Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
運用を見据えたAIエージェント設計実践
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
amacbee
June 07, 2026
Technology
5.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
運用を見据えたAIエージェント設計実践
amacbee
June 07, 2026
More Decks by amacbee
See All by amacbee
技育CAMPアカデミア (2025-12-10)
amacbee
0
87
AI Agentsで沖縄を盛り上げたい
amacbee
0
89
[デモ説明資料] AIエージェントで実現するクラウドネイティブの世界
amacbee
1
87
ちゅらデータ会社紹介資料 / ChuraDATA Introduction
amacbee
2
57k
データサイエンスの業界トレンドと今後の動向
amacbee
1
1.2k
pip install pyladies
amacbee
0
470
PyCon Kyushu 2018 - Keynote
amacbee
0
2.7k
Pythonで競技プログラミングハンズオン
amacbee
1
1.4k
日本人投手の2016年振り返り
amacbee
1
1.4k
Other Decks in Technology
See All in Technology
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
0
710
キャリアLT会#3
beli68
0
160
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
490
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
880
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
0
550
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
250
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
270
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
230
Making sense of Google’s agentic dev tools
glaforge
1
290
発表と総括 / Presentations and Summary
ks91
PRO
0
150
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
470
Featured
See All Featured
KATA
mclloyd
PRO
35
15k
Navigating Weather and Climate Data
rabernat
0
390
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Transcript
運用を見据えた AIエージェント設計実践 AI Engineering Summit Tokyo 2026 (AIE2026) 2026年6月8日 10:30-11:00
真嘉比 愛 / ちゅらデータ株式会社
真嘉比 愛 (Ai Makabi) 大学院にて自然言語処理を専攻。卒業後、広告事業の データ分析などを経験し、2016年に DATUM STUDIO に入社。翌2017年にちゅらデータを創業。 会社経営のかたわらデータサイエンティストとしても
従事しており、これまで自然言語処理、画像解析、異 常検知など100社を越えるAI構築のコンサルティング・ 開発に従事。 ちゅらデータ株式会社 代表取締役社長 DATUM STUDIO株式会社 取締役副社長 Women In Tech 30 (2024) @Forbes JAPAN NLP2023 副実行委員長 人工知能学会 SIAI 実行委員 (2023) 2
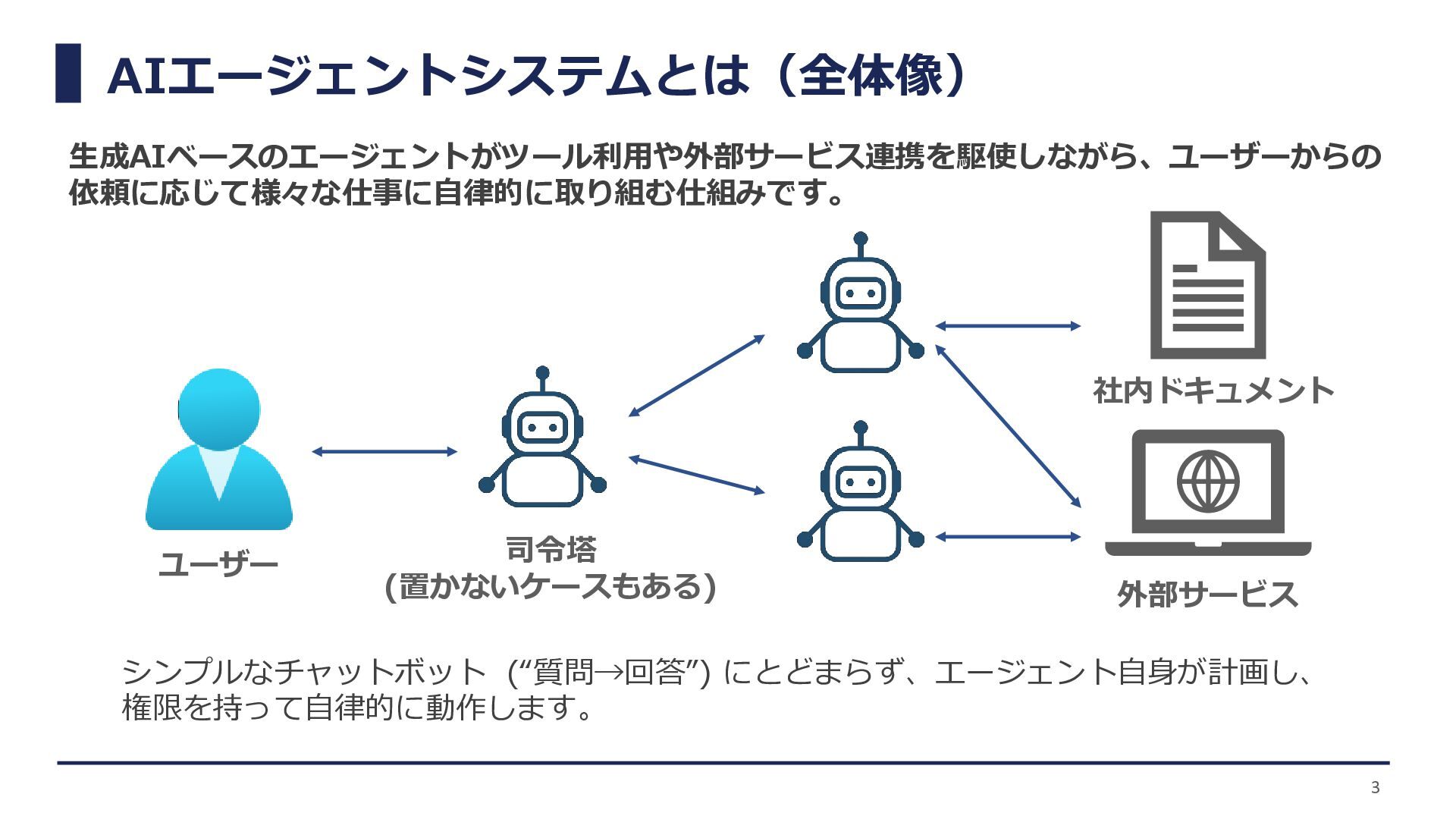
AIエージェントシステムとは(全体像) ユーザー 司令塔 (置かないケースもある) シンプルなチャットボット (“質問→回答”) にとどまらず、エージェント自身が計画し、 権限を持って自律的に動作します。 生成AIベースのエージェントがツール利用や外部サービス連携を駆使しながら、ユーザーからの 依頼に応じて様々な仕事に自律的に取り組む仕組みです。
外部サービス 社内ドキュメント 3
『作れる』と『使われ続ける』は別問題 PoCではうまくいっていたけれども、本番で重大な事故を起こしてしまった事例は多数報告され ています。平均して46%のAI PoCが本番化に至らず中止されているという報告*1もあります。 コード凍結中にも関わらず本番DBを削除。1,206名の経営幹部記録 と1,196社のデータが影響を受けた AIチャットボットが存在しない遺族割引を誤案内した結果、裁判所が 航空会社に賠償を命令 カスタマーサービスをAIに置き換えた結果、約67%の自動化を実現 したものの、顧客体験の品質が低下して人間のサポートを再投入
Replit Air Canada Klarna 4 *1: https://www.constructiondive.com/news/AI-project-fail-data-SPGlobal/742934/
本日のテーマ:『作れる』の次は『使われ続ける』 それっぽく動く”エージェントを作るのは容易ですが 使われ続けるためには、安全性やブランドを守りながら 高品質に運用するための設計が重要となります。 5
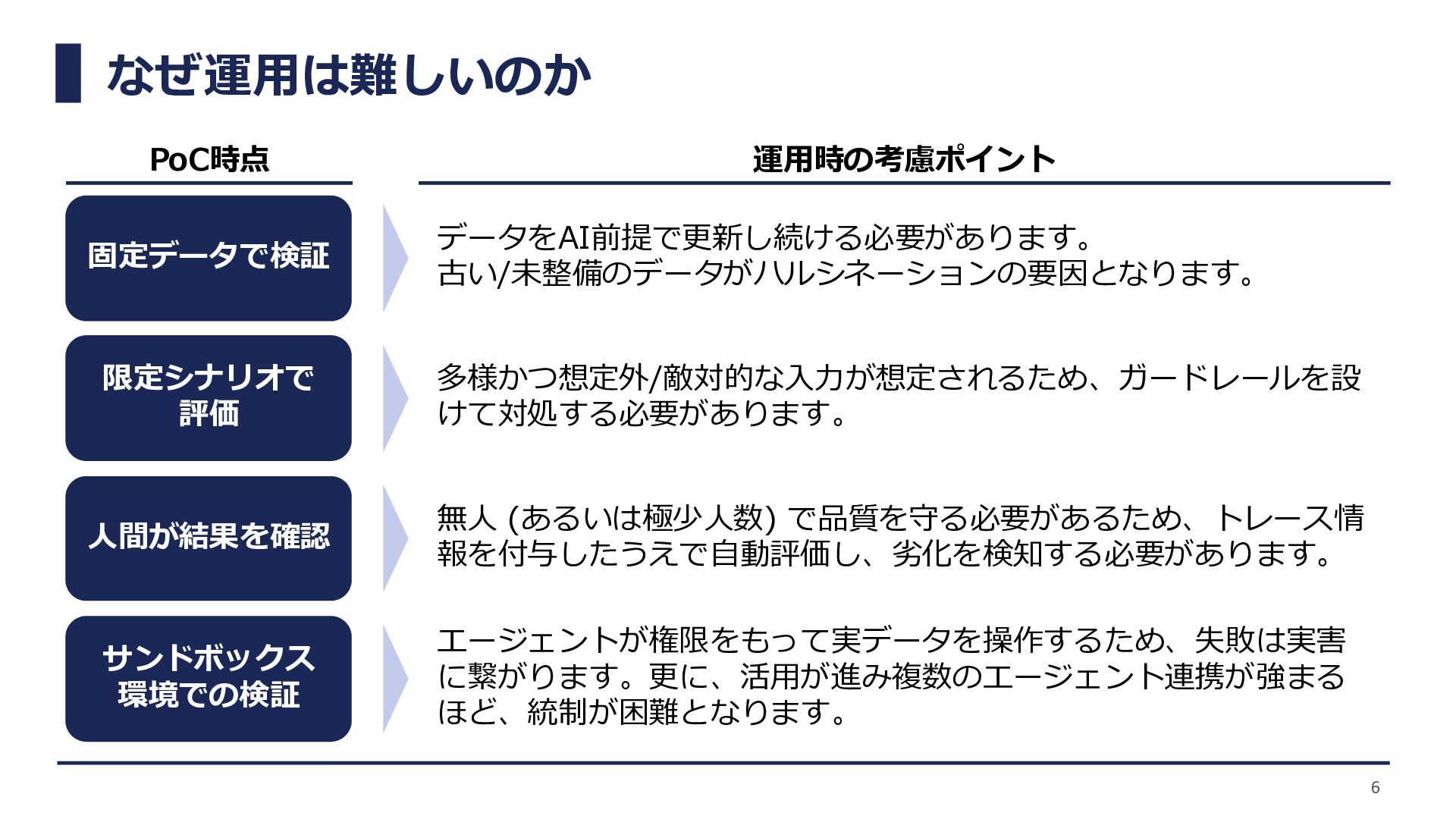
なぜ運用は難しいのか PoC時点 運用時の考慮ポイント 固定データで検証 限定シナリオで 評価 人間が結果を確認 サンドボックス 環境での検証 データをAI前提で更新し続ける必要があります。
古い/未整備のデータがハルシネーションの要因となります。 多様かつ想定外/敵対的な入力が想定されるため、ガードレールを設 けて対処する必要があります。 無人 (あるいは極少人数) で品質を守る必要があるため、トレース情 報を付与したうえで自動評価し、劣化を検知する必要があります。 エージェントが権限をもって実データを操作するため、失敗は実害 に繋がります。更に、活用が進み複数のエージェント連携が強まる ほど、統制が困難となります。 6
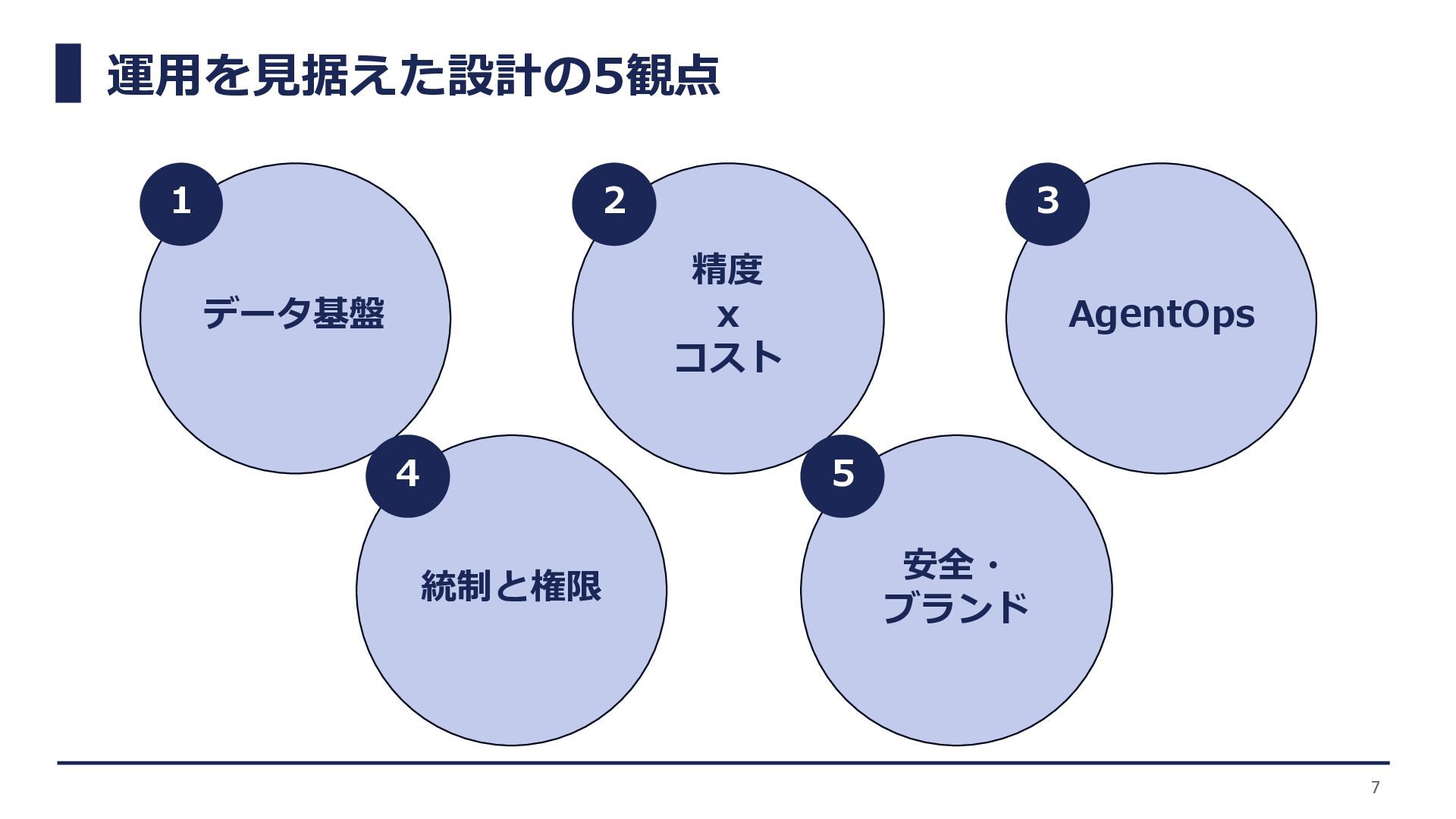
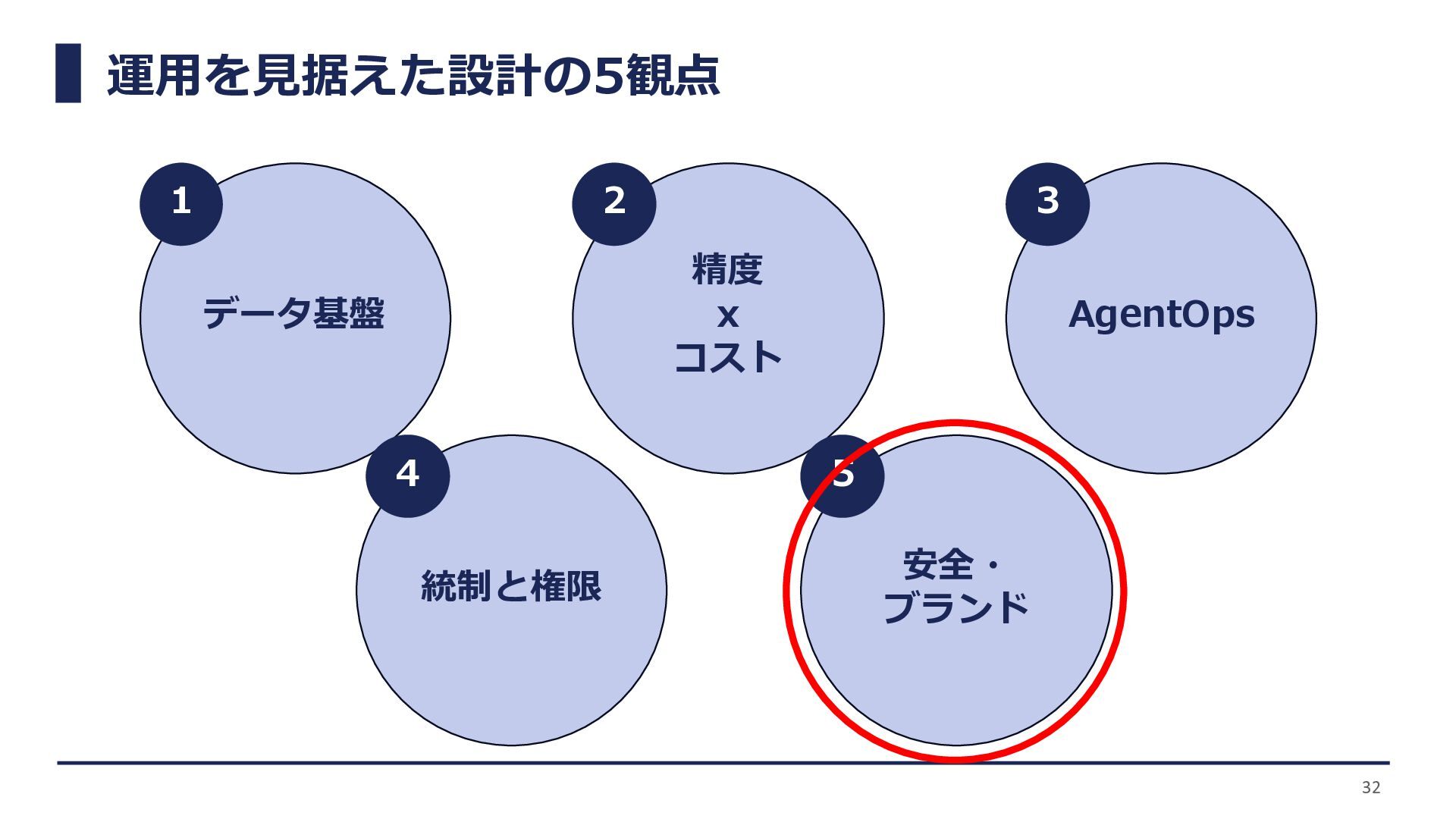
運用を見据えた設計の5観点 データ基盤 精度 x コスト AgentOps 統制と権限 安全・ ブランド 7
1 2 3 4 5
[補足] “静かに使われなくなる” ことを防ぐ 8 仮に運用に載せることができても、適切なKGI/KPIやユーザーシナリオが設計されていなかっ たり、運用体制に不備があるケースでは、エージェントは “静かに使われなくなります”。 ユーザーシナリオ/ 業務接続の未設計 現場のフローに載らず
結局使われない (サイレント抵抗) KGI/KPI未設定 価値を測れないため、 費用対効果も 継続/廃止判断も できなくなる 運用責任者・ 改善体制の空白 運用改善を実施 する人がいない ため、放置されて しまい劣化
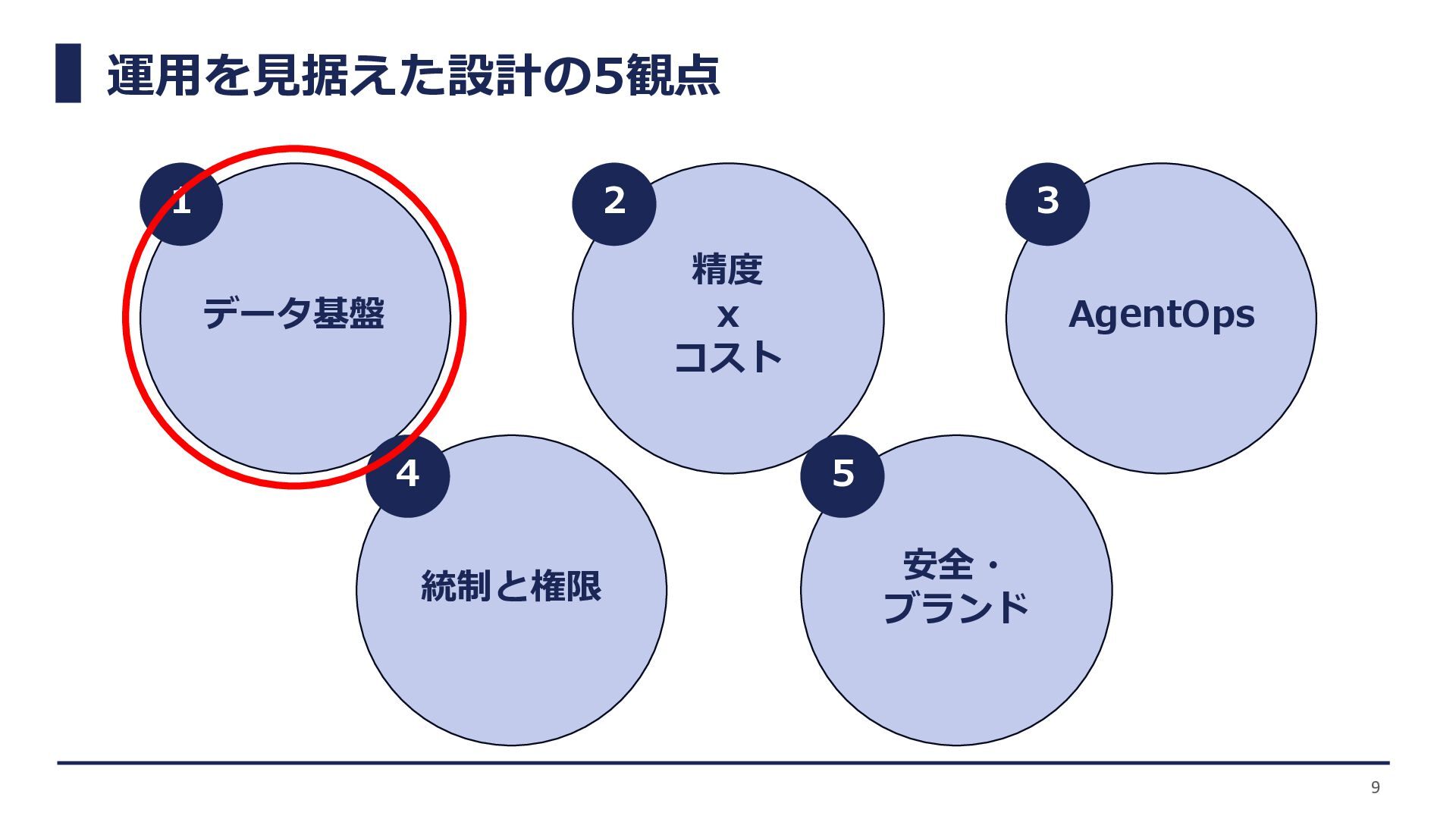
運用を見据えた設計の5観点 データ基盤 精度 x コスト AgentOps 統制と権限 安全・ ブランド 9
1 2 3 4 5
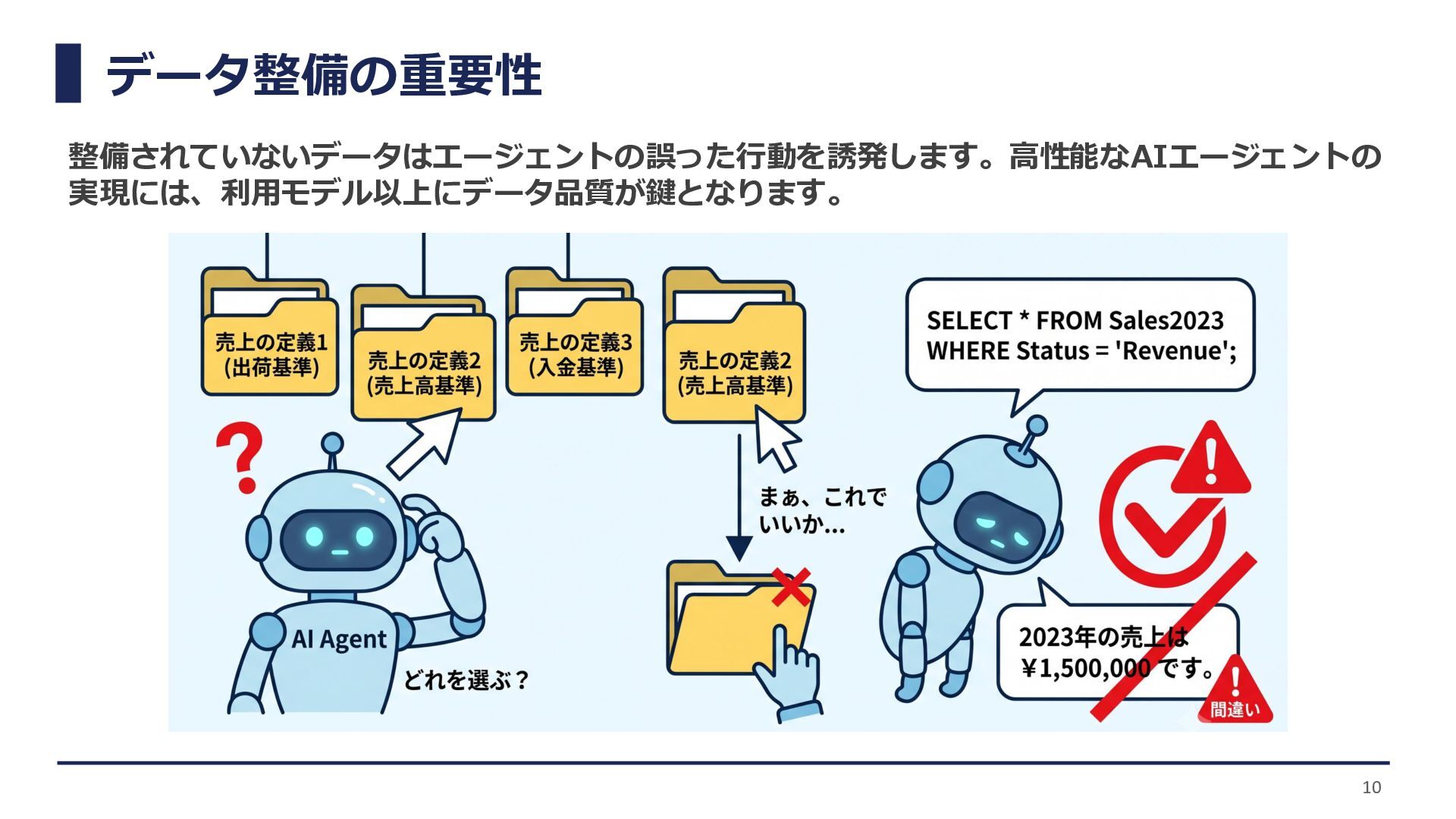
データ整備の重要性 整備されていないデータはエージェントの誤った行動を誘発します。高性能なAIエージェントの 実現には、利用モデル以上にデータ品質が鍵となります。 10
AI Readyなデータ基盤の5層 層 担うこと 具体例 ①コンテキスト データに「意味・出自・鮮度・前提」を付 与 ※メタデータ 「このカラムは税抜か税込か」「こ
の売上は会計基準か管理会計か」 ②データモデル データの構造・粒度・関係性を定義 スタースキーマで fact_ / dim_ が明 確に分離されている。「売上」の粒 度が一貫している ③オントロジー ドメインの概念とその関係を、テーブルを 超えた抽象レベルで定義 (テーブル構造か ら独立した「意味のグラフ」として表現) “解約予兆” = “直近3ヶ月の利用頻 度が前年同期比50%以下” といった 定義が複数テーブル間で共有される ④ガードレール AIが「やってはいけないこと」を構造的に 防御。アクセス制御、PIIマスキング、行レ ベル/列レベルセキュリティ等 エージェントが個人を特定可能な形 で集計結果を返さない (k匿名性) ⑤評価ハーネス AIの出力が「正しいか・劣化していない か」を継続的に測定・検証 本番でのトレース取得と、異常な回 答パターンのアラート 11
[補足] オントロジーに載る指標: Semantic Layer 12 オントロジーが「概念と関係 (e.g. 顧客・売上 という概念がどう繋がるか)」を定義し、 セマンティックレイヤーが「その概念をどう計
算するか (売上=SUM(order_amount)」を定 義します。 metrics: monthly_revenue: label: 月次売上 description: 確定した受注金額の月 次合計 (テスト・キャンセルを除く) type: sum expr: order_amount grain: month filters: [exclude_test, exclude_canceled] dimensions: order_date: type: time… 指標の「意味 (定義)」と「実装 (クエリ)」を1つの定義単位で一元管理します。別々に持つと、 運用の中で定義が必ずズレていきます。(metric drift)
データ基盤の運用保守 13 AI Readyなデータ基盤は “作って終わり” のものではなく、運用を回す必要があります。定義 はコードとして管理したうえで、継続監視することが重要です。 データオブザーバビリティで “データの劣化” を継続的に検知します。
リネージ (=データの来歴、依存関係) と組み合わせ、原因の上流と 波及する下流を特定することも重要です。 データオブ ザーバビリ ティ definitions- as-code メトリクス定義をコードとして管理します。(PRレビュー、CIテスト、 バージョニング、廃止ルールを整備) メトリクスオーナーを置いて、保守を特定のユーザーに集中させない (=属人化を防ぐ) ことが重要です。
運用を見据えた設計の5観点 データ基盤 精度 x コスト AgentOps 統制と権限 安全・ ブランド 14
1 2 3 4 5
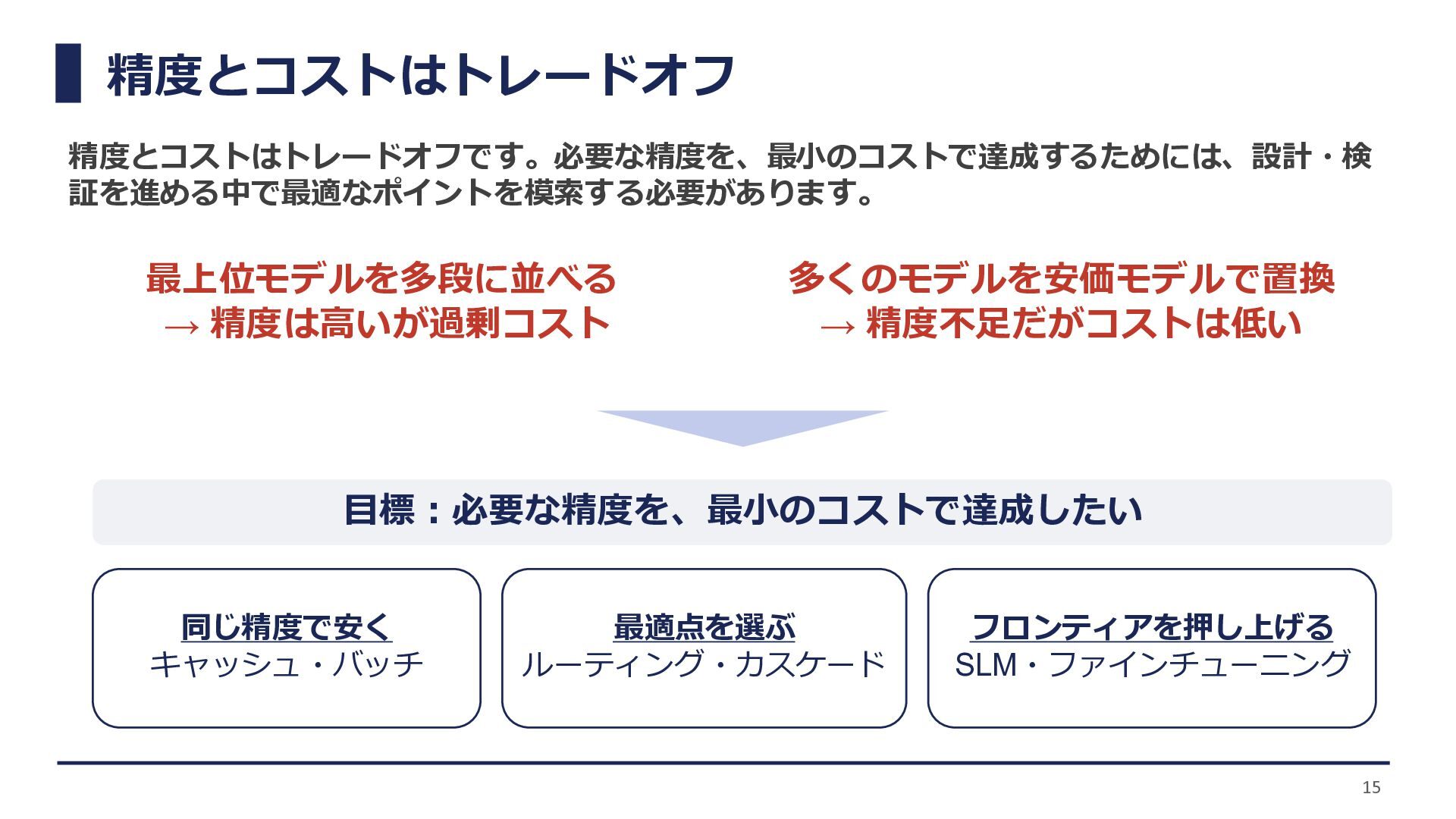
精度とコストはトレードオフ 15 精度とコストはトレードオフです。必要な精度を、最小のコストで達成するためには、設計・検 証を進める中で最適なポイントを模索する必要があります。 最上位モデルを多段に並べる → 精度は高いが過剰コスト 多くのモデルを安価モデルで置換 → 精度不足だがコストは低い
目標:必要な精度を、最小のコストで達成したい 同じ精度で安く キャッシュ・バッチ 最適点を選ぶ ルーティング・カスケード フロンティアを押し上げる SLM・ファインチューニング
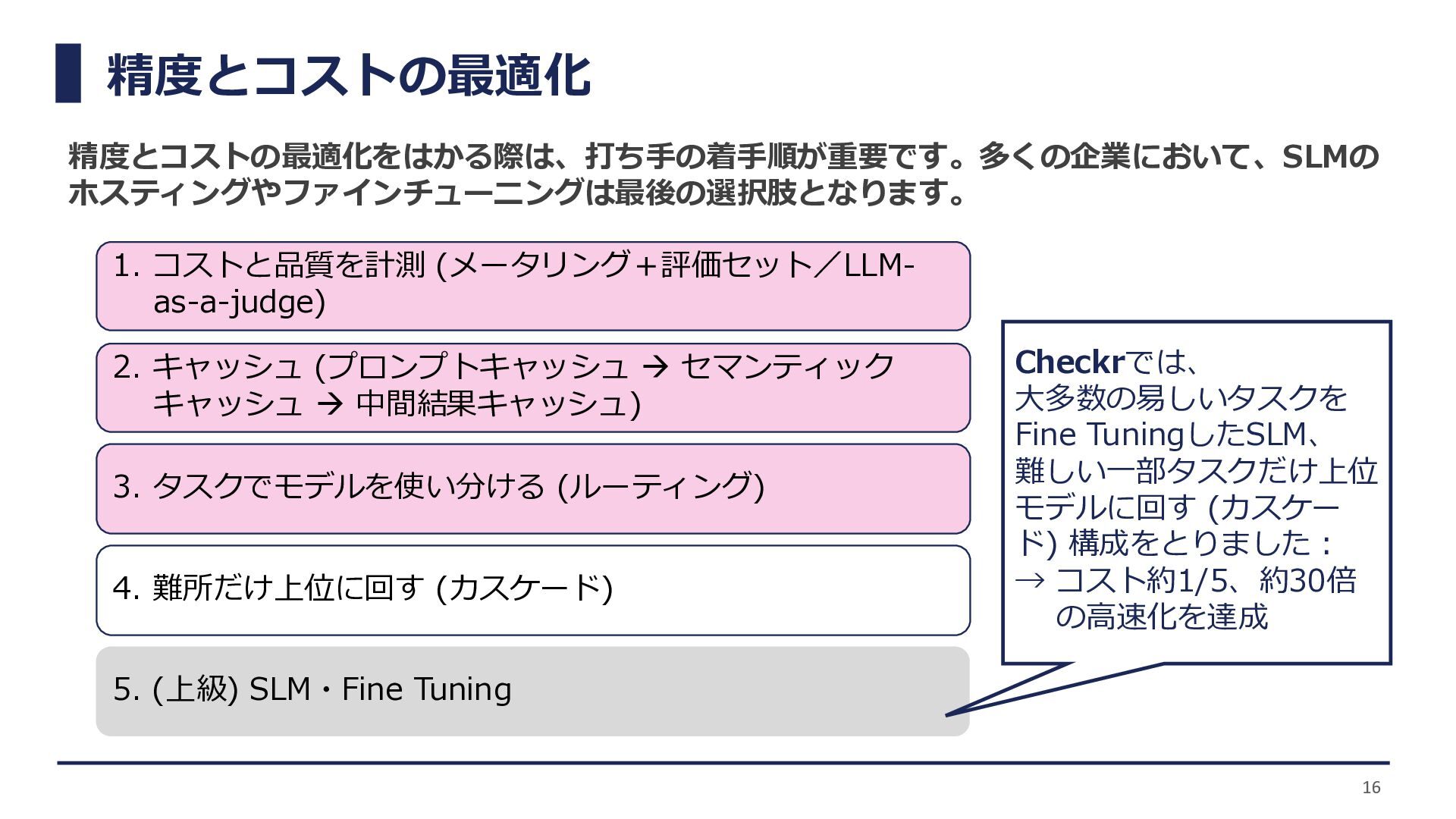
精度とコストの最適化 精度とコストの最適化をはかる際は、打ち手の着手順が重要です。多くの企業において、SLMの ホスティングやファインチューニングは最後の選択肢となります。 1. コストと品質を計測 (メータリング+評価セット/LLM- as-a-judge) 2. キャッシュ (プロンプトキャッシュ
→ セマンティック キャッシュ → 中間結果キャッシュ) 3. タスクでモデルを使い分ける (ルーティング) 4. 難所だけ上位に回す (カスケード) 5. (上級) SLM・Fine Tuning 16 Checkrでは、 大多数の易しいタスクを Fine TuningしたSLM、 難しい一部タスクだけ上位 モデルに回す (カスケー ド) 構成をとりました: → コスト約1/5、約30倍 の高速化を達成
ルーティングの考え方 タスクの難易度とリスクに応じてモデルを使い分けます。複雑な仕組みよりも、まずはルール ベースで十分です。自動ルーターに任せきりにはせず、計測しながら段階的に導入します。 こういうタスクは こう考える 定型・大量・低リスク 軽量モデルで十分なケースが多い 標準的な業務QA・ツール選択 中位モデルを軸に試しながら、必要に応じて軽量/上位モデ ルも検討
※シナリオ分解が必要 多段推論・高リスク 上位+推論モデルでどこまで解けるかまず整理 難易度が読めない 中位モデルを軸に試しながら、必要に応じて軽量/上位モデ ルも検討 ※シナリオ分解が必要 低レイテンシが必須 軽量+キャッシュで必要な非機能要件が達成されるかをま ず整理。ルールベースとの役割分担が必要となる 17
[注意] コストは “静かに” 暴走する エージェントシステムでは、エージェントは呼び出し回数を人が握らない設計となることが多い ため、コストが気づかぬうちに膨張するリスクがあります。 計測だけではなく、上限を設けましょう。 18 代表的な事例 暴走したマルチエージェントAIシステムが、エージェ
ント同士で264時間やりとりを続け、11日間で $47,000のLLM API費用を発生させました。 → ステップ上限・予算上限・終了判断を行うオーケ ストレーターのいずれもなかった → エージェント同士の会話においていずれもAPI エラーなどは発生しなかったため、月額請求が くるまで発覚しなかった
モデル変更への備え (回帰テスト) 利用しているモデルは予告なく更新されることがあります。バージョン固定とモデル変更時の回 帰テストにより、品質を維持する活動が欠かせません。 19 フォールバック先 を用意 定期/不定期の 回帰テストを実施 ゴールデンセット
の用意 公開ベンチを 盲信しない 問題発生時にモデル切り替え (フォールバック) が可能な状態とする ※フォールバック先の品質も回帰テストで事前確認できていると吉 回帰テストを実施して、モデルやプロンプト変更に伴うデグレをチェッ クする。コストとのバランスを考え、週次/変更時などタイミングを定義 入力と正解をペアにした品質の基準となる評価用データセット (=ゴー ルデンセット) を用意し、定期/変更時に評価を回す 公開ベンチは汎用的な能力を測る設計で、自社の実タスクの品質を必ず しも反映しない。必ず自社タスクで評価する必要がある
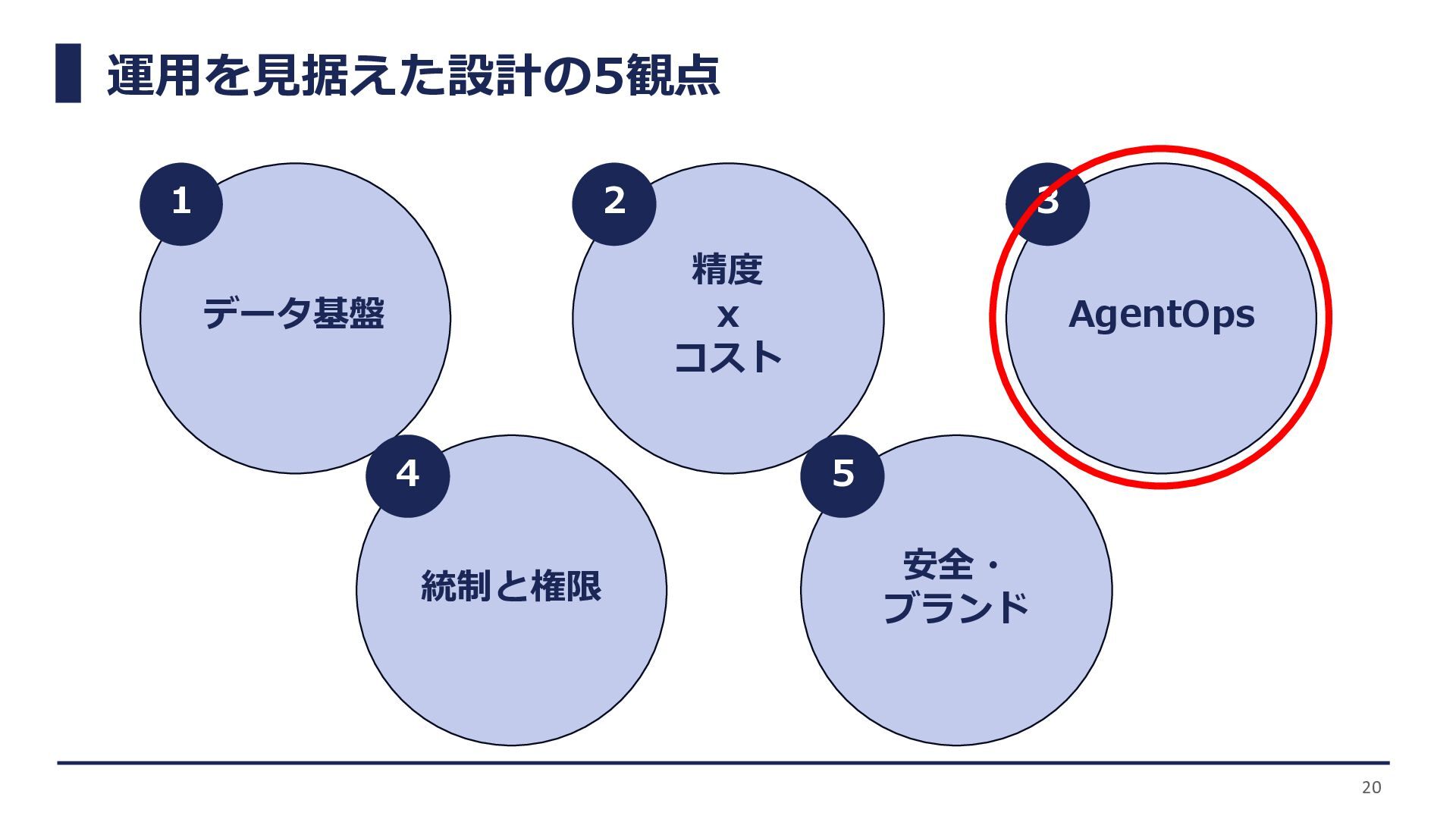
運用を見据えた設計の5観点 データ基盤 精度 x コスト AgentOps 統制と権限 安全・ ブランド 20
1 2 3 4 5
MLOps → LLMOps → AgentOps AgentOpsとは 複数ステップにわたるタスク遂行やAPI連携などを行うエージェント全体のライ フサイクル管理を重視し、これに伴う複雑性や非決定論性へ対応する 観測性 トレーサビリティ
フィードバック ループ エージェントの 安全性/ガバナンス エージェントの内部状態や意思決定プロセスを可視化する 入力から出力までのプロセスを記録する エージェントの性能評価やユーザー行動データを収集し、モデルやプロン プトを継続的に改善する エージェントが実行するアクションが安全であるかをリアルタイム判定し、 リスクが高い場合はHuman-in-the-loopで確認する
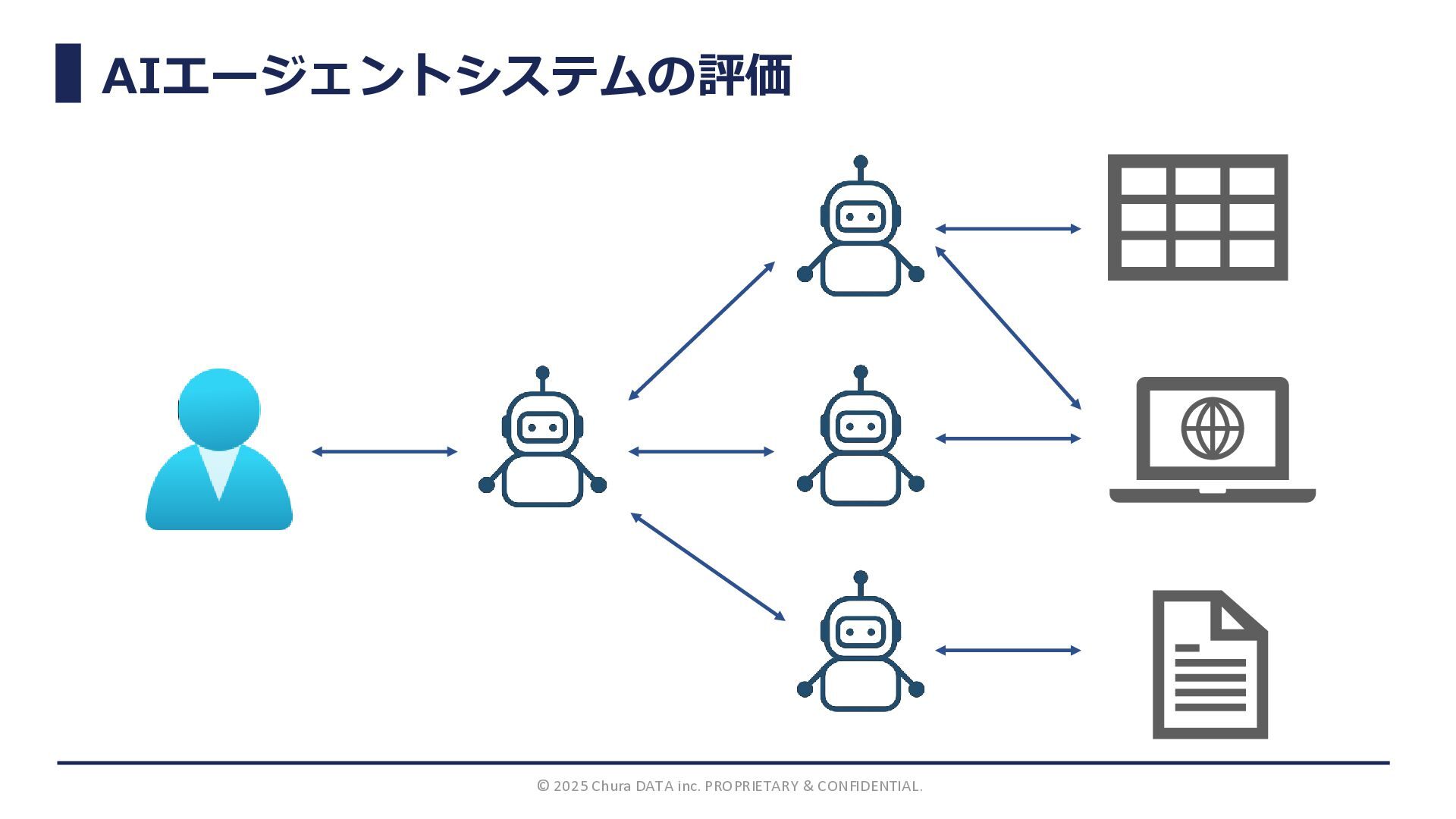
AIエージェントシステムの評価 © 2025 Chura DATA inc. PROPRIETARY & CONFIDENTIAL.
AIエージェントシステムの評価 © 2025 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. システム全体の評価
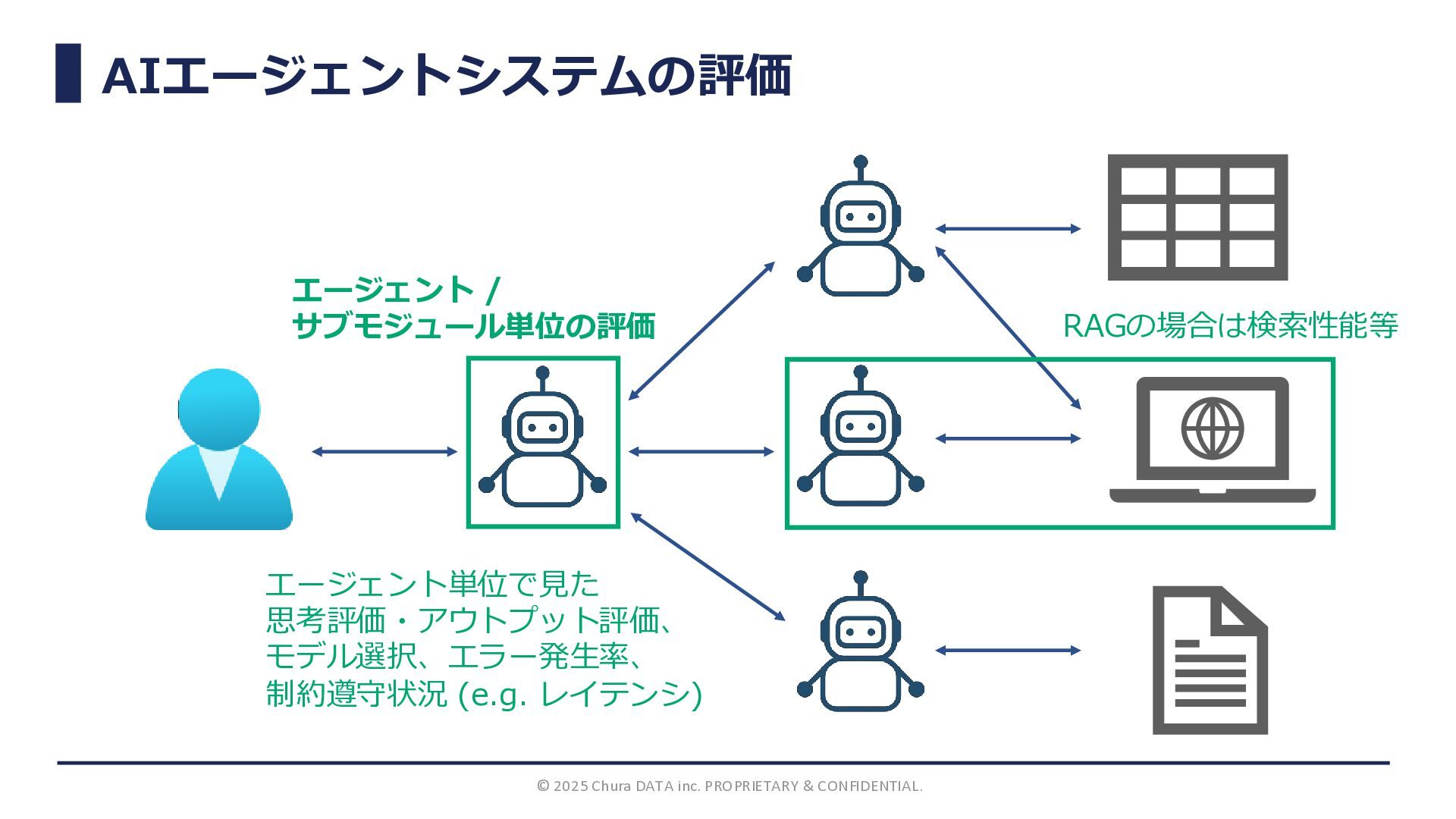
エージェント / サブモジュール単位の評価 選択や 軌跡の評価
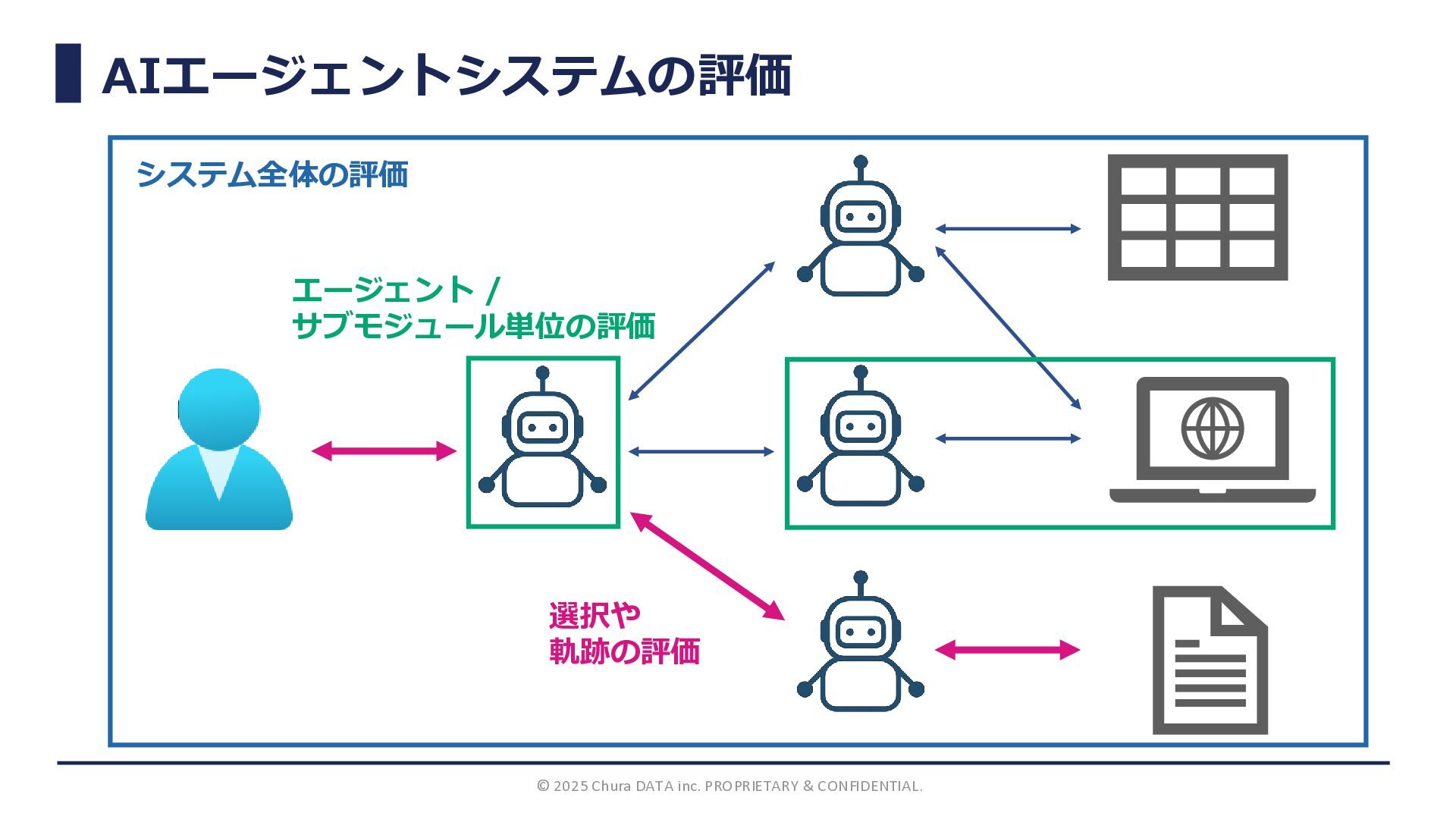
AIエージェントシステムの評価 © 2025 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. システム全体の評価
入力に対する出力の品質評価 (=タスク 達成度) 制約遵守状況 (e.g. レイテンシ、 コスト)
AIエージェントシステムの評価 © 2025 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. エージェント
/ サブモジュール単位の評価 エージェント単位で見た 思考評価・アウトプット評価、 モデル選択、エラー発生率、 制約遵守状況 (e.g. レイテンシ) RAGの場合は検索性能等
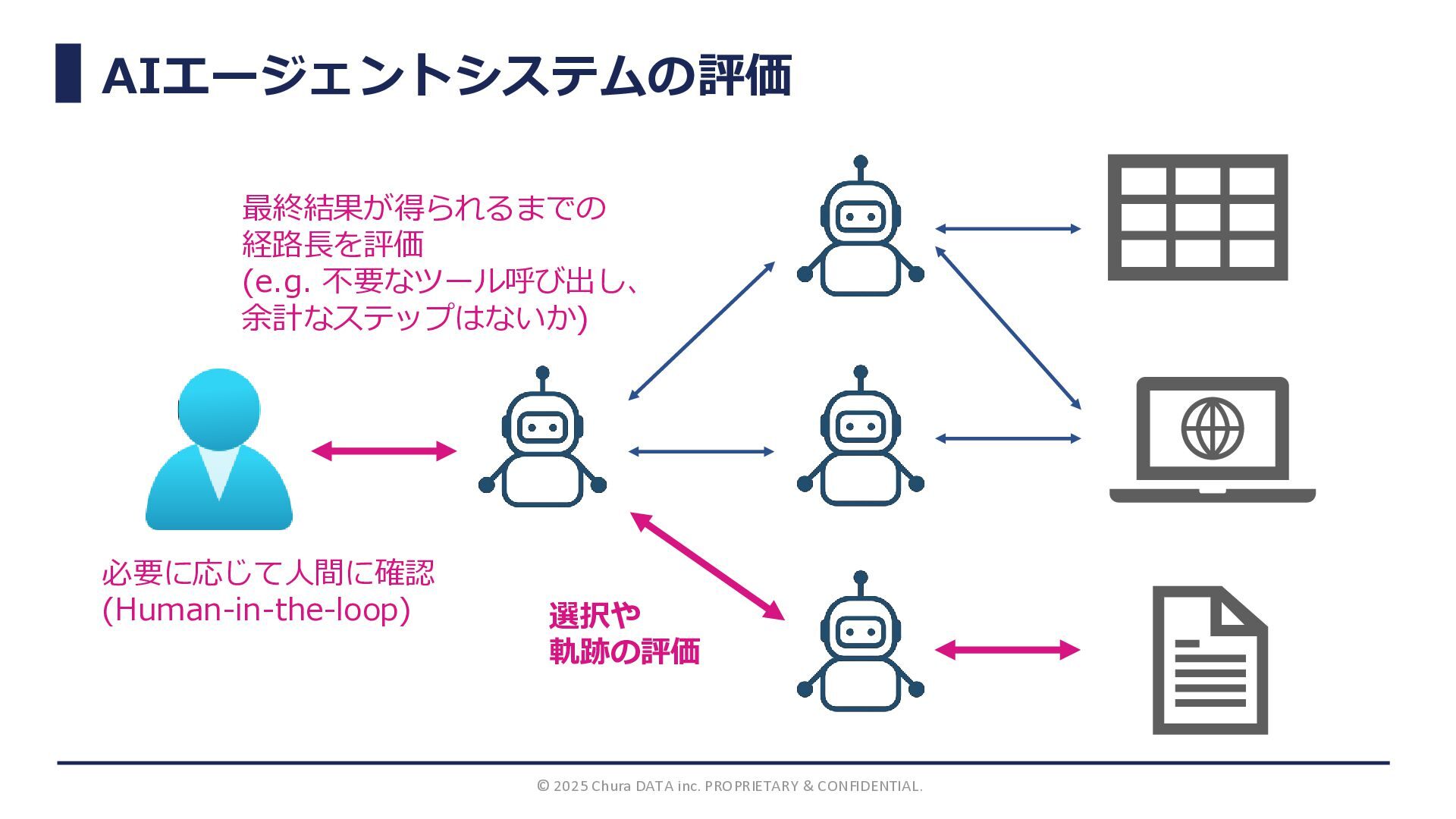
AIエージェントシステムの評価 © 2025 Chura DATA inc. PROPRIETARY & CONFIDENTIAL. 選択や
軌跡の評価 最終結果が得られるまでの 経路長を評価 (e.g. 不要なツール呼び出し、 余計なステップはないか) 必要に応じて人間に確認 (Human-in-the-loop)
どこまでやるか (MUST / SHOULD / NICE) 一度にすべての評価をカバーしようとするのではなく、投資対効果を見ながら最小構成 (MUST) の評価から段階的に広げていきます。 MUST(最低限・最優先で導入)
トレース収集 / 小さなデータセットでの評価 / 変更時の回帰 / HITL (人手による確認) SHOULD(あると良い) オンライン評価 / 選択や軌跡の評価 / 評価セットの拡充 NICE(先進的) シナリオの自動生成 / 評価役 (=LLM-as-a-judgeモデル自体) の検証 / マルチ評価 27
[参考] 評価タイミングごとに必要となる機能の違い 28 観点 開発時の評価(検証・改善) 運用時の評価(モニタリング) タイミング オフライン(リリース前) オンライン(本番中・継続) 目的
精度を作り込む・回帰を防ぐ ドリフト・コスト急増・異常を検知 使うもの 正解付きデータ/LLM-as-a-judge 本番トレース/サンプリング評価・ 閾値アラート ツール傾向 評価特化が強い 観測・監視が強い 評価には2つのタイミングがあり、目的も使う機能も違います。通常の開発&運用では、両方を 組み合わせて使い分けます。
運用を見据えた設計の5観点 データ基盤 精度 x コスト AgentOps 統制と権限 安全・ ブランド 29
1 2 3 4 5
エージェントシステム統制の課題 30 エージェントに対して不必要に強い権限を与えるてしまい、誤りや 乗っ取りが発生した場合の被害リスクが高くなる 社内でのエージェント開発が盛んになった結果、様々なエージェント が作られ、それらが管理されず放置・残存し、攻撃面が増えてしまう 過剰権限 乱立 エージェントシステムの統制上、代表的な課題が「過剰権限」と「乱立」です。 『権限の最小化』と『乱立の管理』を適切に実施できるかが論点となります
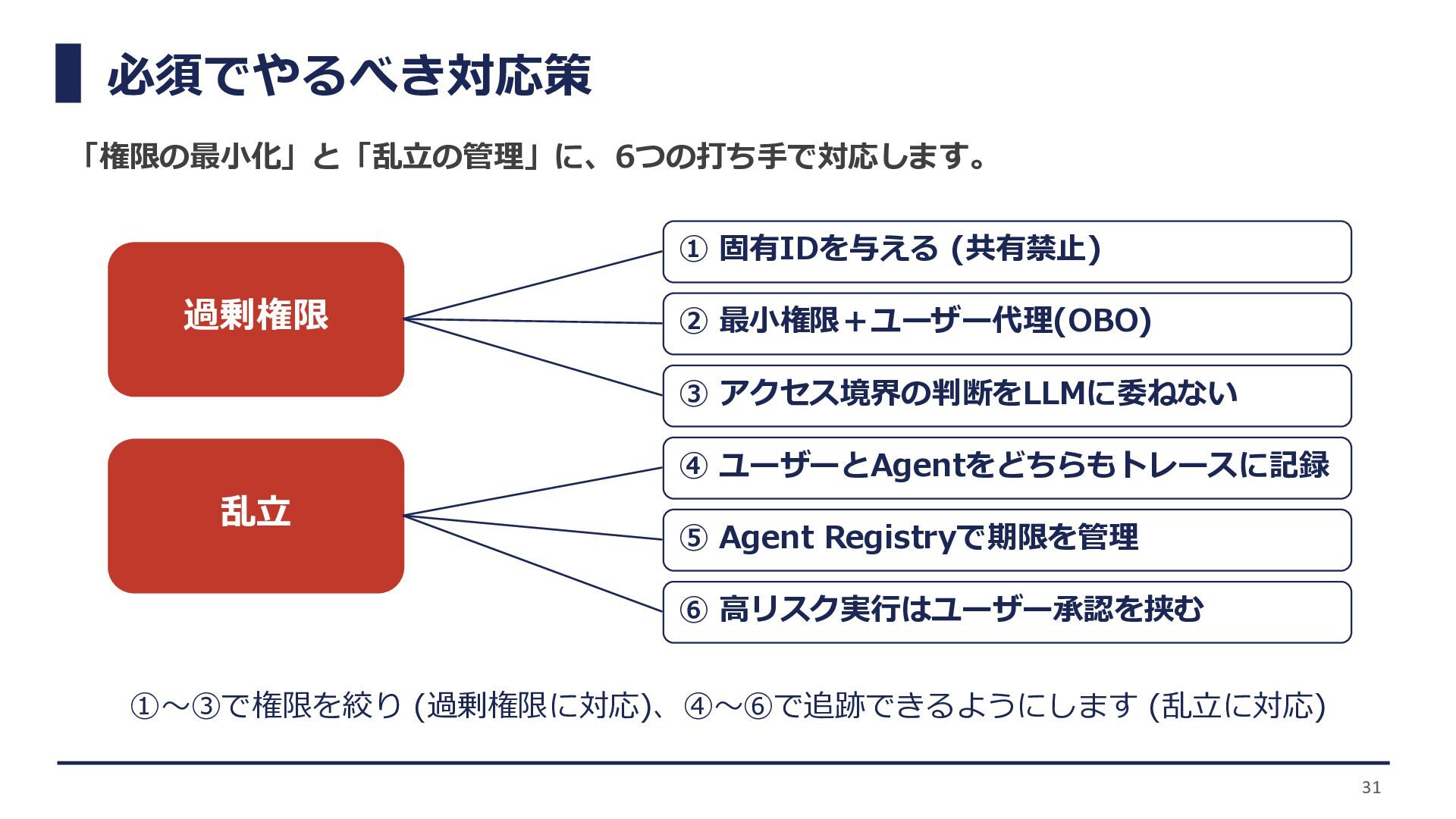
必須でやるべき対応策 「権限の最小化」と「乱立の管理」に、6つの打ち手で対応します。 過剰権限 乱立 ① 固有IDを与える (共有禁止) ② 最小権限+ユーザー代理(OBO) ③
アクセス境界の判断をLLMに委ねない ④ ユーザーとAgentをどちらもトレースに記録 ⑤ Agent Registryで期限を管理 ⑥ 高リスク実行はユーザー承認を挟む ①〜③で権限を絞り (過剰権限に対応)、④〜⑥で追跡できるようにします (乱立に対応) 31
運用を見据えた設計の5観点 データ基盤 精度 x コスト AgentOps 統制と権限 安全・ ブランド 32
1 2 3 4 5
安全やブランド 33 ユーザーや外部と接するエージェントは、敵対的な入力やブランド毀損のリスクに常に晒されて います。特にtoC向けに自由入力のチャットボットを提供するケース等でリスクが高くなります。 DPD: 配送botが誘導され、自社を罵倒・批判する投稿 を生成して炎上した ブランド 毀損 トーン・禁止トピックを出力ガードで強制。逸脱を検
知したら人へエスカレーションする。 敵対的 入力 実例 検討事項 EchoLeak: メール1通のゼロクリックで、Copilotから 社内情報が外部へ流出した 入力検証とプロンプトインジェクション対策。外部 データは非信頼として扱い、ツール権限を分離する 実例 検討事項
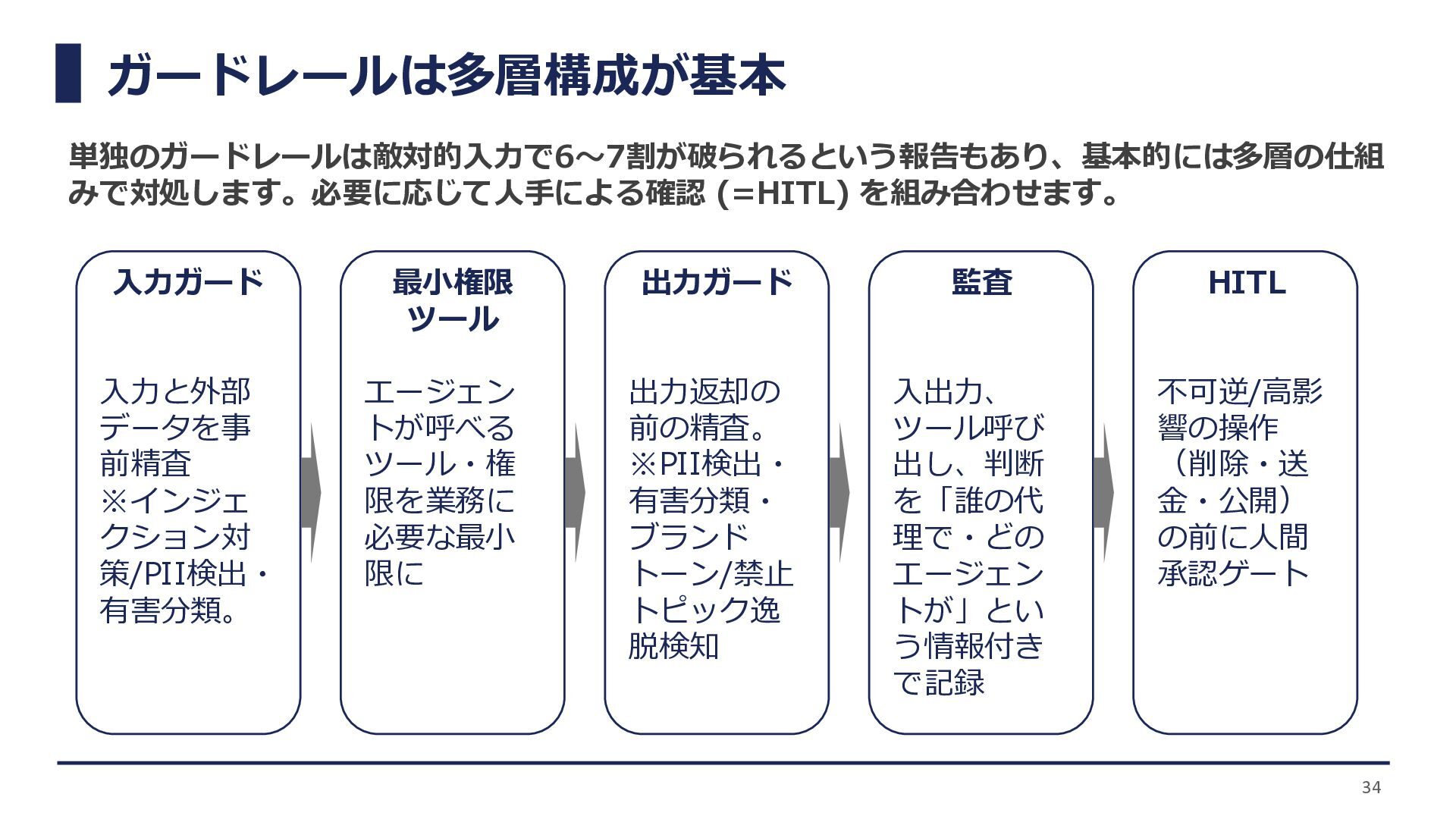
ガードレールは多層構成が基本 34 単独のガードレールは敵対的入力で6〜7割が破られるという報告もあり、基本的には多層の仕組 みで対処します。必要に応じて人手による確認 (=HITL) を組み合わせます。 入力ガード 入力と外部 データを事 前精査
※インジェ クション対 策/PII検出・ 有害分類。 最小権限 ツール エージェン トが呼べる ツール・権 限を業務に 必要な最小 限に 出力ガード 出力返却の 前の精査。 ※PII検出・ 有害分類・ ブランド トーン/禁止 トピック逸 脱検知 監査 入出力、 ツール呼び 出し、判断 を「誰の代 理で・どの エージェン トが」とい う情報付き で記録 HITL 不可逆/高影 響の操作 (削除・送 金・公開) の前に人間 承認ゲート
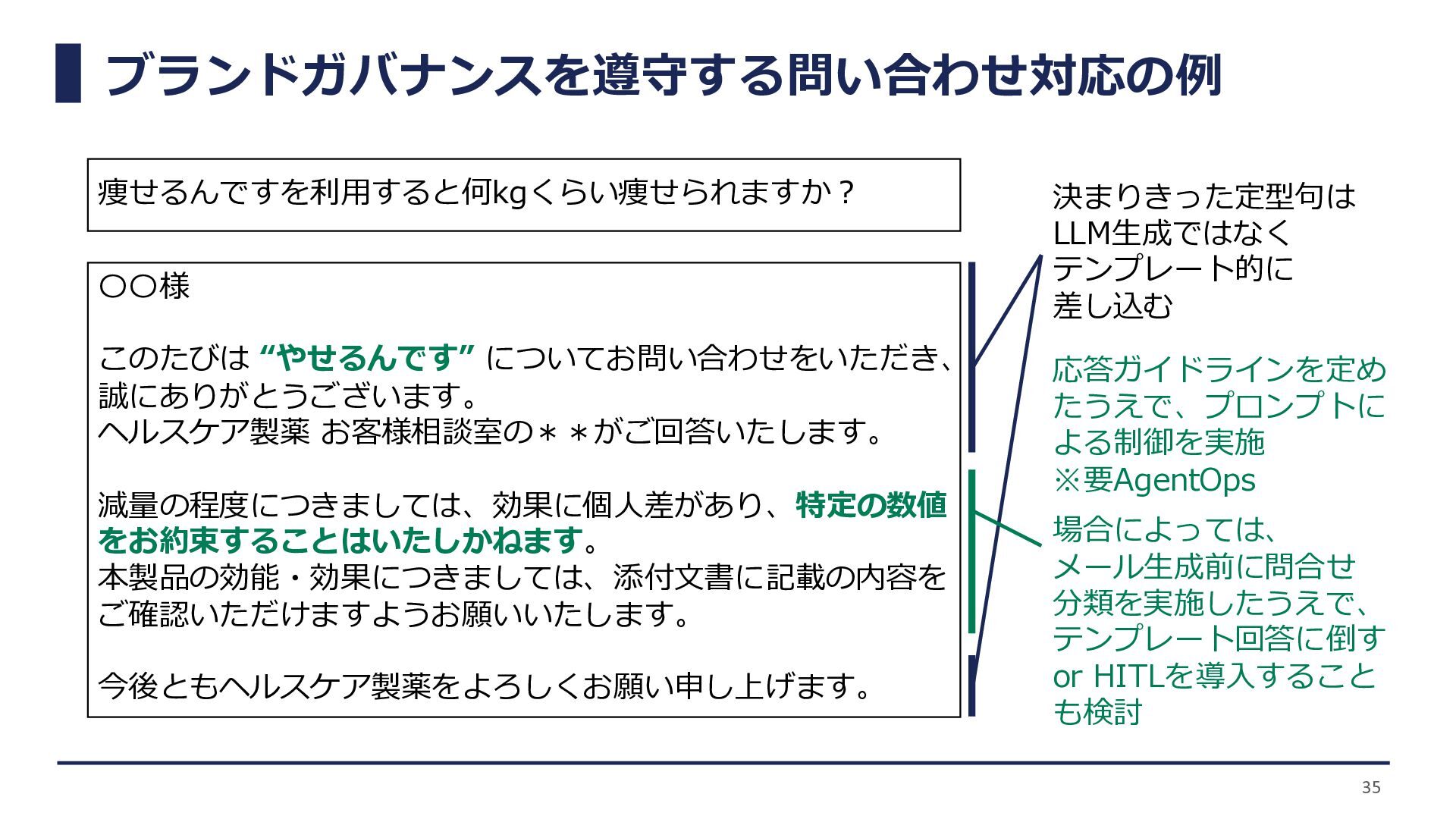
ブランドガバナンスを遵守する問い合わせ対応の例 35 〇〇様 このたびは “やせるんです” についてお問い合わせをいただき、 誠にありがとうございます。 ヘルスケア製薬 お客様相談室の**がご回答いたします。 減量の程度につきましては、効果に個人差があり、特定の数値
をお約束することはいたしかねます。 本製品の効能・効果につきましては、添付文書に記載の内容を ご確認いただけますようお願いいたします。 今後ともヘルスケア製薬をよろしくお願い申し上げます。 痩せるんですを利用すると何kgくらい痩せられますか? 決まりきった定型句は LLM生成ではなく テンプレート的に 差し込む 応答ガイドラインを定め たうえで、プロンプトに よる制御を実施 ※要AgentOps 場合によっては、 メール生成前に問合せ 分類を実施したうえで、 テンプレート回答に倒す or HITLを導入すること も検討
まとめ 36
総論: 『作れる』の次は『使われ続ける』 37 使われ続けるエージェントを作るために、 安全性やブランドを守りながら 高品質に運用するための設計を実践しましょう
会社紹介 38
会社概要 “ちゅらデータ株式会社” は 沖縄に本社を構えるIT企業です 社名 ちゅらデータ株式会社 代表者 真嘉比 愛 設立
2017年8月7日 所在地 〒901-2134 沖縄県浦添市港川512番 地55 ゆがふBizタワー浦 添港川 3F 社員数 130名 ※ 2026年4月時点 ※ アルバイト含む 39
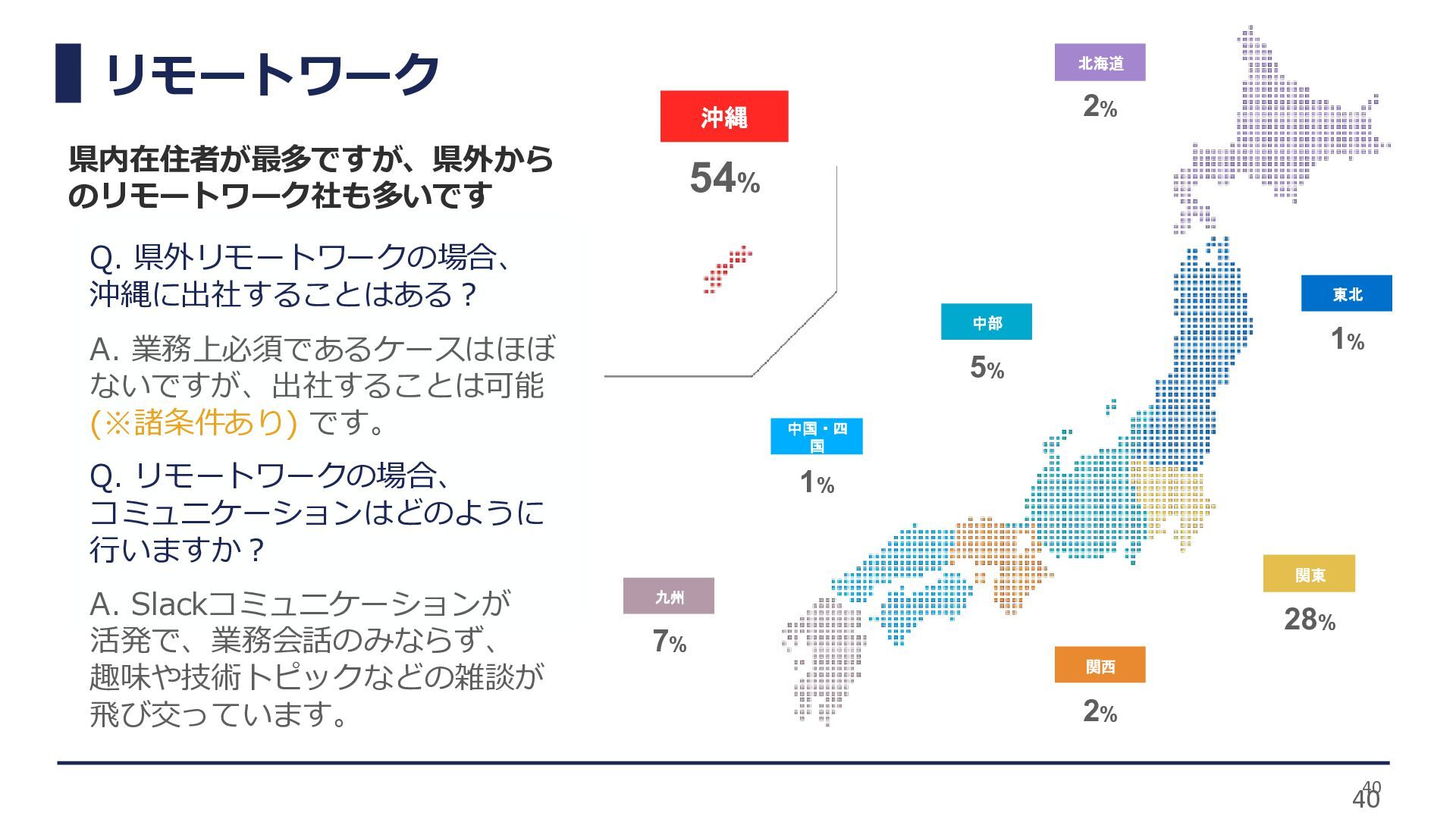
リモートワーク 40 北海道 中国・四 国 1% 九州 7% 関西 2%
中部 5% 東北 1% 関東 28% 2% 沖縄 54% Q. 県外リモートワークの場合、 沖縄に出社することはある? A. 業務上必須であるケースはほぼ ないですが、出社することは可能 (※諸条件あり) です。 Q. リモートワークの場合、 コミュニケーションはどのように 行いますか? A. Slackコミュニケーションが 活発で、業務会話のみならず、 趣味や技術トピックなどの雑談が 飛び交っています。 県内在住者が最多ですが、県外から のリモートワーク社も多いです 40
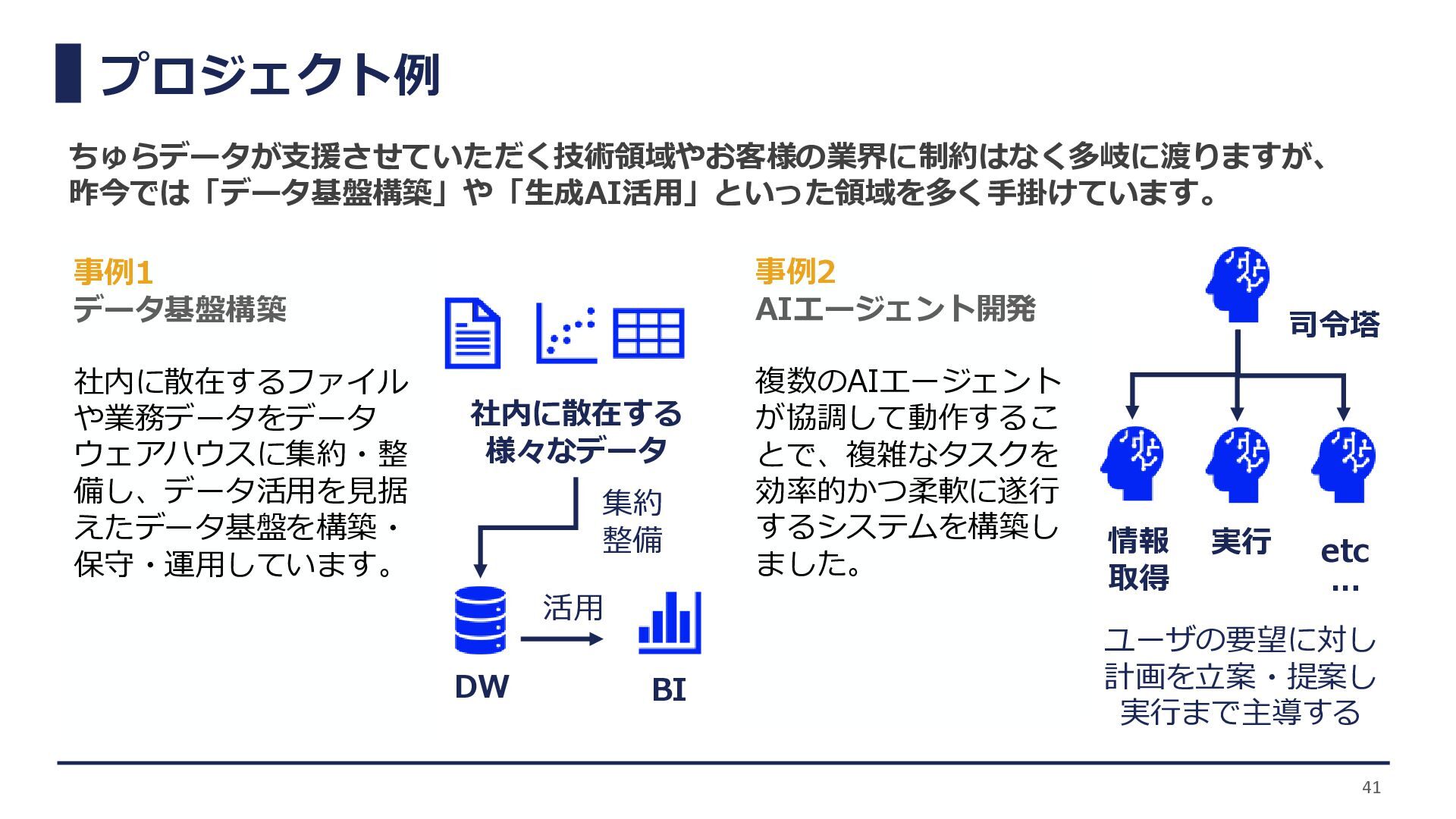
プロジェクト例 事例1 データ基盤構築 社内に散在するファイル や業務データをデータ ウェアハウスに集約・整 備し、データ活用を見据 えたデータ基盤を構築・ 保守・運用しています。 事例2
AIエージェント開発 複数のAIエージェント が協調して動作するこ とで、複雑なタスクを 効率的かつ柔軟に遂行 するシステムを構築し ました。 社内に散在する 様々なデータ DW BI 集約 整備 活用 情報 取得 実行 etc … ユーザの要望に対し 計画を立案・提案し 実行まで主導する ちゅらデータが支援させていただく技術領域やお客様の業界に制約はなく多岐に渡りますが、 昨今では「データ基盤構築」や「生成AI活用」といった領域を多く手掛けています。 司令塔 41
We are Hiring! 様々な職種で積極て採用中です!ご興味ある方はぜひカジュアル面談から! https://churadata.okinawa/recruit/ • AIエンジニア • Webアプリケーションエンジニア •
システムエンジニア • データエンジニア • データサイエンティスト • データビジネスコンサルタント 42 まっちょいびんど〜 (待ってるよ〜)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] “静かに使われなくなる” ことを防ぐ 8 仮に運用に載せることができても、適切なKGI/KPIやユーザーシナリオが設計されていなかっ たり、運用体制に不備があるケースでは、エージェントは “静かに使われなくなります”。 ユーザーシナリオ/ 業務接続の未設計 現場のフローに載らず](https://files.speakerdeck.com/presentations/25dde58662974665835ad69e4dbb1da8/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] オントロジーに載る指標: Semantic Layer 12 オントロジーが「概念と関係 (e.g. 顧客・売上 という概念がどう繋がるか)」を定義し、 セマンティックレイヤーが「その概念をどう計](https://files.speakerdeck.com/presentations/25dde58662974665835ad69e4dbb1da8/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[注意] コストは “静かに” 暴走する エージェントシステムでは、エージェントは呼び出し回数を人が握らない設計となることが多い ため、コストが気づかぬうちに膨張するリスクがあります。 計測だけではなく、上限を設けましょう。 18 代表的な事例 暴走したマルチエージェントAIシステムが、エージェ](https://files.speakerdeck.com/presentations/25dde58662974665835ad69e4dbb1da8/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[参考] 評価タイミングごとに必要となる機能の違い 28 観点 開発時の評価(検証・改善) 運用時の評価(モニタリング) タイミング オフライン(リリース前) オンライン(本番中・継続) 目的](https://files.speakerdeck.com/presentations/25dde58662974665835ad69e4dbb1da8/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}