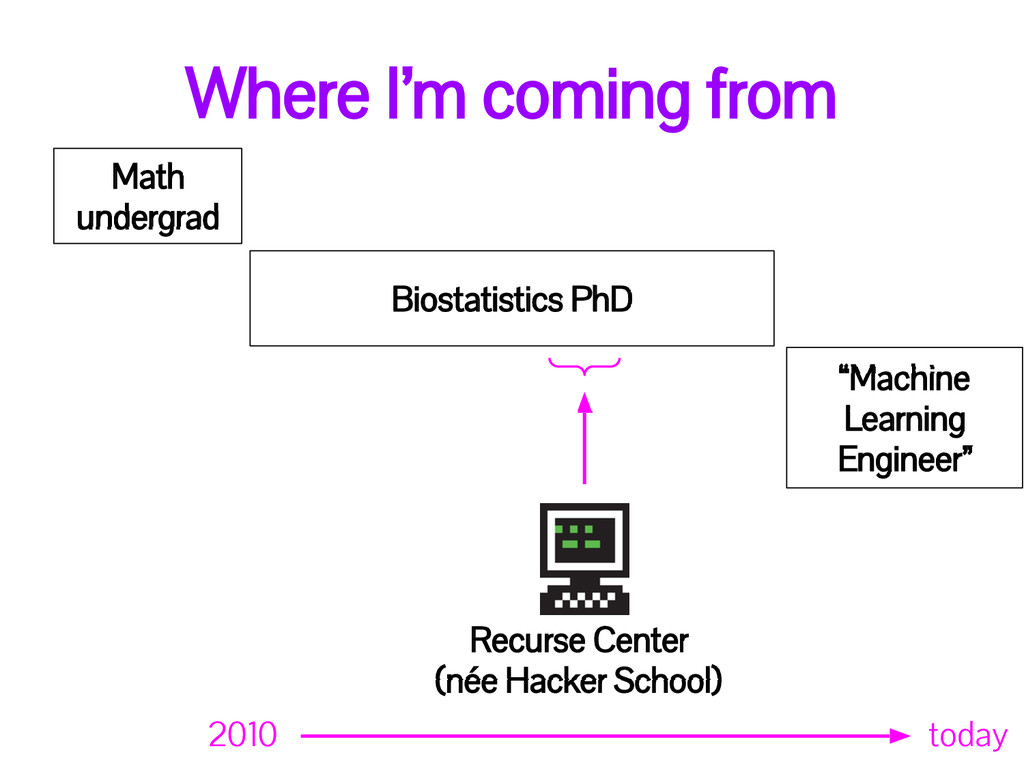
grad program called [bio]statistics • Know things about martingales and the delta method • Can explain what a p-value is and interpret linear regression coefficients points against: • Haven’t proved a theorem since 2011 • Spend more time writing bash scripts than inventing estimators • No publications in statistics journals
program in more than one language • Actively use git & GitHub • Have written R packages and reproducible reports • Once made a web app and also a D3.js graph points against: • Not working in industry • Have never written a SQL query more complicated than select * from table • Understanding of Hadoop, Spark, and AWS is vague at best • Have never written production code
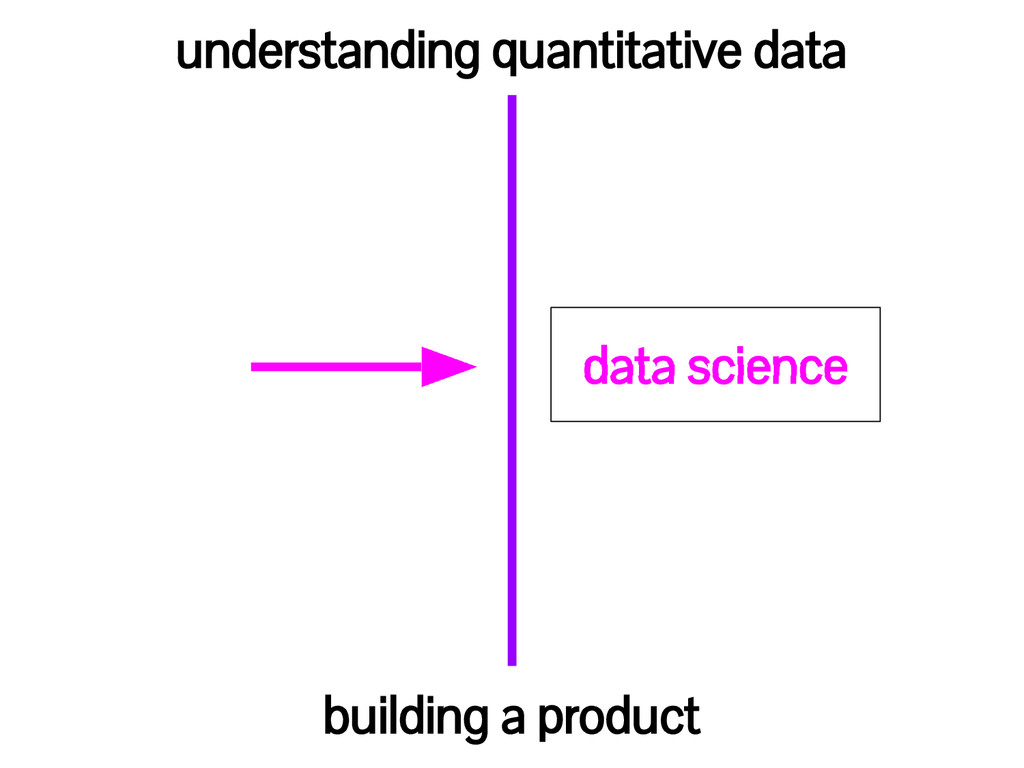
say! Camp #1: Data science is just a rebranding of applied statistics. Camp #2: Statistics and data science are overlapping. Neither is a subset of the other. Camp #3: Statistics is irrelevant to data science.
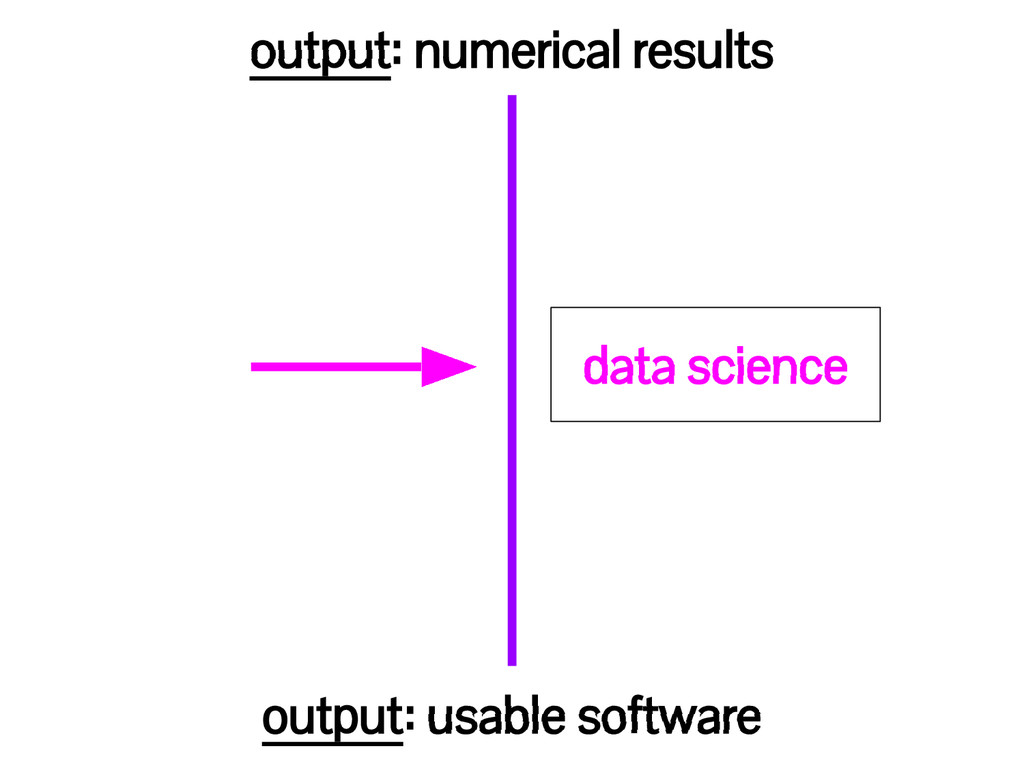
efficiency • version control • code quality (cleanliness, modularity) • documentation / usability • unit testing • systematic debugging • giving and receiving code review • and other principles of software engineering
Ruby, Scala, Coffeescript, and Python • fought with maven • backfilled some busted tables in our databases • investigated the mystery of why some of our cluster boxes are overworked • learned how to be on call (so I can fix some of Stripe if it breaks at 3am) • helped teach a SQL class • and did some statistics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}