If you don’t understand your datastore’s strengths and weaknesses, your application is not going to scale. When is it best to carefully craft a SQL query to get exactly the information you want, and when should you just say “find(45)” and munge your data in application code?
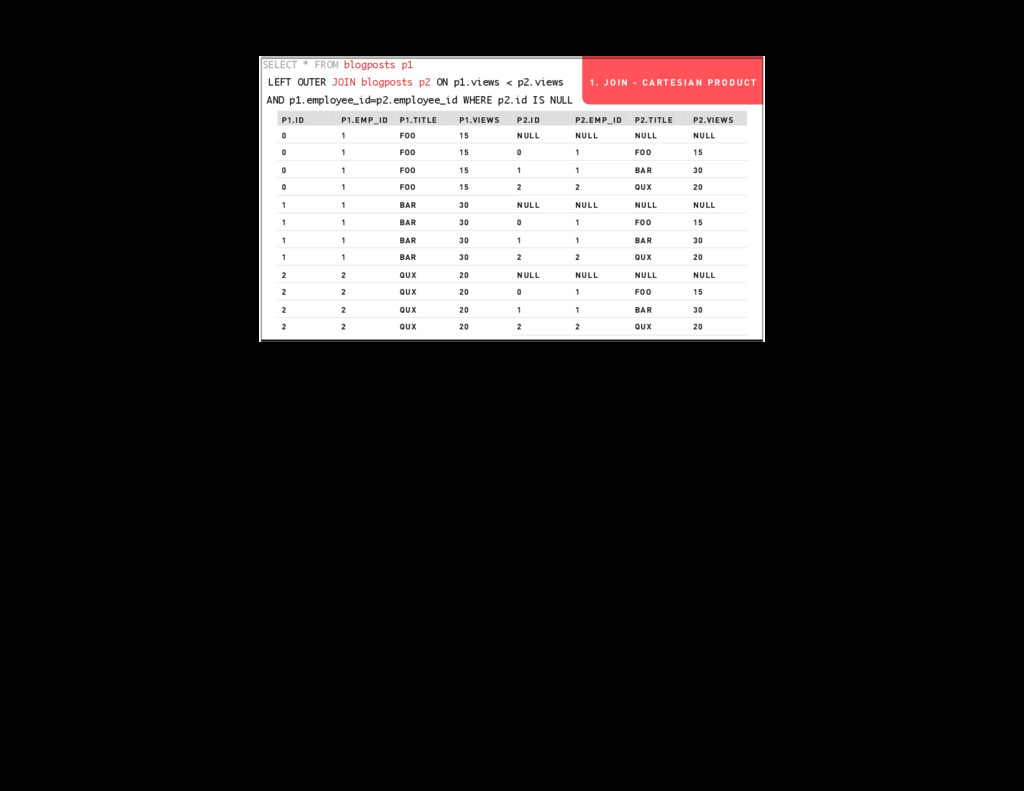
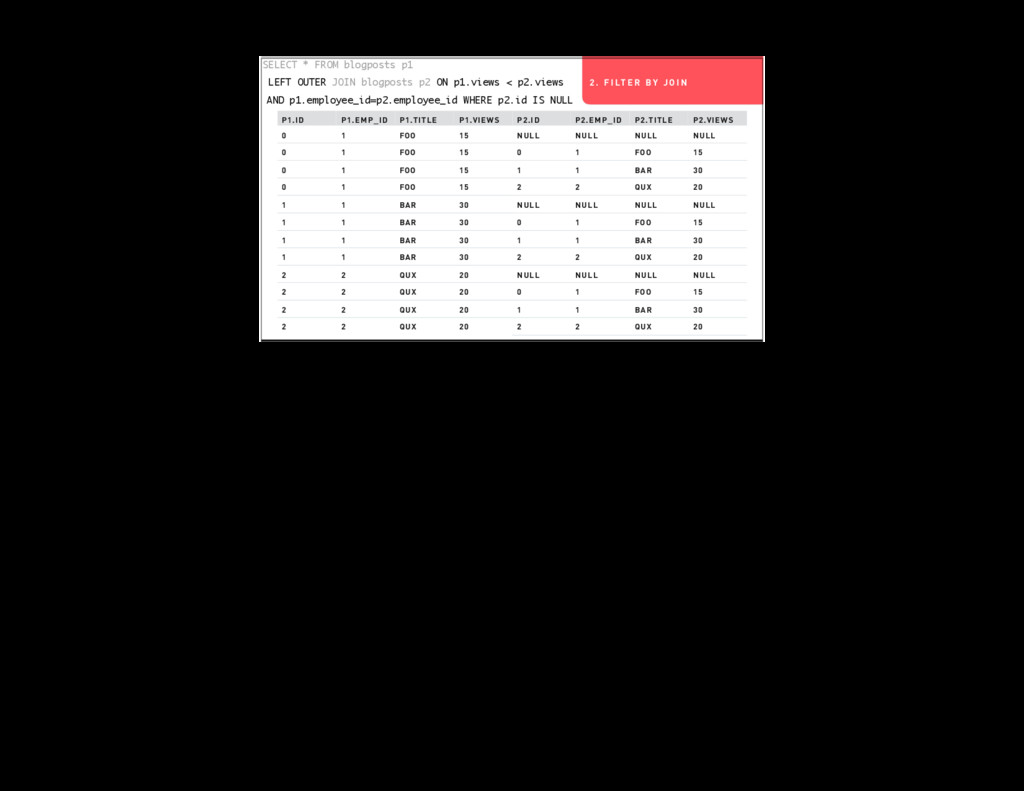
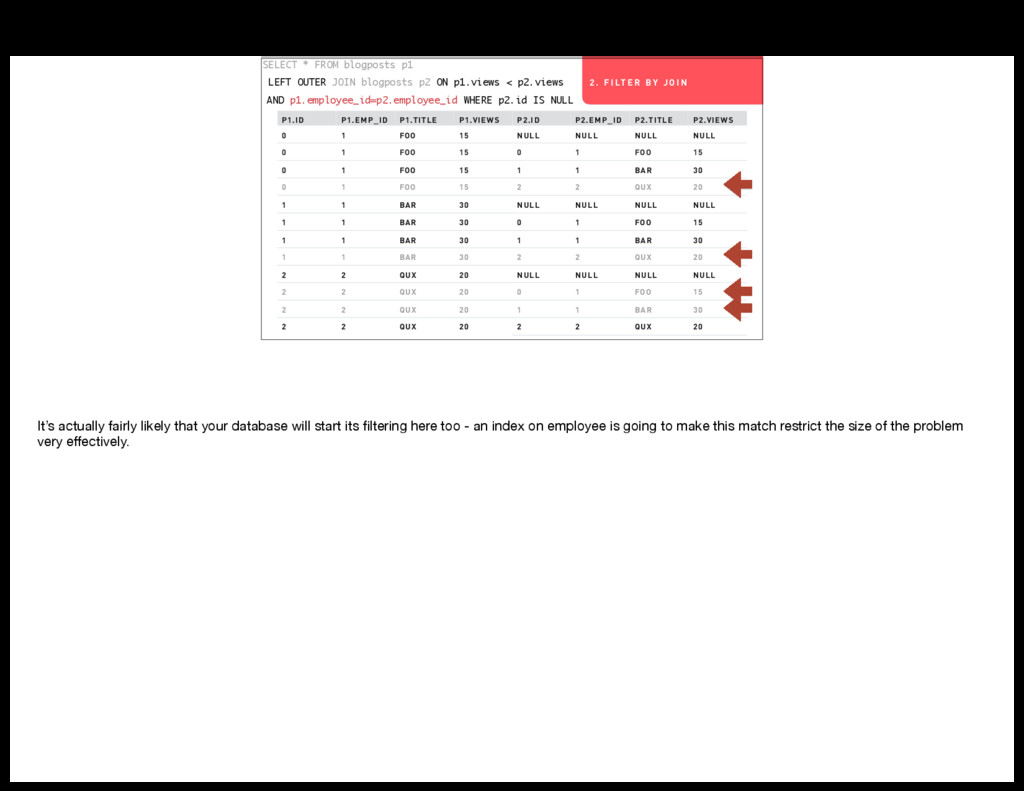
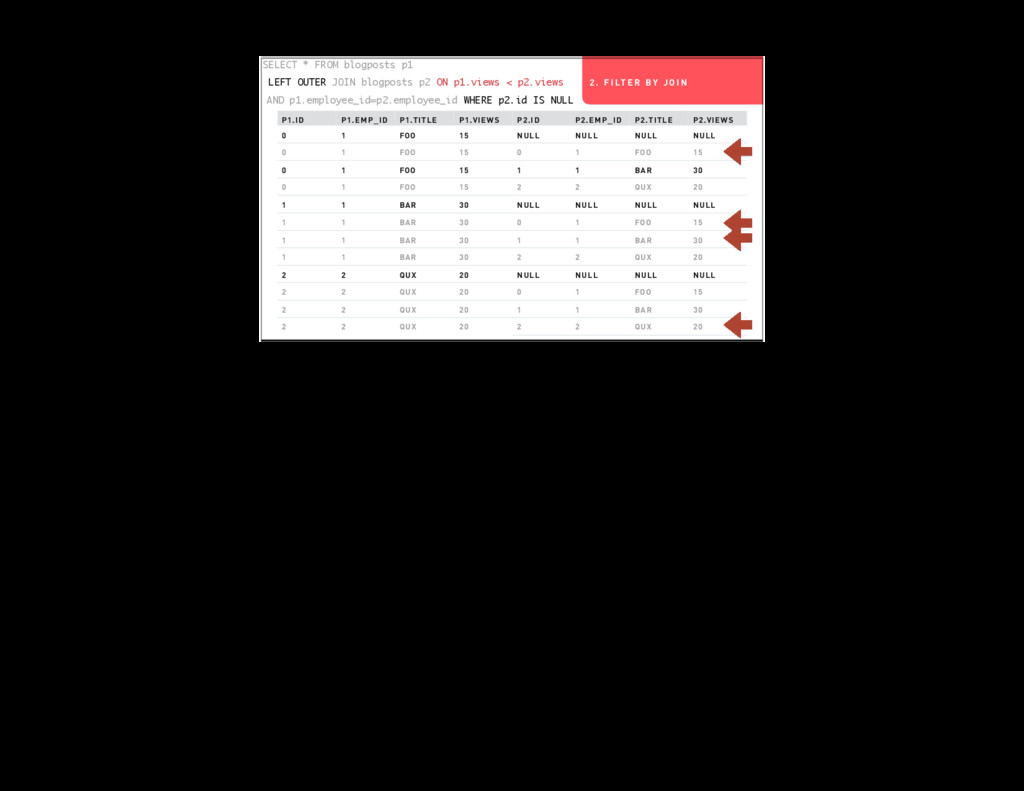
Armed with a better understanding of SQL’s worldview you can make better decisions about what work goes in what part of your systems. We’re going to dig into a couple of example queries that do things like joining tables to themselves and intentionally creating cartesian products.
For each example you’ll see both sides of the coin:
- Conceptually what each query is doing (as relational algebra)
- Practically what each query is doing (iterating over data structures in your database)
Seeing this complete picture will let you write queries that solve common real-world problems and debug the performance of your existing queries. You won’t need to be an expert in ActiveRecord, Hibernate, or another ORM, but a working knowledge of SQL will help you get the most out of this talk.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
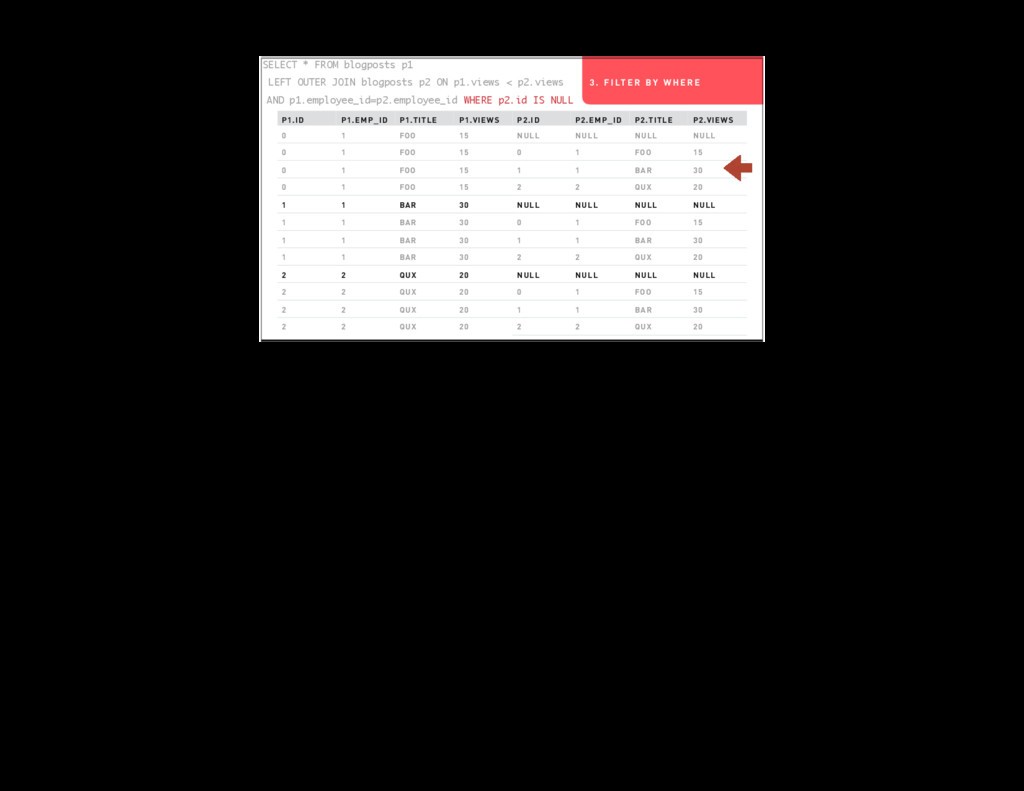{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
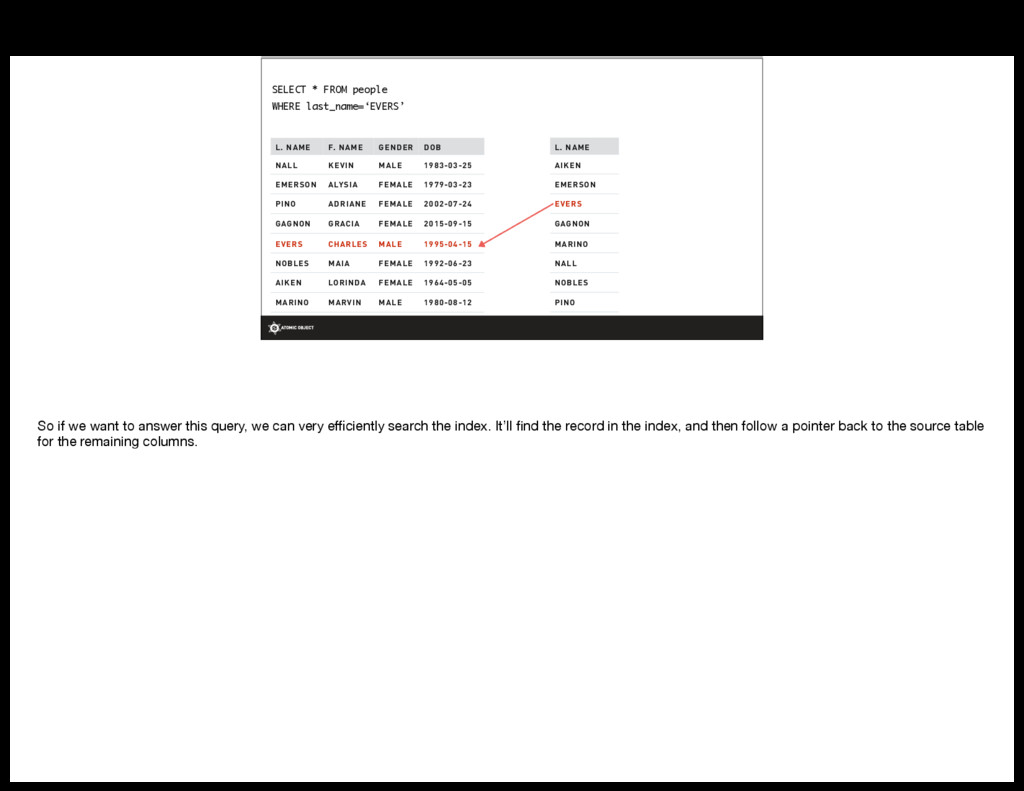{kind=link}
{kind=link}
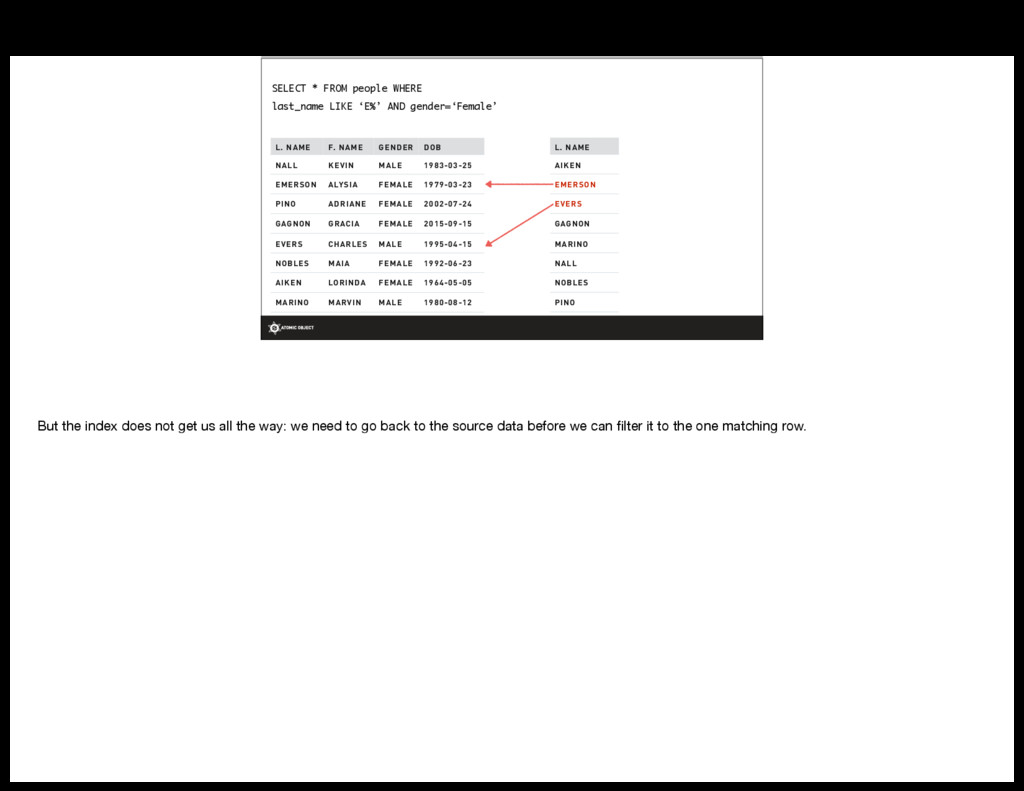{kind=link}
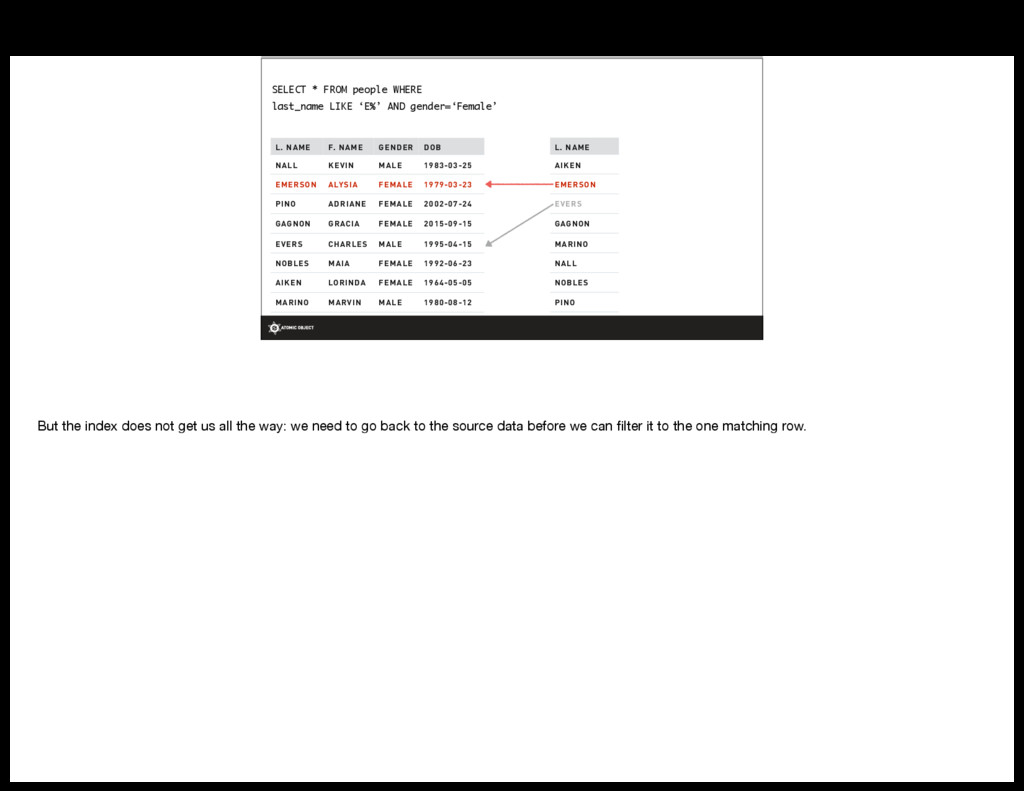{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}