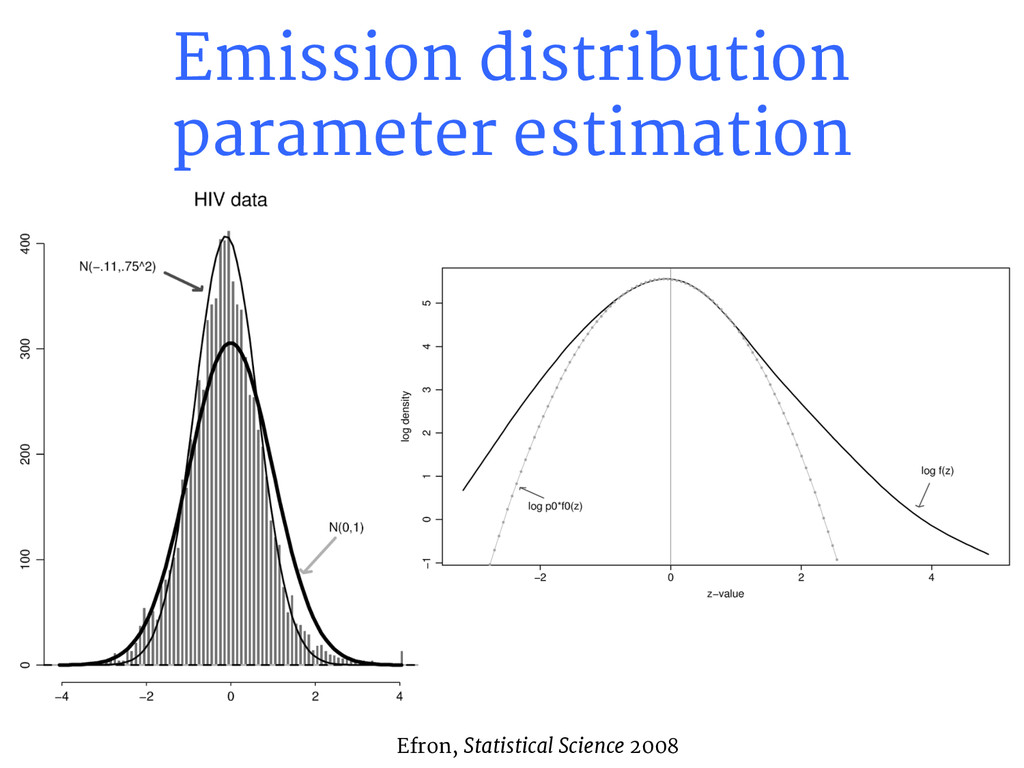
(2014). “Differential expression analysis of RNA-seq data at single- base resolution.” Biostatistics 15(3): 413-426 Frazee AC, Pertea G, Jaffe AE, Salzberg SL, Leek JT (2015). “Ballgown bridges the gap between transcriptome assembly and expression analysis.” Nature Biotechnology, to appear. Frazee AC, Jaffe AE, Langmead B, Leek JT (2014): “Polyester: simulating RNA-seq datasets with differential transcript expression.” Under revision at Bioinformatics. AC’t Hoen P et al (2013): “Reproducibility of high-throughput mRNA and small RNA sequencing across laboratories.” Nature Biotechnology 31(11): 1015-22. Anders S and Huber W (2010). “Differential expression analysis for sequence count data.” Genome Biology 11(10): R106. Bernard E, Jacob L, Mairal J, Vert J (2014). “Efficient RNA isoform identification and quantification from RNA-seq data with network flows.” Bioinformatics 30(17): 2447-2455. Efron B (2008): “Microarrays, empirical Bayes, and the two-groups model.” Statistical Science 23(1): 1-22. Jaffe AE, Murakami P, Lee H, Leek JT, Fallin MD, Feinberg AP, Irizarry RA (2012): “Bump hunting to identify differentially methylated regions in epigenetic epidemiology studies.” International Journal of Epidemiology 41(1): 200-209. Law CW, Chen Y, Shi W, Smyth GK (2014): “Voom: precision weights unlock linear model analysis tools for RNA-seq read counts.” Genome Biology 15(2): R29. Lappalainen T et al (2013). “Transcriptome and genome sequencing uncovers functional variation in humans.” Nature 501 (7468): 506-11. Leng N, Dawson JA, Thomson JA, Ruotti V, Rissman AI, Smits BMG, Haag JD, Gould MN, Steward RM, Kendziorski C (2013). “EBSeq: an empirical Bayes hierarchical model for inference in RNA-seq experiments.” Bioinformatics 29(8): 1035-1043. Robinson MD, McCarthy DJ, Smyth GK (2010). “edgeR: a Bioconductor package for differential expression analysis of digital gene expression data.” Bioinformatics 26(1): 139-40. Smyth GK (2004). Linear models and empirical Bayes methods for assessing differential expression in microarray experiments. Statistical Applications in Genetics and Molecular Biology 3(1):3. Trapnell C, Hendrickson DG, Sauvageau M, Goff L, Rinn JL, Pachter L (2013). “Differential analysis of gene regulation at transcript resolution with RNA-seq.” Nature Biotechnology 31(1): 46-53. References
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
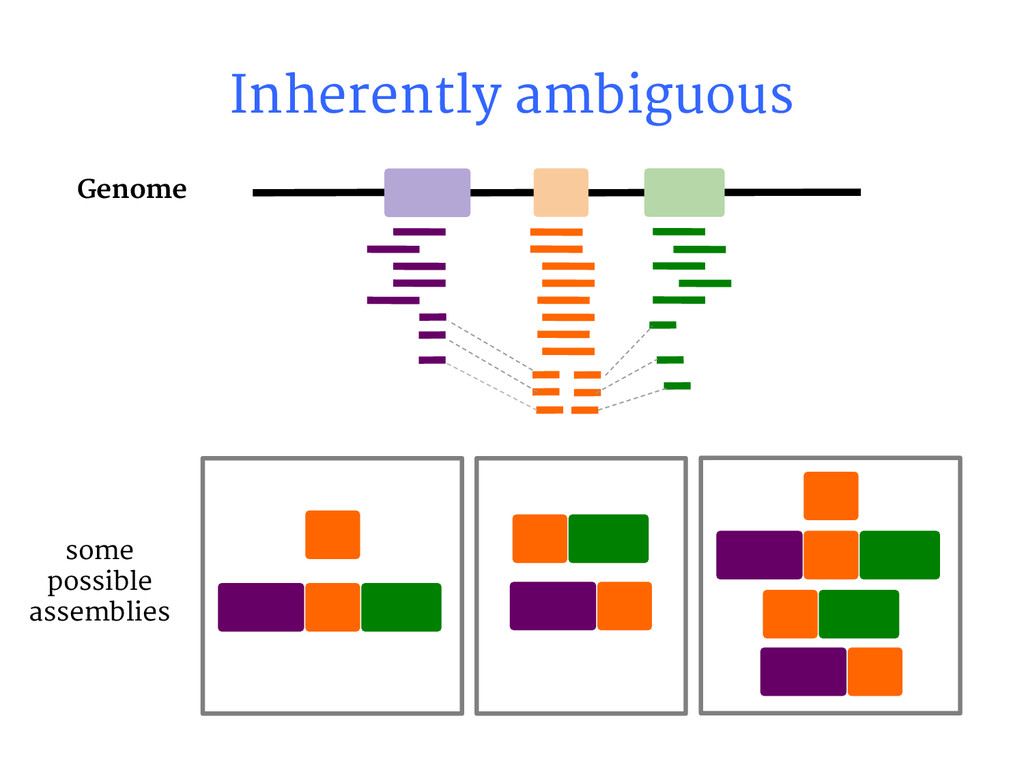{kind=link}
{kind=link}
{kind=link}
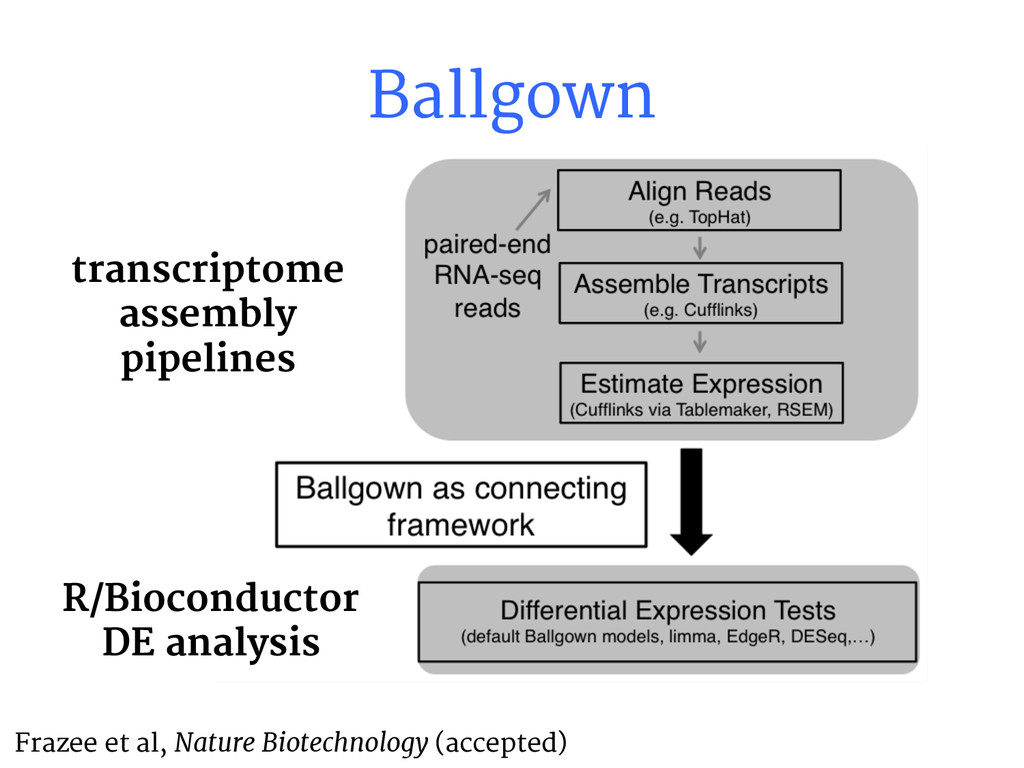{kind=link}
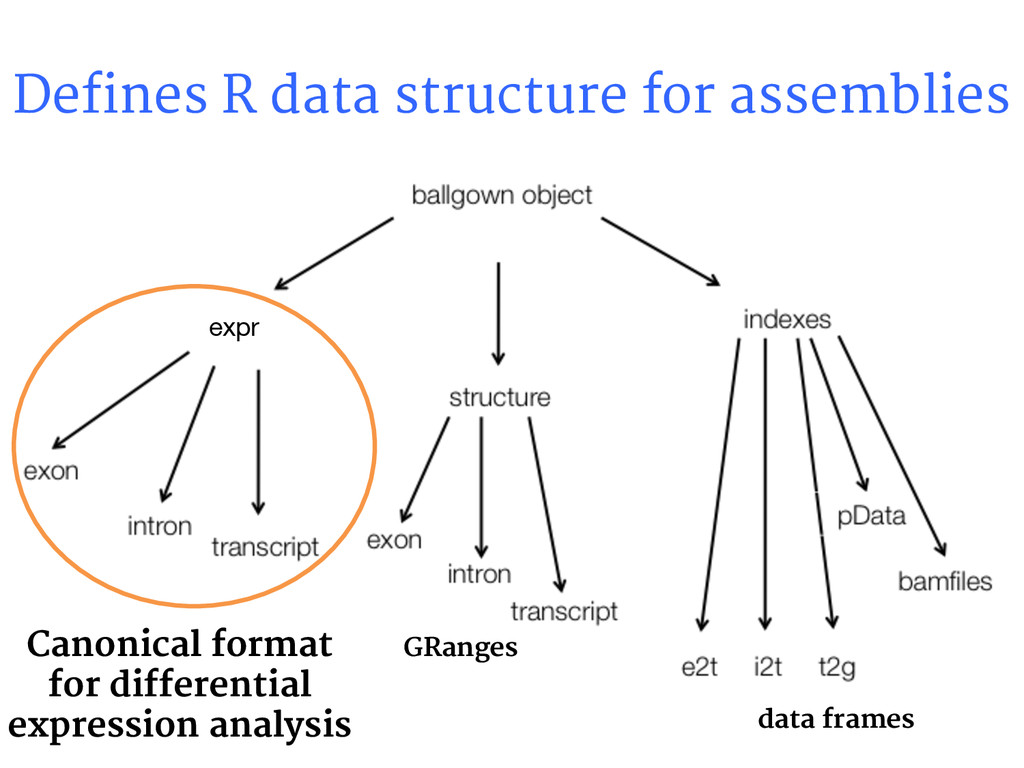{kind=link}
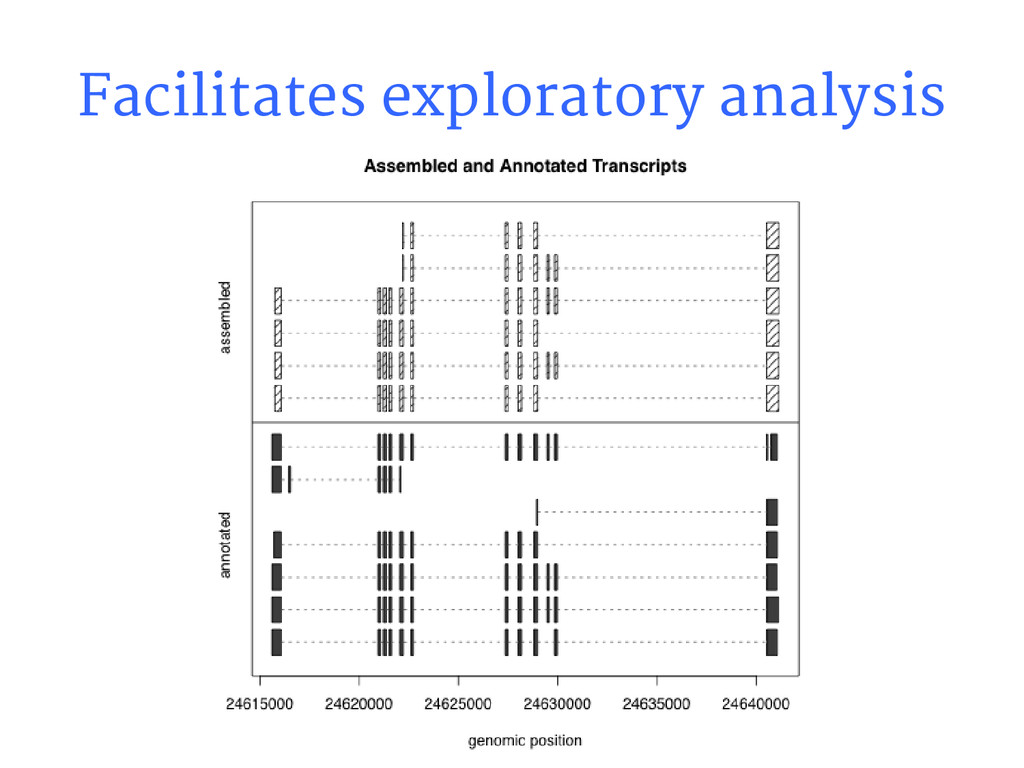{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
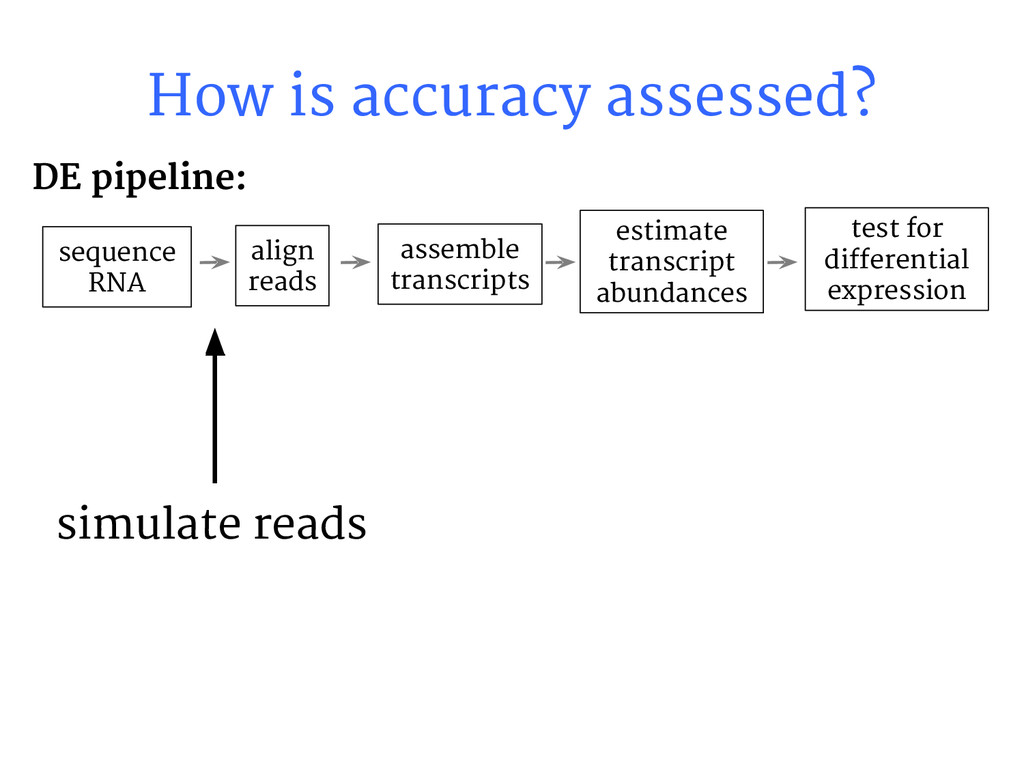{kind=link}
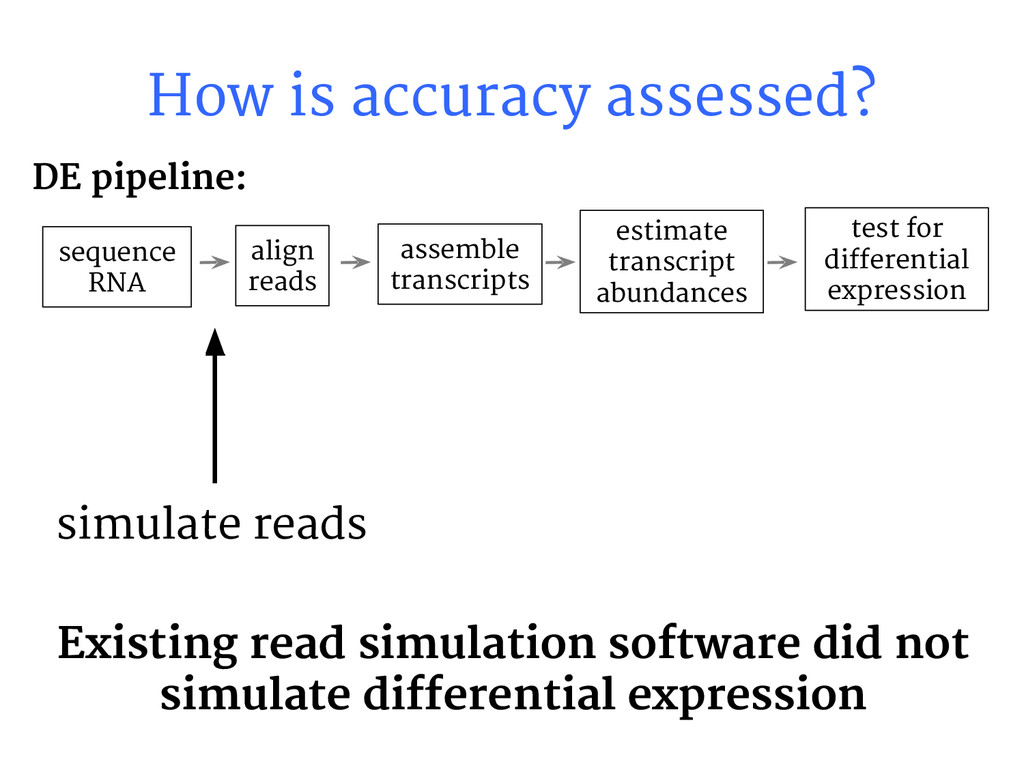{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
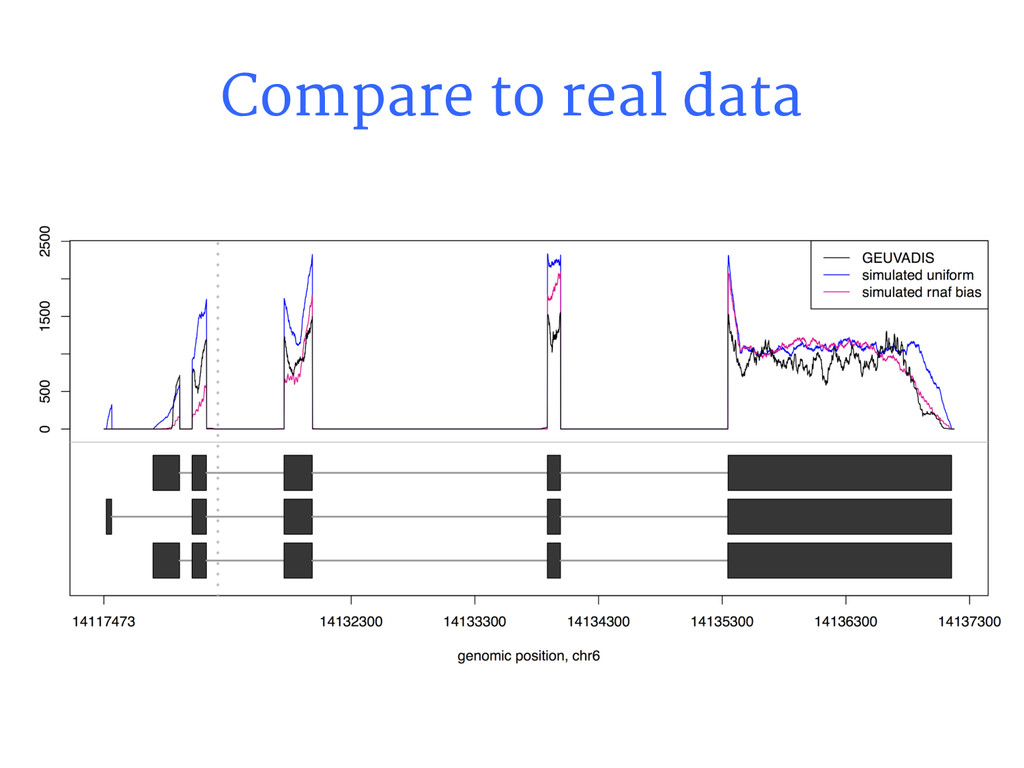{kind=link}
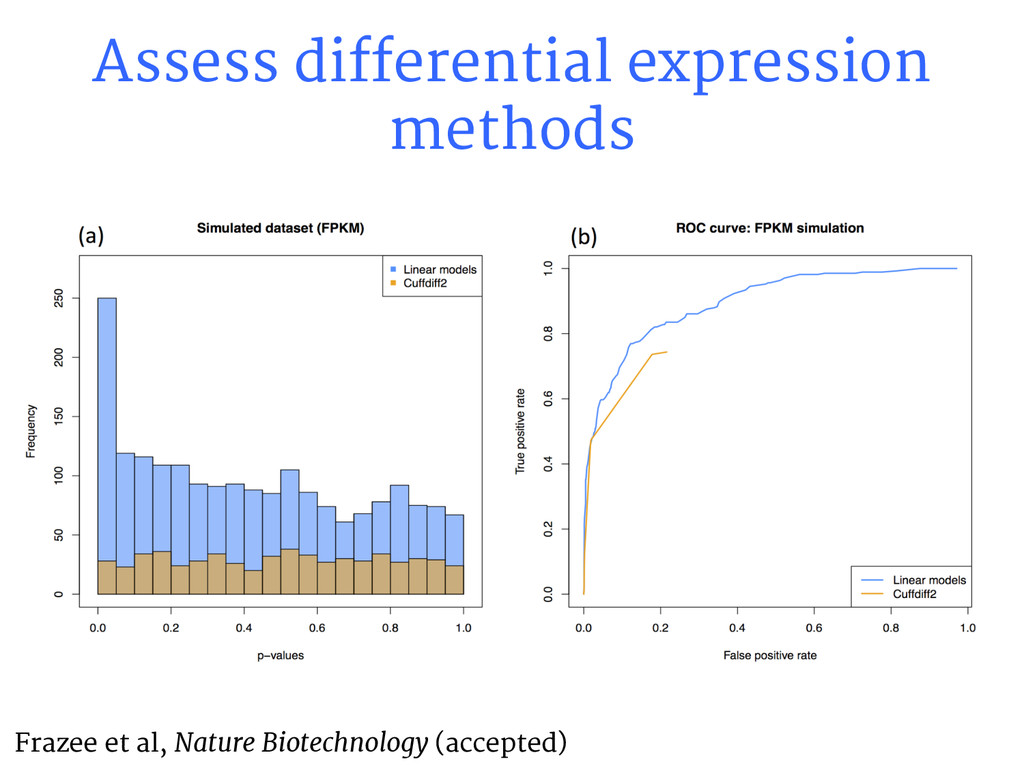{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}