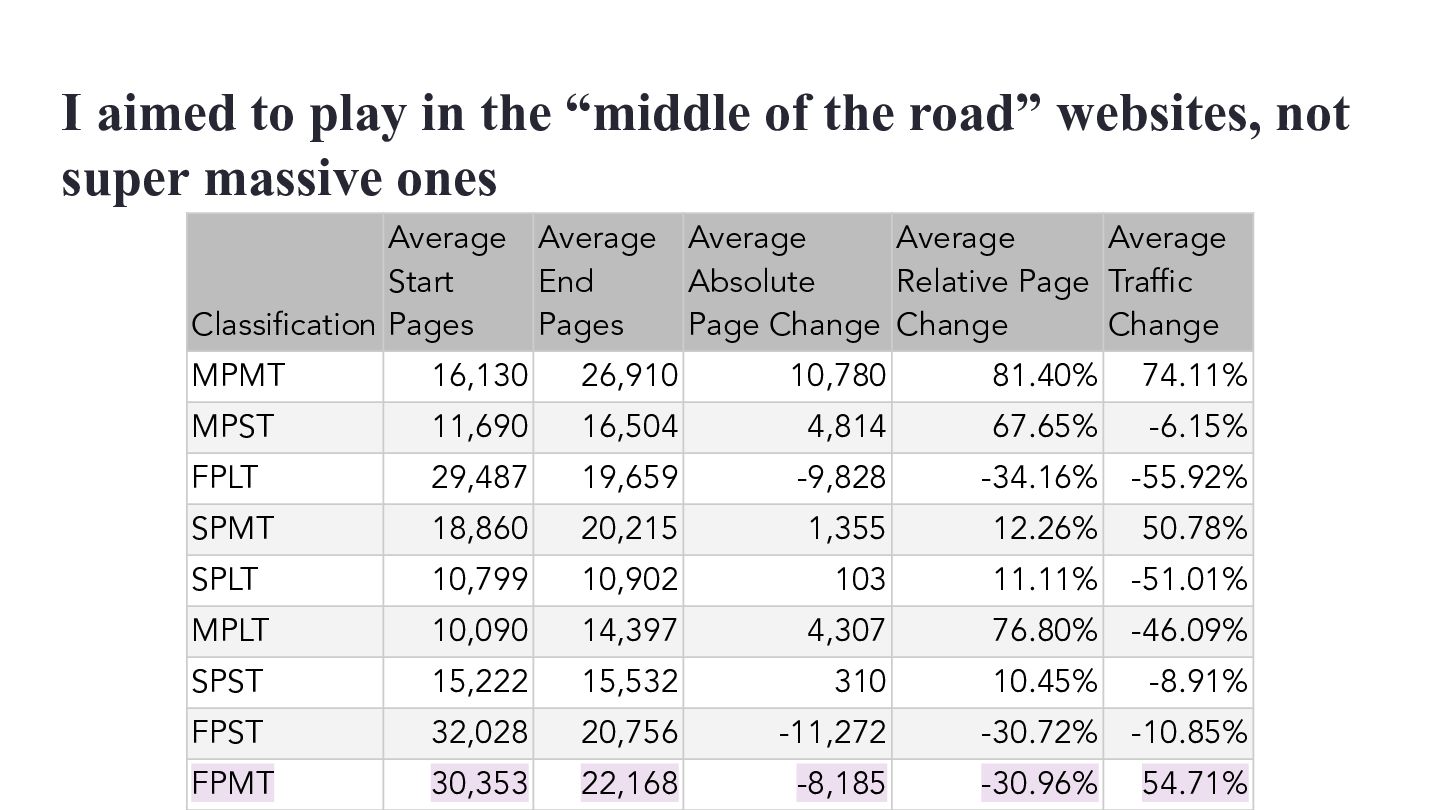
websites, not super massive ones Classification Average Start Pages Average End Pages Average Absolute Page Change Average Relative Page Change Average Traffic Change MPMT 16,130 26,910 10,780 81.40% 74.11% MPST 11,690 16,504 4,814 67.65% -6.15% FPLT 29,487 19,659 -9,828 -34.16% -55.92% SPMT 18,860 20,215 1,355 12.26% 50.78% SPLT 10,799 10,902 103 11.11% -51.01% MPLT 10,090 14,397 4,307 76.80% -46.09% SPST 15,222 15,532 310 10.45% -8.91% FPST 32,028 20,756 -11,272 -30.72% -10.85% FPMT 30,353 22,168 -8,185 -30.96% 54.71%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
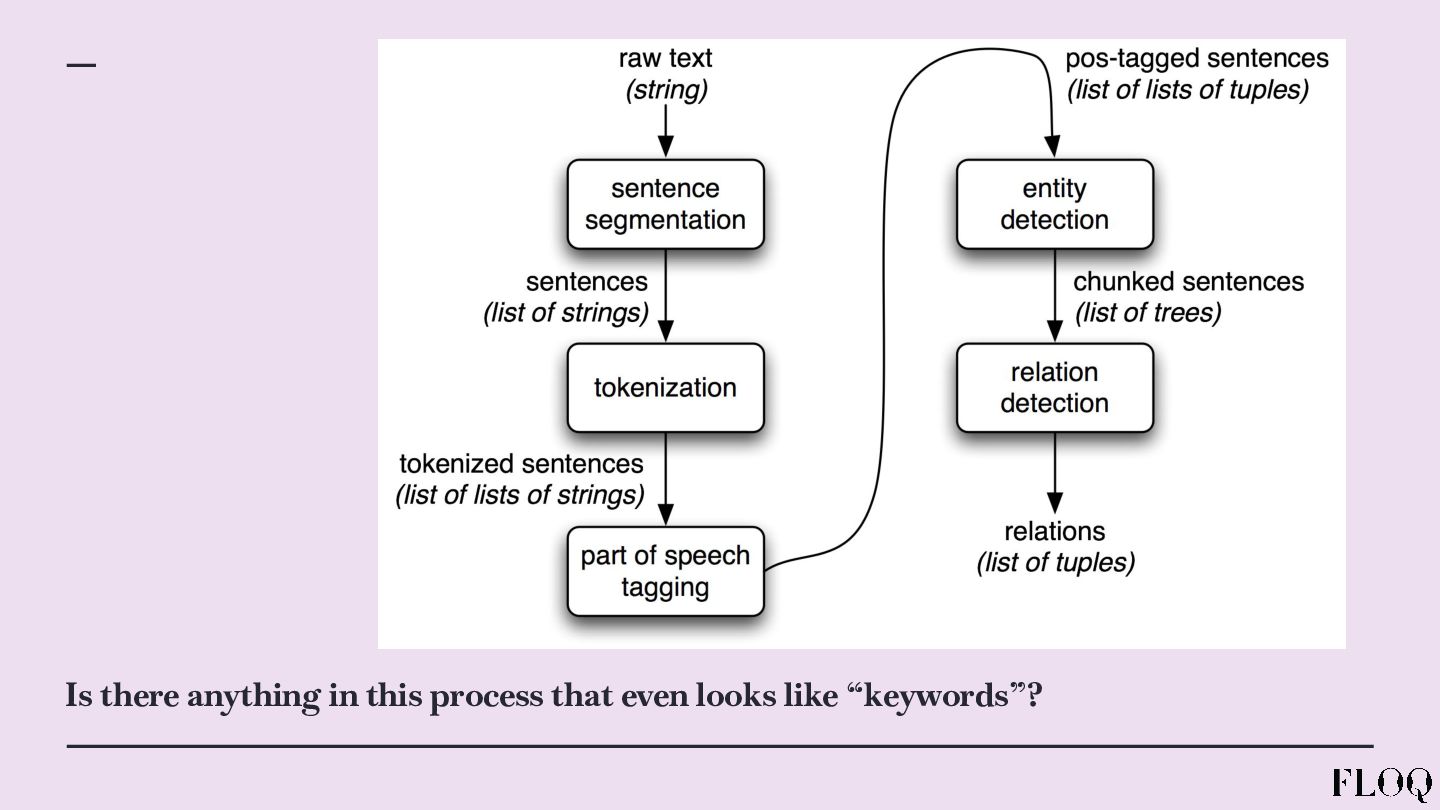
![Queries very quickly become entities “[...]identifying queries in query data;](https://files.speakerdeck.com/presentations/8aaf36a8c3804f7983dba676443148b8/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
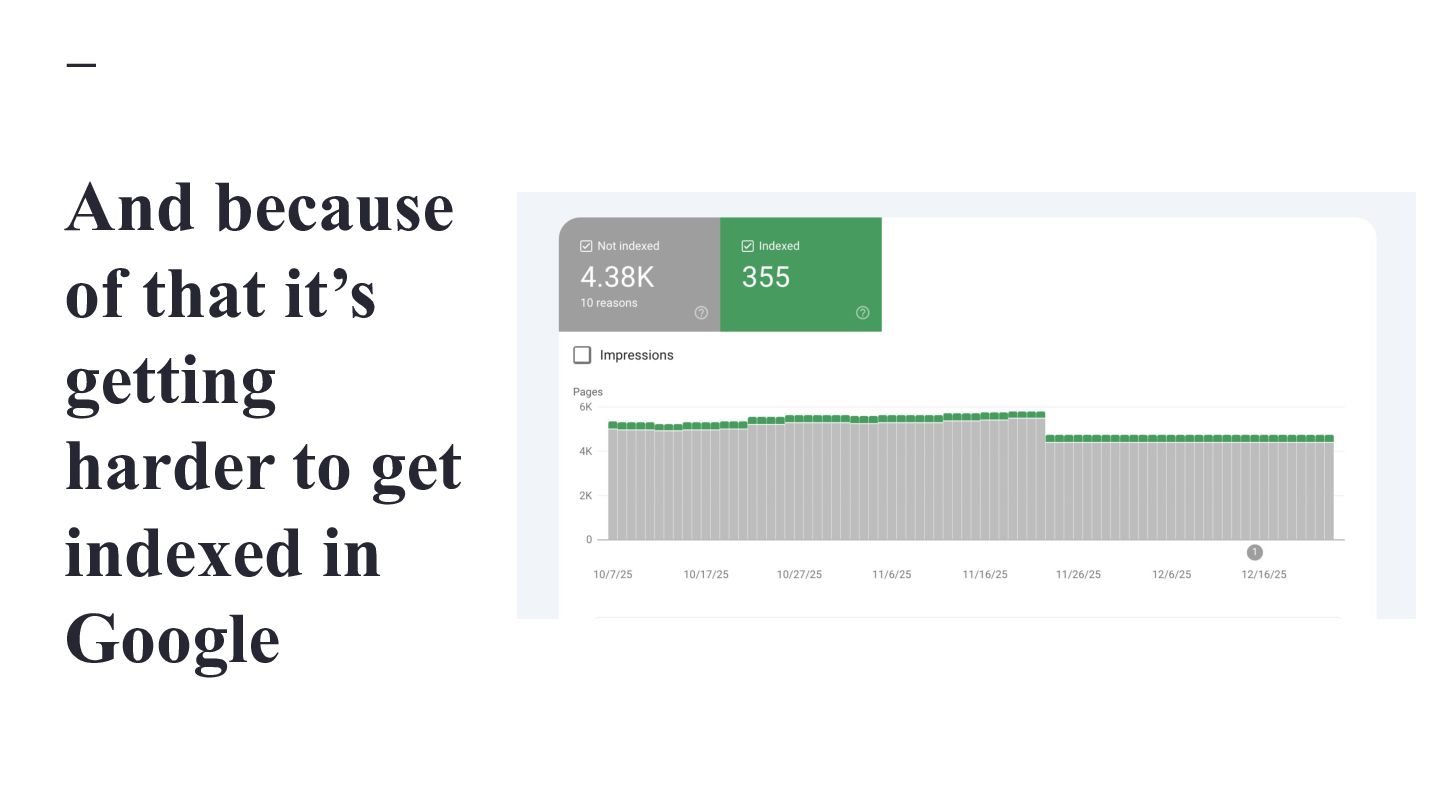{kind=link}
{kind=link}
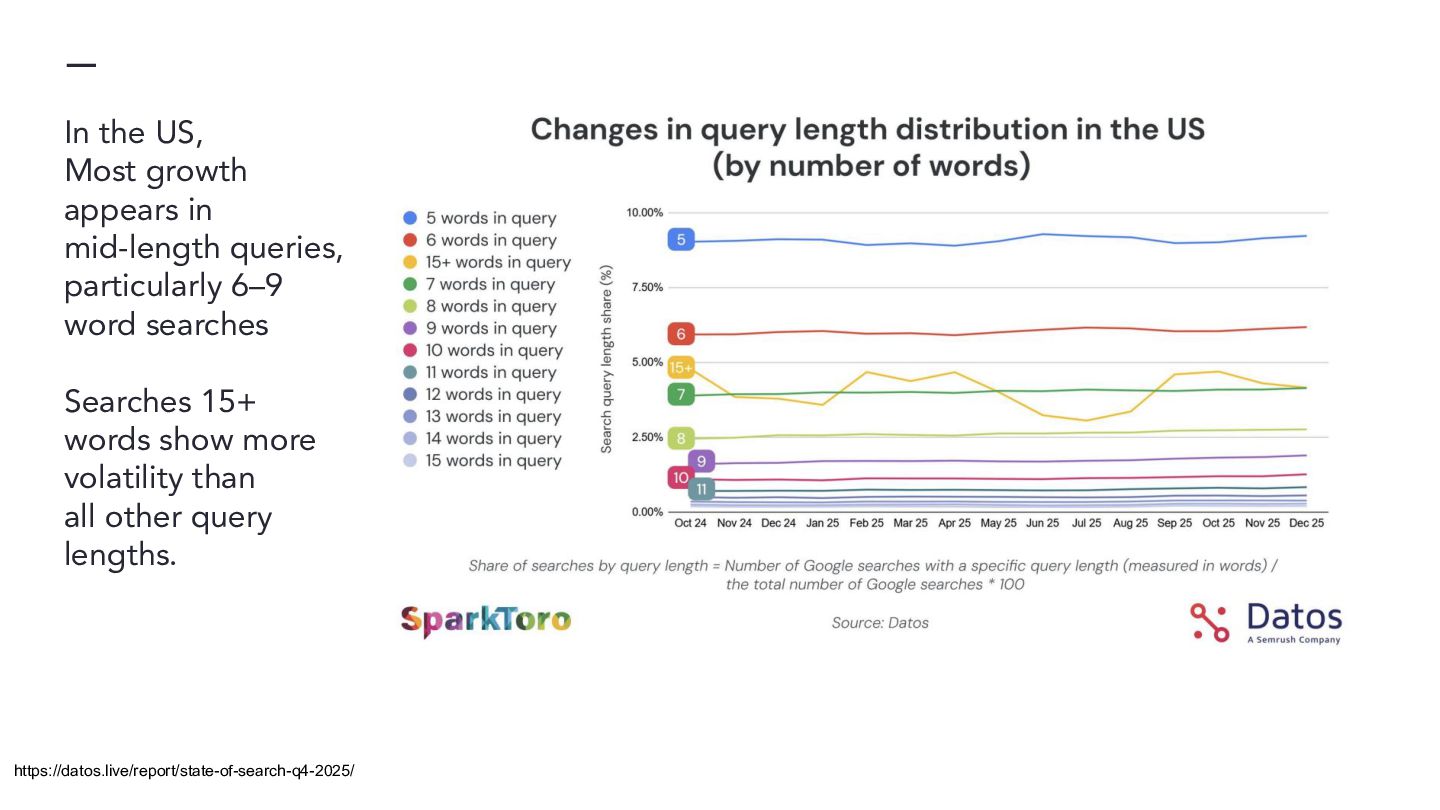{kind=link}
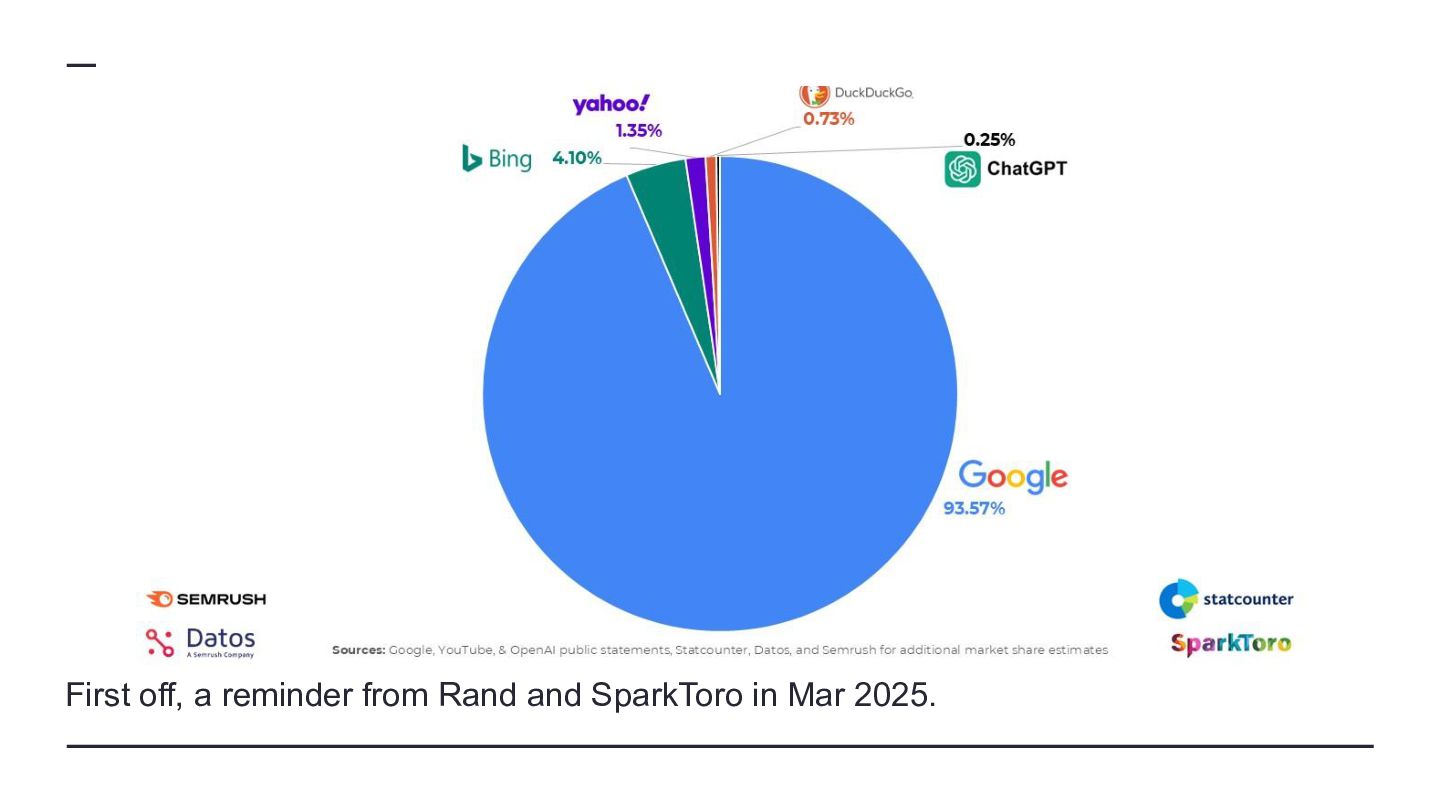{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
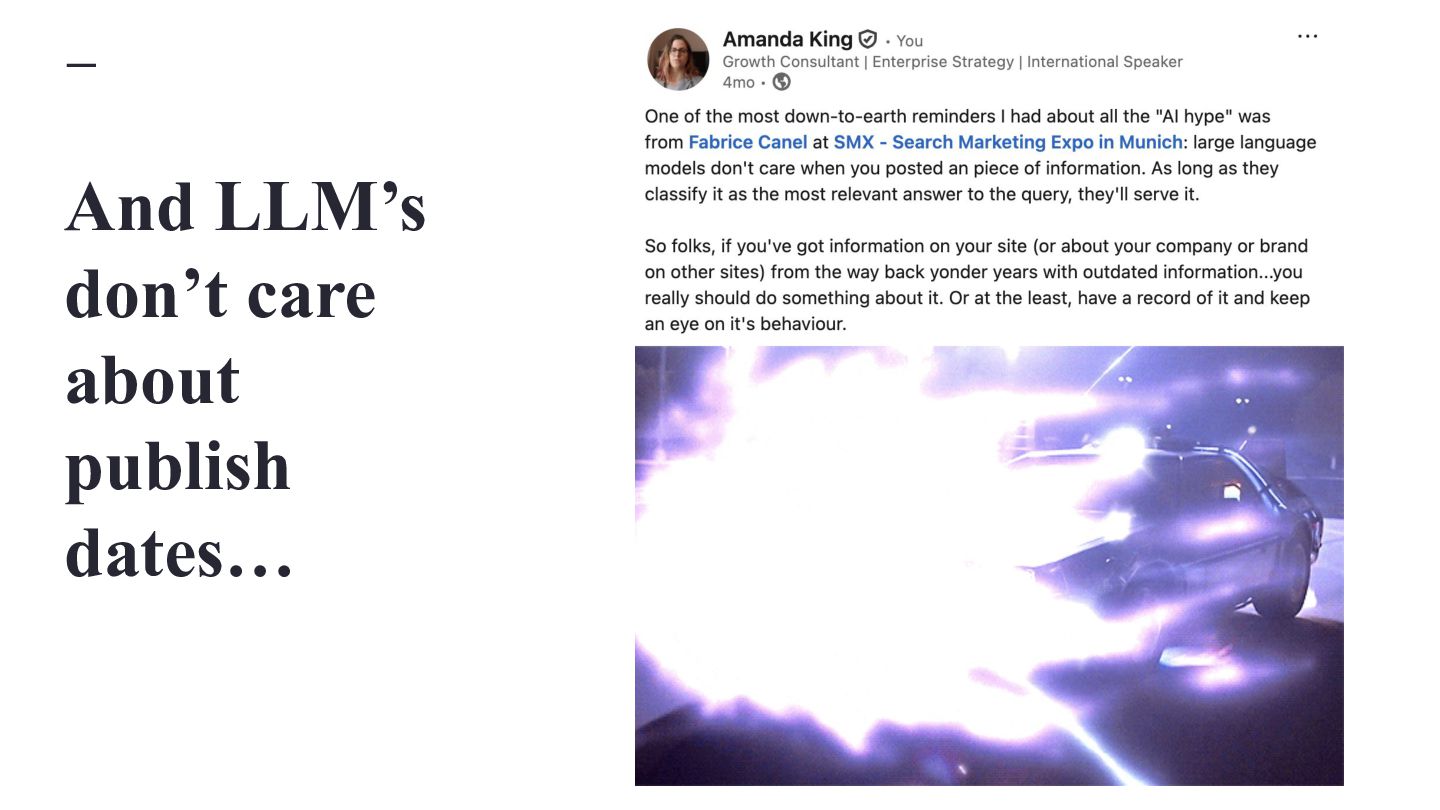{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
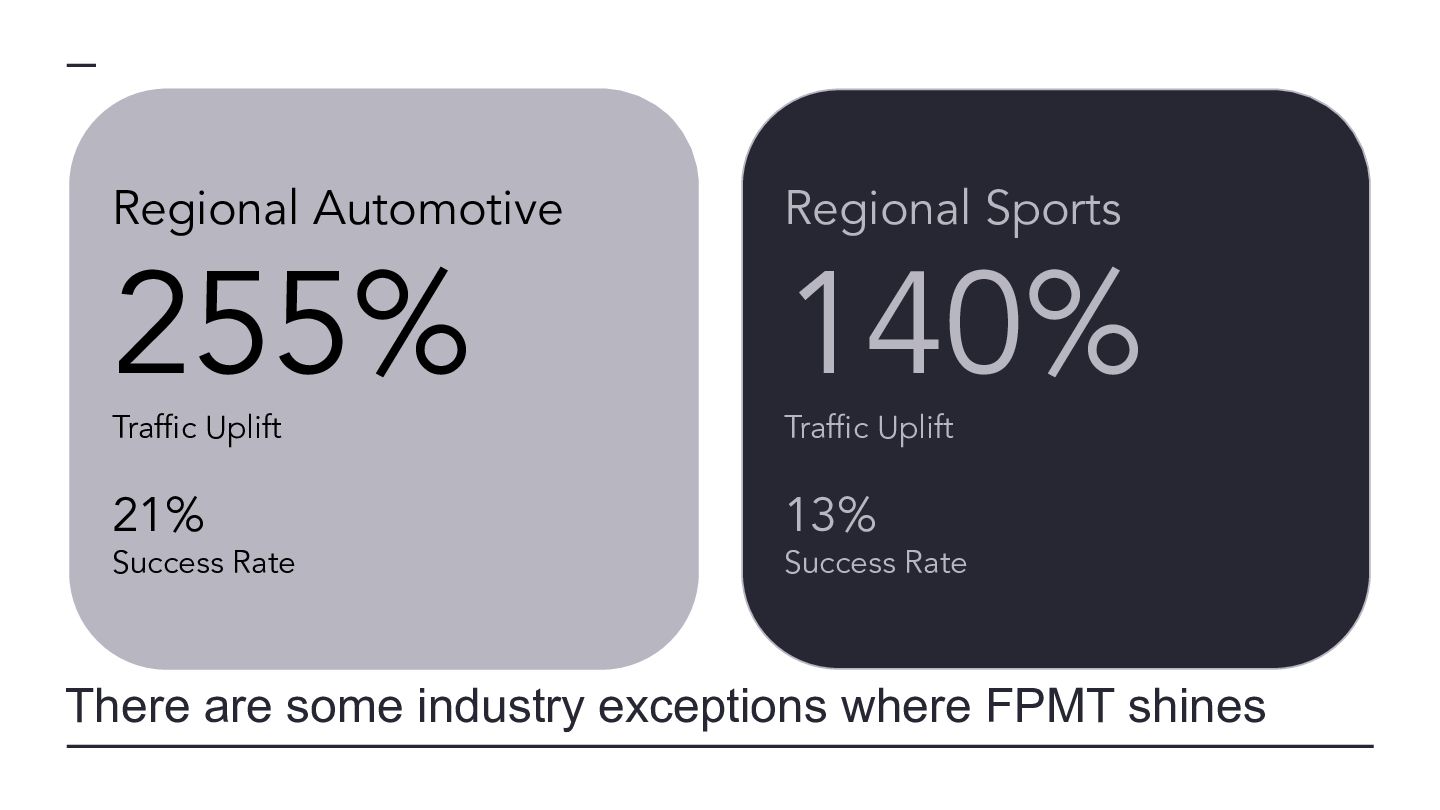{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
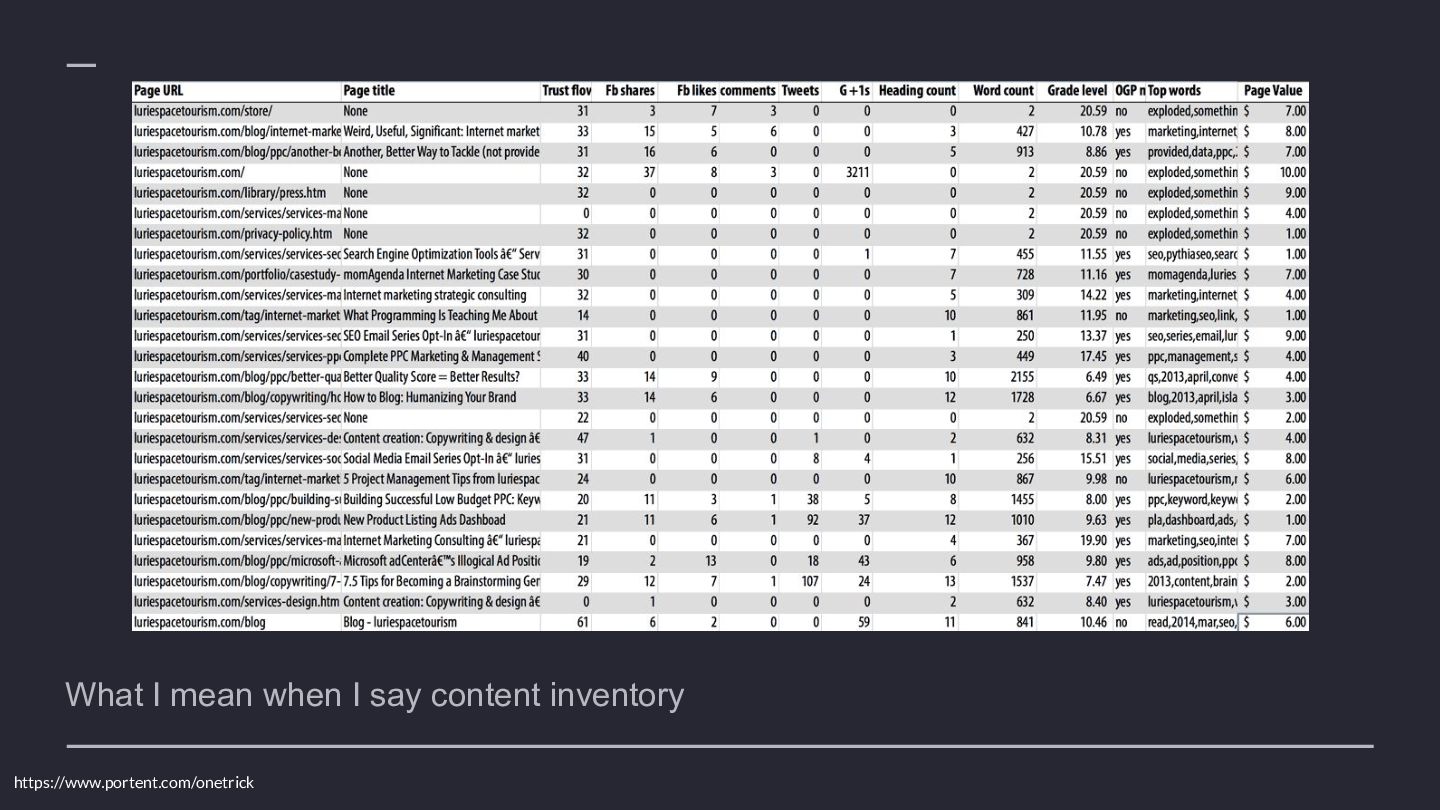{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
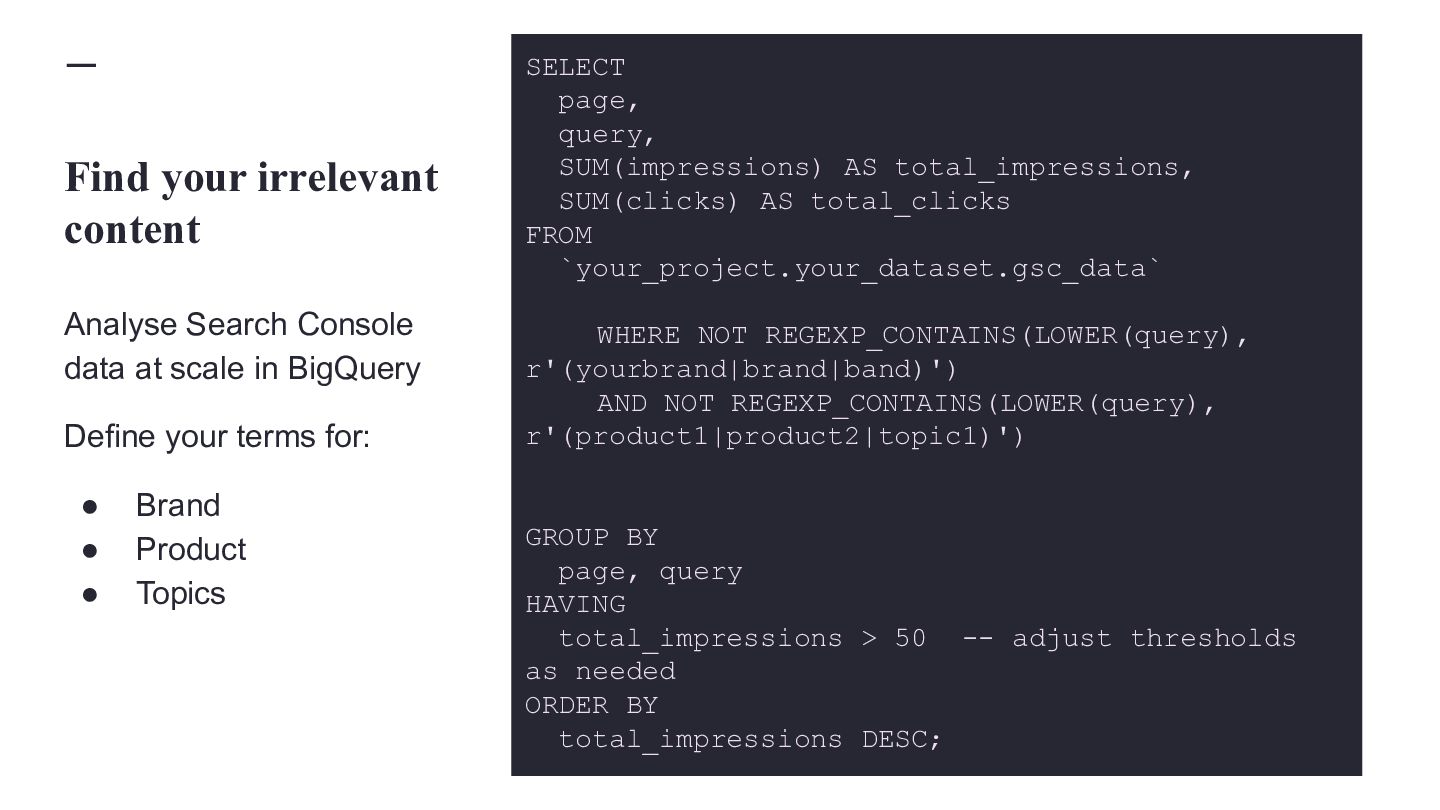{kind=link}
{kind=link}
{kind=link}
{kind=link}
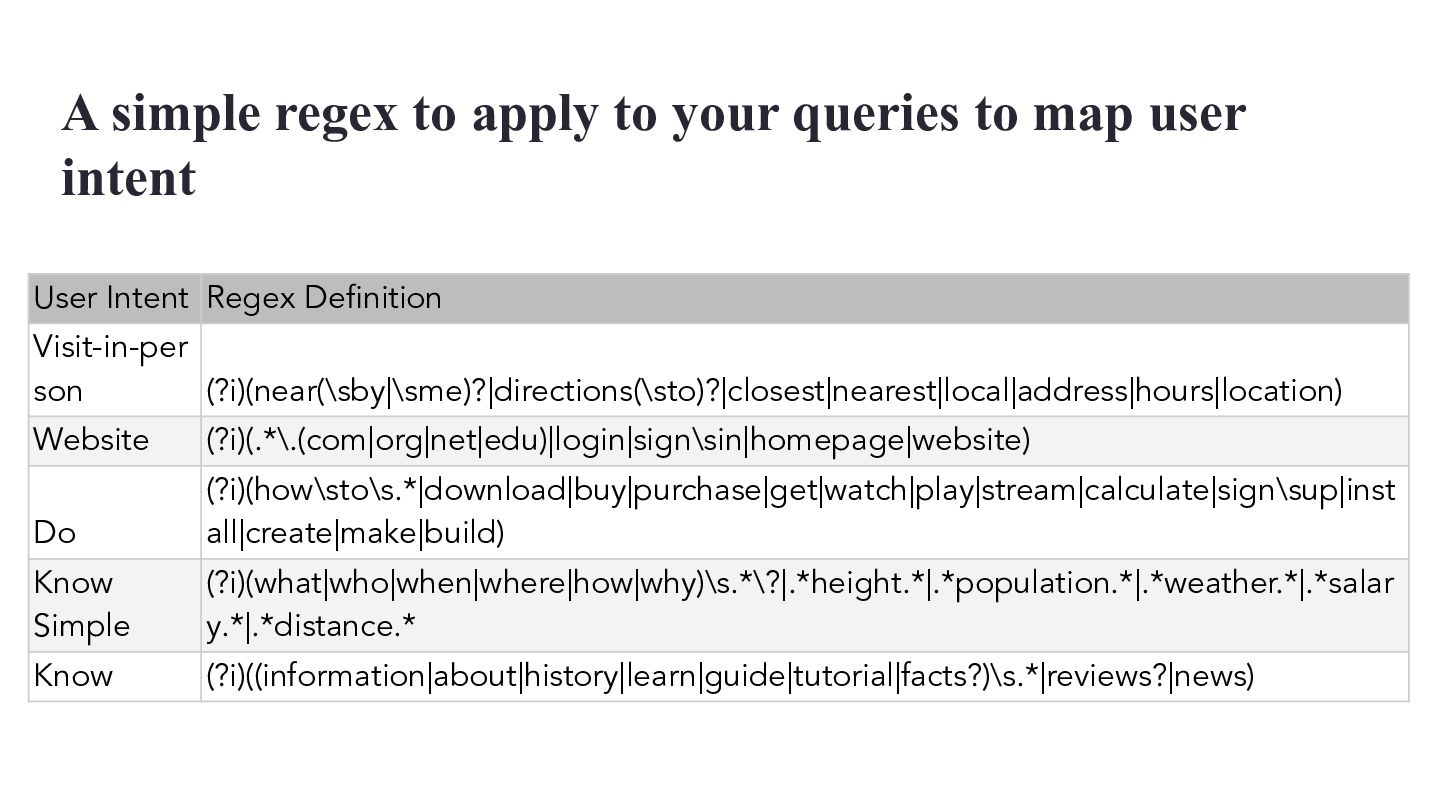{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
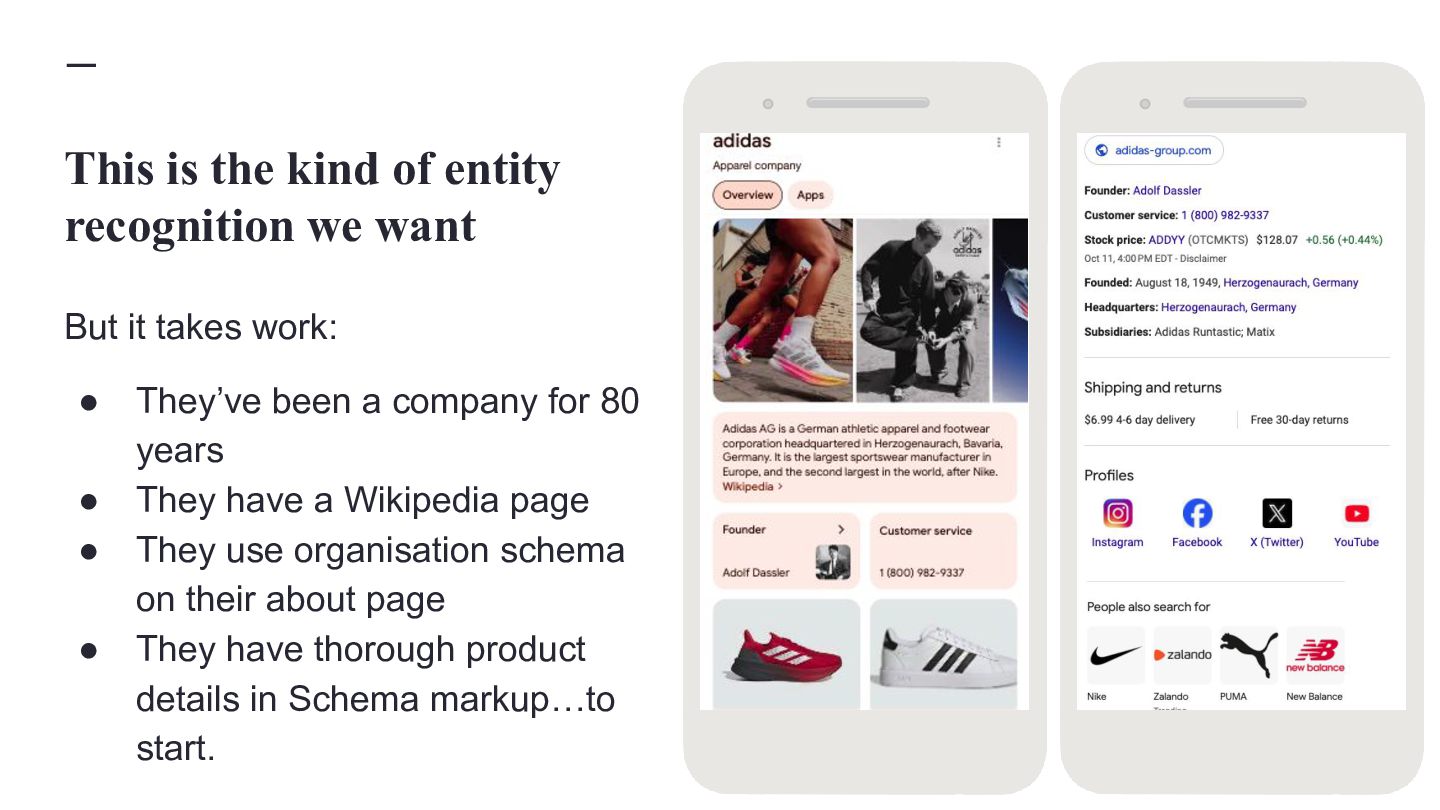{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}