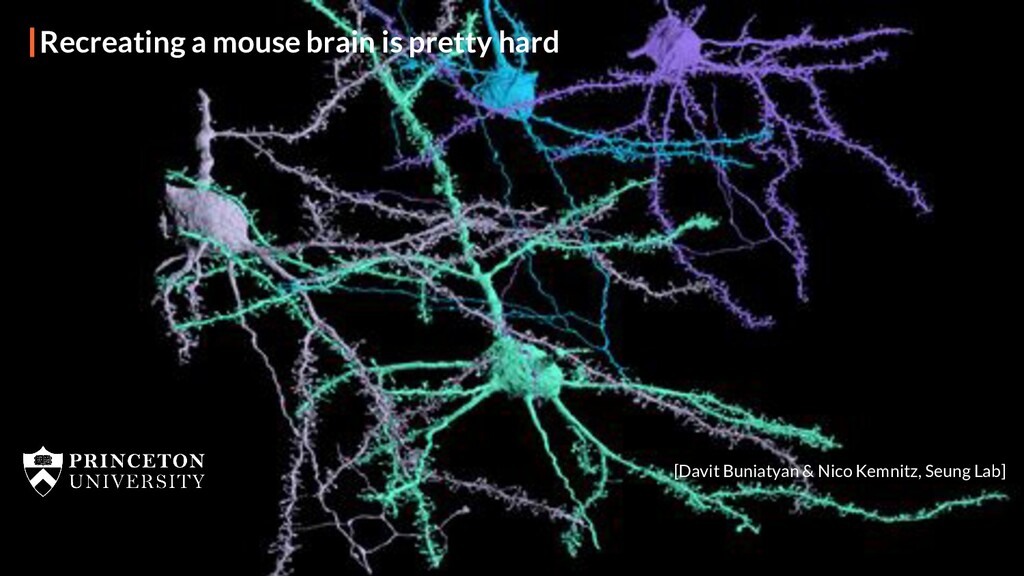
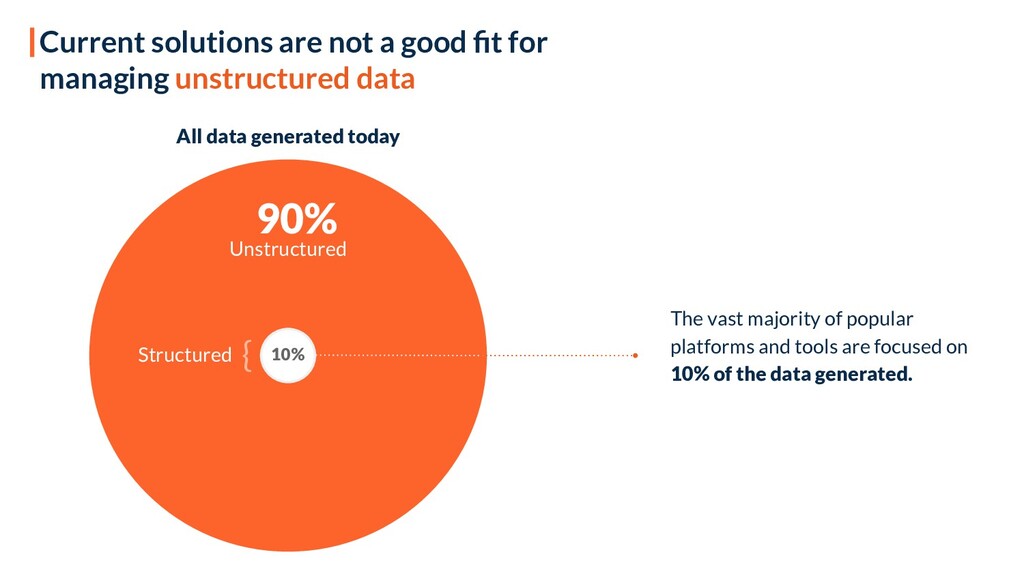
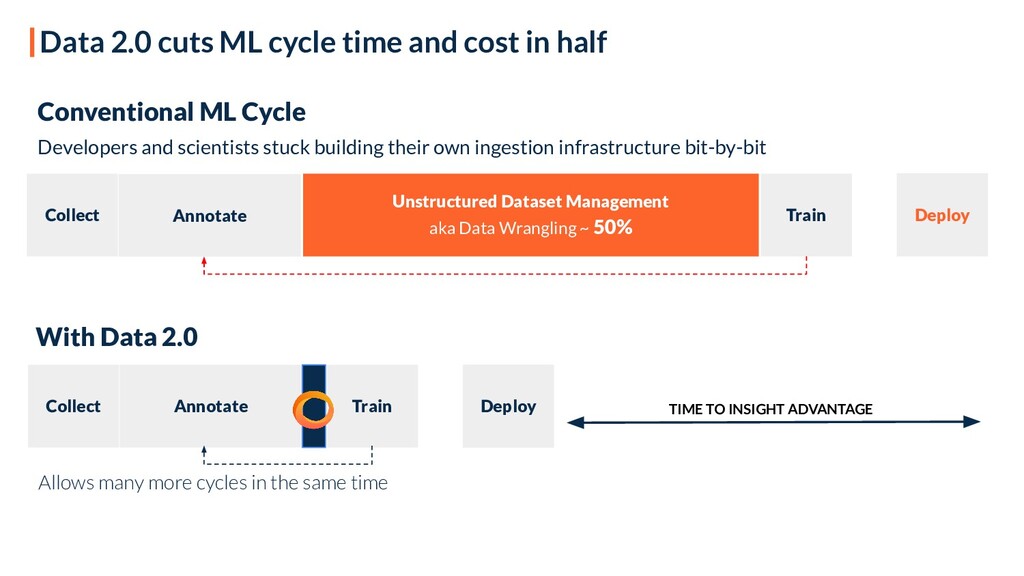
Every day, 90% of the data we generate is in unstructured form. However, current solutions for storing the data we create - Databases, Data Lakes, and Data Warehouses (or the Data 1.0 minions), are unfit for storing unstructured data. As a result, data scientists today work with unstructured data like developers used to work in the pre-database era. This slows down ML cycles, bottlenecks access speed and data transfer, and forces data scientists to wrangle with data instead of training models.
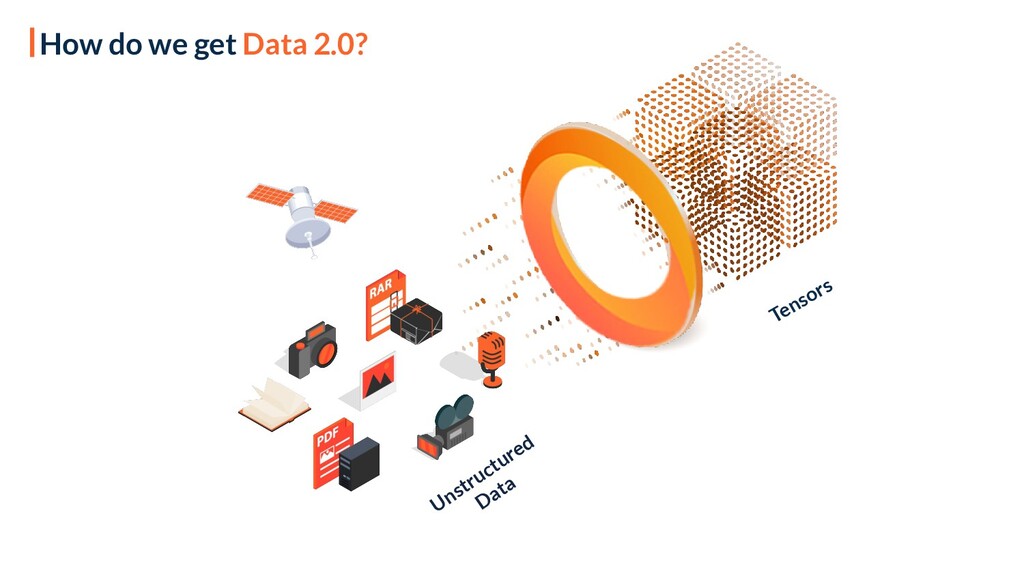
Creating Software 2.0 requires a new way of working with unstructured data, which we explore in this session. We present Data 2.0 - a framework bringing together all types of data under one umbrella, representing them in a unified tensorial form which is native to deep neural networks. The streaming process of the method is used for training and deploying machine learning models for both compute and data-bottlenecked operations as if the data is local to the machine. In addition, it allows version-controlling and collaborating on petabyte-scale datasets, as single numpy-like arrays on the cloud or locally. Lastly, we use Ray to improve our workflows.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}