access and analyze data on-demand Power digital experiences and intelligence Swift Predictions Machine-learning-as-a-service Harness a catalog of adaptive algorithms Embed predictive APIs to make your apps smarter
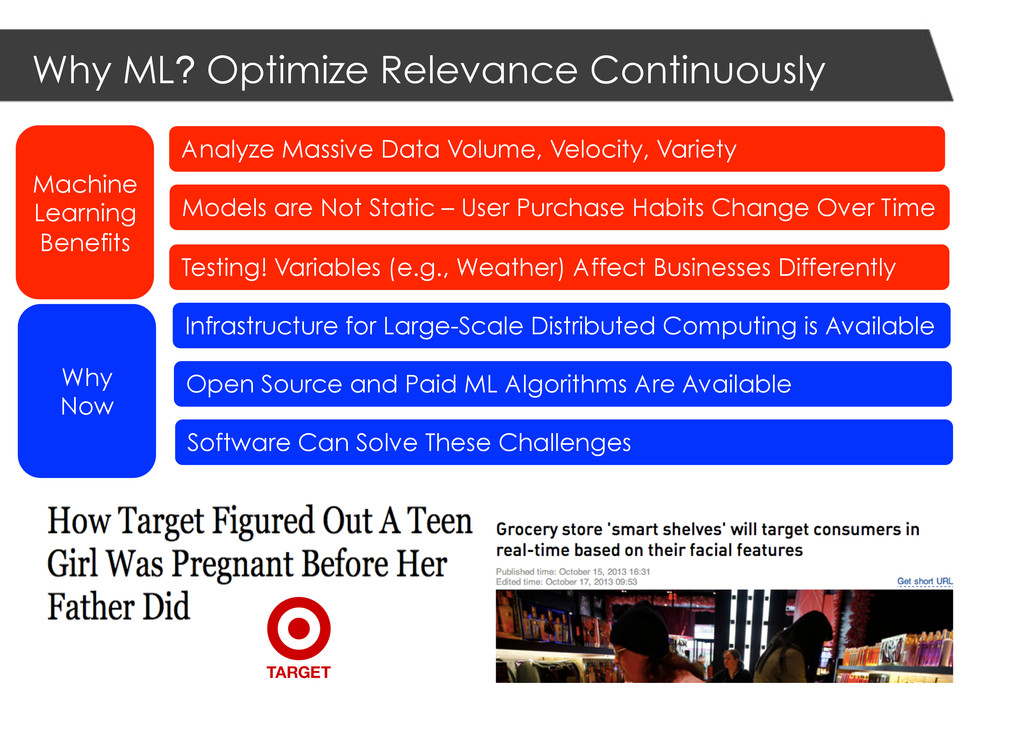
Variety Models are Not Static – User Purchase Habits Change Over Time Testing! Variables (e.g., Weather) Affect Businesses Differently Infrastructure for Large-Scale Distributed Computing is Available Open Source and Paid ML Algorithms Are Available Software Can Solve These Challenges Machine Learning Benefits Why Now
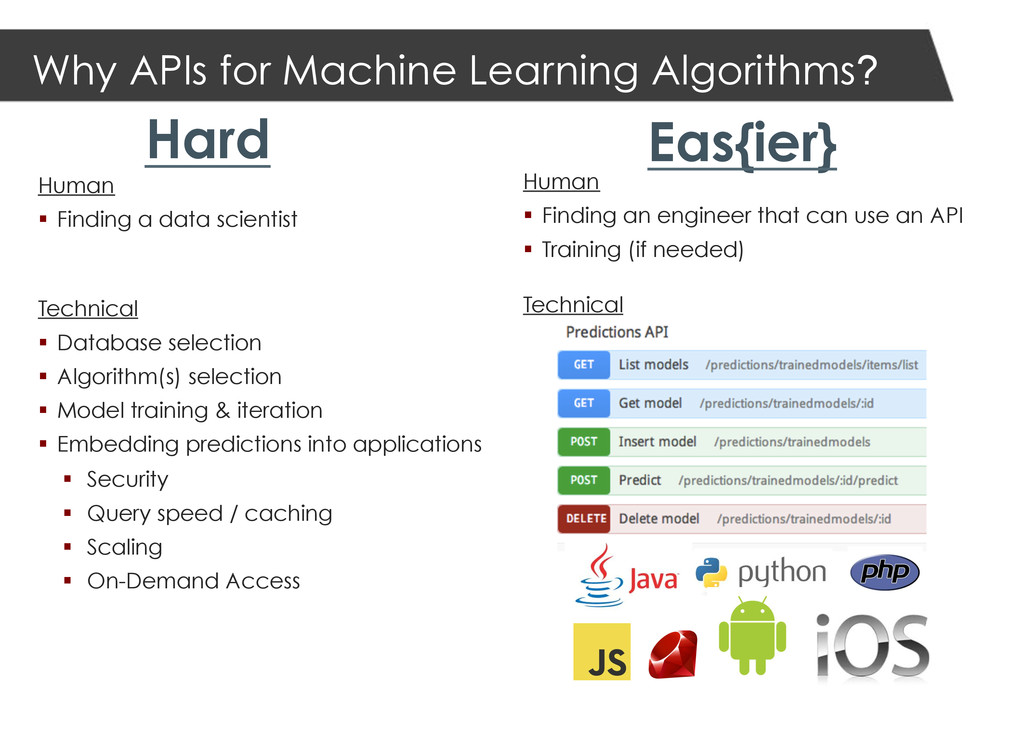
Finding a data scientist Technical Database selection Algorithm(s) selection Model training & iteration Embedding predictions into applications Security Query speed / caching Scaling On-Demand Access Human Finding an engineer that can use an API Training (if needed) Technical
finds items users might like Frequent Pattern Mining: Discovers unique frequently co-occurring items in a transaction list Classification: Learns from existing categorized data and assigns a category to uncategorized data Clustering: Organizes items from a large volume of data into groups of similar items and features
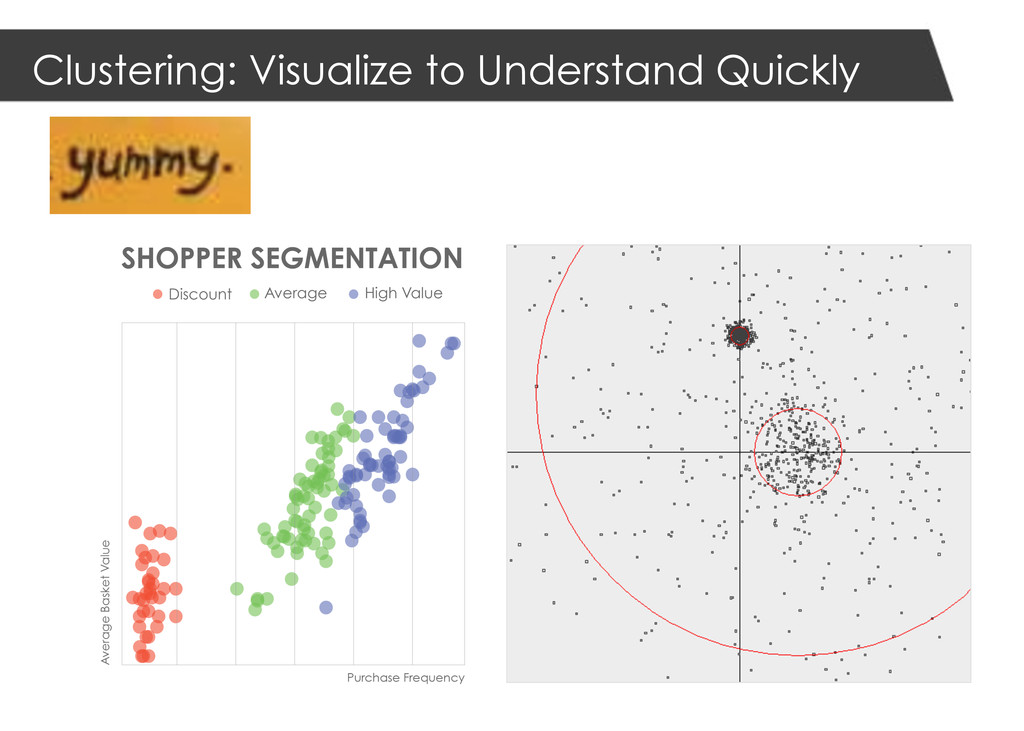
the user likes and finds similar items (“I like the Chicago Bulls, I may like the Chicago Bears”) User Recommendation: recommend items finding similar users and sees what they like (e.g., Kin and I are friends. He likes IPAs. I may like IPAs) Product Affinity: if X user wants X, what else is Y user likely to want based on the relationship between X and Y (men who buy diapers, also tend to buy beer) Predict Inventory: based on history, predict future sales (next 7, 30 days, etc.) Discover Customer Segments: examine purchasing habits to identify clusters of shopper segments Prevent Fraud: identify anomalies in cashier activity, such as voids (is this likely fraud? yes/no)
history (user ID, past purchases) Web behavior (page views, adds to cart) Segmentation (age, income) Search path (keywords, items bought) 2. Run algorithm 3. Query User ID Response Returns a score for items that are deemed relevant based on item/score pair
to a SKU (not continuous) Model Training {Inputs} Inventory: date, purchase history, other (offers) Evaluation: # instances, mean squared error Query a SKU Search: keywords, adds to cart, orders Evaluation: # instances, accuracy score (0.80) Query a keyword or feature (e.g., area rugs) Response 6.686672
Visual appearance: Casual Job: Entrepreneur IP Address: San Francisco Buys: T-Shirts & Jeans Name Male Frequent traveler Love APIs Love IPAs Browses: tech sites Visual appearance: Formal Job: Public employee IP Address: Washington DC Buys: Suits & Tie Browses: Gov websites
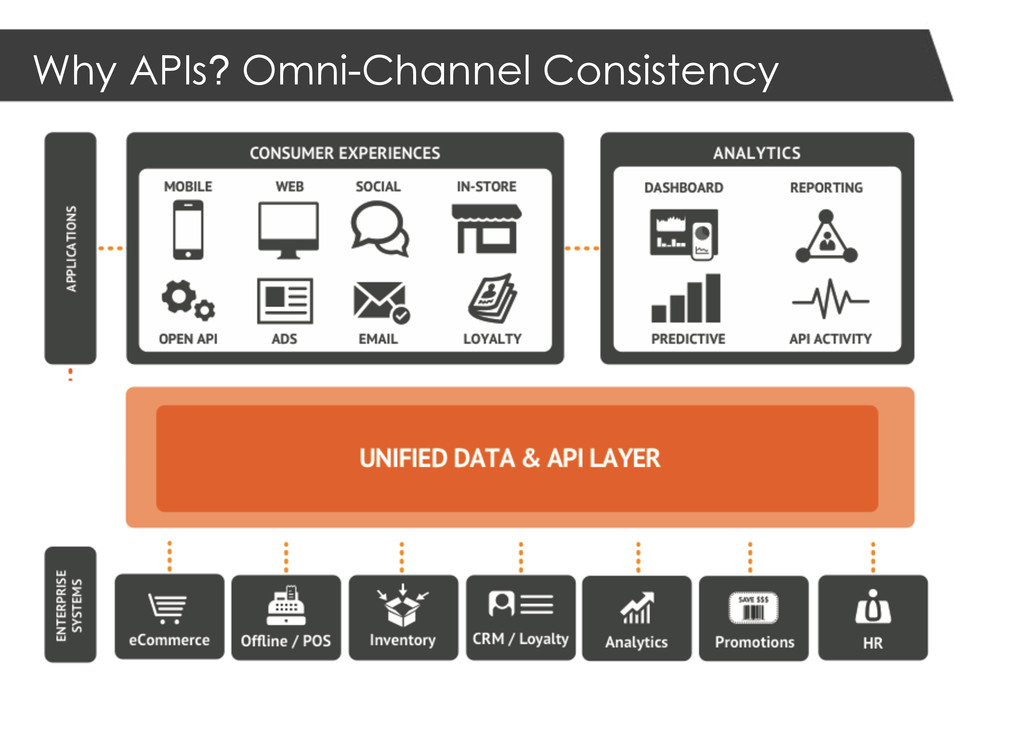
be relevant always in the now Adaptive Intelligence v1.0 = machine readable data (APIs) / collaboration v2.0 = automate decisions with machine learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Frequent Pattern Mining API Response Pattern Count [milk, bread],1](https://files.speakerdeck.com/presentations/b33b94c0226e013194623e9c5344185b/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}