Big Things Meetup -- Tel Aviv
http://www.meetup.com/Big-things-are-happening-here/events/225339994/
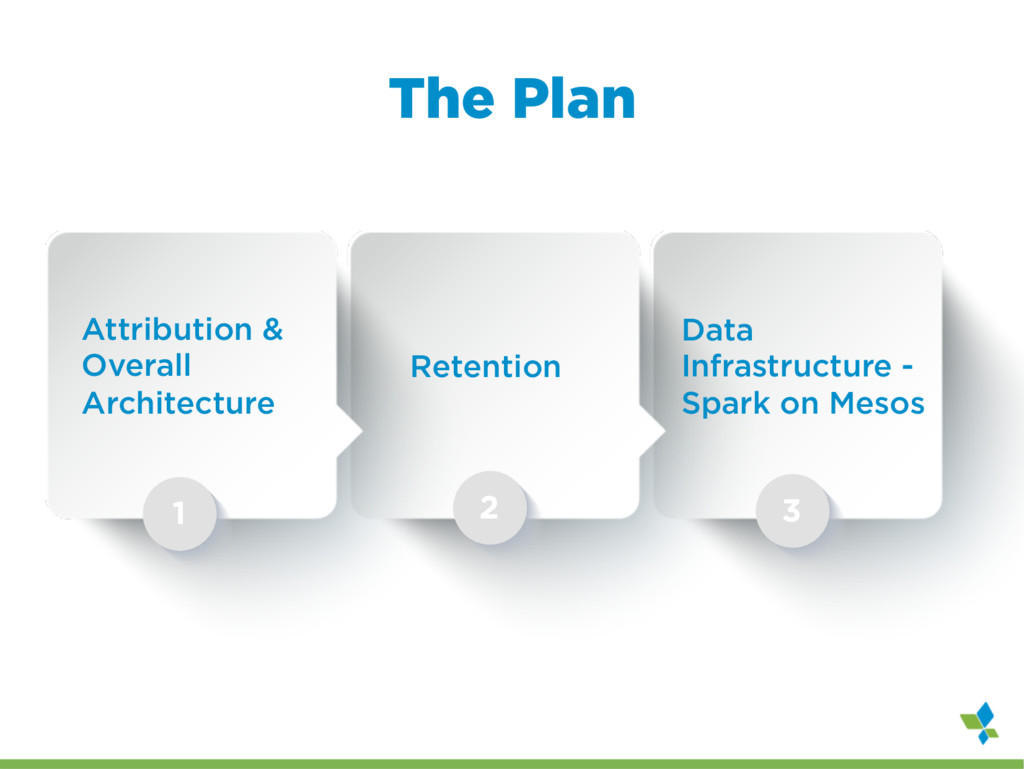
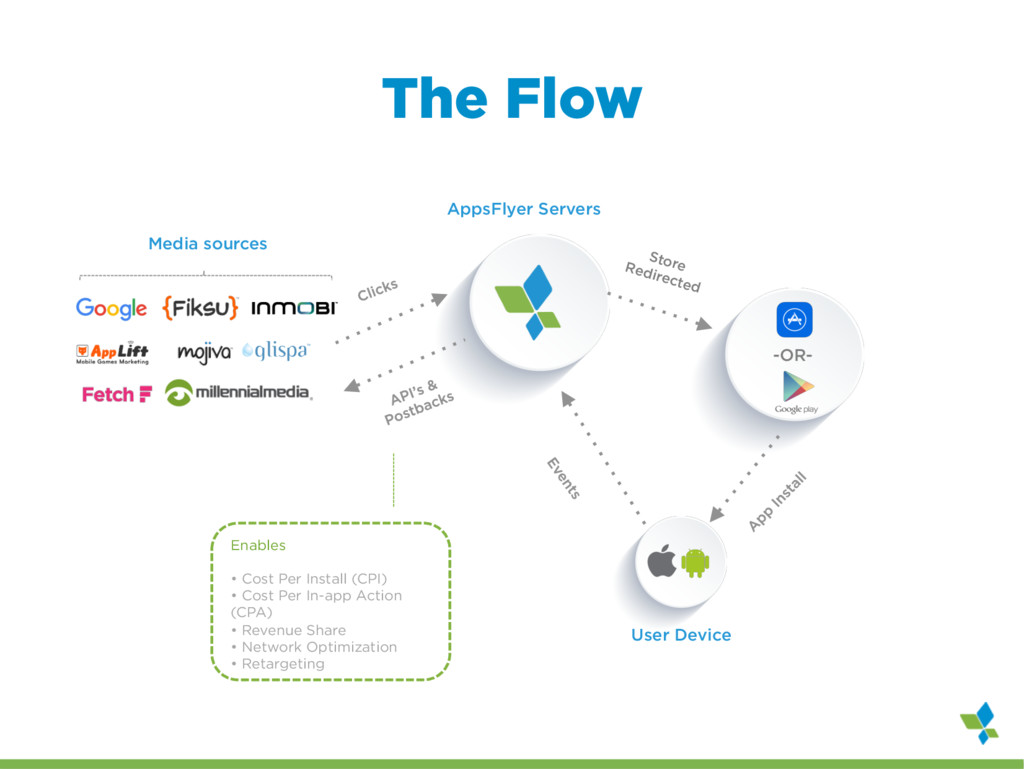
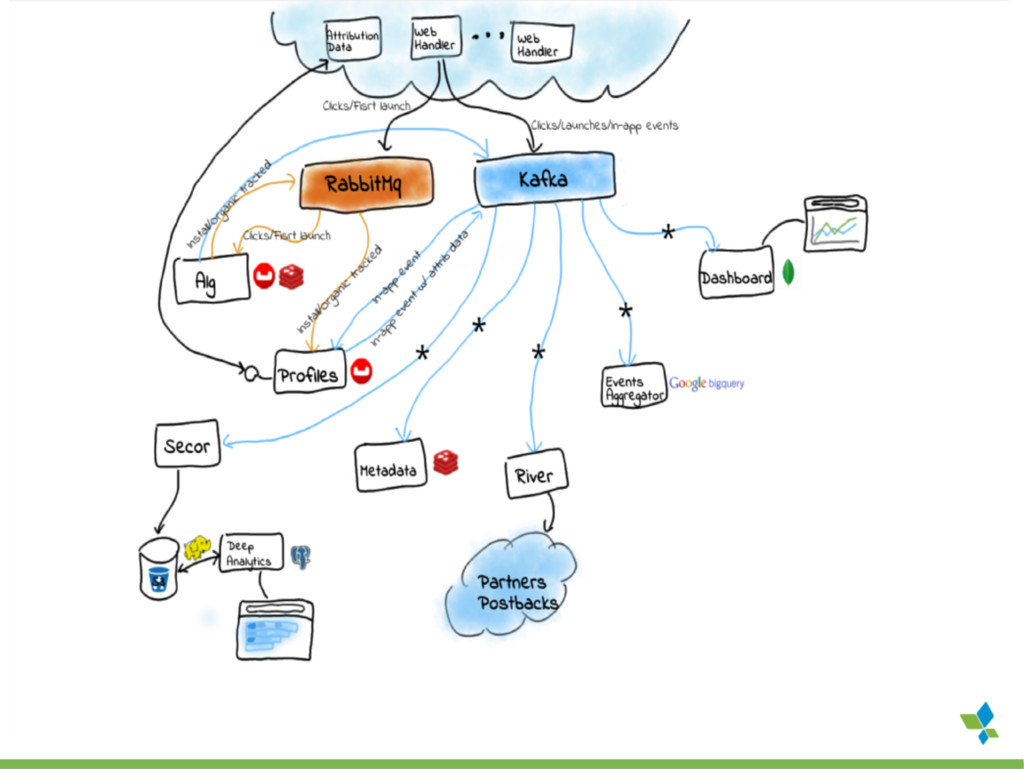
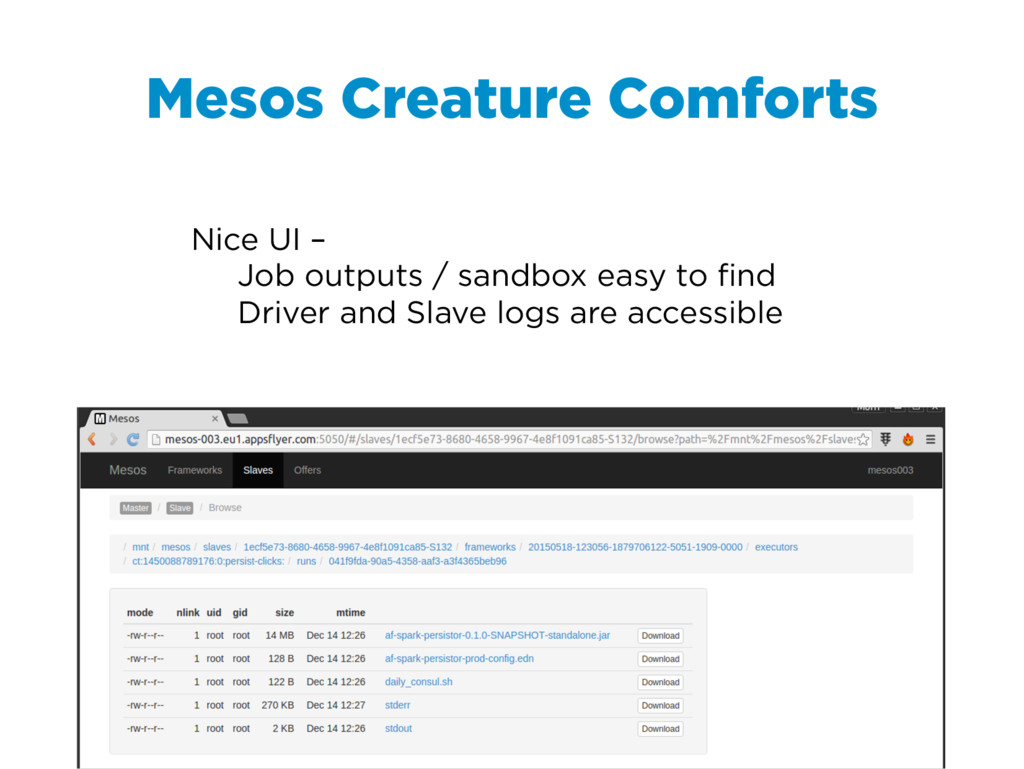
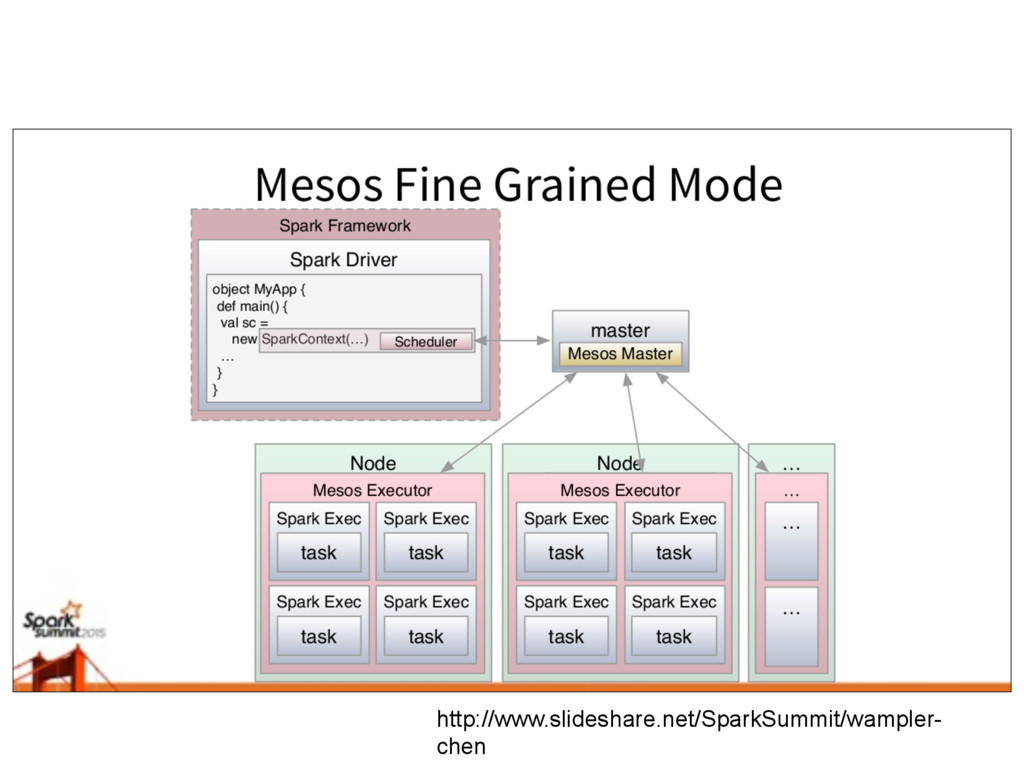
As a startup, we've had the luxury of developing our batch processing infrastructure from scratch allowing us to incorporate some unconventional combinations of technologies. I will outline our current infrastructure, Spark running over mesos with data stored exclusively on S3 as a mixture of raw data in Hadoop sequence files and Parquet files, and explain the advantages it offers us over a more typical setup with Spark running on top of YARN backed by HDFS. However, running spark in this way has not been without challenges and a few set backs. I will highlight a few of the larger problems we encountered and what we did to solve them. Despite the challenges, choosing Spark has opened up many possibilities for us. To highlight the performance and flexibility we gained by using Spark, I will dive into one process, Retention, that we originally implemented using Cascalog (Datalog translated into Cascading/Hadoop) and then rewrote as a Spark job.
Morri's bio -
Morri studied epi-genetics as a post-doc at the Weizmann institute and has
PhD in Biophysics from University of California San Francisco. He left the world of academia to crack Big Data problems. That's why he joined the AppsFlyer Dev team.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
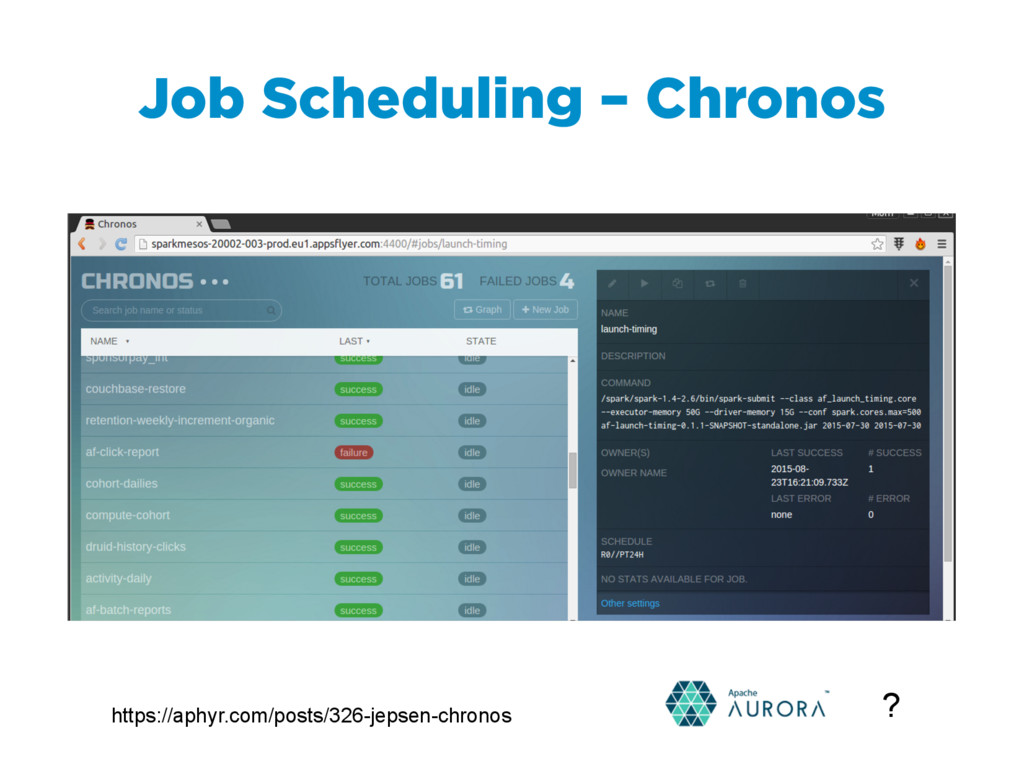{kind=link}
{kind=link}
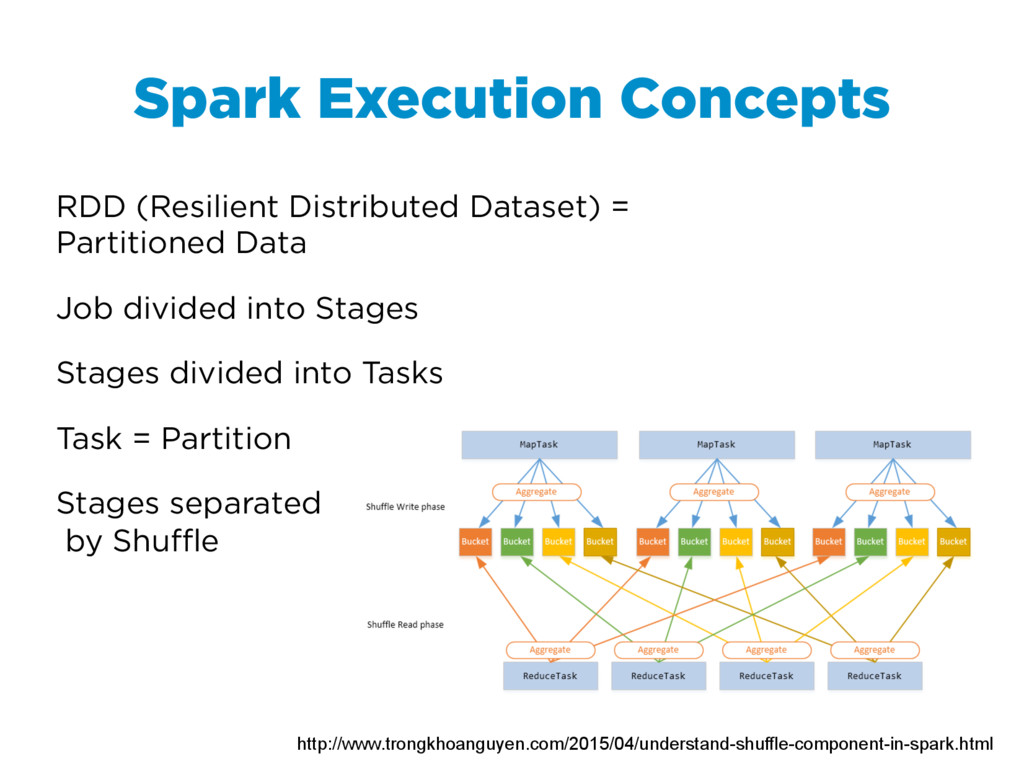{kind=link}
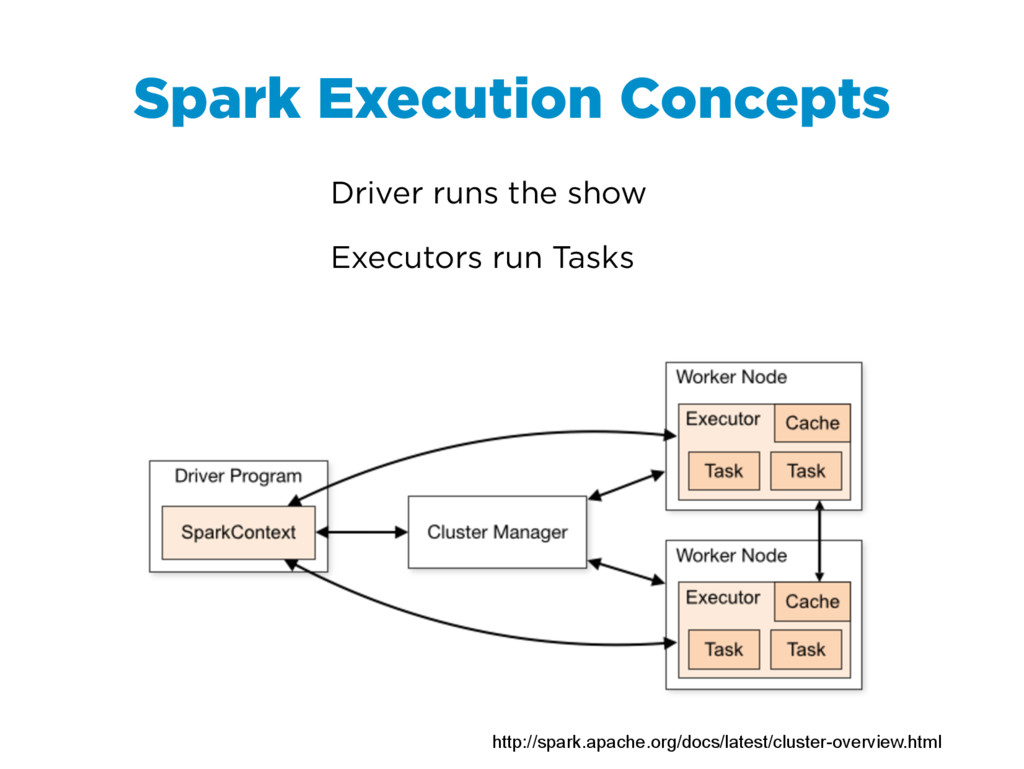{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
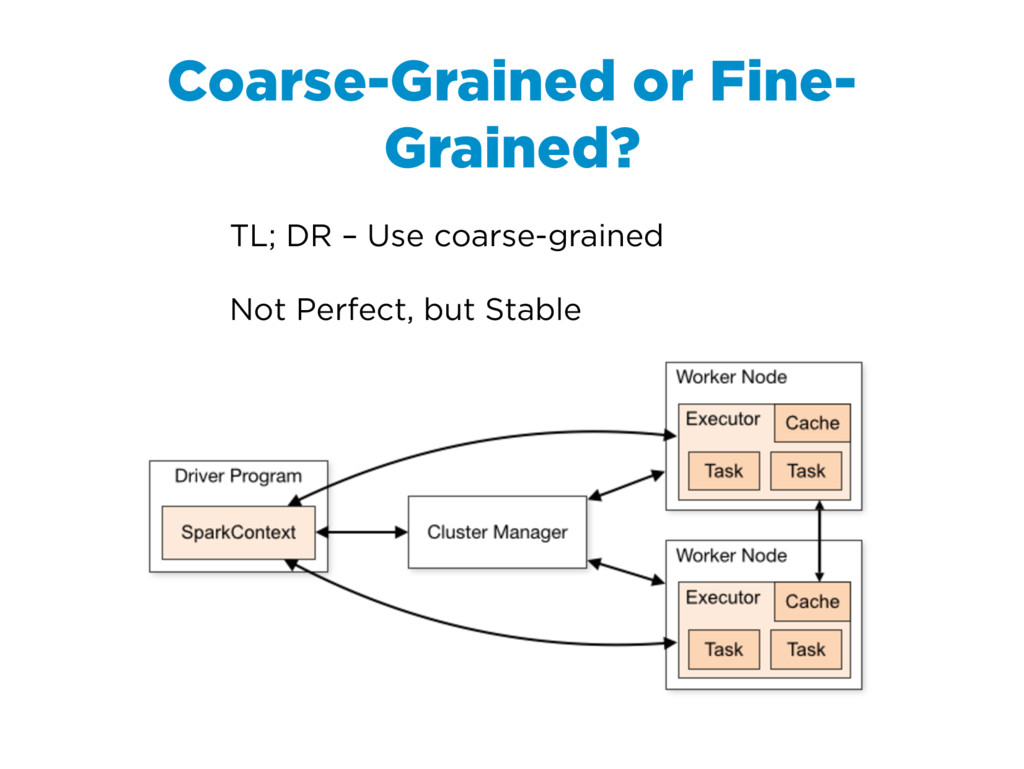{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}