“A Reliable Effective Terascale Linear Learning System,” J. Mach. Learn. Res., vol. 15, no. 1, pp. 1111–1133, Jan. 2014. [2]M. Zinkevich, M. Weimer, L. Li, and A. J. Smola, “Parallelized stochastic gradient descent,” in Advances in neural information processing systems, 2010, pp. 2595–2603. [3]K. Weinberger, A. Dasgupta, J. Langford, A. Smola, and J. Attenberg, “Feature Hashing for Large Scale Multitask Learning,” in Proceedings of the 26th Annual International Conference on Machine Learning, New York, NY, USA, 2009, pp. 1113–1120. [4]O. Dekel, R. Gilad-Bachrach, O. Shamir, and L. Xiao, “Optimal distributed online prediction using mini-batches,” The Journal of Machine Learning Research, vol. 13, no. 1, pp. 165–202, 2012.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
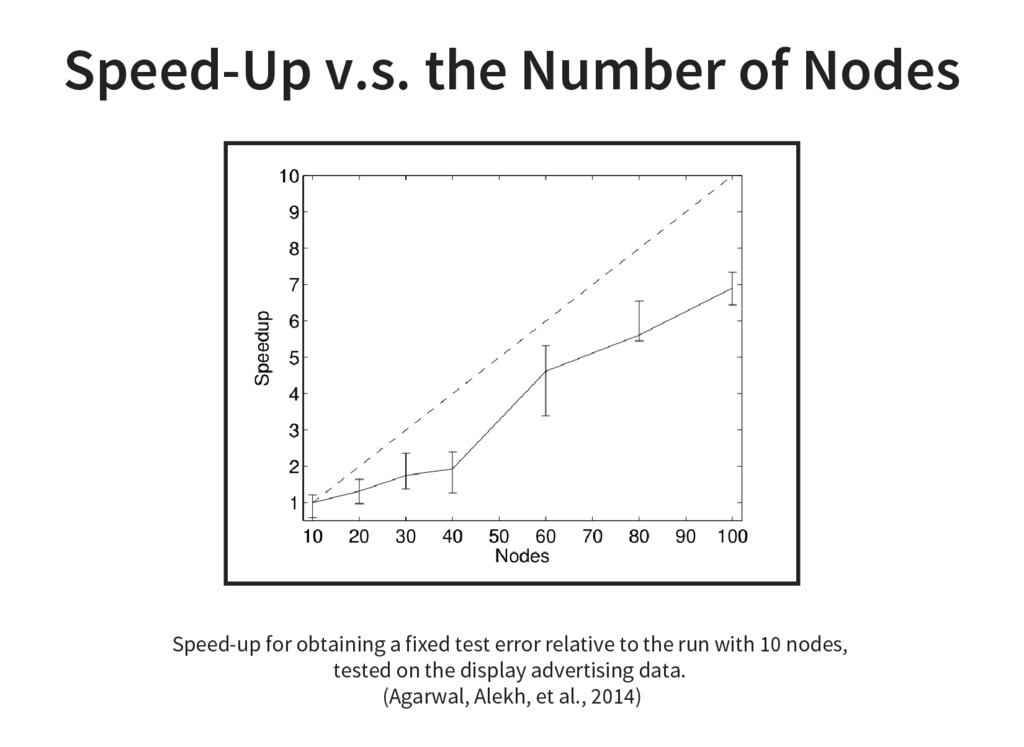{kind=link}
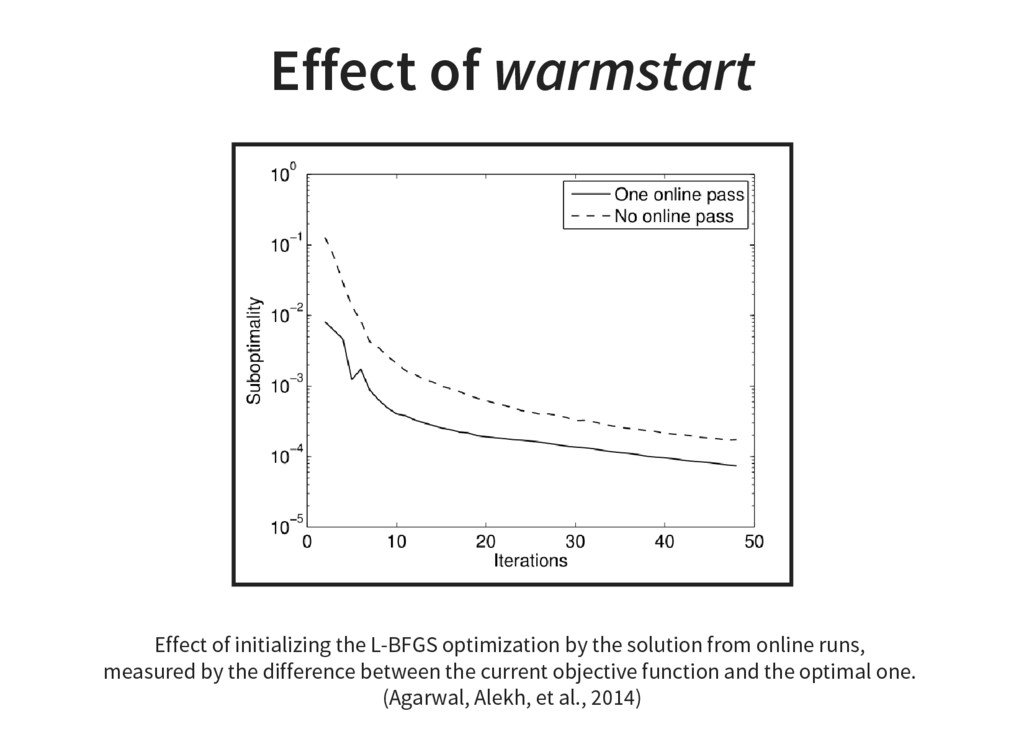{kind=link}
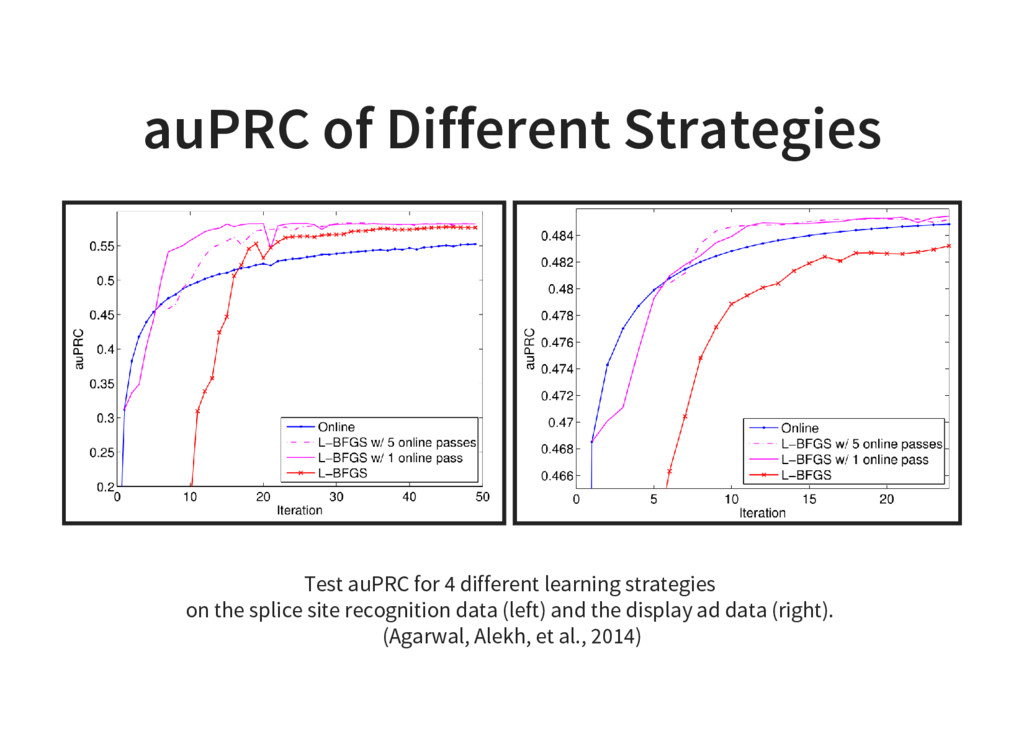{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
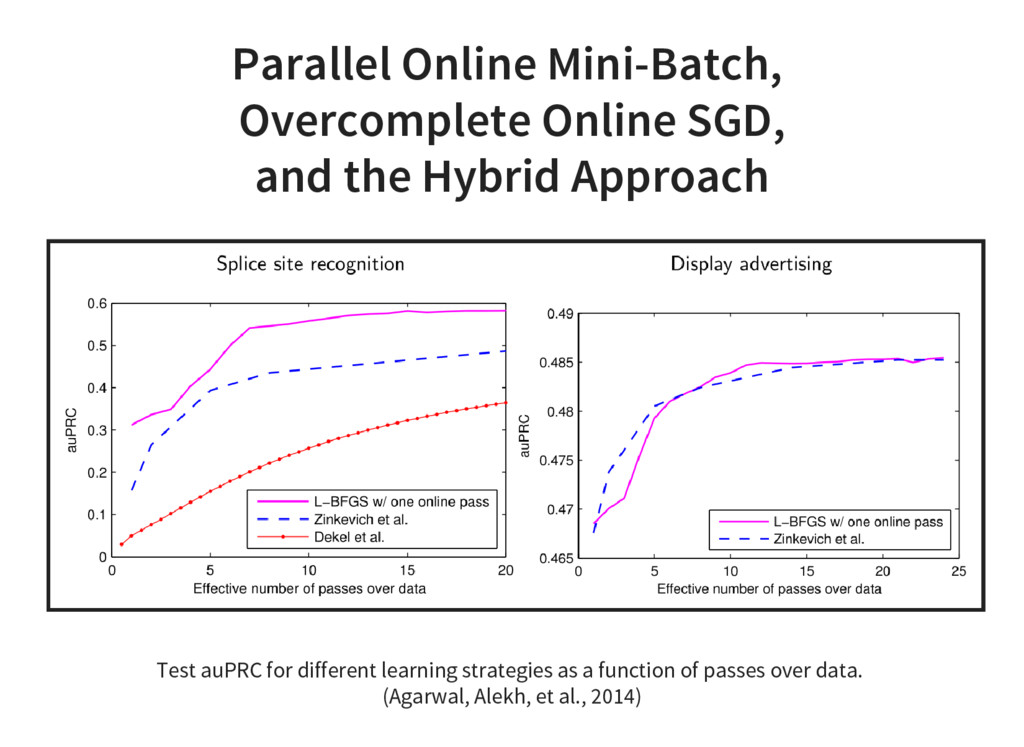{kind=link}
{kind=link}
![References [1]A. Agarwal, O. Chapelle, M. Dudík, and J. Langford,](https://files.speakerdeck.com/presentations/96cc13f4c20b4438906e47a3f74640c8/slide_47.jpg){kind=link}
{kind=link}