Watch the presentation at: http://www.infoq.com/presentations/Data-Structures
Most programmers rely on a few core data structures, but they’re missing out on useful properties that more specialized data structures provide.
The wrong data structures can bog implementation down in irrelevant detail or create behaviors which waste time and effort, but the right ones can give powerful guarantees for free. My talk will present lesser-known data structures and their unique advantages:
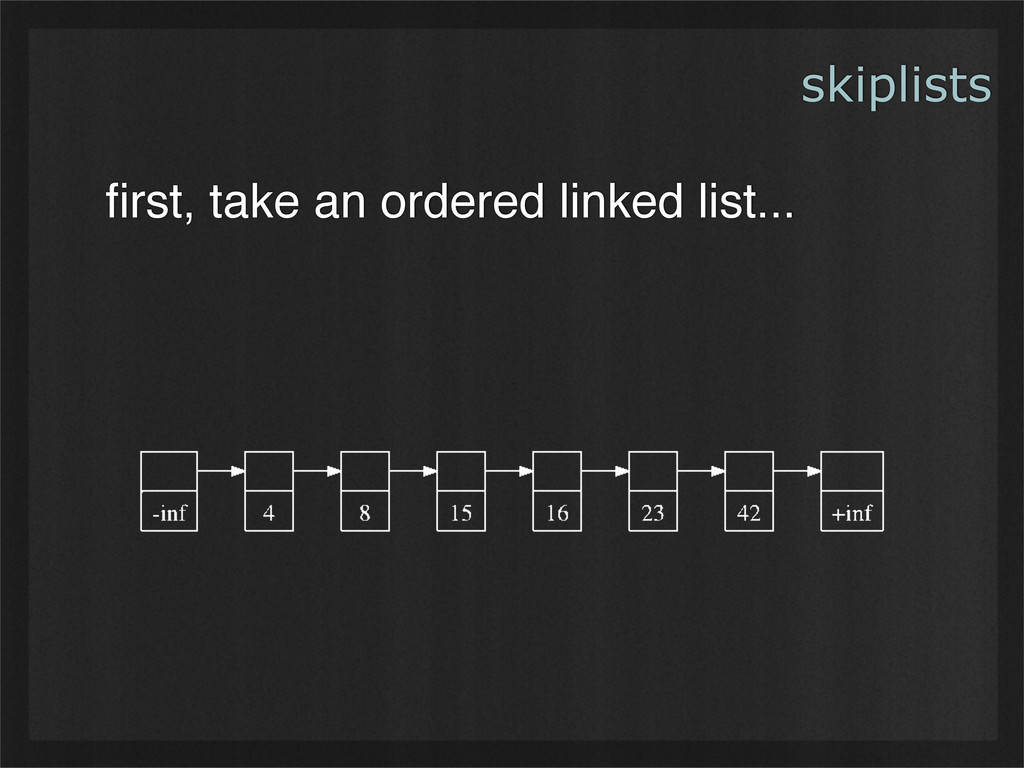
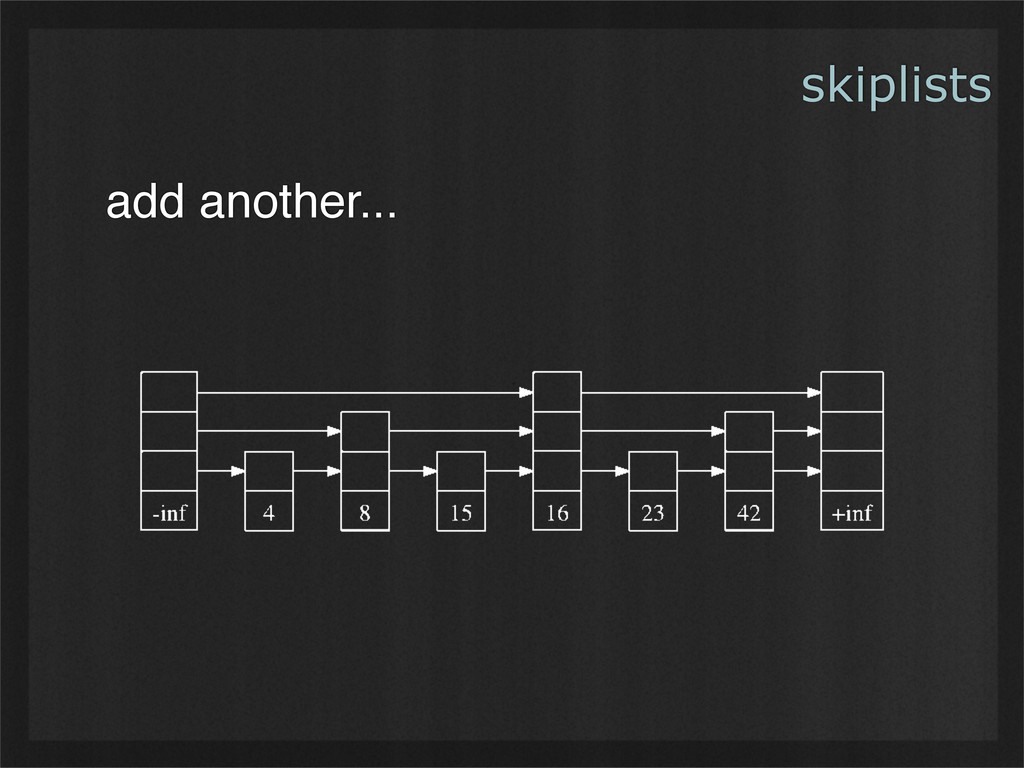
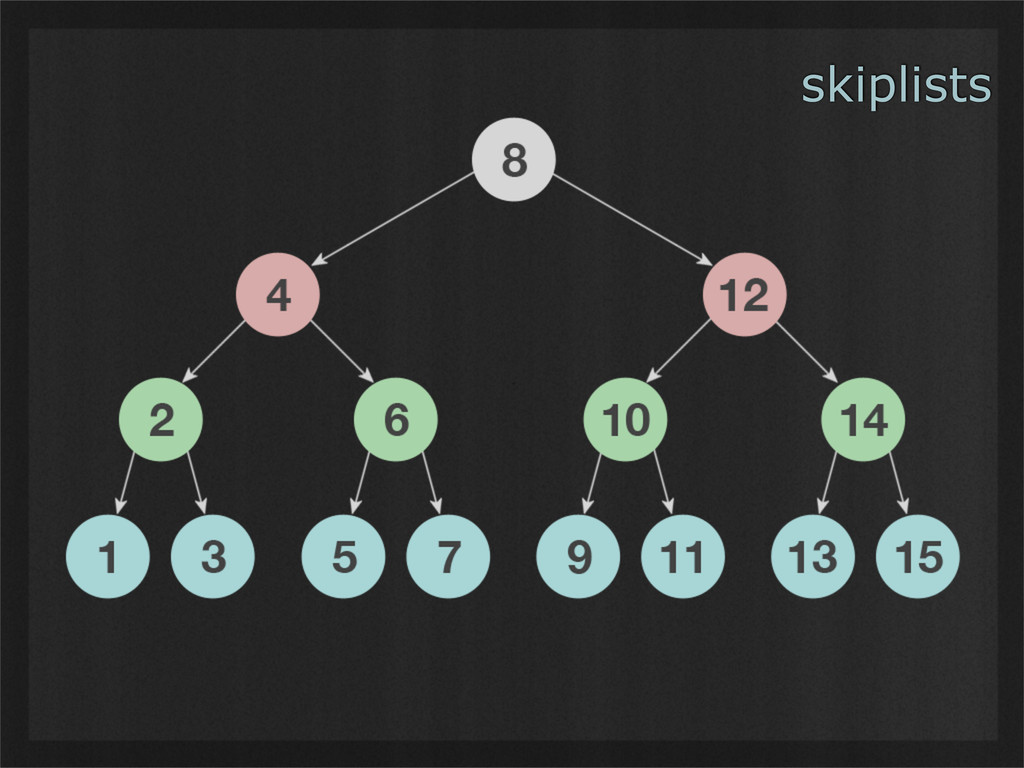
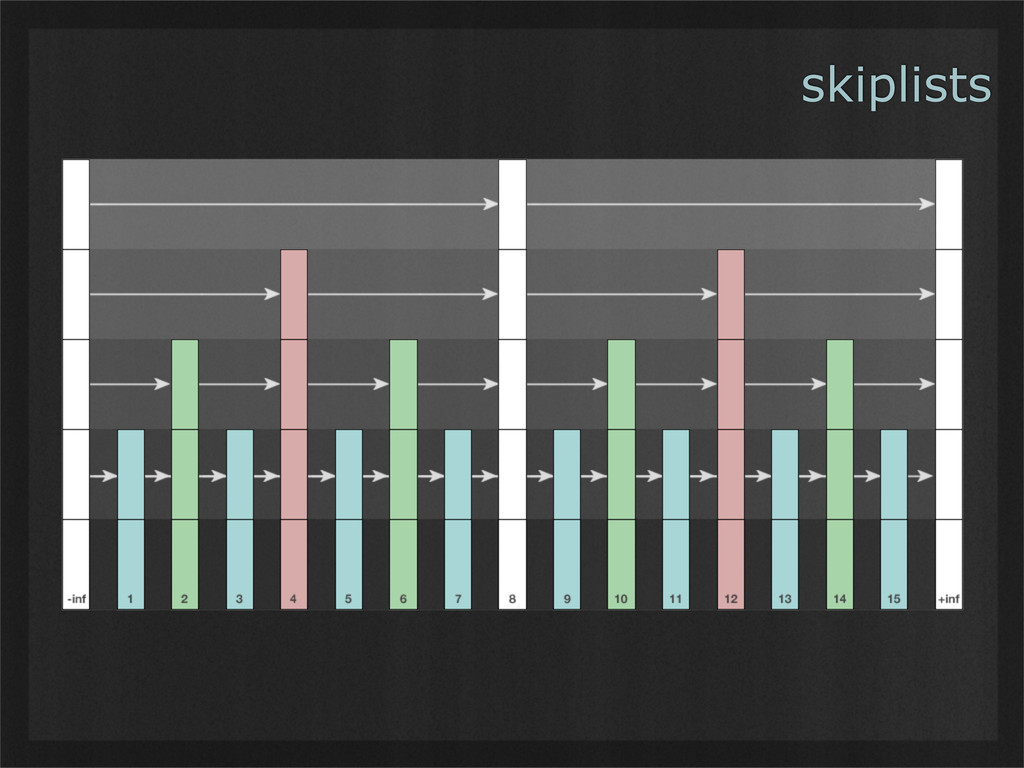
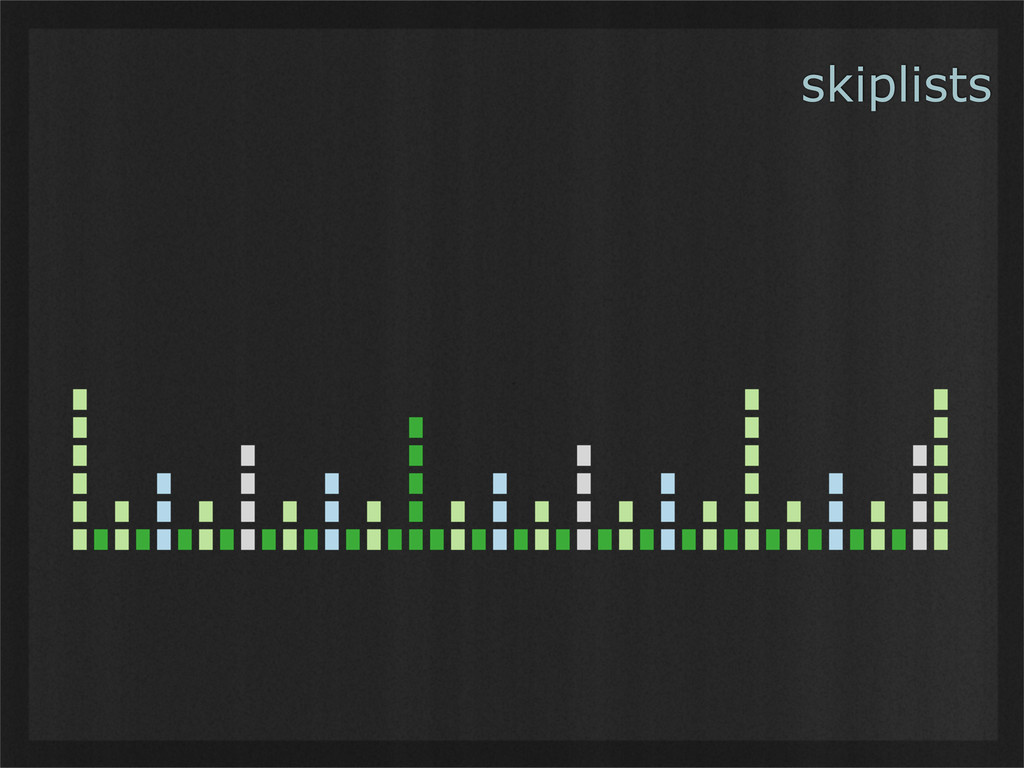
- Skiplists are simple data structures whose design leads to balanced binary tree-like performance, without any need for non-localized operations such as rebalancing. (Example use case: Demonstrating how simple invariants can lead to powerful emergent properties.)
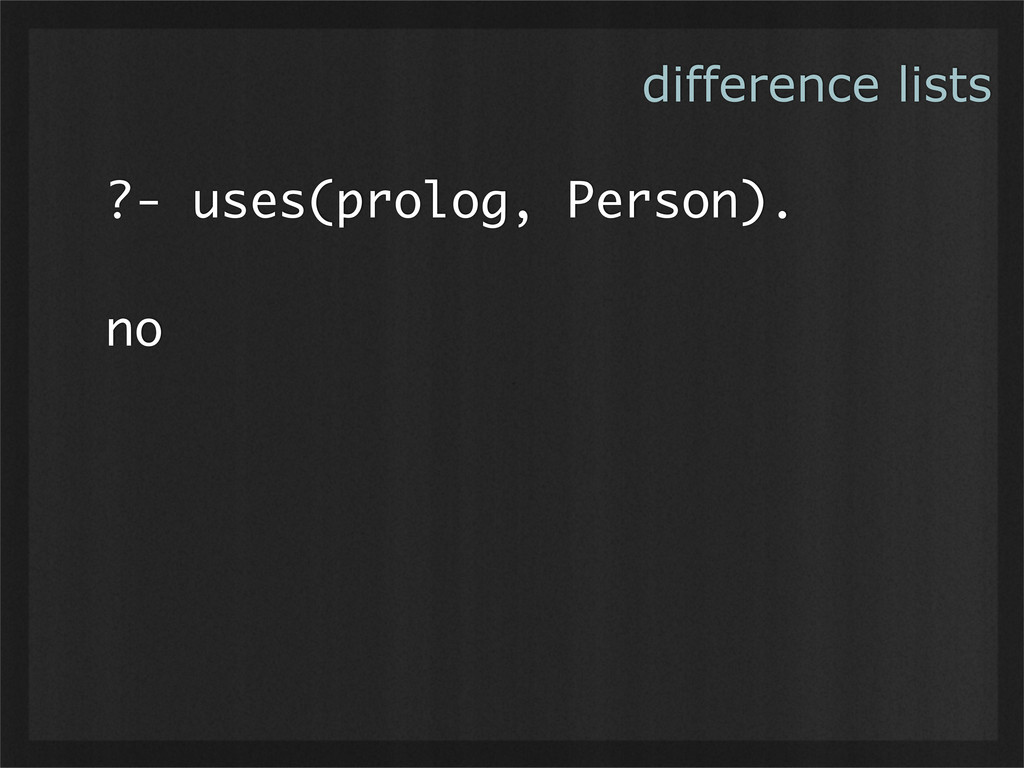
- Difference lists provide a way to explicitly model temporary uncertainty. They are immutable, yet can still be refined as more information becomes available. They have much in common with lazy evaluation, but for data rather than control flow. (Example use case: Adding more flexibility to immutable languages by relaxing the flow of time.)
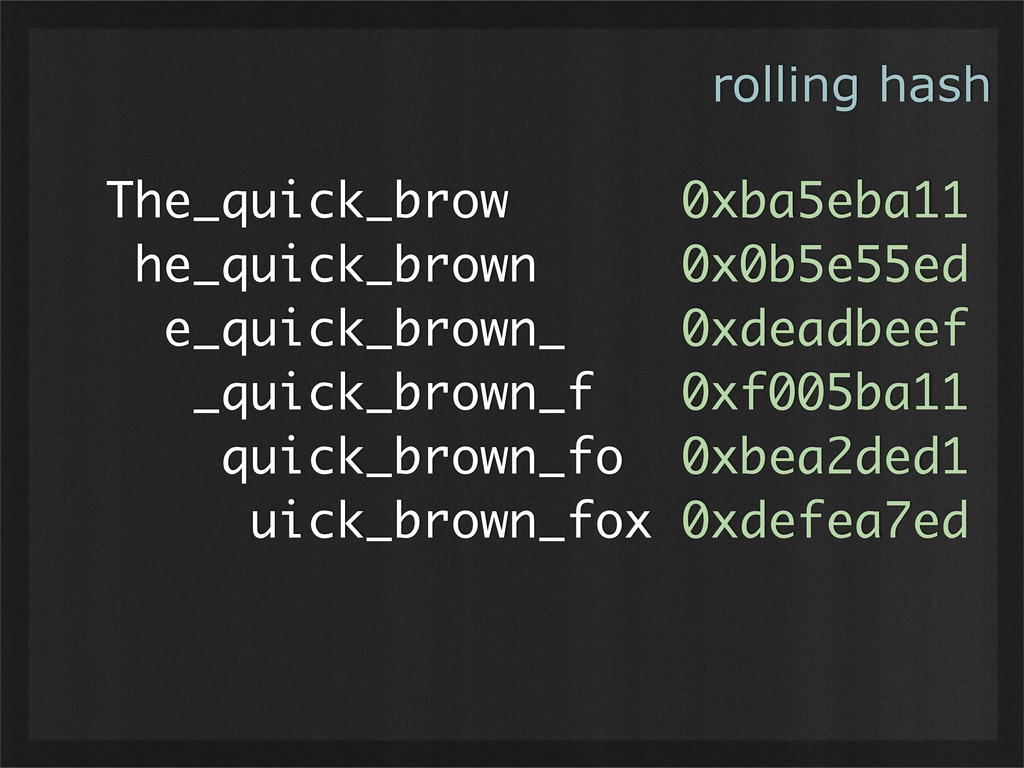
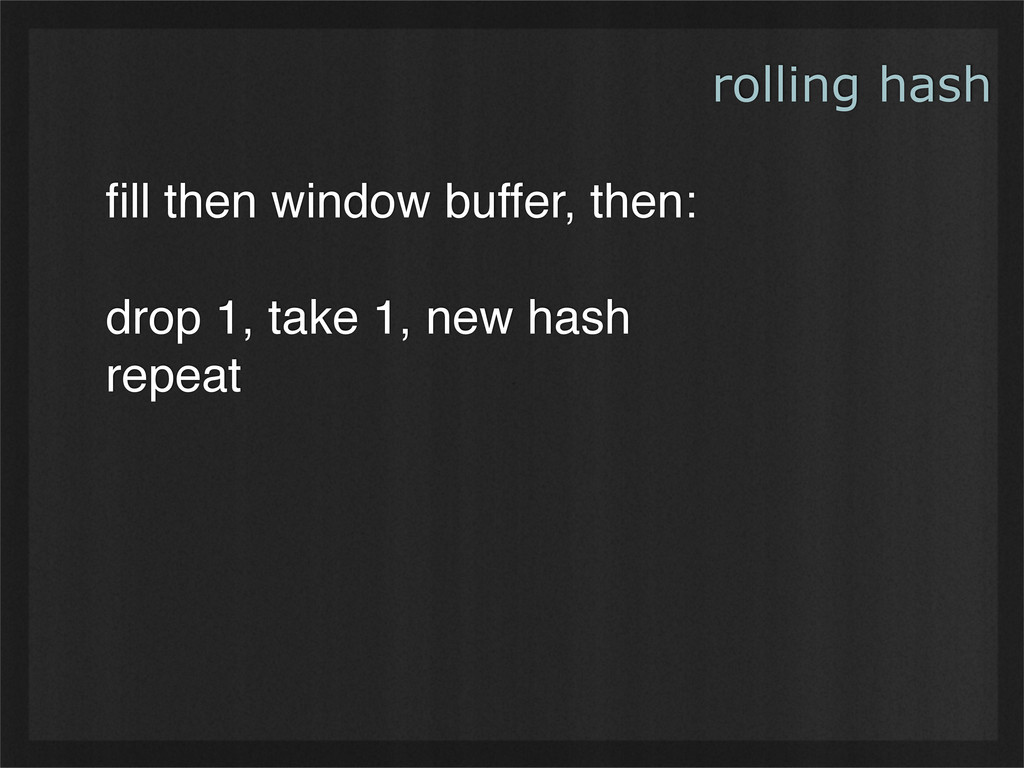
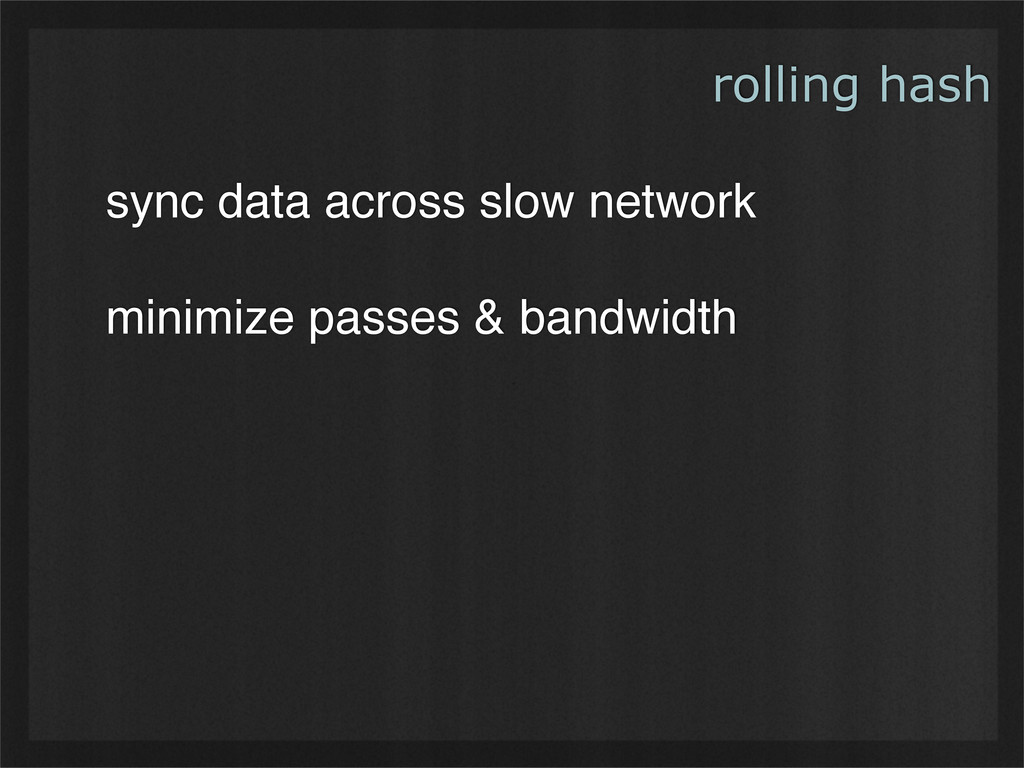
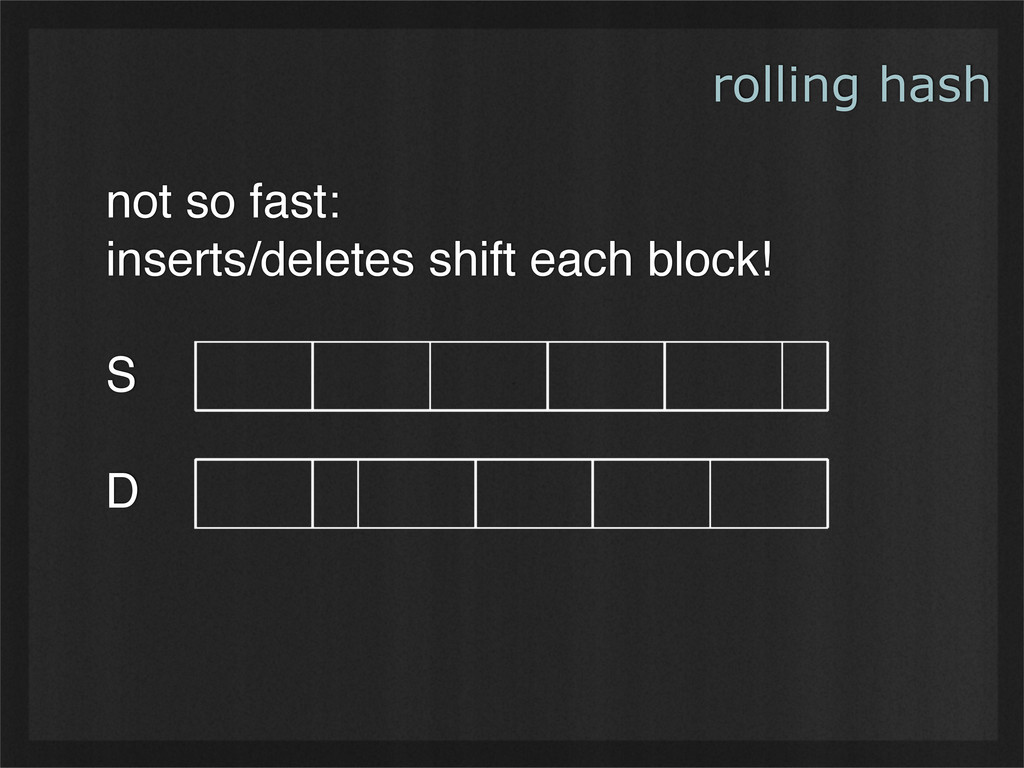
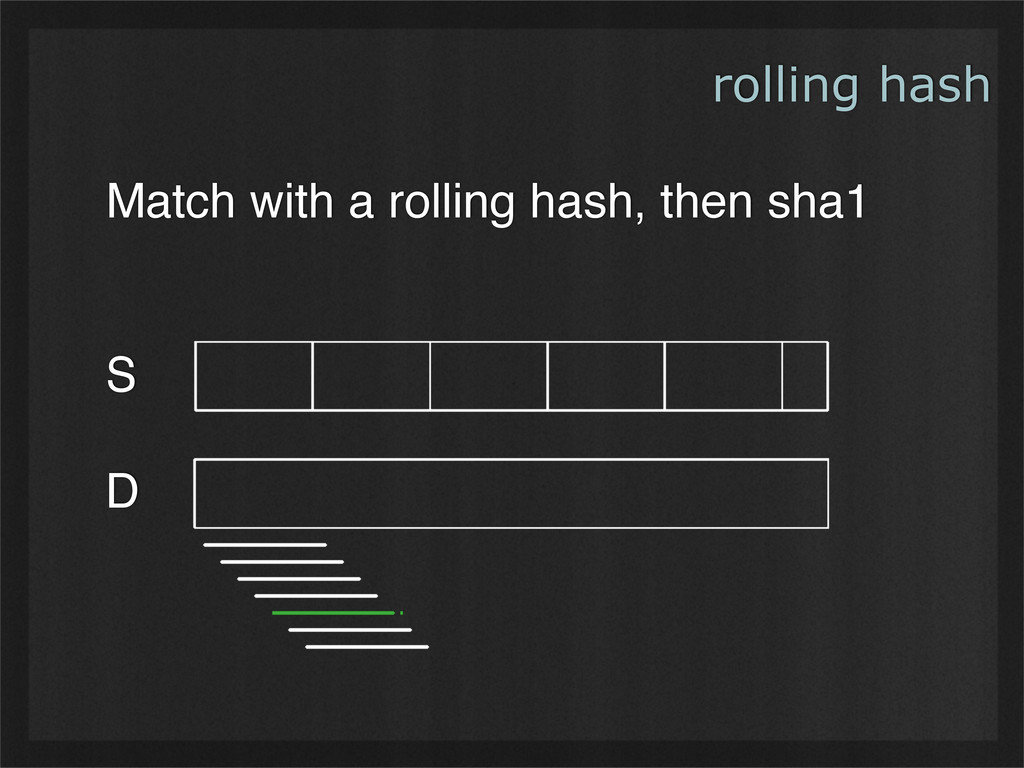
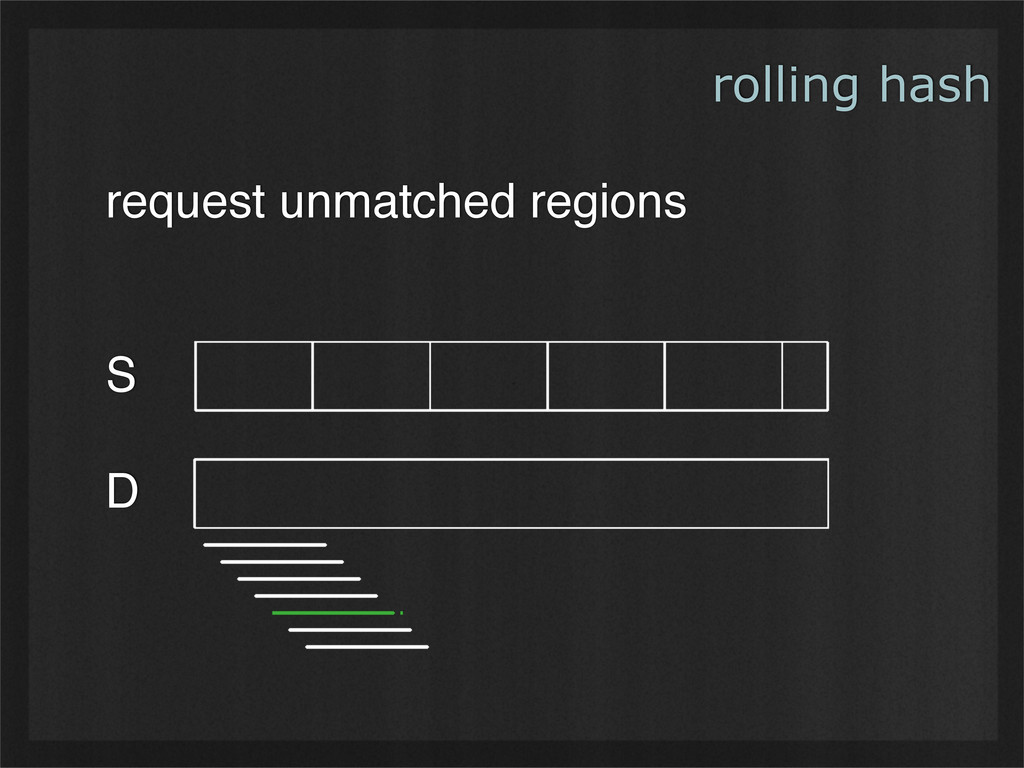
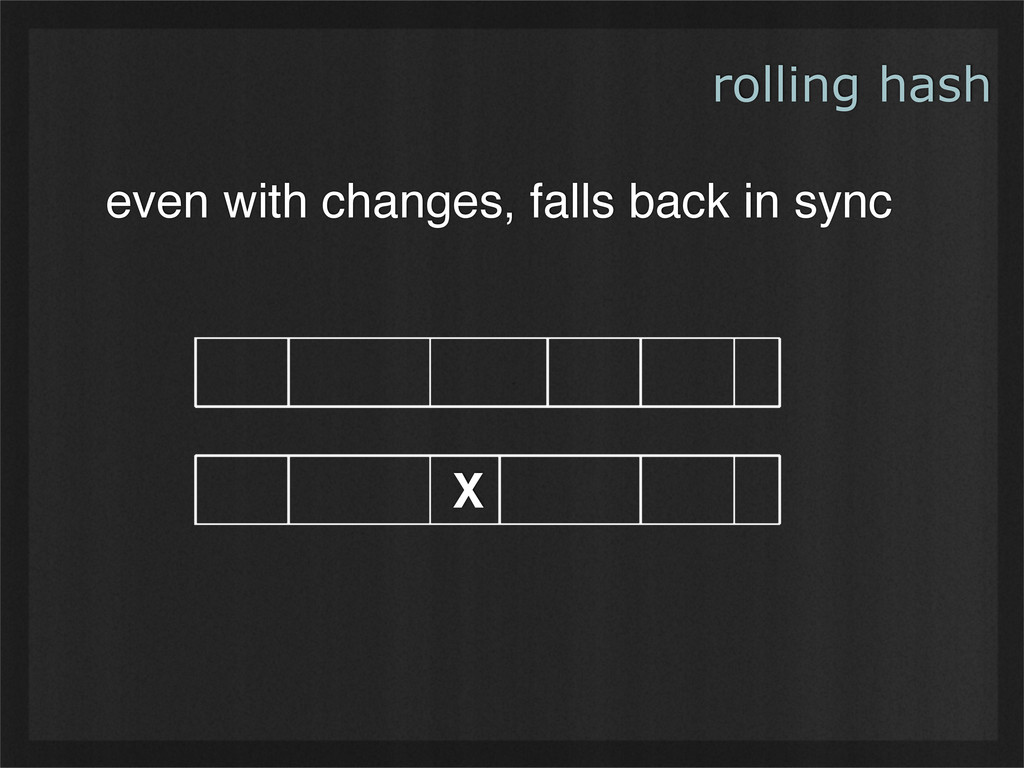
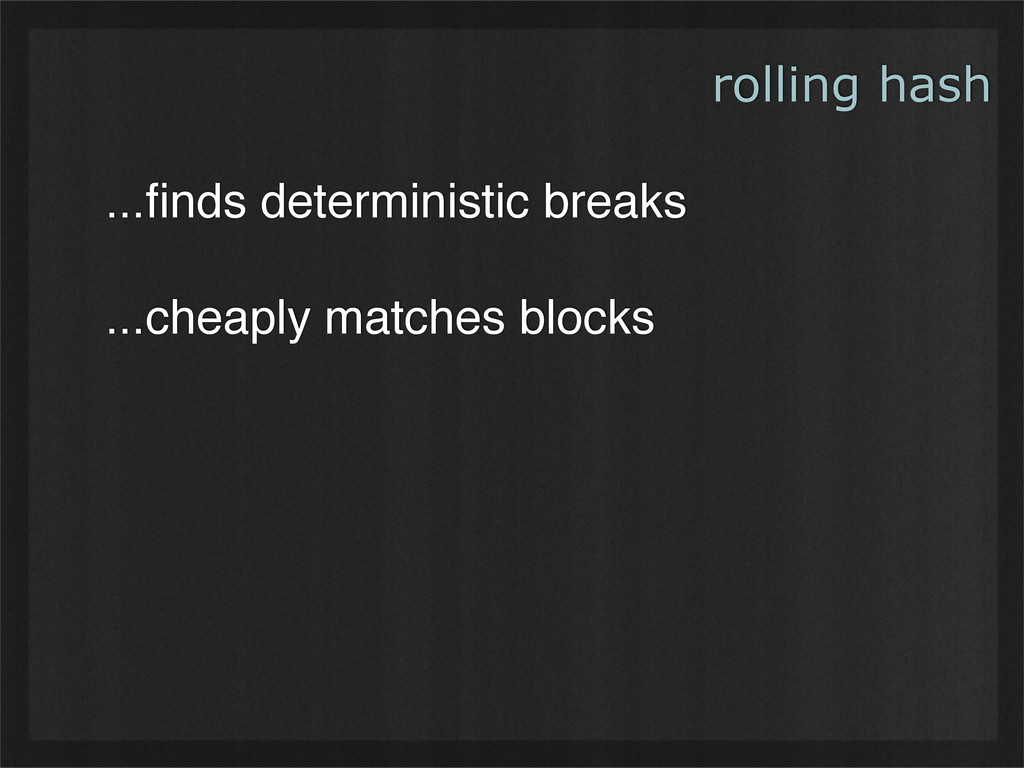
- Rolling hashes can find deterministic breaking points in buffers of binary data, enabling consistent chunking and re-use as data changes. (Example use case: rsync.)
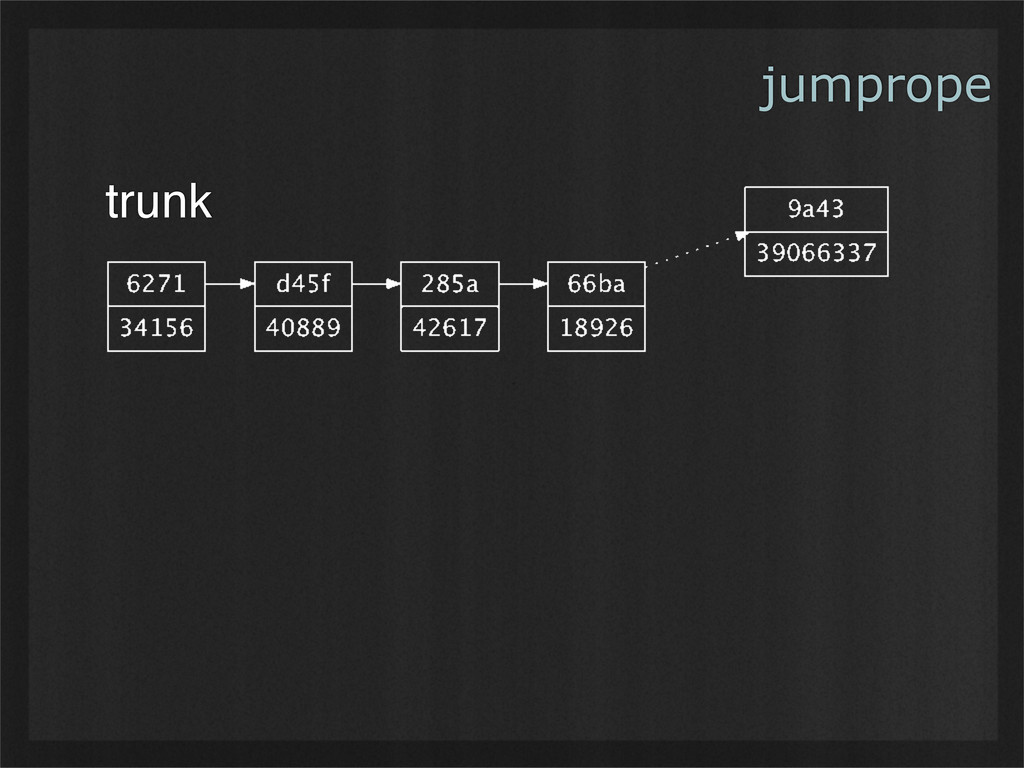
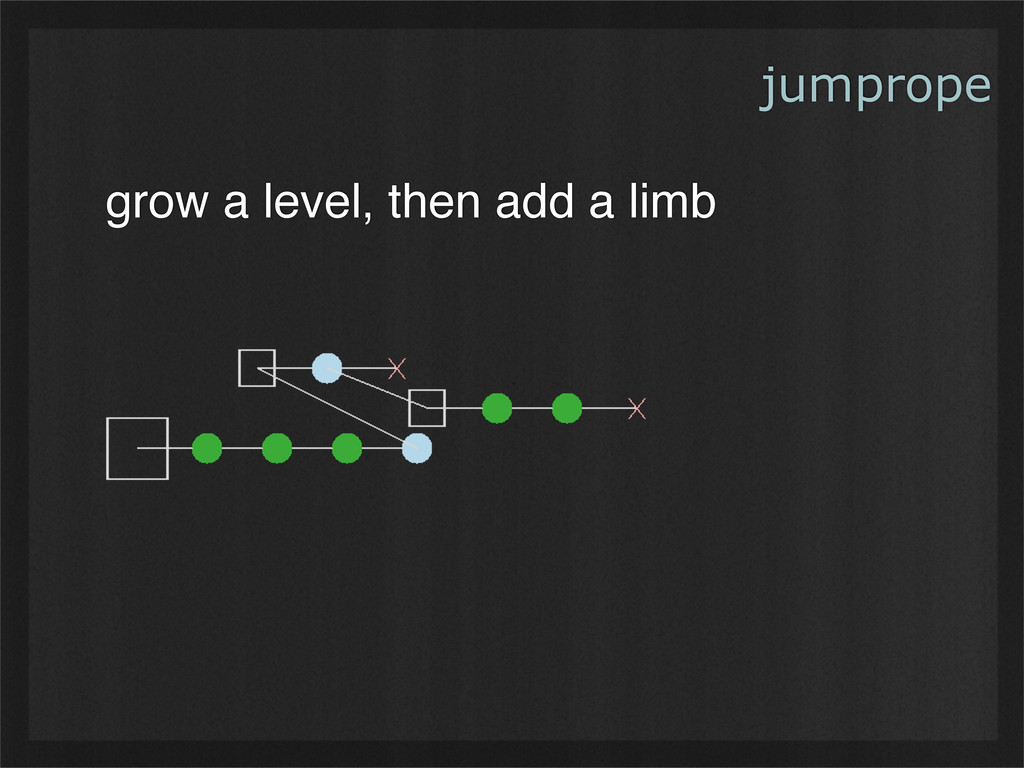
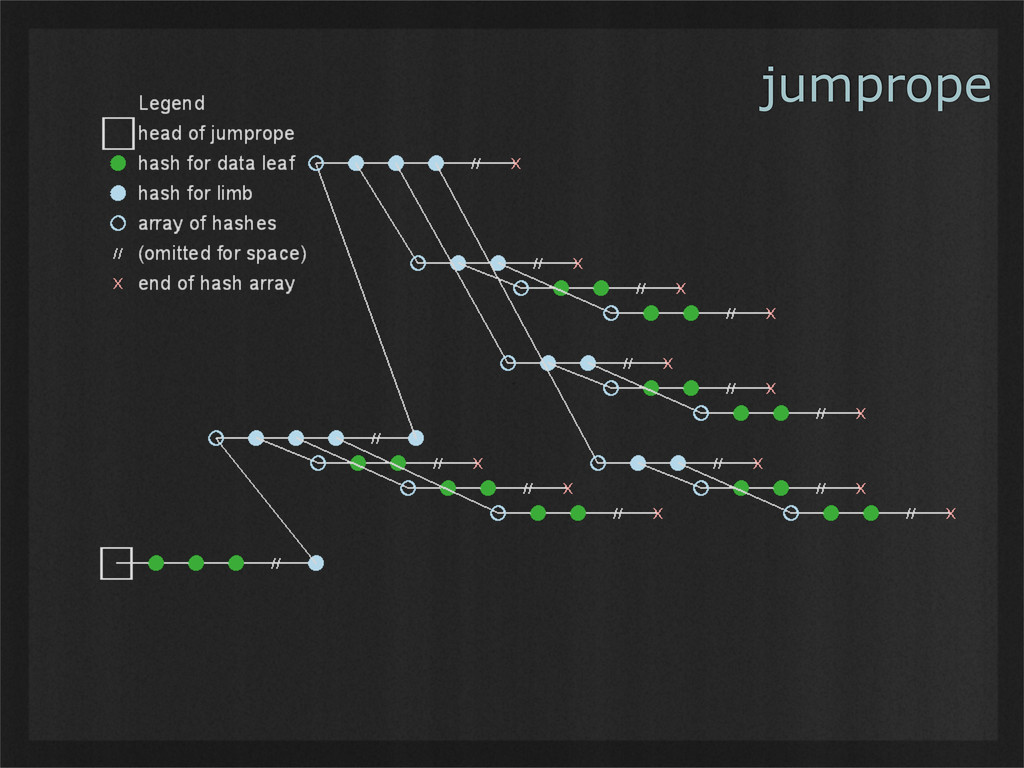
- Jumpropes (a data structure of my own invention) automatically de-duplicate content stored in them, including data shared between multiple files. Modified content can be stored with very little additional overhead, allowing for cheap versioning. Finally, the next several fragments can always be retrieved in parallel, enabling simple buffering for streaming media. (Example use case: scatterbrain, a distributed filesystem to be released soon.)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Unification ?- [X, Y, X] = [1, 2, Z]. X](https://files.speakerdeck.com/presentations/31b054101a2c01309a9f1231381a9bc7/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
![Unification ?- [X, Y, H] = [1, 2, Z]. X](https://files.speakerdeck.com/presentations/31b054101a2c01309a9f1231381a9bc7/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
![?- A = [1,2|B], B = [3|C] A = [1,](https://files.speakerdeck.com/presentations/31b054101a2c01309a9f1231381a9bc7/slide_41.jpg){kind=link}
![?- A = [1,2|B], B = [3|C] A = [1,](https://files.speakerdeck.com/presentations/31b054101a2c01309a9f1231381a9bc7/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}