usual_dim integer[4], nested text[][], nested_dim integer[3][3], ansi_sql integer ARRAY, ansi_sql_dim integer ARRAY[4] ); SELECT ‘{1,2,3}’, ARRAY[1,2,3], ‘{ {1,2,3}, {4,5,6} }’, ARRAY[ [1,2,3], [4,5,6] ]; SELECT '{1,2,3}'::int[][1]; -- outputs: 1, since indeces start from 1 SELECT '{1,2,3}'::int[][2:3]; -- result: {2,3} UPDATE my_array SET my_array [4] = 15000; UPDATE my_array SET my_array[1:2] = ‘{1,2}’; SELECT ‘{1,2}’::int[] || ‘{3,4}’::int[]; -- result: {1,2,3,4} SELECT ARRAY[1,4,3] @> ARRAY[3,1]; -- true SELECT unnest(string_to_array(‘a.b’, ‘.’)); --- arrays from query SELECT ARRAY (SELECT * FROM orders WHERE status = ‘pending’); unnest text a b
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data types: Arrays SQL CREATE TABLE test_arrays ( usual integer[],](https://files.speakerdeck.com/presentations/25676950b713013184ac42b7f74d85e8/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data types: JSON JSON operators SELECT array_to_json('{{1,5},{99,100}}'::int[]); -- [ [1,5],[99,100]](https://files.speakerdeck.com/presentations/25676950b713013184ac42b7f74d85e8/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
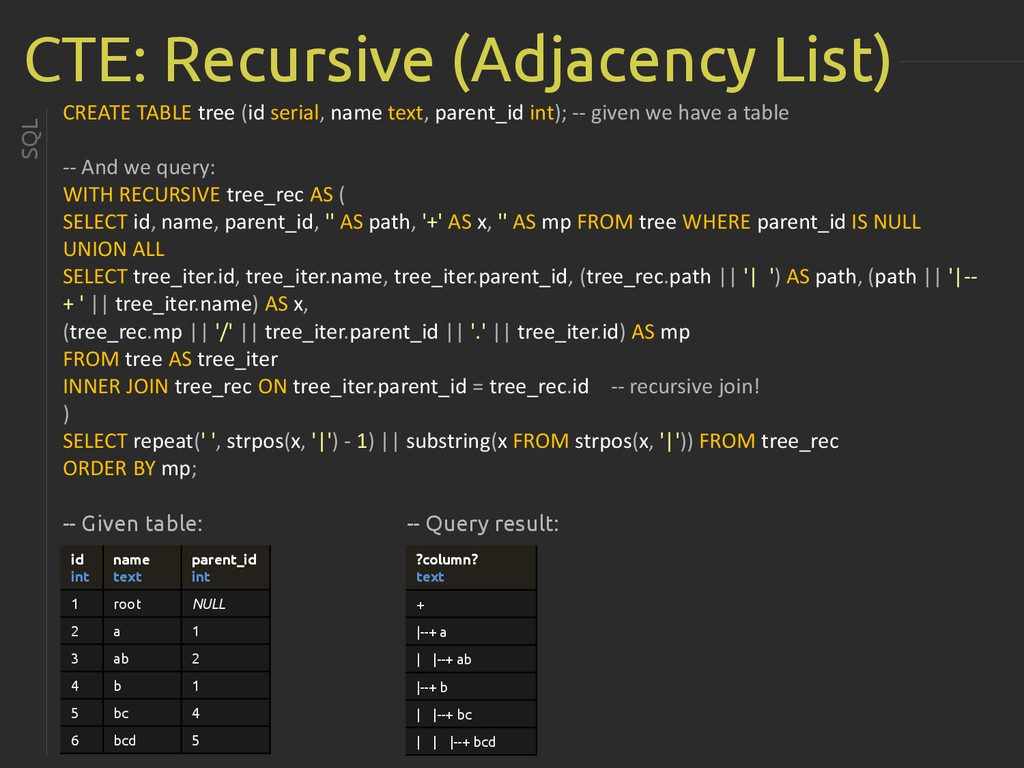{kind=link}
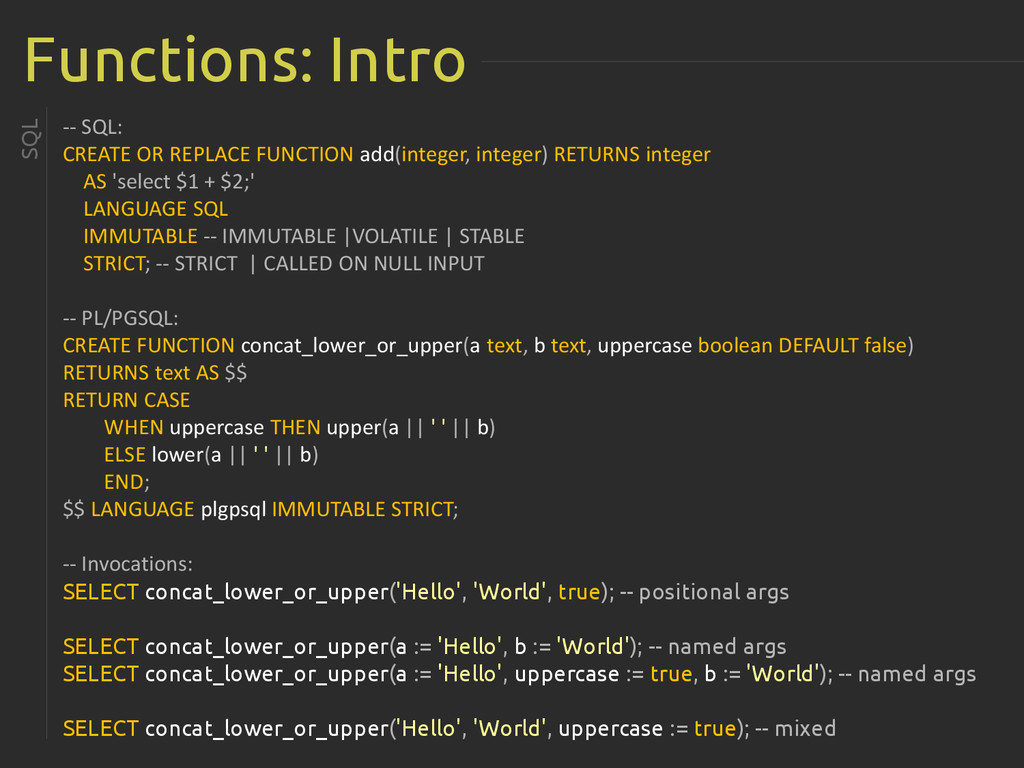{kind=link}
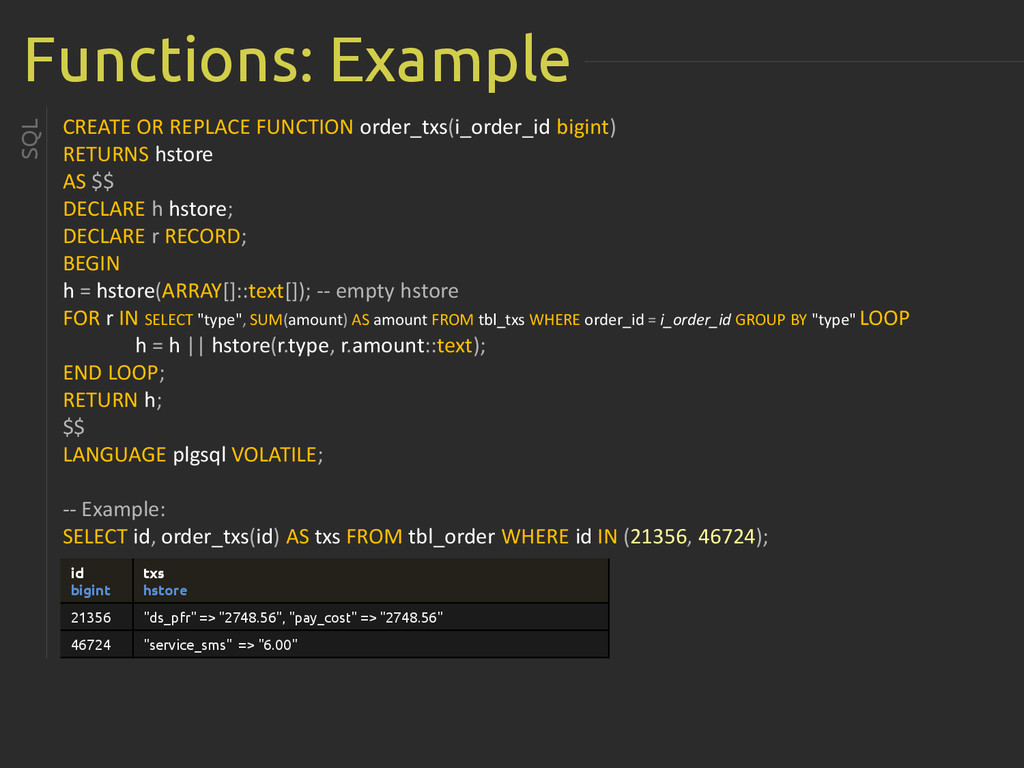{kind=link}
{kind=link}
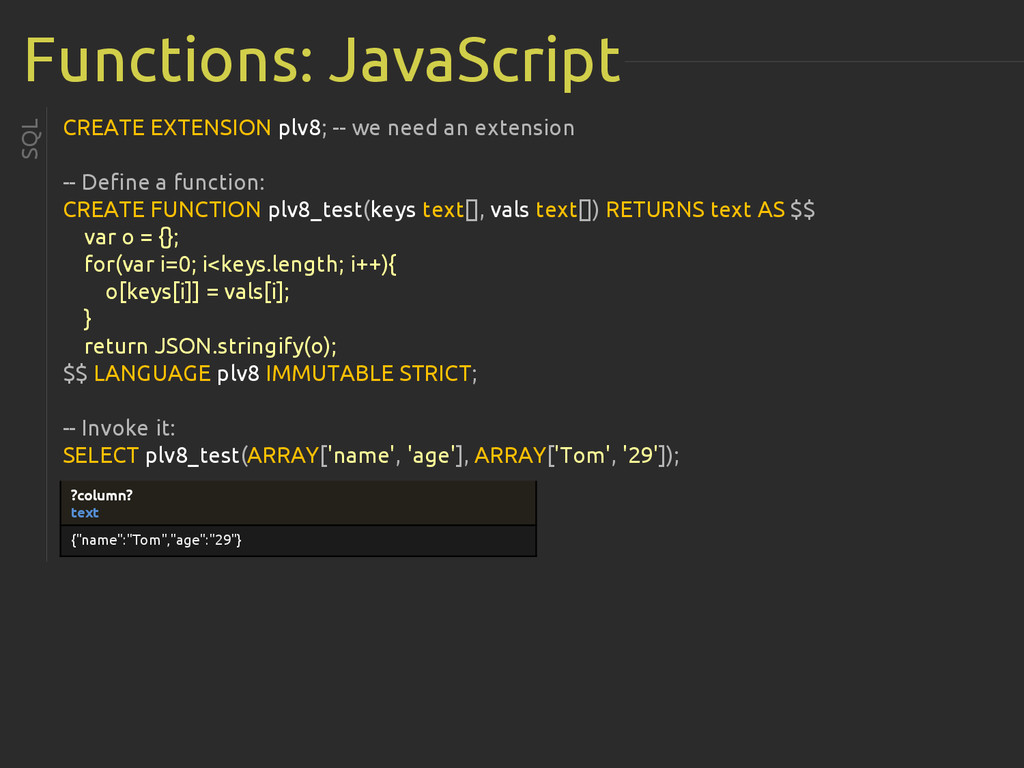{kind=link}
{kind=link}
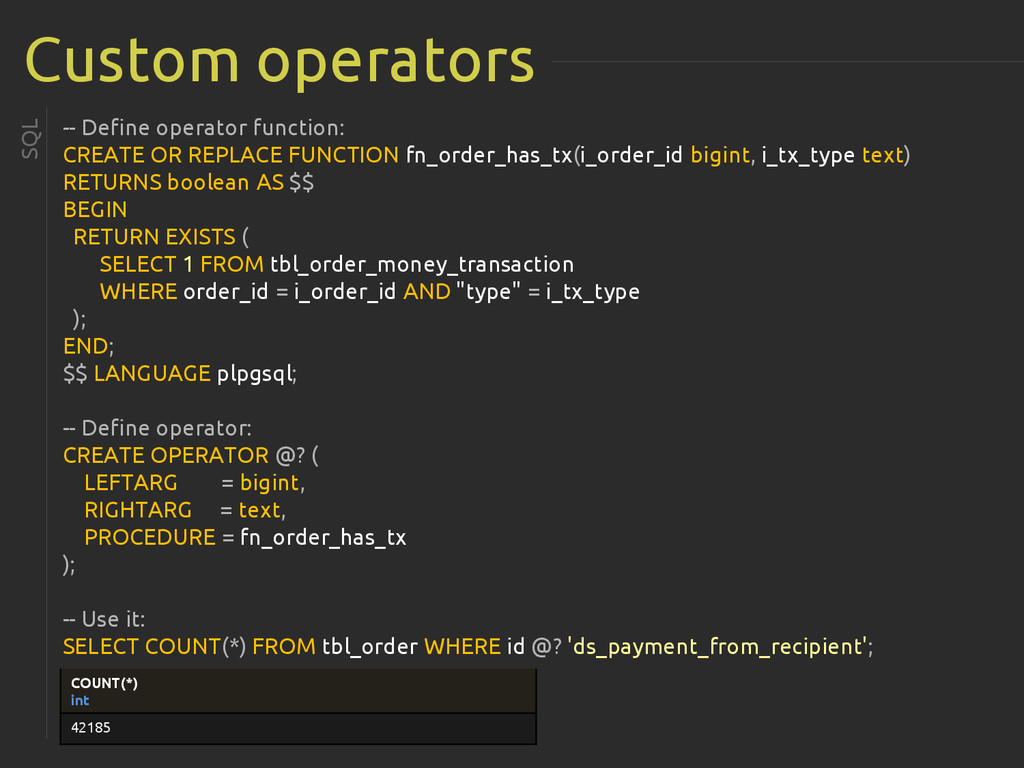{kind=link}
{kind=link}
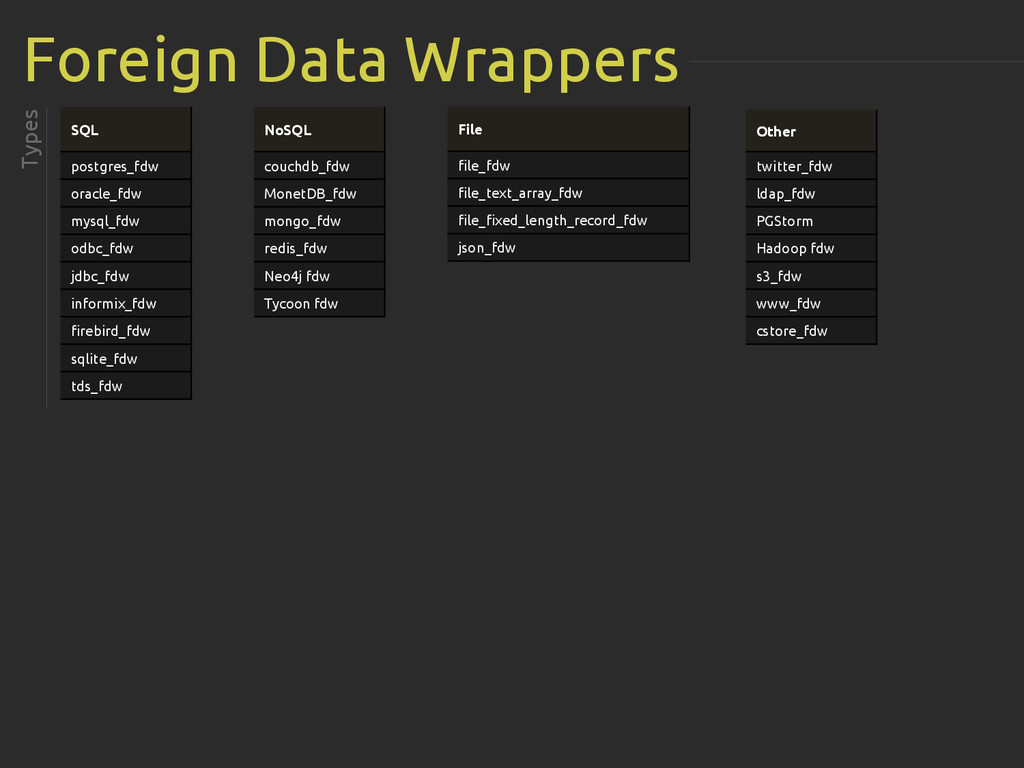{kind=link}
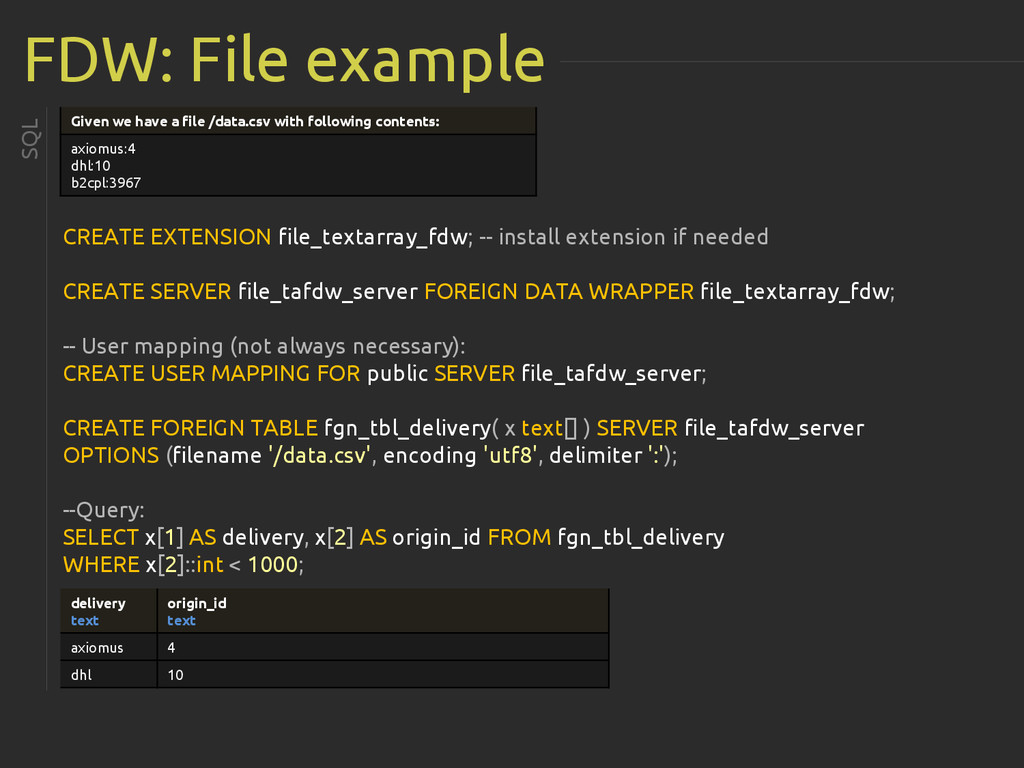{kind=link}
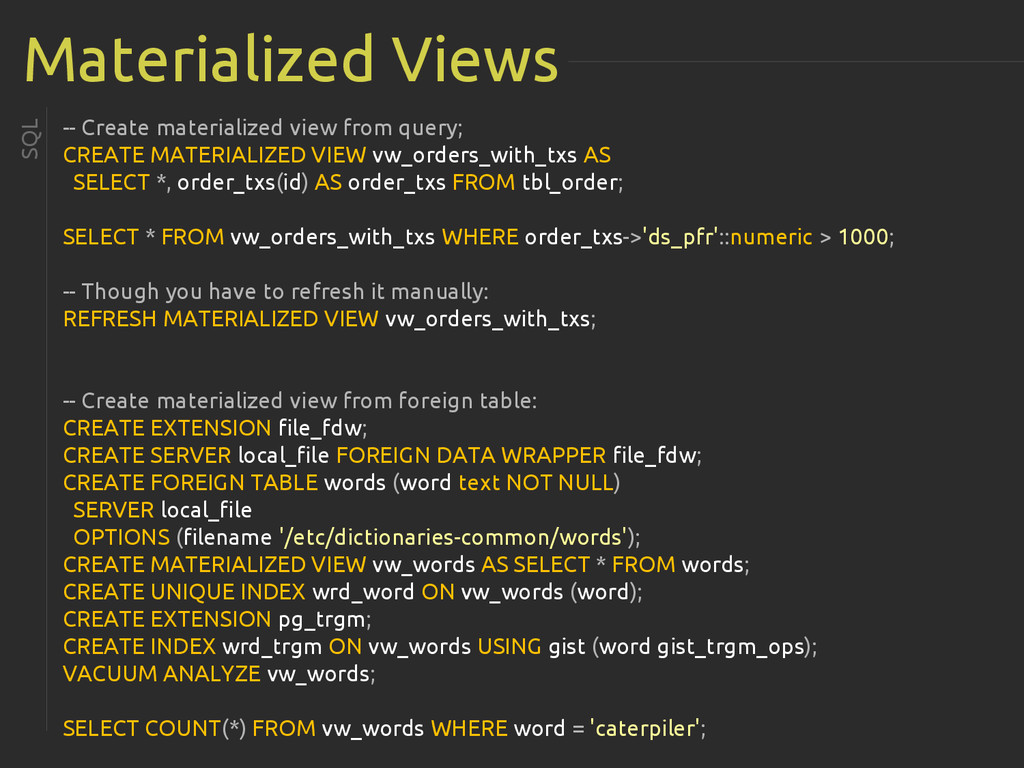{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THE END [email protected]](https://files.speakerdeck.com/presentations/25676950b713013184ac42b7f74d85e8/slide_37.jpg){kind=link}