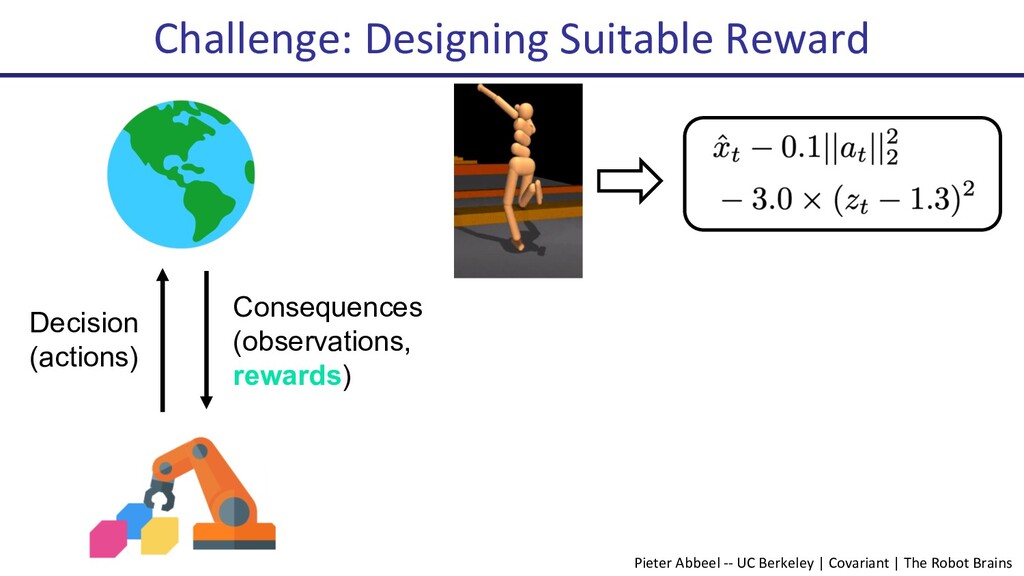
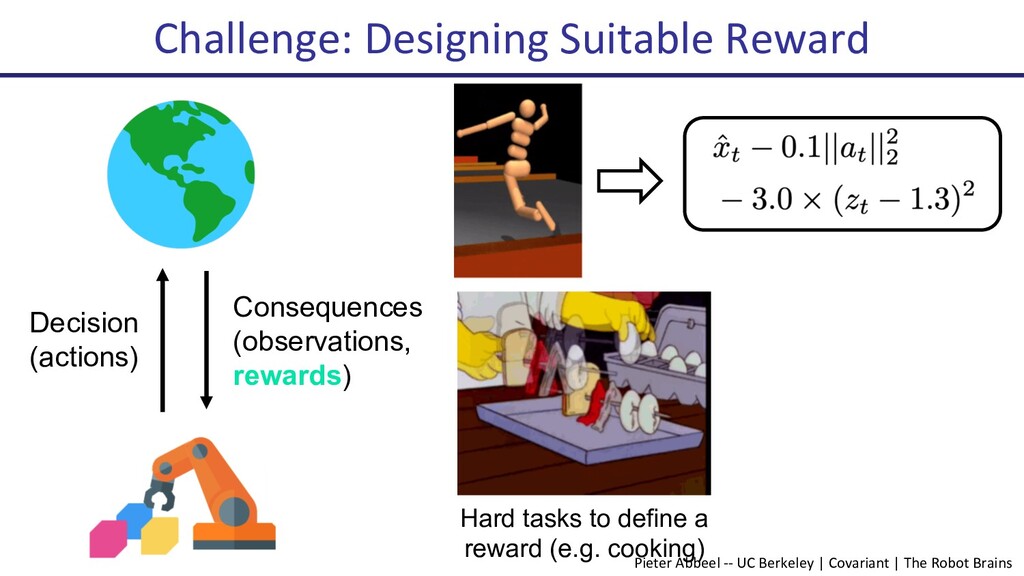
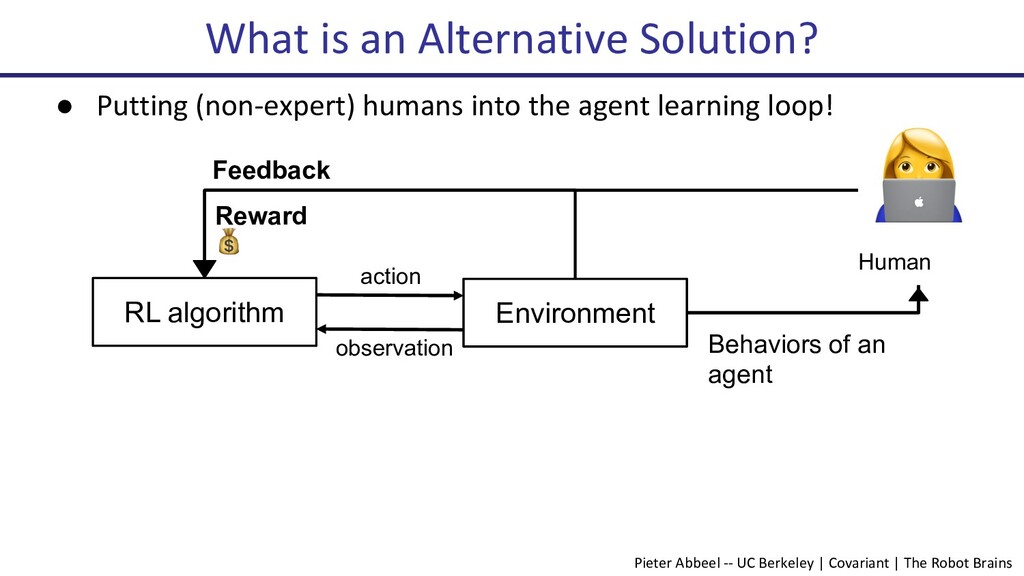
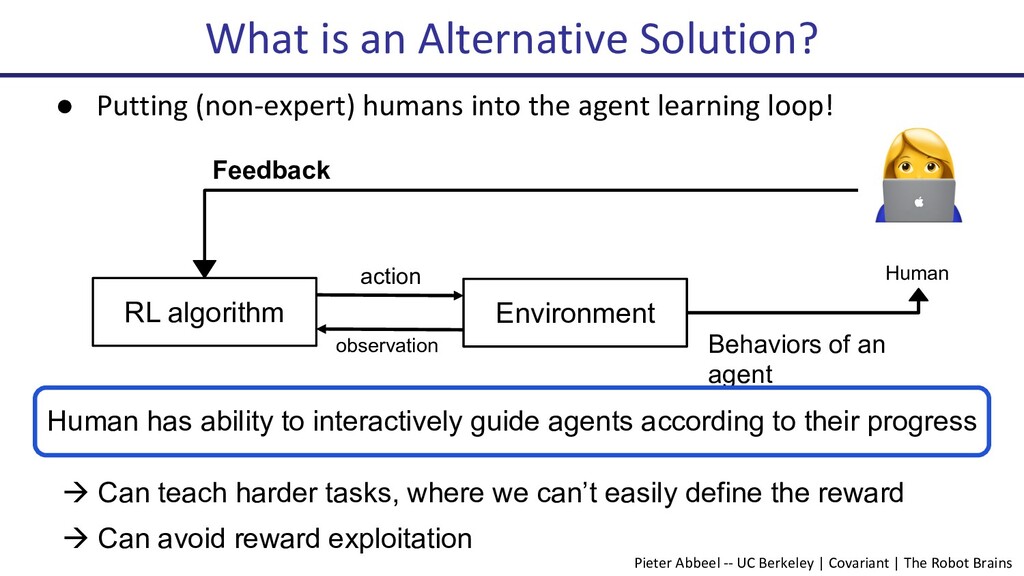
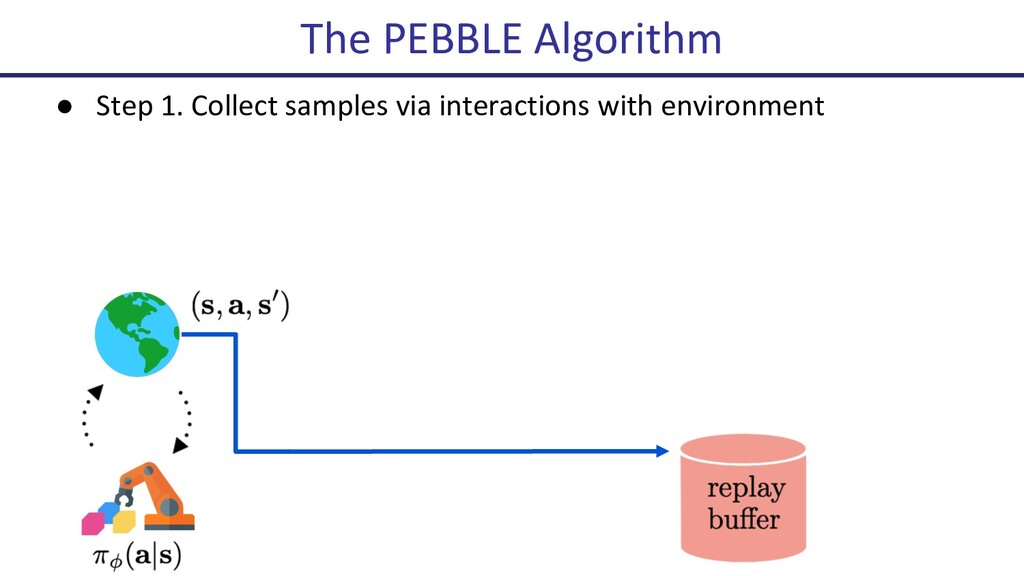
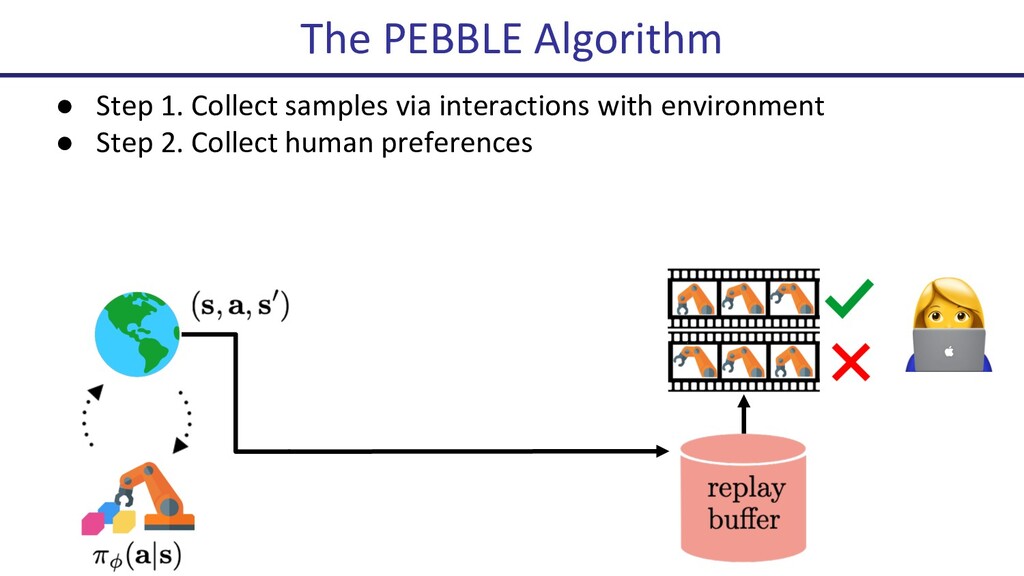
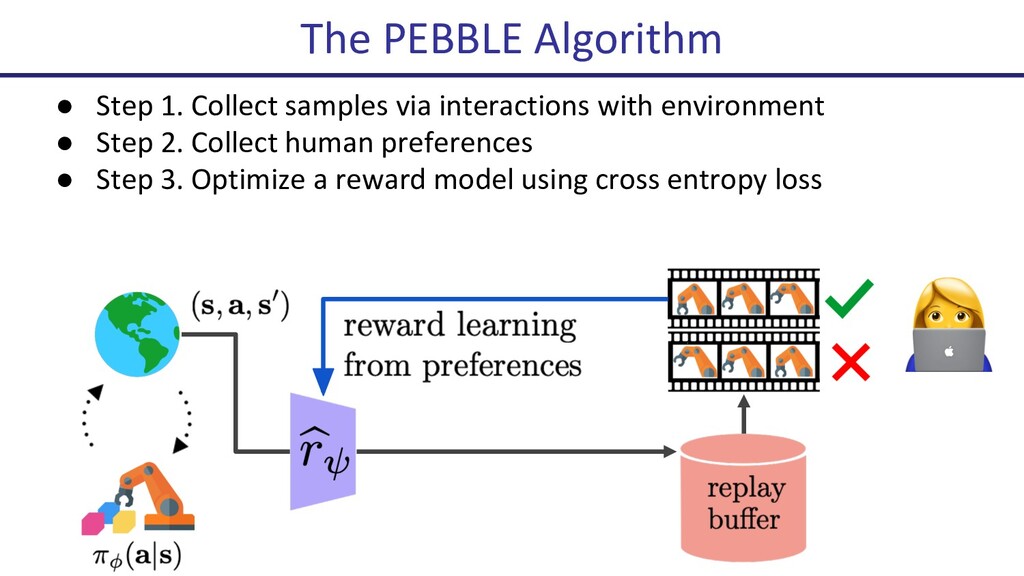
Deep reinforcement learning (Deep RL) has seen many successes, including learning to play Atari games, the classical game of Go, robotic locomotion and manipulation. However, now that Deep RL has become fairly capable of optimizing reward, a new challenge has arisen: How to choose the reward function that is to be optimized? Indeed, this often becomes the key engineering time sink for practitioners. In this talk, I will present some recent progress on human-in-the-loop reinforcement learning. The newly proposed algorithm, PEBBLE, empowers a human supervisor to directly teach an AI agent new skills without the usual extensive reward engineering or curriculum design efforts.
{kind=link}
![Fast Progress on Deep RL 2013 Atari (DQN) [Deepmind] Pong](https://files.speakerdeck.com/presentations/e439d9e9a468471c89153d56ac80a74a/slide_1.jpg){kind=link}
![[Source: Mnih et al., Nature 2015 (DeepMind) ] Deep Q-Network](https://files.speakerdeck.com/presentations/e439d9e9a468471c89153d56ac80a74a/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fast Progress on Deep RL 2013 Atari (DQN) [Deepmind] 2015](https://files.speakerdeck.com/presentations/e439d9e9a468471c89153d56ac80a74a/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
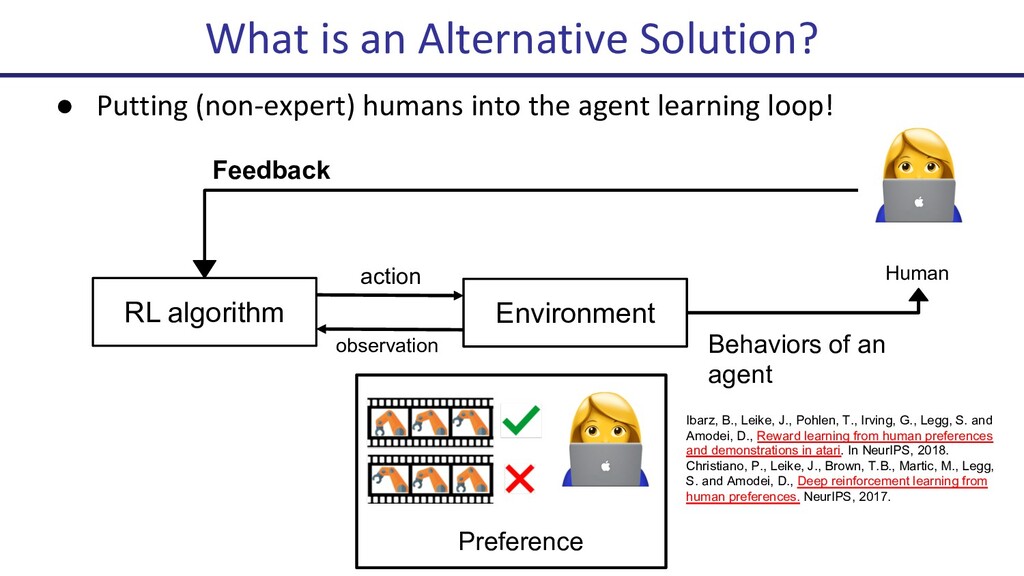
![Learning Reward from Preferences • Fitting a reward model [1]](https://files.speakerdeck.com/presentations/e439d9e9a468471c89153d56ac80a74a/slide_17.jpg){kind=link}
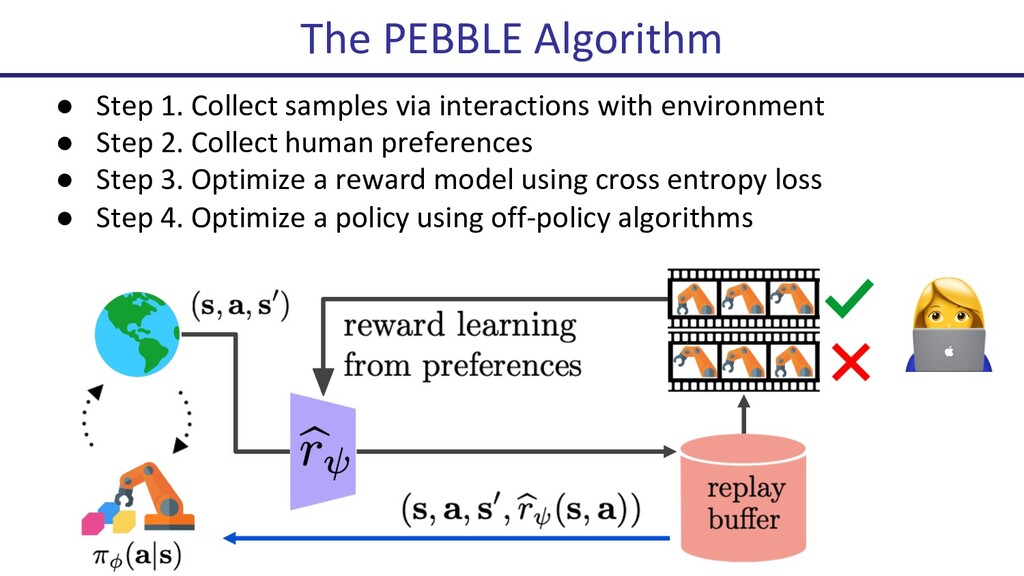{kind=link}
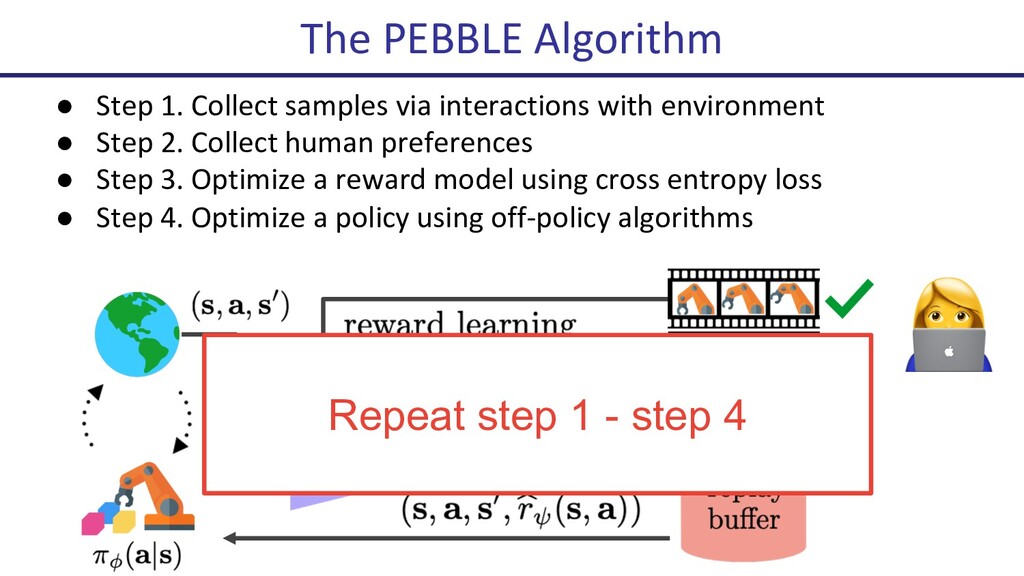{kind=link}
{kind=link}
{kind=link}
{kind=link}
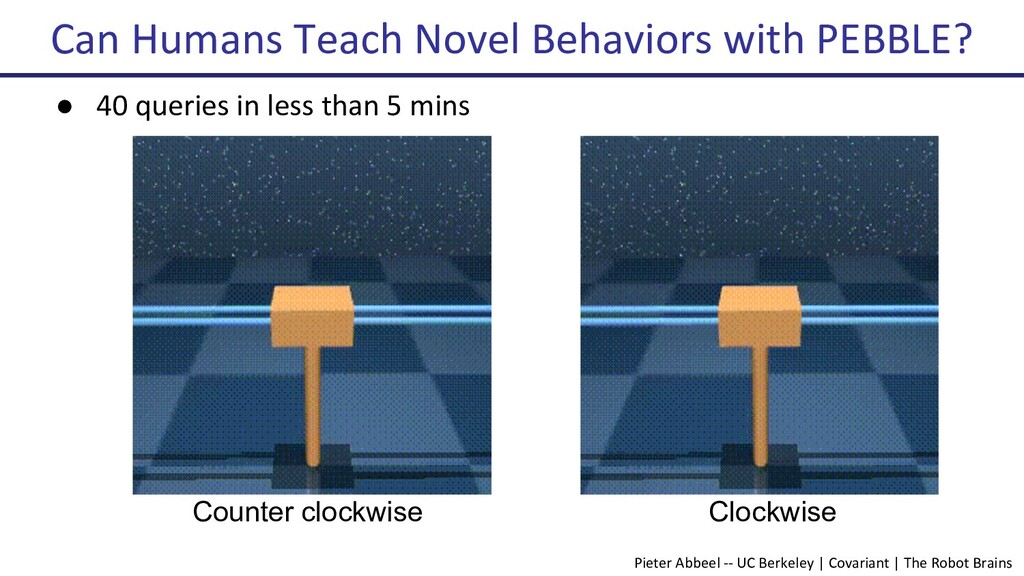{kind=link}
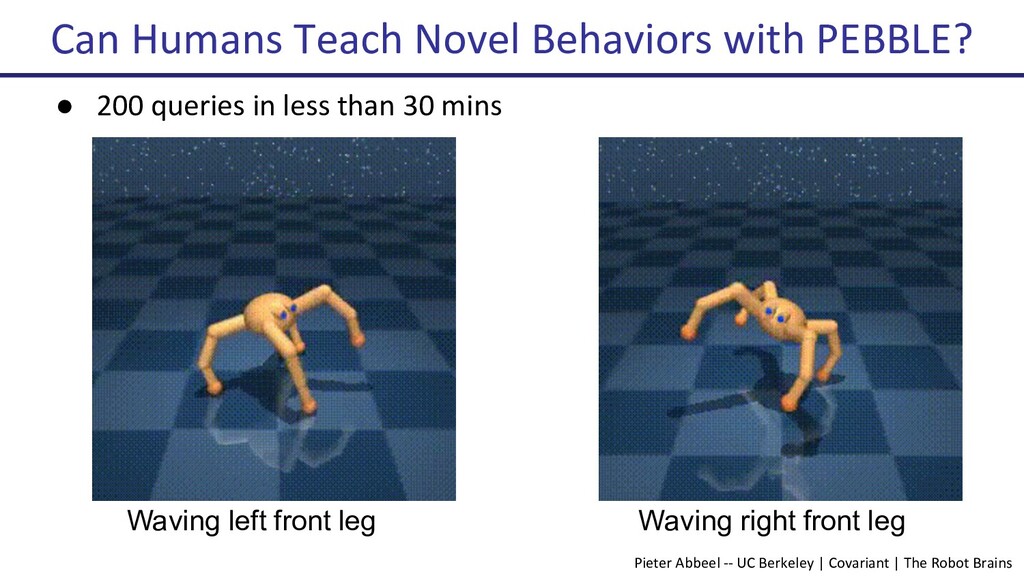{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
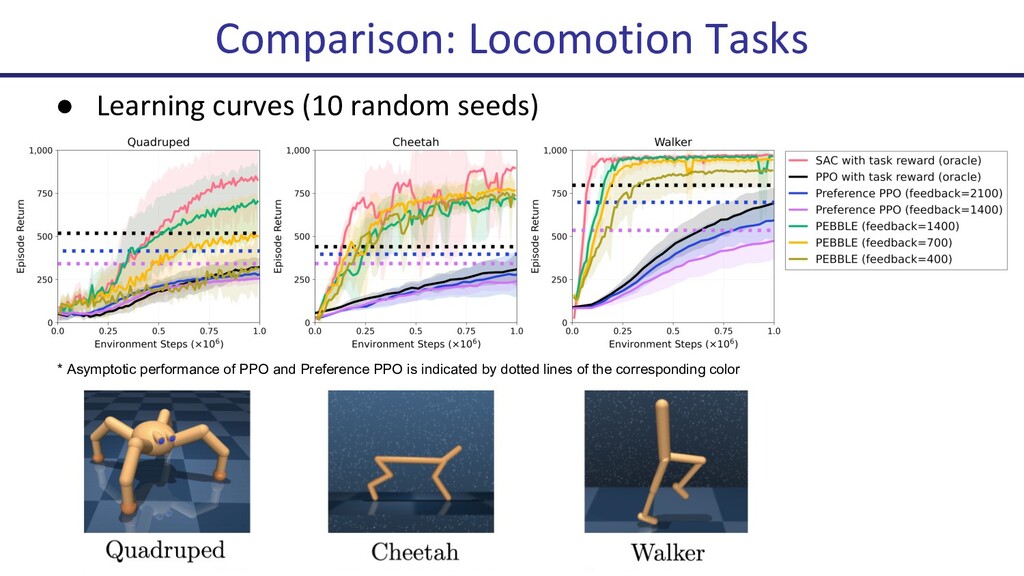{kind=link}
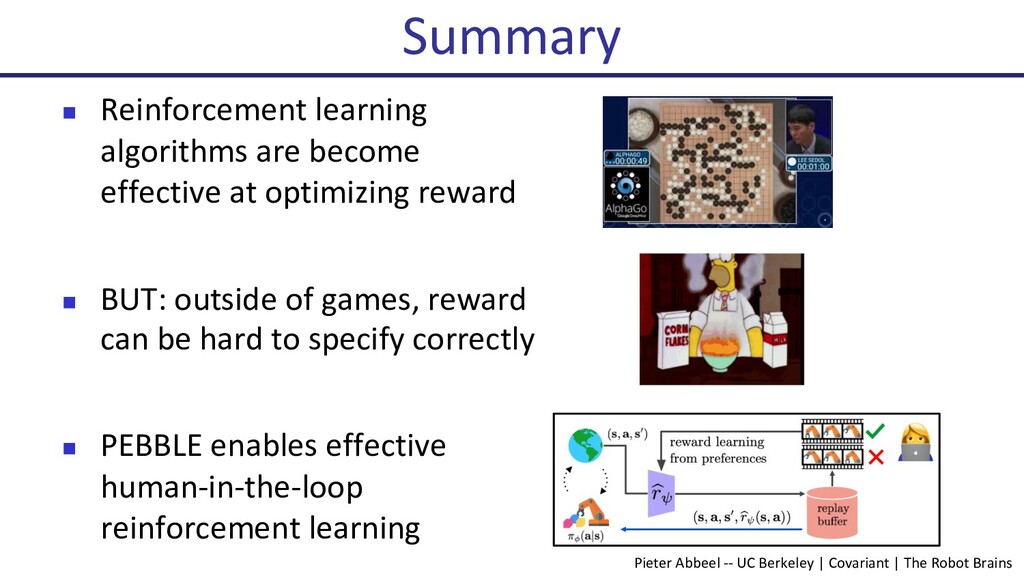{kind=link}