regression using OLS in Stata References 6.1 Lab Session 6 Multiple regression using OLS in Stata ME 423 - Stata Lab 12 November 2015 Andrew Musau University of Agder
regression using OLS in Stata References 6.3 Classical OLS assumptions The classical assumptions are: 1. The error term has zero unconditional mean: E(u) = 0 2. The error term has zero conditional mean: E(u|X) = 0. This implies E(X u) = 0. 3+4. The error term has constant variance (i.e., is homoskedastic), and is independent across observations: Var(u|X) = E(uu |X) = σ2I where σ2 < ∞ 5. The error term has finite kurtosis: E(u4 i |x) < ∞ We often replace assumptions 1-5 with the single stronger assumption: 6. The error term is distributed normally, independently and identically, i.e., (u|X) ∼ N(0, σ2I)
regression using OLS in Stata References 6.4 Properties of OLS Under assumptions (1-2): a. OLS is unbiased: E(ˆ β) = β Under assumptions 1-5: b. Var(ˆ β) = (X X)−1σ2. c. OLS is efficient in the class of linear unbiased estimators (i.e., it is Best Linear Unbiased Estimator or BLUE). The implication here is that for any other linear unbiased estimator ˜ β, Var(˜ β) − Var(ˆ β) is positive semi-definite, i.e., a Var(˜ β) − Var(ˆ β) ≥ 0 for all choices of a (the Gauss-Markov theorem). Under assumption 6: d. ˆ β ∼ N β, (X X)−1σ2 and (X X)−1σ2 is the Cramer-Rao bound, i.e., OLS fully exploits the sample information.
regression using OLS in Stata References 6.5 Derivations of OLS 1. Least squares: minˆ β RSS(ˆ β) ⇔ minˆ β n i=1 e2 i ⇔ minˆ β y − X ˆ β y − X ˆ β 2. Method of moments: Impose 1 n X e = 0 analogously to E [X u] = 0 in the population. 3. Maximum likelihood: maxˆ β L ˆ β, ˆ σ2; y = 1 (2πˆ σ2)n 2 exp − y − X ˆ β y − X ˆ β 2ˆ σ2
regression using OLS in Stata References 6.6 Error Variance Because the population error variance σ2 is unknown, we need to estimate it. 1. Maximum likelihood estimate: ˆ σ2 = 1 n e e 2. Unbiased estimate: s2 = 1 n − k e e For large n, the difference is unimportant. Under assumption (6), e e σ2 ∼ χ2 n−k . Hence E e e σ2 = n − k.
regression using OLS in Stata References 6.7 Inference with respect to single parameters Consider the null hypothesis H0 : βj = β0 j relative to the alternative H1 : βj = β0 j . The normalized estimate ˆ βj − β0 j σ √ wjj ∼ N(0, 1) where W = (wij ) = (X X)−1. Not knowing σ, we use ˆ βj − β0 j s √ wjj = ˆ βj −β0 j σ √ wjj s2 σ2 which is the ratio of a normally distributed variable and the square root of an independent χ2 variable. It follows that ˆ βj − β0 j wjj s ∼ tn−k has the Student distribution.
regression using OLS in Stata References 6.8 Inference with respect to multiple parameters Partition the model as y = Xβ + Zγ + u where Z is n × m and X is n × k − m. Consider the null hypothesis H0 : γ = 0 relative to the alternative H1 : γ = 0. Wald test: The unrestricted estimates give RSS1 = RSS(ˆ β, ˆ γ). The restricted estimates give RSS0 = RSS(˜ β, 0) ≥ RSS1 . RSS1 σ2 ∼ χ2 n−k and RSS0 σ2 ∼ χ2 n−(k−m) . Because the difference of two χ2 variables is also χ2, RSS0 − RSS1 σ2 ∼ χ2 m . This difference is independent of RSS1 . The ratio of two independent χ2 variables, divided by their degrees of freedom, has the F-distribution. Hence W = (RSS0 − RSS1)/m RSS1/(n − k) ∼ Fm,n−k .
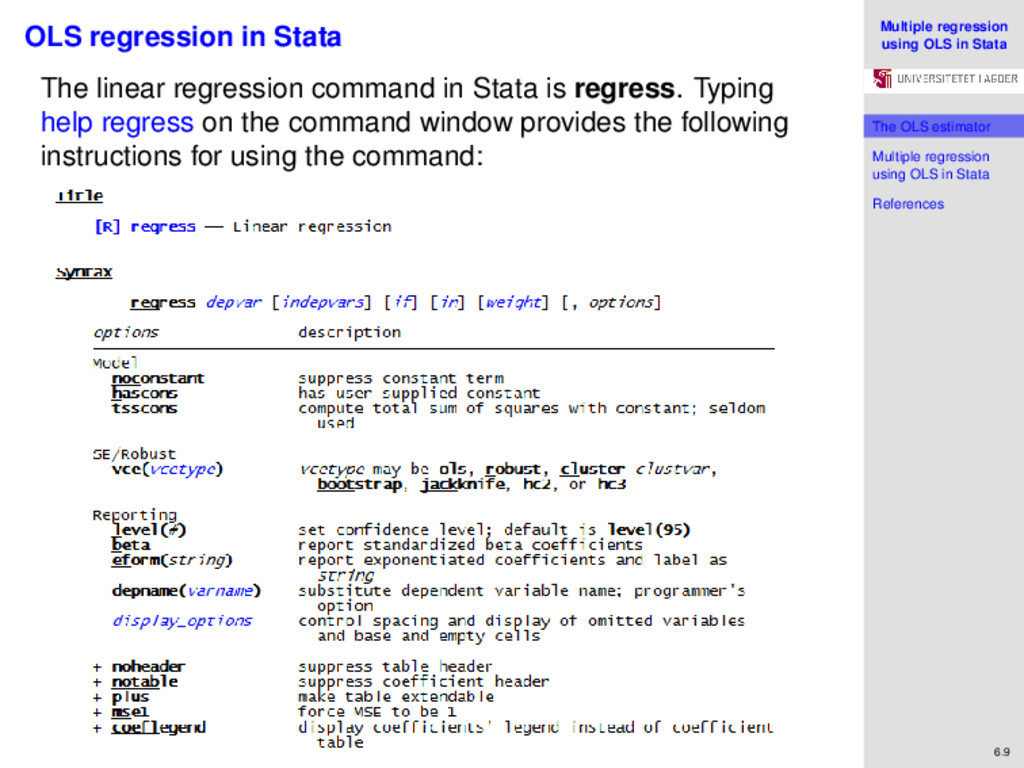
regression using OLS in Stata References 6.9 OLS regression in Stata The linear regression command in Stata is regress. Typing help regress on the command window provides the following instructions for using the command:
regression using OLS in Stata References 6.10 OLS regression in Stata The underlined parts of the commands show the shortest abbreviations that we can use, for example, it is sufficient to use reg in place of regress. First, we specify a dependent variable, then independent variables. Stata automatically includes a constant when running regress, unless we explicitly include the option noconstant. Standard errors are calculated assuming homoskedasticity of the error terms. Including the robust alternative will result in White-consistent standard errors being reported (these are corrected for heteroskedasticity). To standardize coefficients, we specify the beta option. To illustrate an application of multiple regression using OLS in Stata, we consider problem 6.13.4 in Weisberg (2005), which also enables us to examine the effect of exclusion of relevant variables in a regression model.
regression using OLS in Stata References 6.11 OLS regression in Stata Problem 6.13.4 in Weisberg (2005) is based on the dataset salary.dta. This includes the salary and other characteristics of 52 tenure-track professors in a small college in the US Midwest in 1980. The dataset was used for presentation purposes in a court case where the issue at hand was pay discrimination against women. It can be publicly downloaded from Princeton University’s website at the following link: salary.dta. The variables in the dataset are as follows: Variable Description sx Sex, 1 for female and 0 for male rk Rank, 1=Assist.-, 2=Assoc.-, and 3=Full-Professor yr No. of years in current rank dg Highest degree, 1 if Doctorate, 0 if Masters yd No. of years since highest degree was earned sl Academic salary in dollars
regression using OLS in Stata References 6.12 OLS regression in Stata In problem 6.13.4, Weisberg notes that Finkelstein (1980), in a discussion of the use of regression in discrimination cases, wrote, “. . . [a] variable may reflect a position or status bestowed by the employer, in which case if there is discrimination in the award of the position or status, the variable may be ‘tainted’. Thus, for example, if discrimination is at work in promotion of faculty to higher ranks, using rank to adjust salaries before comparing the sexes may not be acceptable to the courts." We will thus compare two multiple regression models estimated using OLS in Stata, where in one model we exclude rank. We then check whether there are rank effects on inferences concerning differential in pay by sex.
regression using OLS in Stata References 6.13 OLS regression in Stata We wish to fit the following model: sl = β1 + β2 sx + β3 yr + β4 yd + β5 dg We do this using the command reg sl sx yr yd dg, and obtain the following: The upper left of the regression table is an analysis-of-variance (ANOVA) table. SS, df, and MS denote “sum of squares", “degrees of freedom", and “mean square", respectively. The model includes a constant, and total SS represents the sum after removal of means.
regression using OLS in Stata References 6.14 OLS regression in Stata The df are calculated as the total observations less 1 for the mean removal. The F-statistic on the upper right tests the hypothesis that β2 = · · · = β5 = 0. The results show that women on average earn 1287 dollars less than men, but this difference is not significant (ρ = 0.332). On the other hand, a one year increase in no. of years in current rank, and no. of years since highest degree was earned increases salary by 352, and 339 dollars, respectively. Finally, PhD degree holders on average earn 3299 dollars more than Master degree holders. The coefficients of yr, yd and dg are all significant at the 5 percent level. If we wanted to obtain standardized coefficients, we would run the command reg sl sx yr yd dg, beta. We wish to include rank to check for rank effects. However, we first note that this is a categorical variable with 3 categories, and thus we have to create indicator variables for each category. We do this in Stata by typing tabulate rk, gen(rank). This will generate 3 variables, rank1, rank2, and rank3, representing the categories Assistant-, Associate-, and Full-Professor, respectively.
regression using OLS in Stata References 6.15 OLS regression in Stata The indicator variable for each will take on a value of one if an individual in the sample has that particular rank, and zero otherwise. Before adding these variables into the regression equation, we need to leave out one which will be our comparison group. Which one we leave out does not matter. Therefore, if we leave out rank1 (Assistant Professor), we thus would want to fit the model: sl = β1 + β2 sx + β3 yr + β4 yd + β5 dg + β6 rank2 + β7 rank3
regression using OLS in Stata References 6.16 OLS regression in Stata We do this using the command reg sl sx yr yd dg rank2 rank3, and obtain the following: Here, we observe that the coefficient of sex has a positive sign. Women on average earn 1166 dollars more than men. However, this difference is still not significant (ρ = 0.214). Other interesting changes to note are that a one year increase in the no. of years since the highest degree was earned decreases salary by 125 dollars, whereas PhDs on average earn 1389 dollars less than Master degree holders. However, none of this is significant (ρ = 0.115 & ρ = 0.180, reapectively).
regression using OLS in Stata References 6.17 OLS regression in Stata As we would expect, Associate- and Full-Professors, on average, earn 5292 and 11118 dollars more than Assistant Professors, respectively. We could test whether salaries of Associate- and Full-Professors differ. To do this, we specify the command test rank2=rank3. This is a wald test that the difference in the two coefficients is equal to zero. The F-statistic is highly significant, and we conclude that Full Professors on average earn higher salaries. Comparing the two models, we observe that excluding rank results in a sign reversal for the coefficient of gender. What does this mean in terms of inference? If we exclude a relevant variable, then it may be what explains our result. But does this imply that we should always include all variables in the regression model? As the earlier quote of Finkelstein hints, we need to use additional reasoning when deciding on what variables to include a regression, or when drawing inferences.
regression using OLS in Stata References 6.18 Multicollinearity test After the regress command, Stata allows for the calculation of variance inflation factors using the command vif. Define: tolerance = 1 − R2 j where R2 j is the R-squared statistic from a regression of regressor j on all other regressors in the model. vif is thus calculated as vif = 1 tolerance . As a rule of thumb, a vif of 5 or 10 indicates a multicollinearity problem. From our first model: We conclude that we do not have a multicollinearity problem.
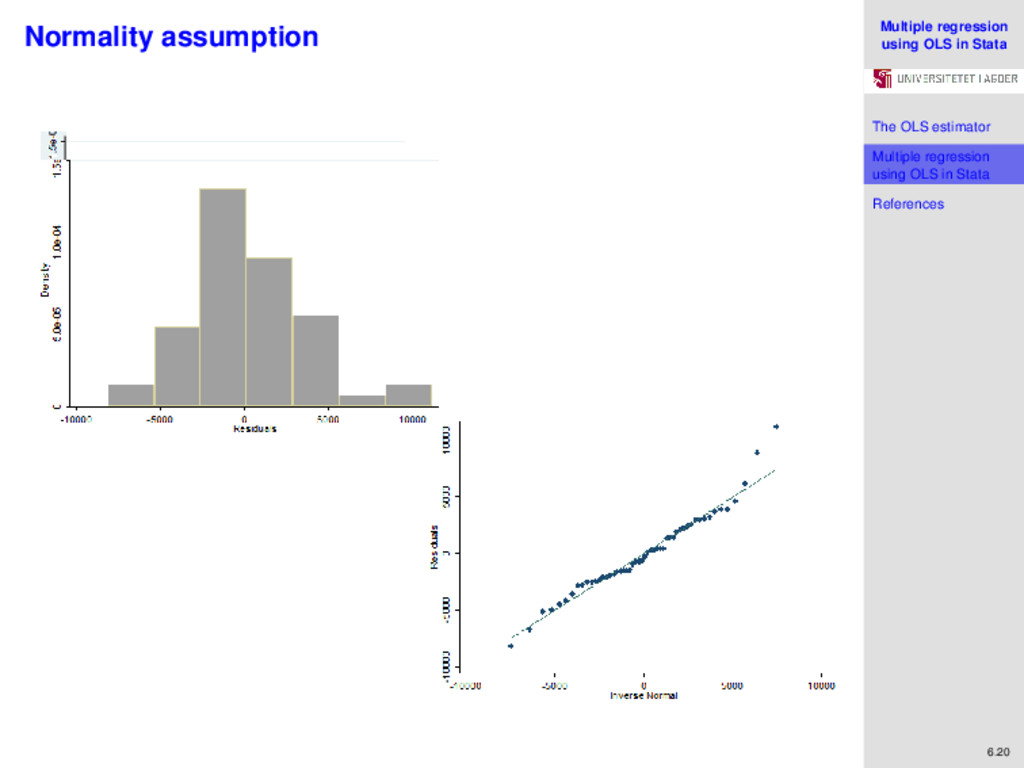
regression using OLS in Stata References 6.19 Normality assumption One of the classical assumptions of OLS (assumption 6) is that the error term is normally, independently, and identically distributed. We can obtain the predicted value of the outcome variable using the command predict y_hat. Similarly, we can obtain the predicted residuals using the command predict r, residual. We can thereafter check whether the residual is normally distributed by a variety of graphical methods, or using formal tests including the Skewness and Kurtosis normality test, the Shapiro-Wilk normality test, and the Shapiro-Francia normality test. We implement all these for our first model.
regression using OLS in Stata References 6.21 Normality assumption From these tests of normality, we conclude that we cannot reject the hypothesis that the error term is normally distributed at the 5 percent level of significance.
regression using OLS in Stata References 6.22 References Gilbert C. L. 2011. Advanced Econometrics Lecture Notes. University of Trento. StataCorp. 2013. Stata 13 Base Reference Manual. College Station, TX: Stata Press. Weisberg S. 2005. Applied Linear Regression, Third Edition. New York: John Wiley and Sons.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}