Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
project yamcha phase 1
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
andmohiko
November 18, 2018
Programming
120
1
Share
project yamcha phase 1
学生の一行プロフィールをベクトル化して類似度の高いものを探す
andmohiko
November 18, 2018
More Decks by andmohiko
See All by andmohiko
Mantine + React Hook Form + Zod でフォームをつくる
andmohiko
0
750
文章のベクトル化
andmohiko
0
440
Predicting categories of news articles
andmohiko
0
140
kobachi presentation
andmohiko
0
220
Other Decks in Programming
See All in Programming
AWSコミュニティ活動は顧客のクラウド推進に効くのか / Do AWS community activities help customers adopt the cloud?
seike460
PRO
0
160
AIエージェントで業務改善してみた
taku271
0
550
2026-04-15 Spring IO - I Can See Clearly Now
jonatan_ivanov
1
140
t *testing.T は どこからやってくるの?
otakakot
1
840
実践CRDT
tamadeveloper
0
610
Liberating Ruby's Parser from Lexer Hacks
ydah
2
2.3k
GitHubCopilotCLIをはじめよう.pdf
htkym
0
300
AI時代のPhpStorm最新事情 #phpcon_odawara
yusuke
0
240
煩雑なSkills管理をSoC(関心の分離)により解決する――関心を分離し、プロンプトを部品として育てるためのOSSを作った話 / Solving Complex Skills Management Through SoC (Separation of Concerns)
nrslib
4
1.1k
JOAI2026 1st solution - heron0519 -
heron0519
0
160
第3木曜LT会 #28
tinykitten
PRO
0
120
AIベース静的検査器の偽陽性率を抑える工夫3選
orgachem
PRO
4
380
Featured
See All Featured
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
22k
Bash Introduction
62gerente
615
210k
Writing Fast Ruby
sferik
630
63k
What does AI have to do with Human Rights?
axbom
PRO
1
2.1k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.2k
How to Think Like a Performance Engineer
csswizardry
28
2.6k
Scaling GitHub
holman
464
140k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
130
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
250
How to Ace a Technical Interview
jacobian
281
24k
Producing Creativity
orderedlist
PRO
348
40k
The Pragmatic Product Professional
lauravandoore
37
7.2k
Transcript
やみつき飲茶な熱帯夜 Project yamcha phase 1 2018/09/11 いとぅー
あうとらいん • 目的 • 理論 • 手法 • 結果 •
考察 • 今後の展望
目的 人事が今までにスカウトを打った学生と似ている学生をキャッチコ ピーを使って探し出す。 つまりキャッチコピーが似ている人を探し当てたい。
目的 人事が今までにスカウトを打った学生と似ている学生をキャッチコ ピーを使って探し出す。 つまりキャッチコピーが似ている人を探し当てたい。 自然言語において「似ている」とは 数学的にどういうことか?
自然言語において「似ている」とは、 文章をベクトルに変換し、そのベクトル同士の類似度を測る。 doc2vecという手法を使うが、 doc2vecについて説明するためにまずword2vecについて説明する。 理論
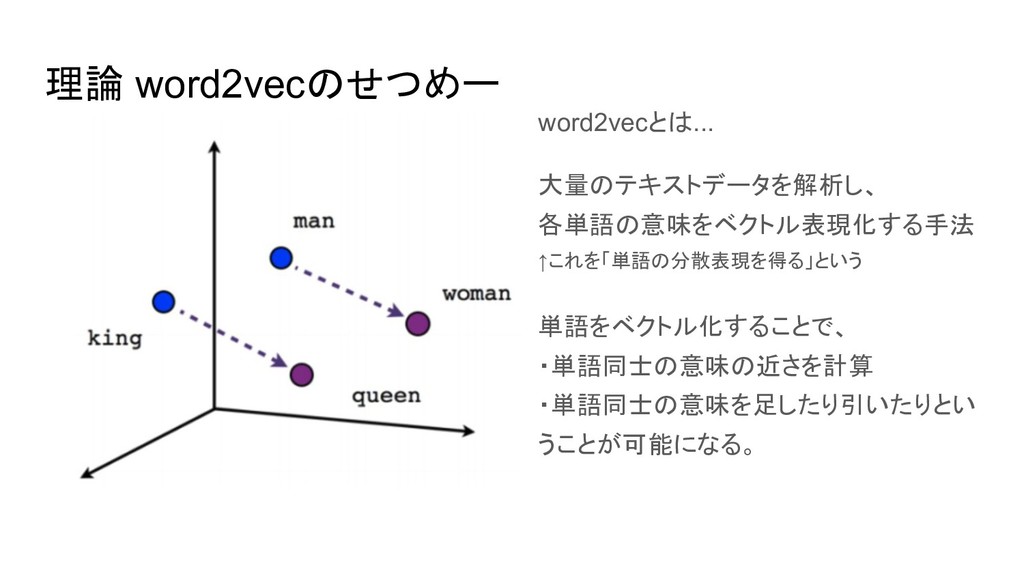
理論 word2vecのせつめー word2vecとは... 大量のテキストデータを解析し、 各単語の意味をベクトル表現化する手法 ↑これを「単語の分散表現を得る」という 単語をベクトル化することで、 ・単語同士の意味の近さを計算 ・単語同士の意味を足したり引いたりとい うことが可能になる。
理論 word2vecのせつめー word2vecとは... 大量のテキストデータを解析し、 各単語の意味をベクトル表現化する手法 ↑これを「単語の分散表現を得る」という 単語をベクトル化することで、 ・単語同士の意味の近さを計算 ・単語同士の意味を足したり引いたりとい うことが可能になる。
king - man + woman = queen となる!!!
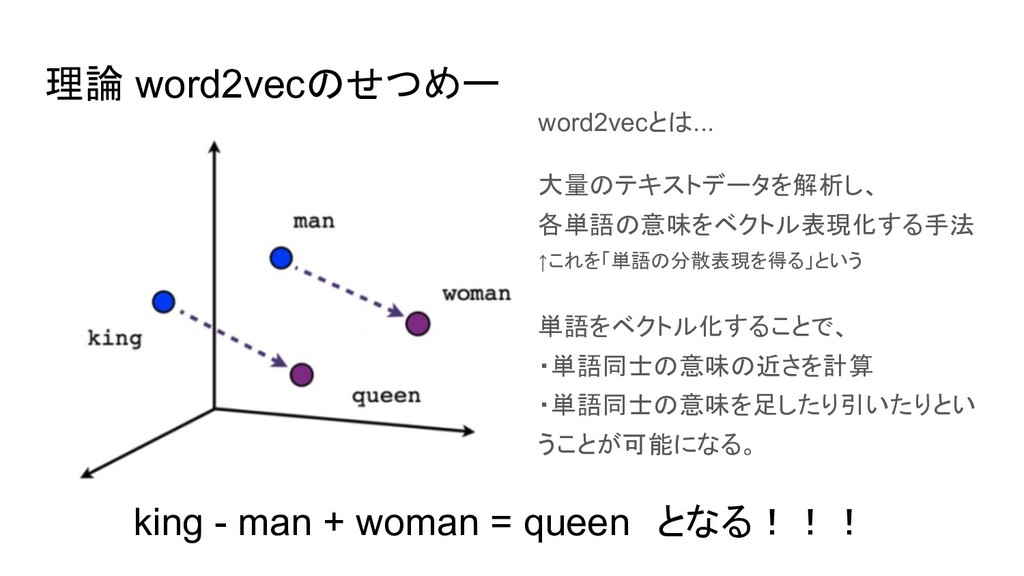
理論 word2vecのせつめー word2vecとは... 大量のテキストデータを解析し、 各単語の意味をベクトル表現化する手法 ←これを「単語の分散表現を得る」という 単語をベクトル化することで、 ・単語同士の意味の近さを計算 ・単語同士の意味を足したり引いたりとい うことが可能になる。
king - man + woman = queen となる!!! word2vecを文章レベルに 拡張したものがdoc2vecである
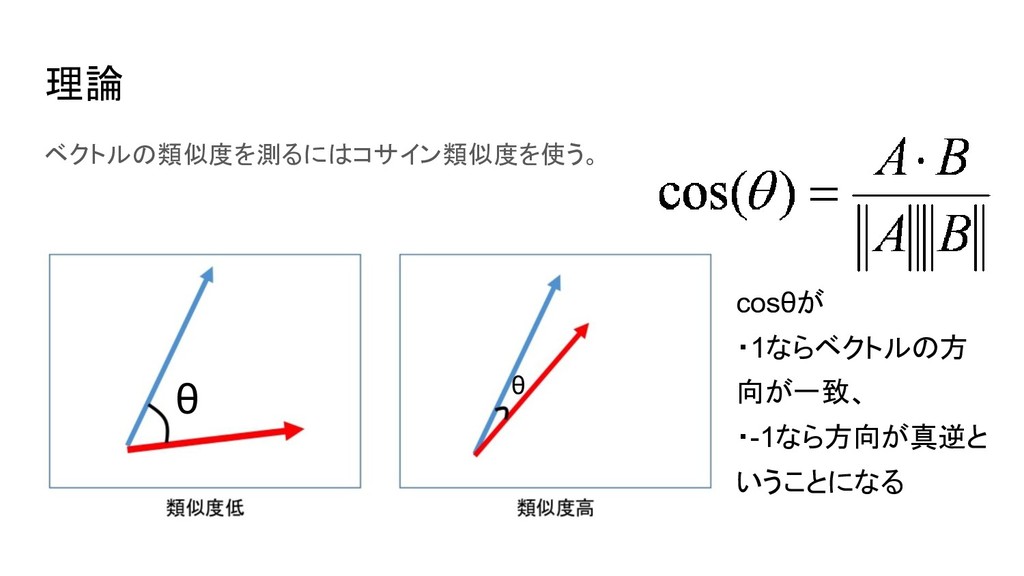
理論 ベクトルの類似度を測るにはコサイン類似度を使う。 cosθが ・1ならベクトルの方 向が一致、 ・-1なら方向が真逆と いうことになる θ θ
手法 • 使用したデータ TRUNKのレジュメに記入されたユーザーのキャッチコピーと自己紹介 • データセットの作り方 キャッチコピーと自己紹介をただ学習させるのか、 同じ文脈としてstringをくっつくる方がよいのか。 • 特徴量の作り方
全ての単語を使用するか、 名詞のみ取り出すか、 名詞と動詞を取り出すか。
結果 jupyter notebookをご覧ください
結果 • 単語は名詞と動詞と形容詞を取り出して使うのがよい • データセットはシンプルにキャッチコピーと自己紹介を学習させるのがよい
考察 & 反省まとめ • 「似ている」とされたキャッチコピーは「なんとなく似てるかも...?」「うーん」「あー」く らいなものが取ってこれた。 →テキストデータが増えればここの精度は上がるはず • 逆に「似ていない」とされたキャッチコピーはしっかり似ていない 明らかに「ちげーな」って思うやつははじくことができた
• データ整形の時間を辞書追加の時間にすればよかった
• 「なんとなく近いかも」くらいなものを取り出すことに成功したので、 現状のものをAPI化してプロダクトに埋め込む • API化に向けてコードを書き直す • それに伴って発生する課題 ◦ 新しいユーザーが追加される →学習し直すタイミング
◦ キャッチコピーや自己紹介が更新された時の旧文章の扱い 今後の展望と課題
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}