⭐️ DevOps in Azure: Why Alert Emails are not a Monitoring Strategy#
With 24/7 enterprise cloud applications, the Ops part of DevOps is our top priority. We will walk you through our transformation from inbox-driven incident management to a scalable monitoring and alerting solution. We share the failures and pitfalls we encountered, and how we now leverage Azure’s monitoring capabilities to detect issues earlier, respond faster, and operate with minimal noise.
🙂 ALEXANDER SAMELI ⚡️ Cloud Platform Engineer @ Maison du Software
🙂 DANIEL STEINMANN ⚡️ Cloud Platform Engineer @ Maison du Software
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
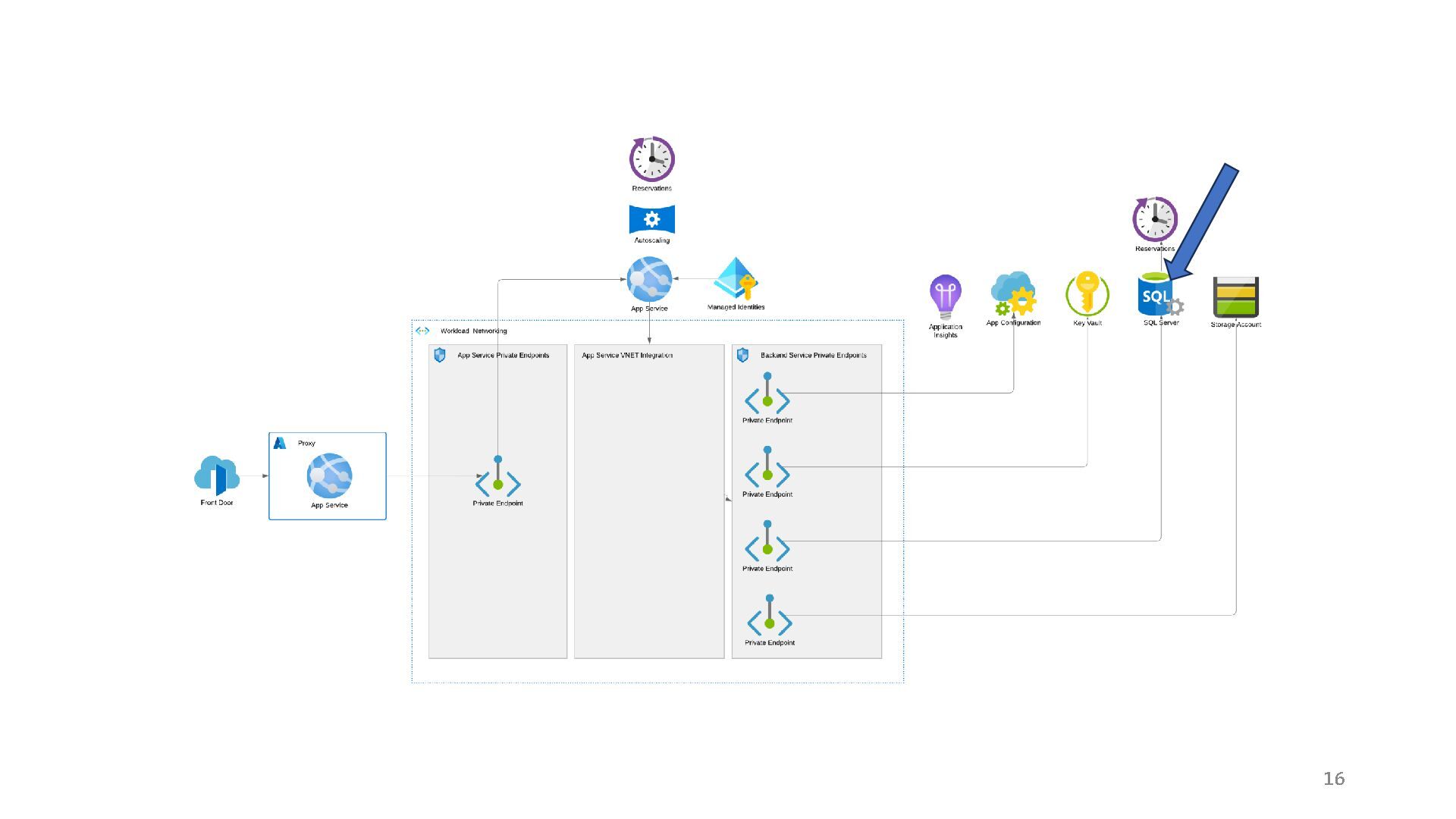{kind=link}
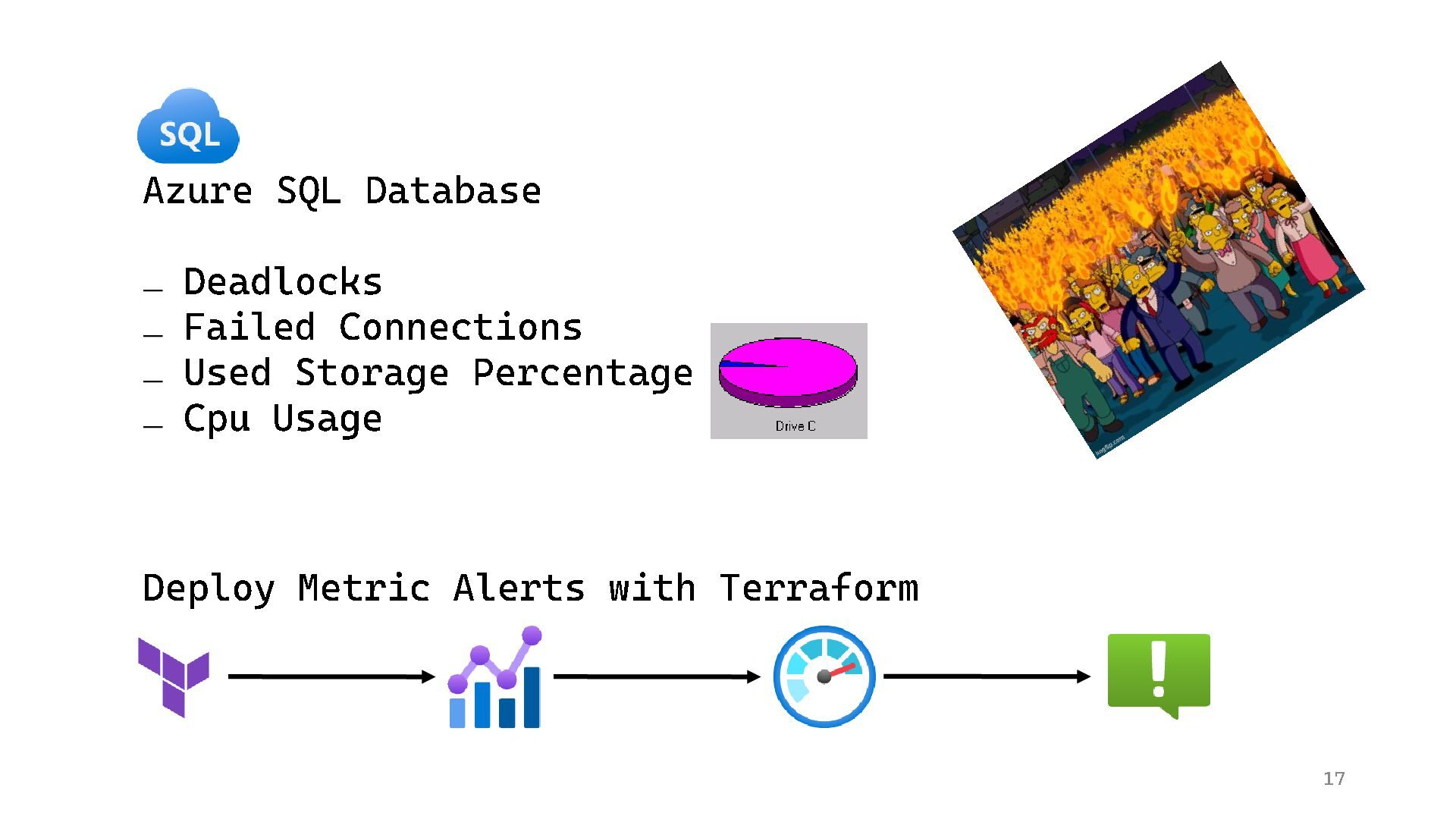{kind=link}
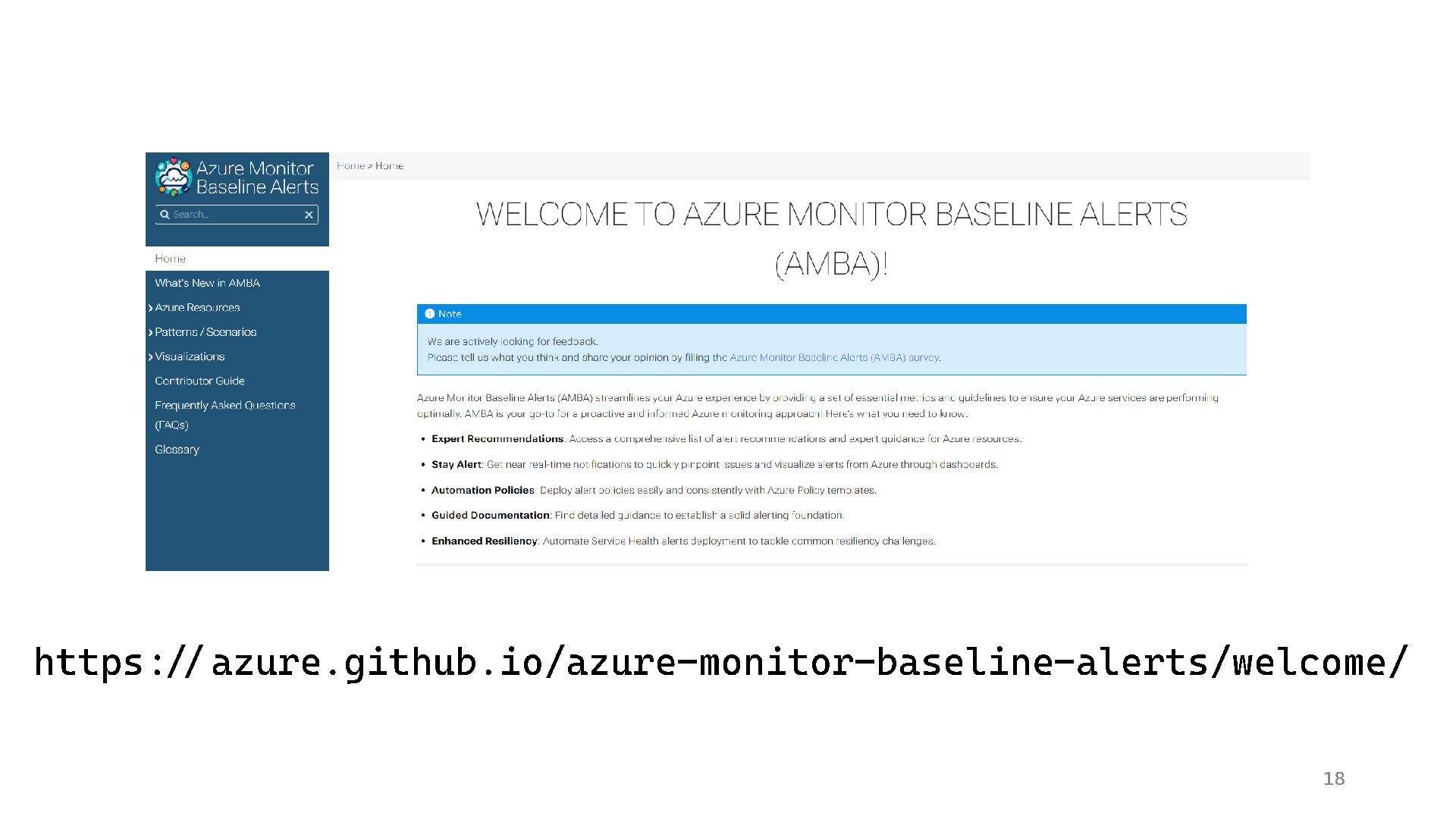{kind=link}
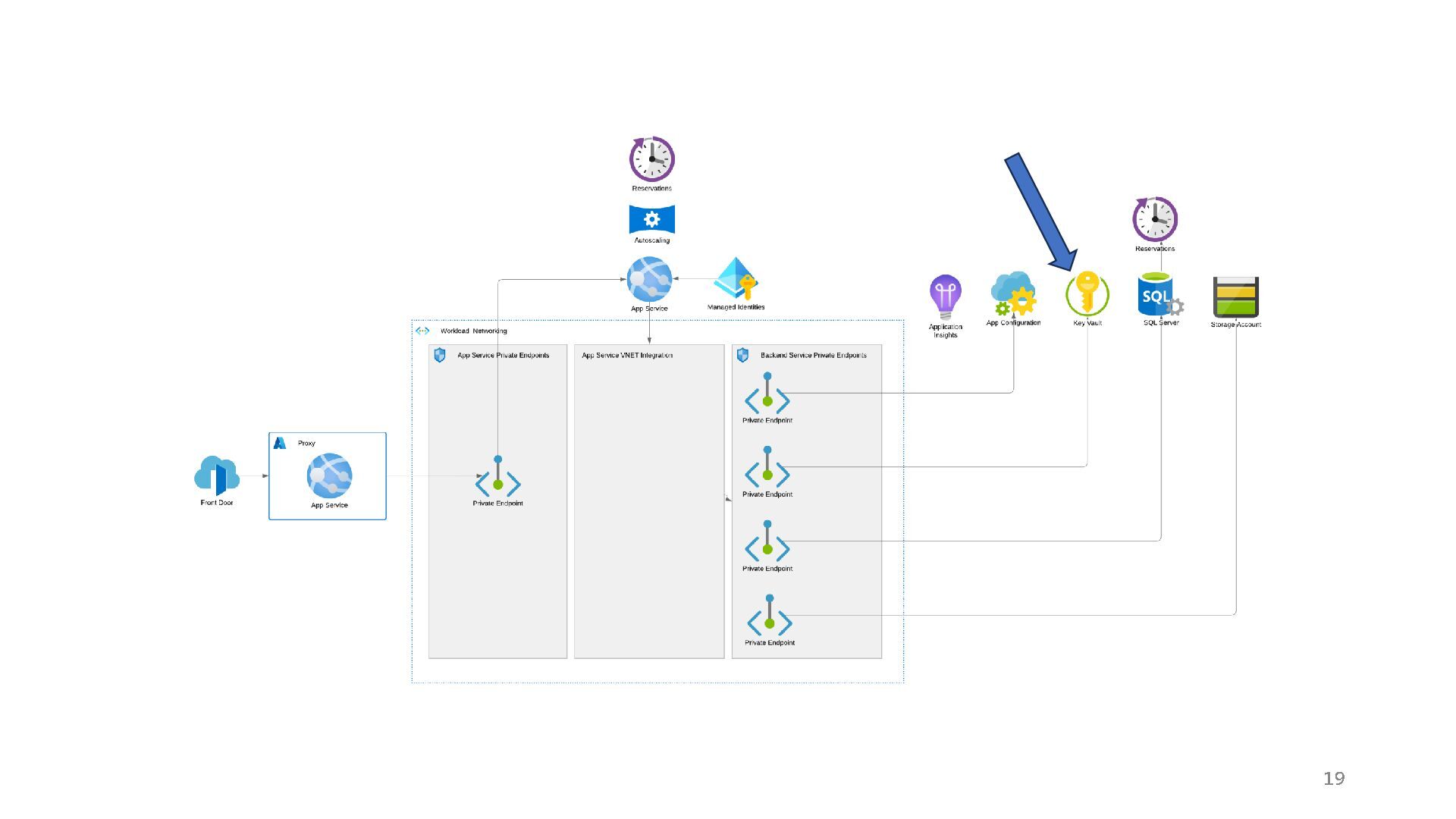{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
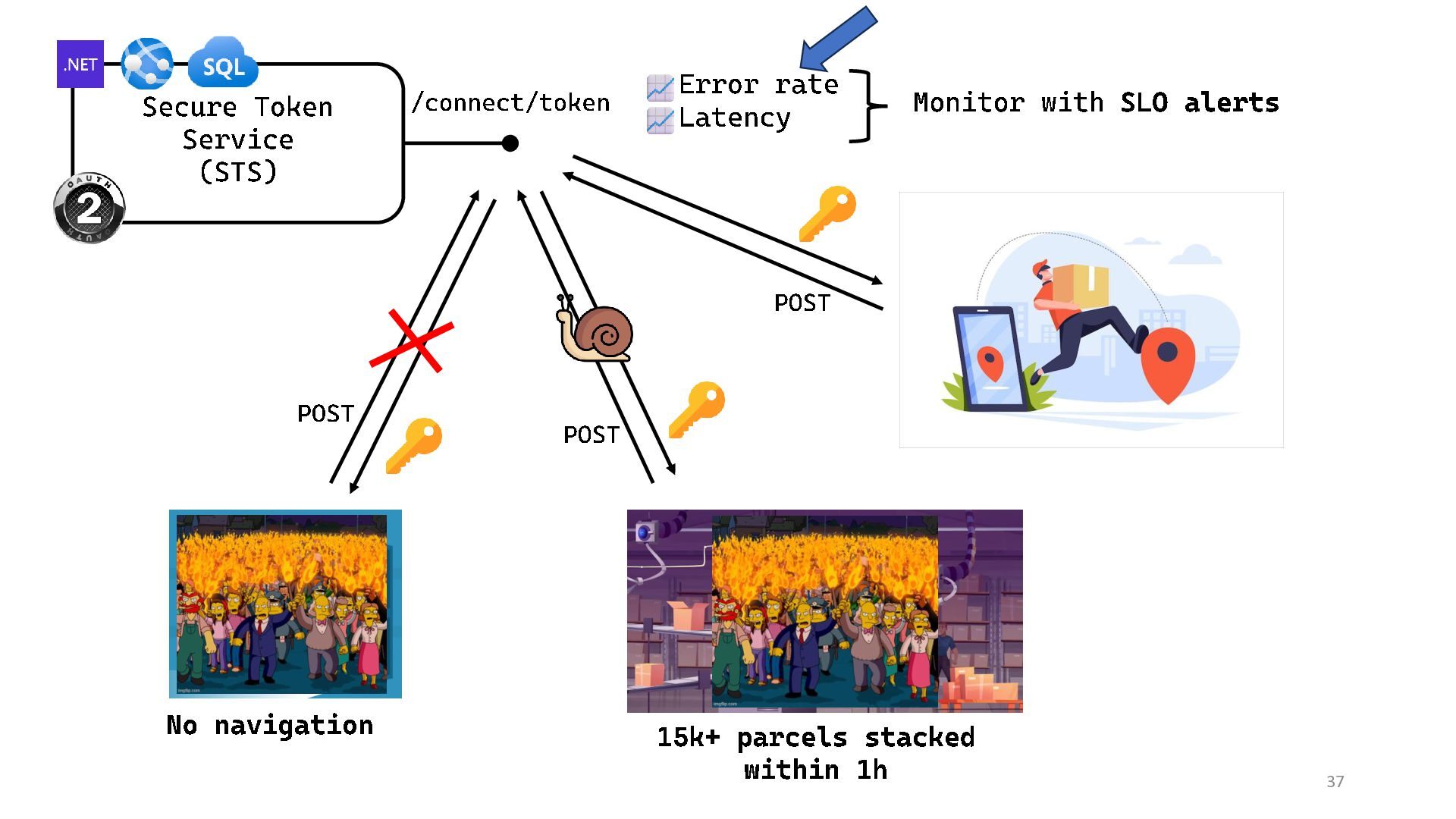{kind=link}
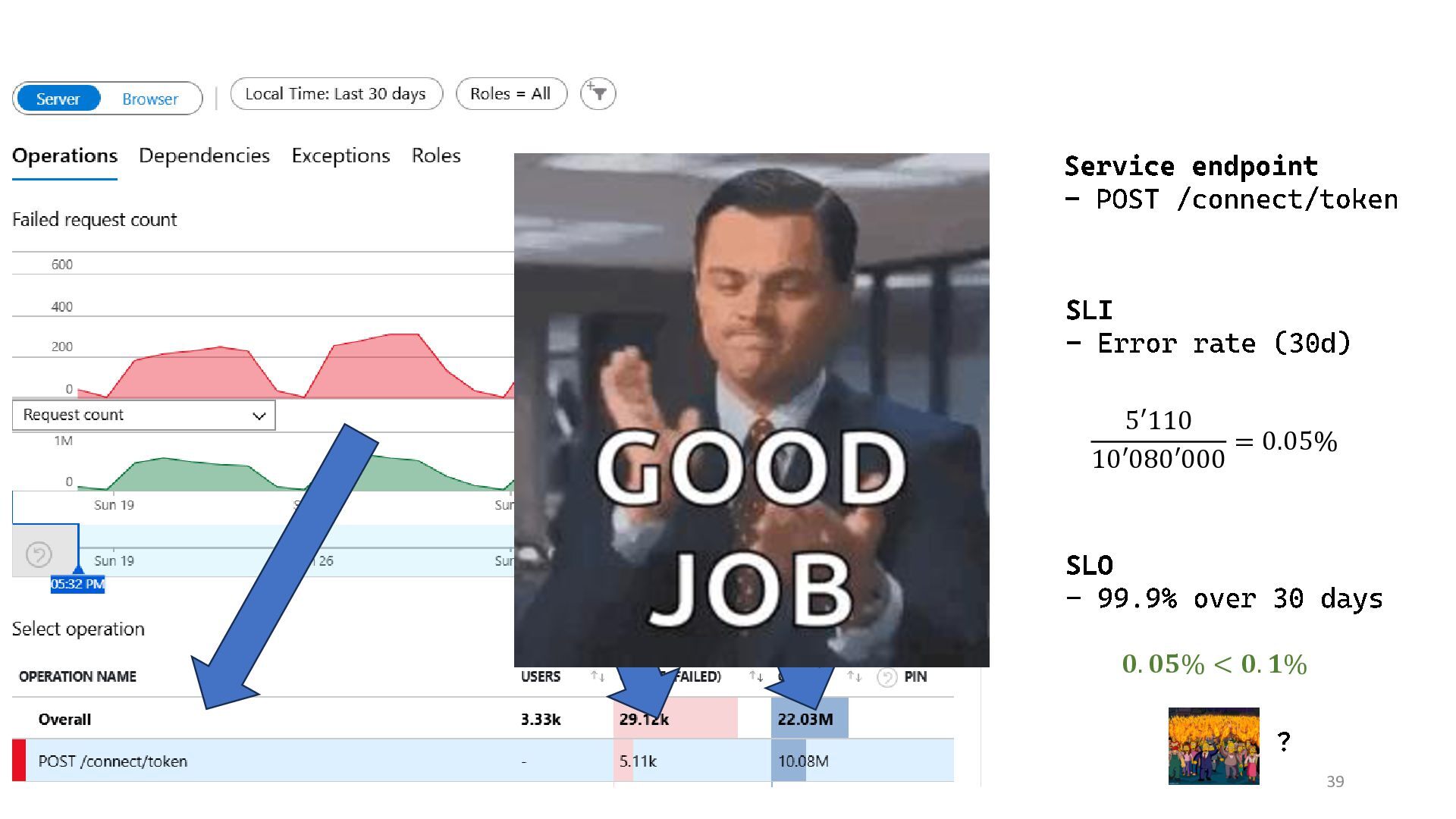{kind=link}
{kind=link}
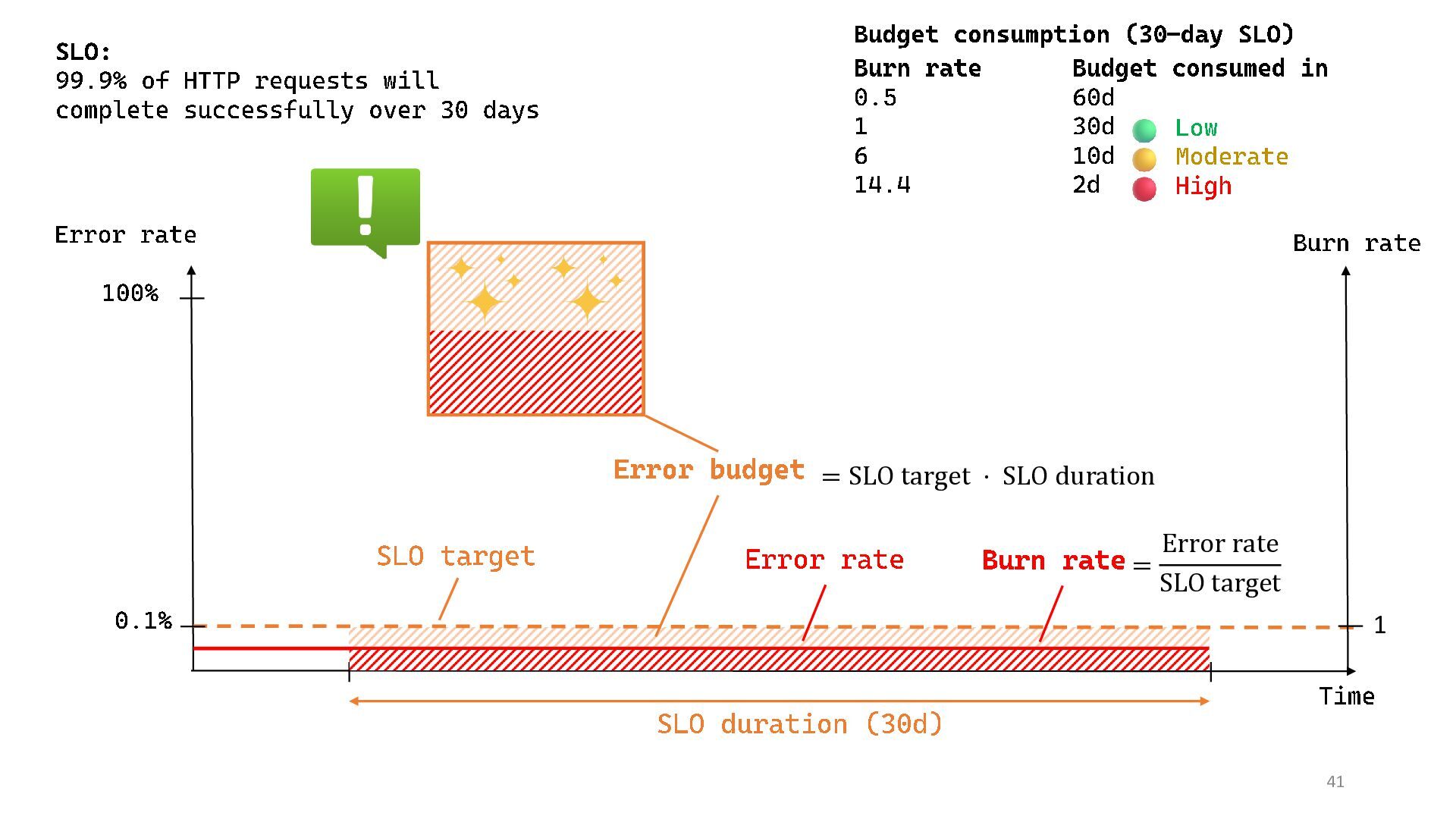{kind=link}
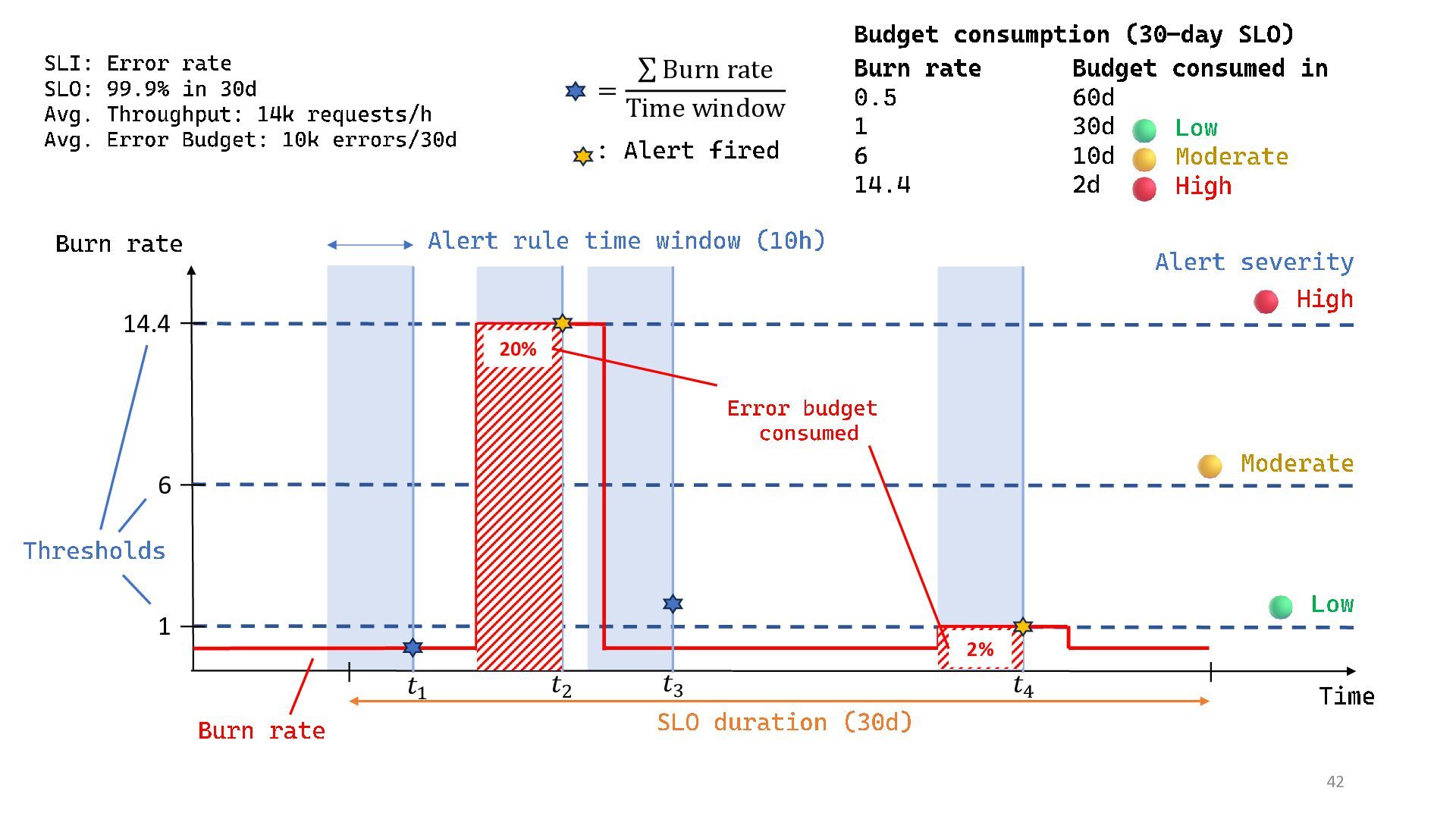{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}