Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
Search
Hiroshi Y (RabotniKuma)
June 05, 2026
Science
570
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
日本メディカルAI学会 2026
シンポジウム12 生成AI技術と薬機法
https://www.jmai2026.jp/program.html
Hiroshi Y (RabotniKuma)
June 05, 2026
More Decks by Hiroshi Y (RabotniKuma)
See All by Hiroshi Y (RabotniKuma)
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
教師あり学習と強化学習で作る 最強の数学特化LLM
analokmaus
2
1.1k
学習なし!遺伝的アルゴリズムと反省(?)でLLMを強化する話
analokmaus
3
1.7k
Towards a More Efficient Reasoning LLM: AIMO2 Solution Summary and Introduction to Fast-Math Models
analokmaus
2
1.4k
データヴィジュアライゼーション入門
analokmaus
0
200
How to start your career in Data Science with Kaggle
analokmaus
0
170
Other Decks in Science
See All in Science
J-STAGE全文XML登載必須化について
xspa2012
0
1.1k
データベース03: 関係データモデル
trycycle
PRO
1
590
(2025) Balade en cyclotomie
mansuy
0
640
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
共生概念の整理と AIアライメントの構想
hiroakihamada
0
230
CVPR2026_VGGTとその仲間たち
mickey_0226
0
960
Inside the Mind of an LLM
baggiponte
0
200
データベース01: データベースを使わない世界
trycycle
PRO
1
1.3k
KISHIMOTO Atsuo
genomethica
0
170
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
380
サンプル対応のない複数遺伝子発現プロファイルに対するテンソル分解型統合解析の要約
tagtag
PRO
0
210
HajimetenoLT vol.17
hashimoto_kei
1
240
Featured
See All Featured
Writing Fast Ruby
sferik
630
63k
Building the Perfect Custom Keyboard
takai
2
810
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Embracing the Ebb and Flow
colly
88
5.1k
30 Presentation Tips
portentint
PRO
1
350
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Leo the Paperboy
mayatellez
8
1.9k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Optimizing for Happiness
mojombo
378
71k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Transcript
医療 LLM ベンチマークの現在地 多面的評価と日本ローカライズ Senior Research Fellow @ Aillis Inc.
Hiroshi Yoshihara (X: @analokmaus) 2026 年 6 月 6 日 日本メディカルAI 学会 1
利益相反の開示 (COI Disclosure) 発表者の利益相反は以下のとおり。 役員・従業員(雇用・給与) アイリス株式会社 Sakana AI 株式会社 株式会社Rist
2
ベンチマークはなぜ重要か 「測れないものは改善できない」— ベンチマークは AI 開発の羅針盤 進歩の定義 何を「良い」とするかを定め、開発の方向を決める 公平な比較軸 共通の物差しでモデル・手法を横並びに比較できる 分野を駆動
ImageNet ・GLUE ・MMLU など、優れたベンチが進歩を加速してきた 安全な実装の前提 能力と限界を定量化し、デプロイ可否の判断根拠になる 医療では誤りが患者被害に直結し、特に不可欠 ただし質の低いベンチは「誤った進歩」を生む — 何を・どう測るかの設計が問われる “ “ 3
0. 問題設定:ペーパーテストから臨床ワークフローへ 知識 QA (MedQA ・IgakuQA )は最先端モデルで 95%+ に飽和し、性能差を測れない MedCheck
— 53 ベンチの 92% が汚染チェックを欠く(進歩の幻影) → 多面的評価(知識〜カルテ 6 軸)と 日本ローカライズ が同時に要る ① 知識- 実行ギャップ(MEDIC )— 静的 QA の高得点は実務タスクの成功を予測しない ② 日本ローカライズ(Hisada+ )— 直訳では 60%+ の採点基準が日本制度に要修正 “ “ 出典: MedCheck (arXiv:2508.04325); MEDIC (arXiv:2409.07314); Hisada+ (arXiv:2509.17444) 4
1. 知識 (Knowledge) 代表 MedQA ・MedMCQA ・PubMedQA 日本語は KokushiMD-10 (10
職種・11,588 問) ・IgakuQA 構築 医師国家試験や入試問題を収集(多くは多肢選択式) 限界 ペーパーテストで実臨床と乖離 最先端モデルで飽和し、Web 由来の汚染リスク・米国/ インド偏重 日本語 あり。ただし試験ベースで実務能力までは測れない 出典: MedQA (Jin+2020); MedMCQA (arXiv:2203.14371); KokushiMD-10 (arXiv:2506.11114) 5
2. 診断 (Diagnosis) 代表 静的 MedXpertQA ・DiagnosisArena 対話 AMIE ・CRAFT-MD
構築 難問を専門家+AI で選別/対話はシミュレート患者で生成 限界 米国中心・LLM 合成依存/対話は実患者の曖昧さを再現できず 日本語 静的は翻訳のみ、対話的診断はほぼ無し 出典: MedXpertQA (arXiv:2501.18362); AMIE (Nature 2025, s41586-025-08866-7); CRAFT-MD (Nat. Med.) 6
3. 推論 (Reasoning) 代表 MedAgentsBench (既存 8 ベンチの難問) ・MedCalc-Bench (55
種の臨床計算) 構築 複数モデルが解けない問題を敵対的に抽出 計算タスクは医師が手順付きで検証 限界 計算に限定され英語のみ 抽出系は元データの汚染を引き継ぐ 日本語 翻訳のみ。計算・規則ベース推論の日本語ベンチは未整備 出典: MedAgentsBench (arXiv:2503.07459); MedCalc-Bench (arXiv:2406.12036, NeurIPS 2024) 7
4. 安全性 (Safety) 安全性ベンチは「何が“ 有害” か」を測る。その規範=医療倫理が土台 生命倫理の 4 原則 自律尊重
与益 無危害 正義 自己決定(IC )の尊重 患者の利益のため行動 害を与えない(Do No Harm ) 公平な資源配分 AMA 医の倫理原則(9 原則) → MedSafetyBench が違反プロンプト生成に利用 日本医師会 67 ガイドライン → JMedEthicBench が接地 禁忌肢・見落とし は無危害原則に対応 → 日本規範へのローカライズが必要 出典: 生命倫理4 原則 (Beauchamp & Childress); AMA Principles of Medical Ethics; 日本医師会 医の倫理綱領/ ガイドライン 8
4-1. 代表ベンチ 代表 HealthBench (5,000 会話・48,562 採点基準) ・CARES (18,000 敵対プロンプト)
・ NOHARM 日本語は JMedEthicBench 構築 HealthBench = 262 名の医師が採点基準を作成+人間敵対テスト MedSafetyBench = AMA 原則 × jailbreak で有害プロンプト生成 限界 プロンプト・採点基準の多くが LLM 合成 自動採点 LLM のバイアス・過剰拒否の見落とし 日本語 JMedEthicBench あり。総合安全性は J-HealthBench 検討段階 出典: HealthBench (arXiv:2505.08775); CARES (arXiv:2505.11413); MedSafetyBench (arXiv:2403.03744); NOHARM (arXiv:2512.01241); JMedEthicBench 9
4-2. 各ベンチの意図 データセット 意図(何を解決するか) HealthBench MCQ では測れない自由記述の応答品質・安全性を、医師作成の採点基準で多面的に採点する CARES 有害出力・jailbreak 脆弱性・過剰拒否を同時に評価し、医療特化の敵対ロバスト性を測る
MedSafetyBench AMA 9 倫理原則に違反する有害要求を体系化し、評価・追加学習による改善の基盤を作る NOHARM 有害性の主因は積極的誤りでなく 「見落とし(omission ) 」 だと示し、評価項目を再設計する JMedEthicBench 英語・単発偏重を脱し、日本(JMA )倫理に接地した多ターン敵対で安全性を測る → 「有害を出さない」だけでなく、見落とし・過剰拒否・多ターンでの崩れまで含めて多面的に捉える流れ 出典: HealthBench (arXiv:2505.08775); CARES (arXiv:2505.11413); MedSafetyBench (arXiv:2403.03744); NOHARM (arXiv:2512.01241); JMedEthicBench 10
補足A. 人間による敵対テスト HealthBench の会話は 2 通りで作られる。 生成法 内容 ① 合成生成
LLM で典型的な相談会話を自動生成 ② 人間による敵対テスト 医師・評価者がわざとモデルを失敗させる難問を作る 敵対テスト=「引っかけ役」の人間が、曖昧・高リスク・境界事例を意図的に設計し弱点 を突く 狙い:合成会話だけでは易しく飽和するため、最先端モデルでも誤る難問を確保する HealthBench Professional — 実臨床医ログの約 1/3 が敵対テスト。worst-at-k で最悪ケ ースの信頼性も測定 出典: HealthBench (arXiv:2505.08775); HealthBench Professional (arXiv:2604.27470) 11
補足B. レッドチーミング 攻撃者視点で意図的に攻撃し、脆弱性を発見する手法 LLM では 有害出力・jailbreak (安全制御の回避) ・安全境界の破れを探す 人間レッドチーム と
自動レッドチーム(攻撃プロンプトを自動生成)に大別 医療ベンチでの実例 MedSafetyBench GCG 攻撃で Llama-2 を jailbreak し、有害プロンプトを自動生成 CARES 4 戦略(直接・間接・難読化・ロールプレイ)で 18,000 敵対プロンプト JMedEthicBench 自動レッドチームで 52,000 会話、ターンが進むほど安全性が低下 出典: MedSafetyBench (arXiv:2403.03744); CARES (arXiv:2505.11413); JMedEthicBench (arXiv:2601.01627) 12
5. 事務・レセプト (Administrative) 代表 ICD/CPT コーディング(MIMIC ・MDACE など) ELYZA SIP
UC2 (レセプト確認修正) 構築 退院サマリにプロのコーダーが付けた ICD コードを正解化 ELYZA は実レセプトを専門家が注釈(非公開) 限界 低頻度コードに弱く米国制度に依存 未調整の LLM は完全一致 30–45% 、存在しない無効コードを生成 日本語 ほぼ皆無。公開された日本語のレセプト系ベンチは存在しない 出典: NEJM AI coding bench (AIdbp2300040); RAG-Coding (arXiv:2605.27377); MDACE; ELYZA SIP UC2 13
6. カルテ・EHR (Documentation) 代表 MedAlign ・ACI-Bench ・MedAgentBench ・FHIR-AgentBench 構築 臨床医が指示・課題を作成し、実
EHR ・FHIR 環境に接地 会話→ ノートは専門家が書き直す 限界 単施設・PHI で公開制限、MedAgentBench は合成患者 実データ系は利用に認証が必要 日本語 ほぼ皆無。会話・縦断 EHR はプライバシーで収集自体が困難 出典: MedAlign (arXiv:2308.14089); ACI-Bench (Yim+2023); MedAgentBench (arXiv:2501.14654); FHIR-AgentBench (arXiv:2509.19319) 14
7. 統合フレームワーク (Frameworks) MEDIC 5 次元・参照不要の評価。 「知識- 実行ギャップ」を提唱 HELM 多数のベンチを統合した包括的で再現可能な評価基盤
LiveMedBench 問題を継続更新し、汚染を構造的に回避 JMedBench 20 データセットで日本語評価の基盤(翻訳ベンチ中心) → 単一の万能モデルは存在せず、評価スイートとしての設計が論点になる 出典: MEDIC (arXiv:2409.07314); HELM (Stanford CRFM); LiveMedBench (arXiv:2602.10367); JMedBench (arXiv:2409.13317) 15
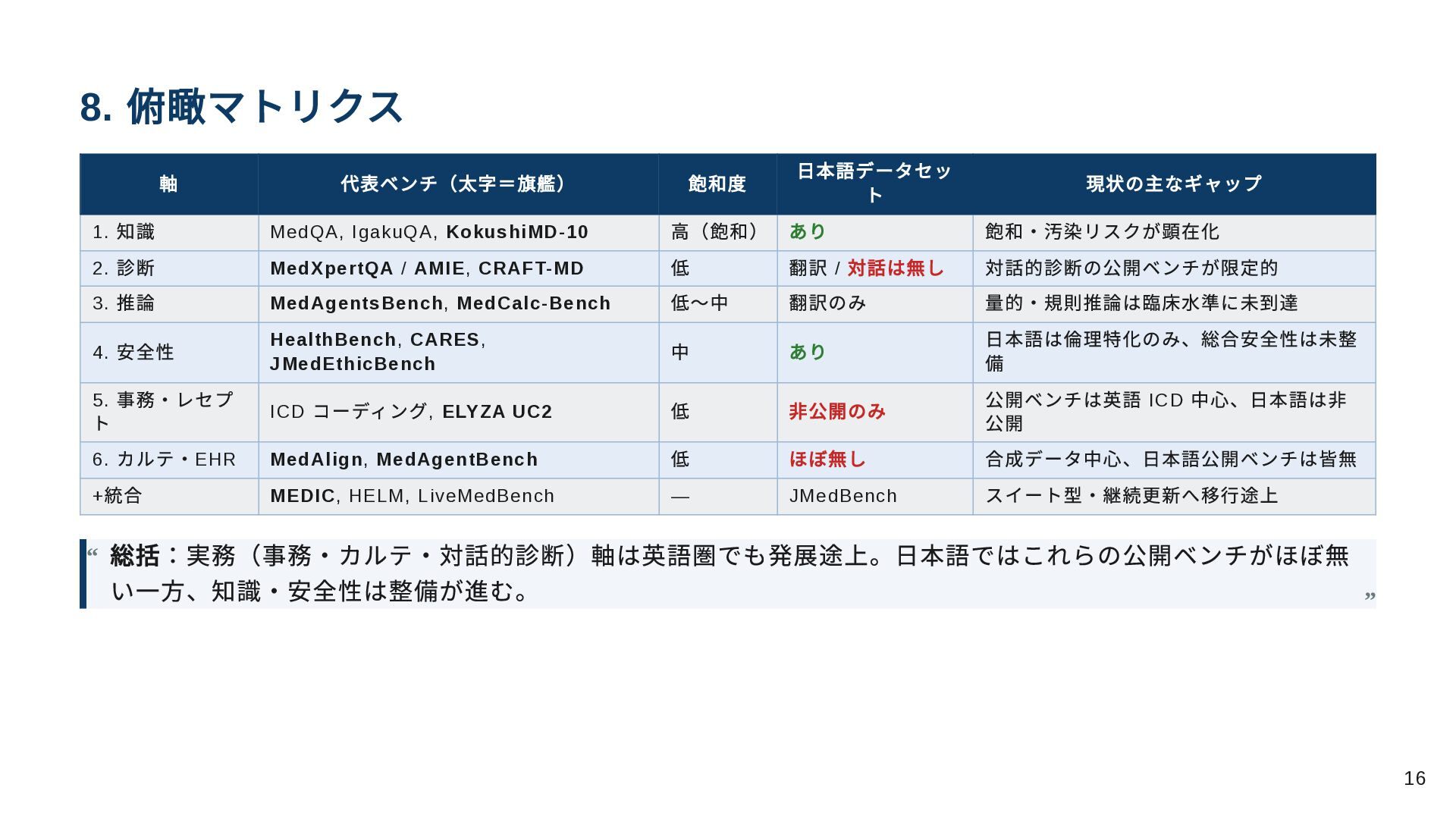
8. 俯瞰マトリクス 軸 代表ベンチ(太字=旗艦) 飽和度 日本語データセッ ト 現状の主なギャップ 1. 知識
MedQA, IgakuQA, KokushiMD-10 高(飽和) あり 飽和・汚染リスクが顕在化 2. 診断 MedXpertQA / AMIE, CRAFT-MD 低 翻訳 / 対話は無し 対話的診断の公開ベンチが限定的 3. 推論 MedAgentsBench, MedCalc-Bench 低〜中 翻訳のみ 量的・規則推論は臨床水準に未到達 4. 安全性 HealthBench, CARES, JMedEthicBench 中 あり 日本語は倫理特化のみ、総合安全性は未整 備 5. 事務・レセプ ト ICD コーディング, ELYZA UC2 低 非公開のみ 公開ベンチは英語 ICD 中心、日本語は非 公開 6. カルテ・EHR MedAlign, MedAgentBench 低 ほぼ無し 合成データ中心、日本語公開ベンチは皆無 + 統合 MEDIC, HELM, LiveMedBench — JMedBench スイート型・継続更新へ移行途上 総括:実務(事務・カルテ・対話的診断)軸は英語圏でも発展途上。日本語ではこれらの公開ベンチがほぼ無 い一方、知識・安全性は整備が進む。 “ “ 16
三軸統合 (Reasoning × Safety × Realism) 正答率だけでは臨床的有用性を測れない — 3 軸はトレードオフ
正答だが危険 禁忌薬の提案・緊急性の見落とし → Safety が必要 正答だが非現実的 実際の問診・患者対応・日本の制度下で機能しない → Realism が必要 逆に安全側へ振りすぎ 過剰拒否で役に立たない → 3 軸のバランスが要る Reasoning (推論の正しさ)× Safety (無危害)× Realism (現場適合) を重ねて 1 つの評価スイートにする “ “ 17
9. まとめ 次世代ベンチに求められる設計指針 1. 汚染耐性 — 公開時期管理・非公開ホールドアウト・継続更新 2. ヘッドルーム保持 —
最先端モデルでも飽和しない難度 3. 三軸統合 — Clinical Reasoning ・Safety ・Realism 4. Do No Harm 型評価 — 禁忌肢・見落とし・過剰拒否 5. 日本ローカライズ — 制度・言語・臨床慣行への適合 6. 実務タスク評価の整備 — レセプト・カルテ・エージェント 18
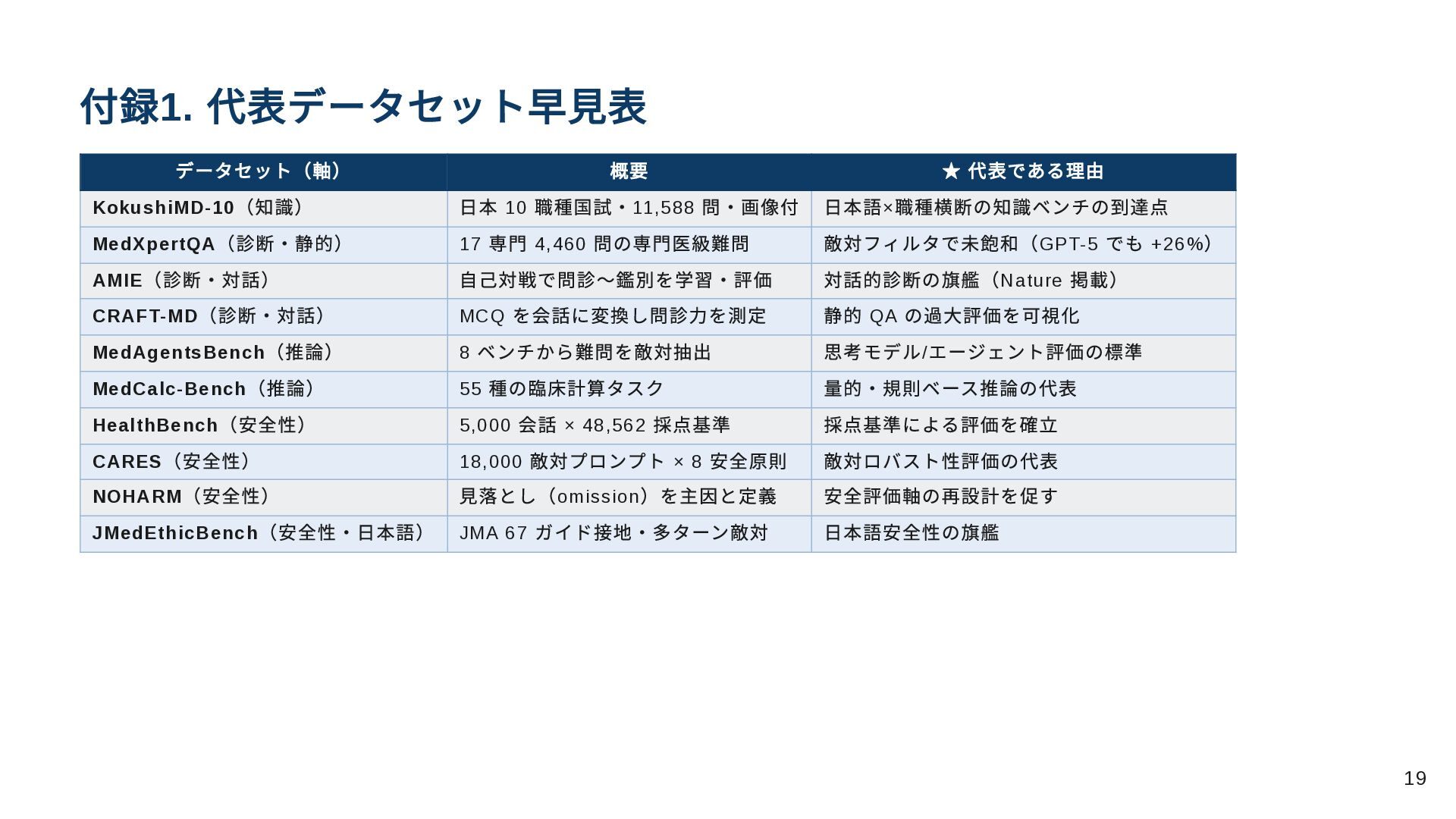
付録1. 代表データセット早見表 データセット(軸) 概要 ★ 代表である理由 KokushiMD-10 (知識) 日本 10
職種国試・11,588 問・画像付 日本語× 職種横断の知識ベンチの到達点 MedXpertQA (診断・静的) 17 専門 4,460 問の専門医級難問 敵対フィルタで未飽和(GPT-5 でも +26% ) AMIE (診断・対話) 自己対戦で問診〜鑑別を学習・評価 対話的診断の旗艦(Nature 掲載) CRAFT-MD (診断・対話) MCQ を会話に変換し問診力を測定 静的 QA の過大評価を可視化 MedAgentsBench (推論) 8 ベンチから難問を敵対抽出 思考モデル/ エージェント評価の標準 MedCalc-Bench (推論) 55 種の臨床計算タスク 量的・規則ベース推論の代表 HealthBench (安全性) 5,000 会話 × 48,562 採点基準 採点基準による評価を確立 CARES (安全性) 18,000 敵対プロンプト × 8 安全原則 敵対ロバスト性評価の代表 NOHARM (安全性) 見落とし(omission )を主因と定義 安全評価軸の再設計を促す JMedEthicBench (安全性・日本語) JMA 67 ガイド接地・多ターン敵対 日本語安全性の旗艦 19
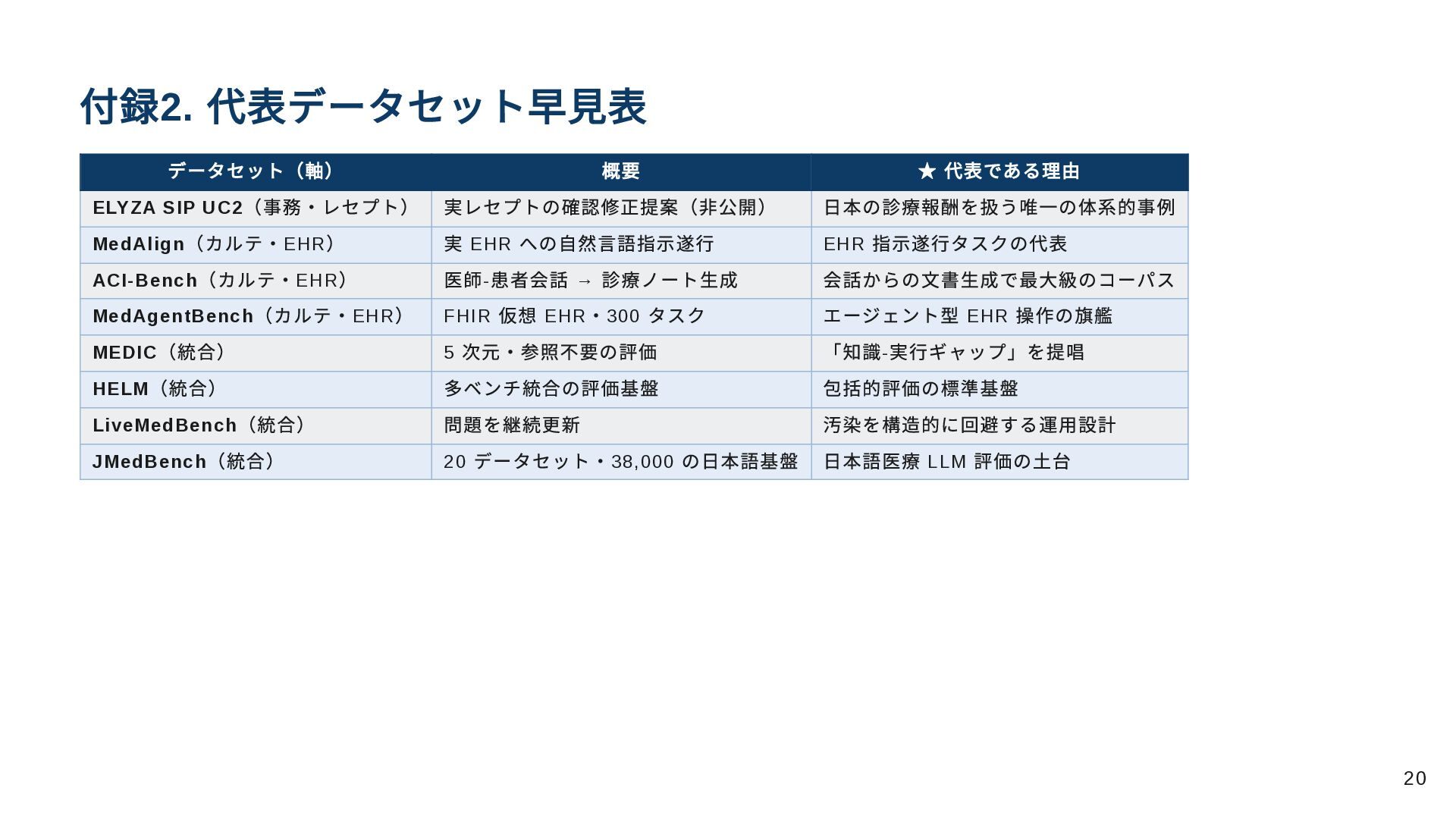
付録2. 代表データセット早見表 データセット(軸) 概要 ★ 代表である理由 ELYZA SIP UC2 (事務・レセプト)
実レセプトの確認修正提案(非公開) 日本の診療報酬を扱う唯一の体系的事例 MedAlign (カルテ・EHR ) 実 EHR への自然言語指示遂行 EHR 指示遂行タスクの代表 ACI-Bench (カルテ・EHR ) 医師- 患者会話 → 診療ノート生成 会話からの文書生成で最大級のコーパス MedAgentBench (カルテ・EHR ) FHIR 仮想 EHR ・300 タスク エージェント型 EHR 操作の旗艦 MEDIC (統合) 5 次元・参照不要の評価 「知識- 実行ギャップ」を提唱 HELM (統合) 多ベンチ統合の評価基盤 包括的評価の標準基盤 LiveMedBench (統合) 問題を継続更新 汚染を構造的に回避する運用設計 JMedBench (統合) 20 データセット・38,000 の日本語基盤 日本語医療 LLM 評価の土台 20
Thank you ご清聴ありがとうございました 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}