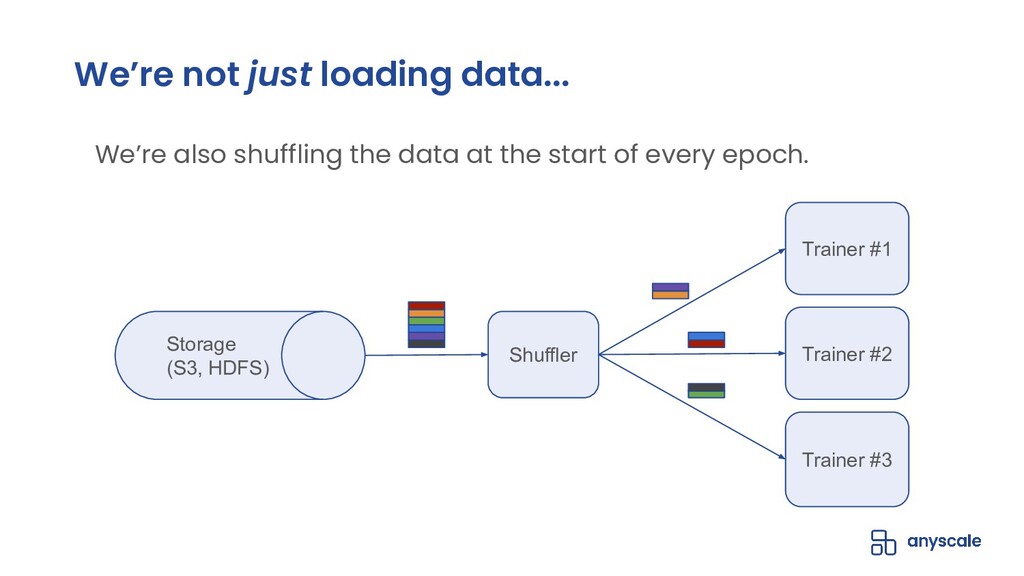
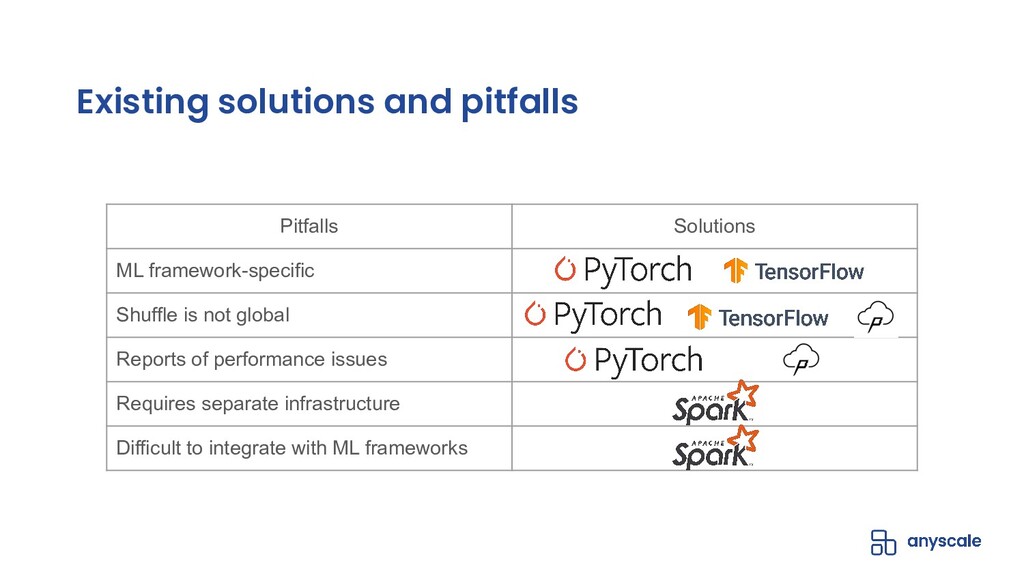
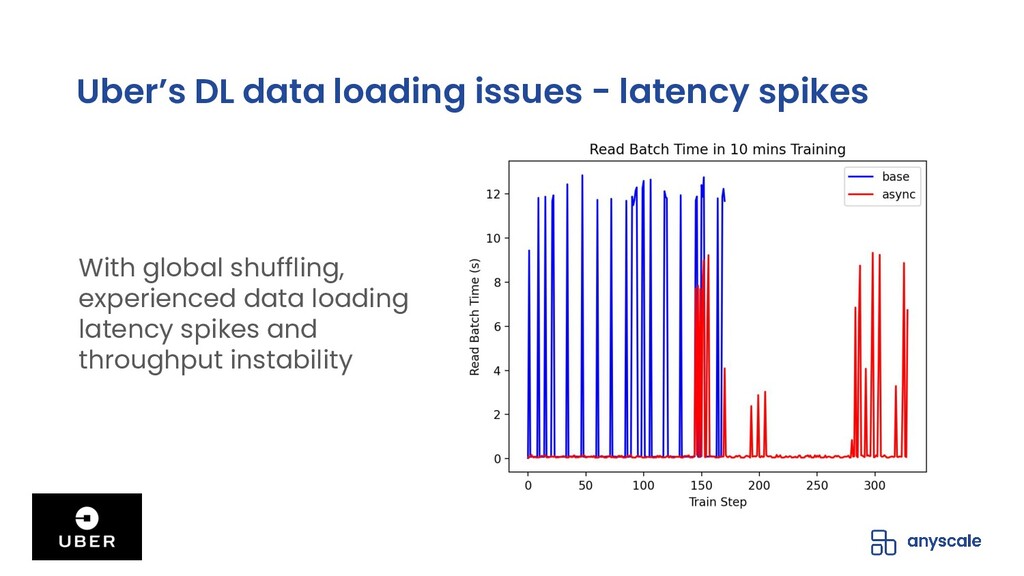
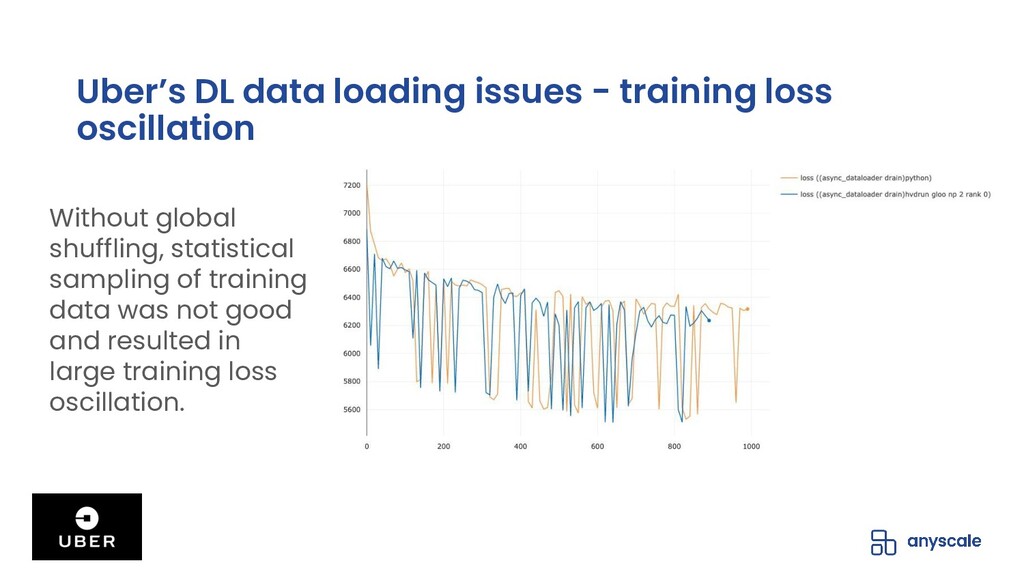
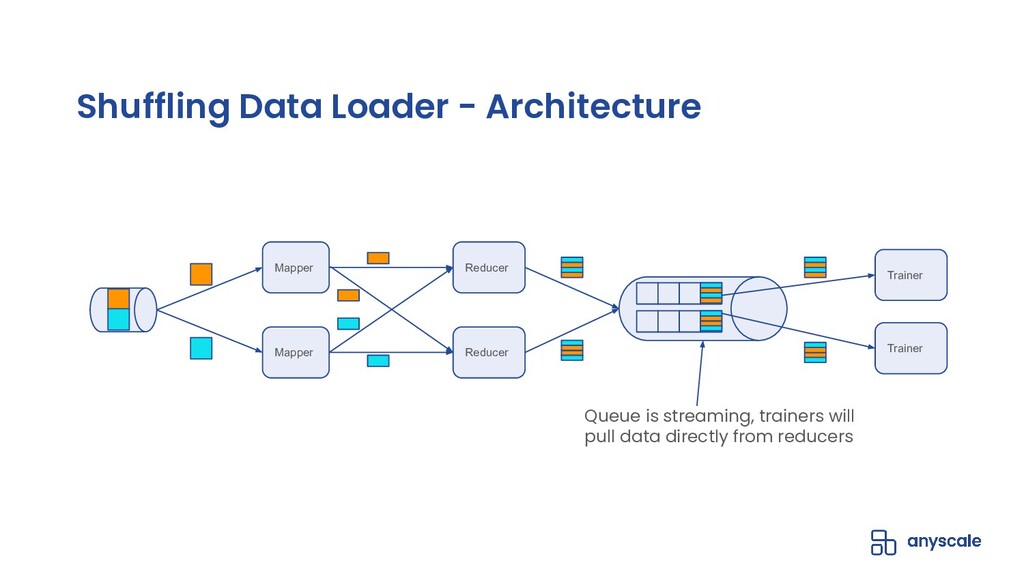
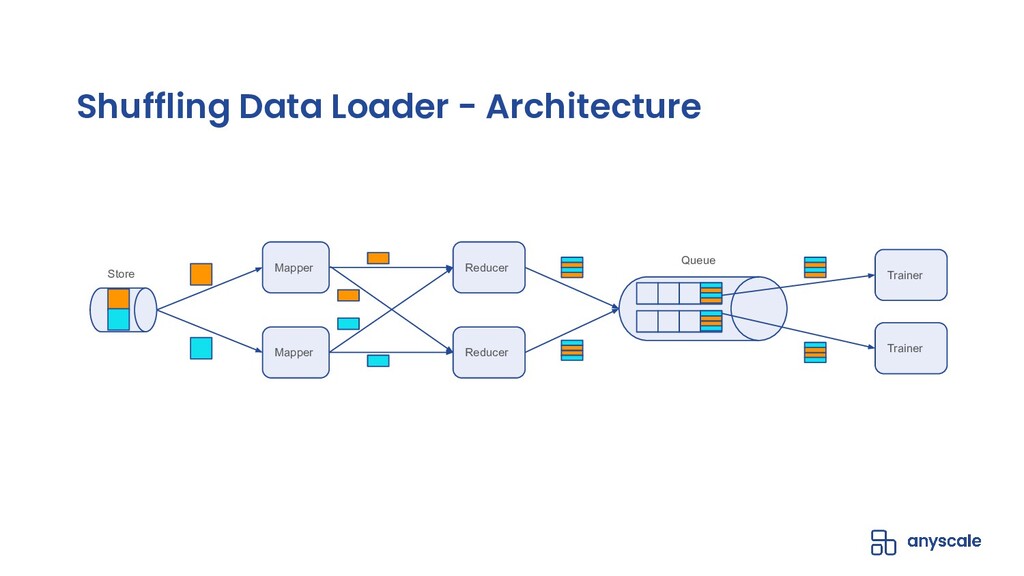
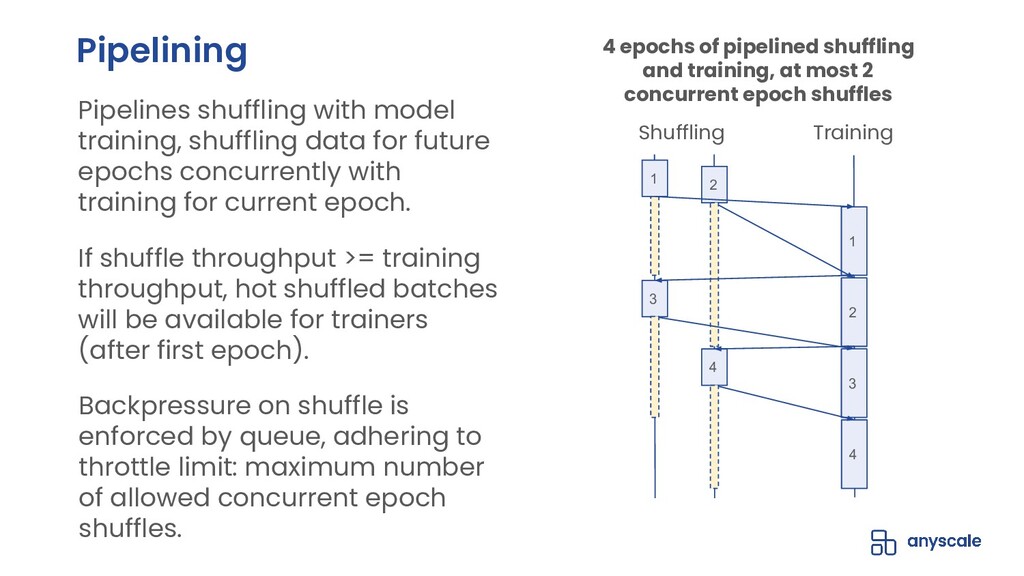
Shuffling training data, both before training and between epochs, helps prevent model overfitting by ensuring that batches are more representative of the entire dataset (in batch gradient descent) and that gradient updates on individual samples are independent of the sample ordering (within batches or in stochastic gradient descent); the end-result of high-quality per-epoch shuffling is better model accuracy after a set number of epochs. When the training dataset is small and the model is only being trained on a single GPU, shuffling the entire dataset before each epoch is easy; when the training dataset is large or the model is being trained in parallel on multiple GPUs, even with each trainer operating on a manageable subset of the training data, data loading and shuffling time can dominate training time, and many data loaders will compromise the quality of their per-epoch shuffle in order to save on data loading time by only shuffling within the trainer's data partition or even not shuffling at all.
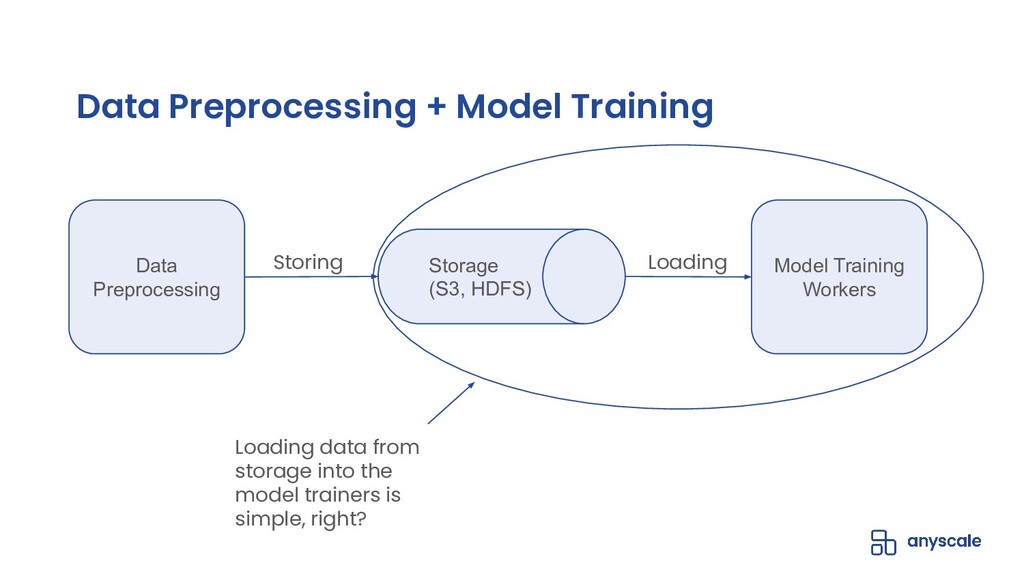
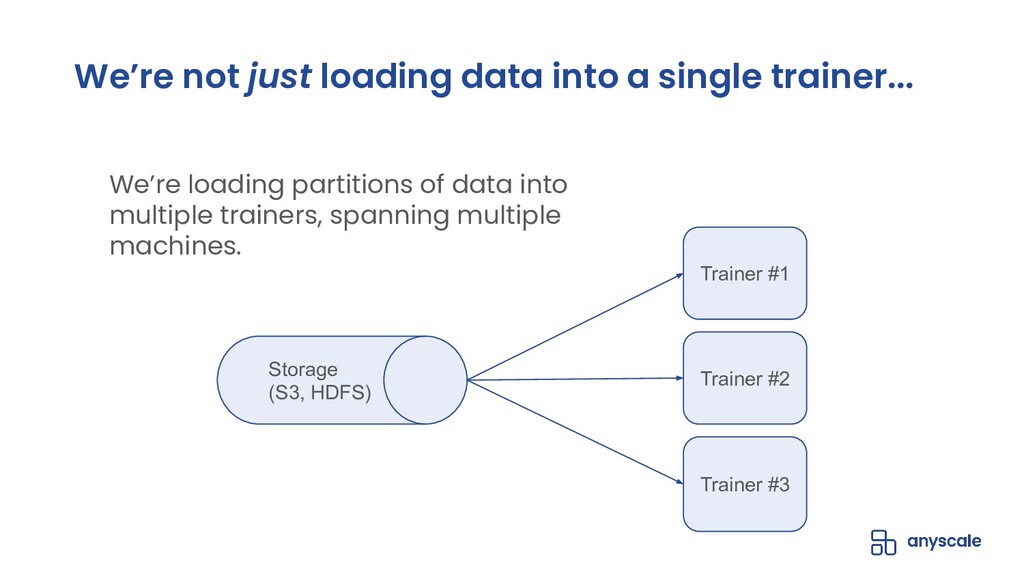
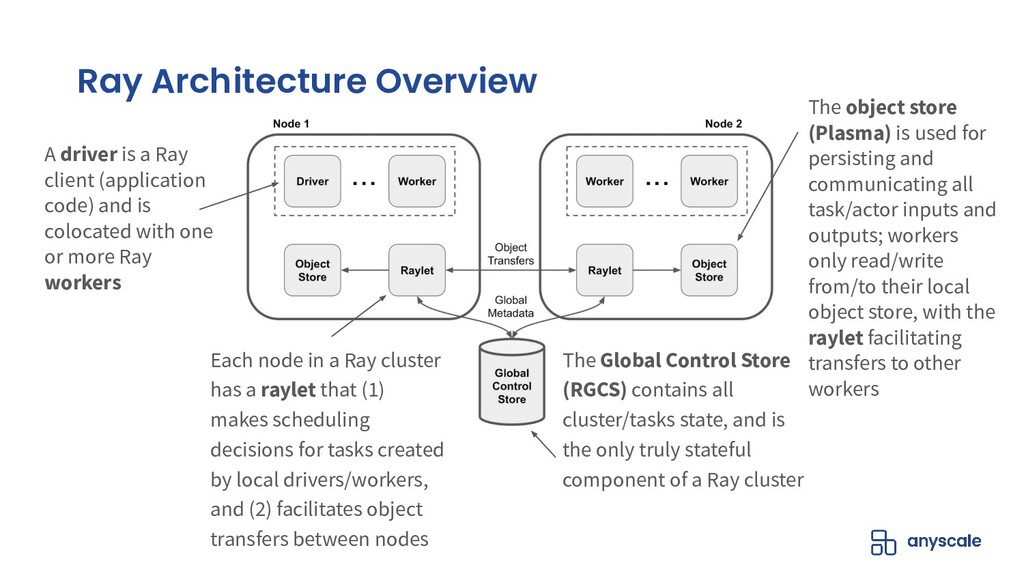
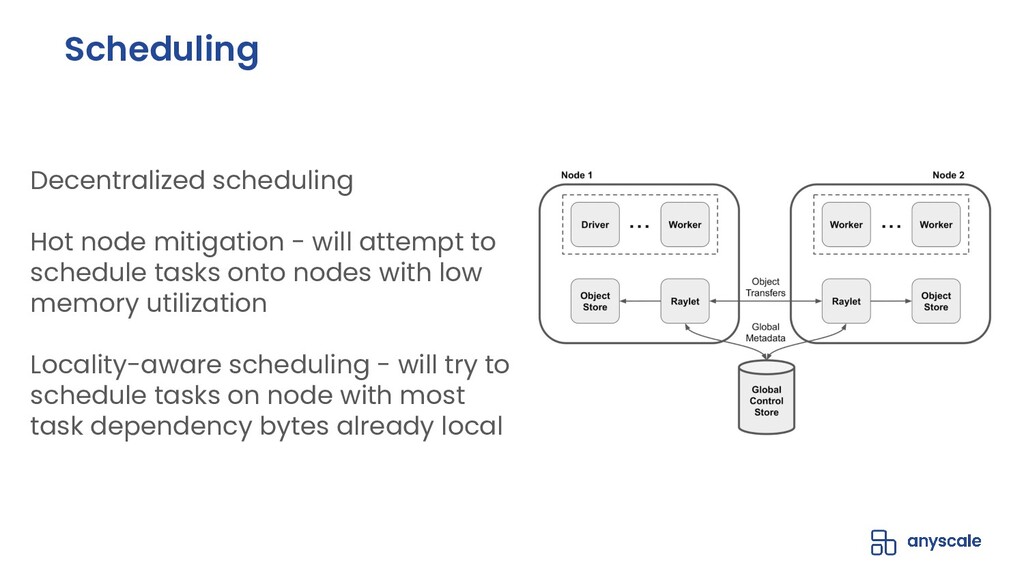
In this talk, we will go over our Ray-based per-epoch shuffling data loader, capable of providing high throughput of globally shuffled batches to dozens of trainers via an easy-to-use iterable dataset interface. When paired with Horovod-on-Ray, you get distributed model training with high-throughput shuffled data loading all running on a fast, reliable, resource-efficient Ray cluster!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}