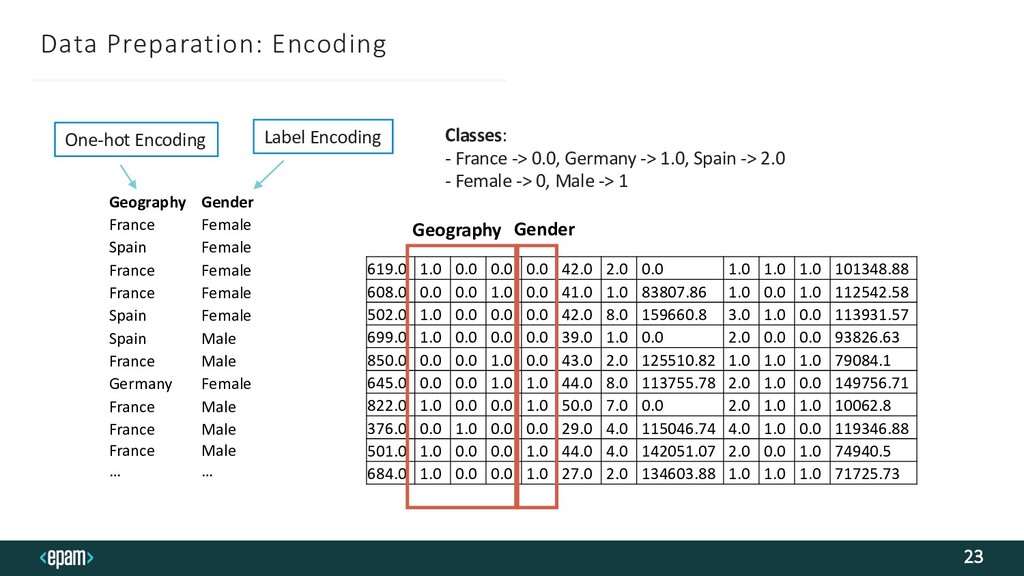
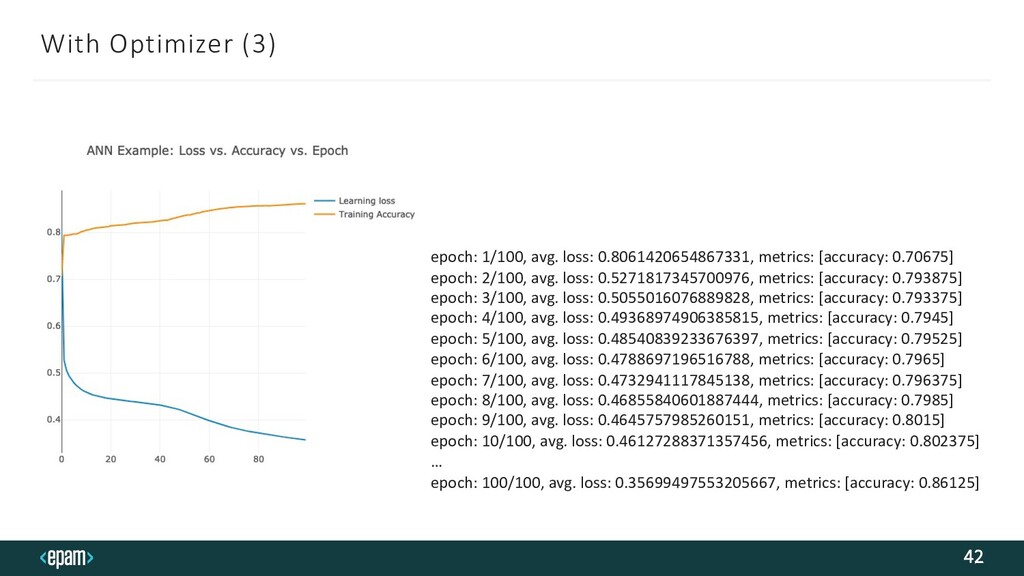
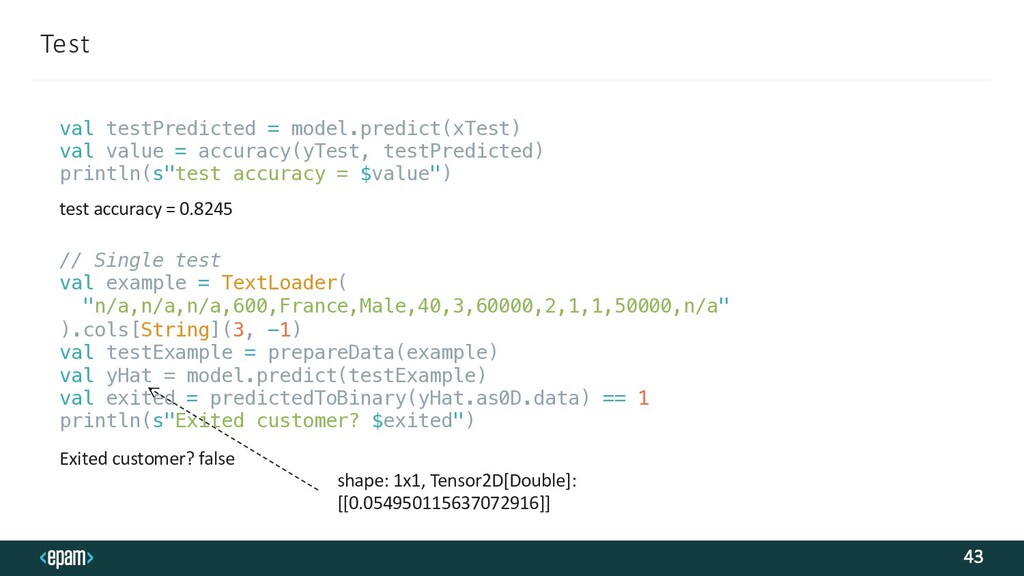
Classifier RowNumber,CustomerId,Surname,CreditScore,Geography,Gender,Age,Tenu re,Balance,NumOfProducts,HasCrCard,IsActiveMember,EstimatedSalary,Exit ed 1,15634602,Hargrave,619,France,Female,42,2,0,1,1,1,101348.88,1 2,15647311,Hill,608,Spain,Female,41,1,83807.86,1,0,1,112542.58,0 3,15619304,Onio,502,France,Female,42,8,159660.8,3,1,0,113931.57,1 4,15701354,Boni,699,France,Female,39,1,0,2,0,0,93826.63,0 CreditScore, Geography, Gender, Age, Tenure, Balance, NumOfProducts, HasCrCard, IsActiveMember, EstimatedSalary Raw Data (not encoded): Input features as X: Target as Y: Exited
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Tensor in Scala 18 sealed trait Tensor[T]: def length: Int](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_17.jpg){kind=link}
 extends Tensor[T]: override def](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_18.jpg){kind=link}
 // dot product](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 val ((xTrain,](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
![Model 29 sealed trait Model[T]: def train(x: Tensor[T], y: Tensor[T],](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_28.jpg){kind=link}
{kind=link}
![Layer Stack 31 def add(layer: LayerCfg[T]): Sequential[T, U] = copy(layerStack](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_30.jpg){kind=link}
![Training Algorithm 32 x: Tensor[T], y: Tensor[T] layers: List[Layer[T]] =>](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_31.jpg){kind=link}
![Train N epochs 33 def train(x: Tensor[T], y: Tensor[T], epochs:](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_32.jpg){kind=link}
![Train on batches: forward 34 private def trainEpoch( batches: Array[(Array[Array[T]],](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Optimizer 38 type Stub trait Optimizer[U]: def updateWeights[T: ClassTag: Fractional](](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_37.jpg){kind=link}
{kind=link}
![With Optimizer (1) 40 type StandardGD weights: List[Layer[T]], activations: List[Activation[T]],](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_39.jpg){kind=link}
![With Optimizer (2): Backpropagation + Gradient Descent 41 layers.zip(activations) .foldRight(List.empty[Layer[T]],](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Test 45 sealed trait Model[T]: def predict(x: Tensor[T]): Tensor[T] Feed](https://files.speakerdeck.com/presentations/76c6d533786e4b63974d43675f6f7ce4/slide_44.jpg){kind=link}
{kind=link}
{kind=link}