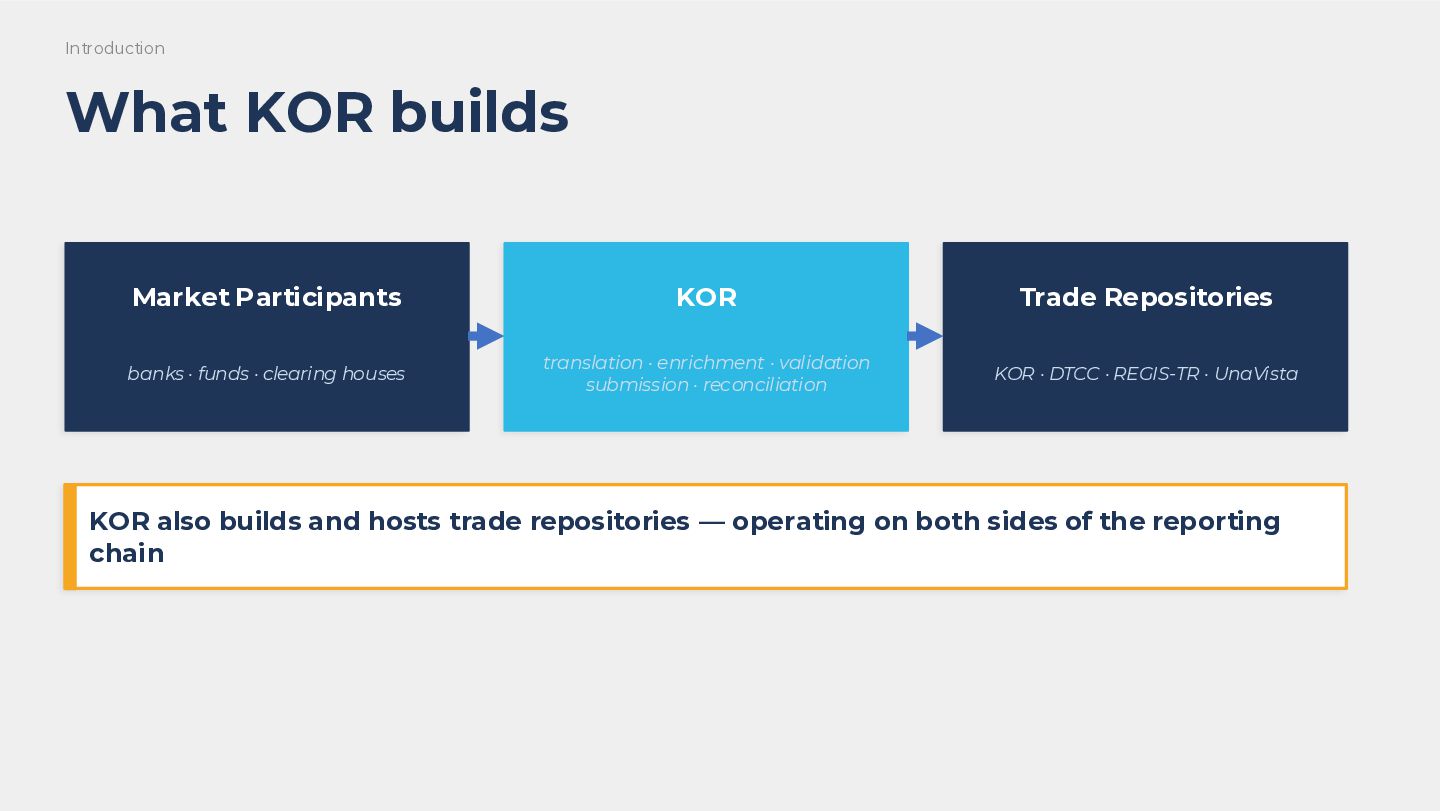
Kafka Streams is a powerful choice for stateful stream processing: a library, not a cluster, that runs alongside your application and handles exactly-once semantics, fault tolerance, and partition-local state out of the box. At KOR, we build financial-grade trade reporting infrastructure on top of it. That means regulatory deadlines, SLA requirements, and zero tolerance for data loss. We pushed Kafka Streams hard.
This talk is about what we found.
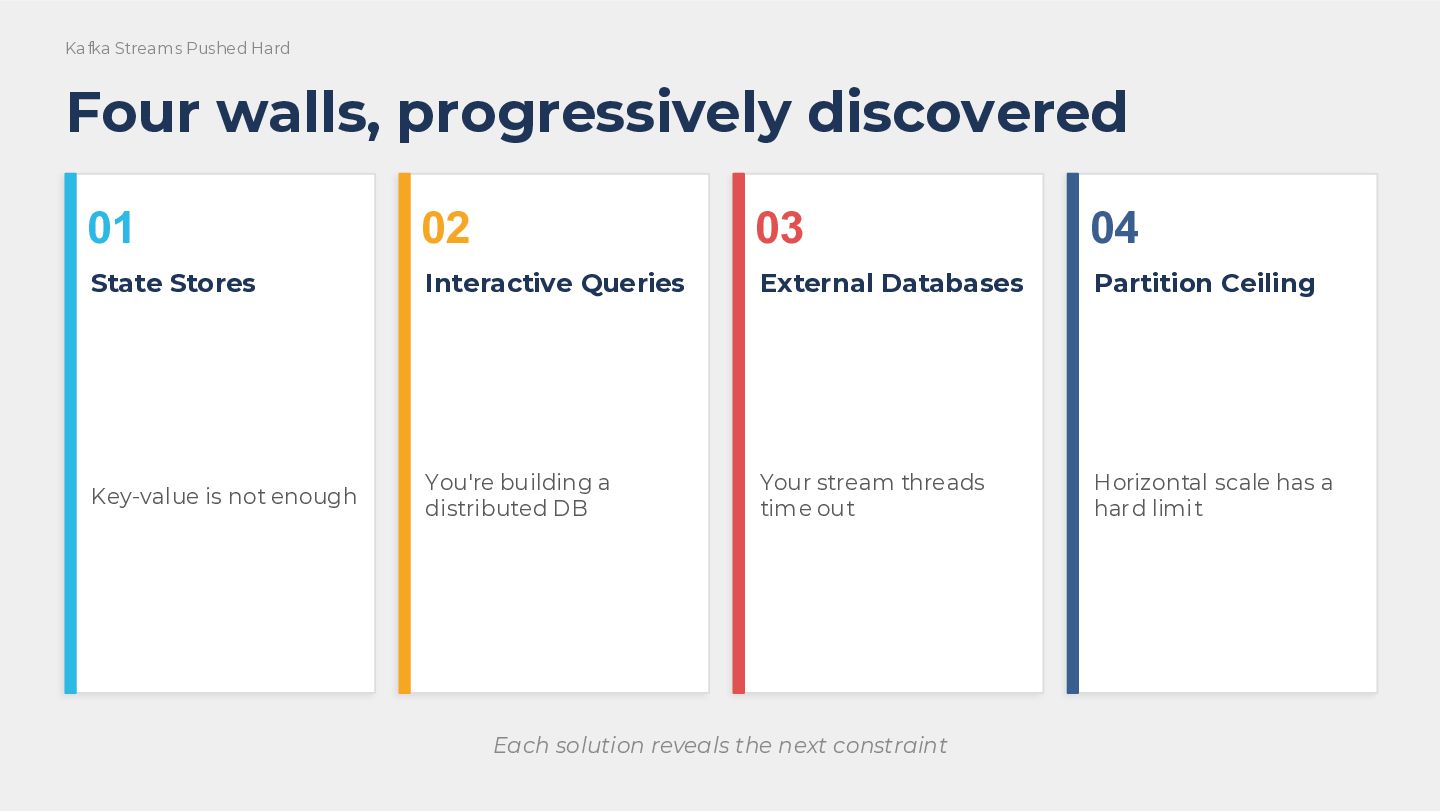
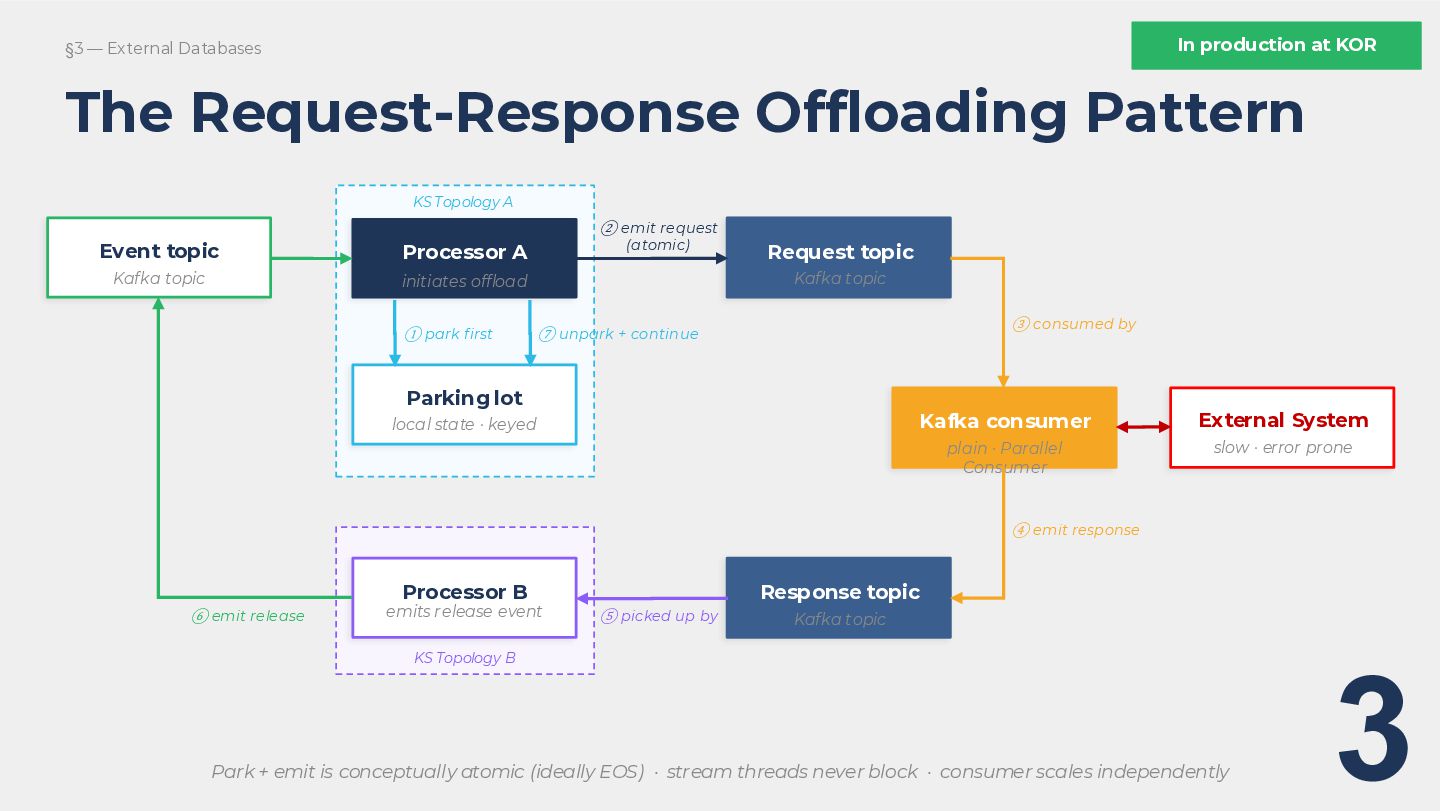
We will walk through four walls we hit in production. Not theoretical limitations, but real engineering decisions with real consequences. First, what happens when your access patterns outgrow key-value stores, and why plugging in a custom document database is a much larger commitment than the API suggests. Second, why Interactive Queries can lead you to accidentally build a distributed database inside your application. Third, why making external calls from within a stream processor will eventually crash your application, and the request-response offloading pattern with a parking lot that solves it. Fourth, the partition ceiling, the hard limit on Kafka Streams parallelism, what your options are when you hit it, and why we studied Flink seriously but chose not to run it.
Each section covers a constraint, the wall it created, and the exit we found or considered. Some exits are clean. Some are costly. All of them are honest.
If you are running Kafka Streams in production, or planning to, this talk will save you some expensive discoveries.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You www.korfinancial.com Andreas Evers · KOR [email protected]](https://files.speakerdeck.com/presentations/5de64a99813644f0adb18ac90b26bdc9/slide_17.jpg){kind=link}