As a Scala developer writing new Flink job, you expect to use latest Scala 3 version, rather the one Flink was compiled with. Support of Scala 2.13 and Scala 3 was not really possible until Flink 1.15 came out. In this talk we will review how the Scala API was done in Apache Flink prior the version 1.15 and what has changed in that release. Apache Flink chose quite opposite way to enable Scala developers to use any Scala version than Apache Spark project and that is interesting discussion on its own.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
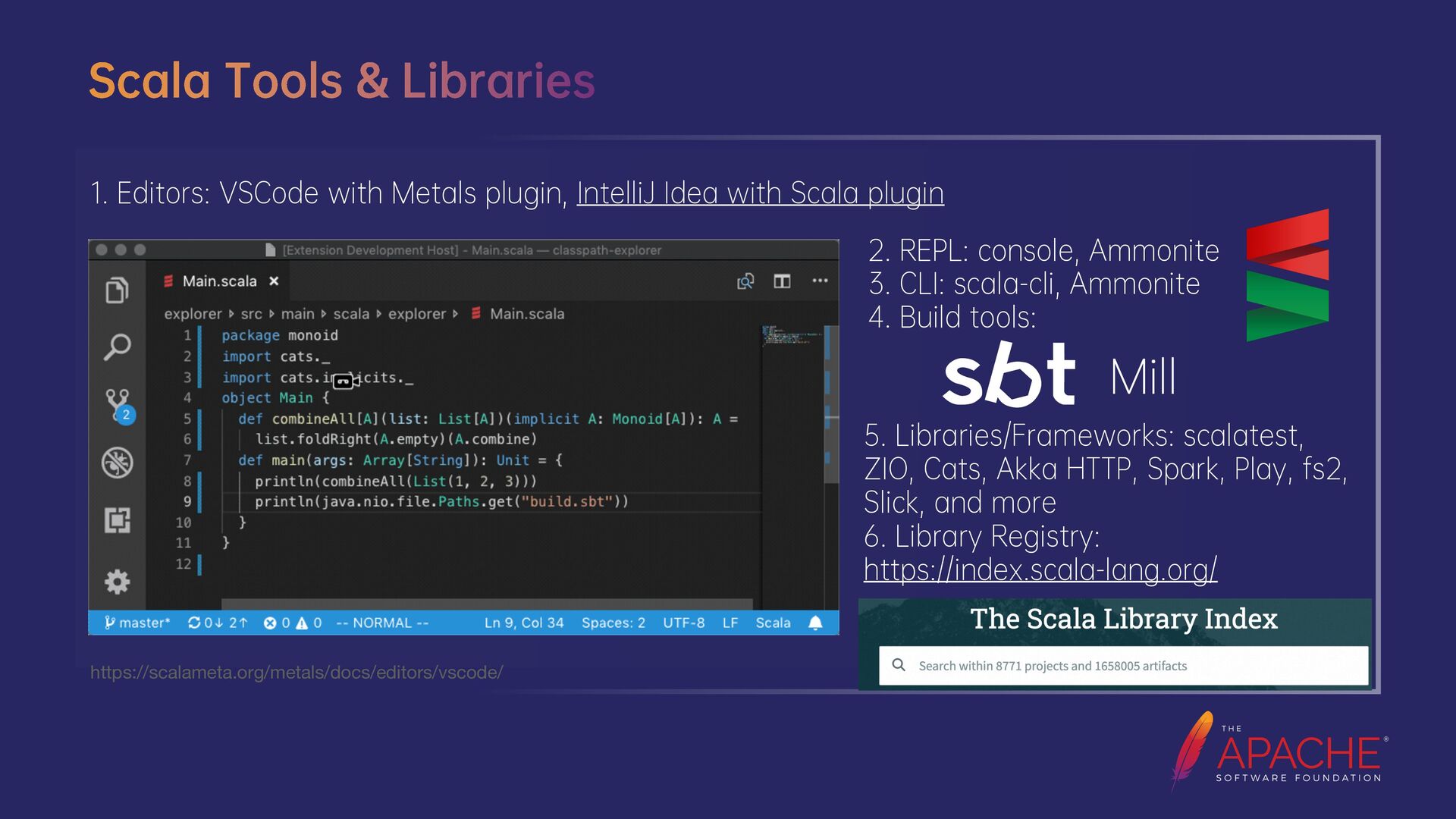{kind=link}
{kind=link}
{kind=link}
{kind=link}
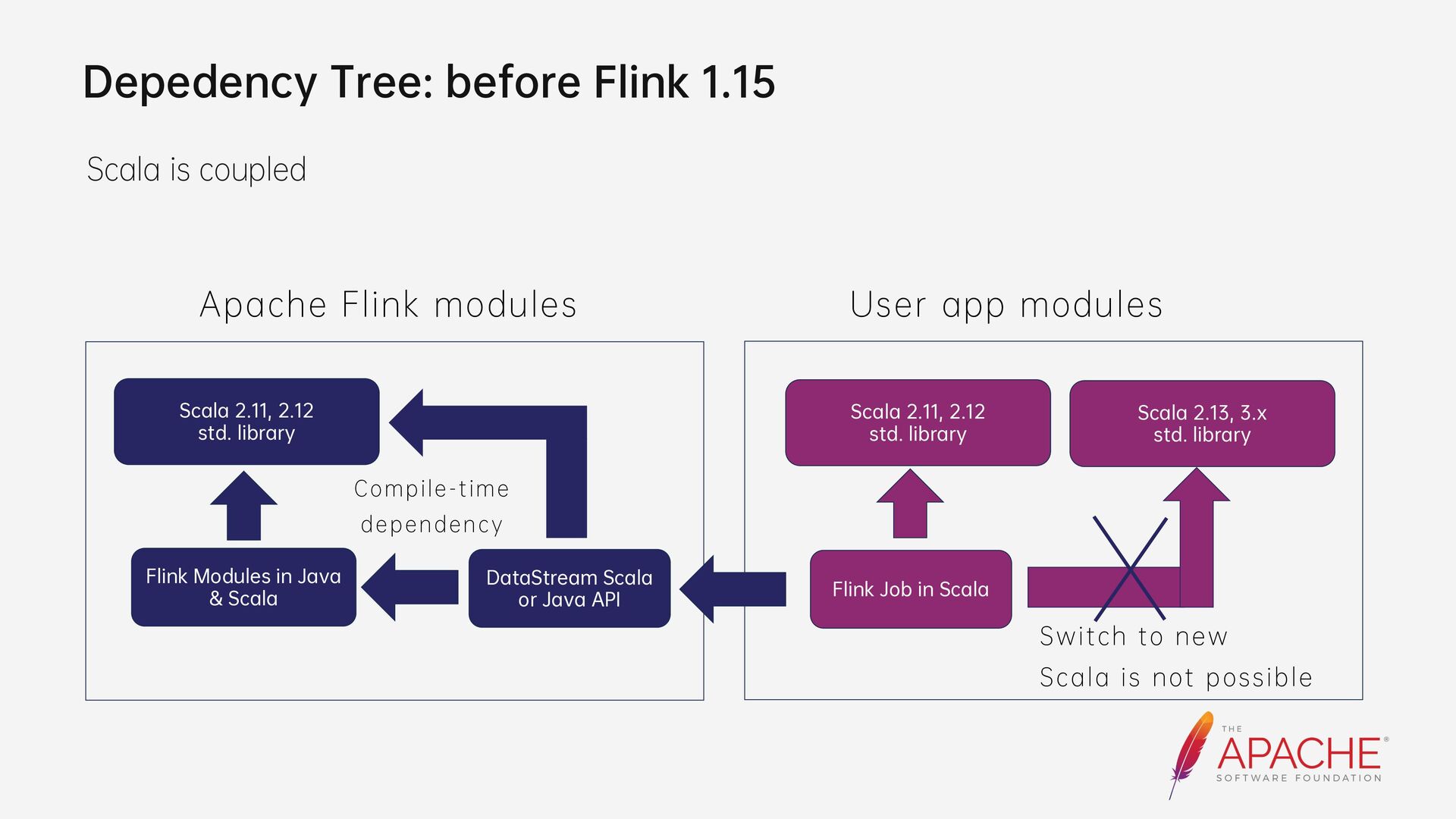{kind=link}
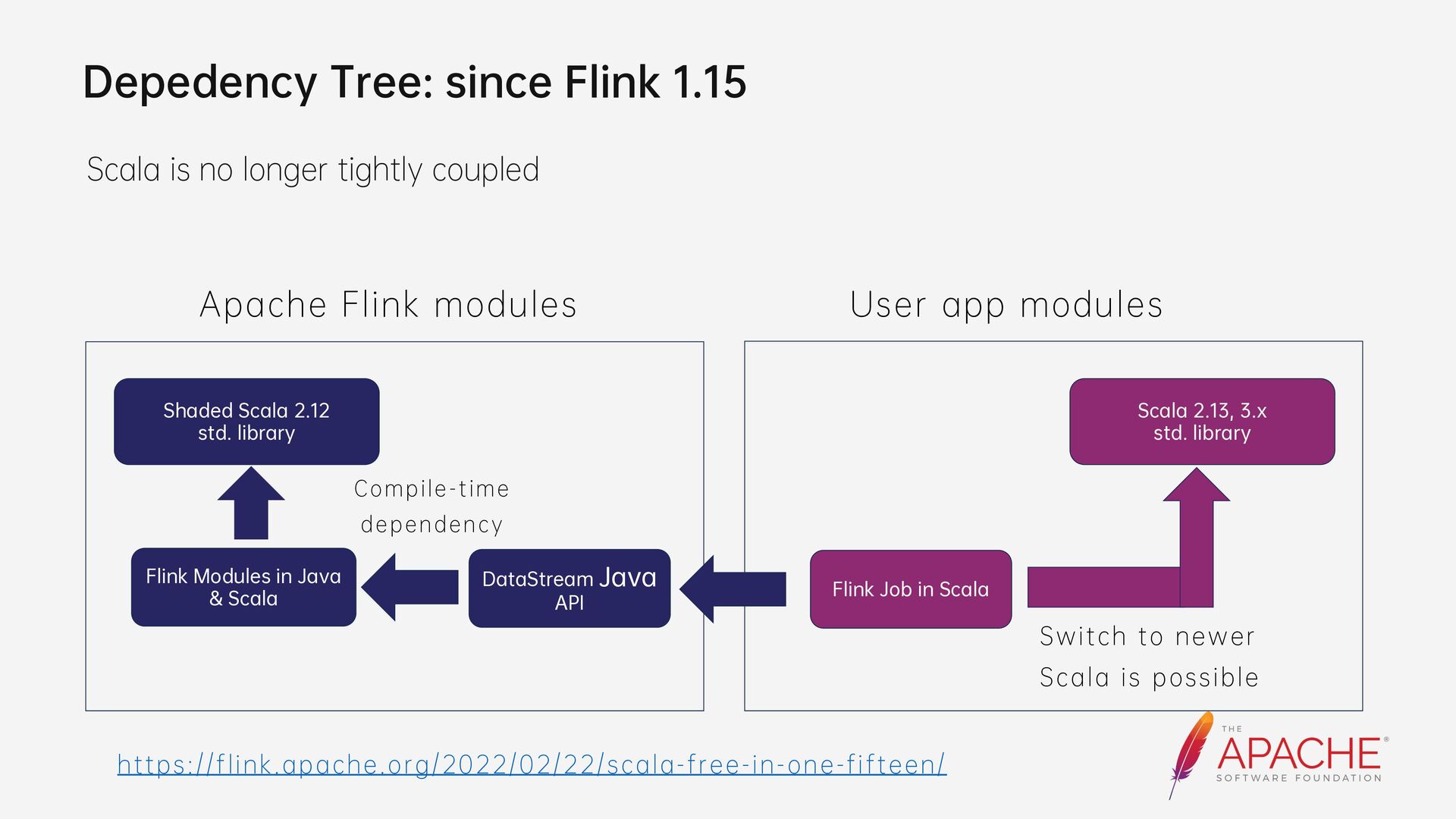{kind=link}
{kind=link}
{kind=link}
{kind=link}
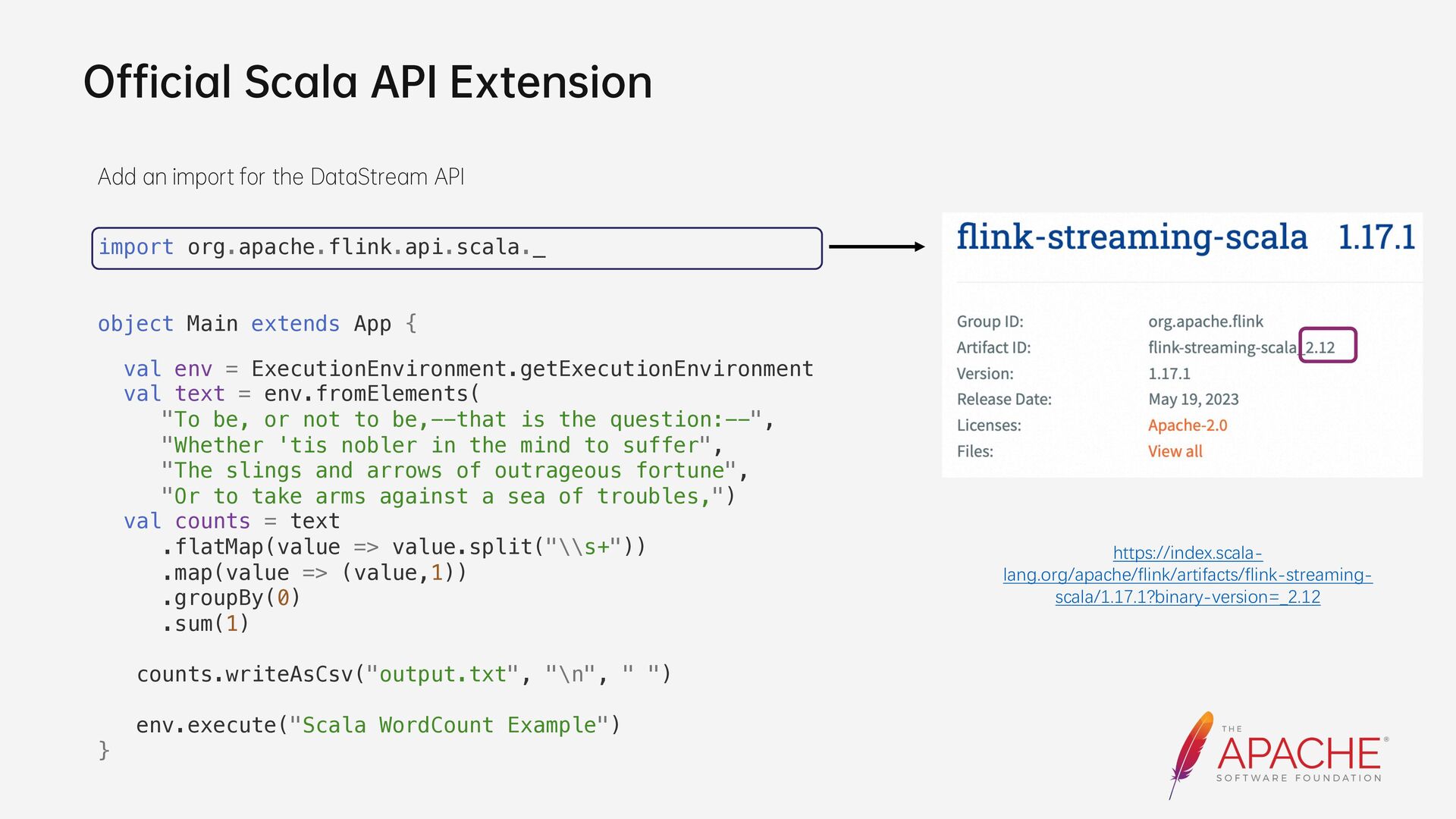{kind=link}
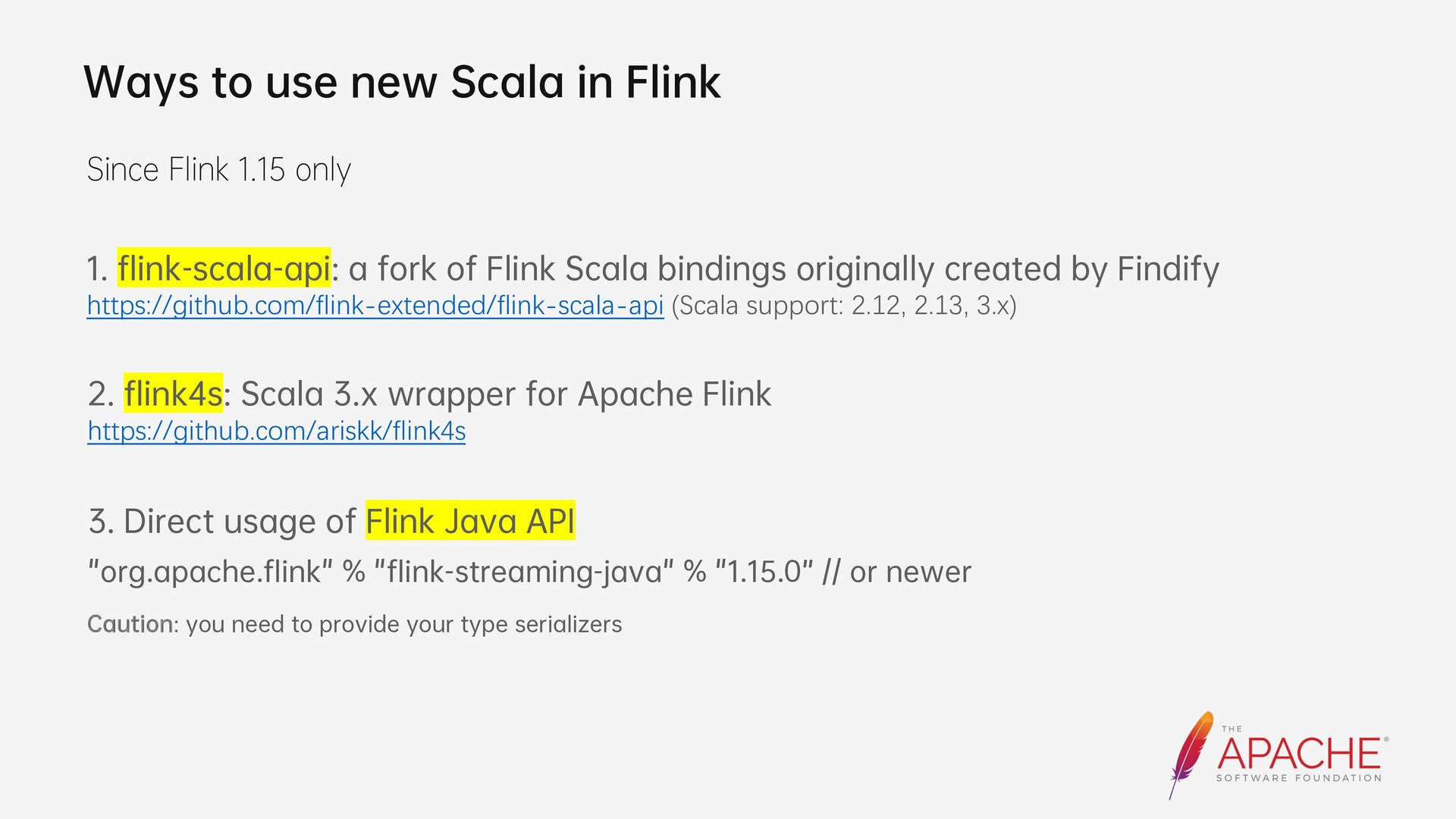{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
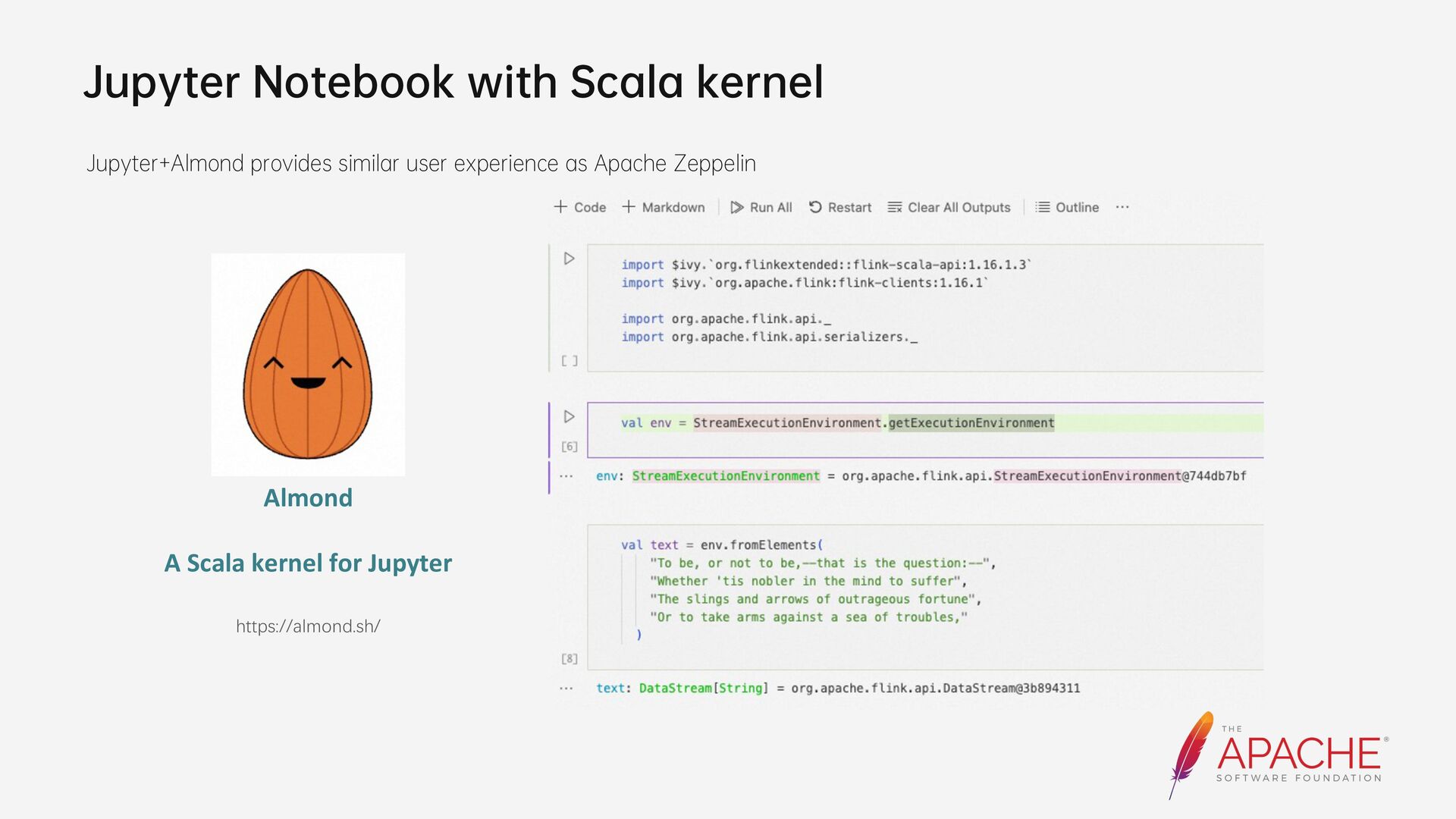{kind=link}
{kind=link}
{kind=link}
{kind=link}