Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NERのための転移学習
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
altescy
September 18, 2019
Research
1.3k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NERのための転移学習
altescy
September 18, 2019
Other Decks in Research
See All in Research
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
200
Ankylosing Spondylitis
ankh2054
0
180
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
230
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
280
「車1割削減、渋滞半減、公共交通2倍」を 熊本から岡山へ@RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
1
1.3k
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
500
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
590
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
140
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
180
Featured
See All Featured
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
Chasing Engaging Ingredients in Design
codingconduct
0
230
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
Building the Perfect Custom Keyboard
takai
2
810
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Believing is Seeing
oripsolob
1
160
How STYLIGHT went responsive
nonsquared
100
6.2k
Prompt Engineering for Job Search
mfonobong
0
370
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
Statistics for Hackers
jakevdp
799
230k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Transcript
NERのための転移学習 山口泰弘
自己紹介 山口 泰弘 / Yasuhiro Yamaguchi ID: @altescy 奈良先端科学技術大学院大学 修士1年
転移学習 • あるドメインのデータや学習済みモデルを使って他の ドメインのモデルを学習する手法 • 自然言語処理の分野における転移学習 ◦ Cross-Domain 例: ニュース →
SNS ◦ Cross-Lingual 例: 日本語 → 英語 • データの多いドメインから得られる知識を活用したい domain-specificなNERを行いたいと いう要求は現実問題として多そう
アプローチ 1. 単語翻訳 (cross-lingual) 2. Fine-Tuning 3. 潜在表現の共有
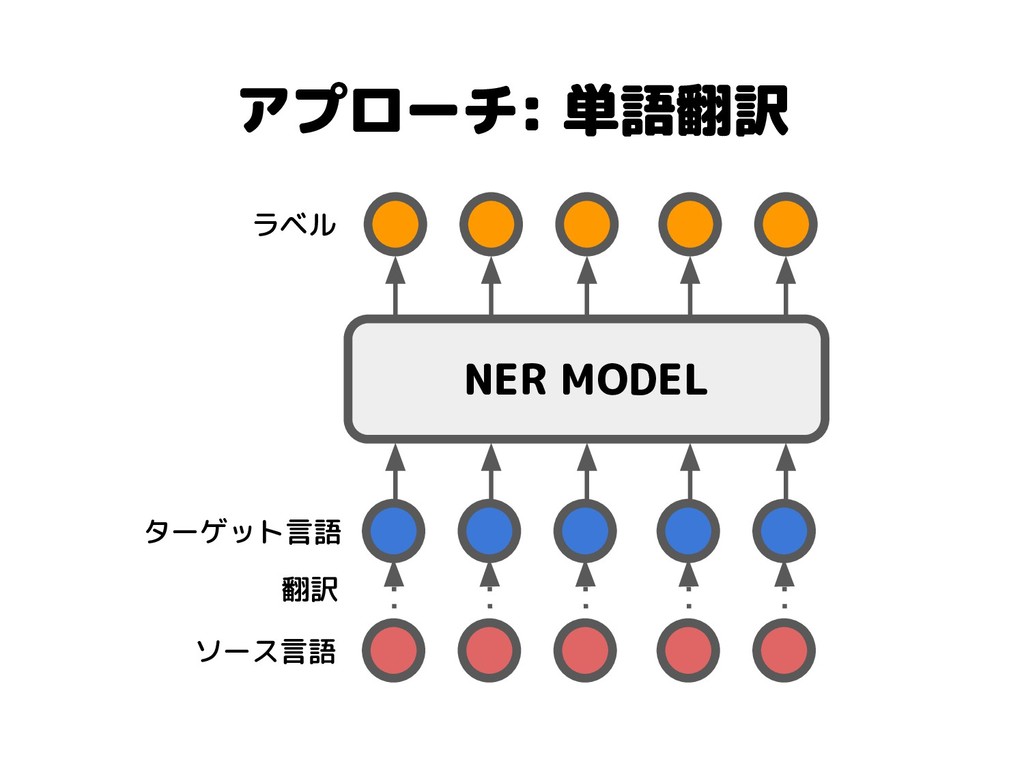
アプローチ: 単語翻訳 NER MODEL 翻訳 ソース言語 ターゲット言語 ラベル
アプローチ: 単語翻訳 • Cheap Translation for Cross-Lingual Named Entity Recognition
[Mayhew+, 2017] ◦ 単語翻訳によるCross-Lingual NERの提案 • Neural Cross-Lingual NER with Minimal Resources [Xie+, 2018] ◦ 単語埋め込みのアライメントによる単語翻訳 ◦ self-attentionによる語順の違いの吸収
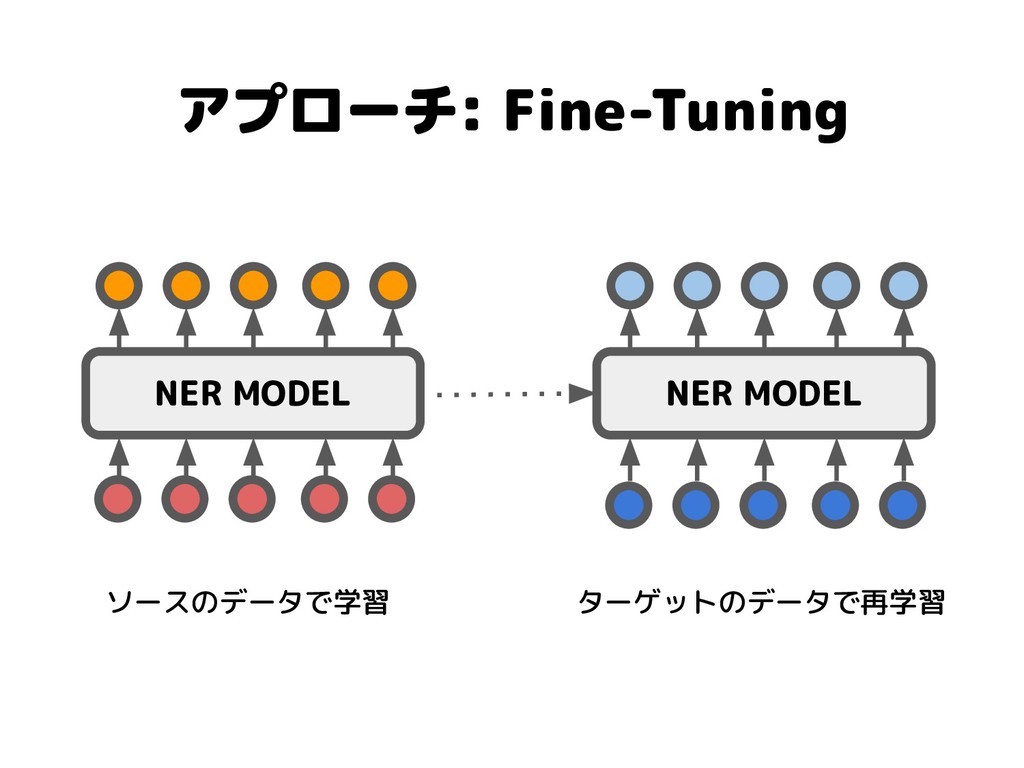
アプローチ: Fine-Tuning NER MODEL NER MODEL ソースのデータで学習 ターゲットのデータで再学習
アプローチ: Fine-Tuning • How Transferable are Neural Networks in NLP
Applications? [Mou+, 2016] ◦ Fine-TuningによるNERタスクの転移学習の可能性を 考察 • Neural Adaptation Layers for Cross-domain Named Entity Recognition [Lin+, 2018] ◦ Fine-Tuningと,固定の学習済みエンコーダの前後に レイヤーを追加する手法の比較
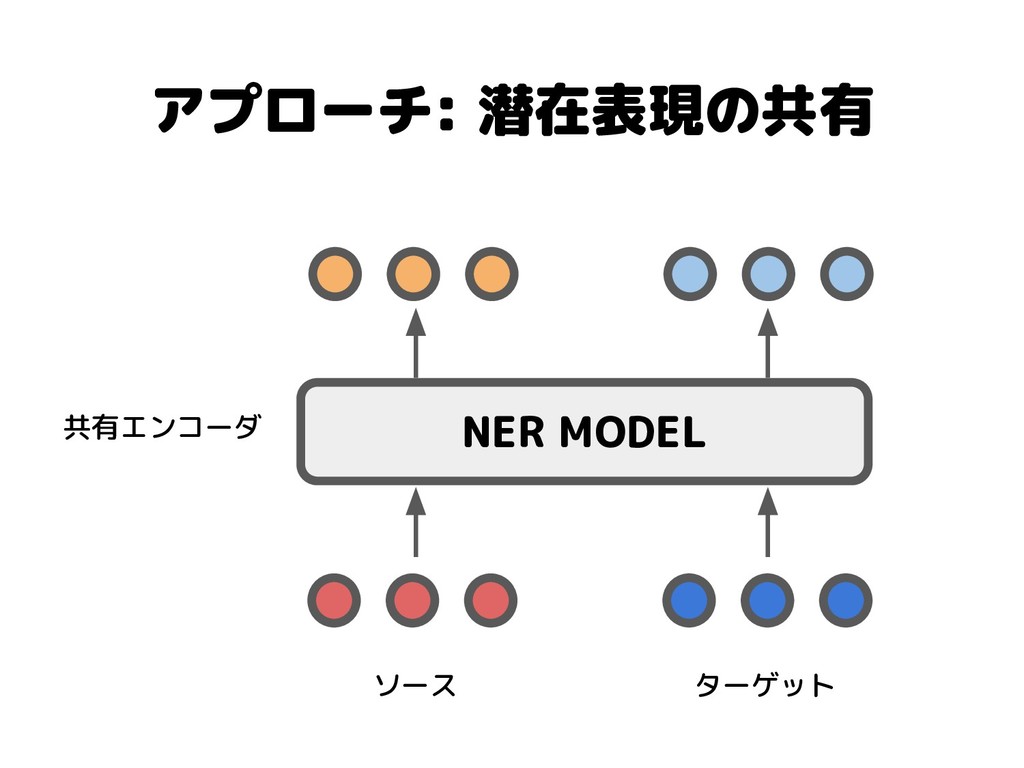
アプローチ: 潜在表現の共有 NER MODEL 共有エンコーダ ソース ターゲット
アプローチ: 潜在表現の共有 • Adversarial Transfer Learning for Chinese Named Entity
Recognition with Self-Attention Mechanism [Cao+, 2018] ◦ 中国語における,単語分割→NERの転移学習 • Dual Adversarial Neural Transfer for Low-Resource Named Entity Recognition [Zhou1+, 2019] ◦ 高リソース→低リソースの転移学習 ◦ 今回はこれにフォーカスします
Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] 概要
• 高リソース→低リソースの転移学習 • 潜在表現を共有するモデル 提案手法 • リソース同士のデータの不均衡を考慮する (データ規模・予測の難しさ) • リソース特有の特徴を考慮する • 敵対訓練による正則化を行う
Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] DATNet-P
ソース / 共有 / ターゲット DATNet-F すべて共有
Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] Discriminator
• 共有の潜在表現がどちらのリソースのものか判別 • エンコーダは判別器が誤るように学習 • 不均衡を考慮した誤差関数 (いわゆる Focal-Loss) データ規模の不均衡を調整 予測の難しい例を学習 Adversarial Training • 単語埋め込みに敵対的摂動を与えながら学習
Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] POSなど追加の特徴量を使わず既存手法と同程度以上
cross-lingual cross-domain
Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] Cross-Lingual
(英→西) • ターゲットのデータ数が少ないときはDATNet-F, 多いと きはDATNet-Pがよい Cross-Domain (ニュース→SNS) • データ規模によらずDATNet-Fがよい
サーベイの所感 • ソースとターゲットで共有する情報と,ドメイン・ 言語特有の情報の処理を分けて学習する • self-attentionを利用する ◦ 大域的な依存関係を捉える ◦ 言語ごとの語順の違いを吸収する
• データの不均衡を考慮する ◦ ソース・ターゲットのデータ規模 ◦ 予測が簡単な例・難しい例
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] 概要](https://files.speakerdeck.com/presentations/09f41afa8fb346a891edf76367c8e75b/slide_10.jpg){kind=link}
![Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] DATNet-P](https://files.speakerdeck.com/presentations/09f41afa8fb346a891edf76367c8e75b/slide_11.jpg){kind=link}
![Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] Discriminator](https://files.speakerdeck.com/presentations/09f41afa8fb346a891edf76367c8e75b/slide_12.jpg){kind=link}
![Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] POSなど追加の特徴量を使わず既存手法と同程度以上](https://files.speakerdeck.com/presentations/09f41afa8fb346a891edf76367c8e75b/slide_13.jpg){kind=link}
![Dual Adversarial Neural Transfer for Low-Resource NER [Zhou1+, 2019] Cross-Lingual](https://files.speakerdeck.com/presentations/09f41afa8fb346a891edf76367c8e75b/slide_14.jpg){kind=link}
{kind=link}