Replicating data inside a Riak cluster and outside of it may sound like the same problem, but they aren't. Latency, bandwidth, security, and other factors make it a significantly different challenge. Basho has invested significant time and effort into building the masterless multi datacenter replication support that is part of Riak Enterprise. This talk will cover the problems, solutions, and evolution of Riak's Multi Data Center support as well as our plans for continued development and enhancement.
![Riak Replication October 12th 2012 Andrew Thompson [email protected] github.com/Vagabond](https://files.speakerdeck.com/presentations/507dc0d06c91910002003a03/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
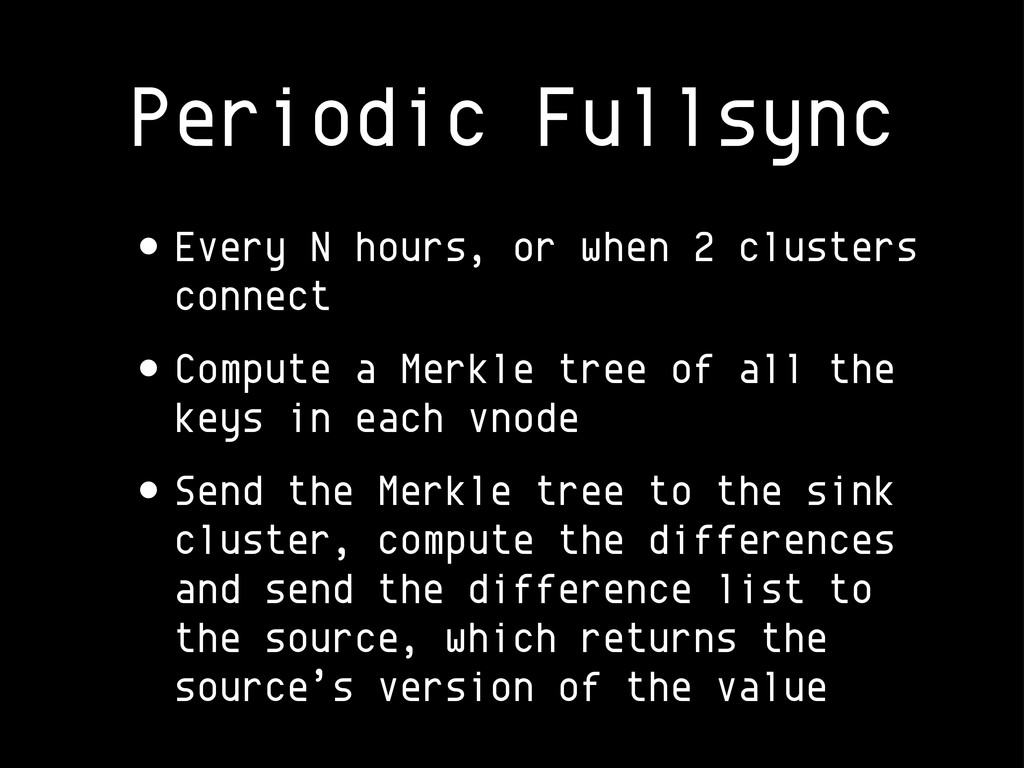{kind=link}
{kind=link}
{kind=link}
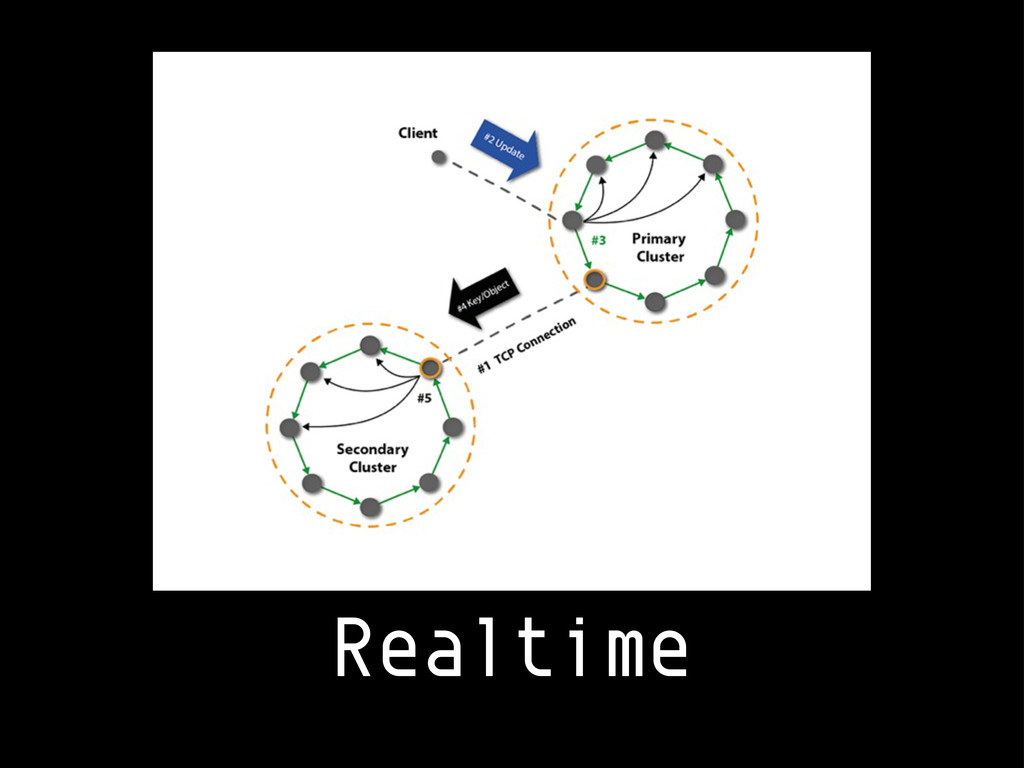{kind=link}
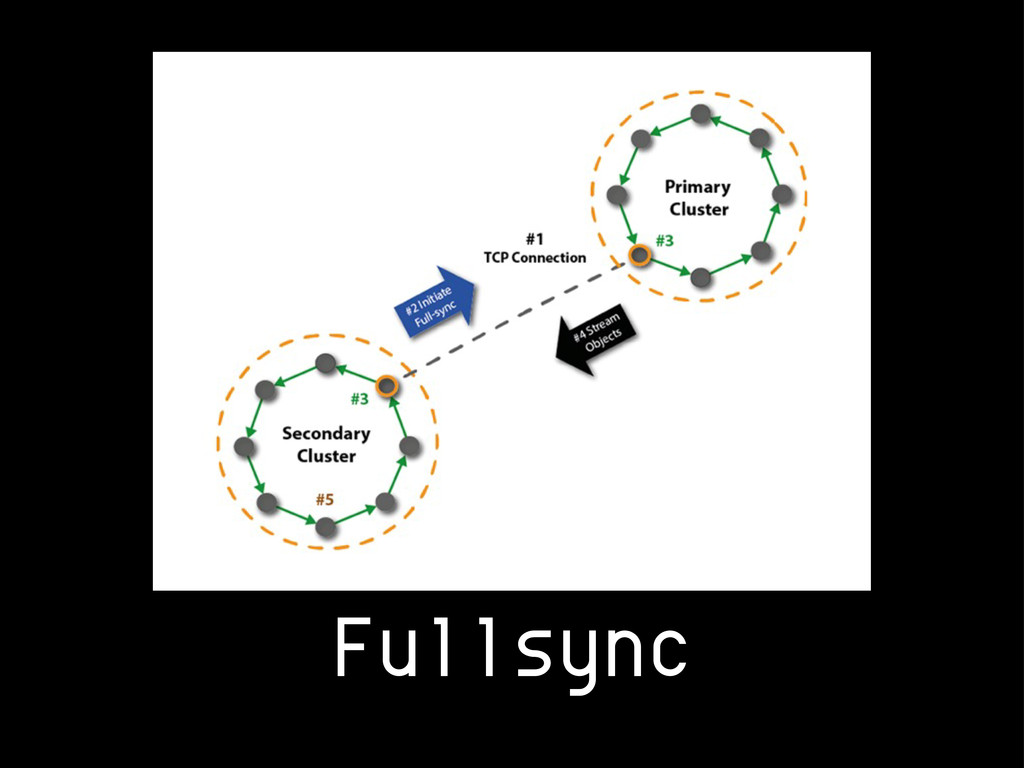{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
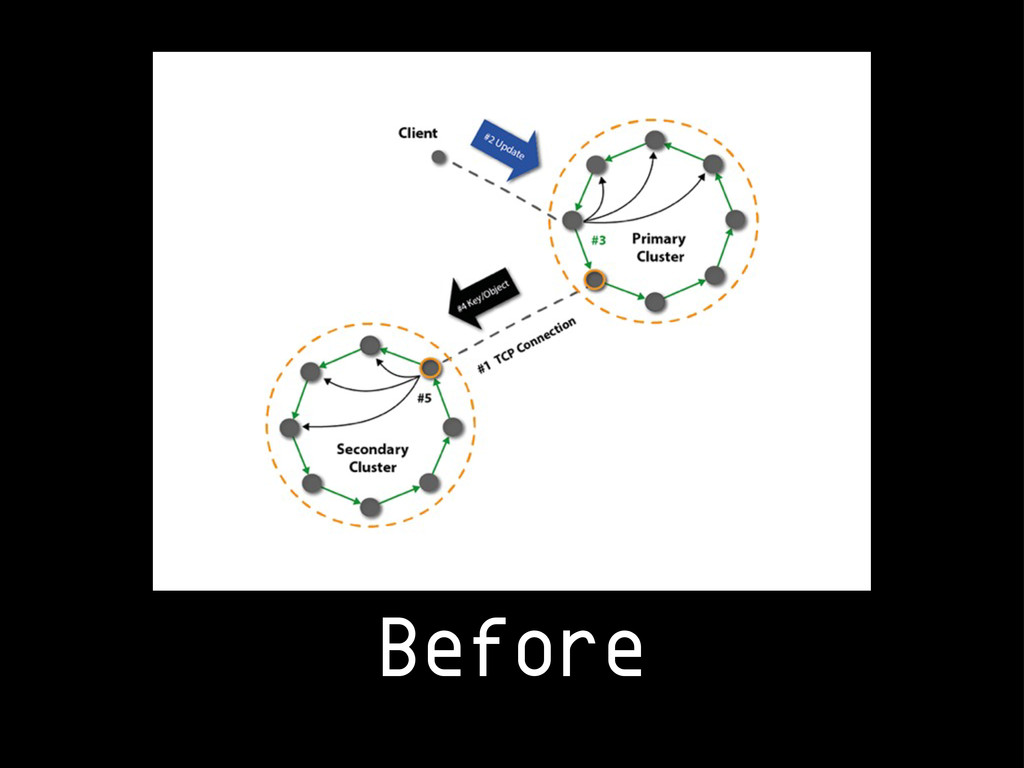{kind=link}
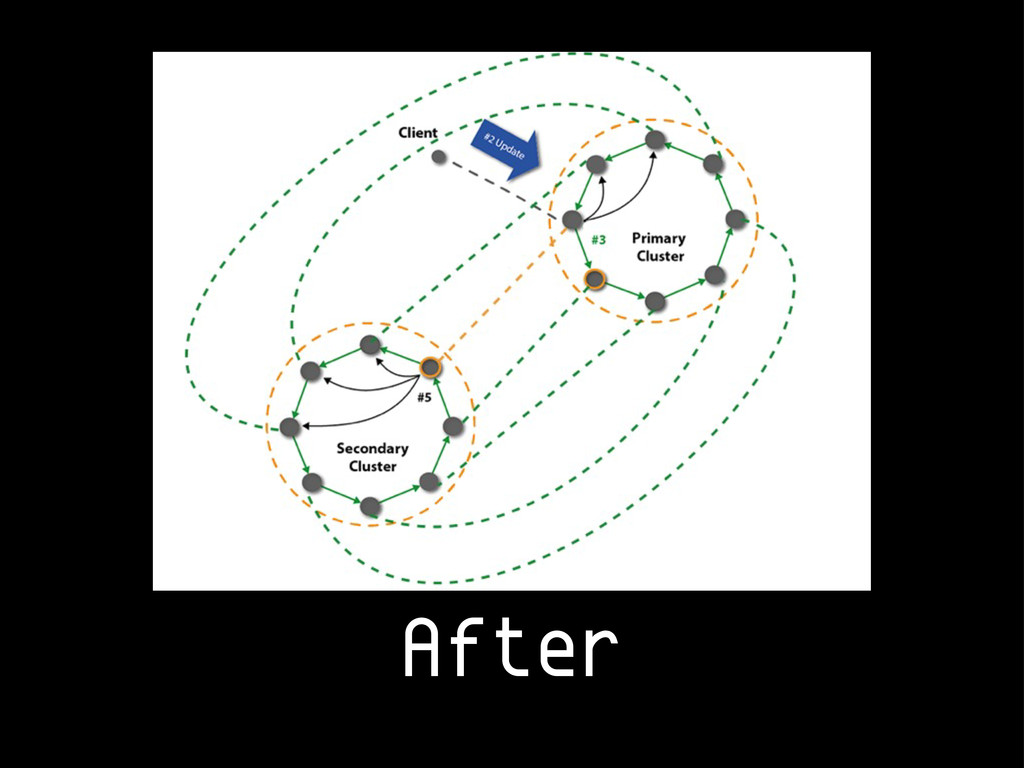{kind=link}
{kind=link}
{kind=link}
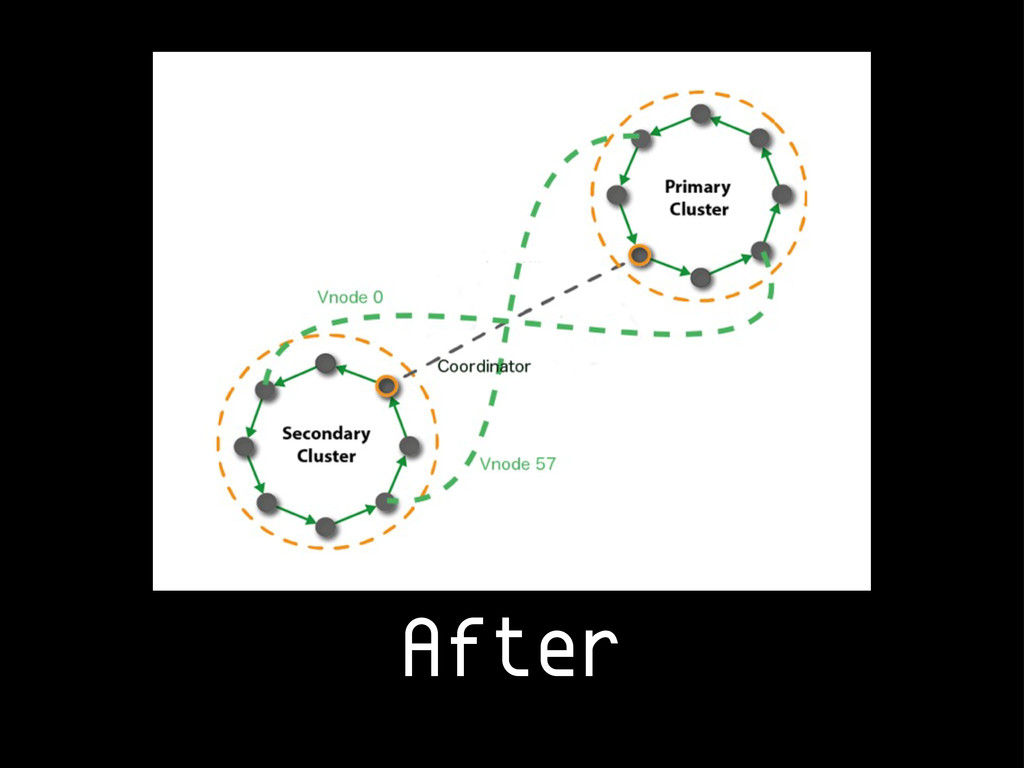{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}