References 3-4.2 Why do we need descriptive statistics? Descriptive statistics provide a simple summary of a sample. Such statistics may be either quantitative (i.e., summary statistics), or visual (i.e., simple to understand graphs). There is demand for descriptive statistics: A newspaper may be interested in the average temperature over the past 30 years, to explain to its readers why this Summer has been exceptionally cold. A senior in college may be interested in the average salary of new college graduates, to have an idea of how much she will make once she graduates. An investor may be interested in the historical returns of a mutual find that invests in emerging market equities, to make an informed investment decision. In this session, we give an overview of how one can use Stata to produce summary statistics and graphs.
References 3-4.3 Summary statistics Measures of central tendency These attempt to describe a set of data with a single value, by identifying the central position of the data. The most common measure of central tendency is the mean. x = n i=1 xi n (1) where xi in the ith data point in a sample of n data points. Others include median, and mode (the most frequently occurring value). Sorting the data from the lowest value to the highest value, the median is defined as Median = n+1 2 th value if n is odd n 2 th value + n 2 + 1 th value 2 if n is even (2) Each of these measures may be more appropriate depending on the distribution of a variable.
References 3-4.4 Summary statistics Measures of dispersion These tell us how data in a sample is spread out, or dispersed about the mean. Some common measures of dispersion include the range, the mean absolute deviation (MAD), the variance and the standard deviation. The range is computed as the maximum value less the minimum value in the sample. The sample- MAD, variance, and standard deviation are computed as follows: Sample MAD = 1 n − 1 n i=1 |xi − ¯ x| (3) Sample variance = s2 = 1 n − 1 n i=1 (xi − ¯ x)2 (4) Sample std. deviation = s = 1 n − 1 n i=1 (xi − ¯ x)2 (5)
References 3-4.5 Summary statistics Skewness and kurtosis Skewness is a measure of the asymmetry of the probability distribution of a random variable, and kurtosis measures whether the data is peaked or flat relative to a normal distribution. The normal distribution has a skewness of zero and a kurtosis of 3. Sample skewness = n (n − 1)(n − 2) n i=1 xi − ¯ x s 3 (6) where s is the sample standard deviation. The sample kurtosis is defined as: n(n + 1) (n − 1)(n − 2)(n − 3) n i=1 xi − ¯ x s 4 − 3(n − 1)2 (n − 2)(n − 3) (7) It should be noted that based on this formula, a perfect normal distribtion will have a kurtosis of zero.
References 3-4.6 Summary statistics in Stata∗ ∗Commands in blue font can be entered directly into Stata. Ensure that there are no line breaks for long commands. The Stata dataset census.dta can be accessed by typing sysuse census.dta on the Stata command window, and contains the following variables: Variable Description state State state2 Two-letter state abbreviation region Census region pop Population poplt5 Pop, < 5 years pop5_17 Pop, 5 to 17 years pop18p Pop, 18 and older pop65p Pop, 65 and older popurban Urban population medage Median age death Number of deaths marriage Number of marriages divorce Number of divorces
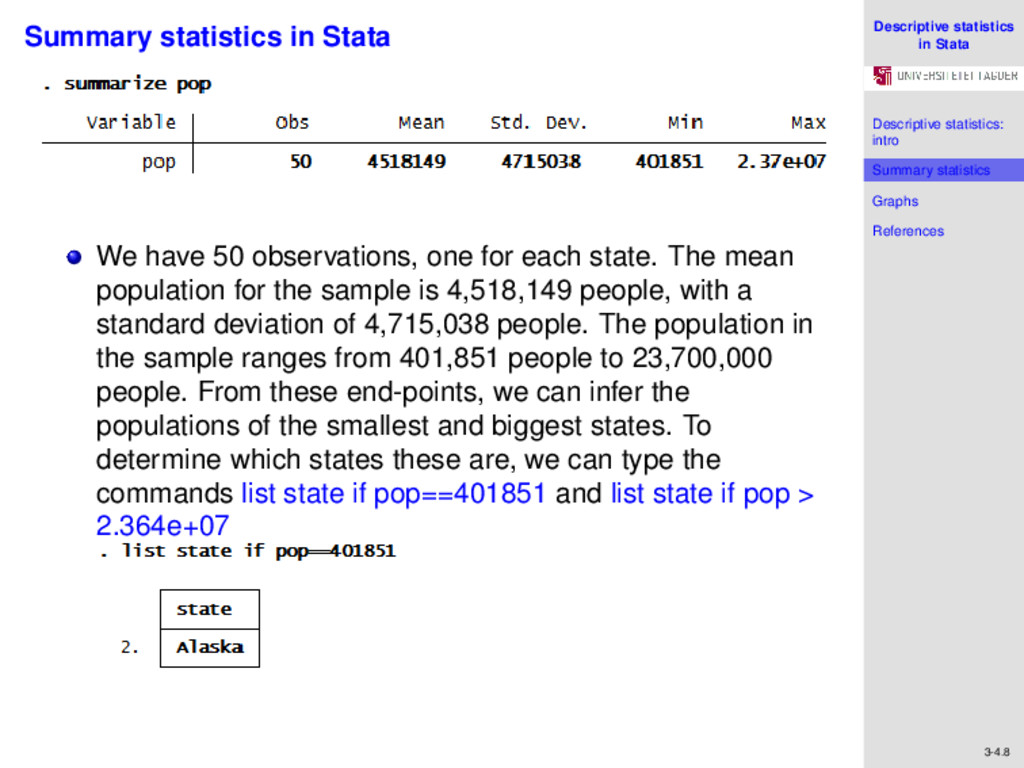
References 3-4.7 Summary statistics in Stata The dataset contains census data for regions of the US. By typing the command describe into the command window, we can see that the variable region has the value label “cenreg". Therefore, to see a summary of the regions, we type the command label list cenreg and obtain the following output We are interested in obtaining summary statistics for the variable pop in the sample. The Stata command summarize calculates and displays a variety of univariate summary statistics. To summarize the population variable, we type the command summarize pop and obtain the following output
References 3-4.8 Summary statistics in Stata We have 50 observations, one for each state. The mean population for the sample is 4,518,149 people, with a standard deviation of 4,715,038 people. The population in the sample ranges from 401,851 people to 23,700,000 people. From these end-points, we can infer the populations of the smallest and biggest states. To determine which states these are, we can type the commands list state if pop==401851 and list state if pop > 2.364e+07
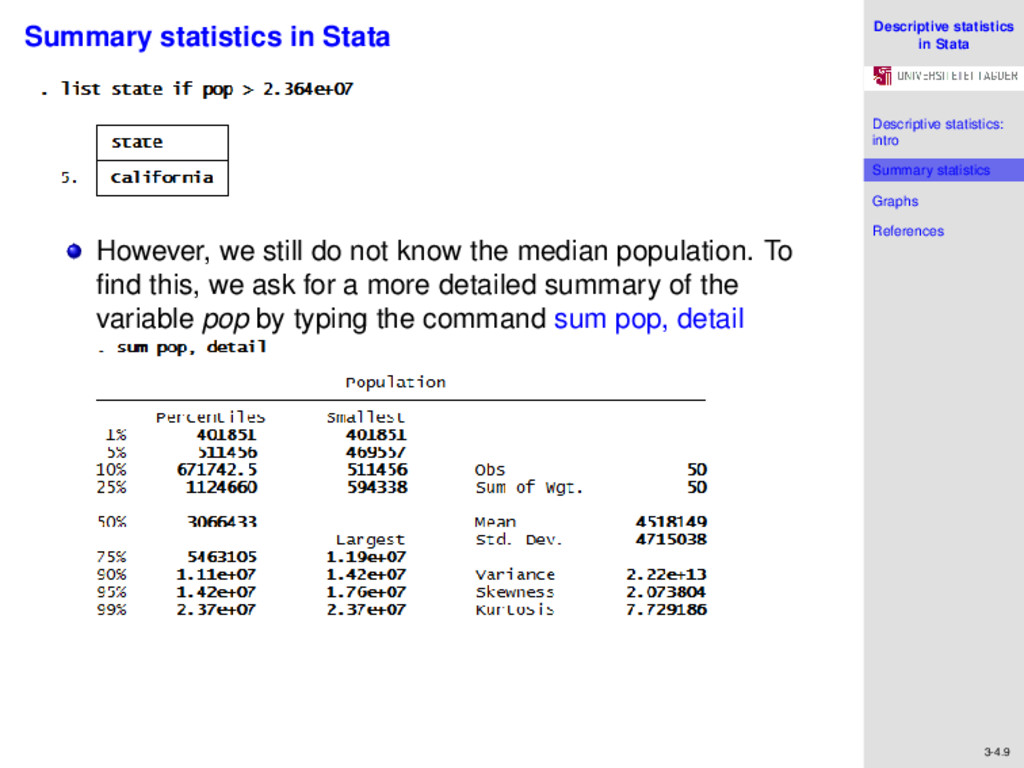
References 3-4.9 Summary statistics in Stata However, we still do not know the median population. To find this, we ask for a more detailed summary of the variable pop by typing the command sum pop, detail
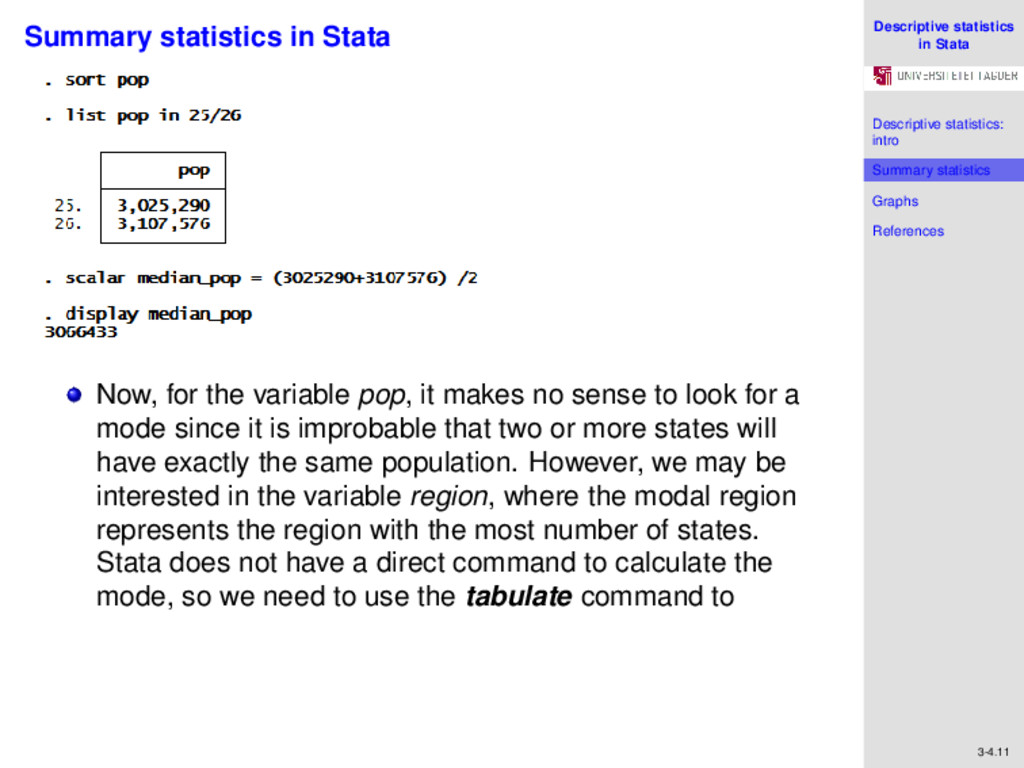
References 3-4.10 Summary statistics in Stata Here we get percentile based information for our sample. The median is the 50th percentile, and is 3,066,433 people. We also observe the values for variance, skewness and kurtosis. From the latter two values, we can infer that the variable pop is not normally distributed since it has a positive skew, and a kurtosis far in excess of 3. We could also determine the median by implementing a few steps, and following the formula described previously. If we type the command sort pop, Stata sorts the variable in ascending order. We know that n = 50 (even), so the median is given by (25th value + 26th value) /2 We can simply list these values after sort, using the commands, list pop in 25/26, and manually perform the computation to find the median.
References 3-4.11 Summary statistics in Stata Now, for the variable pop, it makes no sense to look for a mode since it is improbable that two or more states will have exactly the same population. However, we may be interested in the variable region, where the modal region represents the region with the most number of states. Stata does not have a direct command to calculate the mode, so we need to use the tabulate command to
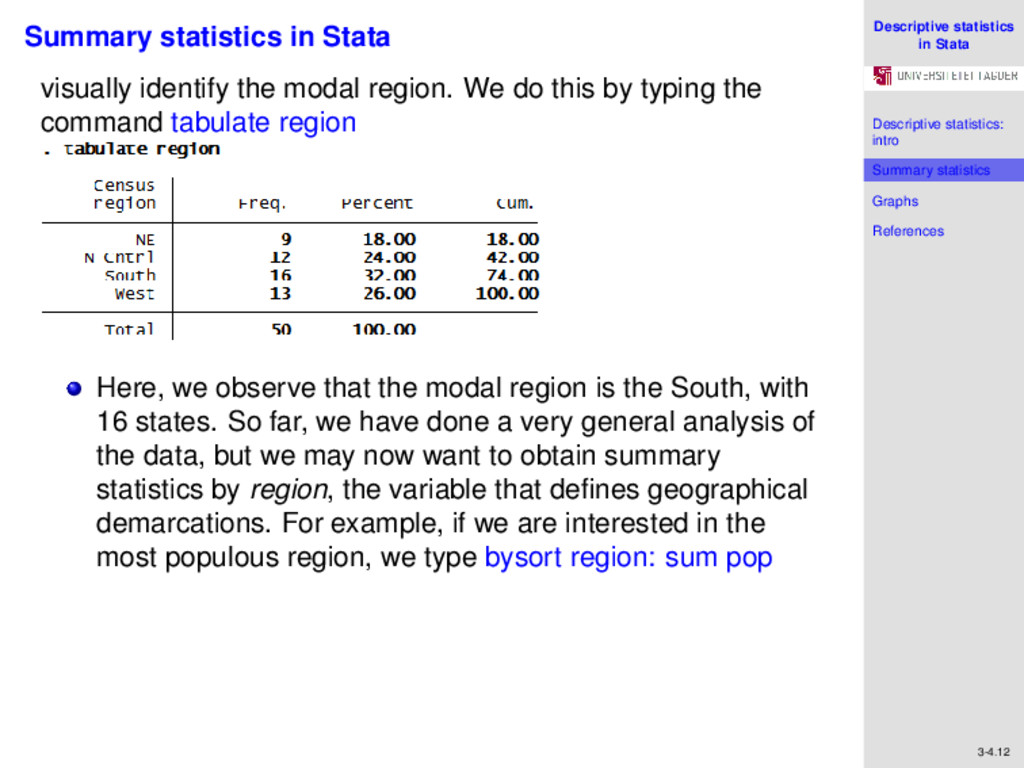
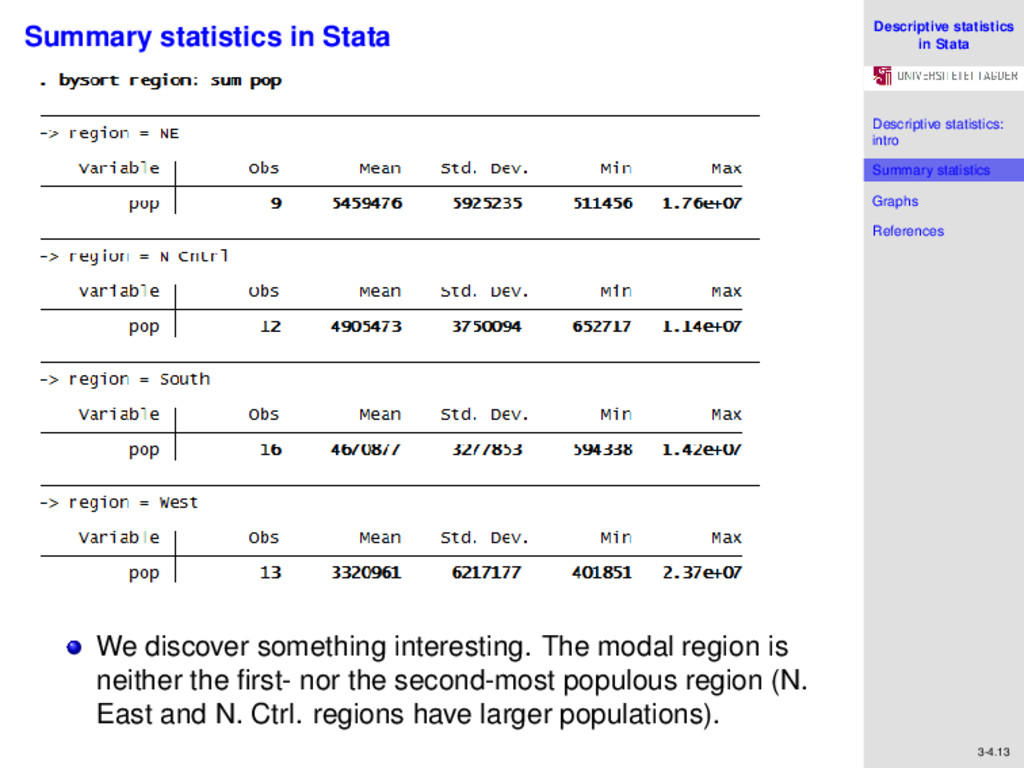
References 3-4.12 Summary statistics in Stata visually identify the modal region. We do this by typing the command tabulate region Here, we observe that the modal region is the South, with 16 states. So far, we have done a very general analysis of the data, but we may now want to obtain summary statistics by region, the variable that defines geographical demarcations. For example, if we are interested in the most populous region, we type bysort region: sum pop
References 3-4.13 Summary statistics in Stata We discover something interesting. The modal region is neither the first- nor the second-most populous region (N. East and N. Ctrl. regions have larger populations).
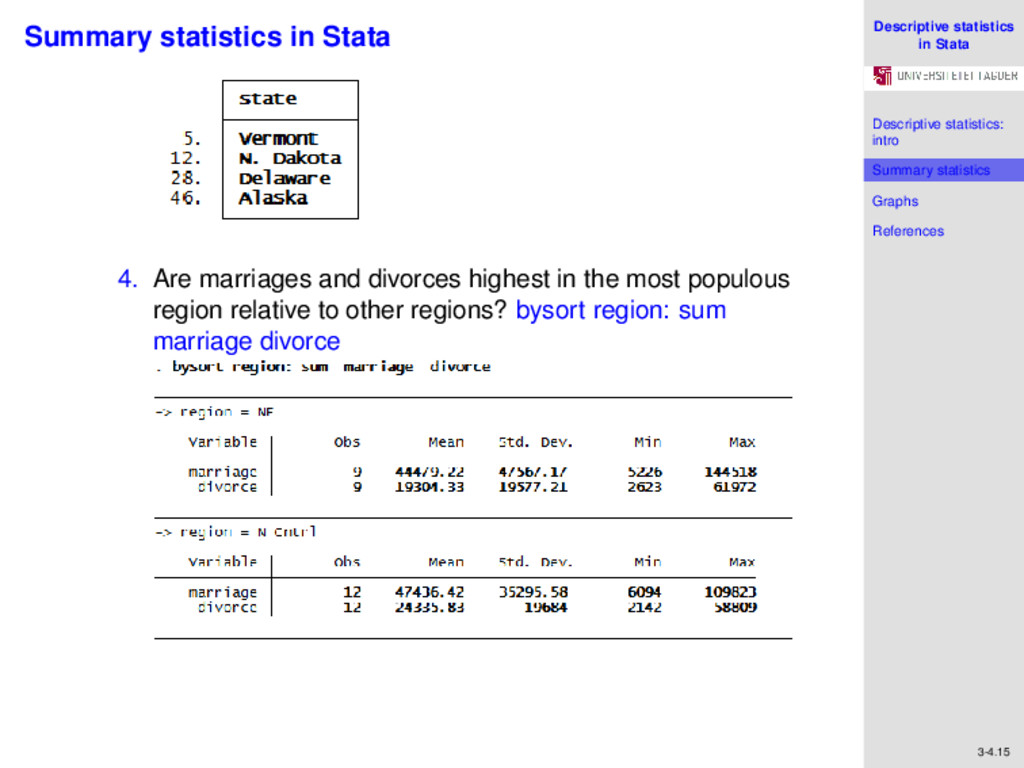
References 3-4.14 Summary statistics in Stata We could also answer a few more other questions which require us to summarize data in our sample. For example: 1. Which region has the highest average urban population? bysort region: sum popurban (The N. East). 2. What are the most populous states in each of the four regions? In two steps: First bysort region: sum pop, and utlizing the values under max for each region, list state if region==1& pop>1.754e+07| region==2& pop>1.134e+07| region==3& pop>1.414e+07| region == 4 & pop>2.364e+07 3. For each region, which states have the lowest number of people aged 65 and over? In two steps: bysort region: sum pop65p, and utlizing the minimum values: list state if pop65p==58166& region==1| pop65p==80445& region==2| pop65p==59179& region==3| pop65p==11547®ion==4
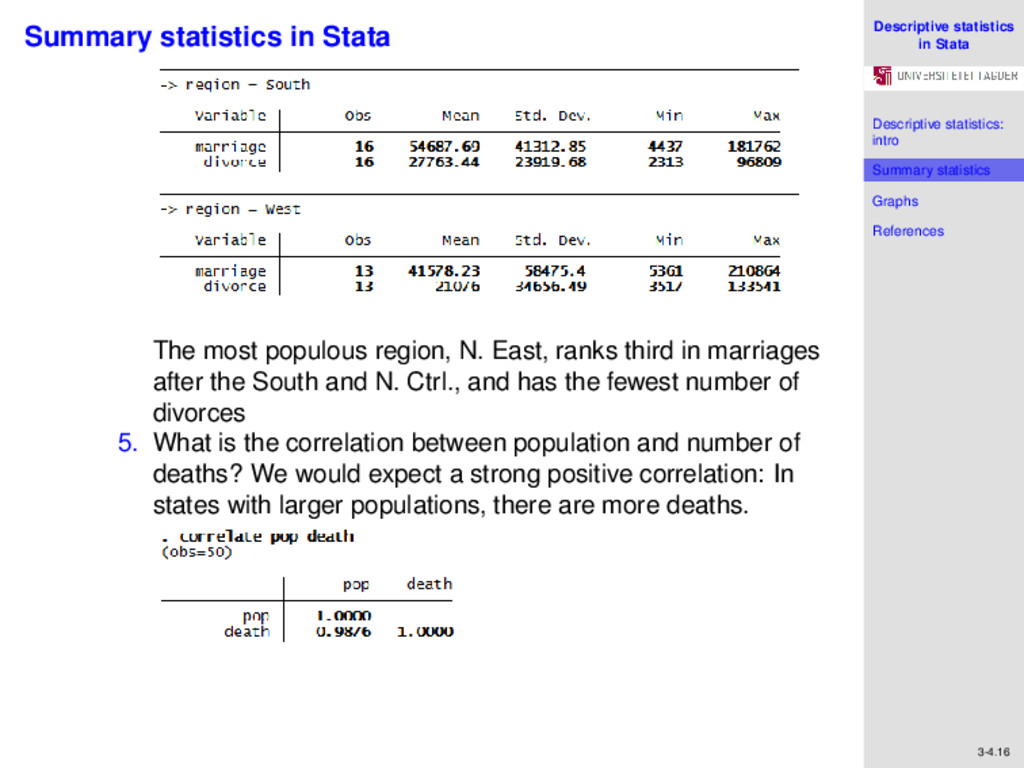
References 3-4.15 Summary statistics in Stata . 4. Are marriages and divorces highest in the most populous region relative to other regions? bysort region: sum marriage divorce
References 3-4.16 Summary statistics in Stata . The most populous region, N. East, ranks third in marriages after the South and N. Ctrl., and has the fewest number of divorces 5. What is the correlation between population and number of deaths? We would expect a strong positive correlation: In states with larger populations, there are more deaths. .
References 3-4.17 Summary statistics by generating variables As the final correlation shows, it is not very useful to just look at absolute values of variables. For example, California will have the highest number of deaths simply because it is the most populous state. In many cases, we need to generate variables to consider per capita relations, which are more comparable across regions or states. Stata has a number of commands that allow us to do this. For our dataset, we can generate per capita values for the variables poplt5 pop5_17 pop18p pop65p popurban death marriage divorce. We do this by dividing each variable by pop. The interpretation of the resulting variables is very intuitive: Multiplying the per capita variable for poplt5 by 100 gives us the percentage of kids in the population less than 5 years of age in each state. Similarly, for the variable death, it gives us the percentage death rate in each state. We use the generate command in Stata to generate the per capita amounts. For the variable poplt5, the command in Stata is gen poplt5_p= poplt5/pop, where we name the per capita variable poplt5_p.
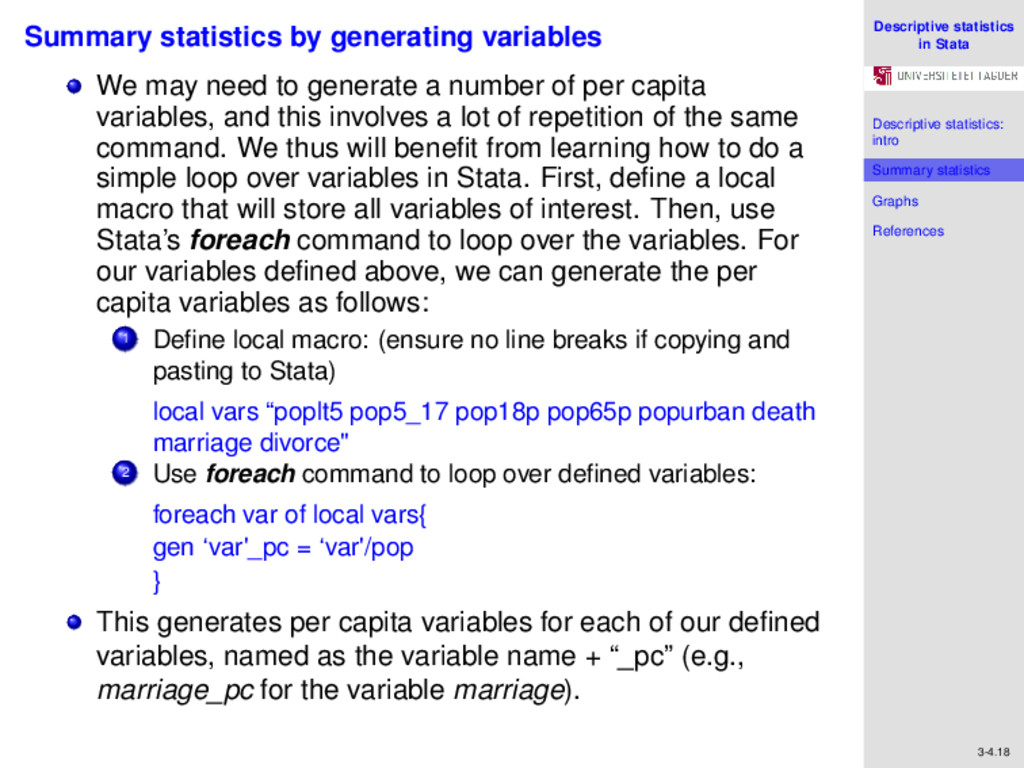
References 3-4.18 Summary statistics by generating variables We may need to generate a number of per capita variables, and this involves a lot of repetition of the same command. We thus will benefit from learning how to do a simple loop over variables in Stata. First, define a local macro that will store all variables of interest. Then, use Stata’s foreach command to loop over the variables. For our variables defined above, we can generate the per capita variables as follows: 1 Define local macro: (ensure no line breaks if copying and pasting to Stata) local vars “poplt5 pop5_17 pop18p pop65p popurban death marriage divorce" 2 Use foreach command to loop over defined variables: foreach var of local vars{ gen ‘var'_pc = ‘var'/pop } This generates per capita variables for each of our defined variables, named as the variable name + “_pc” (e.g., marriage_pc for the variable marriage).
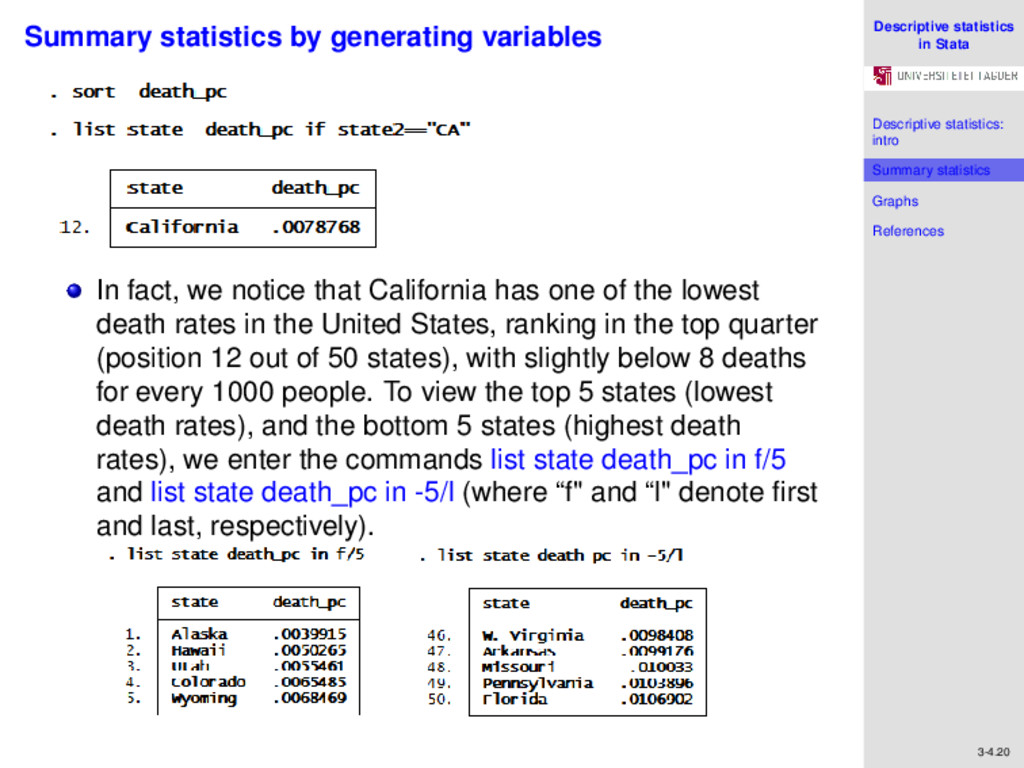
References 3-4.19 Summary statistics by generating variables By virtue of being the most populous state, California has the highest number of deaths. . But does it have the highest number of per capita deaths (or death rate)? We can determine this by sorting death_pc, the per capita death variable that we previously generated. We use the command sort death_pc. This will sort our variables in ascending order (from the lowest to the highest) in terms of values of death_pc. Thereafter, we can check what position California lies in the sort order to answer our question. Since California has the two-letter state abbreviation “CA", we can use the command list state death_pc if state2==“CA"
References 3-4.20 Summary statistics by generating variables . In fact, we notice that California has one of the lowest death rates in the United States, ranking in the top quarter (position 12 out of 50 states), with slightly below 8 deaths for every 1000 people. To view the top 5 states (lowest death rates), and the bottom 5 states (highest death rates), we enter the commands list state death_pc in f/5 and list state death_pc in -5/l (where “f" and “l" denote first and last, respectively). .
References 3-4.21 Summary statistics by generating variables Previously, we saw that Vermont, N. Dakota, Delaware and Alaska were the regional states with the lowest number of people aged 65 and over. But do they have the lowest per capita number of people aged 65 and over in their respective regions? Again, in two steps: bysort region:sum pop65p_pc, and using minimum values, list state if region==1 & pop65p_pc<.1118466| region==2 & pop65p_pc< .0984940| region==3& pop65p_pc<.0920387| region==4& pop65p_pc<.0287346 . We observe that with the exception of Alaska, the other states in relative terms do not have the lowest number of people aged 65 and over in their respective regions. Such descriptive analysis and more can be easily and efficiently conducted using Stata.
References 3-4.22 The egen command in Stata One of the most versatile commands in Stata is egen. To appreciate its full scope, you must review the entry egen within the Stata base reference manual, which can be accessed by typing help egen in the command window. Here, we will review how to use the command to create variables that are summary statistics of other variables in the dataset. We will also show how these variables may be useful if one needs to perform some more advanced analysis. Suppose that we wanted to generate a variable that is the mean of the variable pop. We do this by typing egen pop_m= mean(pop), where we name this variable is pop_m. This variable will take on a single value for all observations, equal to the mean of the variable pop (compare to mean obtained under summarize previously) .
References 3-4.23 The egen command in Stata We are not constrained to an aggregate level analysis with egen. We can generate a mean population variable by region. We type bysort region: egen pop_rm = mean(pop) where the variable is named pop_rm. This variable takes the same value for states in the same region, for example, New York and Massachusetts, but differs between states in different regions, for example, Iowa and Oklahoma. You can use the command bysort region:sum pop_rm to summarize the variable by region. Notice that the variable does not vary within regions, but varies between regions. .
References 3-4.24 The egen command in Stata We could also generate means for the other variables in our dataset. Other options within egen include minimum, maximum, median, mode, standard deviation, skewness, kurtosis, among others. Therefore, even though we remarked earlier that Stata did not have a direct command to calculate the mode, we could in a blink of an eye generate a variable that is the mode of another variable in the dataset, look at the value, and thereafter drop the variable. For the variable region, we proceed with the following commands: egen region_mod = mode(region) list region_mod in 1/2 drop region_mod .
References 3-4.25 The egen command in Stata Instantaneously, from our label list of regions obtained previously, we know that the modal region is the South which is coded “3", and since we have no other use for this variable other than obtaining this information, we drop it from our dataset. An exercise would be to see whether we can compute values of summary statistics that we obtain from the summarize command using the formulas specified previously. Arguably, the one that looks most daunting is the formula for sample kurtosis in Eq. 7, which also requires that we calculate the standard deviation. However, this should be easy to do in Stata. We can start by dividing the formula into three parts which we label “a", “b", and “c". n(n + 1) (n − 1)(n − 2)(n − 3) a n i=1 xi − ¯ x s 4 b − 3(n − 1)2 (n − 2)(n − 3) c
References 3-4.26 The egen command in Stata To check whether our computation based on this formula matches that of Stata for the variable pop, we use the variable pop_m that we generated previously which is the mean of pop. We proceed as follows: *//First, store the number of observations as a scalar qui sum pop scalar n= r(N) *//Next, compute squared deviations from mean gen deviation2= (pop-pop_m)∧2 *//Take the sum of the squared deviations egen sum_deviation2 = sum(deviation2) *//Determine the standard deviation gen sd_pop= ((1/(‘=n'-1))*sum_deviation2)∧0.5 *//Compute the part labeled “a" in the formula gen a= ((‘=n')*(‘=n'+1))/((‘=n'-1)*(‘=n'-2)*(‘=n'-3)) *//Compute the part labeled “c" in the formula gen c= (3*(‘=n'-1)∧2)/((‘=n'-2)*(‘=n'-3)) *//Compute the part labeled “b" in the formula gen b1= ((pop- pop_m)/sd_pop)∧4 egen b= sum(b1)
References 3-4.27 The egen command in Stata *//Determine the value for Kurtosis based on formula in Eq. 7 gen kurtosis1= (a*b)- c *//Use egen to generate Stata’s computation of kurtosis egen kurtosis2= kurt(pop) *//Compare the two values list kurtosis1 kurtosis2 in 1/3 From the output, we observe that the two values do not match. If we did not know better, we would be looking for errors in our code above. However, Stata does not use the formula in Eq. 7 (unbiased estimates of variance and of the fourth moment about the mean) to calculate kurtosis. These are used by the statistical packages SAS and SPSS. Instead, Stata uses the following formula:
References 3-4.28 The egen command in Stata Sample Kurtosis = 1 n n i=1 (xi − ¯ x)4 1 n n i=1 (xi − ¯ x)2 (8) where a perfect normal distribution is expected to have a kurtosis of 3. It is left as an exercise to verify that if one uses this formula, the values for kurtosis from Stata’s output match those that are obtained. In conclusion, even at the very basic level of descriptive analysis, we are required to generate new variables to examine specific relationships in our data. These can be done using Stata’s generate and egen commands. The variables are also needed to conduct more advanced tests of hypotheses. For example, in the context of our dataset, a social scientist may hypothesize that the divorce rate is not significantly different between the N.East and West regions. To test this hypothesis, he may conduct a statistical test comparing differences in mean divorce rates between the regions. This, however, requires that he first generates means by region.
References 3-4.29 Descriptive statistics: graphs The second component of descriptive statistics is graphs. These are graphical representations of data, and popular versions include bar graphs, line graphs, and pie charts. An advantage of graphs is that they are usually easy-to-understand, and convey information more quickly than browsing through raw data. Similar to summary statistics, one graph may be more appropriate relative to another depending on the type of data. The proportion of workers by industry who are unionized can be well represented using a bar graph. On the other hand, a line graph is more suited to represent the economic growth rate of China over the past 30 years. Keeping with our dataset, census.dta, we give a summary review of how one can use Stata to generate graphs. There is a lot of information on the web, as well as on Stata’s base reference manual on this topic, so you should make sure to consult these sources for more details.
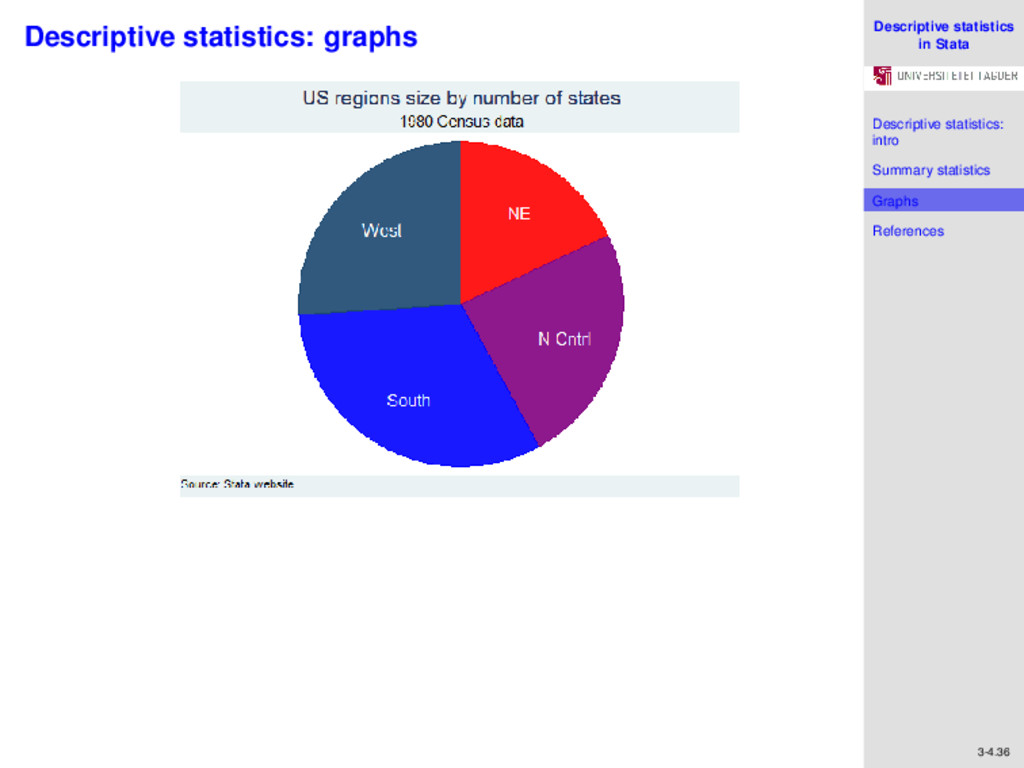
References 3-4.30 Descriptive statistics: graphs A question we addressed previously was which region has the most number of states. A pie chart could give us a graphical representation of this information. We type the command graph pie, over(region), and instantly see that the South has the most states, followed by the West, based on the arc lengths of their respective slices. We could also have drawn a bar graph to get the same information by first generating frequencies using bysort region: gen reg_freq= _N and then graphing using graph bar reg_freq, over(region)
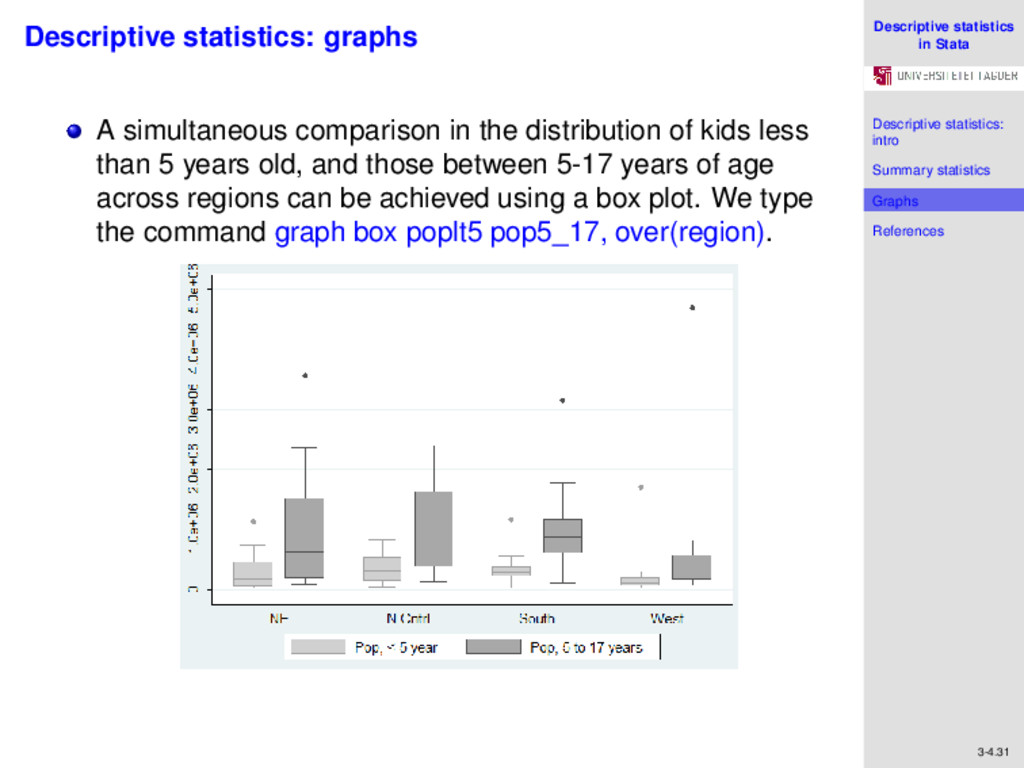
References 3-4.31 Descriptive statistics: graphs A simultaneous comparison in the distribution of kids less than 5 years old, and those between 5-17 years of age across regions can be achieved using a box plot. We type the command graph box poplt5 pop5_17, over(region).
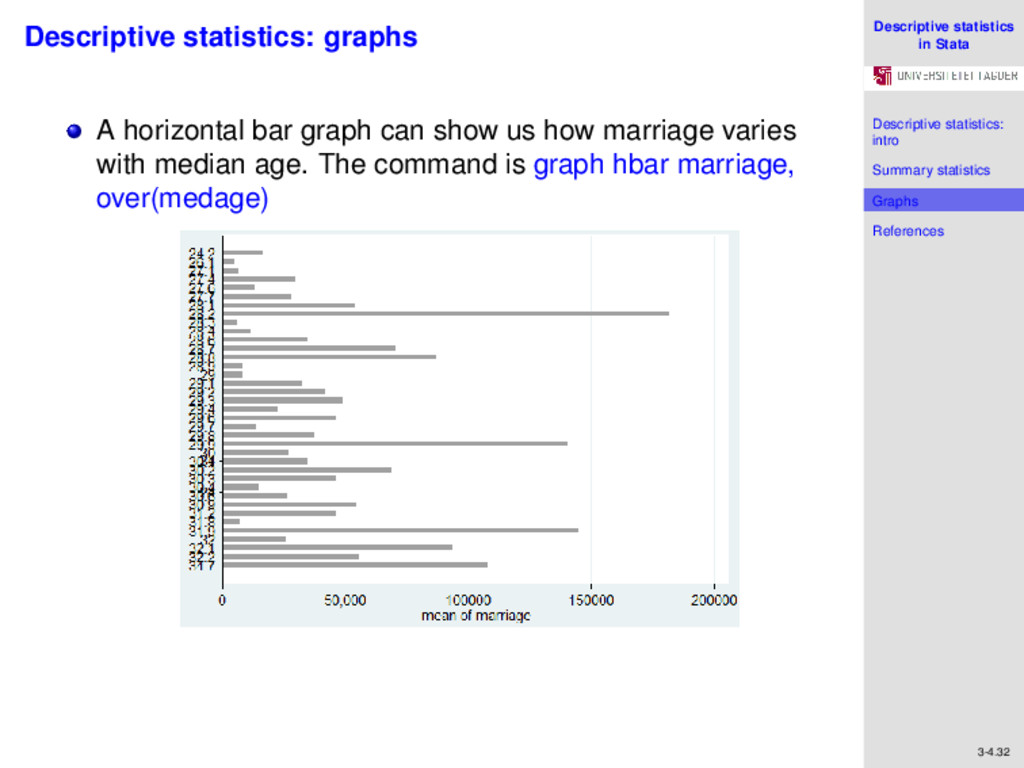
References 3-4.32 Descriptive statistics: graphs A horizontal bar graph can show us how marriage varies with median age. The command is graph hbar marriage, over(medage)
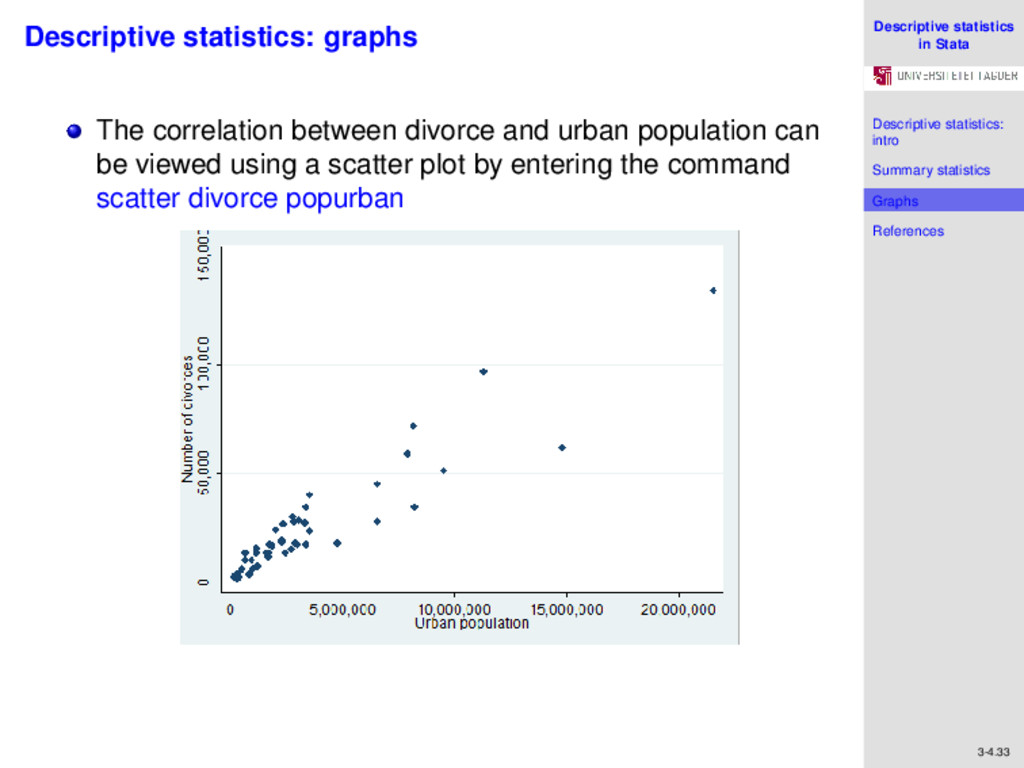
References 3-4.33 Descriptive statistics: graphs The correlation between divorce and urban population can be viewed using a scatter plot by entering the command scatter divorce popurban
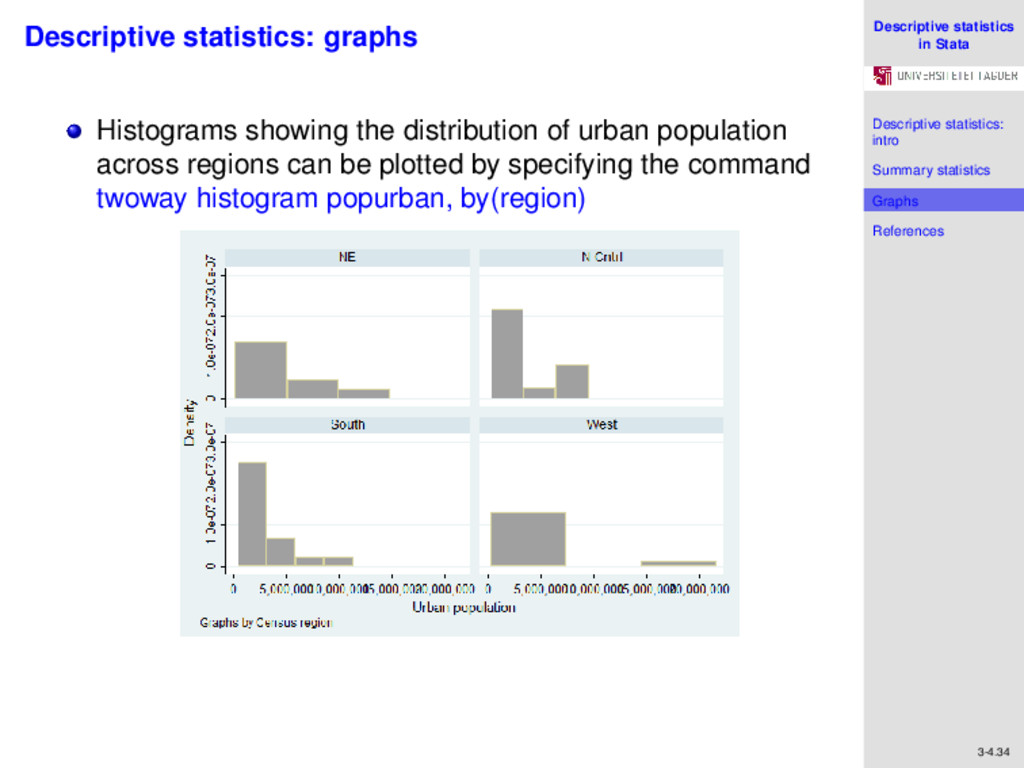
References 3-4.34 Descriptive statistics: graphs Histograms showing the distribution of urban population across regions can be plotted by specifying the command twoway histogram popurban, by(region)
References 3-4.35 Descriptive statistics: graphs More types of graphs are available under Graphics in Stata’s menu bar. Editing of the graphs to suit individual preferences (for example changing default colors, inserting text, etc.) can be done explicitly in the Graph Editor, by left clicking on the graph and selecting “Start Graph Editor". Alternatively, one could use a series of commands. For the pie chart that we plotted previously, we can label the slices with the names of the regions, and specify the colors we want on each slice. In addition, we can determine how we want the plot region to look like, and give a title to the chart, as well as specify the source of data. We do this using the following command: graph pie, over(region) plabel(_all name,size(*1.5) color(white)) legend(off) plotregion(lstyle(none)) pie(1, color(red)) pie(2, color(purple)) pie(3, color(blue)) pie(4, color(navy)) title(”US regions size by number of states") subtitle(”1980 Census data")note(”Source: Stata website")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}