Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
統計勉強会2020 統計学の基礎と分析方法
Search
Daiki Nakamura
October 29, 2020
Education
920
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
統計勉強会2020 統計学の基礎と分析方法
2020年 10 月 29 日~ 11 月 20 日 広島大学
Daiki Nakamura
October 29, 2020
More Decks by Daiki Nakamura
See All by Daiki Nakamura
諸外国の理科カリキュラムにおけるビッグアイデアの構造比較
arumakan
0
890
国際調査ROSESの標本調査設計および調査実施の工夫
arumakan
0
83
適切な回帰推定量の使用が学力調査の推定精度を向上させる効果の検討
arumakan
0
120
Developing a Diverse Interests Scale for STEM Learners: Based on the ROSES Survey in Japan
arumakan
0
120
条件制御能力を測定するコンピュータ適応型テストの開発
arumakan
0
310
科学教育の読書会を中心とした新しい研究活動の展開
arumakan
0
290
The Value of Science Education in an Age of Misinformation
arumakan
1
400
教育研究における研究倫理問題の論点整理
arumakan
0
720
TIMSS 2019 環境認識尺度に関する日本人学習者の特徴
arumakan
0
510
Other Decks in Education
See All in Education
Public Space Is Not For Sale
drikkes
0
120
Center for Entrepreneurship Education | Science Tokyo (Institute of Science Tokyo)
sciencetokyo
PRO
0
110
現場最前線から教えるデータサイエンス1 -ITベンダーにおけるデータサイエンティスト-
hidetoshikawaguchi
0
130
Human-AI Interaction - Lecture 11 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
1.1k
Visionary Initiative: Materials-Positive Society 「モノの進化をポジティブな社会の原動力に」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
640
Examen de Selectividad. Geografía junio 2026 (Convocatoria Ordinaria). UCLM
juanmartin2026
1
1.7k
Stardy 会社紹介資料
stardy
0
2.6k
【デザイナー就活講座】 デザイナー就活市場・企業探し・ポートフォリオのポイント
koheihasebe
0
250
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
550
DECADE_ゴルフ_コースマネジメント完全ガイド.pdf
ozekinote
0
120
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
350
면접관 눈에 띄는 데이터 분석 포트폴리오 만드는 법 | 2026년 5월 세미나
datarian
0
880
Featured
See All Featured
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Automating Front-end Workflow
addyosmani
1370
210k
Building the Perfect Custom Keyboard
takai
2
810
GraphQLとの向き合い方2022年版
quramy
50
15k
KATA
mclloyd
PRO
35
15k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Visualization
eitanlees
152
17k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
A designer walks into a library…
pauljervisheath
211
24k
Transcript
統計勉強会2020 統計学の基礎と分析方法 2020年10月29日~11月20日 @広島大学 広島大学大学院D2 中村大輝
1 本勉強会の方針 目的: 統計学の基礎と実際の分析方法を習得する • 初歩的な統計学の基礎を概説する • 架空のデータを用いて、様々な分析の演習 • 卒論研究に必要な一連の分析技術を習得
× 〇 分からない できない できる 分かる
2 なぜ、いま統計力が必要か •EBM(Evidence-based medicine) •EBPM(Evidence-based policy making) •EBE(Evidence-based education) →証拠に基づく意思決定
•実証研究に必要不可欠 •調査デザインにも影響 •統計教育の広がり メタ分析 無作為化比較 試験(RCT) 比較実践研究 要因対照研究 事例報告 専門家の意見 個人の意見(体験談) 高 低 エビデンスピラミッド (根拠の信頼性) 量
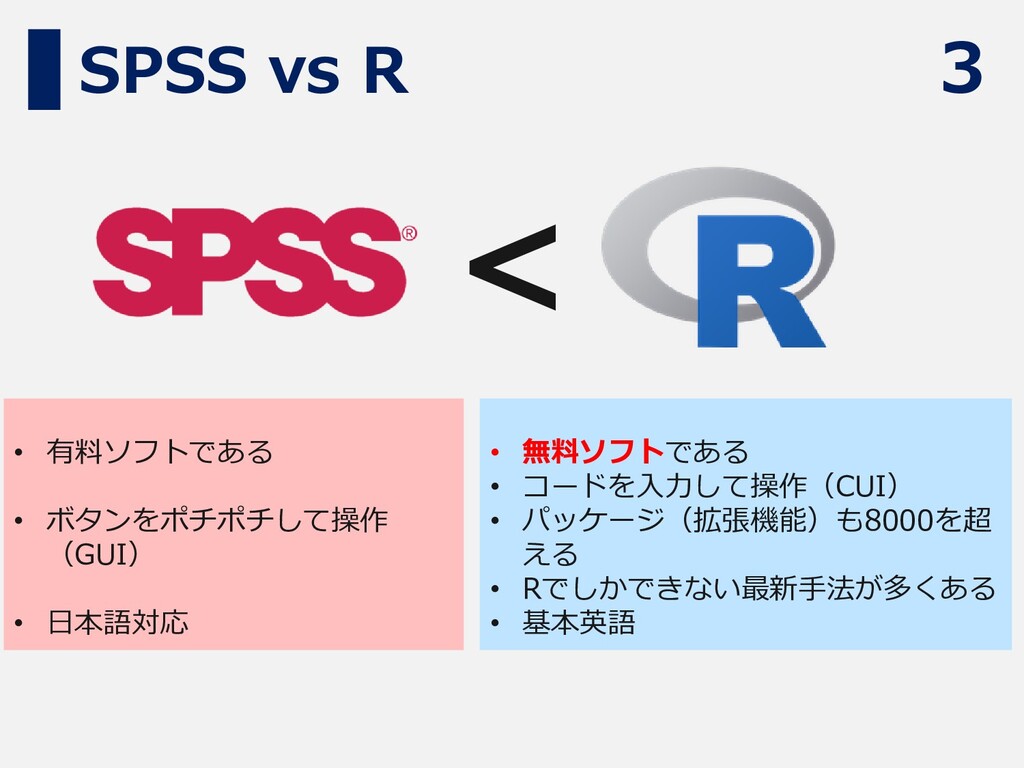
3 SPSS vs R • 有料ソフトである • ボタンをポチポチして操作 (GUI) •
日本語対応 • 無料ソフトである • コードを入力して操作(CUI) • パッケージ(拡張機能)も8000を超 える • Rでしかできない最新手法が多くある • 基本英語 <
4 Rコミュニティの活発な議論
5 準備:RとRStudioをインストールしよう ◼ R CRANからbaseをダウンロード&インストール https://cran.ism.ac.jp/ ◼ RStudio Rstudio社のHPからFree版をダウンロード&インストール https://rstudio.com/products/rstudio/download/#downl
oad
6 RStudioについて ⚫RStudioは、Rをより使いやすくするためのソフト(基本無料) ⚫この講習会では、すべてRStudioを利用して分析する ⚫必ずインストール <便利なところ> • コードの予測変換や引数リストを表示してくれる • 変数の管理が容易
Rの使い方の基礎
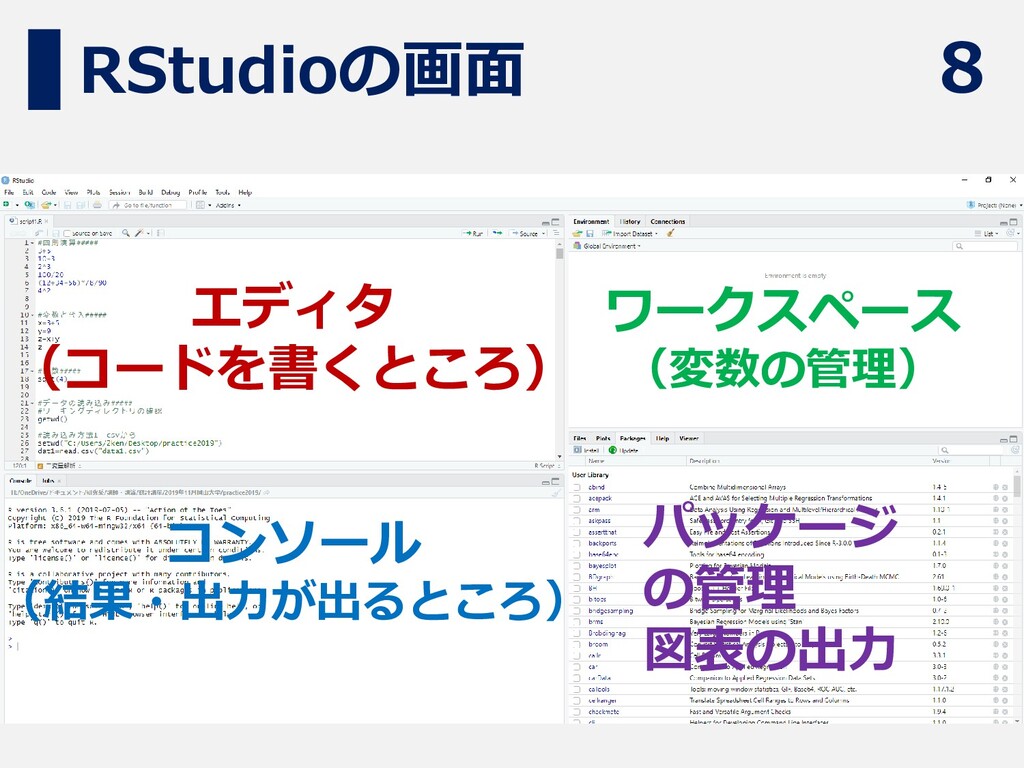
8 RStudioの画面 エディタ (コードを書くところ) コンソール (結果・出力が出るところ) パッケージ の管理 図表の出力 ワークスペース
(変数の管理)
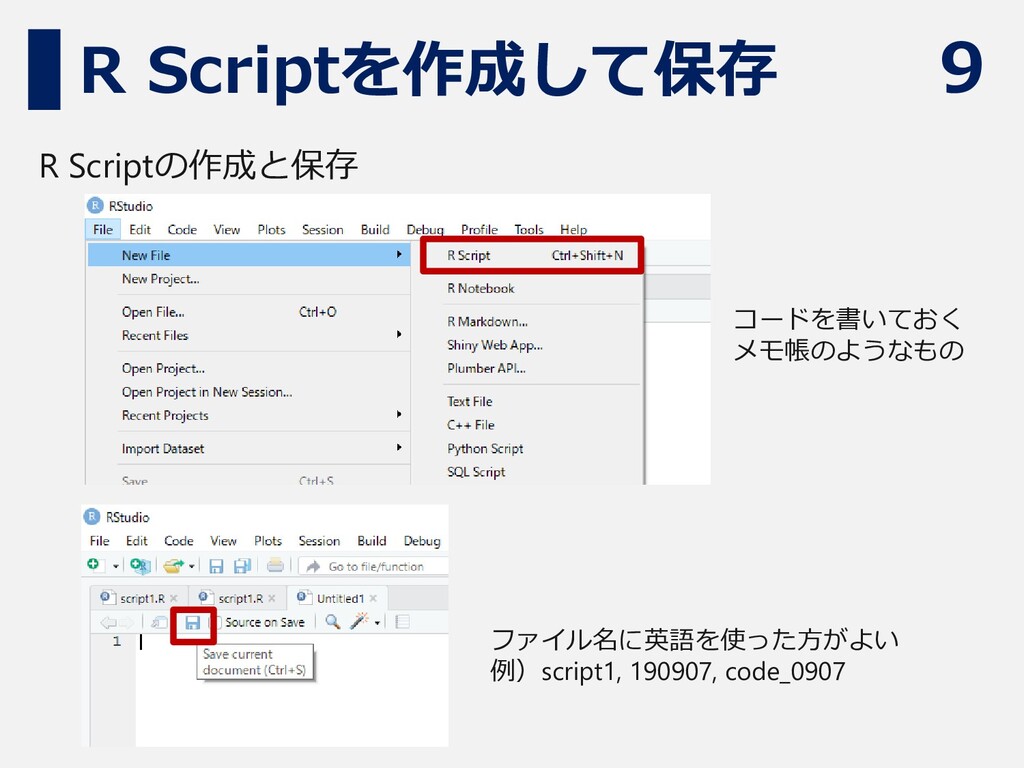
9 R Scriptを作成して保存 R Scriptの作成と保存 ファイル名に英語を使った方がよい 例)script1, 190907, code_0907 コードを書いておく
メモ帳のようなもの
10 四則演算 #四則演算##### 3+5 10-3 2*3 100/20 (12+34-56)*78/90 4^2 •
エディタに書いて実行 or コンソールに直接入力 実行の方法 • Ctr+Enterでその行を実行 • Alt+Enterでその行を実行★ • 範囲を指定してRunをクリック コメントアウト(メモ) • #から始めるとその行は読み込 まれない • メモやコメントを残せる • コメントの後ろに#を連ねると 目次代わりになる
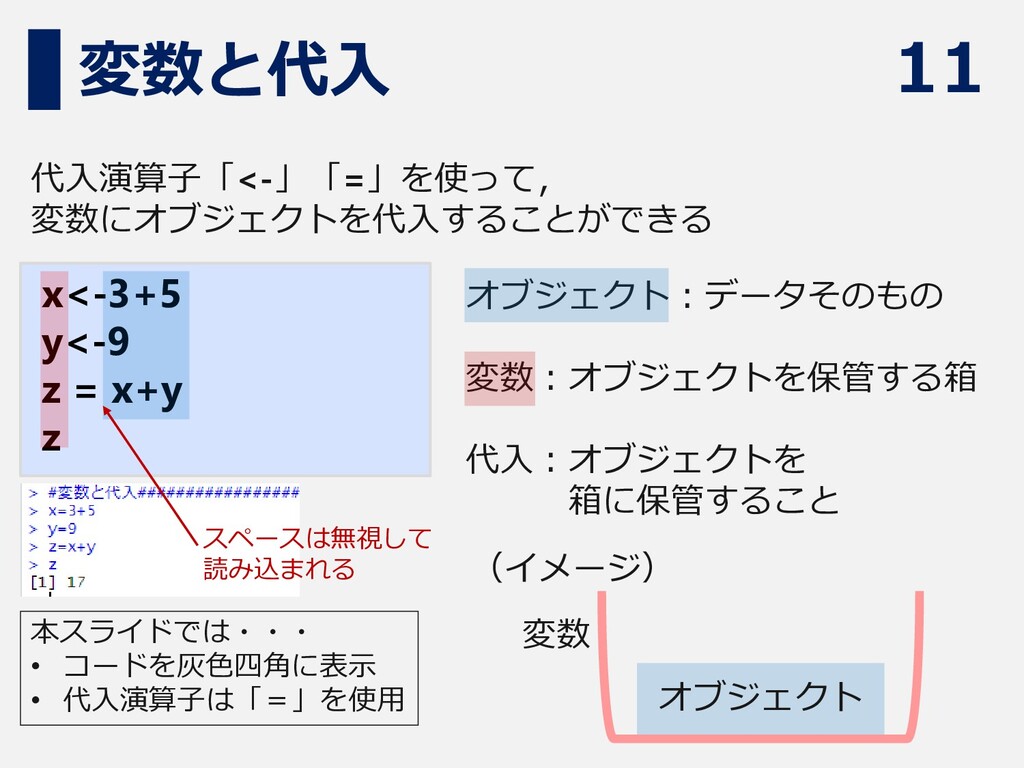
11 変数と代入 代入演算子「<-」「=」を使って, 変数にオブジェクトを代入することができる x<-3+5 y<-9 z = x+y z
オブジェクト 変数 (イメージ) オブジェクト:データそのもの 変数:オブジェクトを保管する箱 代入:オブジェクトを 箱に保管すること 本スライドでは・・・ • コードを灰色四角に表示 • 代入演算子は「=」を使用 スペースは無視して 読み込まれる
12 関数 何らかのインプットに対して処理を加え アウトプットを返すもの アウトプット インプット 処理 関数 2 4
処理 sqrt sqrt(4) 平方根を返す関数「sqrt」
13 Rによる分析の流れ ファイルの 読み込み コードの 入力 分析の実行 分析に使うエクセルファイルを読み込む コード(スクリプト)を書いて, Rにやってほしいことを命令
出力を読み取る
14 今回使用するデータ ⚫ 「data1.xlsx」:教育測定に関する架空データ ID:通し番号(1~250) school:学校名(sakura/kita) grade:学年(5~6)
class:クラス number:出席番号 sex:性別(M男、F女) kokugo1~3:国語のテスト結果 sansu1~3:算数のテスト結果 rika1~3:理科のテストの結果 CT1~7:批判的思考質問紙 Rは変数名を英語にした方が エラーが出にくい まずはデータを眺めて構造を 理解しよう。
15 データの読み込み1(csvから) #データの読み込み##### #ワーキングディレクトリの確認 getwd() #読み込み方法1 csvから setwd(“C:/Users/***/**/practice2019") dat1=read.csv("data1.csv") ←コメントアウトの後ろに#連打で目次
←ワーキングディレクトリ :作業スペースの場所(アドレス) ←csvデータを事前に作成しておく ←ワーキングディレクトリの指定 ←read.csv(”ファイル名”)で読込み dat1にデータセットを格納 オブジェクト dat1 (イメージ) ※csvカンマ区切りで保存を推奨 ※マウス操作でも変えられる ※コンソールにもWDが表示されてる
16 データの読み込み2(excelから) #読み込み方法2 xlsxから library(readxl) dat1=read_excel("data1.xlsx") View(dat1) ←下図を参考に、マウス操作でExcel ファイルから直接読み込み ←read_excel(”ファイル名”)で読込み
←dat1を表示してみる ※実行されたコードをエディタにも コピーしておく。 こっちの方法の方が手早いし楽。 一度コードをコピーしておけば 次回からは、コードを実行する だけでOK.
17 データハンドリング #データハンドリング##### #行列数 dim(dat1) #先頭6行の表示 head(dat1) head(dat1$rika1) ←目次 ←コメントアウト
←dim(データ)で、行数・列数の表示 ←head(データ)で、先頭6行を表示 ←データ$変数名で、1つの変数を指定 250行/22列(250人/22変数) 正しく読み込めているか確認 データセット 変数
18 変数の型の確認と変更 #変数の型の確認と変更 str(dat1) dat1$school=as.factor(dat1$school) dat1$grade=as.ordered(dat1$grade) dat1$sex=as.factor(dat1$sex) • int:整数型(integer)であることを示す •
num:実数型(numeric)であることを示す。小数点を含むもの。 • Factor:順序なし因子型であることを示す。例)性別 • Order:順序あり因子型であることを示す。例)学年 • chr:文字型(character)であることを示す。 ←str(データ)で構造を確認 ←データセット$変数名で特定の変数 を指定。as.factor(変数)で、変数 を因子型にする。 サジェスト機能を活用しよう 変数の型 ↓ Enter 選択
記述統計学と視覚化 基礎統計量、ヒストグラム、箱ひげ図、散布図 19
20 記述統計学と推測統計学 ⚫ 記述統計(descriptive statistics): 得られたデータの特徴や性質を説明・要約する ①数値要約:平均値や標準偏差などの代表値 ②図的要約:ヒストグラム・箱ひげ図・散布図など ⚫ 推測統計(inferential
statistics): 得られたデータから,手元にないデータを含めた全データの 一般的な性質について推測する
21 尺度水準と計算 尺度水準 説明 可能な演算 例 量的変数 比率尺度 0が原点であり、間 隔と比率に意味が
あるもの +-×÷ 重さ、長さ、 標高 間隔尺度 目盛が等間隔に なっているもので、 その間隔に意味が あるもの +- 気温、西暦 質的変数 順序尺度 順序や大小には意 味があるが間隔に は意味がないもの >= 順位 名義尺度 他と区別し分類す るための記号 度数カウント 血液型、郵便 番号、住所 名義 順序 間隔 比率 平均値 ☓ ☓ ◯ ◯ 中央値 ☓ ◯ ◯ ◯ 最頻値 ◯ ◯ ◯ ◯ 尺度水準によって使える分析や指標が 異なる。
22 練習問題 ⚫ 次のデータの尺度水準を答えなさい。 A) 人間の性別 B) 身長・体重 C) 気温(摂氏)
D) 絶対温度(K) E) 成績の順位 F) 血液型 G) アンケートで聞いたやる気度(5段階)※ H) 偏差値 ⚫ テストの項目として問題があるのは?
23 代表値の種類 ◼ 代表値:データの分布の中心的な位置を表す指標値 ⚫ 平均値(mean) ⚫ 中央値(median) データを小さい順に並べた時に中央に位置する値。 データが偶数個の場合は中央の2つの平均を算出。
⚫ 最頻値(mode) 度数の最も多い階級に対する値
24 散布度の指標 ◼ 散布度:データのばらつきの度合を表す指標値 ⚫ 偏差(diviation) 𝑑𝑖 = 𝑥𝑖 −
ҧ 𝑥 ⚫ 分散(variance) 𝑠2 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 − ҧ 𝑥 2 ⚫ 標準偏差(standard deviation) 𝑠 = 𝑠2 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 − ҧ 𝑥 2
25 基礎集計 #基礎集計##### #代表値と散布度 mean(dat1$rika1) #相加平均 median(dat1$rika1 ) #中央値 table(dat1$CT1)
#最頻値 var(dat1$rika1) #不偏分散 sd(dat1$rika1) #標準偏差 標準偏差の2乗が分散の値と一致すること を確認してみよう
26 要約 #要約 summary(dat1) install.packages("psych") library(psych) describe(dat1) ←summary(データ)で、四分位数を表示 ←psychパッケージをインストール(初回のみ) ←psychパッケージを読み込み
←describe(データ)で、基礎集計の表示 追加のパッケージをインストール&読み込むことで、 様々な分析が可能になる。 [最小値、第一四分位、中央値、平均、第三四分位、最大値] [変数番号、サンプルサイズ、平均、標準偏差、中央値、トリ ム平均、中央絶対偏差、最小、最大、レンジ、歪度、尖度、 標準誤差]
27 新しい変数の作成 #新しい変数の作成 dat1$kokugo_all=apply(dat1[,7:9],1,mean) dat1$sansu_all=apply(dat1[,10:12],1,mean) dat1$rika_all=apply(dat1[,13:15],1,mean) ←国語平均の作成。 ←算数平均の作成。 ←理科平均の作成。 ※0なら列,
1なら行に対して処理。 新しい変数名=関数による処理 代入 新しい変数が増えている
28 欠損値の除去 #欠損値除去 dat1=na.omit(dat1) ←リストワイズ除去(欠損値がある行を1行丸々除去する) 1. 完全にランダムに欠損→Missing Completely At Random(MCAR)
2. 観測データに依存する欠損→Missing At Random(MAR) 3. 欠損データに依存する欠損→Missing Not At Random(MNAR) ⚫ 欠損値の種類と対応 • MCARの場合、ペアワイズ削除(その分析に使う場合のみ除去)でもリストワイ ズ削除でもOK • MARの場合、完全情報最尤法による推定や、多重代入法による欠損値代入を行う • MNARの場合、お手上げ状態 ※ペアワイズ削除は、多くの関数でデフォルト設定になっている。
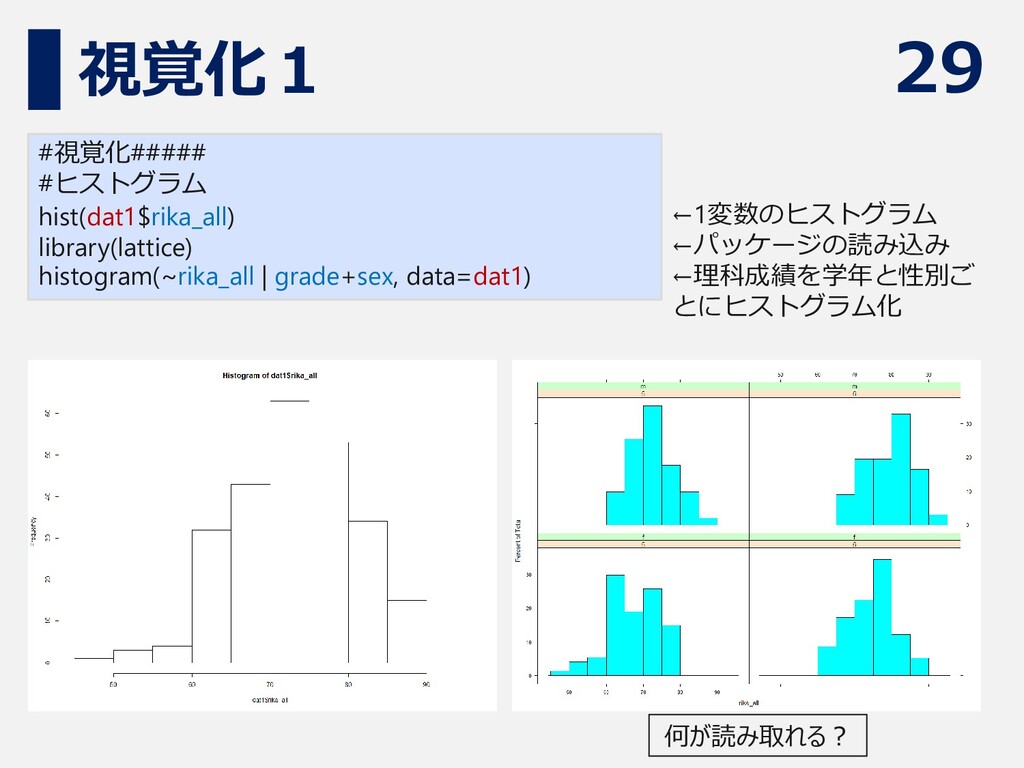
29 視覚化1 #視覚化##### #ヒストグラム hist(dat1$rika_all) library(lattice) histogram(~rika_all | grade+sex, data=dat1)
←1変数のヒストグラム ←パッケージの読み込み ←理科成績を学年と性別ご とにヒストグラム化 何が読み取れる?
30 視覚化2 #箱ひげ図 boxplot(dat1$rika_all,horizontal = T) boxplot(rika_all~sex, data = dat1,horizontal
= T) ←TRUE=横書き, FALSE=縦書き ←性別ごとに箱ひげ図をプロット • 画像として保存 • Metafile形式なら、パワポ 上で細かくいじれる f m 50 60 70 80 90 rika_all sex ↓Metafile形式で出力して色を付けた例 最小値 中央値 第一四分位/第三四分位 最大値
31 視覚化3 #散布図 plot(dat1$sansu_all, dat1$rika_all) plot(dat1$sansu_all, dat1$rika_all,pch=21,bg=c("blue","red")[unclass(dat1$sex)]) plot(dat1$sansu_all, dat1$rika_all,pch=as.numeric(dat1$sex), cex=1.5)
↑ plot(x軸の変数, y軸の変数) ★引数の参考 http://cse.naro.affrc.go.jp/takezawa/r- tips/r/53.html
32 ハイレベルな視覚化 #ペアプロット library(GGally) dat_ksr=dat1[,c("school","grade","sex","kokugo_all","sansu_all","rika_all")] dat_ksr=subset(dat1,select=c("school", "grade", "sex", "kokugo_all", "sansu_all",
"rika_all")) colnames(dat_ksr)=c(“学校”,“学年”,“性別”,“国語”,“算数”,“理科”) #日本語化 ggpairs(dat_ksr, aes_string(colour="学校", alpha=0.5)) #学校ごとに色分け ggpairs(dat_ksr, aes_string(colour="学年", alpha=0.5)) #学年ごとに色分け ggpairs(dat_ksr, aes_string(colour="性別", alpha=0.5)) #性別ごとに色分け 同じ • 対角行列はその変数の分布 • 三角行列は変数間の関連 • 縦と横の変数の重なりを見る
33 課題 ⚫ データを視覚化し、どのような傾向がありそうか についてディスカッションしましょう。データの 傾向について見通しを持つことは、その後の分析 方針を立てる上で役に立ちます。
確率分布 正規分布を知る
35 確率変数と確率分布 ⚫ 確率変数 取る値の範囲と取る確率だけがわかっている変数 ➢ 連続確率変数: 例)身長 ➢ 離散確率変数:
例)コインの表裏 ⚫ 確率分布 確率変数がとる値とその値をとる確率の対応の様子 コインの出る目の確率分布 コインの表裏 表(=1) 裏(=0) 確率 0.5 0.5
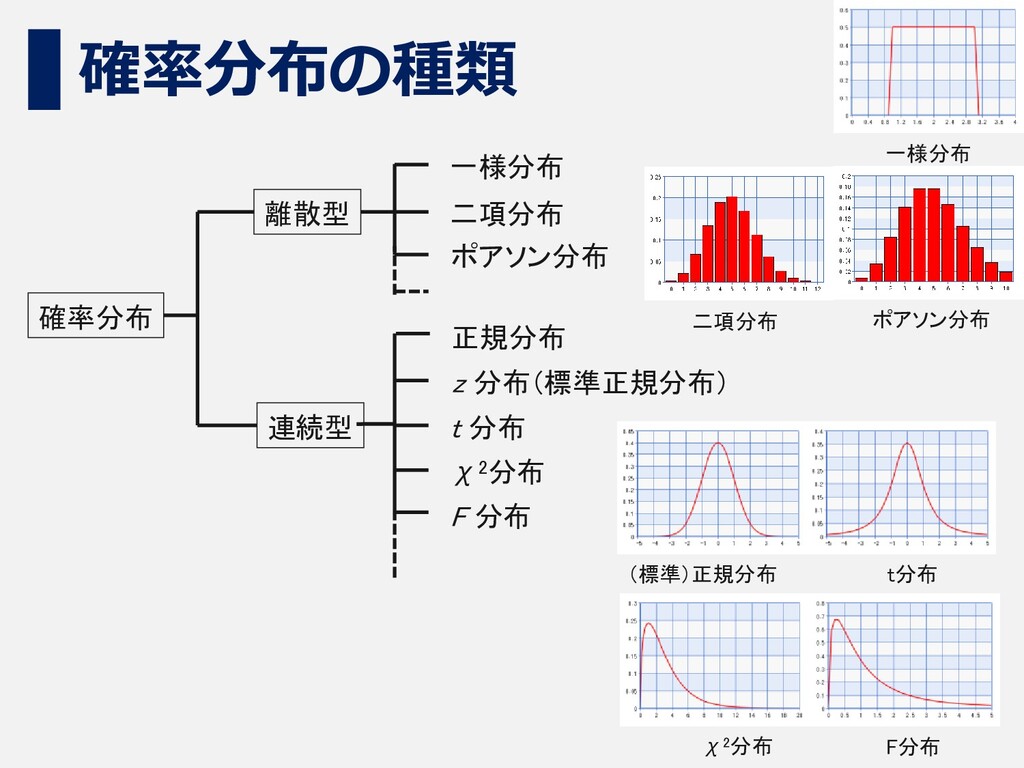
36 確率分布の種類 確率分布 離散型 一様分布 二項分布 ポアソン分布 正規分布 z 分布(標準正規分布)
t 分布 χ2分布 F 分布 連続型 χ2分布 (標準)正規分布 t分布 F分布 二項分布 ポアソン分布 一様分布
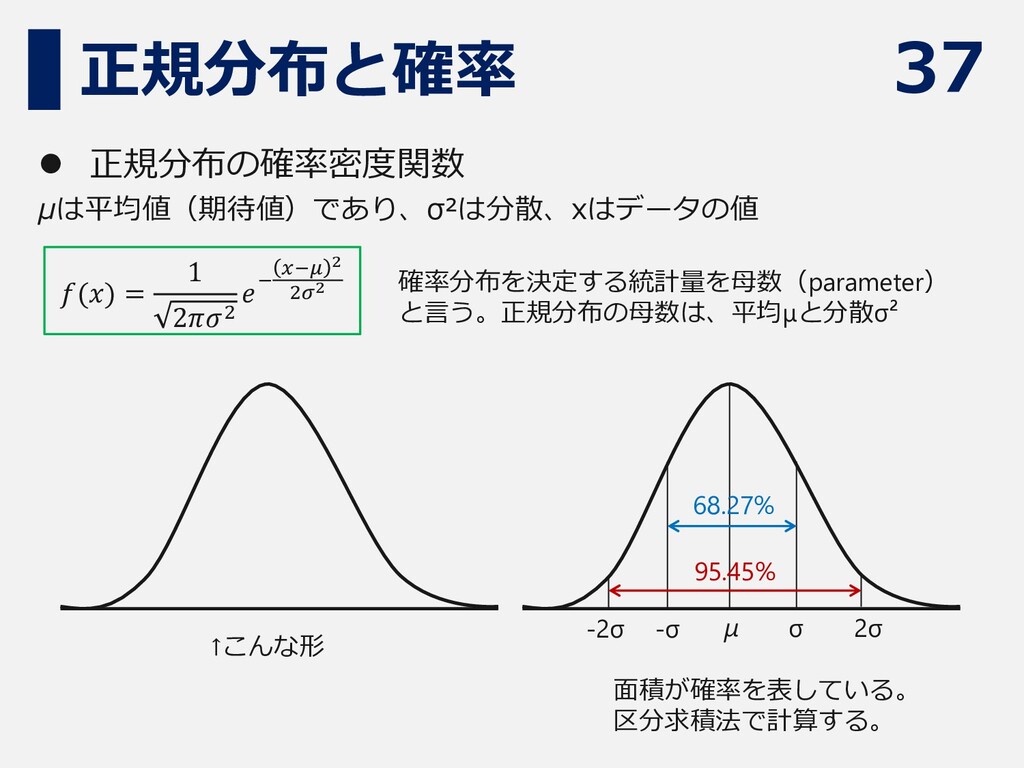
37 正規分布と確率 ⚫ 正規分布の確率密度関数 μは平均値(期待値)であり、σ²は分散、xはデータの値 𝑓(𝑥) = 1 2𝜋𝜎2 𝑒−
𝑥−𝜇 2 2𝜎2 面積が確率を表している。 区分求積法で計算する。 68.27% 95.45% μ σ 2σ -σ -2σ ↑こんな形 確率分布を決定する統計量を母数(parameter) と言う。正規分布の母数は、平均μと分散σ²
38 正規分布の例 ⚫ 日本人17歳男性の身長分布 𝑓(𝑥) = 1 2𝜋 ∗ 33
𝑒− 𝑥−170 2 2∗33 日本の成人男性の 身長(確率変数) 170cm 190cm 150cm 存在する確率 (確率密度) 極端に長身や低身の人は滅多にいない
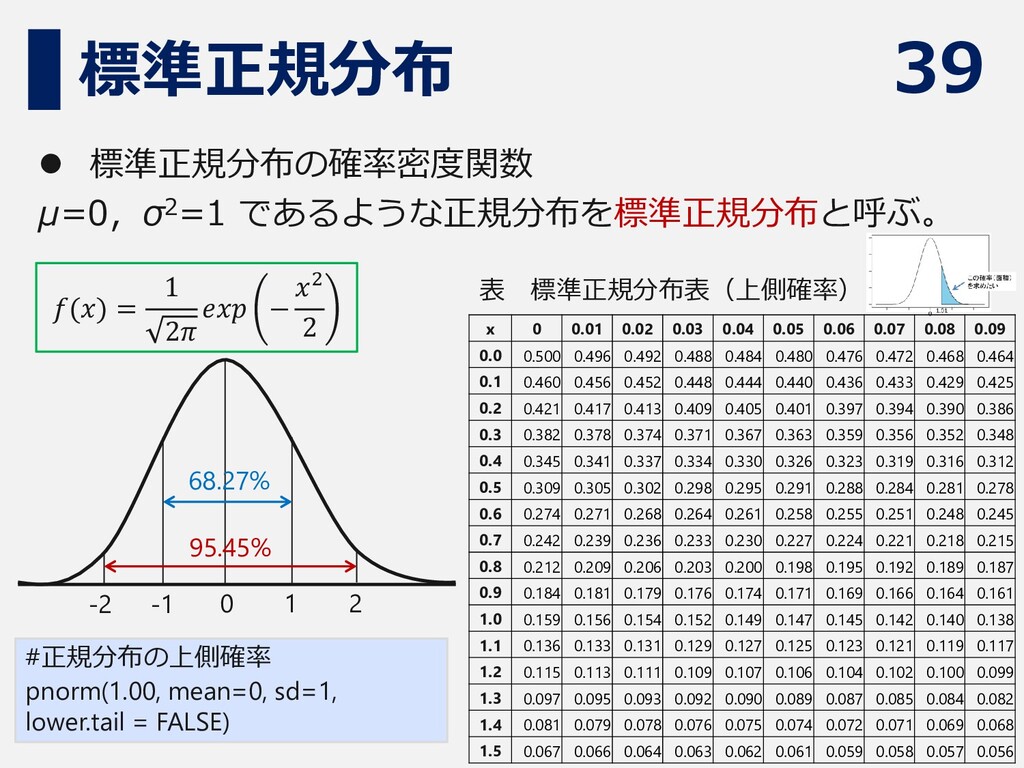
39 標準正規分布 ⚫ 標準正規分布の確率密度関数 μ=0,σ2=1 であるような正規分布を標準正規分布と呼ぶ。 𝑓(𝑥) = 1 2𝜋
𝑒𝑥𝑝 − 𝑥2 2 68.27% 95.45% 0 1 2 -1 -2 x 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.500 0.496 0.492 0.488 0.484 0.480 0.476 0.472 0.468 0.464 0.1 0.460 0.456 0.452 0.448 0.444 0.440 0.436 0.433 0.429 0.425 0.2 0.421 0.417 0.413 0.409 0.405 0.401 0.397 0.394 0.390 0.386 0.3 0.382 0.378 0.374 0.371 0.367 0.363 0.359 0.356 0.352 0.348 0.4 0.345 0.341 0.337 0.334 0.330 0.326 0.323 0.319 0.316 0.312 0.5 0.309 0.305 0.302 0.298 0.295 0.291 0.288 0.284 0.281 0.278 0.6 0.274 0.271 0.268 0.264 0.261 0.258 0.255 0.251 0.248 0.245 0.7 0.242 0.239 0.236 0.233 0.230 0.227 0.224 0.221 0.218 0.215 0.8 0.212 0.209 0.206 0.203 0.200 0.198 0.195 0.192 0.189 0.187 0.9 0.184 0.181 0.179 0.176 0.174 0.171 0.169 0.166 0.164 0.161 1.0 0.159 0.156 0.154 0.152 0.149 0.147 0.145 0.142 0.140 0.138 1.1 0.136 0.133 0.131 0.129 0.127 0.125 0.123 0.121 0.119 0.117 1.2 0.115 0.113 0.111 0.109 0.107 0.106 0.104 0.102 0.100 0.099 1.3 0.097 0.095 0.093 0.092 0.090 0.089 0.087 0.085 0.084 0.082 1.4 0.081 0.079 0.078 0.076 0.075 0.074 0.072 0.071 0.069 0.068 1.5 0.067 0.066 0.064 0.063 0.062 0.061 0.059 0.058 0.057 0.056 表 標準正規分布表(上側確率) #正規分布の上側確率 pnorm(1.00, mean=0, sd=1, lower.tail = FALSE)
40 標準化とz得点 ⚫ 標準化 データを平均0、標準偏差(分散)1に変換する作業。 𝑧 = 𝑥𝑖 − 𝜇𝑥
𝜎𝑥 • どんな正規分布に従う確率変数でも、標準化すれば標準正 規分布で表せて便利 • 変換した後の得点をz得点(標準得点)と呼ぶ。
41 Rで正規分布を描画してみよう #確率分布の描画 curve(dnorm(x, 0, 1), -5, 5) curve(dnorm(x, 50,
10), 0, 100) curve (関数の式, 横軸の最小値, 横軸の最大値) ←標準正規分布 ←平均50、標準偏差10の正規分布 ↑この分布、どこかで見たような…
42 偏差値 ⚫ 偏差値 偏差値 = 50 + 10 ∗
𝑧得点 • 平均50、標準偏差10になるように変換 • 受験者全体の分布の中でどれだけ高いかを反映している ⚫ 知能指数(IQ) IQ = 100 + 15 ∗ 𝑧得点 • 平均100、標準偏差15になるように変換 ※ただし、いくつかのバージョンがあるのと、フリン効果で分布が変化しつつある
43 練習問題 ① 偏差値が平均50, 標準偏差10の正規分布に従う場合、 偏差値60以上は全体の何%であるか。 ヒント1:偏差値=z得点×10+50 ヒント2:z得点は標準正規分布に従う ③ あなたの理科の試験の得点は80点でした。クラス全体が
平均60点、標準偏差10点の正規分布に従う場合、あな たの得点の標準化した値と偏差値を求めなさい。 ② IQが平均100, 標準偏差15の正規分布に従う場合、 IQ130以上は全体の何%であるか。Rで計算せよ。 pnorm(130, mean=100, sd=15, lower.tail = FALSE)
44 復習問題 1. 4つの尺度水準とその具体例を答えよ 2. 代表値と散布度の指標を2つずつ答えよ 3. (標本)分散の計算式を答えよ 4. 標準正規分布の特徴を説明せよ
5. 標準化とはどのような作業か説明せよ
推測統計学の基礎 標本分布、標準誤差、中心極限定理
46 記述統計学と推測統計学 母集団 記述統計学・・・サンプルの性質の要約 推測統計学 ”標本統計量の値をもとに, 母数についてできるだけ正確な推測 をする” サンプル (標本)
サンプリング ⚫ 記述統計学と推測統計学 目の前のサンプルに関する ことしか言えない
47 標本統計量と標本誤差 母集団 サンプル (標本) μ m 標本統計量(sample statistic) 母数(parameter)
標本平均 母平均 サンプリング 母 数 ( 未 知 の 真 の 値 ) 推 定 値 標本誤差 平均や分散 標本データから母数を推定する場合は必ず 誤差(標本誤差)が生じる
48 標本平均と標本分布 母集団 (テントウムシの体長) 標本 (n=2) 母平均1.0cm (実際は未知) 標本平均0.9cm (実際に観測できる)
標本平均1.1cm 標本平均1.3cm 標本平均◦.◦cm 標 本 平 均 は 分 布 す る 何度でも 抽出できる 標本平均の標本分布 1.0 繰り返しサンプリングする状況 を考えてみよう。複数得られた 統計量の分布をその統計量の 標本分布という。
49 標本平均のばらつき(標準誤差) 母集団 (テントウムシの体長) 母平均1cm (実際は未知) 標本平均0.9cm 標本平均1.1cm 標本平均0.5cm 何度でも
抽出できる nの数によって・・・ 標本平均2.5cm nが大きいと、 標本平均のバラツキ は小さい nが小さいと、 標本平均のバラツキ は大きい 標本分布の標準偏差を標準誤差と呼ぶ nが大きいほど標準誤差は小さくなる Standard Error
50 サンプルサイズと標準誤差 μ 母集団の最小値 (最小個体) 母集団の最大値 (最大個体) 母集団の個体の分布 標本平均の分布(n=5) 標本平均の分布(n=10)
標本平均の分布 (n=全数N,母平均) 母標準偏差σ 母標準誤差σ/√5 母標準誤差σ/√10 x ➢ 母標準誤差(SE) 𝜎 ҧ 𝑥 = 𝜎𝑥 𝑛 ➢ 標本標準誤差(se) 𝑆 ҧ 𝑥 = 𝑆𝑥 𝑛 nが大きいほど標準誤差は小さく なる→精度良く母集団の平均値 の推定ができる
51 大数の法則と中心極限定理 標本平均の分布(n=1) 標本平均の分布(n=5) 標本平均の分布(n=10) 標本平均の分布 (n=全数N,母平均) x • より大きいサイズの標本から標本平均を求めると、
真の平均に近づく(大数の法則) nが大きいほど標準誤差は小さく なる→精度良く母集団の平均値 の推定ができる • 標本の大きさnが大きくなると、抽出元の母集団が正規分布でない 場合も、標本平均は正規分布に従う(中心極限定理)
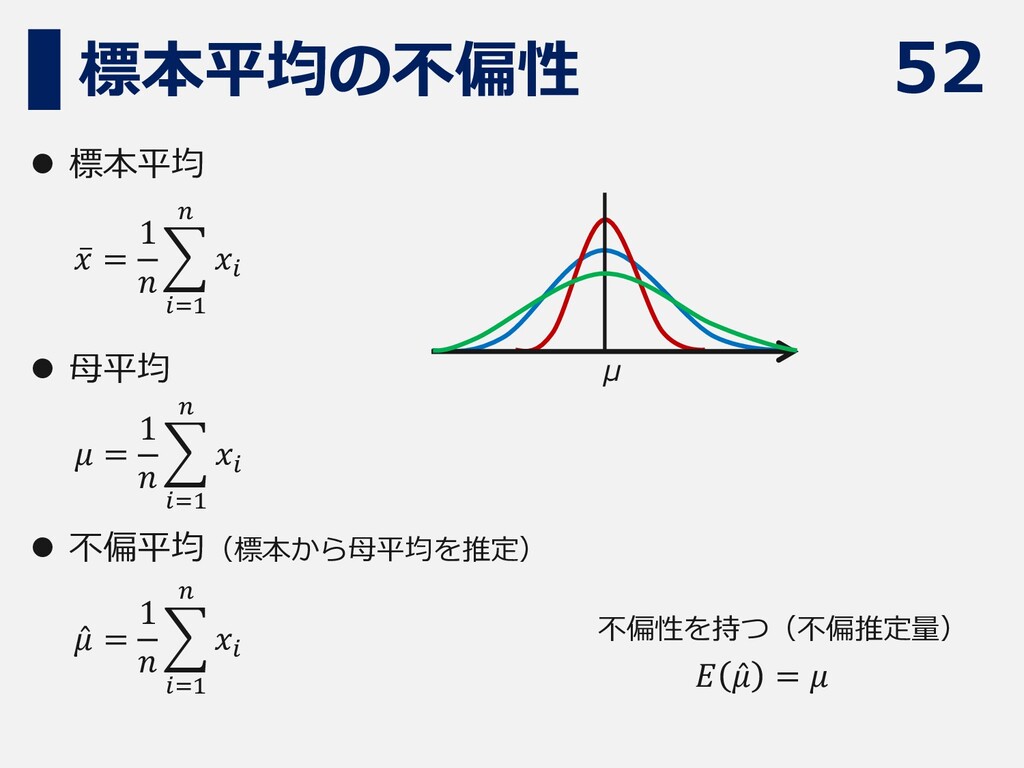
52 標本平均の不偏性 μ ⚫ 標本平均 ⚫ 母平均 ⚫ 不偏平均(標本から母平均を推定) 不偏性を持つ(不偏推定量)
ҧ 𝑥 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 𝜇 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 Ƹ 𝜇 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 𝐸 Ƹ 𝜇 = 𝜇
53 不偏分散 ⚫ 標本分散 𝑠2 = 1 𝑛 𝑖=1
𝑛 𝑥𝑖 − ҧ 𝑥 2 ⚫ 母分散 𝜎2 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 − 𝜇 2 ⚫ 不偏分散(標本から母分散を推定) 𝜎2 = 1 𝑛 − 1 𝑖=1 𝑛 𝑥𝑖 − ҧ 𝑥 2
54 練習問題 1. 標本分布とは何か説明せよ 2. 標準偏差(sd)と標準誤差(se)の違いについて述べよ 3. n=100で20代男性のBMIを調べた結果、 平均22.7、標準偏差4.0であった。この場合の標本平均の 標準誤差を算出せよ。
4. 標準誤差を半分にするには、サンプルサイズを何倍にすれ ばよいだろうか。(ヒント:標準誤差の計算式の分母に注目) 5. 前回のRコードをもう一度実行し、“要約”の部分で標準誤 差(se)が表示されていたことを確認しよう。
区間推定 95%信頼区間
56 点推定と区間推定 ⚫ 点推定 母数の推定値を1つの値で示す(ex. 母平均の推定値は8.3cm) ⚫ 区間推定 誤差を考慮して、母数の推定値を区間で示す (ex.
95%の確率で7.8~8.8cmの間に入る) 68.27% 95.45% μ σ 2σ -σ -2σ 95% 平均 +1.96se -1.96se 正規分布 標本分布 (正規分布) 上限値 (upper) 下限値 (lower)
57 95%信頼区間 ⚫ 95%信頼区間 サンプリングと95%信頼区間の推定を繰り返せば、95%の 確率で母平均(真の値)が含まれる区間。 母平均(真の値) … 95%信頼区間 失敗
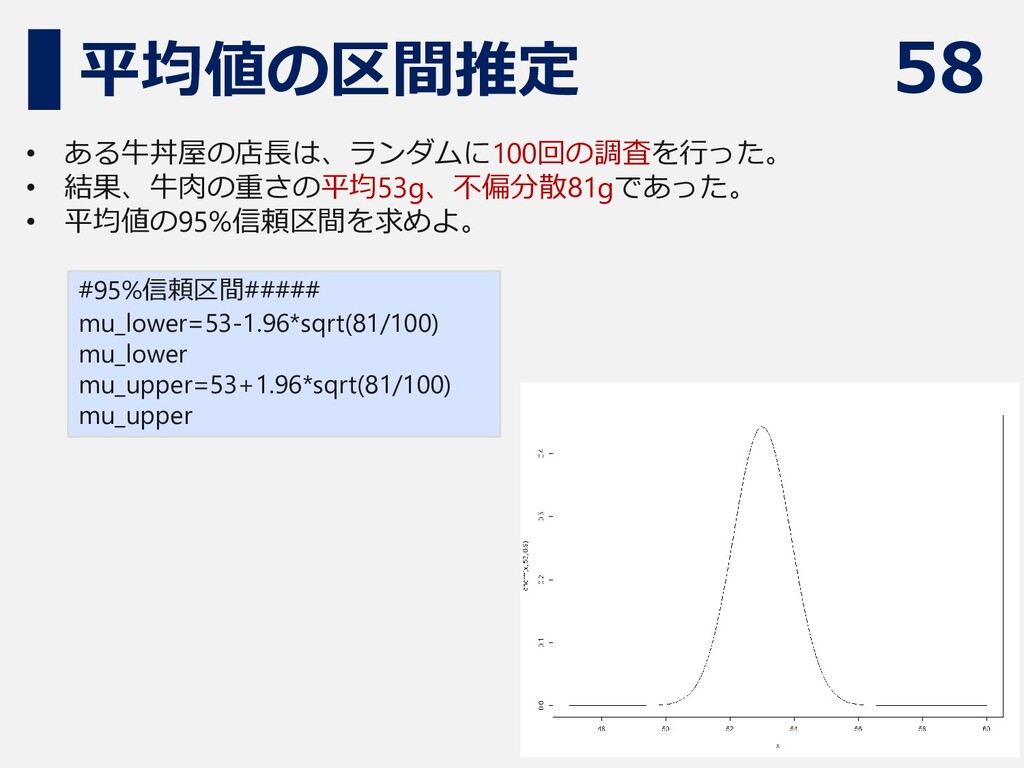
58 平均値の区間推定 • ある牛丼屋の店長は、ランダムに100回の調査を行った。 • 結果、牛肉の重さの平均53g、不偏分散81gであった。 • 平均値の95%信頼区間を求めよ。 #95%信頼区間##### mu_lower=53-1.96*sqrt(81/100)
mu_lower mu_upper=53+1.96*sqrt(81/100) mu_upper
帰無仮説検定の基礎 決定論的アプローチ
60 統計的仮説検定の考え方 ⚫ 統計的仮説検定 標本を使って、母集団に関する判断を下す手法。 仮説を立てて、白黒決着をつけたいというお気持ち。 ⚫ 手順 ① 仮説の設定(ex.
AとBには差がある) ② 仮説検定に用いる標本統計量の選択 ③ 有意水準の設定 ④ 実際のデータ(標本)から標本統計量を計算 ⑤ 仮説の正誤の判断(→結論) ※ただし、仮説検定は常にギャンブルであることを忘れるな
61 仮説の設定 ⚫ 仮説の種類 ◼ 帰無仮説(本来主張したいこととは反対の内容) • AクラスとBクラスの学力には差がない。 ◼ 対立仮説(本来主張したい内容)
• AクラスとBクラスの学力には差がある。 ⚫ 帰無仮説の棄却 帰無仮説の下では、実際に得られたデータはとても極端な 値であり、そんな値が出るのは非常にまれな確率だとなれ ば、「帰無仮説が正しい」という前提を疑い、帰無仮説を 棄却する。背理法的な考え方により、対立仮説を採択する。
62 標本統計量の選択 ⚫ 検定統計量 ◼ 標本から計算される統計量を標本統計量と呼ぶ(復習) ◼ 仮説検定に用いられる標本統計量を検定統計量と呼ぶ ◼ 帰無仮説から離れるほど大きな値を示す指標である
• t, Χ2, F など • データから計算する ⚫ 基本コンセプト ◼ 帰無仮説の下での標本分布(数理的に導かれる)をもとに、 データから計算した検定統計量が得られるのは非常に まれな確率(有意水準以下)なのかを検討する。 →慣例的に5% ※標本分布は母集団に対して同じ条件でサンプリングを 繰り返すことを想定していたことに留意せよ
63 有意水準の設定 ⚫ リスクをコントロールせよ 真実 帰無仮説は正しい (差がない) 帰無仮説は間違い (差がある) 決定
帰無仮説を棄却 第1種の誤り 確率はα(有意水準) 5% 正しい決定 確率は1-β(検定力) 棄却しない 正しい決定 確率は1-α 95% 第2種の誤り 確率はβ • 検定力の目安は0.8 • サンプルサイズを大きくすると、 検定力は上がる • 差が大きいと検定力は上がる
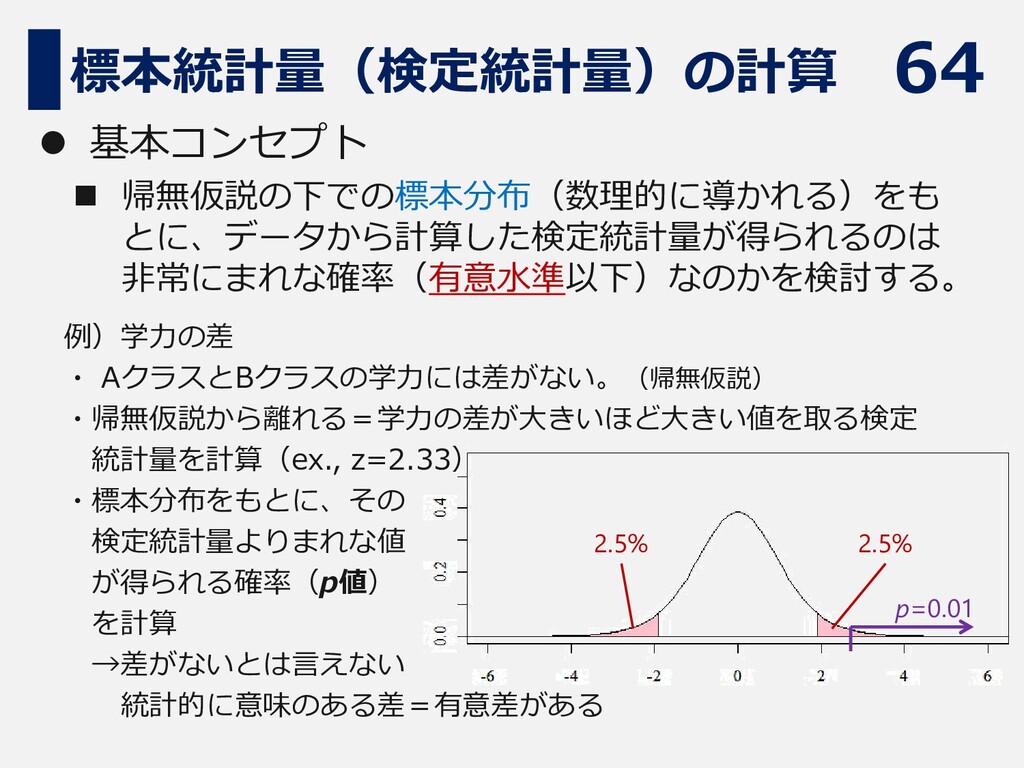
64 標本統計量(検定統計量)の計算 ⚫ 基本コンセプト ◼ 帰無仮説の下での標本分布(数理的に導かれる)をも とに、データから計算した検定統計量が得られるのは 非常にまれな確率(有意水準以下)なのかを検討する。 例)学力の差 ・
AクラスとBクラスの学力には差がない。(帰無仮説) ・帰無仮説から離れる=学力の差が大きいほど大きい値を取る検定 統計量を計算(ex., z=2.33) ・標本分布をもとに、その 検定統計量よりまれな値 が得られる確率(p値) を計算 →差がないとは言えない 統計的に意味のある差=有意差がある 2.5% 2.5% p=0.01
65 仮説の正誤の判断 ⚫ 仮説検定 ◼ p値が有意水準(ex., 5%)を下回った時、検定結果が 有意であると判断し、帰無仮説を棄却する。 ⚫ p値とは何であって何でないのか
◦ 帰無仮説が真であるという仮定の下で、検定統計量が データから計算された値以上に甚だしい値となる確率 × 帰無仮説が真である確率 × 平均に差がないという仮説が正しい確率 × 対立仮説が正しい確率は1-p値 × 帰無仮説が真であるときに、誤って帰無仮説を棄却して しまう確率 × とにかく5%を切ったら嬉しい値
66 色々な検定統計量
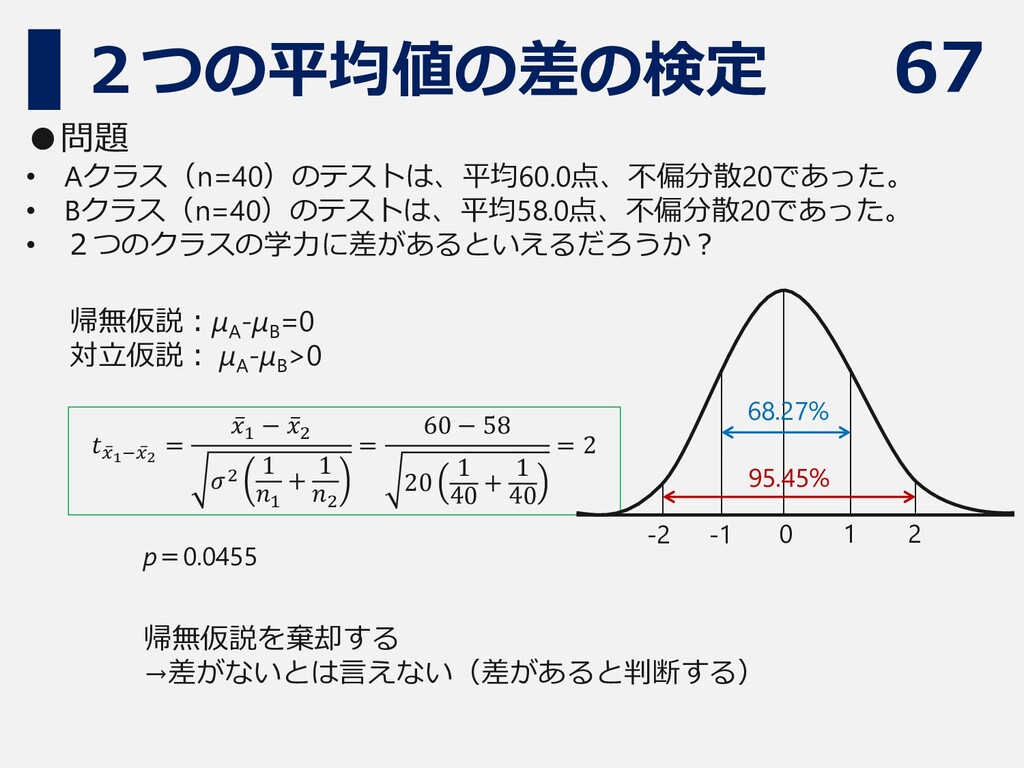
67 2つの平均値の差の検定 •問題 • Aクラス(n=40)のテストは、平均60.0点、不偏分散20であった。 • Bクラス(n=40)のテストは、平均58.0点、不偏分散20であった。 • 2つのクラスの学力に差があるといえるだろうか? 帰無仮説:μA
-μB =0 対立仮説: μA -μB >0 𝑡 ҧ 𝑥1− ҧ 𝑥2 = ҧ 𝑥1 − ҧ 𝑥2 𝜎2 1 𝑛1 + 1 𝑛2 = 60 − 58 20 1 40 + 1 40 = 2 p=0.0455 帰無仮説を棄却する →差がないとは言えない(差があると判断する) 68.27% 95.45% 0 1 2 -1 -2
68 有意差があればOKなのか? ⚫ 検定統計量の式から分かる通り、nが大きければ検定統計 量も大きくなりやすい=p値が小さくなりやすい ⚫ nが大きいということは、自信をもって差を見出せるとい うこと ⚫ 差があるかどうかだけでなく、差の大きさについても検討
する必要がある ⚫ 標準化した差の大きさを効果量と呼ぶ 𝑑 = 𝜇2 − 𝜇1 𝜎
2変量解析 t検定、一元配置分散分析、相関分析、 クロス集計、カイ二乗検定、残差分析 69
70 対応のないt検定1(2群の平均値差) #学年間比較 tapply(dat1$rika_all, dat1$grade, mean) #学年ごとの平均値を見てみる t.test(rika_all~grade, data=dat1, var.equal=F)
#F=Welchのt検定 g5=dat1$rika_all[dat1$grade==“5”] #5年の抽出 g6=dat1$rika_all[dat1$grade==“6”] #6年の抽出 t.test(g6, g5, var.equal=F) #F=Welchのt検定 library(effsize) cohen.d(g6,g5,hedges.correction = T) #効果量:T=heagesのg, F=cohenのd *効果量(Effect Size) 差の大きさを表す指標。 平均値の差が標準偏差の何個分に相当するかを計算。 測定単位が変わっても比較できる。 様々な種類があるが、代表的なのはCohenのd。 Headgesのgは、 Cohenのdの補正版。 同じことの別記法 有意 ⚫ 理科の点数に学年間で差はあるだろうか?
71 対応のないt検定2(2群の平均値差) #性別間比較 tapply(dat1$rika_all, dat1$sex, mean) #性別ごとの平均値 t.test(rika_all~sex, data=dat1, var.equal=F)
#F=Welchのt検定 m=dat1$rika_all[dat1$sex=="m"] #第1群の指定 f=dat1$rika_all[dat1$sex=="f"] #第2群の指定 t.test(m, f, var.equal=F) #Welchのt検定 library(effsize) cohen.d(m, f, hedges.correction = T) #効果量:True=heagesのg, False=cohenのd * Cohenの基準(dとgに適応できる) d=0.2 小さな効果 d=0.5 中程度の効果 d=0.8 大きな効果 中程度の大きさの差 有意 ⚫ 理科の点数に男女間で差はあるだろうか? ※どんなに差が小さくても、サンプルサ イズが大きければ有意になってしまう。 効果量も重要。 同じことの別記法 95%CI
72 報告例(対応のないt検定) 68 70 72 74 76 78 学年 理科点数l
5 6 n=125 n=125 ◼ 男子(N=118)と女子(N=132)の理科の点数に差がある のかを明らかにするために、Welchのt検定を行った。そ の結果、男子(M=76.17, SD=6.88)と女子(M=70.36, SD=7.60)の点数には有意な差が見られた(t (247.96) =6.35, p < .001, g =0.80 (95%CI [0.54, 1.06]))。 ◼ 第5学年と第6学年で、理科の点数に差があるのかについ て、独立な2群のt検定(Welch’s t-test)を実施したとこ ろ、0.1%水準で有意差が認められた(t (247.82)=8.743, p < .001, g =1.102 (95%CI [0.836, 1.369]))。
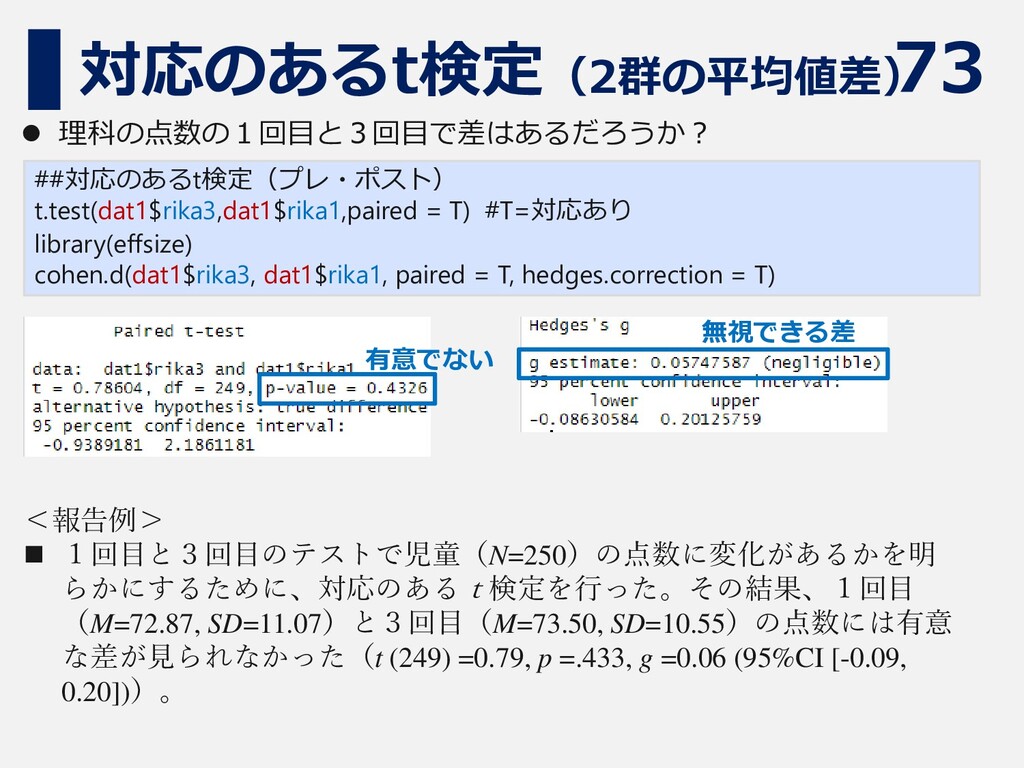
73 対応のあるt検定(2群の平均値差) ##対応のあるt検定(プレ・ポスト) t.test(dat1$rika3,dat1$rika1,paired = T) #T=対応あり library(effsize) cohen.d(dat1$rika3, dat1$rika1,
paired = T, hedges.correction = T) 無視できる差 有意でない ⚫ 理科の点数の1回目と3回目で差はあるだろうか? <報告例> ◼ 1回目と3回目のテストで児童(N=250)の点数に変化があるかを明 らかにするために、対応のあるt検定を行った。その結果、1回目 (M=72.87, SD=11.07)と3回目(M=73.50, SD=10.55)の点数には有意 な差が見られなかった(t (249) =0.79, p =.433, g =0.06 (95%CI [-0.09, 0.20]))。
74 練習問題 1. t検定を用いて、国語(kokugo_all)と算数(sansu_all) の性差を検討せよ 2. 理科の性差は国語の何倍か概算せよ(ヒント:効果量に基づく 比較) 3. 桜小学校と北小学校では、どちらの学力が高いか検討せよ
(※やり方は1つではないので、問題を自由に解釈してよい。)
75 復習 1. 標本分布の標準偏差を何と呼ぶでしょうか 2. 95%信頼区間について説明せよ 3. [正誤判定問題] ①有意水準αを5%に設定するということは、実際には帰無仮説が正 しい(差がない)のに、誤って帰無仮説を棄却する確率を5%以下に
抑えることを意味する。 判定: . ②p値とは、帰無仮説が正しい確率であり、低ければ低いほど良い指 標である。 判定: . 4. 2群の母平均の差について検討する際に使用する検定を答えよ 5. 有意差の有無だけでなく、効果量も報告する必要があるのはなぜで しょうか?
76 分散分析 ⚫ 3群以上の平均値差を比べるにはどうしたらよいだろうか? 1. t検定を繰り返す → αのインフレを補正 2. 分散分析を使用する
◼ 分散分析 𝐹 = 群間変動の分散 群内変動(誤差)の分散 群間全体で差があるか判断する 1 − 1 − 𝛼 𝑛
77 一元配置分散分析(対応なし) ##一元配置分散分析 #学年*性別を組み合わせた変数を作成 dat1$grade_sex=ifelse(dat1$grade=="5" & dat1$sex=="m", "5m", ifelse(dat1$grade=="5" &
dat1$sex=="f", "5f", ifelse(dat1$grade=="6" & dat1$sex=="m", "6m", ifelse(dat1$grade=="6" & dat1$sex=="f", "6f", NA)))) #1要因4水準の分散分析(対応なし) anova(lm(dat1$rika_all~dat1$grade_sex)) ↑ ifelse(条件式,Trueの場合, Falseの場合) ⚫ 4水準の間に全体として差があるか? 5年男子/5年女子/6年男子/6年女子 F値が有意 全体として差がある
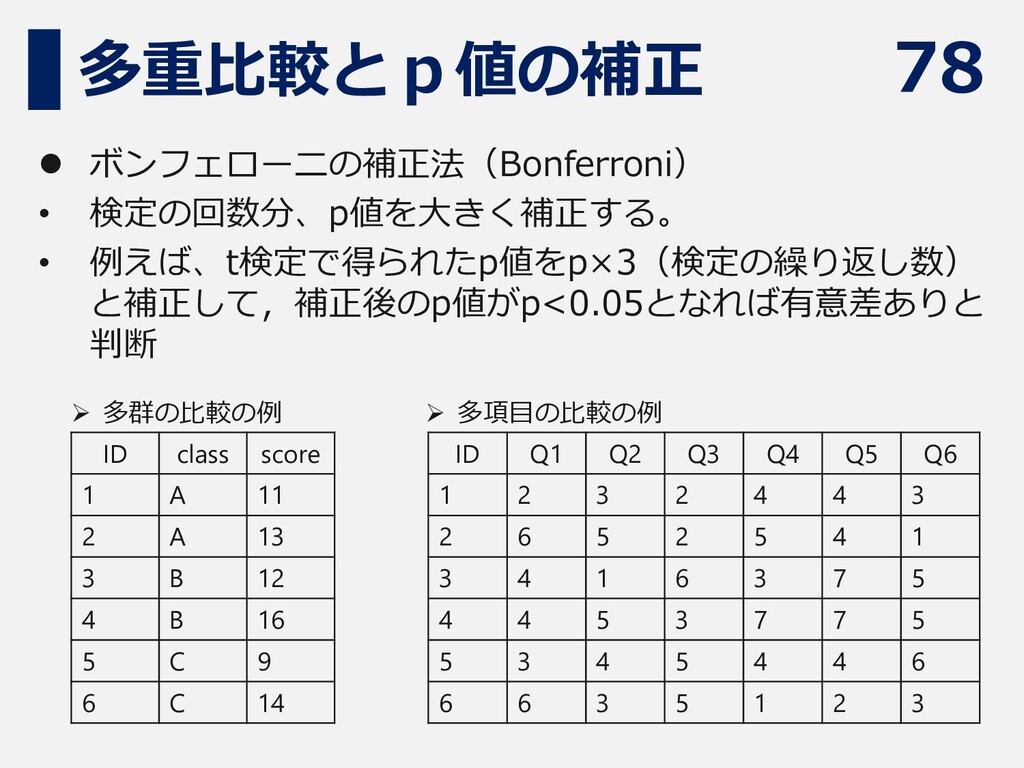
78 多重比較とp値の補正 ⚫ ボンフェローニの補正法(Bonferroni) • 検定の回数分、p値を大きく補正する。 • 例えば、t検定で得られたp値をp×3(検定の繰り返し数) と補正して,補正後のp値がp<0.05となれば有意差ありと 判断
ID class score 1 A 11 2 A 13 3 B 12 4 B 16 5 C 9 6 C 14 ➢ 多群の比較の例 ➢ 多項目の比較の例 ID Q1 Q2 Q3 Q4 Q5 Q6 1 2 3 2 4 4 3 2 6 5 2 5 4 1 3 4 1 6 3 7 5 4 4 5 3 7 7 5 5 3 4 5 4 4 6 6 6 3 5 1 2 3
79 多重比較 ⚫ どの水準間に差があるか? 5年女子/5年男子/6年女子/6年男子 #多重比較 tapply(dat1$rika_all,dat1$grade_sex,mean) #性別*学年ごとの平均値 sort(tapply(dat1$rika_all,dat1$grade_sex,mean)) #並べ替え
pairwise.t.test(dat1$rika_all, dat1$grade_sex, p.adj = "bonf") #ボンフェローニ法 ※検定を繰り返していることになるので、 ボンフェローニ法などでp値を補正する。 多重比較 5年女子 5年男子 6年女子 5年男子 *** 6年女子 *** p=0.63 6年男子 *** *** ** 5年女子 5年男子 6年女子 6年男子 Mean 67.21 72.38 74.38 79.06
80 報告例(1元配置分散分析) ◼ 理科の点数を従属変数、性別と学年(5年男子・5年女子・6 年男子・6年女子)を要因とする一元配置分散分析を行った 結果、有意差が見られた(F(3, 246)=41.04, p < .001)。ボン
フェローニ法による多重比較を行ったところ、6年女子と5 年男子の間を除くすべての組み合わせで有意差が見られた (ps < 0.01)。 ◼ 小学生を対象とした第1回(M=59.10, SD=7.80)、第2回 (M=68.24, SD=8.52)、第3回(M=73.10, SD=7.81)の理科 テストデータを用いて反復測定分散分析を行った。その際、 Mauchlyの検定が有意となり(χ2(2)=39.69, p < 0.001)、球面 性の仮定が満たされないことが示されたため、Greenhouse- Geisserのε =.87を用いて自由度の修正を行った。結果、平均 値には有意な差が見られた( F(1.74, 249) = 290.41, p < .001, η2 =.34)。また、ホルム法による多重比較の結果、すべての テスト間で有意差が見られた( ps < 0.05)。
81 相関係数の種類 ピアソンの積率相関 連続量×連続量(間隔・比率) 線形 ポリコリック相関 順序尺度×順序尺度 線形 ポリシリアル相関 順序尺度×連続量
線形 テトラコリック相関 2値×2値の順序尺度 線形 スピアマンの順位相関 順序or連続量の相関 単調 クラメールの連関 名義尺度×名義尺度 ー ピアソン = +1、スピアマン = +1 ピアソン = +0.851、スピアマン = +1 多変量正規分布 | r | = 0.7~1.0 強い相関 | r | = 0.4~0.7 中程度の相関 | r | = 0.2~0.4 弱い相関 | r | = 0~0.2 ほとんど相関なし ※疑似相関に注意 例)アイスの売り上げと溺死者数 線形〇 単調〇 線形×(非線形) 単調〇
82 ピアソンの積率相関係数 ⚫ 共分散(Covariance) 𝑟 = 𝑠𝑥𝑦 𝑠𝑥 𝑠𝑦 =
1 𝑛 σ𝑖=1 𝑛 (𝑥𝑖 − ҧ 𝑥)(𝑦𝑖 − ത 𝑦) 1 𝑛 σ 𝑖=1 𝑛 (𝑥𝑖 − ҧ 𝑥)2 1 𝑛 σ 𝑖=1 𝑛 (𝑦𝑖 − ത 𝑦)2 Cov x, y = 𝑠𝑥𝑦 = 1 𝑛 𝑖=1 𝑛 (𝑥𝑖 − ҧ 𝑥)(𝑦𝑖 − ത 𝑦) x y ҧ 𝑥 ത 𝑦 𝑥𝑖 − ҧ 𝑥 𝑦𝑖 − ത 𝑦 + + - - ⚫ 相関(Correlation) =標準化した共分散 帰無仮説は相関が無い( r=0 )として、検定をかける。 有意であれば、相関があると判断。
83 相関分析1 #Pearsonの積率相関係数 cor(dat1$rika1,dat1$rika2) #2変数の相関 cor(dat_seiseki) #3教科の相関 plot(dat_seiseki) #散布図 library(psych)
corr.test(dat_seiseki) #相関係数の検定 ⚫ 変数間の関連の強さは? すべて有意 *相関係数の目安 | r | = 0.7~1.0 強い相関 | r | = 0.4~0.7 中程度の相関 | r | = 0.2~0.4 弱い相関 | r | = 0~0.2 ほとんど相関なし
84 相関分析2 #カテゴリカル変数を含む相関 library(polycor) hetcor(dat_ksr, ML=T) #カテゴリカル変数を含めた相関行列 ML=最尤法 ⚫ 変数間の関連の強さは?
ポリシリアル相関:順序×連続変数の相関がみられる
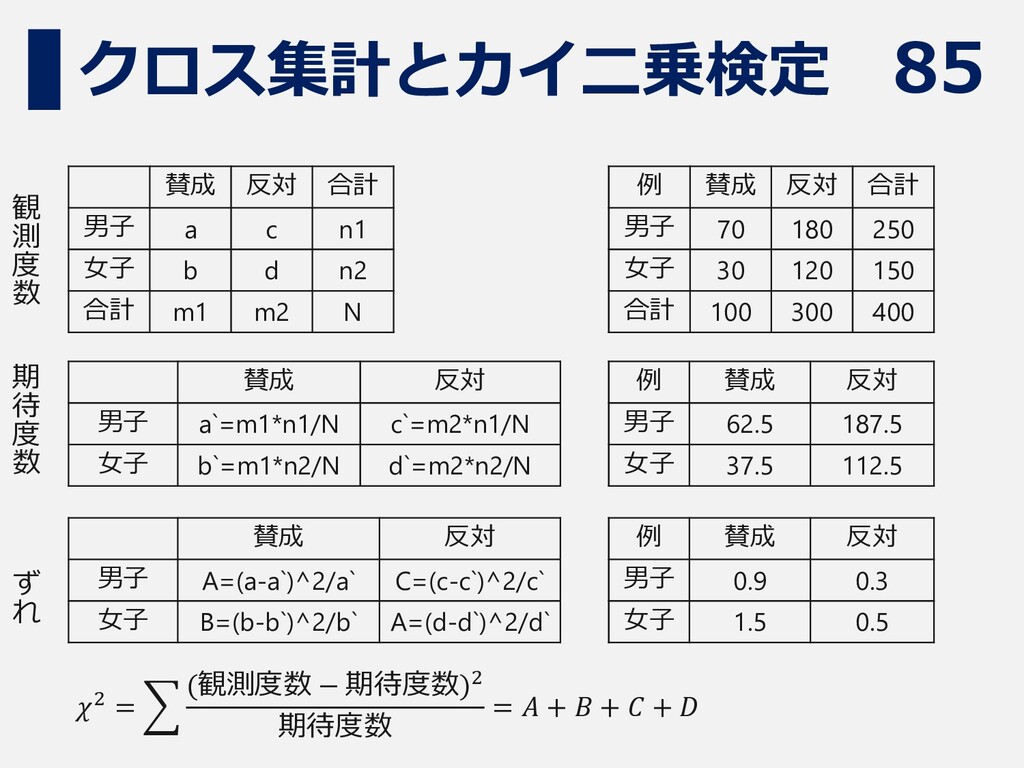
85 クロス集計とカイ二乗検定 賛成 反対 合計 男子 a c n1 女子
b d n2 合計 m1 m2 N 賛成 反対 男子 a`=m1*n1/N c`=m2*n1/N 女子 b`=m1*n2/N d`=m2*n2/N 賛成 反対 男子 A=(a-a`)^2/a` C=(c-c`)^2/c` 女子 B=(b-b`)^2/b` A=(d-d`)^2/d` 例 賛成 反対 合計 男子 70 180 250 女子 30 120 150 合計 100 300 400 例 賛成 反対 男子 62.5 187.5 女子 37.5 112.5 観 測 度 数 期 待 度 数 ず れ 𝜒2 = (観測度数 − 期待度数)2 期待度数 = 𝐴 + 𝐵 + 𝐶 + 𝐷 例 賛成 反対 男子 0.9 0.3 女子 1.5 0.5
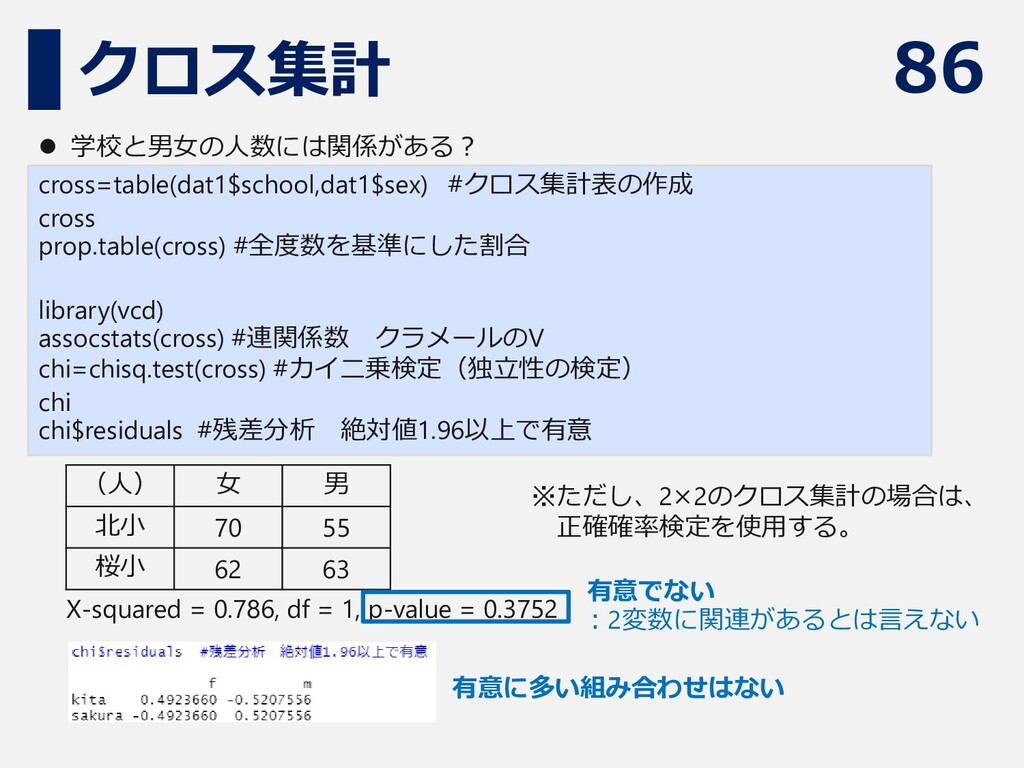
86 クロス集計 cross=table(dat1$school,dat1$sex) #クロス集計表の作成 cross prop.table(cross) #全度数を基準にした割合 library(vcd) assocstats(cross) #連関係数
クラメールのV chi=chisq.test(cross) #カイ二乗検定(独立性の検定) chi chi$residuals #残差分析 絶対値1.96以上で有意 ⚫ 学校と男女の人数には関係がある? (人) 女 男 北小 70 55 桜小 62 63 X-squared = 0.786, df = 1, p-value = 0.3752 有意に多い組み合わせはない 有意でない :2変数に関連があるとは言えない ※ただし、2×2のクロス集計の場合は、 正確確率検定を使用する。
線形モデルの拡張 単回帰分析、重回帰分析、共分散分析
88 線形モデルの種類 分析名 従属変数 独立変数 一般化線 形モデル 一般線形 モデル 単回帰分析
量的データ (正規分布) 量的データ(1つ) 重回帰分析 量的データ (正規分布) 量的データ(複数) (t検定) 量的データ (正規分布) 質的データ (群=2) (分散分析) 量的データ (正規分布) 質的データ (群≧3) ロジスティック回帰分析 質的データ (2値) 何でもOK 順序ロジスティック 回帰分析 質的データ (順序尺度) 何でもOK 多項ロジスティック 回帰分析 質的データ (名義尺度) 何でもOK 何でもOK 何でもOK
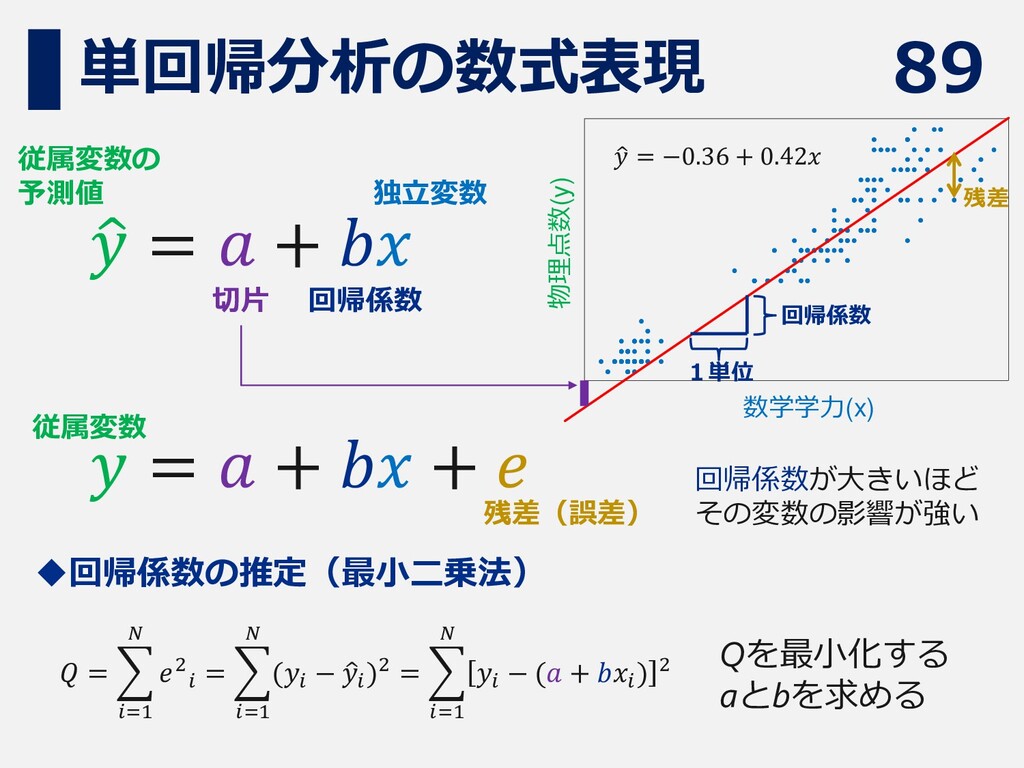
89 単回帰分析の数式表現 数学学力(x) 物理点数(y) ො 𝑦 = 𝑎 + 𝑏𝑥
切片 回帰係数 従属変数の 予測値 独立変数 回帰係数 1単位 ො 𝑦 = −0.36 + 0.42𝑥 𝑦 = 𝑎 + 𝑏𝑥 + 𝑒 残差(誤差) 残差 回帰係数が大きいほど その変数の影響が強い 従属変数 ◆回帰係数の推定(最小二乗法) 𝑄 = 𝑖=1 𝑁 𝑒2 𝑖 = 𝑖=1 𝑁 (𝑦𝑖 − ො 𝑦𝑖 )2 = 𝑖=1 𝑁 𝑦𝑖 − (𝑎 + 𝑏𝑥𝑖 ) 2 Qを最小化する aとbを求める
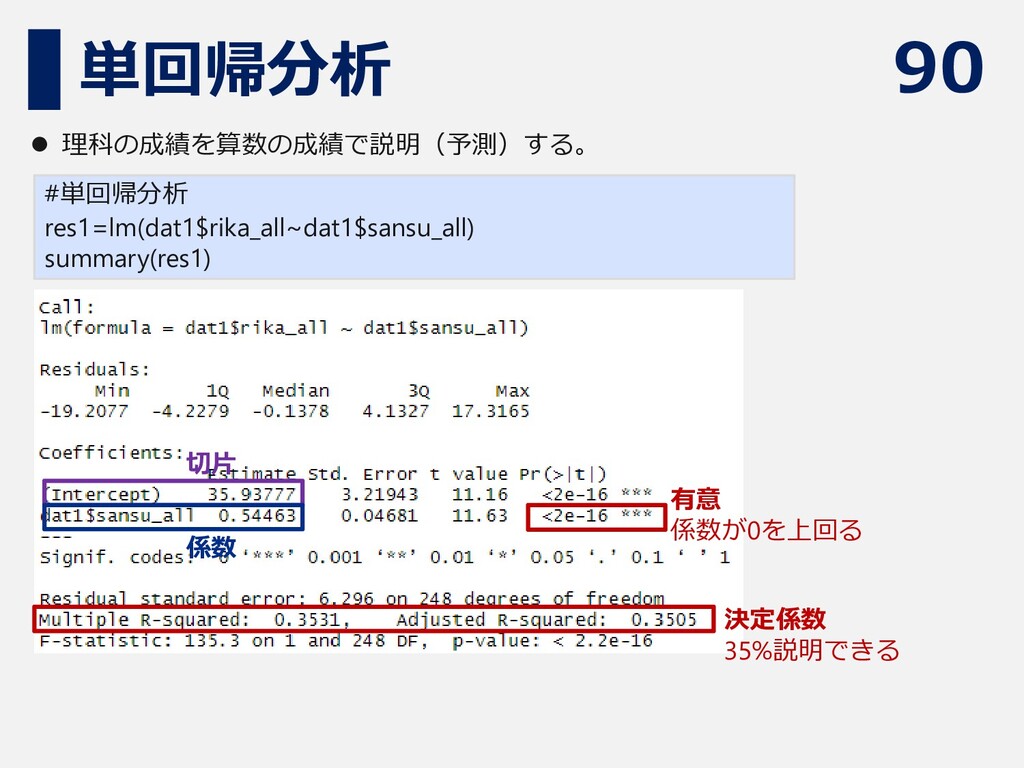
90 単回帰分析 #単回帰分析 res1=lm(dat1$rika_all~dat1$sansu_all) summary(res1) ⚫ 理科の成績を算数の成績で説明(予測)する。 有意 係数が0を上回る 切片
係数 決定係数 35%説明できる
91 重回帰分析の数式表現 読解力 数学力 物 理 点 数 ො 𝑦
= 𝑎 + 𝑏1 𝑥1 + ⋯ +𝑏𝑝 𝑥𝑝 偏回帰係数 偏回帰係数=他の独立変数の影響を取り除いたある独立変数の回帰係数 (b) 標準偏回帰係数=標準化した偏回帰係数。測定単位に依存しないので、 (β) 比較が容易。 標準化(すべての変数を平均0、分散1にそろえる)
92 (標準)偏回帰係数の解釈 ⚫ 偏回帰係数 他の独立変数を一定(同程度)としたとき、 𝑥𝑝 が1単位増えればyが平均的に𝑏𝑝 増える ⚫ 標準偏回帰係数
他の独立変数を一定(同程度)としたとき、 𝑥𝑝 が1標準偏差増えればyが平均的に𝛽𝑝 標準偏差増える 年収=322.9+1.2*年齢+8.7*勤続年数という重回帰式か ら年収(万円)に対する年齢(歳)と勤続年数(年) の影響はどのように解釈できるでしょうか。 年収=0.07*年齢+0.52*勤続年数という標準偏回帰係数 を用いた重回帰式から年収(万円)に対する年齢 (歳)と勤続年数(年)の影響はどのように解釈でき るでしょうか。また、年齢と勤続年数のどちらが大き な影響をもっているでしょうか。
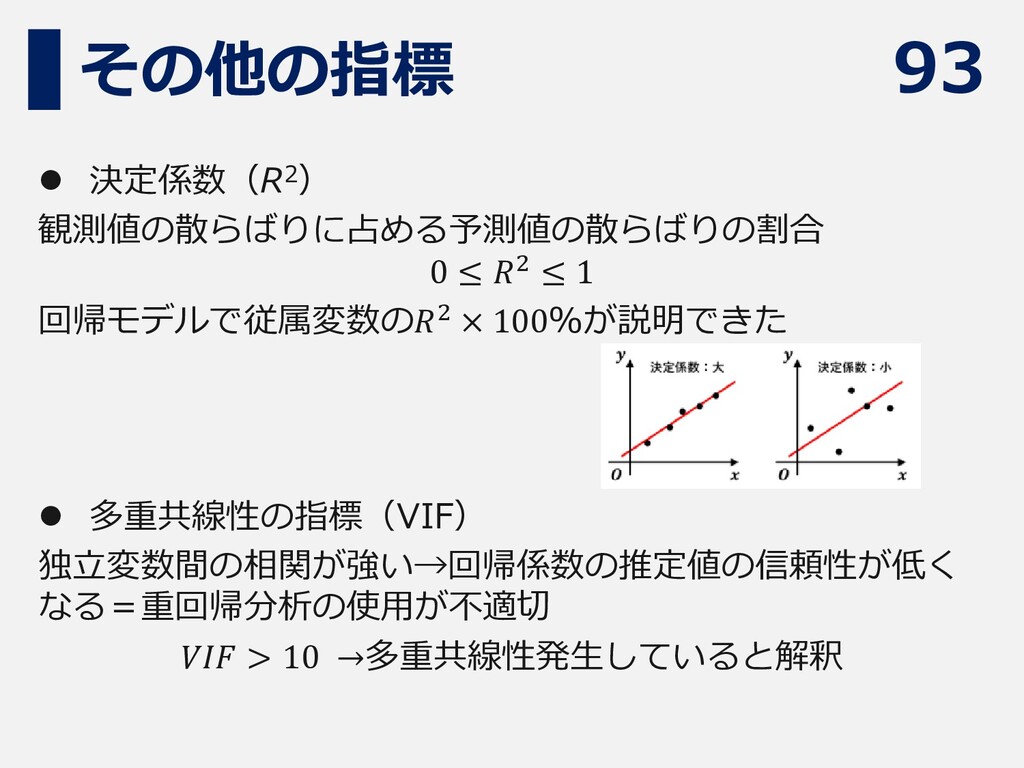
93 その他の指標 ⚫ 決定係数(R2) 観測値の散らばりに占める予測値の散らばりの割合 0 ≤ 𝑅2 ≤ 1
回帰モデルで従属変数の𝑅2 × 100%が説明できた ⚫ 多重共線性の指標(VIF) 独立変数間の相関が強い→回帰係数の推定値の信頼性が低く なる=重回帰分析の使用が不適切 𝑉𝐼𝐹 > 10 →多重共線性発生していると解釈
94 #重回帰分析 res2.1=lm(rika_all~sansu_all+kokugo_all,data = dat1) summary(res2.1) #偏回帰係数 dat_z=scale(dat_seiseki) #標準化 dat_z=data.frame(dat_z)
res2.2=lm(rika_all~sansu_all+kokugo_all,data = dat_z) summary(res2.2) #標準偏回帰係数 library(car) vif(res2.2) # VIF 重回帰分析 ⚫ 理科の成績を算数と国語の成績で説明(予測)する。 有意 VIF>10だと多重共線性に問題あり。 VIF<2なら問題なし。 ↑どうやって解釈する?
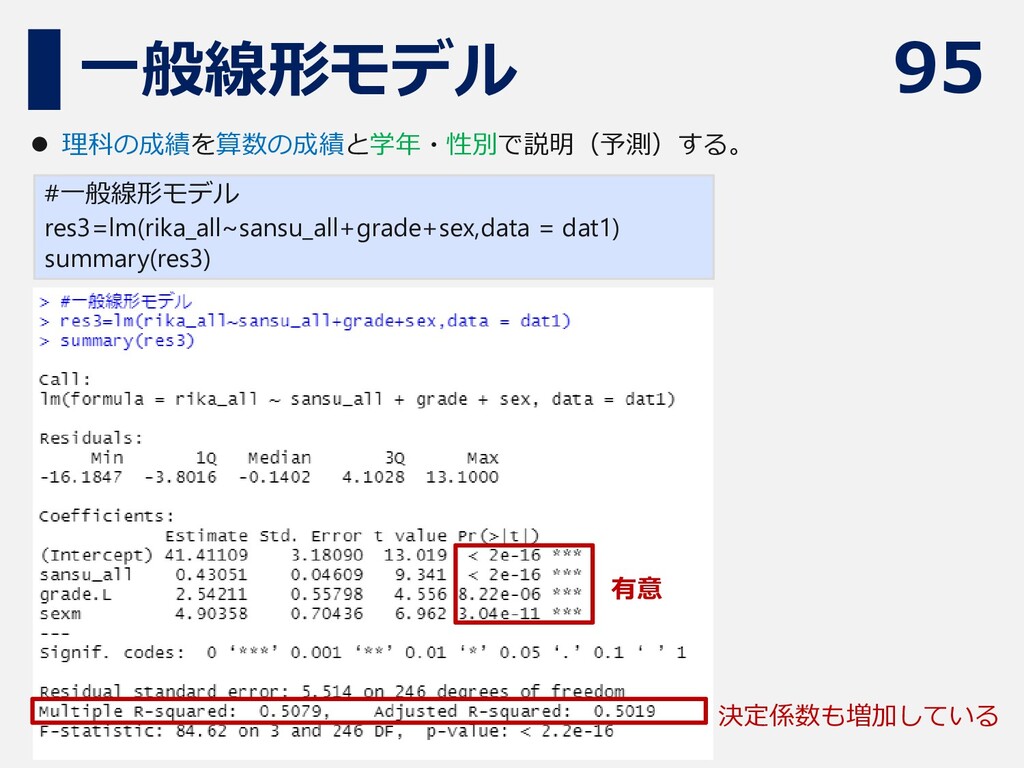
95 一般線形モデル #一般線形モデル res3=lm(rika_all~sansu_all+grade+sex,data = dat1) summary(res3) ⚫ 理科の成績を算数の成績と学年・性別で説明(予測)する。 有意
決定係数も増加している
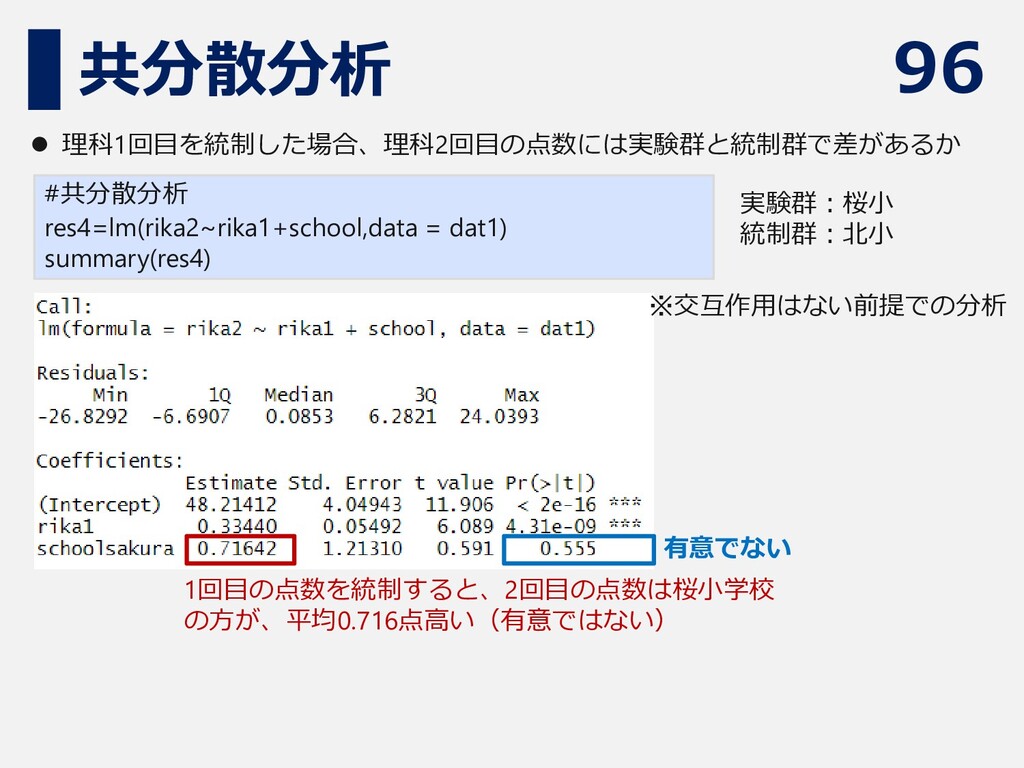
96 共分散分析 #共分散分析 res4=lm(rika2~rika1+school,data = dat1) summary(res4) ⚫ 理科1回目を統制した場合、理科2回目の点数には実験群と統制群で差があるか 有意でない
1回目の点数を統制すると、2回目の点数は桜小学校 の方が、平均0.716点高い(有意ではない) ※交互作用はない前提での分析 実験群:桜小 統制群:北小
97 因果関係を示すためには? ⚫ ミルの三原則 1. 原因は結果よりも時間的に先行していること 2. 原因と結果の間には関連があること 3. 他の因果的説明が排除されていること
• 回帰分析やパス解析で示せるのは2.のみ。 • 因果関係を示すためには、実験計画法や縦断調査が必要。
98 練習問題 1. t検定をそのまま繰り返してはいけないのはなぜか 説明せよ 2. 標準化した共分散を何と呼ぶだろうか 3. 偏回帰係数と標準偏回帰係数の違いを説明せよ
99 復習 1. 3群の平均値の差を検討する際,分散分析が有意であった ことからどのようなことが言えるだろうか。 2. ピアソンの積率相関係数が取り得る値の範囲を答えよ。 3. 重回帰回帰分析において、独立変数間の影響の強さを比較 したい場合、偏回帰係数と標準偏回帰係数のどちらを用い
るべきか。
多変量解析 探索的因子分析、確認的因子分析、 構造方程式モデリング、クラスター分析 100
101 構成概念 ⚫ 人に関する現象を説明するために、研究者によって人為的 に構成された概念 例)思いやり、社交性、理解度、科学的思考力、批判的思考態度 ⚫ 構成概念の影響を受けるであろう複数の行動や態度を測定 し、構成概念の存在を検証する マンガ
好き 行動1 (読む) 行動2 (買う) 行動3 (話す) 理論世界 現実世界
102 心理尺度の測定法 ⚫ 言葉による質問によって行動や考え方を測るものを 心理尺度と呼ぶ ◆ 様々な測定法がある ★リッカート法(評定総和法) Q1. このマンガについてよく知っている
非 常 に 当 て は ま る や や 当 て は ま る あ ま り 当 て は ま ら な い ま っ た く 当 て は ま ら な い ど ち ら で も な い ★サーストン法(等現間隔法) そのマンガについて知らないことはない そのマンガを週刊誌で毎週読んでいる そのマンガの単行本が出たら読む そのマンガを読もうと思ったことがある そのマンガの名前も聞いたことが無い 5.12点 4.05点 3.24点 1.93点 1.13点 ※最も近い項目を選ぶ ★ガットマン法(強度分析法) ★SD法(意味微分法) 1 2 3 4 5
103 構成概念妥当性 construct validity ⚫ 構成概念妥当性(=測りたいものを測れているか) 1. 内容的な側面 :項目内容が構成概念の定義と比べて適切か(網羅しているか) 2.
本質的な側面 :反応プロセスが想定通りか 3. 構造的な側面 :内的なまとまり(因子構造)が理論や仮説と一致しているか 4. 一般化可能性の側面(信頼性) :測定誤差が小さいか(繰り返し同じ結果になるか) 5. 外的な側面 :外的変数との間に予測通りの関係(相関)が見られるか
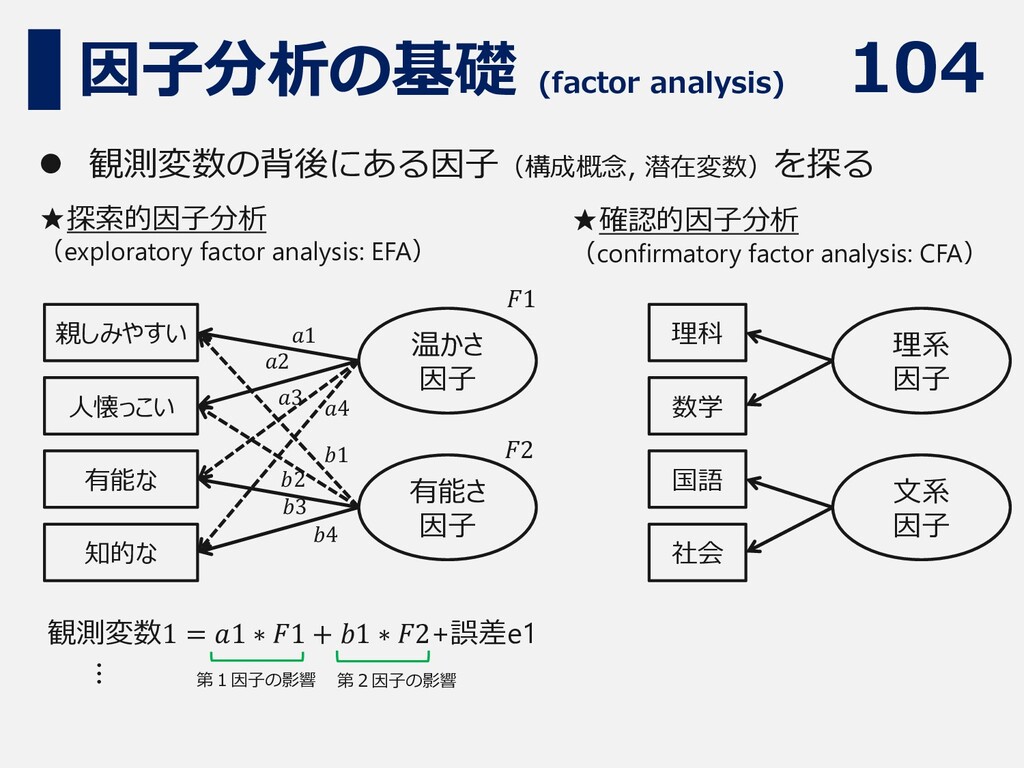
104 因子分析の基礎 (factor analysis) ⚫ 観測変数の背後にある因子(構成概念, 潜在変数)を探る ★探索的因子分析 (exploratory factor
analysis: EFA) ★確認的因子分析 (confirmatory factor analysis: CFA) 親しみやすい 人懐っこい 有能な 知的な 温かさ 因子 有能さ 因子 理科 数学 国語 社会 理系 因子 文系 因子 観測変数1 = 𝑎1 ∗ 𝐹1 + 𝑏1 ∗ 𝐹2+誤差e1 𝑎1 𝑎2 𝑎3 𝑎4 𝑏1 𝑏2 𝑏3 𝑏4 𝐹1 𝐹2 … 第1因子の影響 第2因子の影響
105 因子負荷量 ⚫ 因子負荷量:因子から観測変数への影響力の強さ ⚫ 共通性:因子によって説明される要素 ⚫ 独自性:各項目が持つ独自の要素(因子によって説明されない 部分) 因子
共通性 独自性 共通性 独自性 共 独自性 共通性 独 ◼ 因子分析の結果の例(1因子・2因子) 項目 因子負荷量 共通性 物理が好き .90 .80 化学が好き .82 .66 生物が好き 74 .53 地学が好き .68 .48 項目 F1 F2 共通性 親しみやすい .68 .29 .55 人懐っこい .79 .15 .65 有能な .20 .81 .69 知的な .22 .88 .82
106 因子軸の回転 ⚫ 特別な処理をせずに求めた因子負荷量を初期解と呼ぶ ⚫ 初期解の解釈が難しい場合、因子軸を回転させる(因子負荷 量を変換する)ことで因子が識別しやすくなる(※2因子以上の 時) ★斜交回転 例)プロマックス回転
★直行回転 例)バリマックス回転 因子1 因子1 因子2 項目 F1 F2 共 親しみやすい .70 -.24 .55 人懐っこい .69 -.41 .65 有能な .68 .47 .69 知的な .75 .51 .82 項目 F1 F2 共 親しみやすい .68 .29 .55 人懐っこい .79 .15 .65 有能な .20 .81 .69 知的な .22 .88 .82 ◼ 回転前(初期解) ◼ 回転後
107 探索的因子分析の手順 1. 因子数のあたりをつける ➢ 平行分析、ガットマン基準、スクリーテスト 2. 候補の因子数で因子分析を行う 3. 複数因子で初期解の解釈が難しい場合は、回転を行う
4. 因子負荷量が低い項目(0.4以下)などは外し、再度、因 子分析を繰り返す 5. 信頼性係数を確認する 6. 因子構造を解釈し、因子名を付ける
108 探索的因子分析1 #探索的因子分析##### #データの取り出し dat_CT=dat1[,c(16:22)] #16~22列目の取り出し ⚫ 批判的思考:何を信じ、何を行うかの決定に焦点を当てた、合理的で 省察的な思考(Ennis, 1987)。
←Q1~Q7(7件法) 1 いつも偏りのない判断をしようとする 2 物事を決めるときには、客観的な態度を心がける 3 できるだけ多くの立場から考えようとする 4 自分が偏った見方をしていないかふり返るように している 5 たとえ意見が合わない人の話にも耳を傾ける 6 自分のと異なる考えの人とも議論する 7 物事を見るときは様々な立場から見る
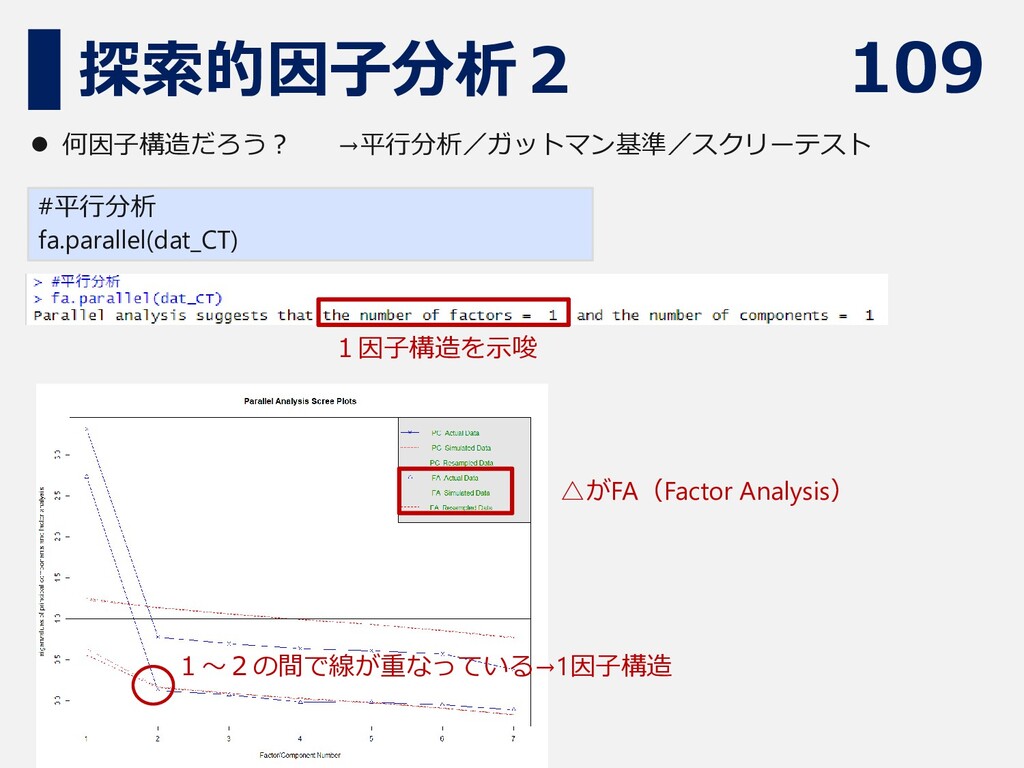
109 探索的因子分析2 #平行分析 fa.parallel(dat_CT) ⚫ 何因子構造だろう? →平行分析/ガットマン基準/スクリーテスト 1因子構造を示唆 1~2の間で線が重なっている→1因子構造 △がFA(Factor
Analysis)
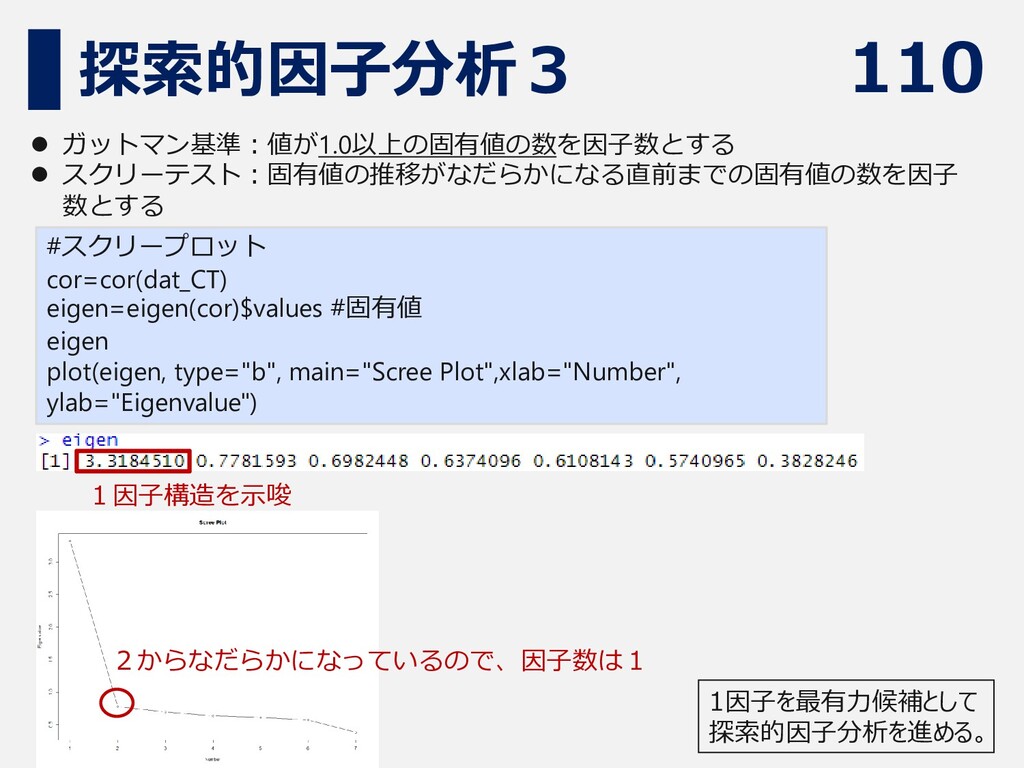
110 探索的因子分析3 #スクリープロット cor=cor(dat_CT) eigen=eigen(cor)$values #固有値 eigen plot(eigen, type="b", main="Scree
Plot",xlab="Number", ylab="Eigenvalue") ⚫ ガットマン基準:値が1.0以上の固有値の数を因子数とする ⚫ スクリーテスト:固有値の推移がなだらかになる直前までの固有値の数を因子 数とする 2からなだらかになっているので、因子数は1 1因子構造を示唆 1因子を最有力候補として 探索的因子分析を進める。
111 探索的因子分析4 #因子数1の検討 fit1 = factanal(x=dat_CT, factors=1, fm="ml", rotation="none") print(fit1)
fit2 = factanal(x=dat_CT, factors=1, fm="ml", rotation="promax") print(fit2, cutoff=0.35) #因子負荷量0.35以下を非表示 ⚫ 因子数1として因子負荷を推定 1因子の場合、回転は不要。 因子間に相関が仮定される場合 プロマックス回転(斜交回転)。 推定方法は最尤法がおすすめ。 ←最尤法、プロ マックス回転 ←因子負荷量(0.4以上ならOK) 本来はこの後、因子名を考えるなどの作業がある。
112 探索的因子分析5 #信頼性係数の算出(アルファとオメガ) psych::alpha(dat_CT)#α係数 omega(nfactors = 1,dat_CT) #ω係数 ⚫ 信頼性の確認
ω係数の方がより正確な信頼性の推 定値。ただし、現実にはα係数とほぼ 同じ値になる。両方を報告することを 推奨。 0.8以上であれば信頼性が高い ←α係数 ←ω係数 #2因子の場合 psych::alpha(dat_因子1)#α係数1 psych::alpha(dat_因子2)#α係数2 omega(nfactors = 1,dat_因子1) #ω係数1 omega(nfactors = 1,dat_因子2) #ω係数2 信頼性係数は、因子ごとに計算する。
113 尺度得点との相関 #相関の検討 dat1$CT=rowMeans(dat1[,c(16:22)]) #指定行の平均値を変数として作成 cor(dat1$rika_all,dat1$CT) #理科とクリシンの相関 cor(dat1$sansu_all,dat1$CT) #算数とクリシンの相関 cor(dat1$kokugo_all,dat1$CT)
#国語とクリシンの相関 ⚫ クリシン得点の変数を作成し、成績との相関を見てみよう ←算数と理科では弱い相関がみられる *相関係数の目安 | r | = 0.7~1.0 強い相関 | r | = 0.4~0.7 中程度の相関 | r | = 0.2~0.4 弱い相関 | r | = 0~0.2 ほとんど相関なし
114 報告例(探索的因子分析) 項 目 因 子 F1 F2 (18) 深く考えなければならないような状況は避けようとする。
.84 -.04 (15) 考えなければならない時しか考えない方である。 .78 -.03 (16) 深く考えなければ切り抜けられないような事態に対処することは任 されたくない。 .73 .02 (14) 長時間一生懸命考えることは苦手な方である。 .69 .03 (4) 読んだものがよく理解できないとき、それを放り出し忘れてしまう。 .53 .13 (21) 常に頭を使わなければ満足できない。 .48 -.05 (17) 考えることは楽しくない。 .05 .73 (7) 新しい考え方を学ぶことにはあまり興味がない。 -.10 .71 (1) いろいろな問題の新しい解決方法を考えることは楽しい。 -.02 .62 (24) 問題の答えがなぜそうなるのかを理解するよりも、単純に答えだけ を知っている方がよい。 -.08 .57 (8) なぜそうなるのかを理解しようとするよりも、物事をあるがままに 受け取るほうが好きだ。 .06 .51 (19) 自分が人生で何をすべきかについて考えるのは好きではない。 .06 .51 負荷量の平方和 2.87 2.29 Cronbachのα係数 .84 .76 McDonaldのω係数 .88 .82 因子間相関 F2 .46 表に基づき各因子を検討すると、第1因子は、「深く考えなければならないような状況は避けようとす る」、「考えなければならない時しか考えない方である」、「長時間一生懸命考えることは苦手な方であ る」など、じっくりと考えることを楽しむ思考傾向に関する質問項目で構成されているため、第1因子を 「熟慮動機」と解釈した。第2因子は、「考えることは楽しくない」、「新しい考え方を学ぶことにはあ まり興味がない」、「いろいろな問題の新しい解決方法を考えることは楽しい」など、考えることを楽し む思考傾向に関する質問項目で構成されているため、第2因子を「思考を楽しむ動機」と解釈した。 次に、各因子の信頼性について検討する。表に示すCronbachのα係数およびMcDonaldのω係数が0.76 ~ 0.88となったことから、内部一貫性が保障されたと考え、十分な信頼性があると判断した。 固有値の減衰状況および平行分析の結果を踏まえ、因子数を2として探索的因子分析(最尤法・プロ マックス回転)を行った結果を表にしめす。
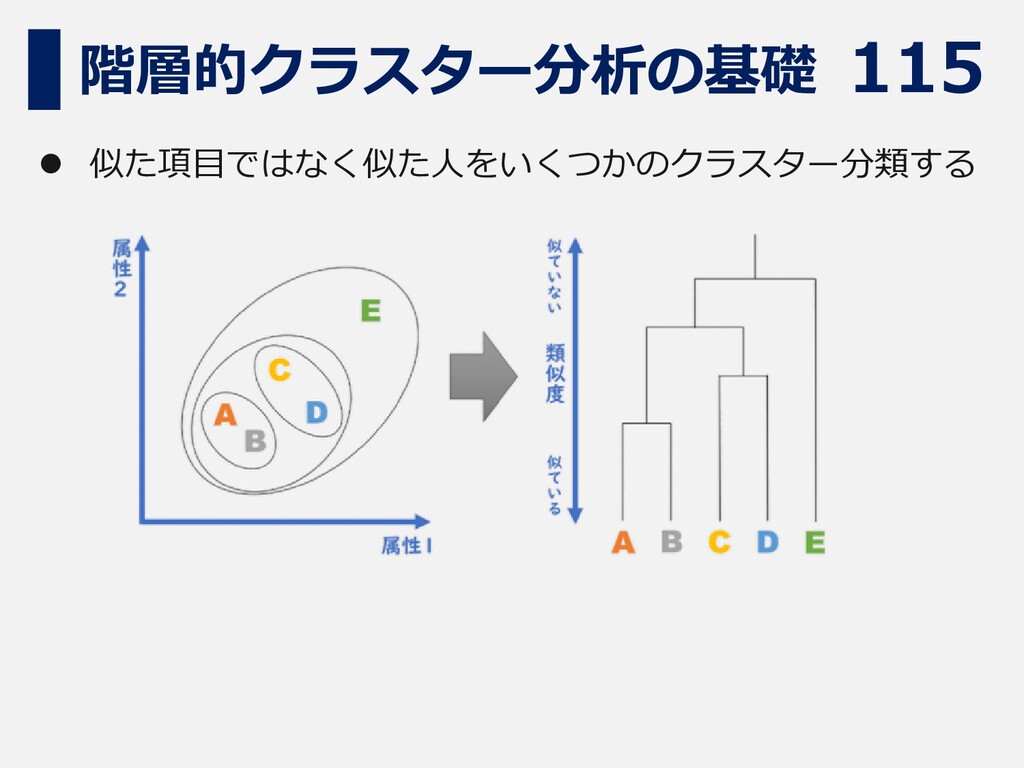
115 階層的クラスター分析の基礎 ⚫ 似た項目ではなく似た人をいくつかのクラスター分類する
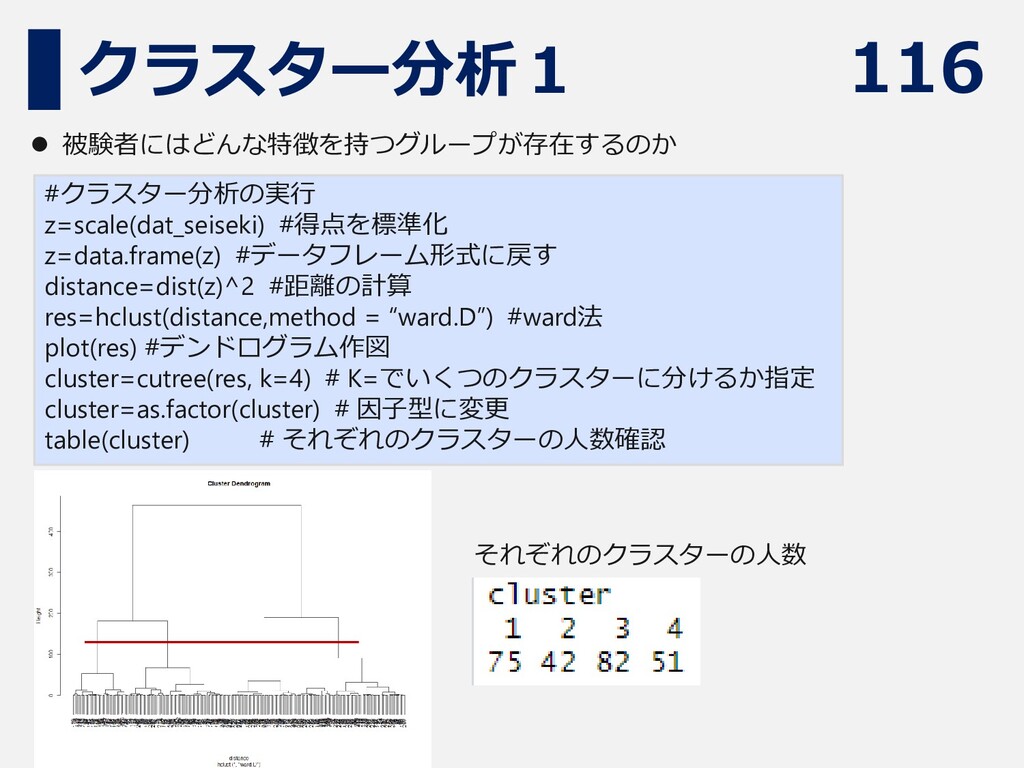
116 クラスター分析1 #クラスター分析の実行 z=scale(dat_seiseki) #得点を標準化 z=data.frame(z) #データフレーム形式に戻す distance=dist(z)^2 #距離の計算 res=hclust(distance,method
= “ward.D”) #ward法 plot(res) #デンドログラム作図 cluster=cutree(res, k=4) # K=でいくつのクラスターに分けるか指定 cluster=as.factor(cluster) # 因子型に変更 table(cluster) # それぞれのクラスターの人数確認 ⚫ 被験者にはどんな特徴を持つグループが存在するのか それぞれのクラスターの人数
117 クラスター分析2 #クラスター分けの結果を結合 x=cbind(z, cluster) # 標準得点のデータフレーム y=cbind(dat_seiseki, cluster) #
素点のデータフレーム #クラスターごとの平均の確認 tapply(x$kokugo_all, x$cluster, mean) #クラスターごとの国語得点 tapply(x$sansu_all, x$cluster, mean) #クラスターごとの算数得点 tapply(x$rika_all, x$cluster, mean) #クラスターごとの理科得点 ⚫ 被験者にはどんな特徴を持つグループが存在するのか クラスター1:国語×算数△理科× 「文字苦手グループ」 クラスター2:国語×算数×理科× 「勉強苦手グループ」 クラスター3:国語〇算数△理科〇 「論理的思考グループ」 クラスター4:国語△算数〇理科〇 「理系グループ」
構造方程式モデリングの世界 分析の統一的な枠組み Structural Equation Modeling (SEM) (共分散構造分析)
119 構造方程式モデリング(SEM) のアプローチ ① 複数の変数間の関連性について、特定の仮説モデルを 設定 ② その仮説モデルの妥当性を検証 ③ モデルが正しいとした場合の変数間の定量的な関連性
を推定 仮説モデル: 変数間にどのような因果関係や相関関係があるかという理論的な仮説 を表現したモデル。パス図という図で視覚的に表現する。 仮説モデルの妥当性: 適合度という概念で検証する。適合度とは、解析に使用したデータと、 仮定されたモデルの間の一致度を意味し、適合度が高いほど、モデル の妥当性が高いことが示唆される。 定量的な関連性: パス係数(パラメータ推定値)と呼ばれる値で表現。仮定したモデルのも とでの変数間の因果関係や相関関係の強さに関する推定値を意味する。
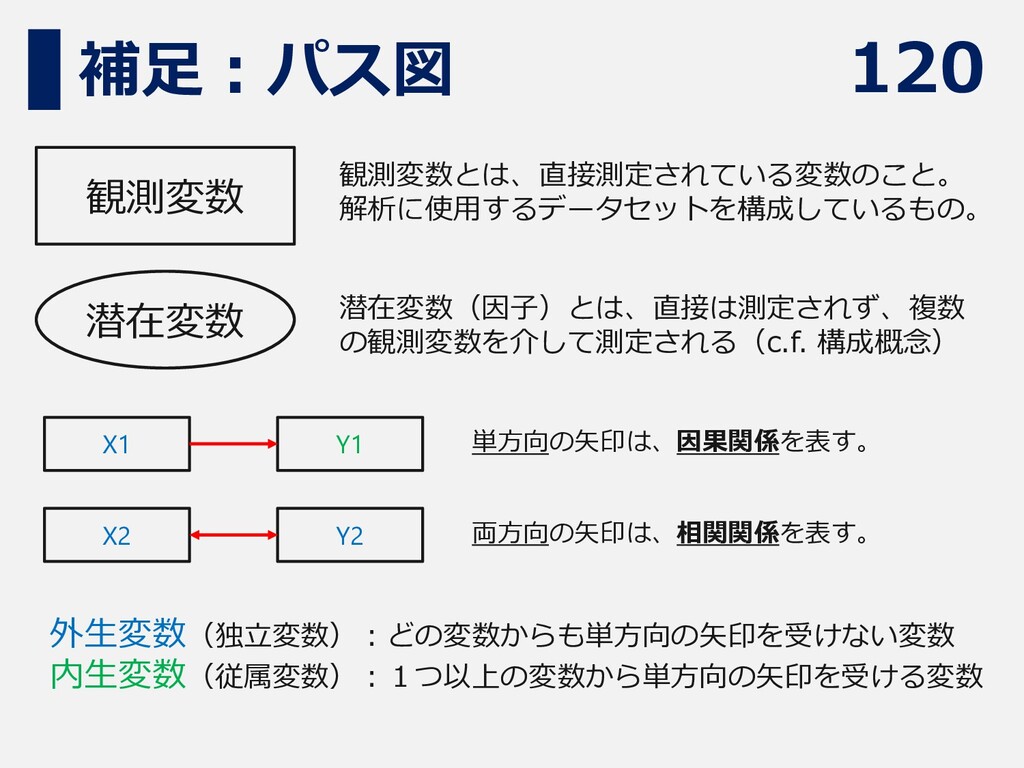
120 補足:パス図 観測変数 潜在変数 観測変数とは、直接測定されている変数のこと。 解析に使用するデータセットを構成しているもの。 潜在変数(因子)とは、直接は測定されず、複数 の観測変数を介して測定される(c.f. 構成概念) X1
Y1 X2 Y2 単方向の矢印は、因果関係を表す。 両方向の矢印は、相関関係を表す。 外生変数(独立変数):どの変数からも単方向の矢印を受けない変数 内生変数(従属変数):1つ以上の変数から単方向の矢印を受ける変数
121 構造モデルと測定モデル F1 F3 F2 <構造モデル> 複数の概念感の因果関係に関する仮説を表すもの。 因果関係に関する仮説は、先行研究の知見や理論 的な検討によって、先験的に設定される必要があ る。
F X1 X2 X3 <測定モデル> 直接観測できない構成概念を、潜在変数(因子) として複数の観測変数を通して定量化するもの。 (≒確認的因子分析) + = <フルSEMモデル> 構造モデルと測定モデルを組み合わせたもの。
122 練習問題 F1 友人関係 F3 抑うつ F2 家族関係 X1 X2
X3 X4 X5 X6 X7 X8 d1 e1 e2 e3 e4 e5 e6 e7 e8 e1~e8, d1 : 誤差変数 内生変数には、他の変数 によって説明されない成 分(残差)が仮定され、 誤差変数と呼ばれる。 Q1 潜在変数はいくつあるか。 Q2 どの変数間に、相関関係が仮定されているか。 Q3 外生変数をすべて挙げよ。 Q4 このパス図が示す、仮説モデルを説明せよ。
123 補足:適合度1 ⚫ 仮説モデルのもとでの分散・共分散行列と、実際 の分散・共分散行列のズレを評価 指標 説明 範囲 良好 悪い
χ2値 因果モデル全体が正し いかどうかの指標。 χ2≧0 有意でなければ OK p>0.05 SRMR モデルとのズレの残差 に関する指標。 SRMR≧0 .08以下(良い) .10以下(許容) 0.1以上 RMSEA モデルの分布と真の分 布の乖離を1自由度あ たりの量として表現し た指標。 RMSEA≧ 0 0.05未満 0.1以上 AIC 複数のモデルを比較す る際に、モデルの相対 的な良さを評価する指 標。 - 想定的に低いほど、予測力 の高いモデル BIC 表1 小さい方が良い指標
124 補足:適合度2 ⚫ 仮説モデルのもとでの分散・共分散行列と、実際 の分散・共分散行列のズレを評価 指標 説明 範囲 良好 悪い
GFI モデルの説明力の指標。 GFI≦1 0.95以上 0.9未満 AGFI GFIの自由度を調整した 指標。 AGFI≦GFI 0.95以上 0.9未満 CFI 独立モデル(すべての 変数が無相関)を基準 とした場合のモデル適 合を評価する指標。 0~1 0.90以上 (0.95以上) 0.9未満 表2 大きい方が良い指標 ※ただし、適合度の高いモデルは、多数存在する「ありうるモデル」の中の 1つにすぎない。 →十分な理論的根拠に基づく判断が必要 ◆ 適合度が悪かったら、モデルを改善して、再度推定してみる。
125 構造方程式と共分散構造 X 1 友人関係 X 2 家族関係 Y 1
抑うつ d 1 φ12 γ11 γ12 <推定したい値> パス係数=γ11, γ12 誤差分散(d1 )=θ1 分散( X1 )=φ11, 分散( X2 )=φ22 共分散(X1, X2 )= φ12 γ◯△ ◯=従属変数の番号 △=独立変数の番号 共分散の値を、両変数の標準 偏差の積で割って標準化した ものが相関係数 *パス係数 回帰分析における回帰係数 (or偏回帰係数)と数学的に 同一。独立変数が1単位上昇 したときの充足変数の変化の 期待値を意味する。 方程式(構造方程式)で表すと・・・ 𝑌1 = 𝛾11 𝑋1 + 𝛾12 𝑋2 + 𝑑1 <得られている値> 観測変数=X1 , X2 , Y1 X1 X2 Y1 X1 φ11 X2 φ12 φ22 Y1 𝛾11 𝜑11 + 𝛾12 𝜑22 𝛾11 𝜑12 + 𝛾12 𝜑22 𝛾2 11 𝜑11 + 2𝛾11 𝛾12 𝜑12 + 𝛾2 12 𝜑22 + 𝜃1 表 構造モデルの共分散構造 ←対角成分は、分散 その他の成分は、共分散 6個のパラメータ
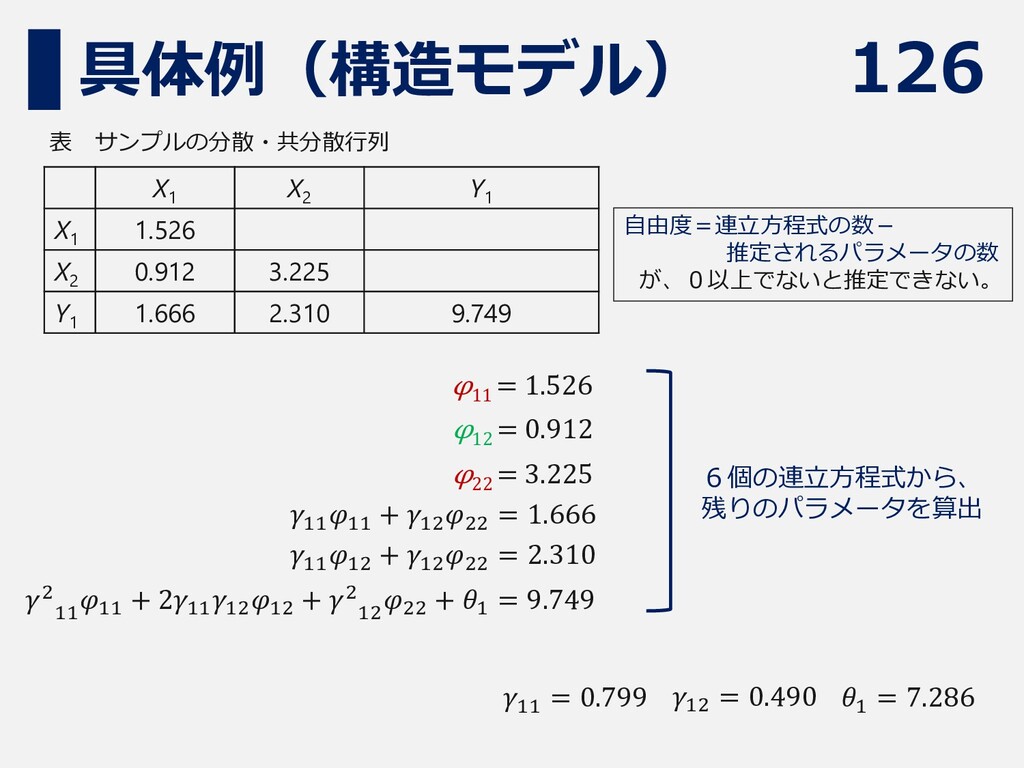
126 具体例(構造モデル) X1 X2 Y1 X1 1.526 X2 0.912 3.225
Y1 1.666 2.310 9.749 表 サンプルの分散・共分散行列 φ 11 = 1.526 φ 12 = 0.912 φ 22 = 3.225 𝛾11 𝜑11 + 𝛾12 𝜑22 = 1.666 𝛾11 𝜑12 + 𝛾12 𝜑22 = 2.310 𝛾2 11 𝜑11 + 2𝛾11 𝛾12 𝜑12 + 𝛾2 12 𝜑22 + 𝜃1 = 9.749 6個の連立方程式から、 残りのパラメータを算出 𝛾12 = 0.490 𝛾11 = 0.799 𝜃1 = 7.286 自由度=連立方程式の数- 推定されるパラメータの数 が、0以上でないと推定できない。
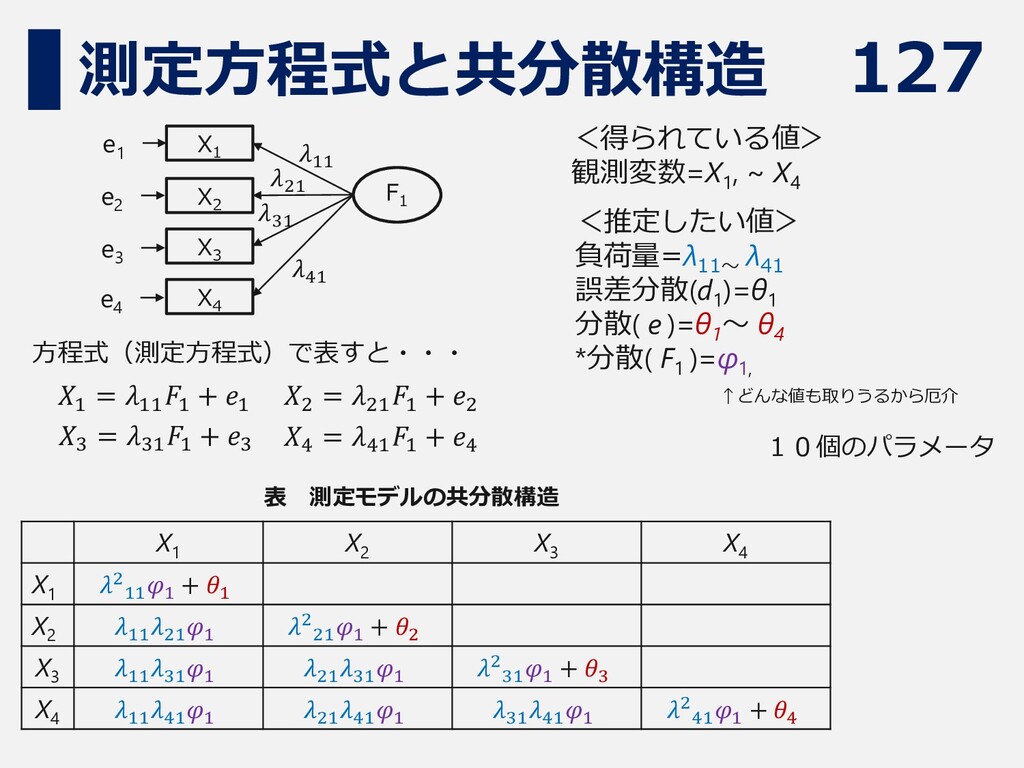
127 測定方程式と共分散構造 <推定したい値> 負荷量=λ11~ λ41 誤差分散(d1 )=θ1 分散( e )=θ1
~ θ4 *分散( F1 )=φ1, 方程式(測定方程式)で表すと・・・ 𝑋1 = 𝜆11 𝐹1 + 𝑒1 <得られている値> 観測変数=X1 , ~ X4 X1 X2 X3 X4 X1 𝜆2 11 𝜑1 + 𝜃1 X2 𝜆11 𝜆21 𝜑1 𝜆2 21 𝜑1 + 𝜃2 X3 𝜆11 𝜆31 𝜑1 𝜆21 𝜆31 𝜑1 𝜆2 31 𝜑1 + 𝜃3 X4 𝜆11 𝜆41 𝜑1 𝜆21 𝜆41 𝜑1 𝜆31 𝜆41 𝜑1 𝜆2 41 𝜑1 + 𝜃4 表 測定モデルの共分散構造 10個のパラメータ F 1 X 1 X 2 X 3 X 4 e1 e2 e3 e4 𝑋2 = 𝜆21 𝐹1 + 𝑒2 𝑋3 = 𝜆31 𝐹1 + 𝑒3 𝑋4 = 𝜆41 𝐹1 + 𝑒4 𝜆11 𝜆21 𝜆31 𝜆41 ↑どんな値も取りうるから厄介
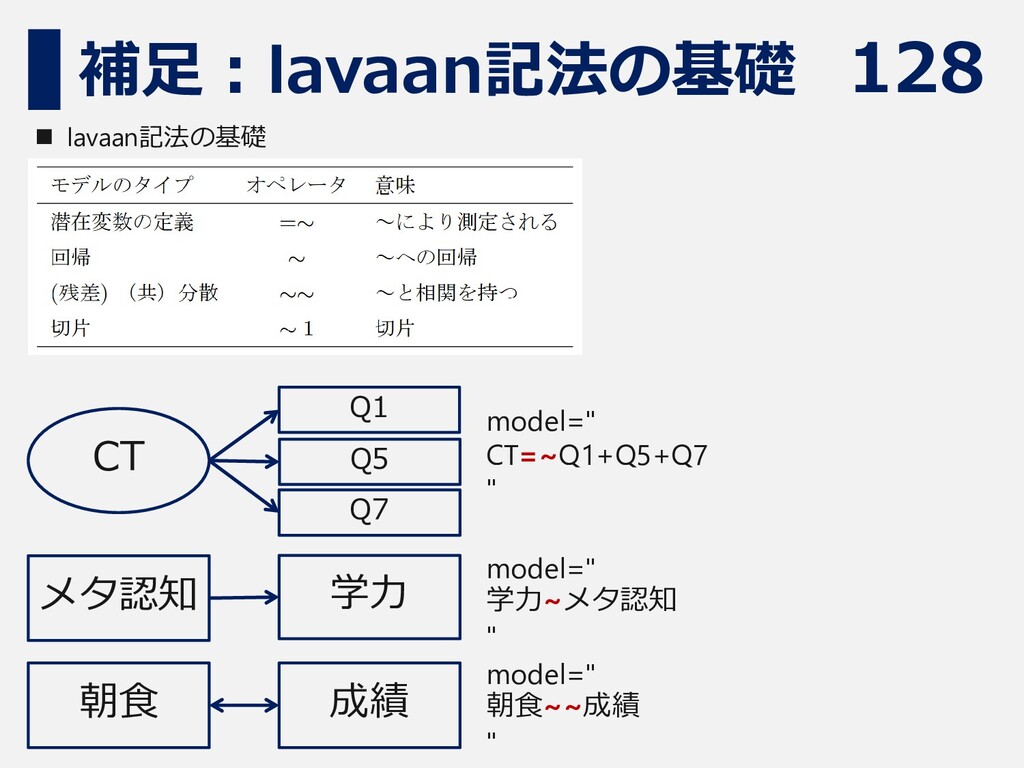
128 補足:lavaan記法の基礎 ◼ lavaan記法の基礎 メタ認知 学力 朝食 成績 CT Q1
Q5 Q7 model=" CT=~Q1+Q5+Q7 " model=" 学力~メタ認知 " model=" 朝食~~成績 "
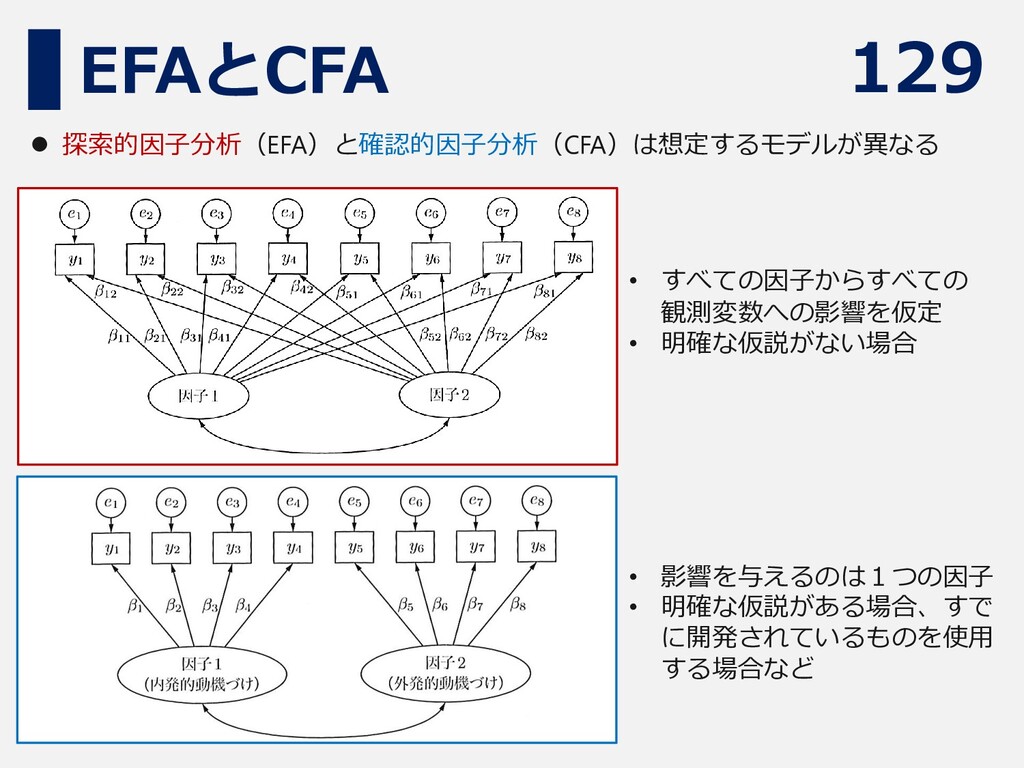
129 EFAとCFA ⚫ 探索的因子分析(EFA)と確認的因子分析(CFA)は想定するモデルが異なる • すべての因子からすべての 観測変数への影響を仮定 • 明確な仮説がない場合 •
影響を与えるのは1つの因子 • 明確な仮説がある場合、すで に開発されているものを使用 する場合など
130 確認的因子分析1 #確認的因子分析##### #SEM library(lavaan) #1因子モデル model1=" F1=~CT1+CT2+CT3+CT4+CT5+CT6+CT7 " fit1=cfa(model1,data=dat_CT)
#確認的因子分析 summary(fit1, standardized=T, fit.measures=T) modificationIndices(fit1, minimum.value = 100) #修正指標 ⚫ 構造方程式モデリングの枠組みで、確認的因子分析を行う。 ML=最尤法で推定 250人のデータ ←標準化した係数=T 適合度表示=T
131 確認的因子分析2 ⚫ 出力の解釈 ←標準化推定値 CFI=1.00, RMSEA=0.00, SRMR=0.03 →十分な適合度
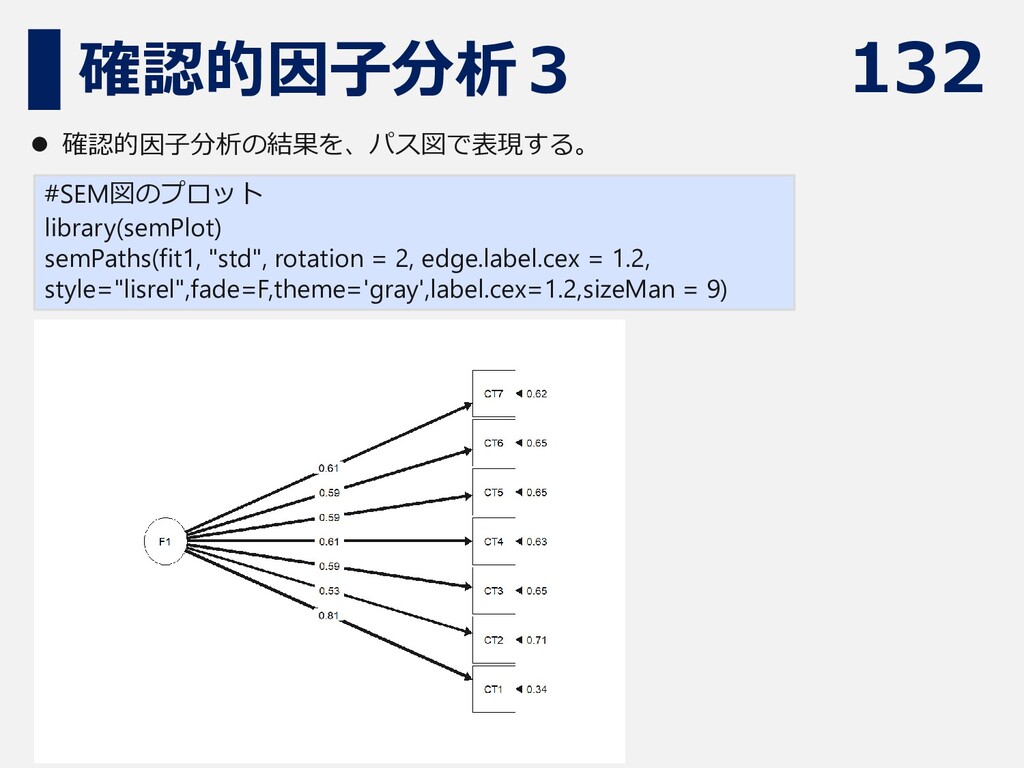
132 確認的因子分析3 #SEM図のプロット library(semPlot) semPaths(fit1, "std", rotation = 2, edge.label.cex
= 1.2, style="lisrel",fade=F,theme='gray',label.cex=1.2,sizeMan = 9) ⚫ 確認的因子分析の結果を、パス図で表現する。
133 報告例1(確認的因子分析) ◼ 先行研究の知見に基づき、批判的思考に1因子構造を想定 した確認的因子分析を行った。分析の結果、適合度指標 は、CFI=1.00, TLI=1.00, RMSEA=.00(90%CI [.00, .06]),
SRMR=0.03であり、データに対するモデルの当てはまり は十分であると判断された。
134 報告例2(確認的因子分析) 3つの因子構造モデルおよび神山・藤原(1991)による1因子モデルについ て、確認的因子分析(CFA)による比較を行うことにした。4つのモデルにおけ る適合度指標および情報量基準を表に示す。 指標 4因子モデル 2因子モデル 修正版2因子モデル 1因子モデル
(神山・藤原,1991) CFI 0.83 0.83 0.98 0.63 TLI 0.80 0.80 0.98 0.57 RMSEA [90%CI] (p値※) 0.09 [0.08, 0.10] (0.00) 0.10 [0.08, 0.11] (0.00) 0.03 [0.00, 0.07] (0.72) 0.13 [0.11, 0.15] (0.00) SRMR 0.08 0.08 0.05 0.10 AIC 6544.02 5877.17 4168.24 5422.28 BIC 6523.04 5971.37 4235.52 5503.02 表 適合度指標および情報量基準 良好な適合度指標値の範囲として小島(2005)は、「CFI≧0.95、RMSEA< 0.05、SRMR<0.05」という基準を提案している。小島(2005)による提案に 基づき表を解釈した結果、適合度が基準を満たし、相対的に予測力が高い修 正版2因子モデルを採択することにした。
135 構造方程式モデリング1 #構造方程式モデリング##### library(lavaan) model2=" ct=~CT1+CT2+CT3+CT4+CT5+CT6+CT7 rika_all~ct " fit2=sem(model =
model2,data = dat1) summary(fit2, standardized=T, fit.measures=T) #SEM図のプロット library(semPlot) semPaths(fit2, "std", rotation = 2, edge.label.cex = 1.2, style="lisrel",fade=F,theme='gray',label.cex=1.2,sizeMan = 9) ⚫ 理科の成績をクリシンで説明(予測)する。 *適合度 CFI=.993, TLI=.990, RMSEA=.026, SRMR=.032 有意 標準化係数 ↑標準化した係数 ↑適合度
136 構造方程式モデリング2 #sem model3=" ct=~CT1+CT2+CT3+CT4+CT5+CT6+CT7 risu=~sansu1+sansu2+sansu3+rika1+rika2+rika3 risu~ct " fit3=sem(model =
model3,data = dat1) summary(fit3, standardized=T, fit.measures=T) lavInspect(fit3, “rsquare”) #決定係数 #SEM図のプロット library(semPlot) semPaths(fit3, "std", rotation = 2, edge.label.cex = 1.2, style="lisrel",fade=F,theme='gray',label.cex=1.2,sizeMan = 9) ⚫ 理数能力をクリシンで説明(予測)する。 *適合度 CFI=.979, TLI=.975, RMSEA=.033, SRMR=.050 理数の説明率=17.9%
137 補足:SEMのサンプルサイズ ✓ 結論:最低でも150、できれば200以上 • N=100~150が目安(Tinsley & Tinsley, 1987; Ding,
Velicer & Harlow, 1995) • N=200が目安(Kline, 2005) • 確認的因子分析では、N=150が合理的(Muthen & Muthen, 2002) • 多母集団分析では、各集団につき100のケースが必要(Kline,2005) • 観測変数の10倍のデータが最低限必要(Nunnally, 1967) • 自由パラメータの10~20倍(Kline, 1998)
138 補足:その他のモデル ⚫ SEMではほかにも様々なモデルが表現できます。 各自でさらに調べてみてください。 • MIMICモデル • 2次因子分析モデル •
PLS (Partial Least Squares) • 多母集団分析
139 演習1 ⚫ data2.xlsxを使用して分析 Q1.各教科の平均得点の変数を作成せよ Q2.学年間で、理科の平均得点に差があるかを検討せよ Q3.男女間で、算数の平均得点に差があるかを検討せよ
140 演習2 Q4.メタ認知尺度の因子構造について検討せよ Q5.仮説モデルを立て、構造方程式モデリングを用いた分析を 実行せよ。 END
補足:例数設計 141
142 検定の基礎 検定の結果 差がある 差があるとはいえ ない 真実 差がある 正しい判断 (1-α)
第2種の過誤 (β) 差がない 第1種の過誤 (α) 正しい判断 (1-β) 危険率(α)=0.05 検定力(1-β)=0.8 が推奨されている →効果量さえ仮定すれば、 必要なサンプルサイズが 見積れる
143 例数設計 #例数設計##### #対応のないt検定の事前分析 power=検定力, delta=効果量, sig.level=危険率 power.t.test(power = 0.8,
delta = 0.2, sig.level = 0.05, type = "two.sample") power.t.test(power = 0.8, delta = 0.5, sig.level = 0.05, type = "two.sample") #対応のあるt検定の事前分析 power.t.test(power = 0.8, delta = 0.2, sig.level = 0.05, type = "paired") power.t.test(power = 0.8, delta = 0.5, sig.level = 0.05, type = "paired") * Cohenの基準 d=0.2 小さな効果 d=0.5 中程度の効果 d=0.8 大きな効果 →394名必要 サンプルサイズが、、、 多すぎると差の大きさに関わらず有意になってしまう 少なすぎると差の大きさに関わらず有意にならない
144 さらなる学習のために *多変量解析全般 川端・岩間・鈴木(2018) 『Rによる多変量解析入門』 オーム社 *構造方程式モデリング 村上ら(2018)『心理学・社会科学研究のための 構造方程式モデリング: Mplusによる実践
基礎編』 ナカニシヤ出版 *例数設計 豊田秀樹(2009)『検定力分析入門』東京図書
項目反応理論 145
146 古典的テスト理論の問題点 ⚫ 仮に難易度が同じ2つのテストがあったとして、あ る受験者が一方のテストを夏に受験して80点、また 他方のテストを秋に受験して90点であったとする。 では、受験者集団の中におけるこの受験者の順位 (偏差値)も上昇しているか? ⚫ テスト得点(例えば90点)が与える情報は、当該のテス
ト問題や受験者集団の性質に依存したものとなる。 ⚫ 全国模試が実施され、ある学校の平均点が、80点で あった昨年度よりも伸びて、今年度は90点であった。 その学校の生徒達の学力が平均的に高くなったと考 えられるか? →×(テストが簡単になっただけかも) →×(他の受験者の方が平均的により高く得点が上 昇しているかも)
147 古典的テスト理論 ⚫ 集団内における位置で個人の成績を判定 ⚫ 各問題の正答率がその問題の困難度 ⚫ 問題Aの正答者が問題Bも正答している(orどちらも不正 解)ような傾向だと、一貫している(識別力が高い)と判 断される。
⚫ 古典的テスト理論の問題点 • 困難度や識別力といった項目に関する指標が、受験者集団 に依存する(標本依存性) • テスト得点といった受験者の能力に関する情報が、テスト の項目に依存する(項目依存性)
148 項目反応理論(IRT) ⚫ 2種類の依存性を克服できる現代テスト理論 • 項目に関する指標と、受験者の能力に関する指標を切り分 けて推定できる。 ⚫ 項目反応理論のメリット •
誰がどの問題を解いたとしても、統一した基準で成績を算 出できる(ただし、等化を行う必要あり) →項目依存性・集団依存性の克服 • 測定精度をきめ細かく確認できる • 平均点をテスト実施前に制御できる • テスト得点の対応表が作成できる • 受験者の能力ごとに最適な問題を瞬時に選び、その場で出 題できる(c.f. コンピュータ適応型テストCAT)
149 項目反応理論の基本 ⚫ 項目反応理論では,受験者集団の性質に依存しない潜在特 性値 (能力値)θ を導入する ⚫ θは直接観測できないが,その分布は正規分布していると 仮定する
⚫ 横軸に特性値θを,縦軸に項目への正答率を配した関数を 項目特性曲線(ICC)と呼び、特性値θと項目の特性(困難 度・識別力)を同時に検討する。
150 項目特性曲線(ICC) • ICC は個々の項目の特徴を表す。項目の数だけある。 • 横軸は受験者の特性値θ、縦軸は当該能力における正答率 となる • 識別力
𝑎 は、各曲線の傾き立 ち上がりの急さを表す • 困 難度 𝑏 は、正答率が0.5 に なる能力値 θ の値を表す
151 ICCに当てはめるモデル
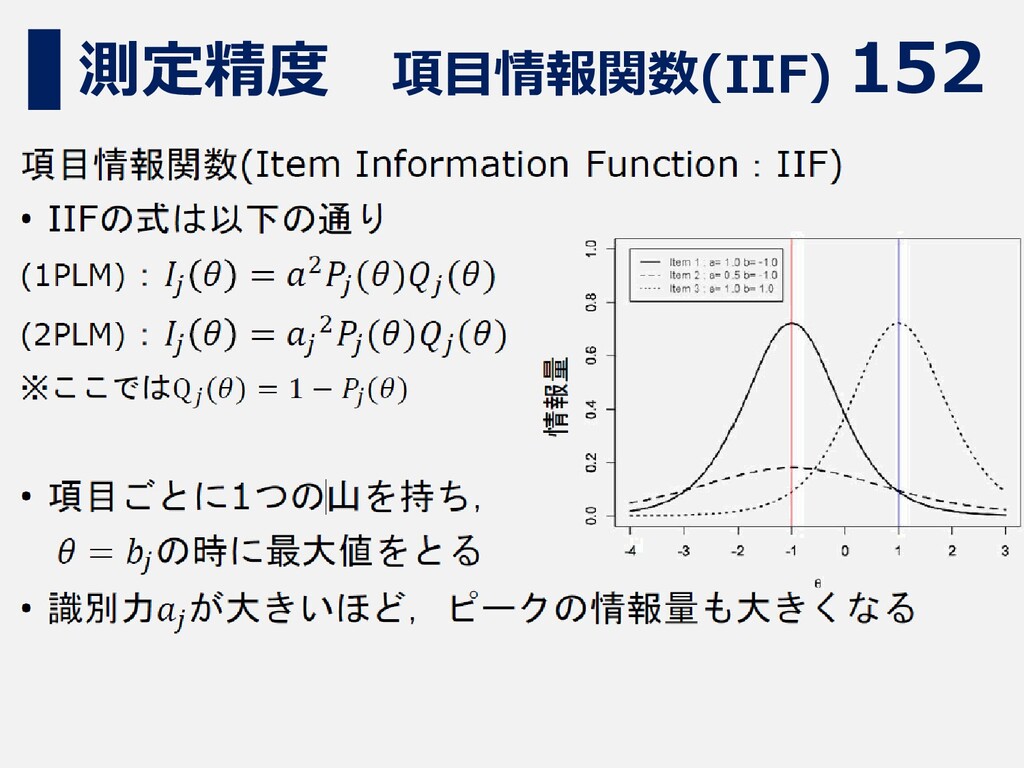
152 測定精度 項目情報関数(IIF)
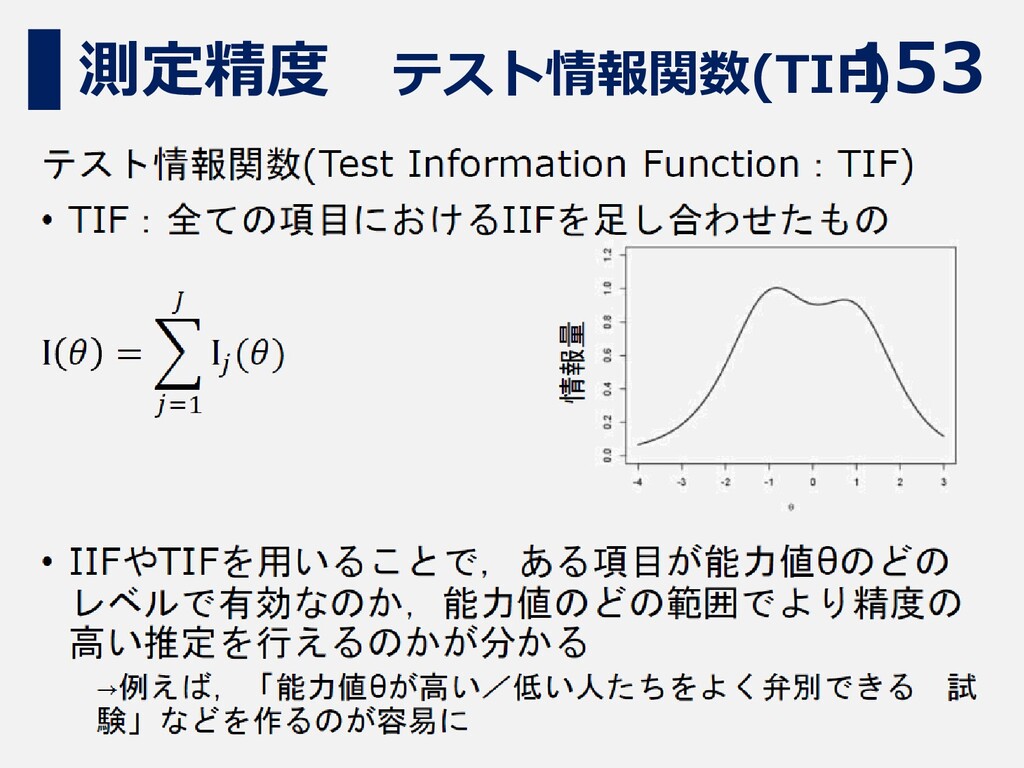
153 測定精度 テスト情報関数(TIF)
154 IRT使用の前提 以下の条件が仮定できる時のみ,IRT は使用可能 1. 尺度の構成概念が 1 次元(1因子)である →因子分析の考え方で確認 2.
局所独立性が保たれている ※局所独立:「能力 θ を固定した時、各項目への反応は互 いに独立である」ということ • 能力と関係なく「ある項目に正解できた人は別の項目に も正解しやすい」という傾向がある場合、局所依存性が あるという • よくある例:数学のテストで,問 1 に正解しているこ とが問2を解く上で必要である(項目連鎖)
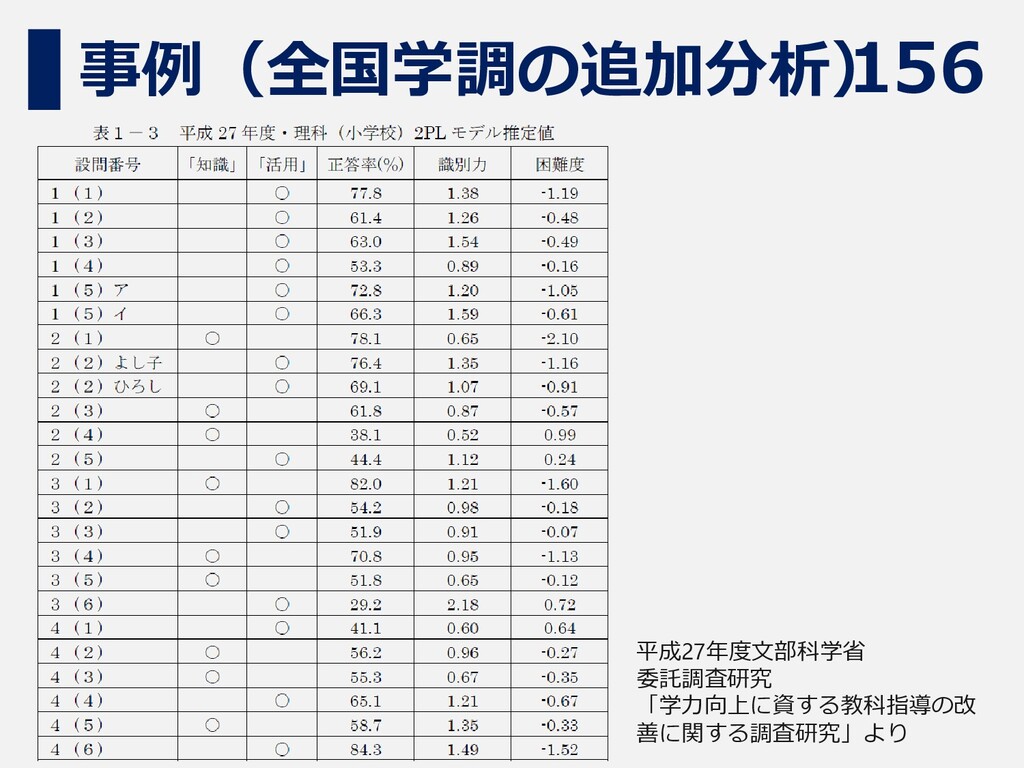
155 事例(全国学調の追加分析) 平成27年度文科省 委託調査研究 「学力向上に資する教 科指導の改善に関する 調査研究」より
156 事例(全国学調の追加分析) 平成27年度文部科学省 委託調査研究 「学力向上に資する教科指導の改 善に関する調査研究」より
157 2PLに基づく分析1 #項目反応理論(IRT)に基づく分析##### #パッケージの読み込み library(ltm) library(irtoys) library(psych) ##データの読み込み #ワーキングディレクトリの確認 getwd()
#csvから読み込み方法 setwd("C:/Users/2ken/Desktop/practice2019") dat2=read.csv("IRT1.csv") head(dat2) ⚫ IRT用の分析対象データを読み込む 誤答0 正答1
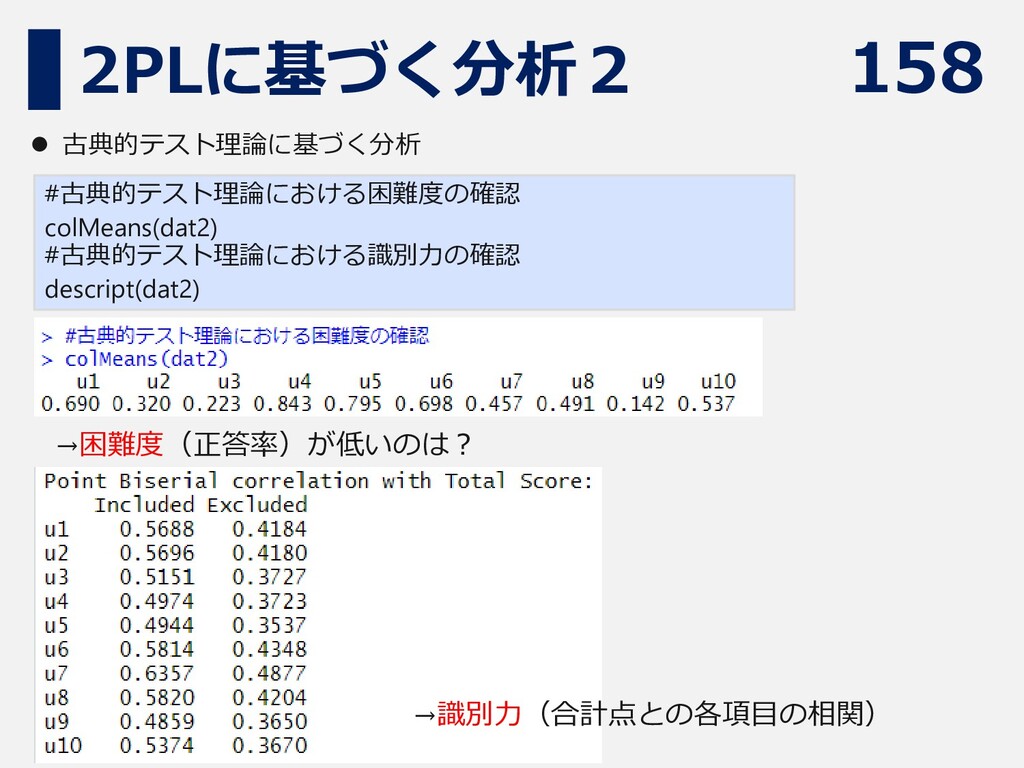
158 2PLに基づく分析2 #古典的テスト理論における困難度の確認 colMeans(dat2) #古典的テスト理論における識別力の確認 descript(dat2) ⚫ 古典的テスト理論に基づく分析 →困難度(正答率)が低いのは? →識別力(合計点との各項目の相関)
159 2PLに基づく分析3 #2PLモデル ip1=est(resp = dat2,model = "2PL",engine = "ltm")
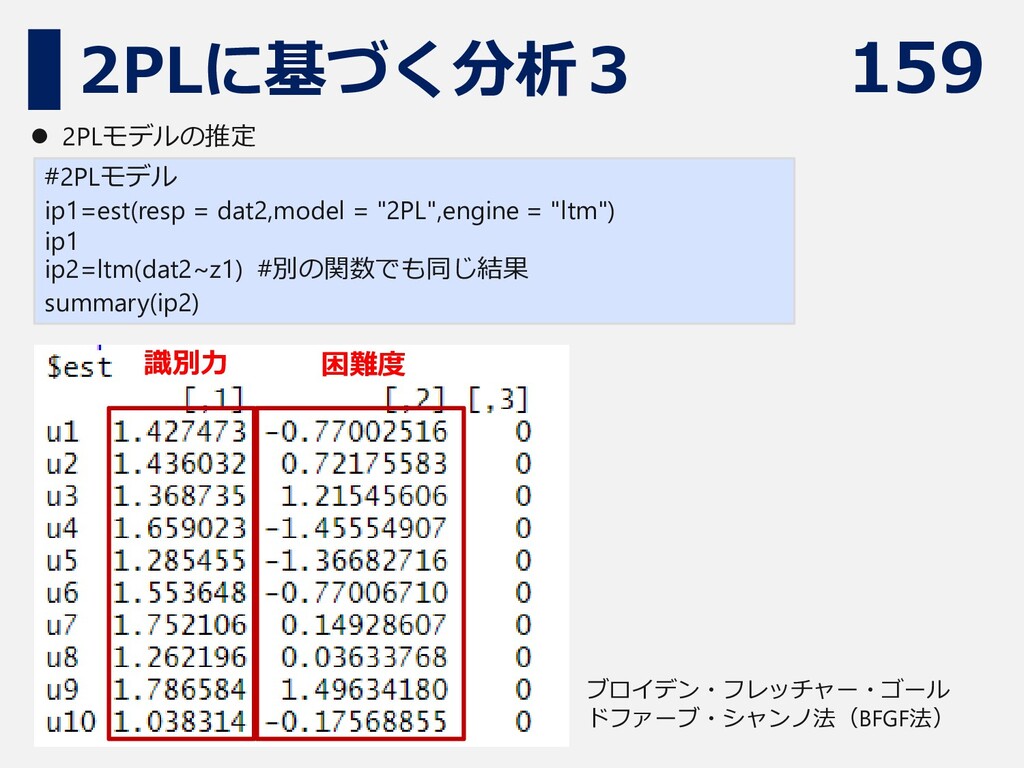
ip1 ip2=ltm(dat2~z1) #別の関数でも同じ結果 summary(ip2) ⚫ 2PLモデルの推定 困難度 識別力 ブロイデン・フレッチャー・ゴール ドファーブ・シャンノ法(BFGF法)
160 2PLに基づく分析4 #項目特性曲線 ICCの表示 icc=irf(ip1$est) plot(icc,label = T,co=NA,main = "ICC")
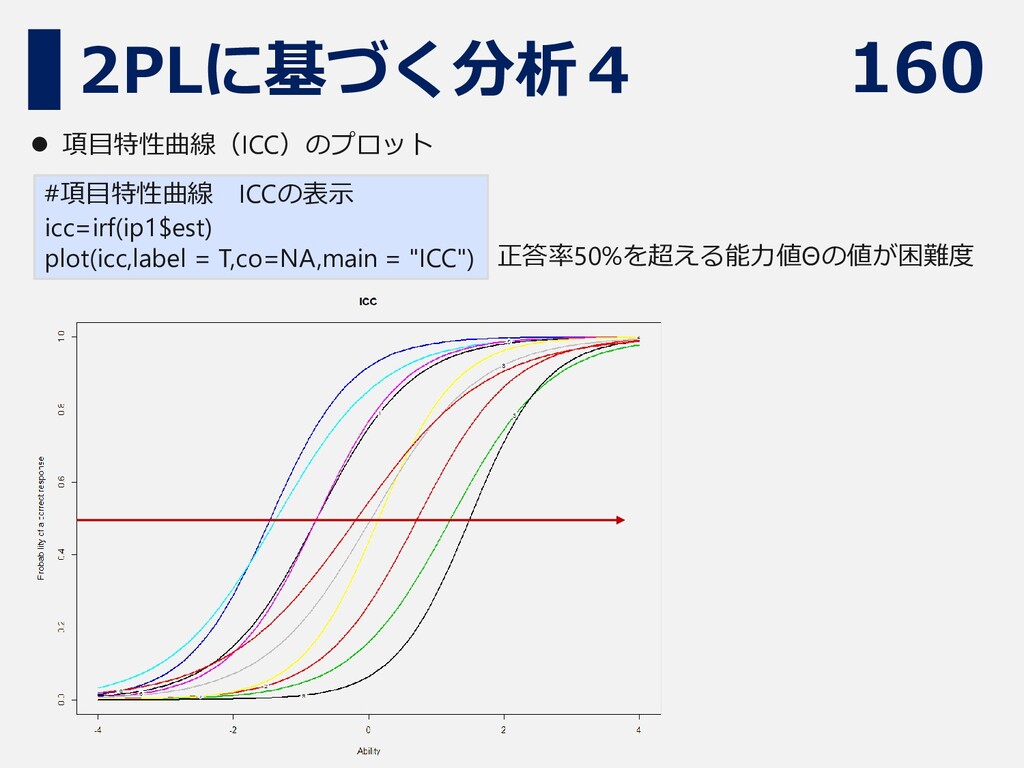
⚫ 項目特性曲線(ICC)のプロット 正答率50%を超える能力値Θの値が困難度
161 2PLに基づく分析5 #テスト特性曲線 TCC tcc=trf(ip$est) plot(tcc,main = "TCC") ⚫ テスト特性曲線(のプロット)
各能力におけるテスト得点の期待値 平均位の能力の受験者の期待得点は5点
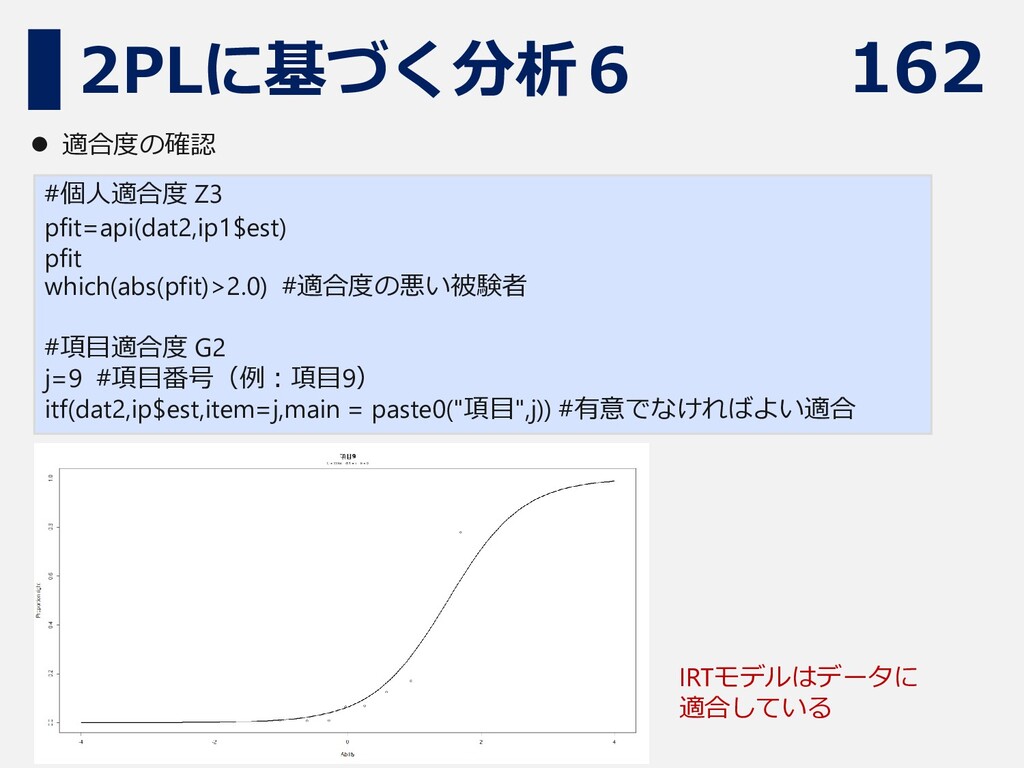
162 2PLに基づく分析6 #個人適合度 Z3 pfit=api(dat2,ip1$est) pfit which(abs(pfit)>2.0) #適合度の悪い被験者 #項目適合度 G2
j=9 #項目番号(例:項目9) itf(dat2,ip$est,item=j,main = paste0("項目",j)) #有意でなければよい適合 ⚫ 適合度の確認 IRTモデルはデータに 適合している
163 2PLに基づく分析7 #項目情報関数 IIF iif=iif(ip1$est) plot(iif, label=T, co=NA, main =
"IIF") #テスト情報関数 TIF tif=tif(ip1$est) plot(tif, laber=T, co=NA, main = "TIF") ⚫ IIFとTIFのプロット θが高い/低い人に適した問題がある 幅広い能力値θに適応した テストになっている
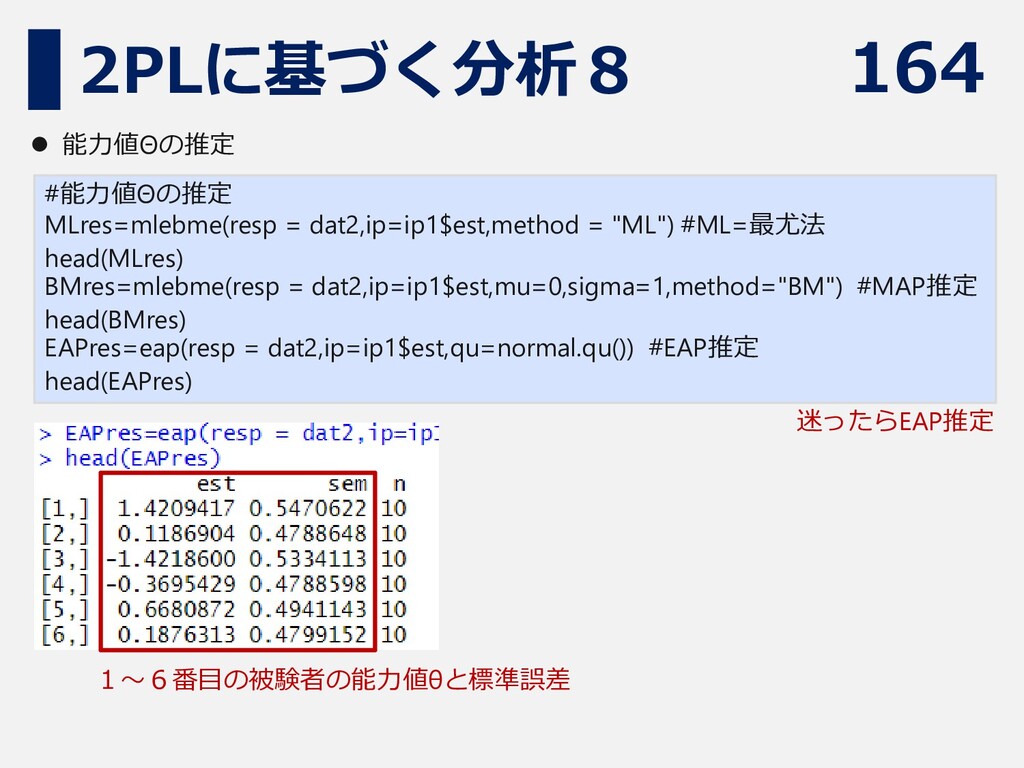
164 2PLに基づく分析8 #能力値Θの推定 MLres=mlebme(resp = dat2,ip=ip1$est,method = "ML") #ML=最尤法 head(MLres)
BMres=mlebme(resp = dat2,ip=ip1$est,mu=0,sigma=1,method="BM") #MAP推定 head(BMres) EAPres=eap(resp = dat2,ip=ip1$est,qu=normal.qu()) #EAP推定 head(EAPres) ⚫ 能力値Θの推定 迷ったらEAP推定 1~6番目の被験者の能力値θと標準誤差
ベイズ統計学に基づく分析 165
166 統計的仮説検定の限界 ⚫ 手続きの煩雑さ • 帰無仮説を立てて棄却するという背理法の考え方 ⚫ P値という概念の難しさ • 帰無仮説が正しいと仮定した場合の、今回より極端な
データが得られる確率→なんじゃそりゃ ⚫ P値ハッキングに起因する、再現性問題 • 心理学の研究の再現率が低い問題 • 有意になるまでサンプルを追加している? ⚫ 複雑なモデルへの対応が困難
167 ベイズの定理 事後分布 = 尤度 × 事前分布 定数 事前分布:パラメーターに関する事前知識(仮説) 事前知識がない場合は、広い値を仮定しておく
事後分布:データを得た後の、パラメーターについての推論 (事前分布とデータから推定した結果) 尤度(確率モデル):データの生成メカニズム (正規分布が使われることが多い) ⚫ 右辺の式に得られたデータを当てはめて、パラメーターを推定 する。
168 ベイズ推定 ⚫ 前ページの式は、積分計算が複雑で、解析的にはとけない →シミュレーションを用いる ⚫ マルコフ連鎖モンテカルロ法(MCMC)を使って、事後分 布を反映した乱数を大量に発生させる →その乱数分布を事後分布とする ⚫
MCMCを実行するには、いくつか追加する必要があり 1.Rtools(インストールの際にオプションにチェックを入れる) 2.rstanパッケージ
169 母平均の差の検討1 ##母平均の差の推定1(t検定に相当) #変数作成 x=dat1$rika_all[dat1$grade=="5"] #第1群の指定 y=dat1$rika_all[dat1$grade=="6"] #第2群の指定 nx =
length(x) #xのサンプルサイズ ny = length(y) #yのサンプルサイズ J=1-(3 /(4*((nx+ny-2)-1))) #効果量gを算出するための補正項 data=list(N1=nx, N2=ny, x1=x, x2=y, c=0, J=J) #リスト形式. c=0→差が0以上の確率 #対応のないt検定(頻度論の検定) t.test(y, x, var.equal=F) #F=Welchのt検定 ⚫ 5年よりも6年の理科の成績の方が高いという仮説が正しい確率は? この後で使うstanは、リスト形式でデータを渡す必要がある。 これからやることは、対応のないt検定のベイズ版。
170 母平均の差の検討2 pairedF <- ' data{ int<lower=0> N1; int<lower=0> N2;
real x1[N1]; real x2[N2]; real c; real J; } parameters{ real mu1; real mu2; real<lower=0> sigma1; real<lower=0> sigma2; } model{ x1 ~ normal(mu1,sigma1); x2 ~ normal(mu2,sigma2); } generated quantities{ real delta; real d_overC; real cohen_d; real hedges_g; delta = mu2 - mu1; d_overC = (delta>c? 1:0); cohen_d = delta /((sigma1^2*(N1-1)+sigma2^2*(N2-1)) /((N1-1)+(N2-1)))^0.5; hedges_g = cohen_d*J; } ' ⚫ 5年よりも6年の理科の成績の方が高いという仮説が正しい確率は? どんなデータを扱うか 何のパラメータの確率分布を推定するか どんな生成メカニズムか(尤度) normal=正規分布 その他、計算して欲しい値
171 母平均の差の検討3 #ベイズ推定 require(rstan) rstan_options(auto_write = TRUE) #コンパイルした結果を保存する options(mc.cores =
parallel::detectCores()) #複数のCPUコアを並列で使う fit<-stan(model_code=pairedF,data=data,chains=5,warmup=1000,iter=21000) #(21000-1000)*5の乱数を発生させる print(fit,digits_summary=3) #小数点以下3位までで表示 ⚫ 5年よりも6年の理科の成績の方が高いという仮説が正しい確率は? 1.2以下だったら 適切に収束 95%確信区間 (95%の確率でこの範囲に入る) 点推定値 (EAP推定値) ※結果は毎回少し変わる可能性あり
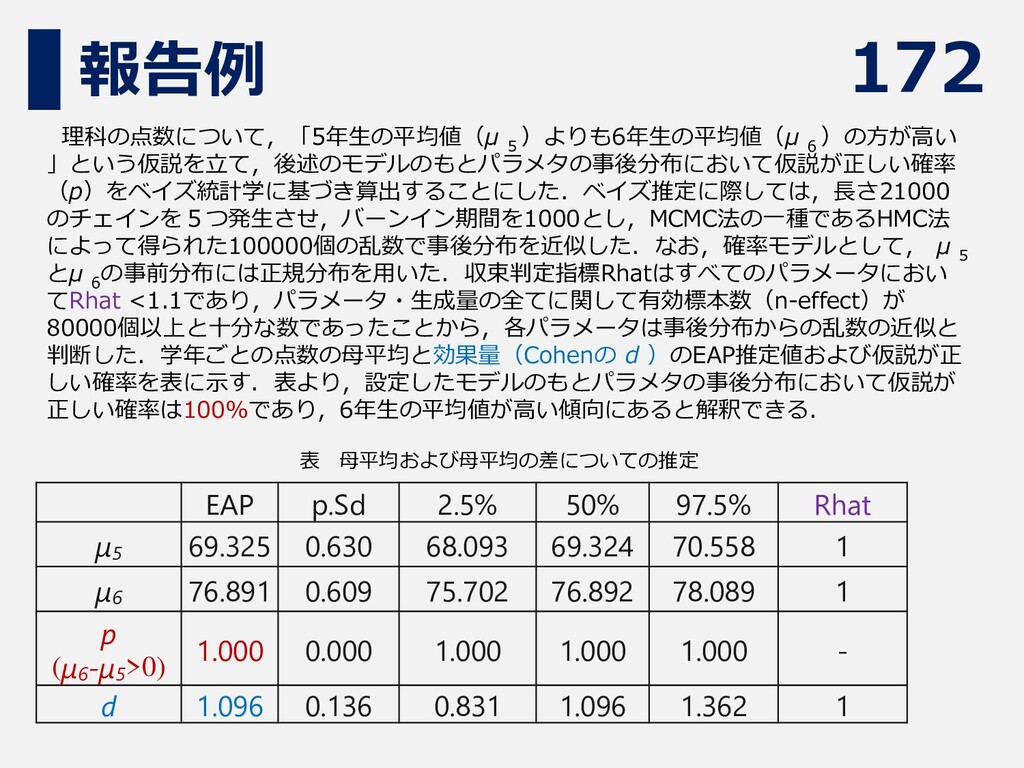
172 報告例 理科の点数について,「5年生の平均値(μ 5 )よりも6年生の平均値(μ 6 )の方が高い 」という仮説を立て,後述のモデルのもとパラメタの事後分布において仮説が正しい確率 (p)をベイズ統計学に基づき算出することにした.ベイズ推定に際しては,長さ21000 のチェインを5つ発生させ,バーンイン期間を1000とし,MCMC法の一種であるHMC法
によって得られた100000個の乱数で事後分布を近似した.なお,確率モデルとして, μ 5 とμ 6 の事前分布には正規分布を用いた.収束判定指標Rhatはすべてのパラメータにおい てRhat <1.1であり,パラメータ・生成量の全てに関して有効標本数(n-effect)が 80000個以上と十分な数であったことから,各パラメータは事後分布からの乱数の近似と 判断した.学年ごとの点数の母平均と効果量(Cohenの d )のEAP推定値および仮説が正 しい確率を表に示す.表より,設定したモデルのもとパラメタの事後分布において仮説が 正しい確率は100%であり,6年生の平均値が高い傾向にあると解釈できる. 表 母平均および母平均の差についての推定 EAP p.Sd 2.5% 50% 97.5% Rhat μ5 69.325 0.630 68.093 69.324 70.558 1 μ6 76.891 0.609 75.702 76.892 78.089 1 p (μ6 -μ5 >0) 1.000 0.000 1.000 1.000 1.000 - d 1.096 0.136 0.831 1.096 1.362 1
173 母平均の差の検討4 x=dat_seiseki #データ n <- nrow(x) #サンプルサイズ data <-list(N
= n, X = x) #リスト形式 ⚫ 理科の点数が国語や算数の点数よりも高いという仮説が正しい確率は? この後で使うstanは、リスト形式でデータを渡す必要がある。 これからやることは、対応のある1元配置分散分析のベイズ版。
174 母平均の差の検討5 anovaP3 <- " data{ int<lower=0> N; vector[3] X[N];
} parameters{ vector[3] mu; real<lower=0> sig[3]; real<lower=-1,upper=1> rho; } transformed parameters{ matrix[3,3] Sigma; Sigma[1,1] = sig[1]*sig[1]; Sigma[2,2] = sig[2]*sig[2]; Sigma[3,3] = sig[3]*sig[3]; Sigma[1,2] = sig[1]*sig[2]*rho; Sigma[1,3] = sig[1]*sig[3]*rho; Sigma[2,3] = sig[2]*sig[3]*rho; Sigma[2,1] = Sigma[1,2]; Sigma[3,1] = Sigma[1,3]; Sigma[3,2] = Sigma[2,3]; } ⚫ 理科の点数が国語や算数の点数よりも高いという仮説が正しい確率は? どんなデータを扱うか 何のパラメータの 確率分布を 推定するか その他の パラメータ 生成メカニズム multi normal =多変量正規分布 uniform=一様分布 cauchy=コーシー分布 その他、 計算して欲しい値 model{ X ~ multi_normal(mu, Sigma); rho ~ uniform(-1,1); sig ~ cauchy(0,2.5); } generated quantities{ real delta21; real delta31; real delta32; real d_overC1; real d_overC2; real d_overC3; delta21 = mu[2] - mu[1]; delta31 = mu[3] - mu[1]; delta32 = mu[3] - mu[2]; d_overC1 = (delta21>0? 1:0); d_overC2 = (delta31>0? 1:0); d_overC3 = (delta32>0? 1:0); } "
175 母平均の差の検討6 require(rstan) rstan_options(auto_write = TRUE) options(mc.cores = parallel::detectCores()) fit
<- stan(model_code = anovaP3, iter=21000, warmup=1000, chains=5, data = data) print(fit, digits_summary = 2) ⚫ 理科の点数が国語や算数の点数よりも高いという仮説が正しい確率は? c1=mu[2] - mu[1]>0の確率 c2=mu[3] - mu[1]>0の確率 c3=mu[3] - mu[2]>0の確率 ※結果は毎回少し変わる可能性あり ※推定に時間かかる mu[1]=国語 mu[2]=算数 mu[3]=理科
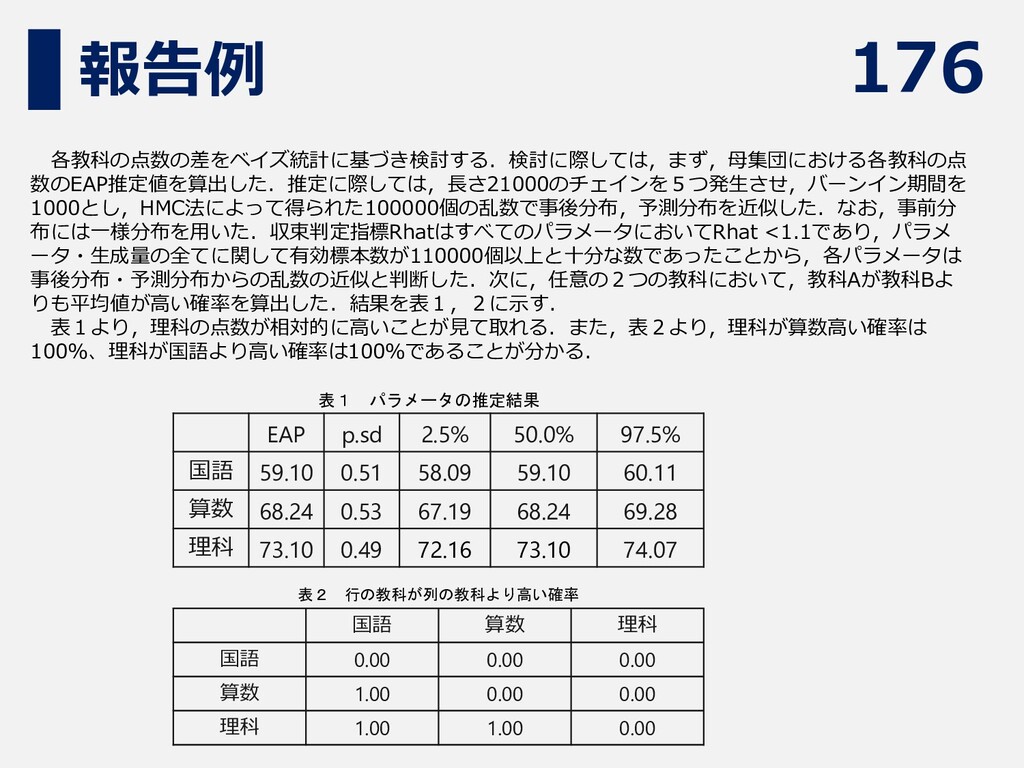
176 報告例 各教科の点数の差をベイズ統計に基づき検討する.検討に際しては,まず,母集団における各教科の点 数のEAP推定値を算出した.推定に際しては,長さ21000のチェインを5つ発生させ,バーンイン期間を 1000とし,HMC法によって得られた100000個の乱数で事後分布,予測分布を近似した.なお,事前分 布には一様分布を用いた.収束判定指標RhatはすべてのパラメータにおいてRhat <1.1であり,パラメ ータ・生成量の全てに関して有効標本数が110000個以上と十分な数であったことから,各パラメータは 事後分布・予測分布からの乱数の近似と判断した.次に,任意の2つの教科において,教科Aが教科Bよ りも平均値が高い確率を算出した.結果を表1,2に示す.
表1より,理科の点数が相対的に高いことが見て取れる.また,表2より,理科が算数高い確率は 100%、理科が国語より高い確率は100%であることが分かる. 表1 パラメータの推定結果 表2 行の教科が列の教科より高い確率 EAP p.sd 2.5% 50.0% 97.5% 国語 59.10 0.51 58.09 59.10 60.11 算数 68.24 0.53 67.19 68.24 69.28 理科 73.10 0.49 72.16 73.10 74.07 国語 算数 理科 国語 0.00 0.00 0.00 算数 1.00 0.00 0.00 理科 1.00 1.00 0.00
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![27 新しい変数の作成 #新しい変数の作成 dat1$kokugo_all=apply(dat1[,7:9],1,mean) dat1$sansu_all=apply(dat1[,10:12],1,mean) dat1$rika_all=apply(dat1[,13:15],1,mean) ←国語平均の作成。 ←算数平均の作成。 ←理科平均の作成。 ※0なら列,](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![31 視覚化3 #散布図 plot(dat1$sansu_all, dat1$rika_all) plot(dat1$sansu_all, dat1$rika_all,pch=21,bg=c("blue","red")[unclass(dat1$sex)]) plot(dat1$sansu_all, dat1$rika_all,pch=as.numeric(dat1$sex), cex=1.5)](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_31.jpg){kind=link}
![32 ハイレベルな視覚化 #ペアプロット library(GGally) dat_ksr=dat1[,c("school","grade","sex","kokugo_all","sansu_all","rika_all")] dat_ksr=subset(dat1,select=c("school", "grade", "sex", "kokugo_all", "sansu_all",](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![75 復習 1. 標本分布の標準偏差を何と呼ぶでしょうか 2. 95%信頼区間について説明せよ 3. [正誤判定問題] ①有意水準αを5%に設定するということは、実際には帰無仮説が正 しい(差がない)のに、誤って帰無仮説を棄却する確率を5%以下に](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![108 探索的因子分析1 #探索的因子分析##### #データの取り出し dat_CT=dat1[,c(16:22)] #16~22列目の取り出し ⚫ 批判的思考:何を信じ、何を行うかの決定に焦点を当てた、合理的で 省察的な思考(Ennis, 1987)。](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_108.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![113 尺度得点との相関 #相関の検討 dat1$CT=rowMeans(dat1[,c(16:22)]) #指定行の平均値を変数として作成 cor(dat1$rika_all,dat1$CT) #理科とクリシンの相関 cor(dat1$sansu_all,dat1$CT) #算数とクリシンの相関 cor(dat1$kokugo_all,dat1$CT)](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_113.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![133 報告例1(確認的因子分析) ◼ 先行研究の知見に基づき、批判的思考に1因子構造を想定 した確認的因子分析を行った。分析の結果、適合度指標 は、CFI=1.00, TLI=1.00, RMSEA=.00(90%CI [.00, .06]),](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_133.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![169 母平均の差の検討1 ##母平均の差の推定1(t検定に相当) #変数作成 x=dat1$rika_all[dat1$grade=="5"] #第1群の指定 y=dat1$rika_all[dat1$grade=="6"] #第2群の指定 nx =](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_169.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![174 母平均の差の検討5 anovaP3 <- " data{ int<lower=0> N; vector[3] X[N];](https://files.speakerdeck.com/presentations/02699440e9504bba89818b93437bc604/slide_174.jpg){kind=link}
{kind=link}
{kind=link}