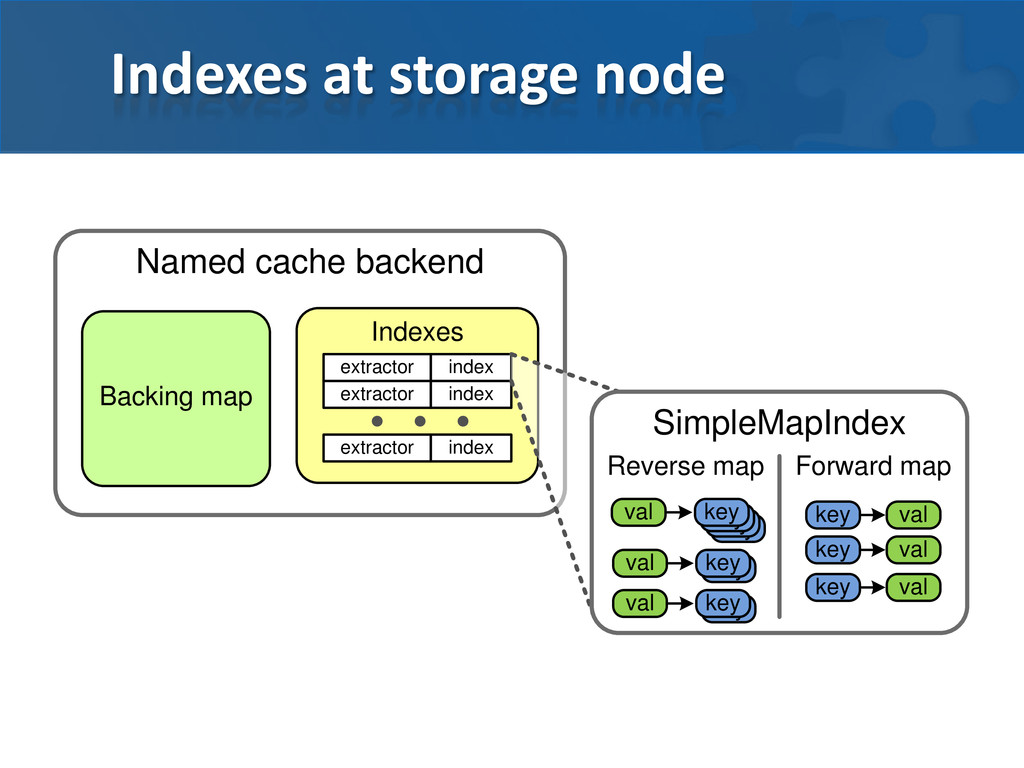
are stored in map • Reverse map is used to speed up filters • Forward map is used to speed up aggregators Custom extractors should obey equals/hashCode contract! QueryMap.Entry.extract(…) is using index, if available
heap • and may consume a lot of memory For partitioned scheme • keys in index are binary blobs, • regular object, otherwise Indexes will keep your key in heap even if you use off heap backing map Single index for all primary partitions of cache on single node
calculateEffectiveness(Map im, Set keys); Filter applyIndex(Map im, Set keys); } • applyIndex(…) is called by cache service on top level filter • calculateEffectiveness(…) may be called by compound filter on nested filters • each node executes index individually • For complex queries execution plan is calculated ad hoc, each compound filter calculates plan for nested filters
for matching index using extractor instance as key If index found, lookup index reverse map for value intersect provided candidate set with key set from reverse map return null – candidate set is accurate, no object filtering required else (no index found) return this – all entries from candidate set should be deserialized and evaluated by filter
AndFilter( new EqualsFilter(“getTicker”, “IBM”), new EqualsFilter(“getSide”, „B‟)) Execution plan • call applyIndex(…) on first nested filter – only entries with ticker IBM are retained in candidate set • call applyIndex(…) on second nested filter – only entries with side=B are retained in candidate set • return candidate set
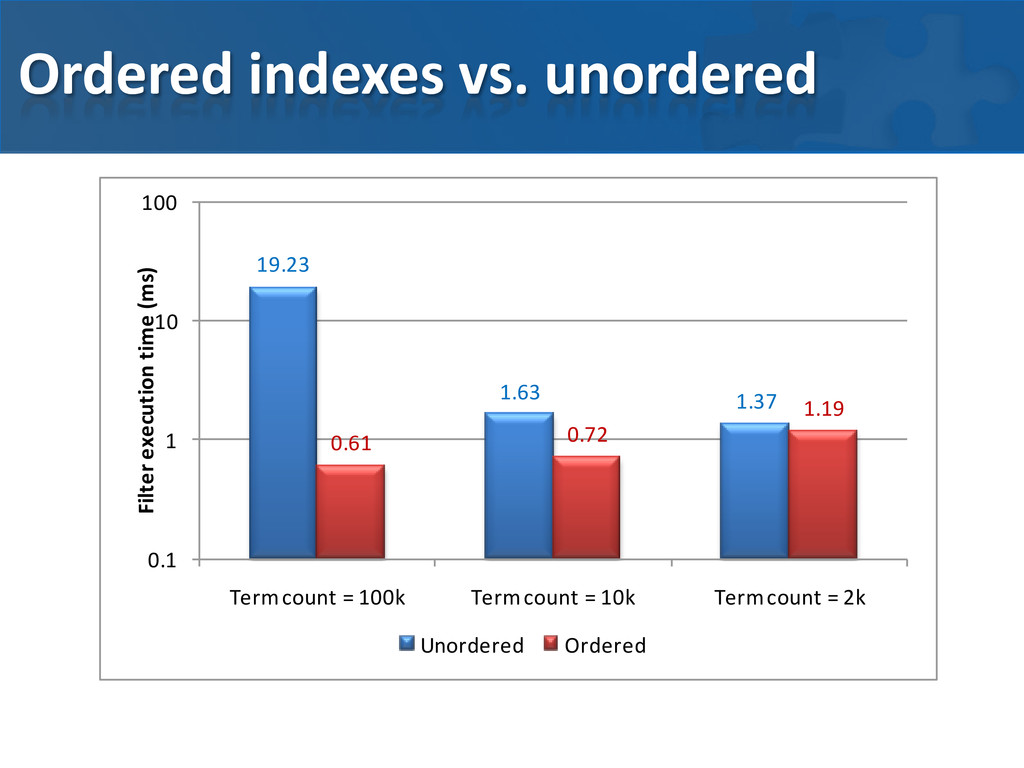
deserialization overhead CONs • very simplistic cost model in index planner • candidate set is stored in hash tables (intersections/unions may be expensive) • high cardinality attributes may cause problems
new AndFilter( new EqualsFilter(“getTicker”, “IBM”), new EqualsFilter(“getSide”, „B‟)) Index for compound attribute new EqualsFilter( new MultiExtractor(“getTicker, getSide”), Arrays.asList(new Object[]{“IBM”, „B‟})) For index to be used, filter’s extractor should match extractor used to create index!
index class (extends MapIndex) • Custom filter, aware of custom index + • Thread safe implementation • Handle both binary and object keys gracefully • Efficient insert (index is updates synchronously)
any advanced data structure tailored for specific queries. • NGram index – fast substring based lookup • Apache Lucene index – full text search • Time series index – managing versioned data
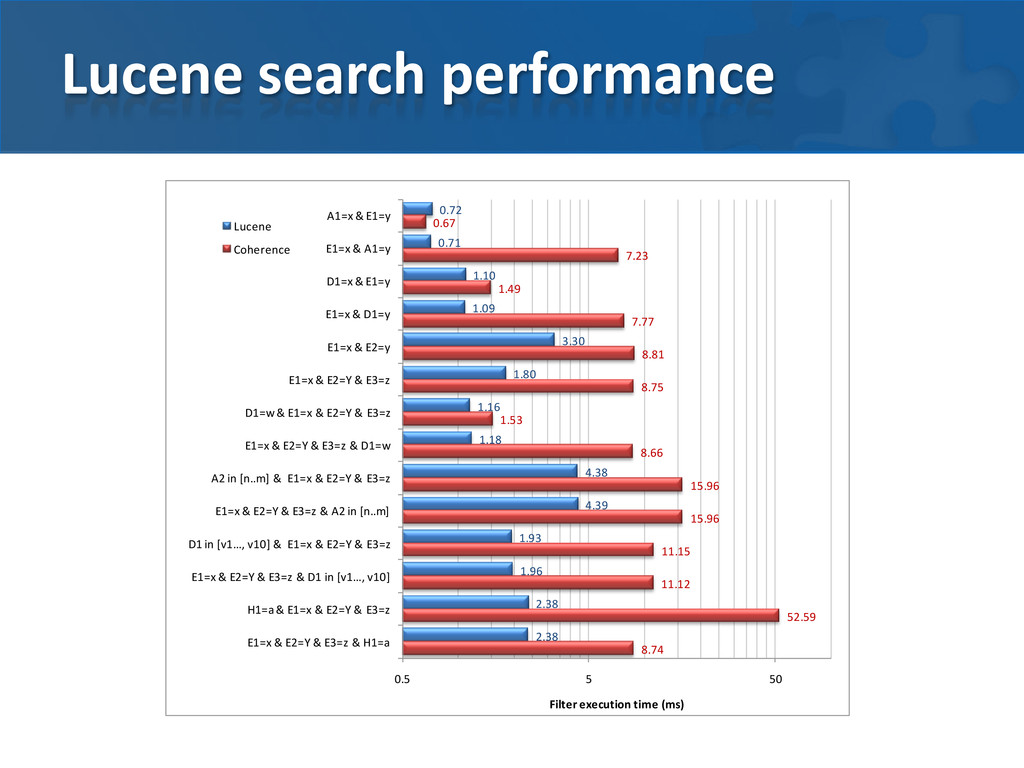
/ rich queries • Zero index maintenance PROs • Index partitioning by Coherence • Faster execution of many complex queries CONs • Slower updates • Text centric
need to define how our object will map // to field in Lucene document LuceneDocumentExtractor extractor = new LuceneDocumentExtractor(); extractor.addText("title", new ReflectionExtractor("getTitle")); extractor.addText("author", new ReflectionExtractor("getAuthor")); extractor.addText("content", new ReflectionExtractor("getContent")); extractor.addText("tags", new ReflectionExtractor("getSearchableTags")); Step 2. Create index on cache // next create LuceneSearchFactory helper class LuceneSearchFactory searchFactory = new LuceneSearchFactory(extractor); // initialize index for cache, this operation actually tells coherence // to create index structures on all storage enabled nodes searchFactory.createIndex(cache);
index is ready and we can search Coherence cache // using Lucene queries PhraseQuery pq = new PhraseQuery(); pq.add(new Term("content", "Coherence")); pq.add(new Term("content", "search")); // Lucene filter is converted to Coherence filter // by search factory cache.keySet(searchFactory.createFilter(pq));
// You can also combine normal Coherence filters // with Lucene queries long startDate = System.currentTimeMillis() - 1000 * 60 * 60 * 24; // last day long endDate = System.currentTimeMillis(); BetweenFilter dateFilter = new BetweenFilter("getDateTime", startDate, endDate); Filter pqFilter = searchFactory.createFilter(pq); // Now we are selecting objects by Lucene query and apply // standard Coherence filter over Lucene result set cache.keySet(new AndFilter(pqFilter, dateFilter));
last version for series k select * from versions where series=k and version = (select max(version) from versions where key=k) Series key Entry id Timestamp Payload Entry key Entry value Cache entry
![Advanced usage of indexes in Oracle Coherence Alexey Ragozin [email protected]](https://files.speakerdeck.com/presentations/4eb8c065f35df4017c002fd7/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Alexey Ragozin [email protected] http://aragozin.blogspot.com - my articles http://code.google.com/p/gridkit](https://files.speakerdeck.com/presentations/4eb8c065f35df4017c002fd7/slide_23.jpg){kind=link}