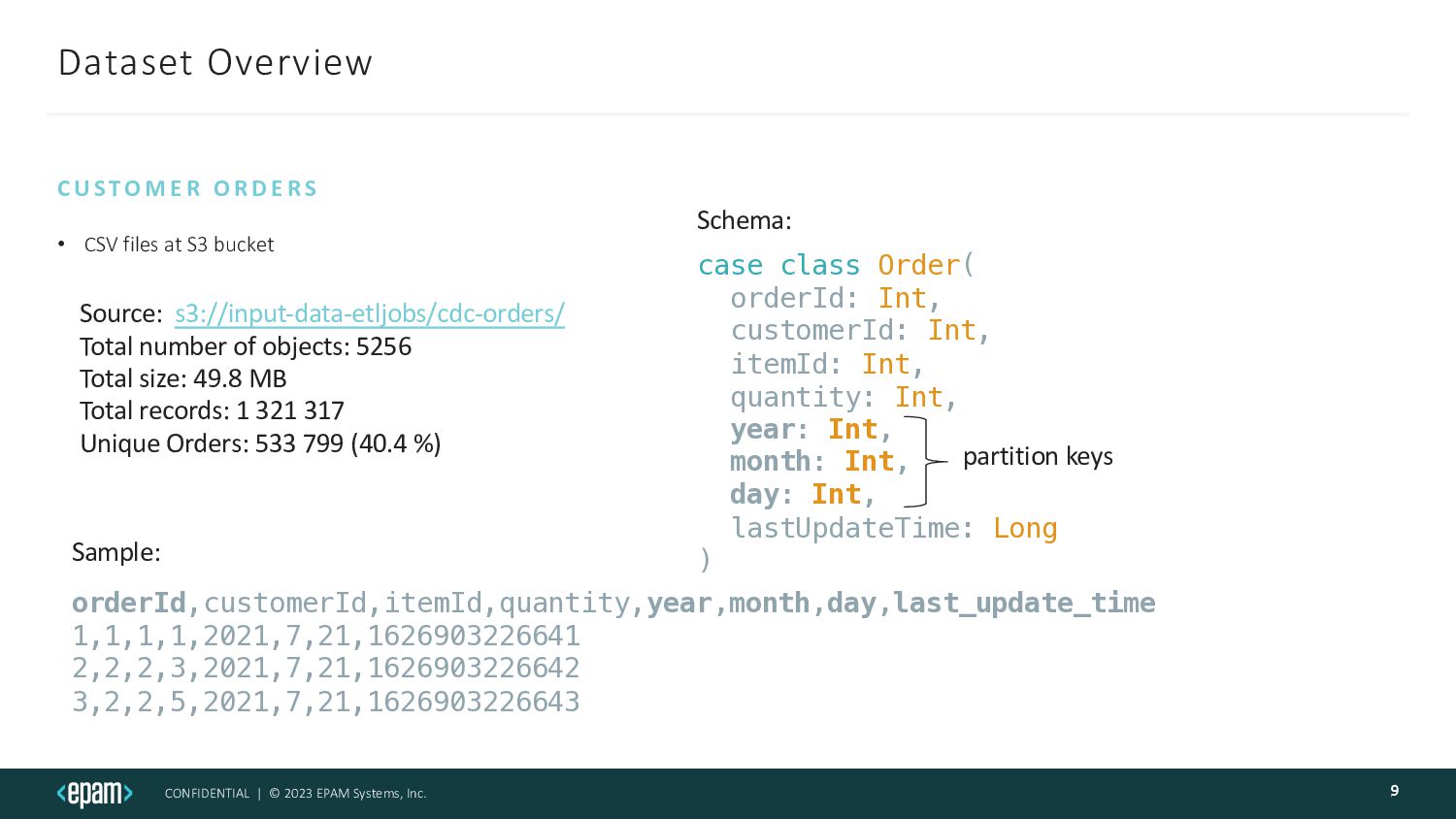
CSV files at S3 bucket C U S TO M E R O R D E R S 9 Source: s3://input-data-etljobs/cdc-orders/ Total number of objects: 5256 Total size: 49.8 MB Total records: 1 321 317 Unique Orders: 533 799 (40.4 %) case class Order( orderId: Int, customerId: Int, itemId: Int, quantity: Int, year: Int, month: Int, day: Int, lastUpdateTime: Long ) Schema: orderId,customerId,itemId,quantity,year,month,day,last_update_time 1,1,1,1,2021,7,21,1626903226641 2,2,2,3,2021,7,21,1626903226642 3,2,2,5,2021,7,21,1626903226643 Sample: partition keys
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}