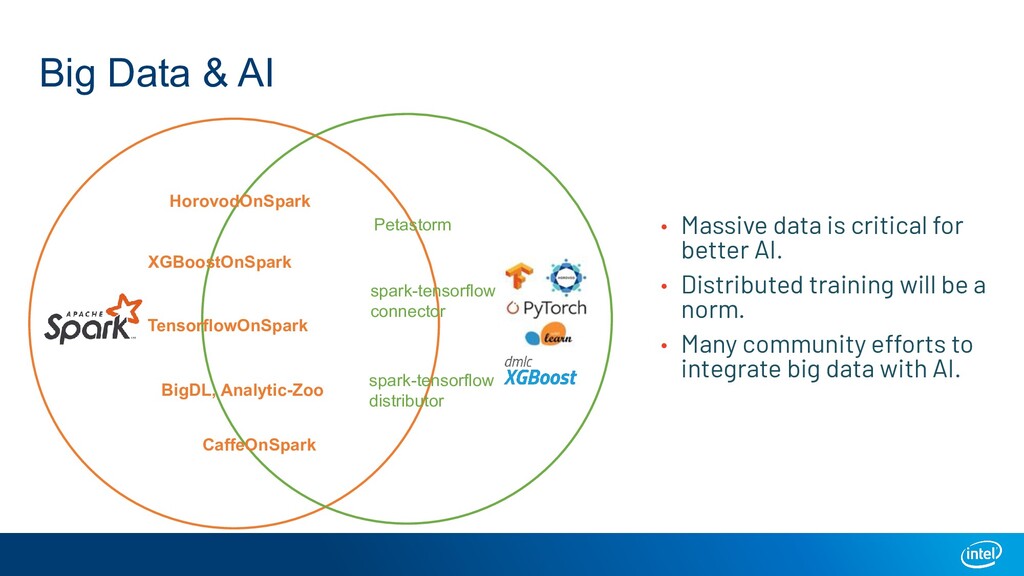
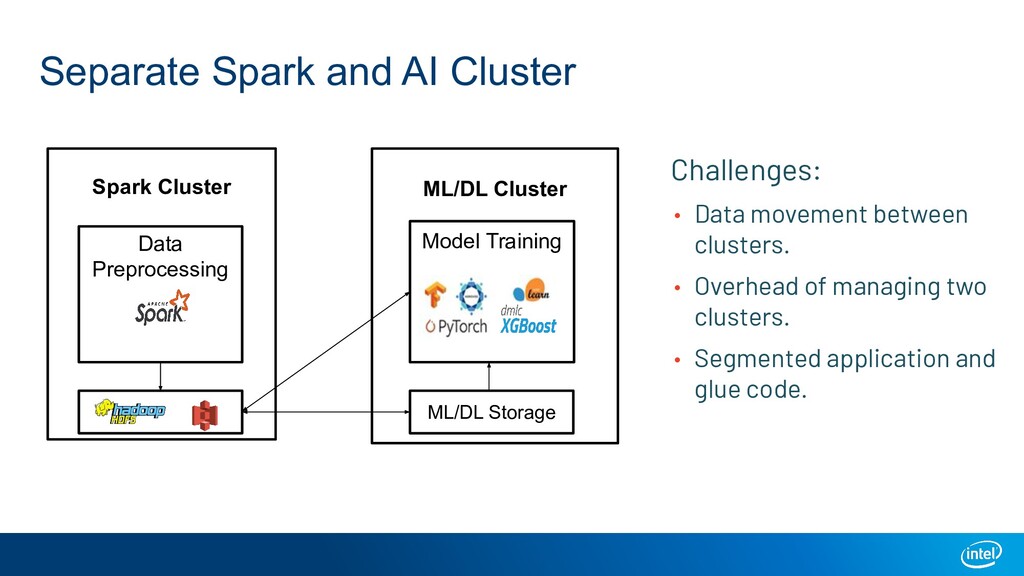
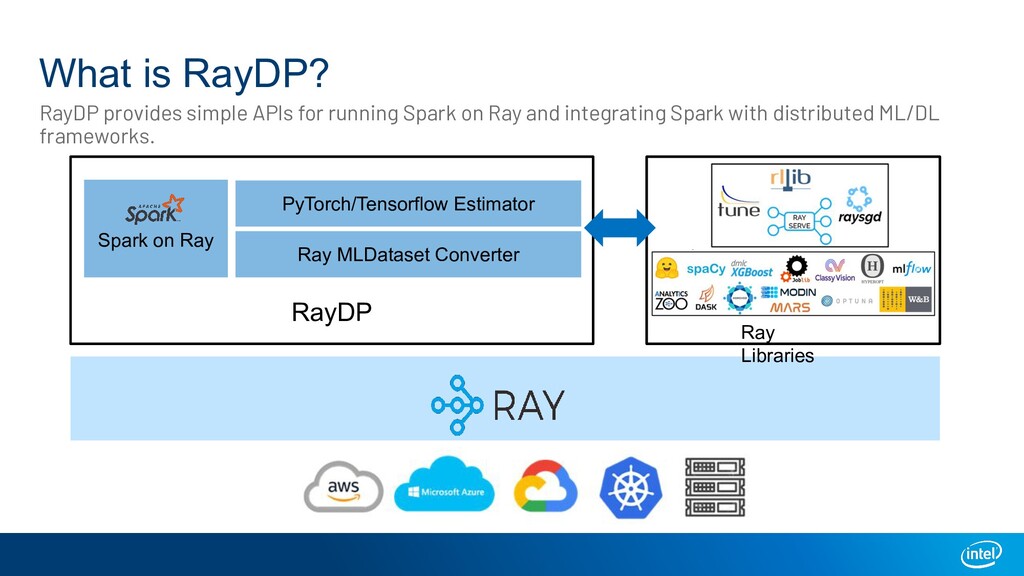
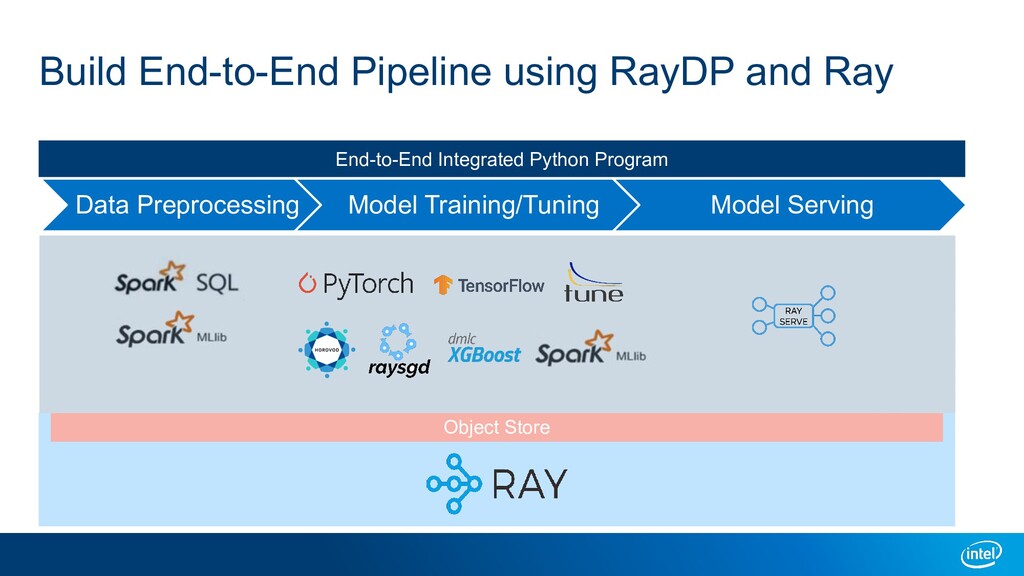
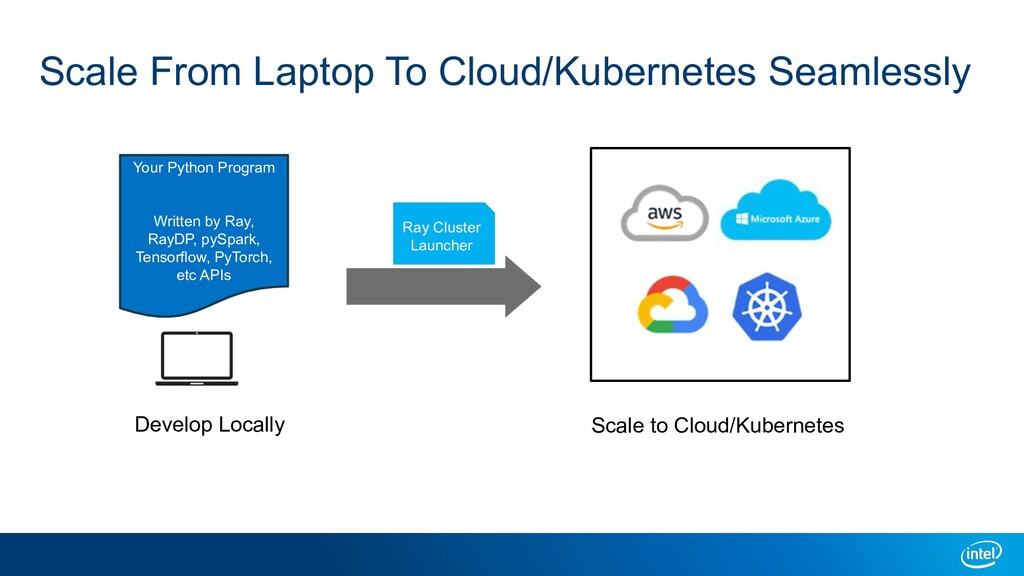
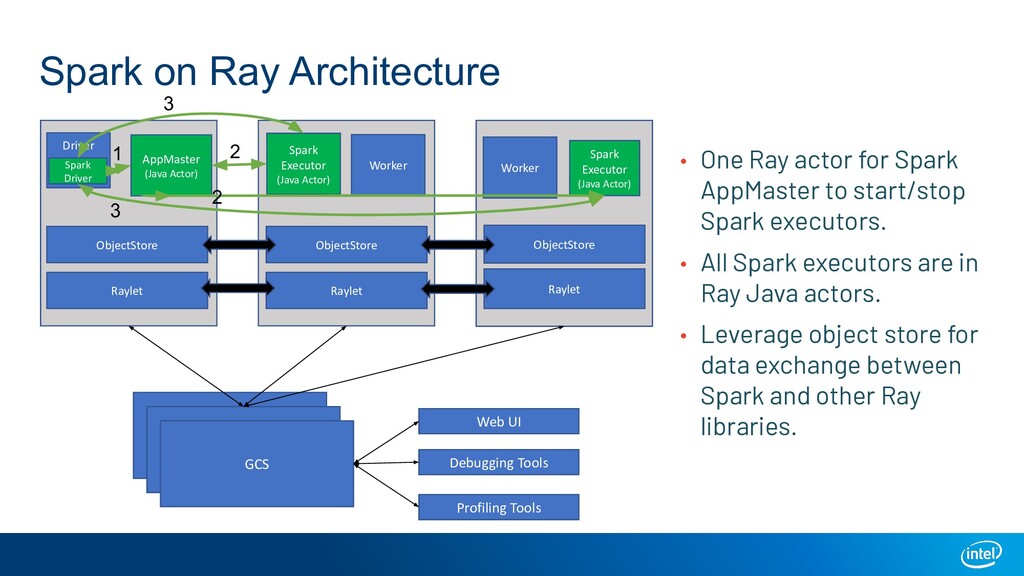
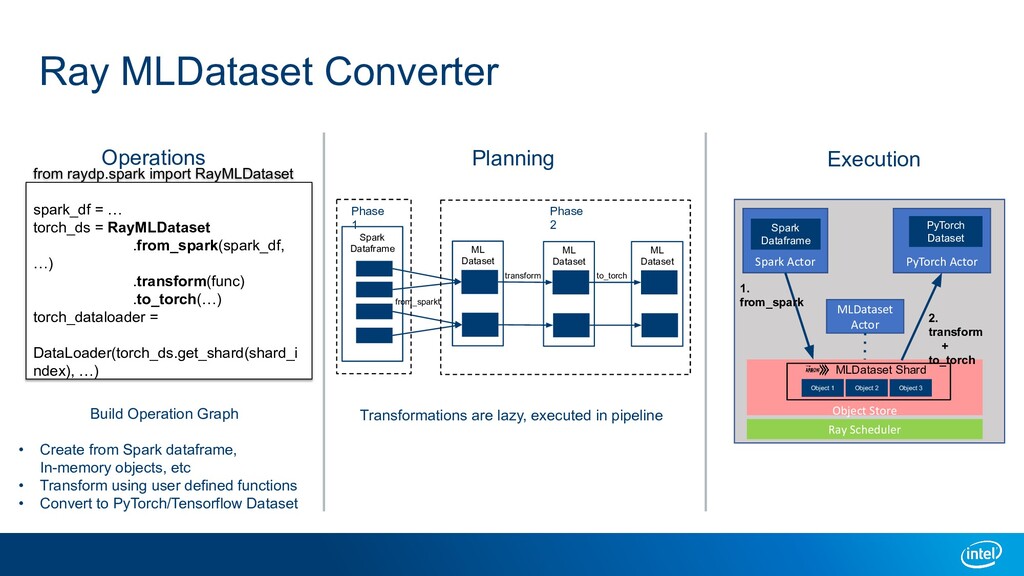
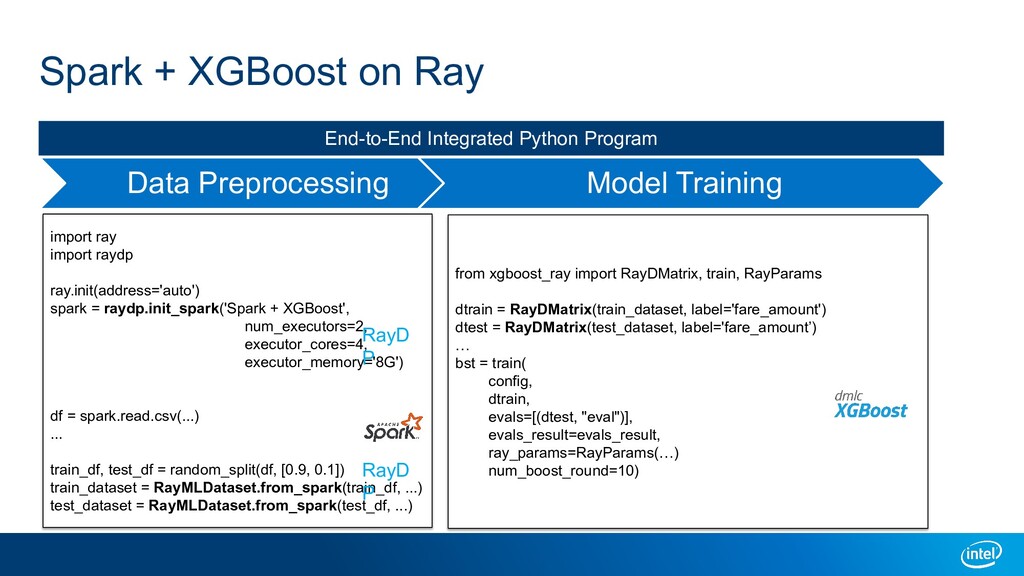
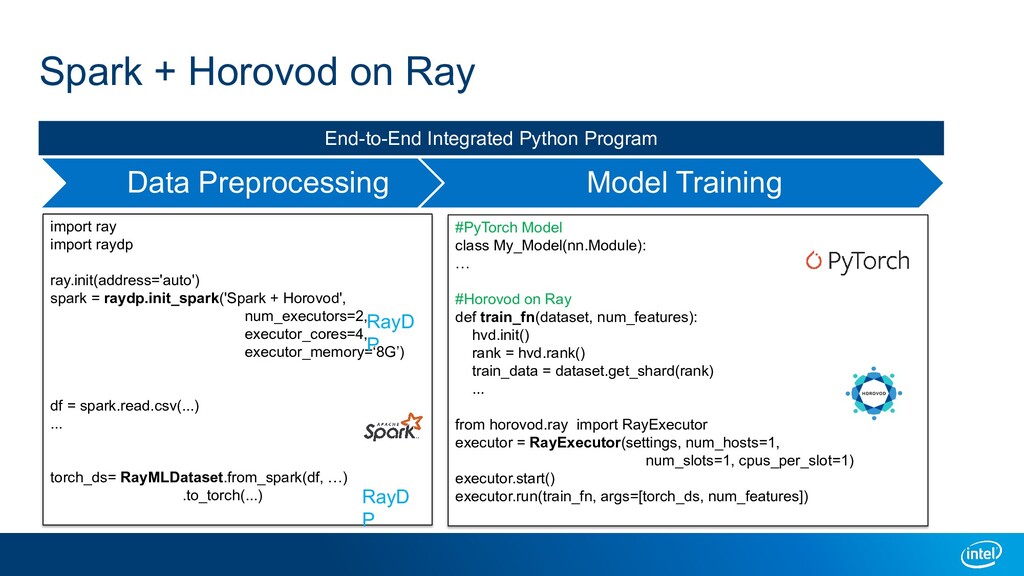
A large-scale end-to-end data analytics and AI pipeline usually involves data processing frameworks such as Spark for massive data preprocessing, and ML/DL frameworks for distributed training on the preprocessed data. A primitive setup is to use two separate clusters and glue multiple jobs. Other solutions include running deep learning frameworks in a Spark cluster, or use workflow orchestrators like Kubeflow to stitch distributed programs. All these options have their own limitations. We introduce Ray as a single substrate for distributed data processing and machine learning. We also introduce RayDP which allows you to start a Spark job on Ray in your python program and utilize Ray's in-memory object store to efficiently exchange data between Spark and other libraries. We will demonstrate how this makes building an end-to-end data analytics and AI pipeline simpler and more efficient.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}