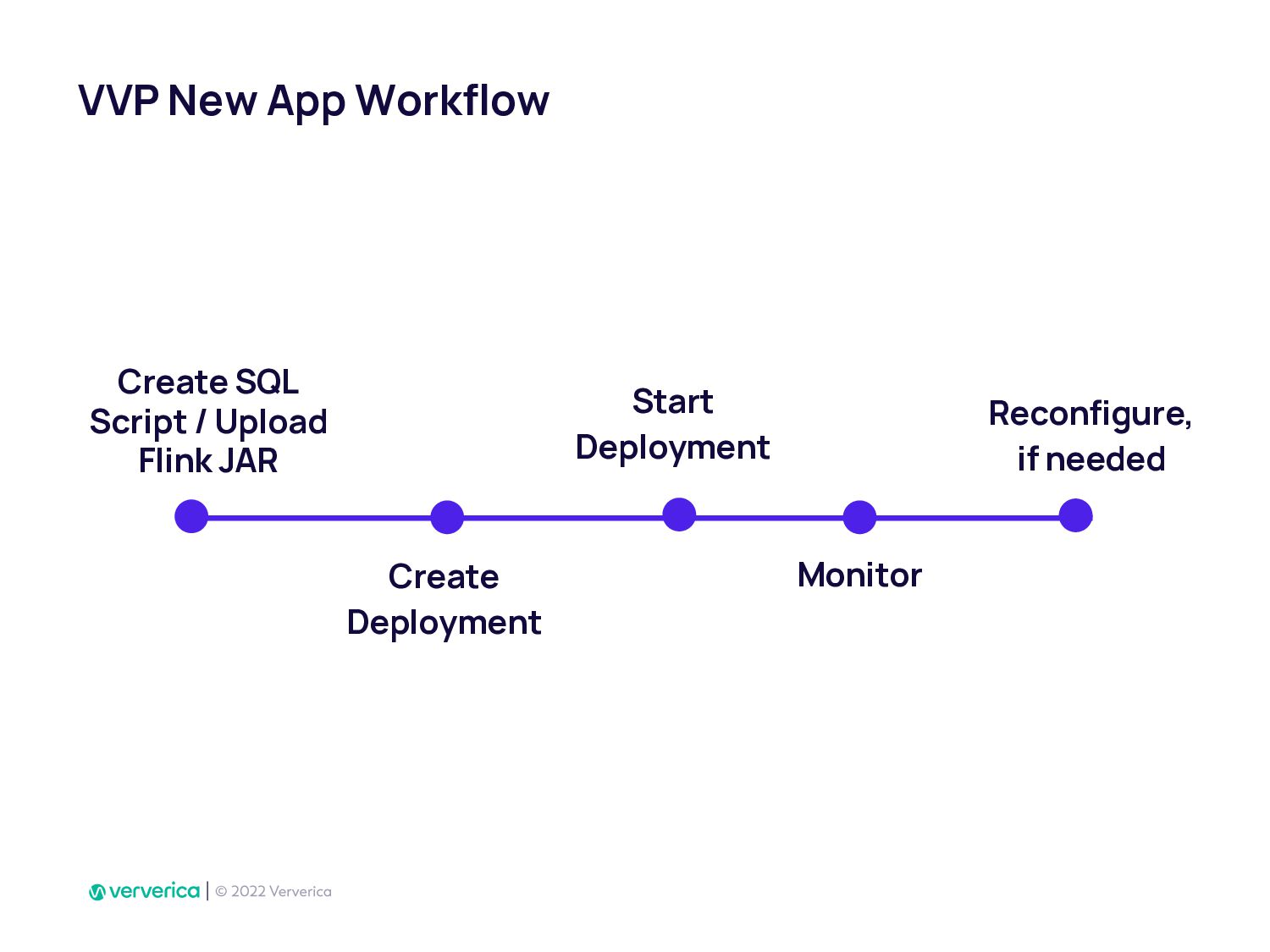
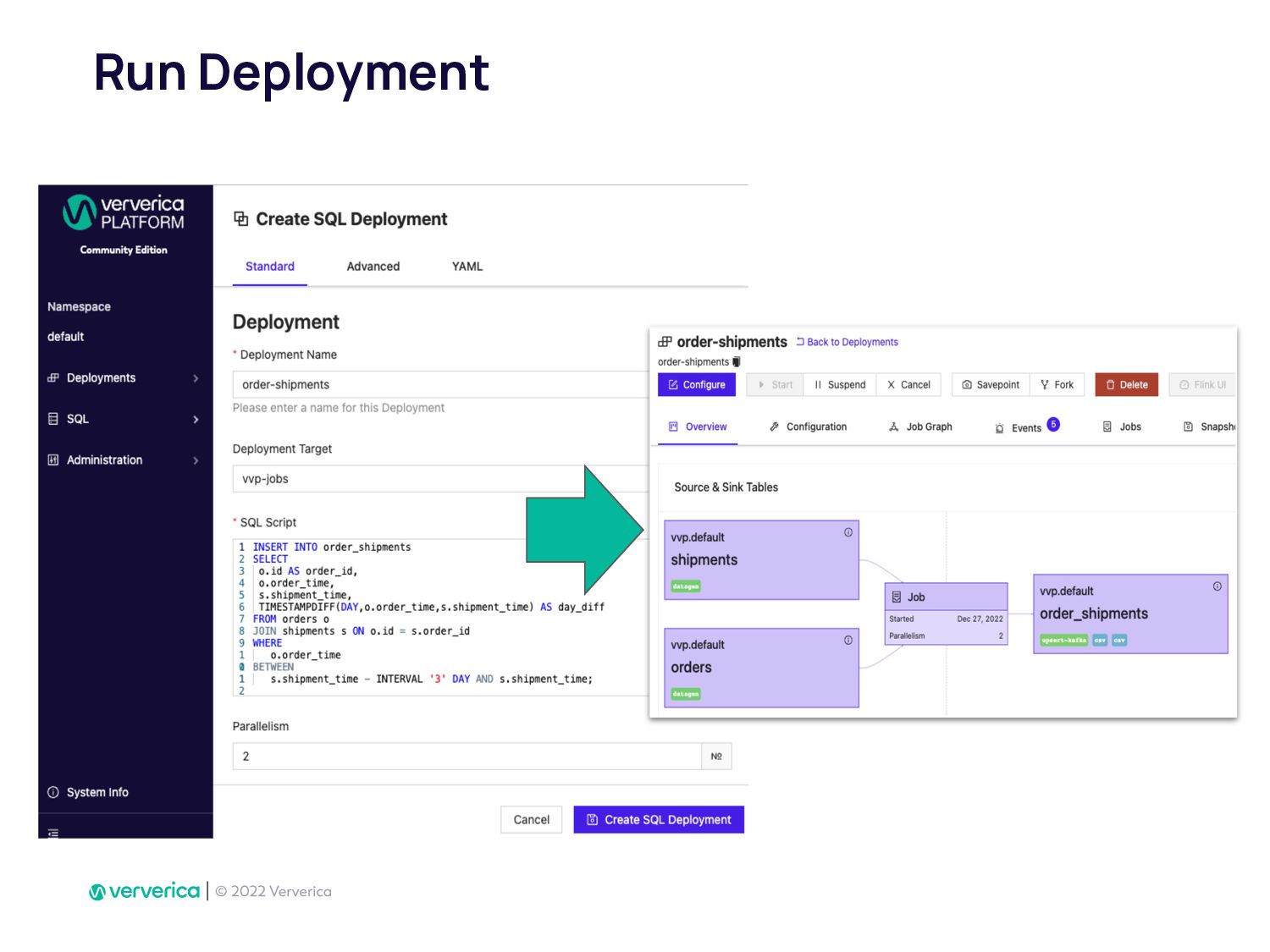
In Ververica, we have taken this issue very seriously by developing Ververica Platform (VVP) which runs Apache Flink with additional unique features. Using VVP UI to create a Job deployment has never been so easy. It also allows Flink SQL developers to create application jobs automatically from VVP SQL Editor. VVP can be installed on your Kubernetes cluster in minutes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you. Questions? [email protected] www.ververica.com @VervericaData](https://files.speakerdeck.com/presentations/d846119f40ba46d39e8dc9b989cb53d0/slide_36.jpg){kind=link}